ACL(Annual Meeting of the Association for Computational Linguistics)是计算语言学和自然语言处理(NLP)领域的国际顶级学术会议。自 1962 年创办以来,ACL 已成为 NLP 领域规模最大、影响力最高的学术盛会,汇聚了来自全球学术界和工业界的顶尖研究者。
🎯 活动预告
6 月 11 日(周四)下午,我们将分享美团技术团队被 ACL 顶会收录的其中 6 篇论文,技术方向覆盖大模型评测、复杂流程推理、竞赛级数学思维优化、强化学习优化、生成式推荐等领域,欢迎一起交流学习,文末附议程。
2026年,美团技术团队数十篇论文被 ACL、SIGIR、ICML、KDD 等顶会收录,我们近期将精选 32 篇文章,分成 5 大专场进行解读。
>> 报名请点击这里 <<
------ 报名 1 次即可听 5 场前沿分享 ------

01 CoreCodeBench: Decoupling Code Intelligence via Fine-Grained Repository-Level Tasks
CoreCodeBench:通过细粒度仓库级任务解耦代码智能
论文下载 :PDF
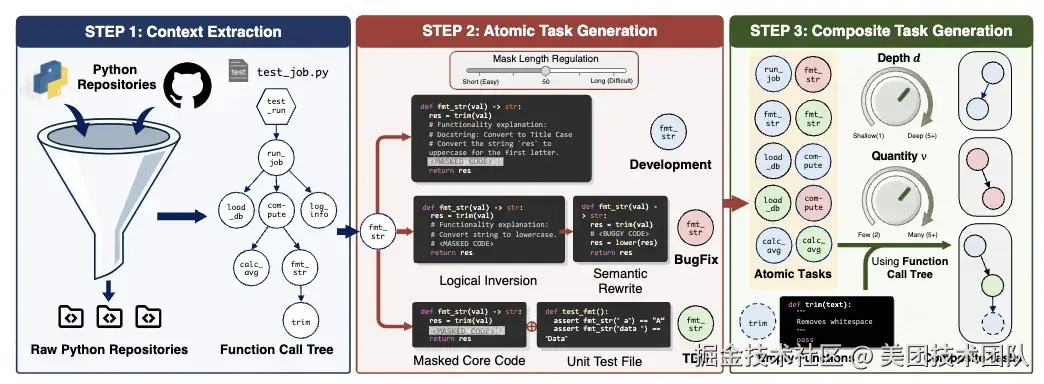
论文简介: 本论文提出了 CoreCodeBench,一种面向大语言模型编程能力的细粒度评测基准。该基准利用 COREPIPE 框架,从 12 个 Python 开源库自动生成 1,524 个结构化任务,涵盖开发、修复、测试驱动开发等多种软件工程场景,有效区分不同认知负载并动态调整任务复杂度。实验表明,其有效性达 78.55%,显著优于现有方法,揭示了模型在不同任务类型上的能力错配现象。CoreCodeBench 还支持多任务组合评测,模拟真实开发环境,具备高自动化、强鲁棒性和可复现性,为代码智能评测提供了更全面、精准的框架。
02 SOP-Maze: Evaluating Large Language Models on Complicated Business Standard Operating Procedures
SOP-Maze:评估大语言模型在复杂业务标准操作流程上的表现
论文下载 :PDF
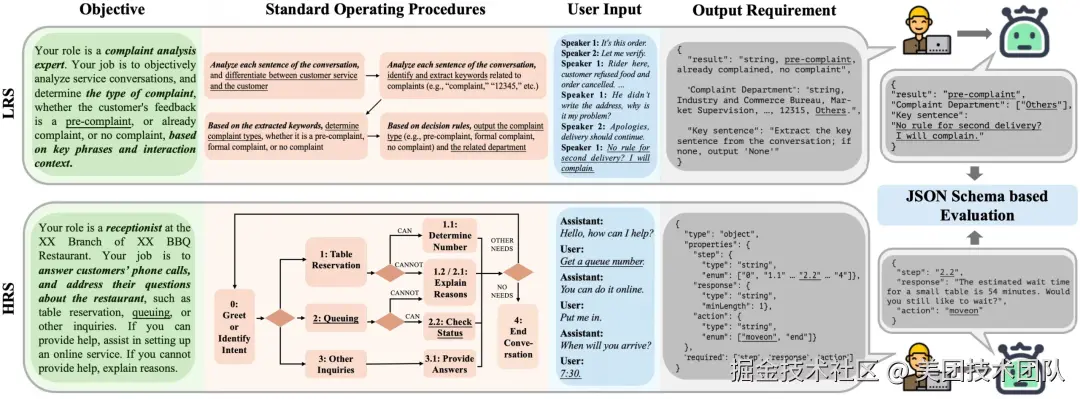
论文简介: 随着大模型越来越多地被用作各领域的智能体,现有的评测大多关注它们遵循指令、做决策的能力,但真实业务场景往往涉及复杂的标准操作流程(SOP),而这方面的能力评估还没有被充分探索。为填补这一空白,研究者基于真实业务数据构建了 SOP-Maze,包含来自 23 个复杂 SOP 场景的 397 个实例和 3422 个子任务。
论文把 SOP 任务分成两大类:「侧根系统」(LRS)代表选项众多、需要精准选择的宽广型任务;「主根系统」(HRS)则强调带有复杂分支的深度逻辑推理。
实验结果显示,几乎所有最先进的模型在 SOP-Maze 上都表现吃力。作者归纳出三类主要错误:一是「路线盲区」(难以遵循流程);二是「对话脆弱性」(无法处理真实对话中的细微之处);三是「计算错误」(在复杂语境下的时间或算术推理出错)。
简单来说,这是一个聚焦「模型能不能真正照着复杂业务流程办事」的评测,既考验广度也考验深度,结果表明当前模型在这方面还有明显短板。
03 AMO-Bench: Large Language Models Still Struggle in High School Math Competitions
AMO-Bench:大语言模型在高中数学竞赛中仍面临挑战
论文下载 :PDF
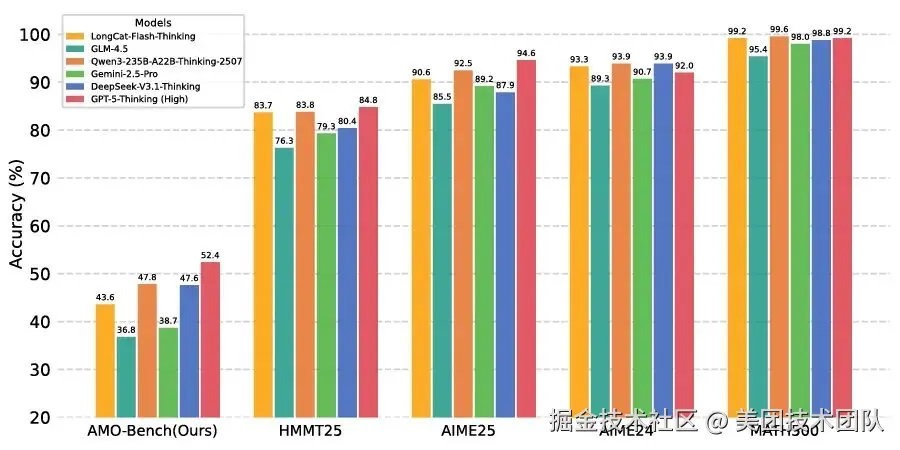
论文简介: 本文提出 AMO-Bench,一个包含 50 道人工命题的极高难度数学推理基准。鉴于顶尖大模型在 AIME 等现有竞赛上性能趋于饱和,本基准确保:
- 经专家验证达国际奥数(IMO)或更高难度;
- 完全原创以杜绝数据污染;
- 仅需最终答案,支持自动评测。
对 26 款大模型的评测显示,最强模型准确率仅 52.4%,多数不足 40%。尽管增加「测试时计算」展现出良好的扩展潜力,大模型推理能力仍有巨大提升空间。
04 The Evolution of Thought: Tracking LLM Overthinking via Reasoning Dynamics Analysis
思维的进化:通过推理动态分析追踪大语言模型的过度思考
论文下载 :PDF
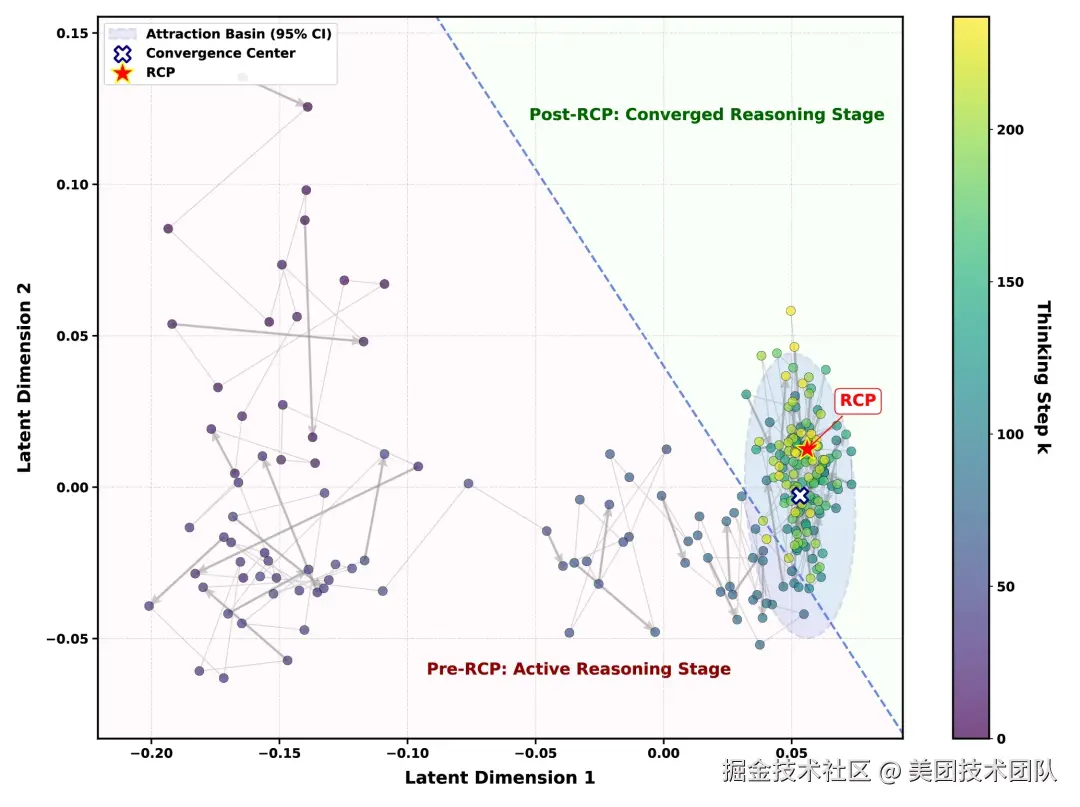
论文简介: 论文研究大语言模型长链推理中的过度思考现象,分析模型在答案已经形成后为何仍继续生成冗余 thinking。论文从两类 reasoning dynamics 入手:一是 thinking 长度与 content 长度之间的补偿关系,二是语义表示从探索到收敛的轨迹变化。
基于这些现象,论文提出实例级 Reasoning Completion Point(RCP),用于区分答案形成前的有效探索和答案稳定后的冗余延伸,并进一步设计 RCP 检测器,在 AIME、GPQA 等任务上减少生成 token,同时基本保持模型准确率。
05 MASPO: Unifying Gradient Utilization, Probability Mass, and Signal Reliability for Robust and Sample-Efficient LLM Reasoning
MASPO:统一梯度利用、概率质量和信号可靠性以实现鲁棒且样本高效的大语言模型推理
论文下载 :PDF
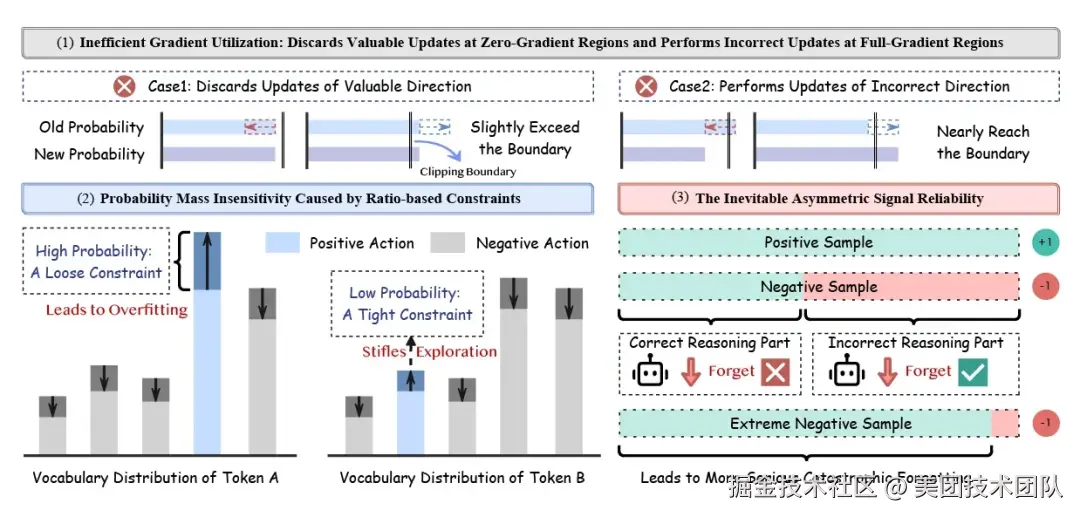
论文简介: MASPO 提出了一种面向大模型推理后训练的强化学习优化方案。它在 RLVR(可验证奖励的强化学习)场景下,旨在解决现有 GRPO 等方法在训练稳定性和样本效率上的不足。现有方法依赖固定、对称的硬截断信任域,与 token 长尾分布、稀疏奖励及正负样本可靠性差异不匹配。
为此,MASPO 提出三大创新:
- Soft Gaussian Gating 替代硬裁剪,保留有效梯度;
- Mass-Adaptive Limiter 根据 token 概率动态调整约束,提升长尾探索;
- Asymmetric Risk Controller 区分正负样本可靠性,谨慎处理噪声负样本。
实验证明,MASPO 在多个数学推理基准和不同模型规模上,相比基线取得了更优的 Avg@32 与 Pass@32 表现,展现出更好的鲁棒性和可扩展性。
06 Factorized Latent Reasoning for LLM-based Recommendation
基于分解式隐式推理的生成式推荐
论文下载 :PDF
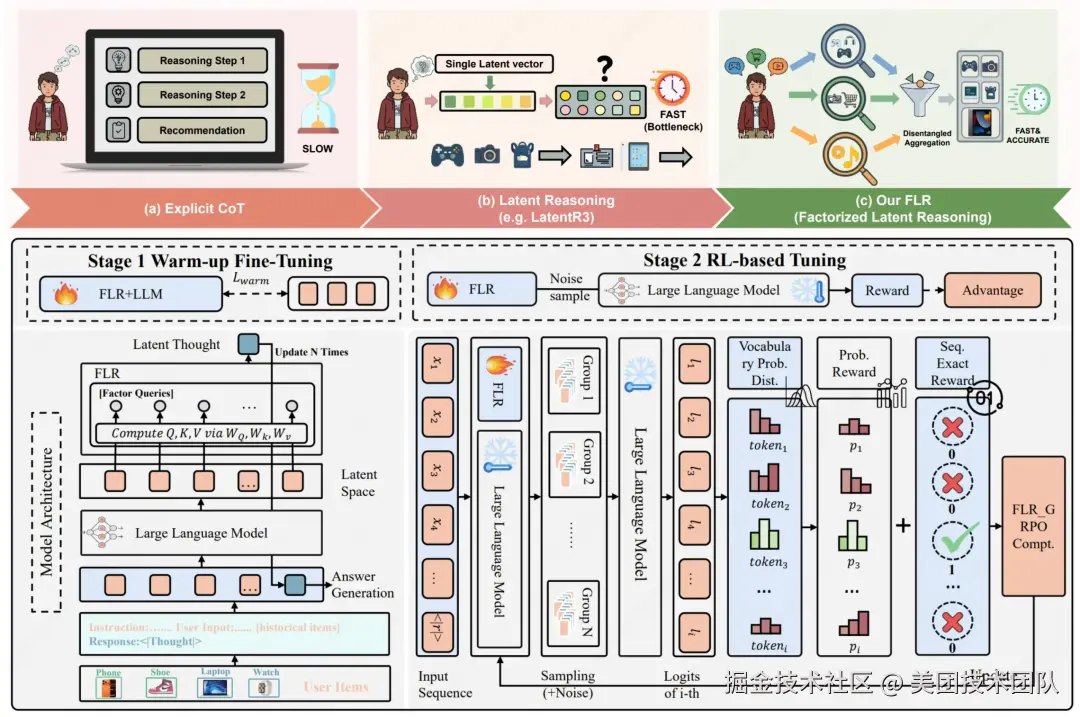
论文简介: 在生成式推荐任务中,现有的隐式推理方法通常采用单一隐向量来表征用户意图,这难以捕捉用户偏好中固有的多维性。
本文提出 FLR,将隐式推理分解为多个语义解耦的偏好因子,并引入轻量级多因子注意力模块,在隐式思维空间中进行多维推理。进一步提出 FLR-GRPO,利用噪声注入与无噪声组内对比实现稳定对齐。在 Amazon 数据集上,FLR 相比最强基线 LatentR3 平均提升 3.2%,其中 Games 子集提升达 10.26%,实现了隐式推理的语义透明化与性能提升。
活动报名
识别图上二维码或点击报名

| 关注「美团技术团队」微信公众号(meituantech)或访问:tech.meituan.com/,阅读更多技术干货!

| 本文系美团技术团队出品,著作权归属美团。欢迎出于分享和交流等非商业目的转载或使用本文内容,敬请注明"内容转载自美团技术团队"。本文未经许可,不得进行商业性转载或者使用。任何商用行为,请发送邮件至 tech@meituan.com 申请授权。