摘要
功能定义: EMR Serverless Spark 原生集成 标量-向量混合检索 能力,基于 DLF Global Index 实现单一 SQL 接口下的多维数据查询。
技术实现: 通过 vector_search UDF 结合标准 WHERE 子句,协同调用 Lumina 向量索引 与 B-tree 标量索引,实现算子下推与联合执行。
核心优势: SQL 原生语法零门槛接入,DLF 索引全自动托管免运维,Serverless 存算分离按需计费无闲置。内置Celeborn 集中式 Shuffle 管理与 Fusion引擎,相比开源Spark 3倍性能提升。
架构价值: 实现湖内原位检索(In-Lake Search),保障数据强一致性与低延迟。
典型场景: 适用于智能驾驶长尾场景挖掘、多模态电商搜索、RAG 知识库增强及大规模离线向量批处理任务。
在海量数据中找到"看起来像"且"符合条件"的那条记录,过去需要两套系统协作------向量数据库管语义相似,关系型数据库管结构化过滤,数据在两者之间反复搬运,链路长、成本高、一致性难保障。
阿里云 EMR Serverless Spark 现已支持 标量向量混合检索------基于 DLF Global Index 提供的向量索引能力,Spark SQL 原生支持标量过滤 + 向量近邻检索的混合查询,一条 SQL 即可完成"语义相似 + 条件约束"的双重检索。
一、什么是标量向量混合检索?为什么传统架构搞不定?
传统的数据检索面临一个两难:
-
纯标量查询(WHERE weather='暴雨' AND speed>80):精确,但找不到"语义相似"的场景
-
纯向量查询(Top-K 近邻):能找"看起来像"的,但无法约束业务条件
以自动驾驶场景为例,工程师常常需要这样的查询:
"从历史数据中,找到所有天气为暴雨、道路类型为城市道路 的、与当前场景最相似的 Top-10 个历史案例"
这种需求在传统架构下需要两步走:先从向量数据库取 Top-K,再在业务数据库中过滤------两次查询、数据搬运、结果可能不满足 K 条。
混合检索的意义:在向量近邻搜索的同时,增加标量过滤条件,一步到位,精确返回既相似又合规的结果。
二、阿里云 EMR Serverless Spark 如何实现标量向量混合检索?
阿里云 EMR Serverless Spark 基于数据湖内 DLF Paimon 表的 Global Index 能力,将向量索引和 B-tree 索引统一纳入 Spark SQL 的查询执行框架,实现了标量过滤与向量近邻检索的联合执行。
核心架构
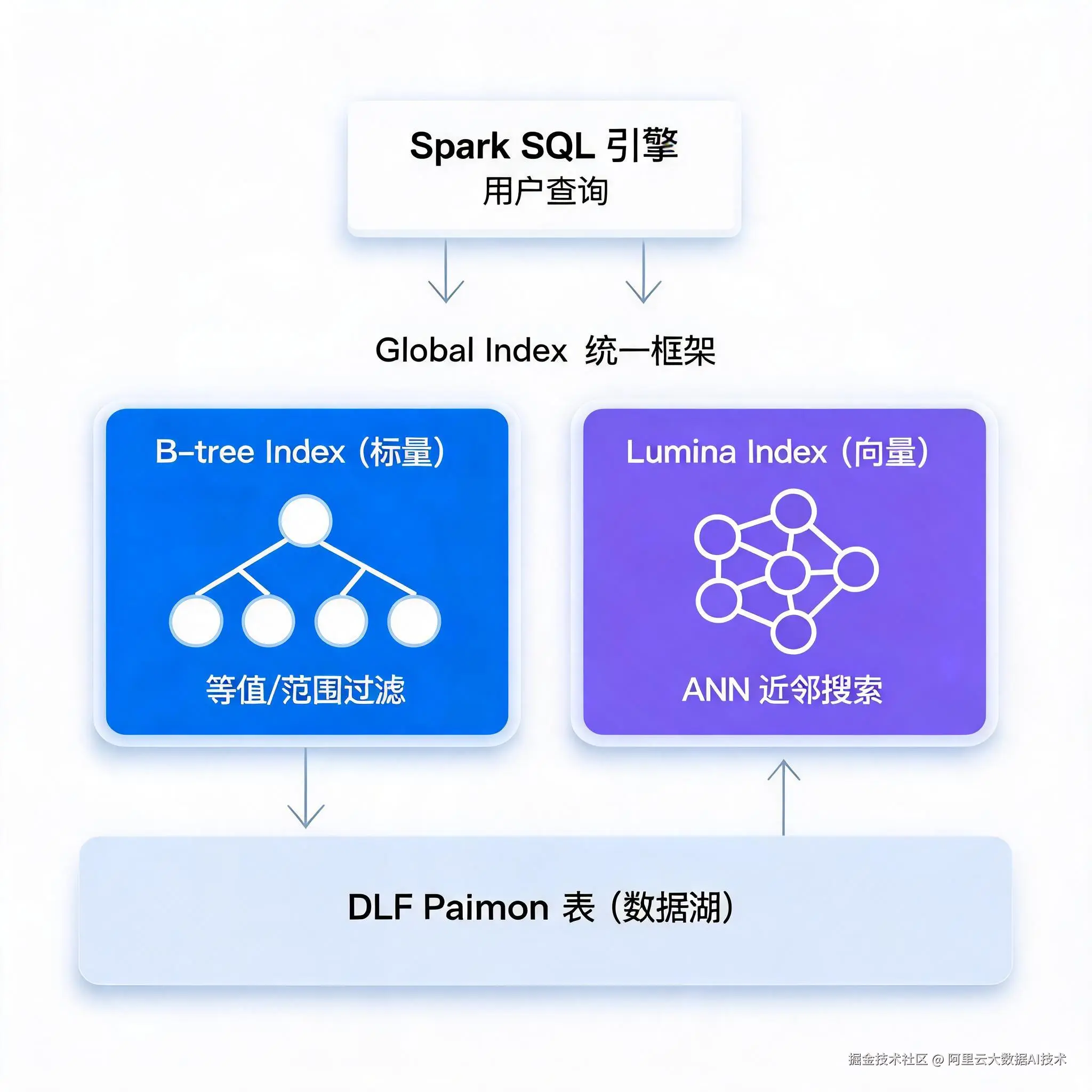 两种索引可以同时建立在同一张 Paimon 表上,Spark 在查询时自动协同两路索引,无需用户关心底层调度。
两种索引可以同时建立在同一张 Paimon 表上,Spark 在查询时自动协同两路索引,无需用户关心底层调度。
向量索引的构建
在 Paimon 表上开启向量索引,只需在建表时指定表属性,Spark 作业写入数据后索引自动生效:
sql
CREATE TABLE ai_dataset.scene_vectors (
id BIGINT,
path STRING,
weather STRING,
road_type STRING,
speed_range STRING,
embedding ARRAY<FLOAT>
) USING paimon
TBLPROPERTIES (
-- 启用 Global Index 基础能力
'row-tracking.enabled' = 'true',
'data-evolution.enabled' = 'true',
-- 开启向量索引
'morax.lumina-index.enabled' = 'true',
'global-index.lumina.index-column' = 'embedding',
-- 指定向量维度(须与实际 embedding 维度一致)
'lumina.index.dimension' = '1152'
);索引构建时机:
-
自动构建 :在 TBLPROPERTIES 中声明
morax.*相关参数,DLF 会根据表中的向量列自动调度构建索引。 -
手动触发 :如果写入数据后希望立即创建索引,或建表时未声明
morax.*相关参数,可以手动调用触发构建索引。
vector_search:Spark SQL 中的向量检索函数
Spark SQL 新增 vector_search 表函数,支持直接在 SQL 中进行向量近邻检索:
sql
-- 基础向量检索:找到与查询向量最相似的 Top-K 条记录
SELECT * FROM vector_search(
'ai_dataset.scene_vectors', -- 目标表
'embedding', -- 向量列
array(0.12F, 0.34F, ...), -- 查询向量
10 -- Top-K
);标量向量混合检索:一步到位
将 vector_search 的结果与标量 WHERE 条件结合,即可实现混合检索:
sql
-- 混合检索:天气=暴雨 AND 城市道路 的 Top-10 相似场景
SELECT id, path, weather, road_type, speed_range
FROM vector_search(
'ai_dataset.scene_vectors',
'embedding',
array(0.12F, 0.34F, ...), -- 当前场景的 embedding
10
)
WHERE weather = 'heavy_rain'
AND road_type = 'urban';执行逻辑:Spark 通过向量索引检索近邻候选集,同时通过 B-tree 索引对标量条件进行过滤,两路协同、一步完成,无需跨系统数据搬运。
三、实践:智能驾驶场景召回,为模型训练准备数据集
感知模型在恶劣天气下表现不佳,需要大量特定条件的场景数据来重新训练和微调模型。但路采数据中这类场景占比极低,人工逐帧筛选效率极差。
以下演示如何用阿里云 EMR Serverless Spark SQL 完成"场景数据入湖 → 混合检索召回 → 导出训练集"的完整流程。
Step 1:路采数据入湖,AI 自动生成标签和向量
路测车每天产生大量视频帧,存储在 OSS 上。通过阿里云 EMR Serverless Spark AI Function,一条 SQL 完成图片读取、标签提取和向量化:
sql
-- 创建场景表(含向量索引和 B-tree 索引)
CREATE TABLE IF NOT EXISTS ad_dataset.driving_scenes (
id BIGINT,
path STRING, -- OSS 图片路径
weather STRING, -- 天气:sunny/cloudy/rainy/snowy/foggy/other
lighting STRING, -- 光照:daytime/nighttime/dusk/tunnel/other
road_type STRING, -- 道路类型:urban/expressway/rural/...
objects ARRAY<STRING>, -- 检测到的目标类别
risks ARRAY<STRING>, -- 检测到的风险类别
scene_tag STRING, -- 场景标签(固定值)
sensor_type STRING, -- 传感器类型(固定值)
embedding ARRAY<FLOAT> -- 图片向量(1152 维)
) USING paimon
TBLPROPERTIES (
'row-tracking.enabled' = 'true',
'data-evolution.enabled' = 'true',
'morax.lumina-index.enabled' = 'true',
'global-index.lumina.index-column' = 'embedding',
'lumina.index.dimension' = '1152',
'global-index.btree.index-columns' = 'weather,road_type,lighting,objects,risks,scene_tag'
);
-- 批量入湖:读取 OSS 图片 → AI 生成标签 + 向量 → 写入 Paimon
WITH raw AS (
SELECT
monotonically_increasing_id() AS id,
path,
ai_query(
'You are an autonomous driving data analysis assistant. '
|| 'Based on the input road scene image, output a JSON object with the following structure: '
|| '{"weather": "sunny/cloudy/rainy/snowy/foggy/other", '
|| '"lighting": "daytime/nighttime/dusk/tunnel/other", '
|| '"road_type": "urban/expressway/rural/intersection/ramp/parking_lot/other", '
|| '"objects": ["car", "pedestrian", "bicycle", "motorcycle", "bus", "truck", '
|| '"traffic_light", "traffic_sign", "cone", "construction_equipment"], '
|| '"risks": ["construction", "congestion", "occlusion", "accident_signs", '
|| '"wrong_way", "illegal_parking", "water_logging", "ice", "other"]}. '
|| 'All field values must exactly match the enum options above (case-sensitive). '
|| 'objects and risks must be arrays of strings; use empty array [] if none. '
|| 'Do not output any extra text, explanation, Markdown, or code block. '
|| 'Output only valid JSON.',
data => content
) AS scene_json,
ai_embedding_multimodal(content) AS embedding
FROM read_files(
'oss://ad-team-raw/camera_front/2025-*/',
suffix => 'jpg,png'
)
)
INSERT INTO ad_dataset.driving_scenes
SELECT
id,
path,
get_json_object(scene_json, '$.weather') AS weather,
get_json_object(scene_json, '$.lighting') AS lighting,
get_json_object(scene_json, '$.road_type') AS road_type,
from_json(get_json_object(scene_json, '$.objects'), 'ARRAY<STRING>') AS objects,
from_json(get_json_object(scene_json, '$.risks'), 'ARRAY<STRING>') AS risks,
'normal' AS scene_tag,
'camera_front' AS sensor_type,
embedding
FROM raw;一条 INSERT 完成三件事:读取 OSS 图片 → AI 函数自动打标 + 生成向量 → 写入带双索引的 Paimon 表,后续查询即可利用向量索引和 B-tree 索引加速。
Step 2:混合检索召回目标场景
感知模型在"暴雨+城市道路"场景下误判率高,需要从历史库中召回相似场景用于模型重训练:
python
##以某次典型误判场景的 embedding 为查询向量
query_vec = spark.sql("""
SELECT embedding
FROM ad_dataset.driving_scenes
WHERE path = 'oss://ad-team-raw/camera_front/2025-10-15/frame_CF_003812.jpg'
""").collect()[0]["embedding"]
vec_literal = "array(" + ",".join(f"{v}f" for v in query_vec) + ")"
#召回"暴雨+城市道路"下与典型误判场景最相似的历史案例
result = spark.sql(f"""
SELECT id, path, weather, road_type, lighting, objects, risks
FROM vector_search(
'ad_dataset.driving_scenes',
'embedding',
{vec_literal},
500
)
WHERE weather = 'rainy'
AND road_type = 'urban'
AND lighting = 'nighttime'
""")
result.show(truncate=False)混合检索的优势:向量检索先从海量数据中找到语义相似的场景,B-tree 索引再精准过滤天气、道路、时段等条件。两路协同,一步到位------传统方案需要先从向量库取候选、再在业务库中二次筛选,且无法保证结果数量。
Step 3:批量召回多种 Corner Case,构建训练集
模型训练不止需要一种场景。用 Spark SQL 的批处理能力,一次作业批量召回多种恶劣场景,直接写入训练数据集:
python
from functools import reduce
from pyspark.sql import DataFrame
# 批量召回多种恶劣场景,
SCENES = [
(
"oss://ad-team-raw/camera_front/2025-10-15/frame_CF_003812.jpg",
{"weather": "rainy", "road_type": "urban"},
500,
"rainy_urban",
),
(
"oss://ad-team-raw/camera_front/2025-11-02/frame_CF_001547.jpg",
{"weather": "foggy", "road_type": "expressway"},
500,
"foggy_expressway",
),
(
"oss://ad-team-raw/camera_front/2025-12-08/frame_CF_000923.jpg",
{"weather": "snowy", "road_type": "rural", "lighting": "nighttime"},
300,
"snowy_rural_nighttime",
),
]
def recall_scene(anchor_path: str, filters: dict, top_k: int, source_label: str) -> DataFrame:
vec = spark.sql(f"""
SELECT embedding FROM ad_dataset.driving_scenes
WHERE path = '{anchor_path}'
""").collect()[0]["embedding"]
vec_literal = "array(" + ",".join(f"{v}f" for v in query_vec) + ")"
where_clause = " AND ".join(f"{col} = '{val}'" for col, val in filters.items())
# 执行向量召回并附加场景标签
return spark.sql(f"""
SELECT
id, path, weather, lighting, road_type,
objects, risks, scene_tag, sensor_type,
'{source_label}' AS source_query
FROM vector_search(
'ad_dataset.driving_scenes',
'embedding',
{vec_literal},
{top_k}
)
WHERE {where_clause}
""")
# 逐场景召回并合并结果
frames = [recall_scene(*scene) for scene in SCENES]
result = reduce(DataFrame.unionByName, frames)
# 将结果写入训练集
spark.sql("""
CREATE TABLE IF NOT EXISTS ad_dataset.training_set_corner_cases (
id BIGINT,
path STRING,
weather STRING,
lighting STRING,
road_type STRING,
objects ARRAY<STRING>,
risks ARRAY<STRING>,
scene_tag STRING,
sensor_type STRING,
source_query STRING
) USING paimon
""")
result.writeTo("ad_dataset.training_set_corner_cases").append()
print(f"Total records written: {result.count()}")关键价值 :一条 SQL 同时完成多种场景的召回 + 合并,source_query 字段标注了每条样本的来源召回条件,便于训练时按场景加权采样。
Step 4:训练集质量分析与去重
召回后需要分析训练集分布、去除重复样本------这些都可以在 Spark SQL 中直接完成:
sql
-- 分析各场景的召回数量分布
SELECT source_query, COUNT(*) AS sample_count
FROM ad_dataset.training_set_corner_cases
GROUP BY source_query
ORDER BY sample_count ASC;
-- 与维度表 JOIN,统计不同城市的覆盖情况
SELECT
t.source_query,
r.city,
COUNT(*) AS sample_count
FROM ad_dataset.training_set_corner_cases t
JOIN dim_road_info r ON t.path = r.image_path
GROUP BY t.source_query, r.city
HAVING COUNT(*) > 5
ORDER BY t.source_query, sample_count DESC;四、适用业务场景

1. 智能驾驶:Corner Case 挖掘与数据闭环
自动驾驶算法迭代的核心痛点是长尾场景(Corner Case)难以高效挖掘。传统方案依赖人工标注和逐帧打标,效率低、成本高。
Spark 混合检索方案:
-
向量维度:通过
ai_embedding_multimodal生成视觉 Embedding,语义匹配相似驾驶场景 -
标量维度:
ai_query自动提取天气、道路类型等标签,按车速区间、传感器类型等条件过滤 -
价值:一条 Spark SQL 从海量路采数据中定位"暴雨+夜间+城市道路"的相似场景,数据闭环效率提升数倍
2. 具身智能:机器人技能与经验检索
机器人面对新任务时,需从历史经验库中检索最相关的操作策略。
Spark 混合检索方案:
-
向量维度:任务描述的语义匹配("抓取红色杯子" → 匹配相似抓取策略)
-
标量维度:机器人型号、末端执行器类型、场景环境(室内/室外)等约束
-
价值:一次查询同时满足"语义相关"和"物理约束",确保检索结果可直接执行
3. 电商:多模态商品搜索与推荐
用户上传图片搜索商品时,需要同时考虑视觉相似性和业务规则。
Spark 混合检索方案:
-
向量维度:商品图片 Embedding 的视觉相似度
-
标量维度:价格区间、品牌、库存状态、上架时间等业务条件
-
价值:搜出的商品既"长得像"又"买得到",转化率显著提升
4. 内容安全:违规内容相似检索与拦截
发现一条违规内容后,需快速定位历史库中的相似内容。
Spark 混合检索方案:
-
向量维度:文本/图片 Embedding 的语义相似度
-
标量维度:内容类型、违规等级、处理状态、时间范围等
-
价值:一条 SQL 同时完成"找相似"和"按条件筛选",无需跨系统操作
5. 医疗影像:相似病例检索与辅助诊断
医生需从历史影像库中检索相似病例,同时考虑患者特征。
Spark 混合检索方案:
-
向量维度:医学影像 Embedding 的视觉相似度
-
标量维度:检查部位、患者年龄段、诊断类别等临床条件
-
价值:检索结果既有影像学相似性,又符合临床诊断约束
五、阿里云 EMR Serverless Spark 混合检索的核心优势
1. 数据零搬迁:检索就在数据湖内完成
向量数据与标量数据存储在同一张 Paimon 表中,Spark 直接在湖内执行混合检索,无需向外部系统同步。数据不出湖,既避免了同步链路的运维成本和数据一致性风险,也消除了跨系统数据搬运带来的延迟和带宽开销。
2. SQL 全表达力:检索只是起点,分析才是归宿
vector_search 返回的是标准 Spark DataFrame,可以直接与数仓中的其他表 JOIN、做窗口函数计算、聚合统计、子查询嵌套。一条 SQL 里,混合检索和后处理分析一气呵成------这是独立向量检索系统无法实现的能力。
3. 批处理原生:亿级数据的离线混合检索
Spark 天然擅长大规模离线批处理,从亿级数据中批量生成 Embedding、批量相似度计算、批量场景去重,在数据湖内一气呵成。无需引入额外计算引擎,一套 Spark 作业即可覆盖"数据入湖 → 向量生成 → 索引构建 → 批量检索"全流程。
4. AI Function 内置:向量生成与检索一条 SQL 搞定
ai_embedding_multimodal 负责生成向量,ai_query 负责提取标量标签,vector_search 负责混合检索------三个函数全部在 Spark SQL 内完成,从数据入湖到检索分析无需离开 SQL 环境,对数据工程师零门槛。
5. 存算分离 + 索引托管:零运维,按需计费
索引由 DLF 自动构建和更新,存储在 OSS 上,Spark 计算资源按作业实际使用量弹性伸缩。无任务时不产生计算费用,无需为索引集群预留固定资源,数据工程师只需关注 SQL 逻辑,索引运维完全透明。
六、总结
阿里云 EMR Serverless Spark 的标量向量混合检索能力,为数据湖带来了三个关键价值:
-
架构简化:无需额外部署向量数据库,Spark SQL 原生支持混合检索,数据不出湖、零搬运
-
SQL 原生 :
vector_search+ AI Function + 标准 WHERE 子句,数据工程师无需学习新接口 -
批处理原生:Spark 天然擅长大规模离线批处理,从亿级数据中批量生成 Embedding、批量相似度计算、批量场景去重,一气呵成
当数据湖有了"理解力",检索不再只是"精确匹配",而是"理解意图 + 满足条件"的智能查找。
常见问题 (FAQ)
Q1: EMR Serverless Spark 的混合检索性能如何?
A: 得益于 DLF Global Index 的存算分离架构,索引存储在 OSS 上,查询时按需加载。对于亿级数据,混合检索通常在秒级完成,且随着数据量增加,相比全表扫描有数量级的性能提升。
Q2: 支持哪些向量距离度量方式?
A: 目前支持 Cosine (余弦相似度)、Euclidean (欧氏距离) 等主流度量方式,可在建表属性 lumina.index.metric-type 中指定。
Q3: 索引构建会影响数据写入性能吗?
A: 不会。索引构建由 DLF 后台异步触发,与 Spark 写入作业解耦。写入完成后,DLF 会自动调度资源构建索引,对用户透明。