【Redis】系列第 1 期:VibeLoop 的数据基石 --- Redis 数据结构与 Spring Boot 集成
VibeLoop 是一个虚构的轻量级内容互动平台,用于本系列统一演示。本文从零开始,带你理解 Redis 五种核心数据结构的底层机制,并集成到 Spring Boot 中实战------为后续的缓存策略、分布式锁、高可用架构打下基础。
- [1. 开篇场景](#1. 开篇场景)
- [2. 五大数据结构全景速览](#2. 五大数据结构全景速览)
- [3. String:不只存字符串](#3. String:不只存字符串)
- [3.1 VibeLoop 实战:Session 共享与接口限流](#3.1 VibeLoop 实战:Session 共享与接口限流)
- [3.2 内部编码:44 字节的临界点](#3.2 内部编码:44 字节的临界点)
- [4. Hash:用户资料的理想容器](#4. Hash:用户资料的理想容器)
- [4.1 VibeLoop 实战:用户资料字段独立更新](#4.1 VibeLoop 实战:用户资料字段独立更新)
- [4.2 内部编码:ziplist → hashtable 的转换秘密](#4.2 内部编码:ziplist → hashtable 的转换秘密)
- [5. List:时间线背后的双向链表](#5. List:时间线背后的双向链表)
- [5.1 VibeLoop 实战:动态 Timeline 与异步消息队列](#5.1 VibeLoop 实战:动态 Timeline 与异步消息队列)
- [5.2 阻塞命令:BRPOP 实现可靠消费](#5.2 阻塞命令:BRPOP 实现可靠消费)
- [6. Set:去重与集合运算](#6. Set:去重与集合运算)
- [6.1 VibeLoop 实战:共同关注与标签聚合](#6.1 VibeLoop 实战:共同关注与标签聚合)
- [7. ZSet:排行榜的灵魂数据结构](#7. ZSet:排行榜的灵魂数据结构)
- [7.1 跳表:为什么 O(logN) 却比红黑树更优?](#7.1 跳表:为什么 O(logN) 却比红黑树更优?)
- [7.2 VibeLoop 实战:24h/7d/30d 三维热榜](#7.2 VibeLoop 实战:24h/7d/30d 三维热榜)
- [8. 单线程模型深度拆解](#8. 单线程模型深度拆解)
- [8.1 IO 多路复用:epoll 三件套](#8.1 IO 多路复用:epoll 三件套)
- [8.2 6.0 的 IO 多线程:别被名字骗了](#8.2 6.0 的 IO 多线程:别被名字骗了)
- [9. Spring Boot 集成:从配置到实战](#9. Spring Boot 集成:从配置到实战)
- [9.1 依赖与配置](#9.1 依赖与配置)
- [9.2 StringRedisTemplate 五种操作速查](#9.2 StringRedisTemplate 五种操作速查)
- [9.3 Lettuce 连接池调优](#9.3 Lettuce 连接池调优)
- [10. 源码走读:Lettuce 连接池 borrowObject](#10. 源码走读:Lettuce 连接池 borrowObject)
- [11. 面试 8 连问](#11. 面试 8 连问)
- [12. 必背速查表](#12. 必背速查表)
1. 开篇场景
假设你正在搭建 VibeLoop,一个轻量级内容互动平台。
用户 Alice 登录后,首页需要展示她的个人信息、关注列表、最新动态时间线、以及当前的热门帖子排行。这些数据,每一次请求都去 MySQL 查?那张用户关注表动辄百万行,每次 JOIN 查询需要 200ms------再加推荐算法、权限校验,用户可能还没刷出首页就已经划走了。
这就是 Redis 的价值:它把「读多写少」的热数据放在内存中,用精心设计的数据结构匹配对应的业务场景,把响应时间从 200ms 压缩到 1ms 以内。
你会怎么用 Redis 的数据结构来承载 VibeLoop 的这些需求?
先别急着翻文档。咱们从五种基本数据类型逐一切入,趁热把内部编码、单线程模型、Spring Boot 集成和连接池源码一并打通。
2. 五大数据结构全景速览
在深入代码之前,先把五大数据结构与 VibeLoop 的业务场景做一次全景映射:
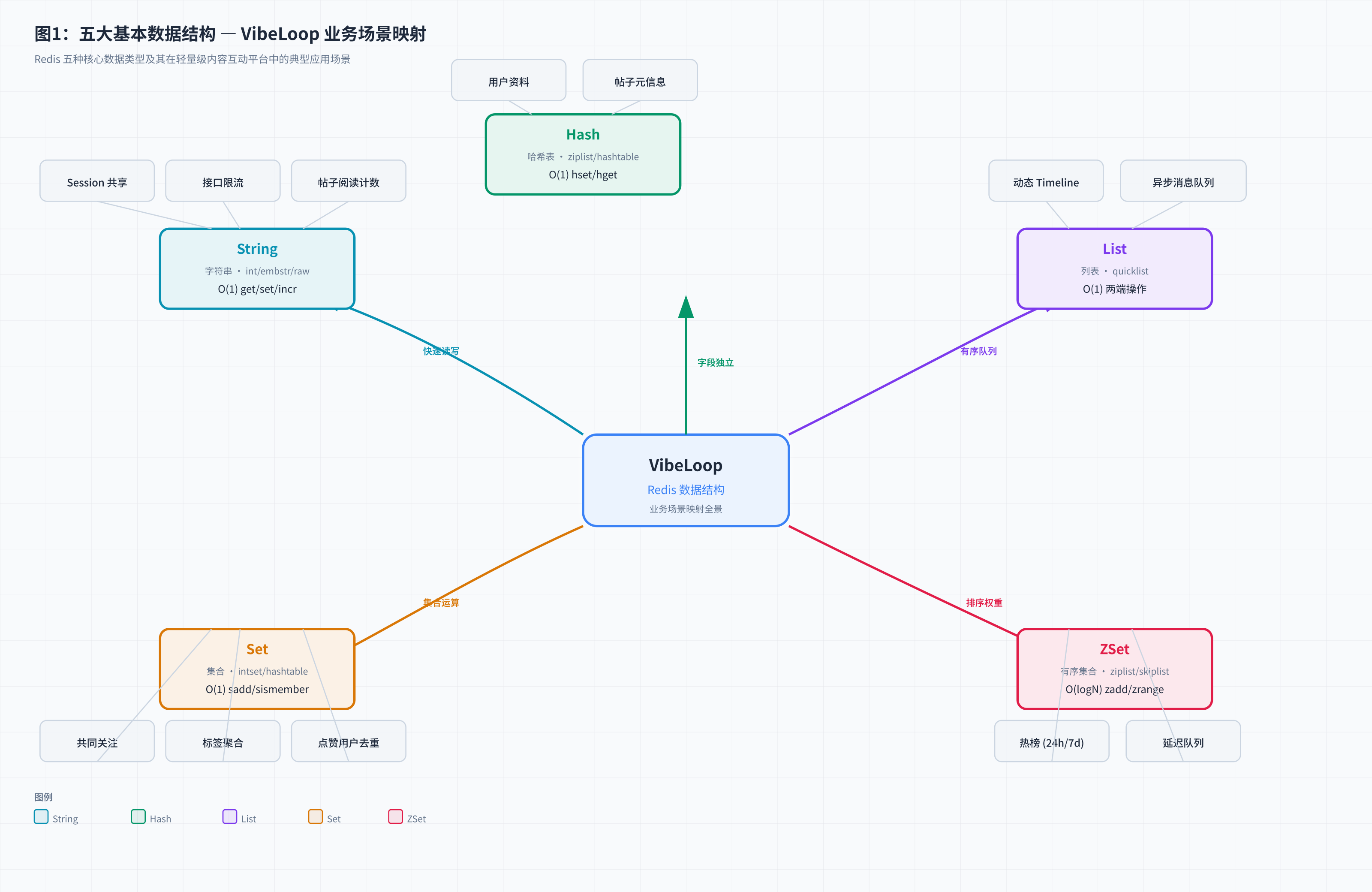
| 数据结构 | VibeLoop 场景 | 核心命令 | 时间复杂度 |
|---|---|---|---|
| String | Session 共享、帖子阅读计数、接口限流 | SET/GET/INCR/EXPIRE |
O(1) |
| Hash | 用户资料(昵称/头像/简介独立字段) | HSET/HGET/HDEL |
O(1) |
| List | 用户动态 Timeline、异步消息队列 | LPUSH/LRANGE/BRPOP |
O(1) 两端 |
| Set | 共同关注、内容标签聚合、点赞去重 | SADD/SINTER/SDIFF |
O(1) |
| ZSet | 热门帖子排行(24h/7d/30d) | ZADD/ZRANGE/ZREVRANK |
O(logN) |
同一个 Redis key 背后,Redis 会根据数据的大小和元素数量,自动选择不同的内部编码来实现。这也是面试中的重灾区------我们会在每个类型章节展开。
3. String:不只存字符串
Redis 的 String 本质上是一个二进制安全的字节数组,最大 512MB。你用它存 JSON 序列化后的对象、整型计数器、二进制图片,都行。
3.1 VibeLoop 实战:Session 共享与接口限流
场景一:Session 共享。 VibeLoop 部署了 3 台 Web 节点,用户登录后 Session 需要跨节点共享。
java
// 用户登录成功后,将 Session 信息存入 Redis
String sessionKey = "vibeloop:session:" + sessionId;
stringRedisTemplate.opsForValue().set(
sessionKey,
JsonUtil.toJson(userSession),
Duration.ofMinutes(30)
);不用 sticky session,不用 Spring Session 的额外依赖。任何一个节点收到请求,直接读 vibeloop:session:<id> 就行。
场景二:接口限流。 VibeLoop 的帖子发布接口被脚本刷了,需要限制同一用户每分钟最多发 3 条。
java
public boolean allowPublish(String userId) {
String rateKey = "vibeloop:rate:publish:" + userId;
Long count = stringRedisTemplate.opsForValue().increment(rateKey);
if (count == 1) {
// 第一次请求,设置窗口
stringRedisTemplate.expire(rateKey, Duration.ofMinutes(1));
}
return count <= 3;
}用 INCR 而非 GET + SET------一个是需要两步操作(有并发窗口问题),一个是单条原子命令。面试官大概率会追问「为什么用 INCR 而不是 GET 后 +1 再 SET」,答不上来就危险了。
3.2 内部编码:44 字节的临界点
Redis 并非只用一个结构来存 String。它有三种内部编码,通过 OBJECT ENCODING 可以看到:
| 编码 | 条件 | 结构 |
|---|---|---|
int |
值可用 long 表示且 <= 20 位数字 | 直接存为 long,无额外开销 |
embstr |
值 <= 44 字节(Redis 5.0+) | 一次 malloc,元数据和值连续存储 |
raw |
值 > 44 字节 | 两次 malloc,redisObject 与 sds 分离 |
44 字节的由来: jemalloc 分配 64 字节内存块,redisObject 占 16 字节,sdshdr8 占 3 字节,\0 占 1 字节。64 - 16 - 3 - 1 = 44。超过 44 字节触发 embstr → raw 转换,多一次内存分配。
重要行为 :embstr 是只读的。一旦对 embstr 执行 APPEND 或 SETRANGE,Redis 会无条件升级到 raw,即使新值仍 <= 44 字节。这是面试中的经典陷阱------「embstr 的 key 做了 APPEND 后会怎样?」
4. Hash:用户资料的理想容器
4.1 VibeLoop 实战:用户资料字段独立更新
VibeLoop 用户资料包含昵称、头像、简介、粉丝数、关注数。如果用 JSON 字符串存在 String 里,每次改昵称都需要全量序列化反序列化。
用 Hash 就很舒服:每个字段独立一个 key-value 对,更新昵称只影响一个字段。
java
// 写入用户资料
String userKey = "vibeloop:user:profile:" + userId;
Map<String, String> profile = Map.of(
"nickname", "Alice_in_Wonderland",
"avatar", "https://cdn.vibeloop.com/avatars/alice.jpg",
"bio", "摄影爱好者 · 旅行博主",
"followerCount", "1280",
"followingCount", "365"
);
stringRedisTemplate.opsForHash().putAll(userKey, profile);
// 修改昵称------只改一个 field
stringRedisTemplate.opsForHash().put(userKey, "nickname", "Alice_V2");对比 String 方案:你拿到整个 JSON → 反序列化 → 找到 nickname 字段 → 修改 → 序列化 → 写回。Hash 只需要一次 HSET,时间复杂度 O(1)。
但小心 :Hash 不适合存字段数量巨大的对象。当元素超过 hash-max-ziplist-entries(默认 512)或单个 value 超过 hash-max-ziplist-value(默认 64 字节),内部编码从 ziplist 切换到 hashtable,内存占用会大幅上升。
4.2 内部编码:ziplist → hashtable 的转换秘密
ziplist(压缩列表)是一个紧凑的连续内存块,所有 field-value 对紧密排列。它省内存,但每次读写需要遍历。
hashtable 是标准哈希表,通过数组 + 链表解决冲突,读 O(1) 但每个节点有指针开销(在 64 位系统上是 8 字节/指针)。
配置建议 :对于 VibeLoop 这种 field 数较少(10 个以内)的用户资料,保持默认配置即可,让 ziplist 生效。如果你存的是电商 SKU 属性表(动辄上百字段),适当调高 hash-max-ziplist-entries 或让它自然切换到 hashtable。
5. List:时间线背后的双向链表
5.1 VibeLoop 实战:动态 Timeline 与异步消息队列
VibeLoop 的首页需要展示用户关注的好友动态------谁发了新帖、谁点了赞。
java
// 用户 Alice 发帖后,推送到所有粉丝的 Timeline
String timelineKey = "vibeloop:timeline:" + followerId;
String entry = JsonUtil.toJson(new TimelineEntry(postId, authorId, timestamp));
stringRedisTemplate.opsForList().leftPush(timelineKey, entry);
// 只保留最近 200 条
stringRedisTemplate.opsForList().trim(timelineKey, 0, 199);LPUSH 把新动态插入链表头部(最新),LTRIM 裁剪到 200 条。粉丝刷新首页时用 LRANGE 0 19 拉取最新 20 条,时间复杂度 O(S+N),S 是偏移量、N 是返回数量。
消息队列 :List 支持的 BRPOP(阻塞右弹出)天然适合做消费者。
java
// 审核队列消费者
while (true) {
String postId = stringRedisTemplate.opsForList()
.rightPop("vibeloop:queue:post:audit", Duration.ofSeconds(30));
if (postId != null) {
auditService.audit(postId);
}
}5.2 阻塞命令:BRPOP 实现可靠消费
BRPOP key timeout 的行为:
- 如果 key 有数据 → 立即弹出返回
- 如果 key 为空 → 阻塞直到有数据或超时
- 多个客户端同时
BRPOP同一个 key → 先阻塞的客户端先拿到(公平队列)
注意:
BRPOP超时返回null不代表出错,你需要while(true)循环持续取,而不是抛异常退出。
可靠性提醒 :BRPOP 弹出后消费者挂了,这条消息就丢了。Redis 5.0 引入的 Stream 类型才是生产级消息队列方案(有 ACK 机制和消费者组),List 适用于对丢失容忍度较高的场景(如 Timeline 推送、简单的异步任务)。
6. Set:去重与集合运算
6.1 VibeLoop 实战:共同关注与标签聚合
共同关注:Alice 关注了 {Bob, Charlie, David, Eve},Bob 关注了 {Alice, Charlie, Frank, Grace}。
java
String aliceKey = "vibeloop:following:" + aliceId; // Set: Bob, Charlie, David, Eve
String bobKey = "vibeloop:following:" + bobId; // Set: Alice, Charlie, Frank, Grace
// 共同关注
Set<String> common = stringRedisTemplate.opsForSet()
.intersect(aliceKey, bobKey);
// 结果: {Charlie}sinter 的时间复杂度是 O(N * M),N 是最小集合的元素数,M 是集合数。对于关注列表这种场景(大多数人关注几百到几千人),性能完全够用。
点赞去重 :VibeLoop 每篇帖子有一个 vibeloop:post:liked:<postId> Set,存所有点赞用户 ID。用户点赞前先 SISMEMBER 判断是否已点赞,SADD 后 SCARD 获取总数。
内部编码 :元素全是整数时用 intset(紧凑有序数组),一旦有非整数字符串元素立刻切换到 hashtable。
7. ZSet:排行榜的灵魂数据结构
这是五大数据类型中面试浓度最高的一个,也是 VibeLoop 热榜功能的核心。
ZSet 的每个元素由一个 member 和一个 score 构成,按 score 排序。它不像 Set 只管「有没有」,而是多了一层「排第几」的维度。
7.1 跳表:为什么 O(logN) 却比红黑树更优?
ZSet 的双编码:
ziplist:元素数 <= 128 且所有元素长度 <= 64 字节skiplist + dict:超过阈值后切换
skiplist(跳表)是一个多层链表:每一层都是下一层的快速通道。查找时从最高层开始,每次决定「往下走」还是「往右跳」,最终落到目标附近。
为什么不用红黑树? 面试标准答案:
- 范围查询:跳表找到起点后直接往后遍历,O(logN + M);红黑树需要中序遍历
- 实现复杂度:跳表的插入/删除只需修改相邻节点的指针,无需旋转和重新染色
- 空间换时间:跳表每层平均有 1/2 的节点,总空间 O(N),实际约 1.33N 个节点
7.2 VibeLoop 实战:24h/7d/30d 三维热榜
java
// 帖子被点赞,增加热度分
String hotKey24h = "vibeloop:hot:posts:24h";
stringRedisTemplate.opsForZSet().incrementScore(hotKey24h, postId, 1);
// 获取 24h 热榜 Top 20(分数从高到低)
Set<ZSetOperations.TypedTuple<String>> topPosts = stringRedisTemplate.opsForZSet()
.reverseRangeWithScores(hotKey24h, 0, 19);
// 定时任务:每小时清理 24 小时前的过期数据
long cutoff = System.currentTimeMillis() - 24 * 3600 * 1000;
stringRedisTemplate.opsForZSet().removeRangeByScore(hotKey24h, 0, cutoff);三个 ZSet key(vibeloop:hot:posts:24h、7d、30d)各维护一个榜。点赞 +1 分,评论 +3 分,分享 +5 分。定时任务清理过期数据确保不会无限膨胀。
延迟队列 也是 ZSet 的经典场景:把任务执行时间作为 score,ZRANGEBYSCORE 0 now 取到期任务。
8. 单线程模型深度拆解
面试中 80% 的人能答出「Redis 是单线程的」。但接下来的 20% 追问就能筛掉 80%------「单线程为什么还这么快?」
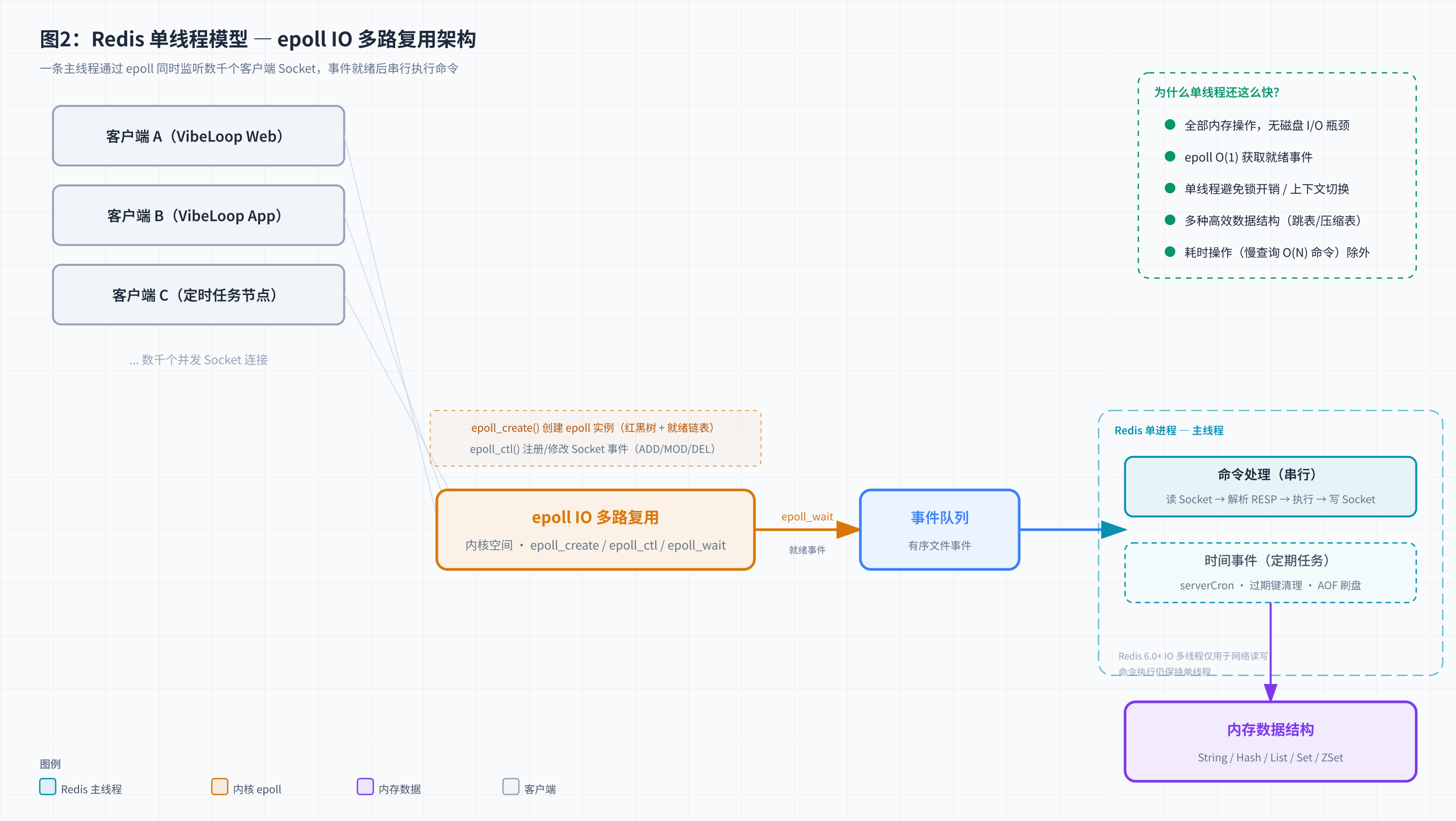
8.1 IO 多路复用:epoll 三件套
Redis 使用 epoll 实现 IO 多路复用。核心三件套:
| 函数 | 作用 |
|---|---|
epoll_create() |
创建 epoll 实例,内核分配红黑树 + 就绪链表 |
epoll_ctl() |
向 epoll 实例注册/修改/删除需要监听的 Socket fd |
epoll_wait() |
阻塞等待,直到有 Socket 就绪,O(1) 返回就绪事件列表 |
对比 select/poll:epoll 用红黑树管理所有 fd,就绪事件放在链表里。epoll_wait 不需要遍历全部 fd,直接返回就绪链表------这正是「O(1) 获取就绪事件」的由来。
Redis 的事件循环核心逻辑:
while (true) {
// 1. 计算最近时间事件的到期时间
// 2. epoll_wait 阻塞等待文件事件(超时 = 最近时间事件)
// 3. 处理就绪的文件事件(读/写网络数据)
// 4. 处理到期的时间事件(serverCron、过期键清理等)
}快的原因总结:
- 全部内存操作,无磁盘 IO
- epoll O(1) 拿到就绪 Socket
- 单线程避免锁竞争和上下文切换
- 内部数据结构经过精心选择和优化
慢的场景 :O(N) 命令(KEYS *、SMEMBERS、HGETALL)会阻塞整个事件循环。生产环境严禁 KEYS *,用 SCAN 代替。
8.2 6.0 的 IO 多线程:别被名字骗了
Redis 6.0 引入的「IO 多线程」只用于网络数据的读写------Socket 数据从内核读到用户空间,以及从用户空间写到内核,可以由多个 IO 线程并行处理。
但命令的解析和执行仍然在主线程中串行完成。
这意味着:
- 单个命令不会被多线程并发执行,不存在并发安全问题
- 耗时命令(如
KEYS *)仍然会阻塞整个服务 - IO 多线程默认关闭(
io-threads 1),高并发场景才需要手动开启
9. Spring Boot 集成:从配置到实战
9.1 依赖与配置
Spring Boot 3.x 默认使用 Lettuce 作为 Redis 客户端。Jedis 虽然也很流行,但 Spring Data Redis 从 2.x 起已将 Lettuce 设为默认(Netty 异步驱动,线程安全,连接天然共享)。
Maven 依赖:
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>application.yml(VibeLoop 开发环境配置):
yaml
spring:
data:
redis:
host: 127.0.0.1
port: 6379
password: ${REDIS_PASSWORD:}
timeout: 3000ms
lettuce:
pool:
max-active: 16 # 最大活跃连接数
max-idle: 8 # 最大空闲连接数
min-idle: 2 # 最小空闲连接数
max-wait: 2000ms # 获取连接最大等待时间9.2 StringRedisTemplate 五种操作速查
Spring Data Redis 提供 StringRedisTemplate(key 和 value 都是 String 序列化),日常开发 90% 的场景足够。
java
@RestController
@RequestMapping("/api/redis-demo")
public class RedisDemoController {
@Autowired
private StringRedisTemplate redis;
// ===== String =====
@GetMapping("/string")
public void stringOps() {
redis.opsForValue().set("vibeloop:counter:post:10001", "42");
redis.opsForValue().increment("vibeloop:counter:post:10001");
redis.opsForValue().get("vibeloop:counter:post:10001"); // "43"
}
// ===== Hash =====
@GetMapping("/hash")
public void hashOps() {
redis.opsForHash().put("vibeloop:user:profile:alice", "nickname", "Alice_V2");
redis.opsForHash().get("vibeloop:user:profile:alice", "nickname");
redis.opsForHash().hasKey("vibeloop:user:profile:alice", "avatar");
redis.opsForHash().delete("vibeloop:user:profile:alice", "bio");
}
// ===== List =====
@GetMapping("/list")
public void listOps() {
redis.opsForList().leftPush("vibeloop:timeline:bob", "post:1024");
redis.opsForList().leftPushAll("vibeloop:timeline:bob", "post:1025", "post:1026");
redis.opsForList().range("vibeloop:timeline:bob", 0, 9); // 最近10条
redis.opsForList().trim("vibeloop:timeline:bob", 0, 199); // 保留200条
}
// ===== Set =====
@GetMapping("/set")
public void setOps() {
redis.opsForSet().add("vibeloop:post:tags:10001", "美食", "旅行", "摄影");
redis.opsForSet().add("vibeloop:post:tags:10002", "美食", "科技");
redis.opsForSet().intersect(
"vibeloop:post:tags:10001", "vibeloop:post:tags:10002"); // ["美食"]
}
// ===== ZSet =====
@GetMapping("/zset")
public void zsetOps() {
redis.opsForZSet().add("vibeloop:hot:posts:24h", "post:1024", 50);
redis.opsForZSet().incrementScore("vibeloop:hot:posts:24h", "post:1024", 3);
redis.opsForZSet().reverseRange("vibeloop:hot:posts:24h", 0, 9); // Top 10
redis.opsForZSet().rank("vibeloop:hot:posts:24h", "post:1024");
}
}9.3 Lettuce 连接池调优
| 参数 | 默认值 | VibeLoop 建议 | 说明 |
|---|---|---|---|
max-active |
8 | 16 | 并发请求数 = 业务线程数,适当调大 |
max-idle |
8 | 8 | 空闲时保留的连接,避免频繁创建销毁 |
min-idle |
0 | 2 | 预创建 2 个连接应对突发流量 |
max-wait |
-1(无限) | 2000ms | 等待超时后抛异常,避免线程堆积 |
10. 源码走读:Lettuce 连接池 borrowObject
当 VibeLoop 的 Web 线程执行 redis.opsForValue().get("key") 时,底层发生了什么?
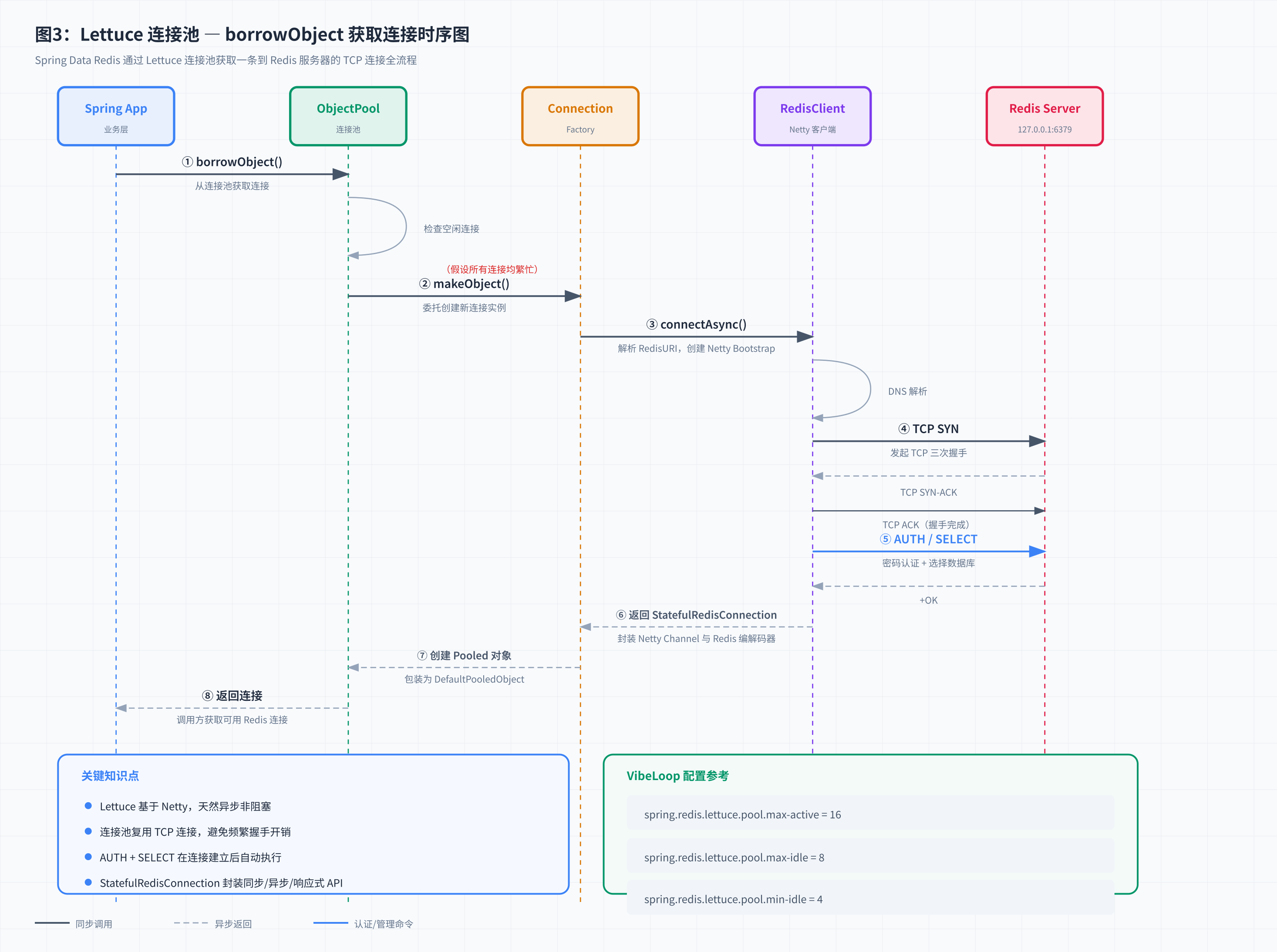
核心调用链:
StringRedisTemplate.getConnection()→ 委托给RedisConnectionFactoryLettuceConnectionFactory.getConnection()→ 调用GenericObjectPool.borrowObject()borrowObject()先检查idleObjects链表是否为空- 有 idle :从链表头部取出,执行
testOnBorrow验证(默认关闭),验证通过则返回 - 无 idle :触发
makeObject()创建新连接
- 有 idle :从链表头部取出,执行
makeObject()→RedisClient.connectAsync()→ Netty 建立 TCP 连接 →AUTH认证 → 包装为StatefulRedisConnection- 回到
borrowObject:调用factory.activateObject()(订阅连接事件) - 应用拿到连接,执行 Redis 命令(如
GET vibeloop:user:profile:10001) - 命令执行完毕后,
returnObject(conn)归还连接池
关键点 :Lettuce 的 StatefulRedisConnection 本身是线程安全的。连接池的作用不是解决线程安全问题,而是限制并发连接数、复用 TCP 连接以减少建连开销。
11. 面试 8 连问
Q1:Redis 的 String 最大能存多大?
A:512MB。超出会报错 ERR value is out of range。实际生产建议控制在 10KB 以内------单 key 过大影响网络传输、阻塞主线程、触发 raw 编码浪费内存。
Q2:ZSet 底层用了什么数据结构?为什么不用红黑树?
A:ziplist(小数据)或 skiplist + dict(大数据)。跳表比红黑树更适合范围查询(O(logN) + 直接向后遍历),实现更简单无需旋转染色,且红黑树的树形结构在范围查询时需要中序遍历,不如跳表直接。
Q3:embstr 和 raw 的区别?什么情况下 embstr 会变成 raw?
A:embstr 是 <= 44 字节时的一次性分配,redisObject 和 sds 连续存储;raw 是 > 44 字节时的两次分配。任何修改操作(APPEND、SETRANGE)都会触发 embstr → raw 的不可逆转换。
Q4:Hash 和 String 存对象哪个更好?
A:字段少且需要独立更新的场景,Hash 更好(HSET 单字段 O(1),String 需要全量序列化)。字段多且很少单独更新的场景,String 可能更简单。Hash 内部编码切换(ziplist → hashtable)可能导致内存陡增,需关注配置阈值。
Q5:Redis 为什么用单线程?单线程为什么还这么快?
A:Redis 的性能瓶颈从来不在 CPU,而是内存和网络带宽。单线程简化了实现(无锁、无上下文切换)。快的原因:纯内存操作 + epoll IO 多路复用 + 精心设计的数据结构。6.0 引入的 IO 多线程只处理网络读写,命令执行仍为单线程。
Q6:List 做消息队列有什么问题?
A:BRPOP 弹出后消费者崩溃会导致消息丢失(无 ACK 机制);不支持消费者组和消息回溯。简单异步任务可用 List,生产级消息队列建议用 Redis Stream(5.0+)或 RabbitMQ/Kafka。
Q7:KEYS * 为什么被禁用?替代方案是什么?
A:KEYS * 遍历整个 keyspace,时间复杂度 O(N),执行期间整个 Redis 阻塞。生产环境用 SCAN 游标式渐进遍历,每次只返回少量 key,对业务无感。SCAN 不保证不重复不遗漏,需在业务层做去重。
Q8:Lettuce 和 Jedis 的区别?Spring Boot 为什么选 Lettuce?
A:Jedis 是同步客户端,连接非线程安全,需配合 JedisPool 使用。Lettuce 基于 Netty 异步驱动,StatefulRedisConnection 本身线程安全,连接天然可共享。Spring Data Redis 2.x 起将 Lettuce 设为默认,因为它在高并发下连接管理更优、更适配响应式编程模型。
12. 必背速查表
数据类型时间复杂度
| 命令 | 时间复杂度 | 注意 |
|---|---|---|
SET/GET/INCR/DECR |
O(1) | String 核心操作 |
HSET/HGET/HDEL |
O(1) | Hash 单字段操作 |
HGETALL |
O(N) | 全部 field-value,大 Hash 禁用 |
LPUSH/RPUSH/LPOP/RPOP |
O(1) | List 两端操作 |
LRANGE key 0 9 |
O(S+N) | S=偏移量,N=返回数量 |
SADD/SREM/SISMEMBER |
O(1) | Set 基础操作 |
SINTER |
O(N*M) | N=最小集合大小,M=集合数 |
ZADD/ZREM/ZSCORE |
O(logN) | ZSet 单元素操作 |
ZRANGE key 0 9 |
O(logN+M) | M=返回数量 |
KEYS pattern |
O(N) | 生产禁用,用 SCAN |
内部编码决策表
| 类型 | 编码 | 触发条件 |
|---|---|---|
| String | int |
值可转为 long 且 <= 20 位 |
| String | embstr |
值 <= 44 字节 |
| String | raw |
值 > 44 字节 或 embstr 被修改 |
| Hash | ziplist |
field ≤ 512 且 value ≤ 64B |
| Hash | hashtable |
超过 ziplist 任一阈值 |
| ZSet | ziplist |
元素 ≤ 128 且 member ≤ 64B |
| ZSet | skiplist |
超过 ziplist 任一阈值 |
| Set | intset |
全部元素为整数 |
| Set | hashtable |
出现非整数元素 |
| List | quicklist |
LinkedList + ziplist 混合,所有场景 |
第 1 期到这里。 五种数据结构、内部编码、单线程模型、Spring Boot 集成、Lettuce 连接池源码------这些是 Redis 面试的「地基」。下一期我们进入 VibeLoop 的流量护盾:缓存策略、穿透/雪崩/击穿的彻底解决,以及双写一致性这个面试修罗场。
下期速递 :【Redis】缓存策略与三大经典问题