文献来源:
@article{dai2025hvlf,
title={HVLF: A Holistic Visual Localization Framework Across Diverse Scenes},
author={Dai, Kun and Jiang, Zhiqiang and Qiu, Fuyuan and Liu, Dedong and Xie, Tao and Wang, Ke and Li, Ruifeng and Zhao, Lijun},
journal={IEEE Transactions on Neural Networks and Learning Systems},
year={2025},
publisher={IEEE}
}
一、核心目标与难题
-
目标 :构建一个能够一次性学习多个不同场景的视觉定位框架,使机器仅凭普通RGB摄像头就能在各种室内环境中实时、准确地确定自身的位置和朝向。
-
待解难题 :指出当时先进的多场景方法(如OFVL-MS)存在两大局限:
-
网络结构僵化:其网络的每一层只能选择学习"所有场景的通用知识"或"单个场景的专属知识",限制了模型的表达和学习能力。
-
特征提取能力不足:网络结构较简单,未能充分融合图像的多层次信息,导致提取的特征区分度不够。
-
二、核心创新:两大关键技术
为解决上述问题,HVLF提出了两项关键技术:
-
软权重激活策略
-
做了什么 :打破了"二选一"的僵化模式,允许网络的每一层动态、按比例地同时激活"通用知识"和"专属知识"。
-
如何实现:在每一层引入一个可学习的"评分器",根据当前输入的场景和网络层,自动计算并融合两种知识的权重。
-
形象比喻:像一个能同时听懂"普通话"和"方言"的翻译,根据不同对话自动调整理解侧重,从而更精准地处理所有信息。
-
-
混合注意力感知模块
-
做了什么 :设计了一个强大的特征处理模块,能够从多个维度聚焦于图像的关键信息。
-
如何实现:该模块同时关注三个维度:
-
通道维度:判断哪些特征层面(颜色、纹理等)更重要。
-
空间维度:判断图像的哪些区域(如角落、物体边缘)更重要。
-
元素维度:综合以上,精确判断每个像素点的重要性。
-
-
形象比喻:为系统赋予"火眼金睛",能自动对焦到图像中最关键、最具判别性的物体和细节上,有效忽略干扰。
-
三、实验验证与效果
论文在多个公开数据集上验证了HVLF的有效性:
-
在室内数据集上表现出色 :在权威的7-Scenes等室内数据集上,HVLF的定位精度超过了包括基准方法OFVL-MS在内的多种先进技术。
-
在室外数据集上具备竞争力 :在更具挑战的Cambridge等室外数据集上,HVLF作为端到端的"学习型"方法,也展现了有竞争力的性能。
-
技术通用性强 :作者还将"软权重激活"和"混合注意力"模块应用于3D物体检测 和图像特征匹配这两个完全不同任务,均显著提升了性能,证明了这两项核心技术本身具有强大的通用性和推广价值。
四、总结
HVLF框架 通过**"灵活融合通用与专属知识"** 与**"多维度注意力强化特征"** 两大创新,实现了在多场景下高效、精准的视觉定位。它如同一个"一学多能、目光精准"的智能导航核心,为机器人在复杂多变环境中的自主感知与导航提供了更强大的解决方案。
I. 引言
视觉定位旨在预测摄像机的精确姿态,是大量计算机视觉应用的基石1、2。随着深度学习的迫切需要,卷积神经网络(CNN)被广泛应用于视觉定位任务3、4、5、6。其中,场景坐标回归(SCORE)技术5、6、7、8、9、10、11在小规模场景中表现出优异的性能。从技术上讲,评分方法详细说明了CNN直接回归场景坐标,然后是透视n点(PNP)算法或其变体7来生成6自由度相机姿势。然而,现有的评分方法5、6、7、9、10、11主要是将每个场景中的视觉定位视为一个单独的任务,并利用每个场景域来优化单个模型,从而无法开发跨不同场景的隐含通用属性。为了解决这一问题,OFVL-MS8(文献3.57)设计了一种联合训练框架,该框架可以同时执行跨不同场景域的视觉定位任务,实现了令人印象深刻的定位性能。OFVL-MS的实验结果表明,识别不同场景之间的隐含通用属性和每个场景的特定特征有助于预测准确的姿势。尽管OFVL-MS具有出色的性能,但它仍然具有固有的局限性。
1)刚体权重激活技术导致的特征表示不充分:如图1所示,OFVLMS8以卷积层为例,引入了定义场景共享权重和场景特定权值的刚体权重激活策略,每个权重的维度为RCout×Cin×K×K。该策略使网络能够自适应地确定是否应该独占地激活场景共享权重或场景特定权值的所有CoutCinK2参数来捕获场景通用或场景特定的属性。然而,这种技术不可避免地限制了网络的特征提取能力,因为识别场景通用属性和场景特定属性对于回归准确的场景坐标是必不可少的。因此,研究一种软权重激活策略(SWAS),在每一层同时激活场景共享权重和场景特定权重,从而增强网络的编码能力,是有意义的。
2)缺乏多层次特征融合导致的特征表示不充分:近年来,大量文献1、9、12证明,低层次的几何特征有利于区分相似图像块,而高层的语义特征有利于建模评分问题。此外,研究人员广泛研究了各种注意机制(例如,通道性注意13、14和空间性注意15),这些机制超越了不必要的信息,强调了关键特征以增强特征表征,从而显著提高了大量计算机视觉任务的性能9、13。因此,利用注意力机制结合多层次特征有利于优化特征,从而提高视觉定位精度。然而,OFVL-MS8构建了一个简单的网络范例,不可避免地限制了其特征表示能力,导致了较差的定位性能。
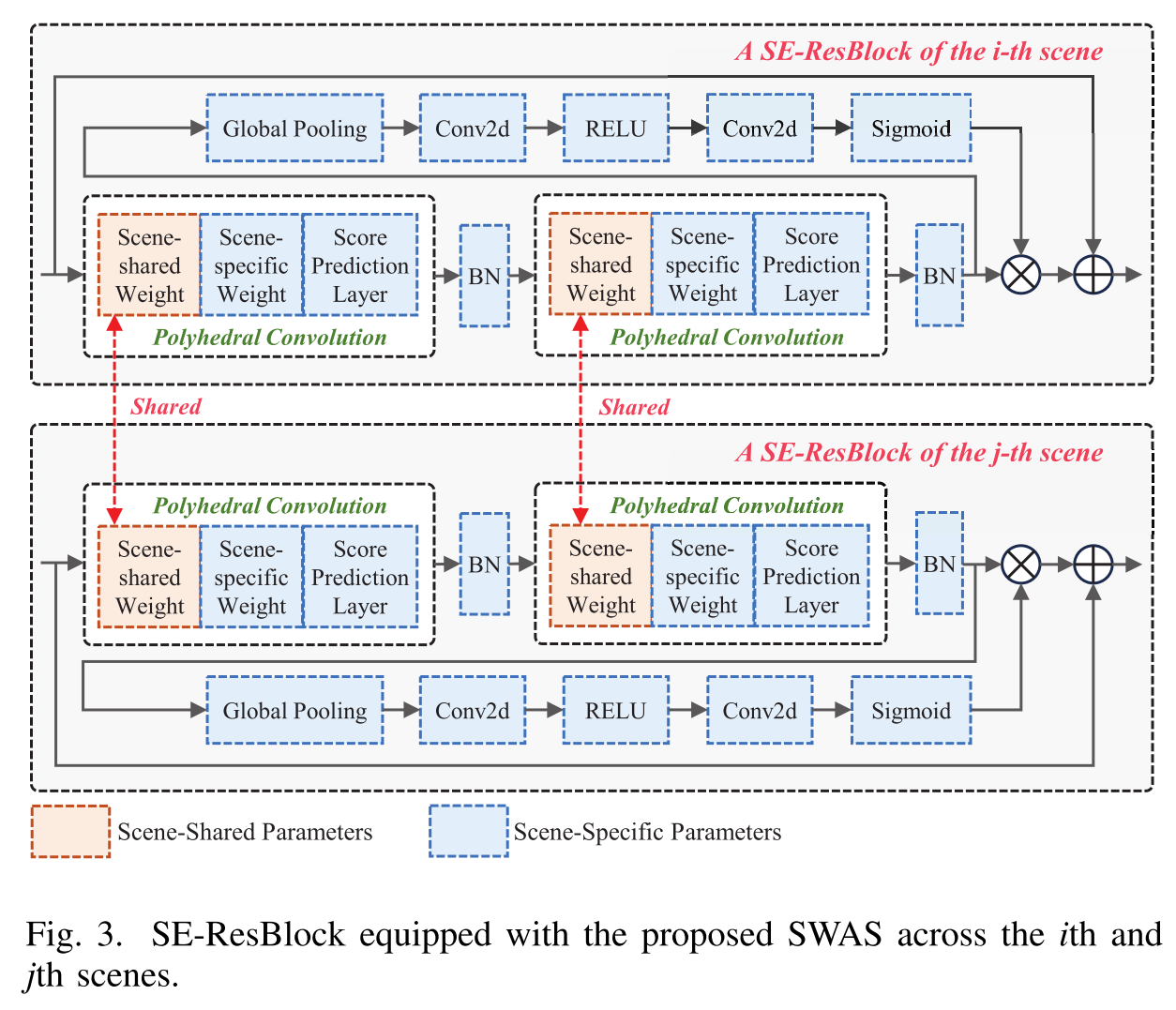
图1 OFVL-MS的刚体重量激活策略与HVLF的SWAS策略的比较。
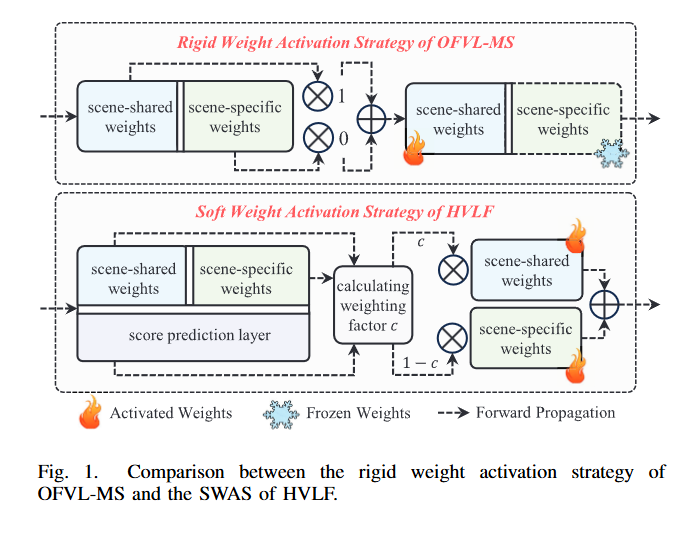
这张图(图1)非常直观地展示了您之前讨论的 HVLF框架的核心创新之一------"软权重激活策略" 与之前主流方法 **OFVL-MS的"刚性权重激活策略"** 之间的根本区别。
简单来说,这张图说明了神经网络在处理不同场景时,如何"调配知识"的两种截然不同的思维方式。
图解核心对比
我们可以将图中的"场景共享权重 "理解为神经网络中学到的通用知识 (比如"墙通常是平的"、"门有把手"),而"场景特定权重 "则是针对某个具体场景的独家记忆(比如"A会议室有一张红色的特定款式的桌子")。
上半部分:OFVL-MS的"刚性"策略
这是一种 "二选一"的开关模式。
-
工作原理 :对于每一个输入,网络在每一层都会通过一个"开关"(图中用0或1 的乘法表示)做出一个硬性决定 :要么完全使用通用知识 ,要么完全使用这个场景的独家记忆。
-
图标象征 :被选中的部分用火焰 图标表示"激活",未被选中的部分用雪花图标表示"冻结"。
-
主要问题:这种方式非常僵化。它假设对于处理某个场景,网络的每一层都只能有一种最佳模式,要么全用通用规则,要么全用具体记忆。这限制了网络灵活学习和表达的能力。
下半部分:HVLF的"柔性"策略
这是一种 "动态调配"的鸡尾酒模式。
-
工作原理 :HVLF增加了一个聪明的 "分数预测层" 。对于每一个输入,这一层会动态计算出一个介于0到1之间的权重因子c。
-
c表示当前输入下,"通用知识"的推荐比例。 -
1-c则表示"场景特定知识"的推荐比例。
-
-
融合过程 :网络不再做"二选一",而是将通用知识的输出乘以
c,将特定知识的输出乘以(1-c),然后将两者结果相加,得到最终的激活输出,送入下一层。 -
核心优势 :这种方式实现了平滑、自适应的融合。对于不同的输入(比如不同角度、光照的图片),网络可以在每一层动态决定"通用知识"和"专属知识"的最佳混合比例。这让网络能更精细、更灵活地处理多样化的场景。
核心差异总结
| 特性 | **OFVL-MS (刚性策略)** | **HVLF (软权重策略 - SWAS)** |
|---|---|---|
| 决策方式 | 硬性选择,非此即彼 | 软性混合,按需调配 |
| 控制信号 | 一个二元的"开关"(0或1) | 一个连续的"调音旋钮"(因子c) |
| 知识利用 | 每一层只能激活一种知识源 | 每一层可同时融合两种知识源 |
| 灵活性 | 低,策略固定 | 高,能根据输入自适应 |
| 类比 | 单选按钮 - 只能选A或B | 混合滑块 - 可以调出70%A + 30%B |
结论 :图1生动地揭示了HVLF性能更优的关键设计原因。通过将僵化的"知识开关"升级为智能的"知识调配器",HVLF的神经网络能够更细腻、更有效地利用从数据中学到的通用规律和特定记忆,从而在复杂的跨场景视觉定位任务中实现更精准、更鲁棒的表现。这正是其论文中强调的"灵活地同时学习通用和专属知识"的具体技术实现。
在这项工作中,我们引入了HVLF,这是一个整体框架,旨在同时实现跨不同场景的视觉定位。对于第一个问题,如图1所示,与仅激活场景共享或场景特定权重的OFVL-MS8不同,HVLF开发了一种SWAS,该SWAS同时优化用于提取场景通用特征和每层内场景特定属性的权重,从而增强网络的特征编码能力。具体地说,SWAS详细描述了具有场景共享权重、场景特定权重和分数预测层(SPL)的多面体卷积。每个多面体卷积计算场景共享权重和场景特定权重之间的差异,该差异由SPL处理以生成用于量化该层在捕获场景通用和场景特定特征方面的贡献的加权因子。基于加权因子,将两个权重合并在一起,以确保它们都参与前向传播和后向传播。SWAS建立在多面体卷积的基础上,将不同场景的视觉定位作为一个联合任务,在所有场景之间共享场景共享权重,并垄断每个场景的场景特定权重,从而实现全面的场景感知。
为了解决第二个问题,HVLF引入了混合注意感知模块(mixed attention perception module,MAPM),该模块利用通道、空间和元素的注意机制来提取区分特征,用于场景坐标的精确回归。具体地说,MAPM首先沿着通道维度串联多层特征,以确保低层几何信息和高层语义特征被集成在一起。在此之后,MAPM计算信道掩码和空间掩码,并进一步利用这些掩码来得到元素掩码。基于这些注意掩码,MAPM自主地识别每个通道、每个像素和每个元素的相对重要性,从而使自监督学习能够用于区分性特征提取。
总的来说,这项工作的主要贡献包括以下几个方面。
1)提出了一个完整的视觉定位框架--HVLF,它以多任务学习(MTL)的方式无缝地处理跨不同场景的视觉定位任务。大量实验表明,该算法在室内和室外的各种数据集上都达到了令人印象深刻的定位精度。
2)提出了一种SWAS算法,该算法通过多面体卷积来同时激活场景共享权重和场景特定权值,从而确保场景通用属性和场景特定属性的有效提取,从而获得准确的评分。
此外,我们对S3DIS16和SUN RGB-D17数据集上的3-D目标检测任务进行了优化实验,以表明SWAS的核心概念在不同任务中是通用的。
3)构建了一个MAPM,它结合了通道、空间和元素的注意机制来生成可区分的特征表征。在特征匹配任务上的实验证明了该模块的通用性。
2.相关工作
2.1 基于结构的方法
基于结构的方法18,19,20,21,22的目的是在2-D像素和3-D场景坐标之间建立匹配,然后用PNP算法恢复摄像机的姿态。
主流的基于结构的方法包括三个步骤,即图像检索、特征匹配和姿态估计。
在给定查询图像的情况下,这些方法首先利用图像检索算法23、24从数据库中捕获最相似的参考图像,从而限制了相机姿势的搜索空间。
随后,采用特征匹配算法4、25、26、27在查询图像和参考图像之间建立二维关键点匹配,并将其映射到三维空间以生成查询图像的二维像素-三维场景坐标对应。
最后,利用PNP算法计算摄像机姿态。
As a ground-breaking work, HLoc 19 introduces a conventional coarse-to-fine visual localization paradigm that utilizes NetVLAD 23 and SuperPoint 28 to realize coarse localization and fine localization, respectively.
作为一项开创性的工作,HLoc19引入了一种传统的从粗略到精细的视觉定位范例,该范例利用NetVLAD23和SuperPoint28分别实现粗略定位和精细定位。此外,利用知识蒸馏降低了NetVLAD和SuperPoint的计算代价,从而保证了HLoc的推理速度。之后,大量的基于结构的方法遵循了HLoc的框架,并异常地提高了定位性能。
近年来,一些技术22、29试图优化图像检索和特征匹配算法,以建立更准确和可靠的几何对应,从而提高定位精度。此外,一些研究人员20的目标是压缩场景地图,以便以更紧凑的形式存储它们,从而减少内存使用。
2.2 基于深度学习的方法
随着人工智能的发展,研究人员探索利用深度学习实现精确视觉定位的可行性。这些方法可分为绝对位姿估计(APE)3、30、31、相对位姿估计(RPE)32、33、Score5、6、7、8、9、10、11。APE方法3,30,31详细阐述了在RGB图像和摄像机姿态之间建立映射函数的CNN,从而以端到端的方式预测摄像机姿态。最近的研究34表明,APE方法本质上类似于通过图像检索直接生成相机姿势,因此在提高APE技术的准确性方面存在瓶颈。对于给定的查询图像,RPE方法32、33首先从数据库中检索最相似的参考图像,然后使用CNN来回归查询图像和参考图像之间的相对姿势。
与APE和RPE不同,SCORE方法5、6、7、8、9、10、11利用随机森林35或CNN预测对应于2-D像素的3-D场景坐标,然后用PNP算法回归摄像机姿势。广泛的研究1、10证明了评分方法在小范围场景中取得了优异的性能。此外,与基于结构的方法相比,评分技术也减少了存储消耗,因为它们不需要数据库。Shotton等人35创新性地提出了得分的概念,并利用随机森林对场景坐标进行预测。
之后,研究人员5、6、7、8、9、10、11研究用CNN取代随机森林,以生成更可靠的3D坐标。HSCNet10引入了一种分层网络体系结构,通过为每个点分配标签来减少相似图像块之间的干扰。SLD11预测每个预定义地标的热图以确定图像中存在哪些地标,从而建立2-D像素和3-D地标之间的对应关系。
考虑到主流评分方法需要几个小时的训练时间,ACE6利用大规模室内数据集ScanNet36将通用属性编码到主干中,只优化MLP来回归场景坐标,大大减少了训练时间。最近,一些研究人员探索了将MTL技术结合到评分方法中的可行性。
OFVL-MS8将每个场景中的定位视为一个单独的任务,并开发了LayerWise权重共享策略,以使网络能够自适应地判断应该在所有任务中共享哪些权重。
2.3 基于结构的技术和基于深度学习的方法的比较
总的来说,这两种方法各有长处和短处。由于图像检索23、24和特征匹配4、25、26、27算法对恶劣的环境条件都具有较强的鲁棒性,因此基于结构的方法18、19、20、21、22在具有大量动态目标和光照变化的室外场景中表现出出色的定位性能。
此外,在建立数据库后,基于结构的方法可以直接泛化到新的场景,而不需要重新训练图像检索和特征匹配算法。然而,在实际设备上部署基于结构的方法带来了巨大的挑战,因为它们需要大量的存储资源来存储包括查询图像、深度图像、六自由度姿势和描述符的数据库。
在基于深度学习的方法中,APE3、30、31和SCORE5、6、7、8、9、10、11技术直接使用神经网络预测六自由度姿态或三维场景坐标。与基于结构的方法相比,基于深度学习的方法更容易在实际设备上部署,因为它们只需要存储预先训练的权重,而不是大型数据库。然而,由于模型参数与特定场景的固定外观紧密相关,基于深度学习的方法在室外场景中难以实现准确的视觉定位。此外,这些方法在推广到新场景时需要重新训练。鉴于我们打算在室内服务机器人中部署该算法,我们将重点放在部署所需的硬件成本上。因此,我们在这项工作中探索了基于学习的方法。
3.提出的方法论
3.1 HVLF Architecture
作为一种评分技术,HVLF以RGB图像i作为输入,预测每个场景的3-D场景坐标,从而建立2-D像素-3-D坐标的对应关系。然后,HVLF使用PNP算法7来回归摄像机姿势。如图2所示,HVLF由一个纠缠的主干和K个单独的回归头组成。
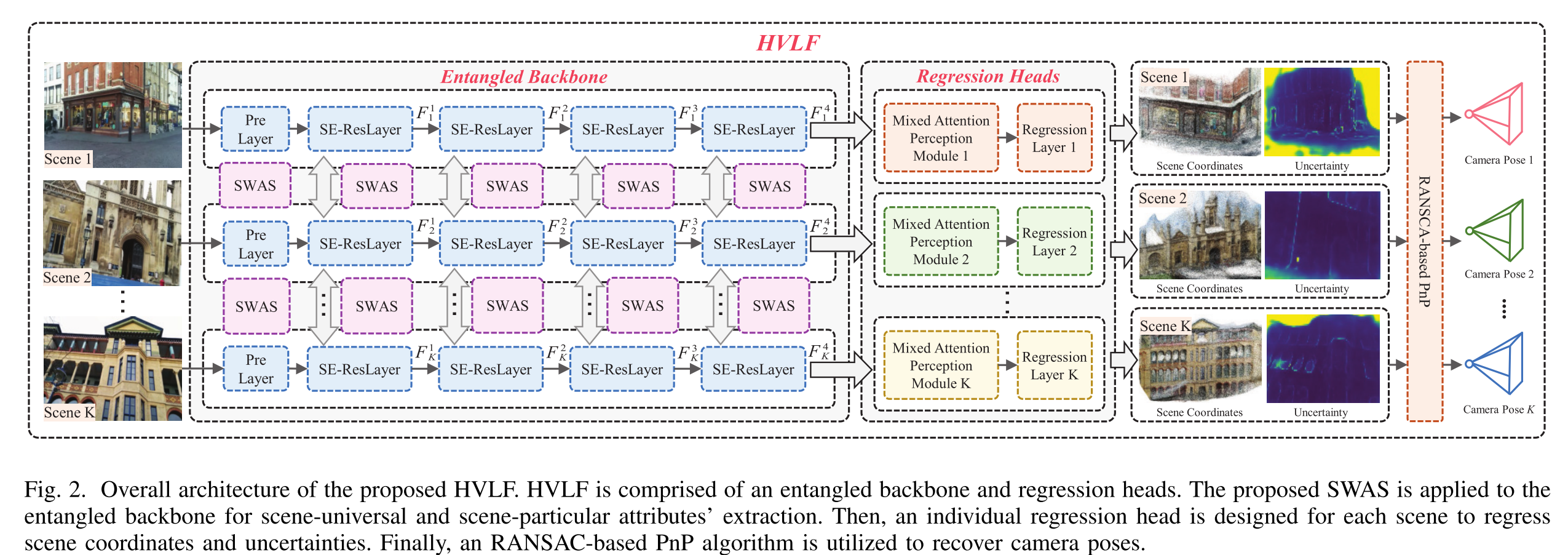
图2:HVLF的整体架构。
这张图清晰地展示了HVLF框架如何从输入图像一步步计算出最终的相机位置,其核心设计体现了 "共享与专属分离" 和 **"由粗到精"** 的先进思想。
整个流程可以分解为四个主要阶段:
阶段一:纠缠骨干网络 - 动态提取两类知识
这是HVLF的共享大脑,负责为所有场景处理输入图像。
-
Pre Layer:一个基础的卷积层,对输入的RGB图像进行初步的特征提取。
-
SE-ResLayer + SWAS模块 :这是核心创新所在。
-
SE-ResLayer:一种强大的残差网络模块,其中的"Squeeze-and-Excitation"操作能让网络学习每个特征通道的重要性(通道注意力),从而增强特征的判别力。
-
SWAS模块 :您在图1中看到的软权重激活策略 就应用在这里。它对SE-ResLayer的输出进行操作,动态地混合"场景通用"和"场景特定" 两套权重,生成一种同时包含普适性和专一性的高级特征。所有场景的图像都共享这个骨干网络。
-
阶段二:专属回归头 - 为每个场景定制"解码器"
经过共享骨干网络处理后,特征会进入各自场景专属的回归头。这是"分"的部分,每个场景都有一个独立的头部。
-
混合注意力感知模块 :这是回归头中的"精炼厂"。它接收来自骨干的混合特征,并再次通过通道、空间、元素三个维度的注意力机制,进一步聚焦于对当前场景定位最关键的视觉线索,滤除噪声和干扰,输出高度提纯的、适用于该场景的特征。
-
回归层:接收HAP模块提纯后的特征,最终回归出两个关键信息:
-
场景坐标:图像中每个像素(或关键点)对应的3D世界坐标。
-
不确定性:对每个坐标预测值的置信度评估(哪些预测更可靠)。
-
阶段三:位姿恢复 - 从3D点计算6D位姿
这不是神经网络部分,而是经典的几何视觉算法。
-
基于RANSAC的PnP算法:
-
输入是上一步得到的2D像素点 (来自图像)和其预测的3D场景坐标 ,以及对应的不确定性(用于加权)。
-
PnP 负责解算:需要多少对2D-3D匹配点,才能计算出相机的6自由度位姿(位置和朝向)。
-
RANSAC 负责鲁棒性:由于回归的3D坐标可能存在误差,RANSAC算法会随机采样多组点进行多次PnP计算,并选取支持点最多(即内点最多)的那个结果作为最终位姿。这能有效排除错误匹配(外点)的干扰。
-
核心思想总结
图2完美诠释了HVLF的名称------"跨场景的整体视觉定位框架":
-
整体性:拥有一个统一的特征提取骨干,学习所有场景的共性。
-
跨场景适应性:通过SWAS在骨干内部实现知识动态混合,通过专属回归头实现场景特定解码。
-
先进特征处理:在骨干和回归头中分别集成了SE注意力、SWAS、HAP等多重注意力机制,确保特征质量。
-
与传统几何结合:最终将深度学习预测的3D坐标,与鲁棒的几何算法结合,得到精准、稳定的相机位姿。
这个架构巧妙地将深度学习的表示学习能力 与传统几何视觉的精确性、鲁棒性结合在了一起,是其性能卓越的关键。
1)纠结主干:
纠缠主干包含K个场景的K个主干。每个主干由预置层和ResNet1837的四个残留层构成。主干中的所有常规层都被所提出的多面体卷积所取代。对于第i场景的视觉定位任务,将第i主干中的场景共享权重和场景特定权重分别定义为θshi和θspi。值得注意的是,θsh1=θsh2=···=θshK。此外,我们将具有场景特定权重φsp i的SENET13应用于每个残差块。因此,给定第i个场景的输入RGB图像Ii,我们将由第j个SE-ResLayer提取的特征定义为Fj i。输出特征F4 i可以表示为
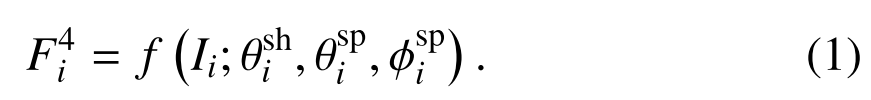
2)回归头:
对于第i个场景的视觉定位任务,回归头利用MAPM和几个具有场景特定权重ξsp i的常规层来处理特征F2 i、F3 i和F4 i,生成3-D场景坐标Pˆi和1-D不确定性Eˆi
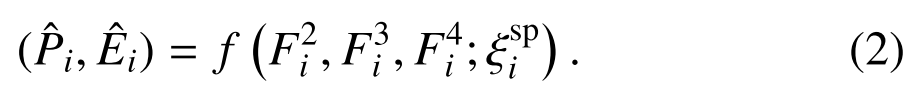
在这项工作中,我们提出了一种SWAS来提高网络的编码能力,以获取场景通用和场景特定的属性。此外,我们还开发了一种MAPM来获取用于预测精确场景坐标的区分性特征。在接下来的内容中,我们将全面介绍拟议的SWAS和MAPM。
3.2 软权重激活策略
最近,OFVL-MS8的成功证明,同时提取场景通用属性和场景特定属性有利于提高视觉定位精度。OFVL-MS采用刚性权重激活策略,该策略专门激活每个卷积层中的场景共享或场景特定的权重。这种体系结构对网络的特征提取能力施加了限制,因为识别场景通用属性和场景特定属性对于实现准确的场景坐标预测至关重要。在这一部分中,我们开发了一个SWAS,它同时优化场景共享和场景特定的权重,以获取场景通用和场景特定的特征,从而有效地增强特征表示。具体地,将SWAS应用于纠缠主干,用所提出的多面体卷积代替传统的卷积。
如图3所示,我们以第i和第j个场景为例,展示了SWAS在这两个场景中配备的单个SE-ResBlock。值得注意的是,第i和第j场景之间的连接是通过多面体卷积建立的。
1)多面体卷积:
如图4所示,与常规卷积不同,多面体卷积包含场景共享权重、场景特定权值和SPL。对于第k卷积层,我们遵循OFVL-MS8,将其初始权值∈Rco×Ci×w×w视为场景共享权重,用于编码场景通用属性。Co、Ci和w分别表示输出维度、输入维度和核大小。之后,我们定义了一个额外的场景特定权值˜wi∈Rco×Ci×w×w,用于区分场景特定的特征。
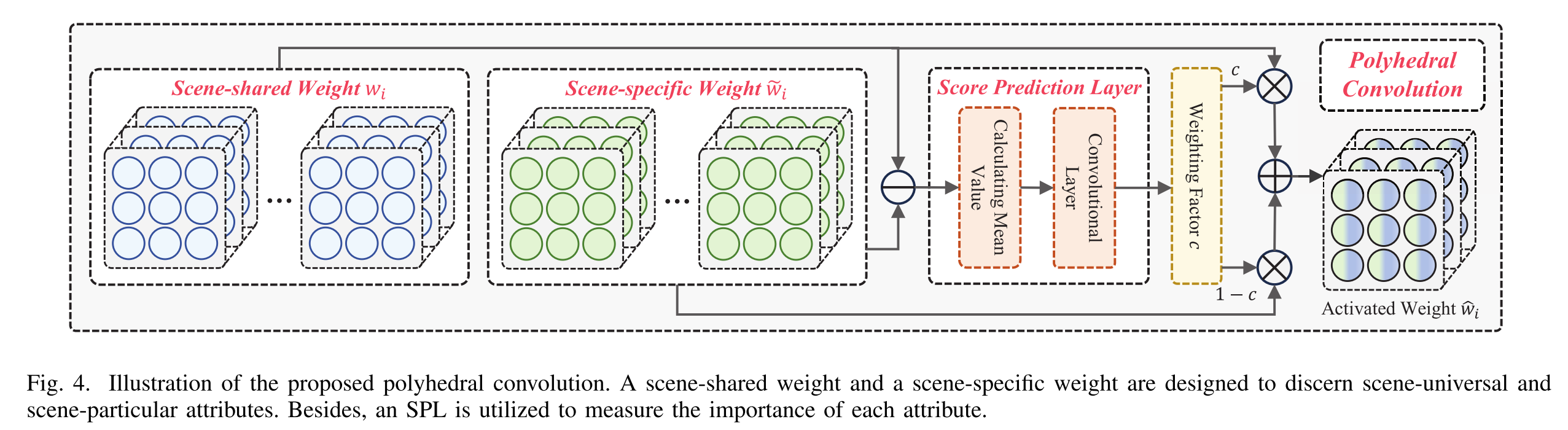
图4.所提出的多面体卷积的图解。场景共享权重和场景特定权重被设计为区分场景通用属性和场景特定属性。此外,还利用SPL来衡量每个属性的重要性。
SPL被设计成生成加权因子,该加权因子量化第i多面体卷积以提取场景通用或场景特定属性的倾向。从技术上讲,我们计算wi和˜wi之间的差异以获得它们的差异,然后通过平均值计算运算和卷积层进行处理,以生成加权因子c∈r1。
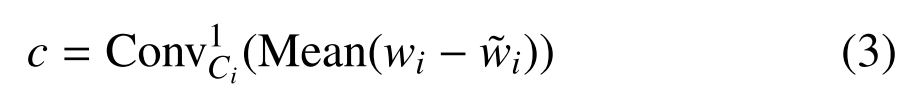
其中Mean(·)表示沿着权重的第一、第三和第四维计算平均值,Conv1Ci(·)表示输入维Ci和输出维1的卷积层。
我们将场景共享或场景特定的权重识别场景通用或场景特定属性的概率分别定义为c或1−c。因此,活化重量ˆwi∈Rco×Ci×w×w定义如下:
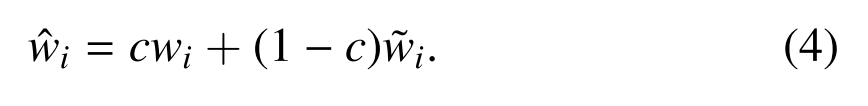
在前向传播过程中,利用RGB提取输入ˆwi图像的特征表示。在反向传播期间,c、wi和˜wi可以直接优化,因为它们都是可微的.
2)多面体卷积的参数分析:
对于每个场景,使用场景共享权wi、场景特定权值˜wi和spl来生成参与前向传播的激活权重ˆwi。因此,我们可以修改模型,在训练后只存储激活的重量ˆwi。因此,所提出的多面体卷积保持了与传统卷积相同的参数数量。
SWAS建立在多面体卷积的基础上,利用分布式数据并行(DDP)技术来确保场景共享权重wi在所有场景中得到优化,同时使每个单独场景优化其自己的场景特定权重˜wi。因此,覆盖所有场景的场景通用属性和每个场景特有的属性都可以通过多面体卷积进行编码,从而便于对所有场景的全面感知。值得注意的是,我们将SPL设置为场景特定的,因为不同的场景往往对场景共享的信息具有不同的依赖关系。
3.3 混合注意感知模块
最近,一些工作1、9表明,几何信息有助于区分相似的图像块,而语义信息有助于对Score问题进行编码。此外,各种注意机制13、15被设计成在强调基本信息的同时抑制无关特征。在这些工作的启发下,我们详细阐述了一种MAPM,它协同结合了通道、空间和元素的注意机制来捕捉可区分的几何和语义特征,从而实现场景坐标的精确回归。
如图5所示,MAPM最初使用常规层来处理由主干提取的特征F2i和F3i,从而确保特征图的相同分辨率。之后,MAPM沿通道维度连接这两个要素,生成中间要素表示F23i
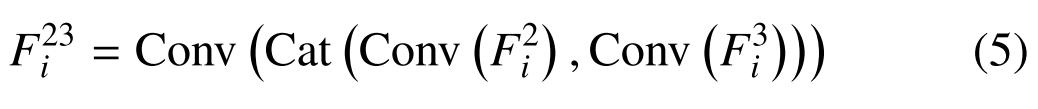
其中,Cat(·,·)表示沿通道维度串联要素。
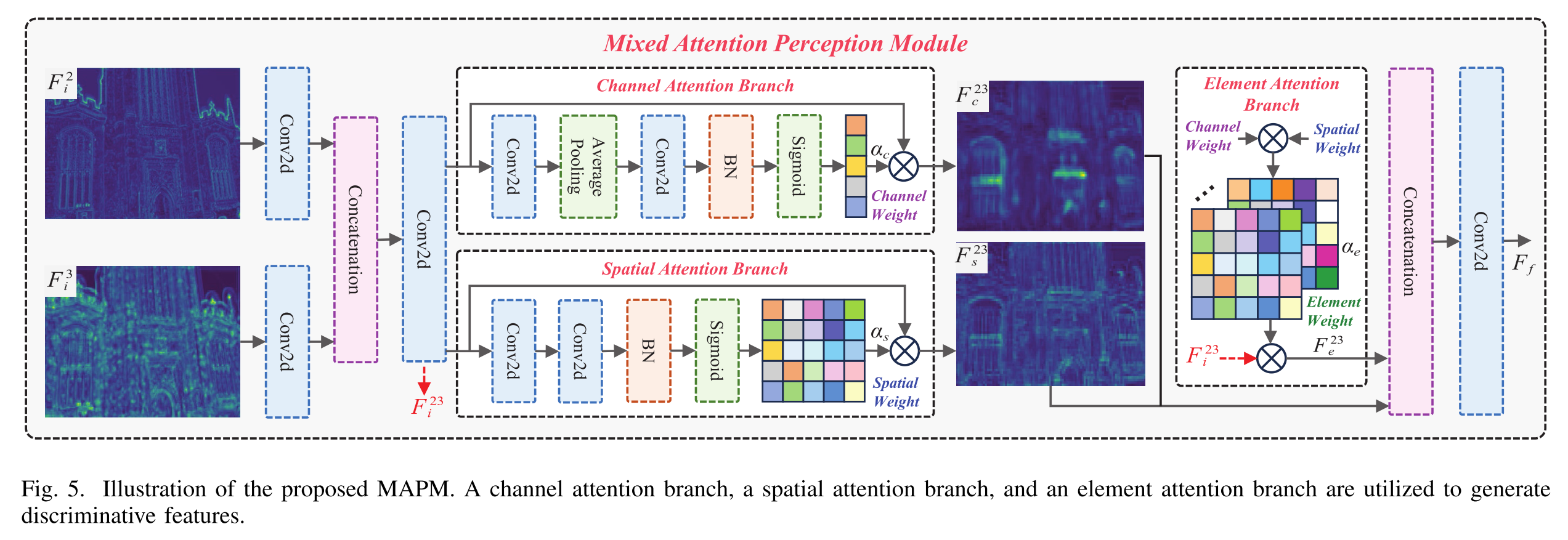
之后,MAPM设计了两个并行分支(即通道注意分支和空间注意分支)来分别产生信道权重αc和空间权重αS。由于αc和αS代表了沿通道和空间维度的特征的重要性,因此MAPM引入了元素级注意力分支,该分支执行αc和αS的乘法以得到元素级权重αe。所有加权掩码都被用来对F23i进行加权,从而强调关键信息并抑制无关特征。这一过程可按如下方式制定:
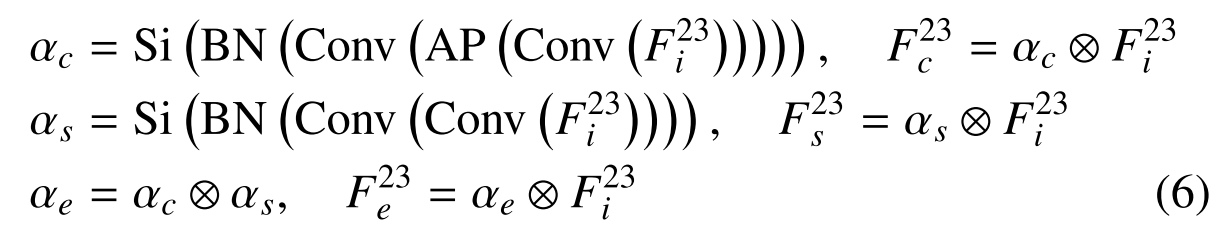
其中,AP(·)表示全局平均池,⊗表示元素乘法。
Subsequently, we concatenate F23 c , F23 s , and F23 e along the channel dimension and use a convolutional layer to squeeze feature dimension, yielding a fused low-level feature Ff
随后,我们沿着通道维度将F23 c、F23 S和F23 e串联,并使用卷积层来压缩特征维度,产生融合的低水平特征Ff
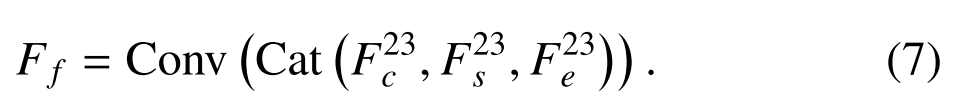
最后,我们将高层特征F4I和融合后的低层特征FF相结合,生成一个可区分的特征FM,该特征封装了丰富的几何和语义信息,用于回归精确的场景坐标
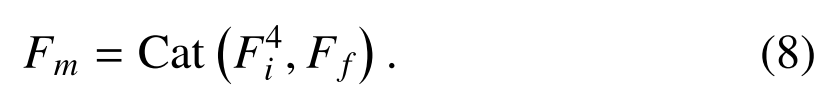
3.4 回归头部和六自由度位姿估计

我们遵循OFVL-MS8,并利用几个卷积层来处理特征Fm,以回归三维场景坐标Pˆi={ˆPj i|j=1,2,.。。,N}和一维不确定性Eˆi={ˆe j i|j=1,2,.。。,N,其中N=H/8×W/8。正如KFNet12所证明的,预测不确定性有利于测量来自数据集和模型的噪声。基于预测的场景坐标Pˆi,我们利用DSAC++7提供的一种基于随机抽样的PNP算法来估计六自由度摄像机的姿态。
3.5 损失
对于每个场景,我们使用主流损失函数12,该函数最大化与场景坐标相关联的概率密度函数的对数似然。给定地面真实场景坐标PI={Pj i|j=1,2,.。。,N},预测场景坐标Pˆi={ˆPj i|j=1,2,.。。,N}和不确定性Eˆi={ˆe j i|j=1,2,.。。,N},我们定义第i个场景的损失函数L为
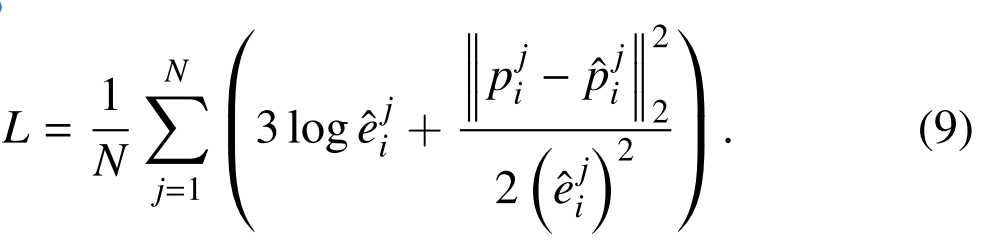
如(9)所示,当预测的场景坐标不准确时,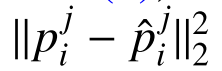 较大。此时,网络将预测较大的不确定性ˆe j i,以确保第二项具有更大的分母。同时,网络将产生更大的惩罚项3logˆe ji,以避免过多的ˆe j i。
较大。此时,网络将预测较大的不确定性ˆe j i,以确保第二项具有更大的分母。同时,网络将产生更大的惩罚项3logˆe ji,以避免过多的ˆe j i。