目录
- 前言
- 一、记忆的本质:构建上下文
- 二、长短期记忆类型对比
- 三、短期记忆:对话历史的直接传递
-
- [3.1 什么是短期记忆](#3.1 什么是短期记忆)
- [3.2 短期记忆的生命周期管理](#3.2 短期记忆的生命周期管理)
- [3.2 短期记忆的挑战:上下文窗口限制](#3.2 短期记忆的挑战:上下文窗口限制)
-
- 常见管理策略
-
- [策略一:滑动窗口(Sliding Window)](#策略一:滑动窗口(Sliding Window))
- [策略二:对话摘要(Conversation Summary)](#策略二:对话摘要(Conversation Summary))
- 四、长期记忆------智能体的知识库与经验库
-
- [4.1 长期记忆的定义与定位](#4.1 长期记忆的定义与定位)
- [4.2 长期记忆的分类体系](#4.2 长期记忆的分类体系)
-
- [4.2.1 情景记忆](#4.2.1 情景记忆)
- [4.2.2 语义记忆](#4.2.2 语义记忆)
- [4.2.3 程序记忆](#4.2.3 程序记忆)
- [4.2.4 记忆类型对比](#4.2.4 记忆类型对比)
- [4.3 长期记忆的生命周期](#4.3 长期记忆的生命周期)
-
- [4.3.1 记忆生成和存储](#4.3.1 记忆生成和存储)
- [4.3.2 记忆检索与触发](#4.3.2 记忆检索与触发)
- [4.3.4 记忆注入](#4.3.4 记忆注入)
- [4.3.5 记忆修剪](#4.3.5 记忆修剪)
- 五、智能体记忆的整体架构
- 六、总结
前言
智能体记忆是指 AI 系统存储、检索和利用历史信息的能力。一个具备记忆能力的智能体,能够在多轮对话中保持连贯性,记住用户的偏好和习惯,积累经验并持续改进。
这篇博客主要将深入总结短期记忆和长期记忆的机制、架构设计,以及如何构建一个带记忆功能的智能体系统。
一、记忆的本质:构建上下文
在讨论记忆之前,首先要理解一个核心概念:记忆的本质是为 LLM 构建上下文(Context)。
LLM 本身是无状态的,每一次调用都是独立的。所谓的"记忆",实际上是在每次调用时,将相关信息注入到 Prompt 中,让模型能够"看到"历史信息。理解了这一点,就能理解记忆系统的核心任务:
- 存储信息:将历史对话、用户偏好、知识等保存下来
- 检索信息:根据当前查询,找到最相关的历史信息
- 构建上下文:将检索到的信息,以合适的方式组装到 Prompt 中
不同的记忆类型,本质上是不同的上下文构建策略。
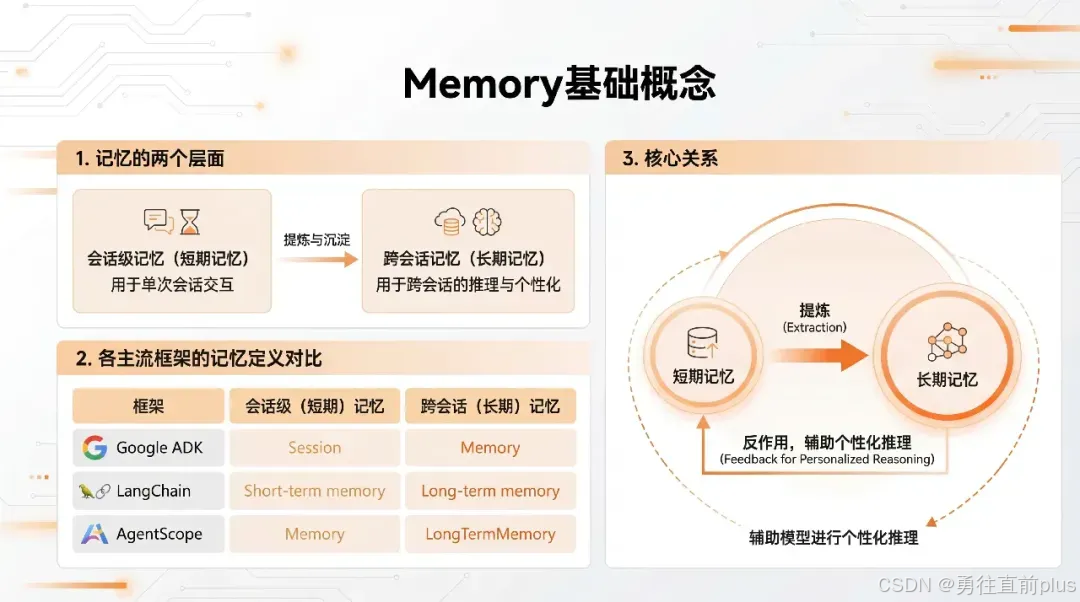
二、长短期记忆类型对比
短期记忆和长期记忆在多个维度上存在显著差异,核心差异是作用范围,而不是存储介质,短期记忆为了保证会话的后续连贯性,也会存储在redis/关系型数据库中。
| 维度 | 短期记忆 | 长期记忆 |
|---|---|---|
| 作用范围 | 当前会话内 | 跨会话持久化 |
| 数据存储 | 内存中的消息列表/redis/数据库 | 数据库/向量数据库 |
| 检索方式 | 直接传递历史消息 | 向量相似度搜索 |
| 容量限制 | 受上下文窗口限制 | 理论上无限 |
| 信息密度 | 完整对话细节 | 压缩后的关键信息 |
| 典型场景 | 多轮对话、任务执行 | 用户偏好、知识库 |
三、短期记忆:对话历史的直接传递
3.1 什么是短期记忆
短期记忆是指在当前会话内保持对话连贯性的机制。它的核心是直接传递对话历史,让模型能够看到之前说了什么。
短期记忆本质上就是维护一个 Message 列表,每次调用 LLM 时,将这个列表作为上下文传入。这个 Message 列表通常包含:
- 系统提示词(System Prompt)
- 历史对话(User 和 Assistant 的消息交替)
- 当前用户输入
一个典型的 Message 列表结构如下:
python
[
{"role": "system", "content": "你是一个有帮助的助手。"},
{"role": "user", "content": "介绍一下自己"},
{"role": "assistant", "content": "你好!我是..."},
{"role": "user", "content": "你刚才说了什么?"} // 模型能看到之前的回复
]3.2 短期记忆的生命周期管理
短期记忆的声明周期管理涉及两个关键时机:何时加载、注入,何时存储。
加载时机:
| 场景 | 加载策略 | 说明 |
|---|---|---|
| 新会话开始 | 初始化空消息列表 | 仅包含系统提示词 |
| 对话进行中 | 从内存中读取 | 保持会话状态连续性 |
| 会话恢复(开启新对话) | 从缓存/持久化存储恢复 | 用户在当前会话继续追问、或重新打开历史会话 |
注入方式:
短期记忆的注入非常直接------它就是 Message 列表本身。每次调用 LLM 时,将历史消息数组直接传入 API 即可。这也是为什么短期记忆也被称为"对话历史缓冲区"。
一个典型的注入流程示例:
python
def inject_short_term_memory(
system_prompt: str,
conversation_history: list[dict],
user_input: str
) -> list[dict]:
"""组装完整的消息列表"""
messages = [{"role": "system", "content": system_prompt}]
# 注入历史对话(短期记忆)
messages.extend(conversation_history)
# 添加当前用户输入
messages.append({"role": "user", "content": user_input})
return messages何时存储和更新:
- 对话进行中,直接将对话迭代历史存储在应用内存中
- 本次对话结束,将当前对话历史(会话历史) 处理(上下文管理策略)后更新到 会话的redis缓存或者数据库中,用于会话恢复和审计
| 存储位置 | 适用场景 | 优缺点 |
|---|---|---|
| 应用内存 | 单次运行、简单场景 | 速度快,但进程结束后丢失 |
| Redis/缓存 | 需要会话恢复 | 可跨进程访问,需管理过期 |
| 数据库 | 需要会话恢复,历史会话审计 | 持久化,但查询性能较低 |
3.2 短期记忆的挑战:上下文窗口限制
短期记忆面临的最大挑战是上下文窗口的长度限制。模型能处理的 Token 数量是有限的,如果对话历史无限增长,最终会超出限制。这就需要记忆管理策略。
常见管理策略
策略一:滑动窗口(Sliding Window)
最简单直接的方法,只保留最近 N 轮对话。比如限制最多保留最近 10 轮对话,超过的部分直接丢弃。这种方式实现简单,但会丢失早期对话信息。
优点 :实现简单,内存占用可控
缺点:丢失早期对话信息,可能丢失重要上下文
python
def apply_sliding_window(
messages: list[dict],
window_size: int = 10
) -> list[dict]:
"""滑动窗口策略:保留最近 N 轮对话"""
system_message = messages[0] # 保留系统提示词
conversation = messages[1:] # 获取对话部分
# 保留最近 window_size 轮对话
if len(conversation) > window_size * 2:
conversation = conversation[-(window_size * 2):]
return [system_message] + conversation策略二:对话摘要(Conversation Summary)
当对话历史接近长度限制时,将早期的对话压缩成一段摘要。比如将前 20 轮对话总结成 200 字的摘要,保留在 Message 列表的开头。这样既节省了空间,又保留了关键信息。
python
def summarize_conversation(
messages: list[dict],
llm_client,
keep_recent: int = 4
) -> list[dict]:
"""对话摘要策略:压缩早期对话"""
system_message = messages[0]
conversation = messages[1:]
if len(conversation) <= keep_recent * 2:
return messages
# 分离早期对话和近期对话
early_conversation = conversation[:-keep_recent * 2]
recent_conversation = conversation[-keep_recent * 2:]
# 调用 LLM 生成摘要
summary_prompt = f"请总结以下对话的关键信息:\n{early_conversation}"
summary = llm_client.chat(summary_prompt)
# 用摘要替换早期对话
return [
system_message,
{"role": "system", "content": f"[历史摘要] {summary}"},
*recent_conversation
]实际应用中,通常会采用混合策略:保留最近几轮完整对话,同时维护一个早期对话的摘要。这样既能精确处理当前上下文,又能追溯历史话题。
四、长期记忆------智能体的知识库与经验库
长期记忆与短期记忆形成双向交互:一方面,长期记忆从短期记忆中提取"事实"、"偏好"、"经验"等有效信息进行存储(Record);另一方面,长期记忆中的信息会被检索并注入到短期记忆中,辅助模型进行个性化推理(Retrieve)。
4.1 长期记忆的定义与定位
长期记忆是指智能体能够跨会话持久化存储并在未来对话中按需检索的信息机制。它解决了短期记忆"会话结束即遗忘"的根本局限,使智能体具备:
- 身份连续性: 记住用户画像、偏好、历史交互
- 知识累积性: 从过往对话中学习和沉淀
- 任务延续性: 追踪和推进长期任务状态
与短期记忆(工作记忆窗口内的上下文传递)不同,长期记忆的核心是语义检索------根据当前意图的相关性,从海量历史信息中精准召回最有价值的记忆片段。
4.2 长期记忆的分类体系
借鉴认知心理学,长期记忆按内容性质分为三大类:
4.2.1 情景记忆
记录特定时空下的具体事件和经历:
- 一次问题解决的完整过程
- 某次对话中的关键决策或结论
示例 : "用户在2024年3月15日咨询了React性能优化方案,最终采用了虚拟滚动技术"
存储特点: 强时序性、强上下文关联、包含"何时何地何人何事"四要素
4.2.2 语义记忆
存储抽象的事实、知识和概念:
- 用户画像信息(职业、技术栈、偏好)
- 项目背景知识(架构、技术选型)
- 领域知识图谱(概念间的关联)
示例 : "用户是Python开发者,偏好使用FastAPI框架,正在构建微服务架构"
存储特点: 弱时序性、可抽象提炼、支持知识推理和关联
4.2.3 程序记忆
保存技能、流程和操作模式:
- 用户常用的工作流程
- 标准化的任务处理步骤
- 个性化的交互习惯
示例 : "用户习惯先讨论方案再实现代码,偏好分模块渐进式开发"
存储特点: 过程性、可复用、可通过Few-shot示例激活
4.2.4 记忆类型对比
| 记忆类型 | 存储内容 | 时序依赖 | 检索触发 | 典型应用 |
|---|---|---|---|---|
| 情景记忆 | 具体事件 | 强 | 时间/事件相似 | "上次那个问题怎么解决的?" |
| 语义记忆 | 事实知识 | 弱 | 语义相关性 | "我对什么技术栈熟悉?" |
| 程序记忆 | 流程技能 | 中 | 任务模式 | "按老规矩帮我review代码" |
4.3 长期记忆的生命周期
4.3.1 记忆生成和存储
存储架构选择:
不同类型的记忆适合不同的存储后端:
| 存储类型 | 适用记忆类型 | 优势 | 典型实现 |
|---|---|---|---|
| 向量数据库 | 情景记忆、语义记忆 | 高效语义检索 | Pinecone, Milvus, Weaviate, Chroma |
| 关系数据库 | 程序记忆、元数据 | 结构化查询、事务支持 | PostgreSQL, MySQL |
| 图数据库 | 语义记忆(知识图谱) | 关系推理、知识关联 | Neo4j, NebulaGraph |
| 文件存储 | 配置、程序记忆模板 | 简单直观、易于维护 | JSON/YAML文件 |
存储时机:
- 实时存储:每轮对话后立即评估并存储
- 批量存储:累积多轮对话或会话结束后统一处理
- 触发式存储:检测到显式信号时触发(如用户说"记住这个"、出现重要实体、强烈情感)
存储方式:
- 大模型总结:调用 LLM 提取关键信息,理解能力强但成本高
- 工具调用:大模型判断需要记忆时,主动调用记忆存储工具,灵活可控
- 程序自动检测:规则引擎、关键词匹配、实体识别,速度快成本低
4.3.2 记忆检索与触发
检索触发时机:
- 每次用户输入时自动触发
- 智能体需要上下文补充时主动触发
- 任务执行遇到知识缺口时按需触发
不同记忆类型的触发机制:
| 记忆类型 | 触发条件 | 检索方式 | 加载策略 |
|---|---|---|---|
| 情景记忆 | 时间词(上次、之前)、事件词(那个问题)、延续词(继续) | 向量相似度检索 | 召回Top-K,按时间衰减排序 |
| 语义记忆 | 语义相关性(始终尝试检索) | 向量检索+知识图谱关联 | 用户画像高权重,知识图谱补充 |
| 程序记忆 | 模式词(老规矩、惯例)、任务模式识别 | 关键词匹配+任务分类 | 匹配触发器,加载完整流程定义 |
代码示例:
python
class MemoryRetriever:
"""记忆检索器 - 根据不同类型触发不同的检索策略"""
def retrieve_episodic(self, query: str) -> List[tuple]:
"""情景记忆检索"""
# 检测触发词
triggers = ["上次", "之前", "昨天", "刚才", "那个", "继续"]
if not any(t in query for t in triggers):
return [] # 无触发词则不检索
# 向量相似度检索
query_embedding = self.embedder.embed(query)
results = self.vector_db.search(
query_embedding,
top_k=5,
filters={"type": "episodic"}
)
# 应用时间衰减
for memory, score in results:
days_old = (datetime.now() - memory.created_at).days
memory.decay_factor *= 0.95 ** days_old
score *= memory.decay_factor
return sorted(results, key=lambda x: x[1], reverse=True)
def retrieve_semantic(self, query: str, user_id: str) -> List[tuple]:
"""语义记忆检索"""
memories = []
# 1. 向量检索语义记忆
query_embedding = self.embedder.embed(query)
vector_results = self.vector_db.search(
query_embedding, top_k=5, filters={"type": "semantic"}
)
memories.extend(vector_results)
# 2. 知识图谱关联检索
entities = self.extract_entities(query)
for entity in entities:
knowledge = self.knowledge_graph.find_related(entity, max_depth=2)
memories.extend(knowledge)
# 3. 加载用户画像(文件存储)
profile = self.file_storage.load_user_profile(user_id)
if profile:
memories.append(("user_profile", profile, 0.95))
return memories
def retrieve_procedural(self, query: str) -> List[tuple]:
"""程序记忆检索"""
# 显式触发词
triggers = ["按老规矩", "像之前一样", "惯例", "标准流程"]
if any(t in query for t in triggers):
return self.relational_db.find_matching_procedure(query)
# 任务模式识别(隐式触发)
patterns = self.detect_task_pattern(query) # 如"code_review", "testing"
results = []
for pattern in patterns:
procedure = self.relational_db.find_matching_procedure(pattern)
if procedure:
results.append(procedure)
return results4.3.4 记忆注入
注入位置选择:
| 注入位置 | 适用记忆类型 | 优点 |
|---|---|---|
| 系统提示词追加 | 语义记忆(用户画像) | 权重最高,LLM必读 |
| 独立System消息 | 程序记忆、混合记忆 | 结构清晰,易于调试 |
| 伪历史对话插入 | 情景记忆 | 保持对话连贯性 |
| 用户消息前缀 | 任务相关记忆 | 与当前意图强关联 |
代码示例:
python
class MemoryInjector:
"""记忆注入器"""
def inject_memories(self,
messages: List[Dict],
retrieved_memories: Dict[str, List]) -> List[Dict]:
"""将检索到的记忆注入到消息列表"""
# 按优先级注入: 语义 > 程序 > 情景
priority_order = ["semantic", "procedural", "episodic"]
for memory_type in priority_order:
memories = retrieved_memories.get(memory_type, [])
if not memories:
continue
# 根据记忆类型选择注入位置
if memory_type == "semantic":
messages = self._inject_to_system_prompt(messages, memories)
elif memory_type == "procedural":
messages = self._inject_as_standalone_system(messages, memories)
else: # episodic
messages = self._inject_as_fake_history(messages, memories)
return messages
def _inject_to_system_prompt(self, messages, memories):
"""注入到系统提示词"""
memory_text = "【用户画像与知识】\n" + "\n".join([m.content for m, _ in memories])
for msg in messages:
if msg["role"] == "system":
msg["content"] += "\n\n" + memory_text
break
return messages
def _inject_as_fake_history(self, messages, memories):
"""伪装成历史对话插入"""
fake_messages = []
for mem, _ in memories:
fake_messages.append({"role": "user", "content": f"[历史记录] {mem.content[:200]}"})
fake_messages.append({"role": "assistant", "content": "[已记录]"})
# 插入到当前用户消息之前
insert_pos = len(messages) - 1
for fake_msg in reversed(fake_messages):
messages.insert(insert_pos, fake_msg)
return messages4.3.5 记忆修剪
| 遗忘策略 | 适用场景 | 实现逻辑 |
|---|---|---|
| 时间衰减 | 全类型记忆 | importance *= 0.95^(距上次访问天数),随时间自动降低记忆权重 |
| 访问频率淘汰 | 情景记忆 | 30 天未访问 + 累计访问次数≤1 → 直接删除记忆 |
| 显式删除 | 过时错误信息 | 用户手动删除 / 内容验证失效后主动清理 |
五、智能体记忆的整体架构
各 Agent 框架在集成记忆系统时,虽然实现细节不同,但都遵循相似的架构模式。理解这些通用模式有助于更好地设计和实现记忆系统。
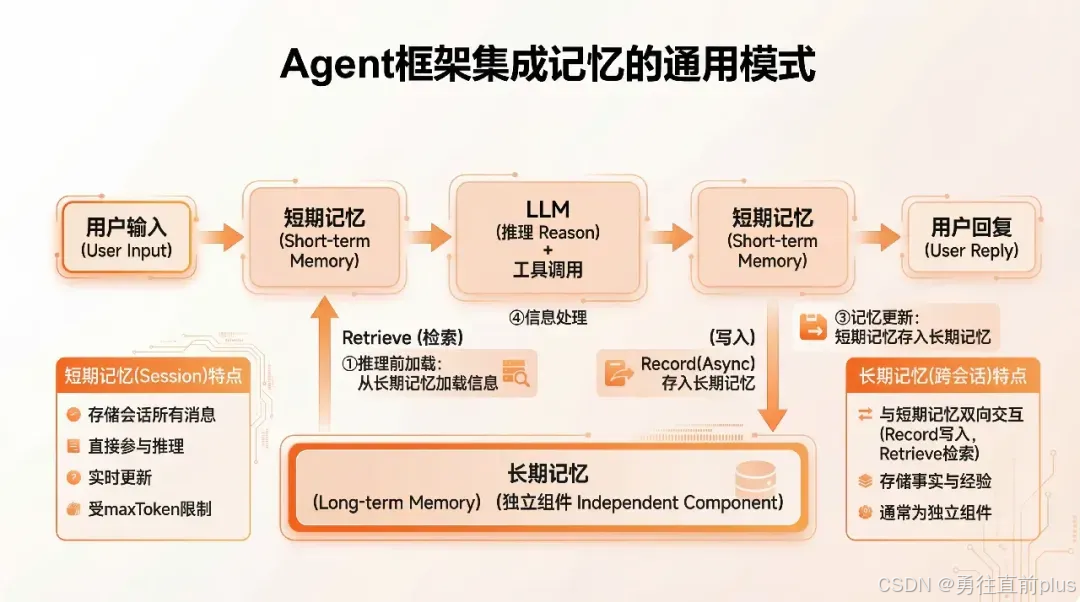
各 Agent 框架集成记忆系统通常遵循以下通用模式:
Step1:推理前加载
在模型对当前用户查询(user-query)进行推理之前,首先根据查询内容从长期记忆中检索相关信息。这一步通常利用向量相似度匹配(如基于嵌入向量的检索)或关键词匹配,找出与当前问题最相关的历史记忆片段。目的是为后续推理提供必要的背景知识,避免模型"遗忘"过去的关键交互或事实。
Step2:上下文注入
将从长期记忆中检索到的相关信息,注入到当前会话的短期记忆(即当前对话上下文或输入序列)中。让模型在回答问题时能够同时参考短期对话历史和长期知识,提升回答的连贯性与准确性。
Step3:记忆更新
在当前轮次的模型推理完成后,将当前短期记忆中的关键信息(包括用户问题、模型回答、中间推理结果等)经过筛选或压缩,加入长期记忆中。
更新策略可以包括:直接存储完整对话片段、提取关键事实后再存储、或根据重要性评分决定是否保留。这一步确保了长期记忆能够持续积累新的知识,实现"终身学习"效果。
Step4:信息处理
作为后台持续性优化环节,长期记忆模块联动LLM大模型+RAG相关组件,对全量长期记忆进行常态化智能处理与迭代优化。
一方面,通过向量化模型对新增记忆、存量记忆统一生成向量嵌入,支撑高效语义检索与相似度匹配;
另一方面,依托LLM的理解、归纳、判别能力,完成记忆的智能提取、摘要压缩、分类打标。
同时配套完整的记忆维护机制:通过时间衰减、访问频率规则实现智能遗忘,自动降低或清理过时、低频无效记忆;通过向量相似度匹配合并重复、冗余记忆;
六、总结
智能体记忆系统的设计需要理解几个核心要点:
-
记忆的本质是上下文构建:短期记忆和长期记忆最终都是为了构建合适的 Message 列表传入 LLM。
-
短期记忆是 Message 列表的直接管理:核心挑战是在上下文窗口限制下保留最有价值的历史对话。
-
长期记忆是语义检索系统:核心是向量数据库和 Embedding 技术,注入方式可以灵活选择(系统提示词、历史消息或独立上下文块)。
-
上下文组装器是关键枢纽:它决定了各种信息如何组织和呈现给 LLM,直接影响智能体的表现。
-
记忆管理需要智能策略:包括重要性评估、遗忘机制、隐私保护等。
一个设计良好的记忆系统,能够让智能体真正"记住"用户,提供个性化和连贯的服务体验。这也是智能体从"工具"走向"伙伴"的关键一步。