【Redis】系列第2期:VibeLoop 的流量护盾 --- 缓存策略与三大经典问题
贯穿案例「VibeLoop」 :为虚拟 的互动平台,仅用于技术演示,并非真实存在 的产品。
上期速递 :【Redis】Redis 数据结构与 Spring Boot 集成
本文是 VibeLoop 系列的 第2期,全文共9 个章节。覆盖缓存更新策略、三大经典问题(穿透/击穿/雪崩)、淘汰策略选型、双写一致性、Spring Cache 踩坑、8 道面试题、必背速查表。
目录
- [开篇场景:Feed 流崩溃之夜](#开篇场景:Feed 流崩溃之夜)
- 理论基础:为什么缓存像图书馆借阅台
- [1. 缓存更新策略四种模式对比](#1. 缓存更新策略四种模式对比)
- [2. 缓存穿透三件套](#2. 缓存穿透三件套)
- [3. 缓存击穿:热点 key 的生死时速](#3. 缓存击穿:热点 key 的生死时速)
- [4. 缓存雪崩:多米诺骨牌效应](#4. 缓存雪崩:多米诺骨牌效应)
- [5. 八种淘汰策略选型矩阵](#5. 八种淘汰策略选型矩阵)
- [6. 双写一致性:最难解的并发题](#6. 双写一致性:最难解的并发题)
- [7. Spring Cache 注解踩坑实录](#7. Spring Cache 注解踩坑实录)
- [8. 面试八连问 + 详解](#8. 面试八连问 + 详解)
- [9. 必背速查表](#9. 必背速查表)
开篇场景:Feed 流崩溃之夜
20xx年双十一当晚,VibeLoop 技术群炸了。
运维老张在群里甩了一张 Grafana 截图:MySQL CPU 飙到 98%,慢查询堆积如山,首页 Feed 流接口 P99 延迟从平日的 80ms 飙升到 12 秒。用户疯狂下拉刷新,每次下拉都是一次 SELECT * FROM posts ORDER BY update_time DESC LIMIT 20,QPS 10000 的路由全砸在数据库上。
值班的小王慌了,紧急加了 Redis 缓存。Feed 流接口查 Redis 命中直接返回,miss 才查 DB。10 分钟后,CPU 降到了 30%,世界清净了。
但是第二天一早,更大的问题来了:
- 缓存穿透:有恶意脚本用随机 userId 疯狂请求不存在用户的主页,Redis 全部 miss,请求一路打到 DB,CPU 又飙了
- 缓存击穿:运营置顶了一个"双十一战报"帖子,访问量暴增。缓存刚好过期的那一秒,几百个线程同时打到 DB 拉了同一份数据
- 缓存雪崩:小王给所有帖子缓存设了统一的 1 小时 TTL。08:00 整,大量缓存同时失效,DB 瞬间被打穿
这就是缓存引入后必须面对的三大经典问题。缓存降低了 DB 压力,但把一致性、可用性、穿透防护的复杂度全部转移到了中间层。会用 Redis 不稀奇,能把缓存用对、用稳、用不出事,才是面试官真正想考察的。
理论基础:为什么缓存像图书馆借阅台
在进入具体方案之前,先建立一个核心类比:
缓存 = 图书馆借阅台 。热门书放在前台随手取(缓存命中),冷门书要去书架深处找(查数据库)。借阅台空间有限,所以要不断淘汰冷门书(淘汰策略)。如果有人捏造一本不存在的书名来查询,借阅台查不到就去书架翻,翻完也没有------这就是缓存穿透 。如果某本书突然爆火但刚好被人还回来还没上架,所有人冲到书架去抢------这就是缓存击穿 。如果图书馆断电,借阅台所有书被清空,全馆读者同时涌向书架------这就是缓存雪崩。
带着这个类比,我们逐个击破。
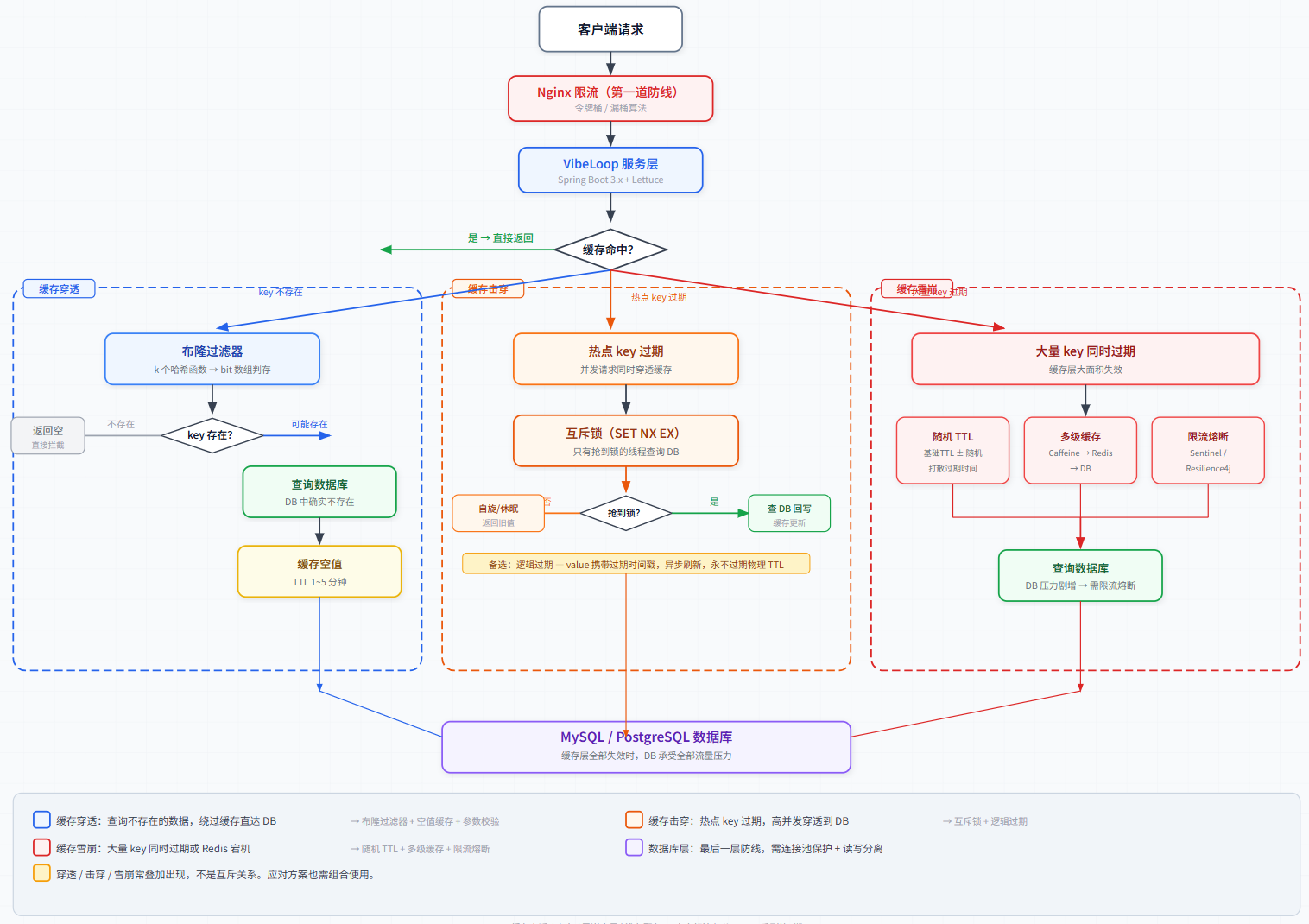
图1:穿透(蓝色)/ 击穿(橙色)/ 雪崩(红色)在请求链路中的位置与应对方案全景
1. 缓存更新策略四种模式对比
缓存的本质是"用空间换时间",但谁来负责更新缓存?有四种经典模式。
1.1 Cache Aside(旁路缓存)--- VibeLoop 实际采用
读:先查缓存 → 命中返回 / miss 查 DB → 写缓存 → 返回
写:先更新 DB → 再删除缓存(而非更新缓存)为什么写时删缓存而不是更新缓存? 因为更新缓存可能产生"写-写"并发导致脏数据:线程 A 更新 DB → 线程 B 更新 DB → 线程 B 更新缓存 → 线程 A 更新缓存(B 的更新被 A 覆盖)。而删除缓存则没有这个问题------缓存被删后,下次读请求会自然从 DB 加载最新值。
VibeLoop 帖子编辑的简化代码:
java
@Transactional
public void updatePost(Long postId, PostDTO dto) {
postMapper.updateById(postId, dto); // 1. 更新 DB
stringRedisTemplate.delete("post:" + postId); // 2. 删除缓存
}适用场景:读多写少,对一致性要求不极端严格。VibeLoop 首页 Feed、帖子详情都用这个模式。
1.2 Read/Write Through(读写穿透)
缓存层直接代理 DB,应用只和缓存打交道:
读:应用 → 缓存 → (miss时缓存自己查DB并回填) → 返回
写:应用 → 缓存 → (缓存同步更新DB) → 返回Redisson 的 RLocalCachedMap 支持类似语义,但 Spring Cache 默认不实现 Write Through。
适用场景:追求代码简洁、缓存与 DB 强绑定的场景。
1.3 Write Behind(异步回写)
写操作只写缓存,异步批量刷入 DB。例如每秒合并 100 次计数器更新为一条 SQL:
应用 → 只写缓存 → 返回
↓ (异步批量)
DB风险极高:缓存宕机 = 数据丢失。VibeLoop 仅用于非关键数据的计数(如帖子浏览数),核心业务不用。
1.4 四种模式对比
| 模式 | 写延迟 | 一致性 | 复杂度 | VibeLoop 场景 |
|---|---|---|---|---|
| Cache Aside | 低 | 最终一致 | 低 | 帖子详情、用户资料 |
| Read Through | 低 | 强一致 | 中 | 配置数据 |
| Write Through | 低 | 强一致 | 中 | 很少使用 |
| Write Behind | 极低 | 弱一致 | 高 | 浏览计数(非关键) |
2. 缓存穿透三件套
问题本质 :查询一个数据库中根本不存在的数据,缓存永远 miss,每次请求都穿透到 DB。
VibeLoop 实战场景:爬虫脚本遍历 userId=1 到 1000000,大量随机 ID 根本不存在。Redis 里没有,MySQL 里也没有,但每次都要扫一遍索引。
2.1 第一件套:布隆过滤器(Bloom Filter)
原理:用极小的内存判断"一个 key 是否一定不存在"。
- 添加元素时,用 k 个哈希函数映射到长度为 m 的 bit 数组,将对应位全部置为 1
- 查询时,同样计算 k 个哈希,如果任意一位为 0 → 100% 确定不存在 ;如果全为 1 → 可能存在(有误判率)
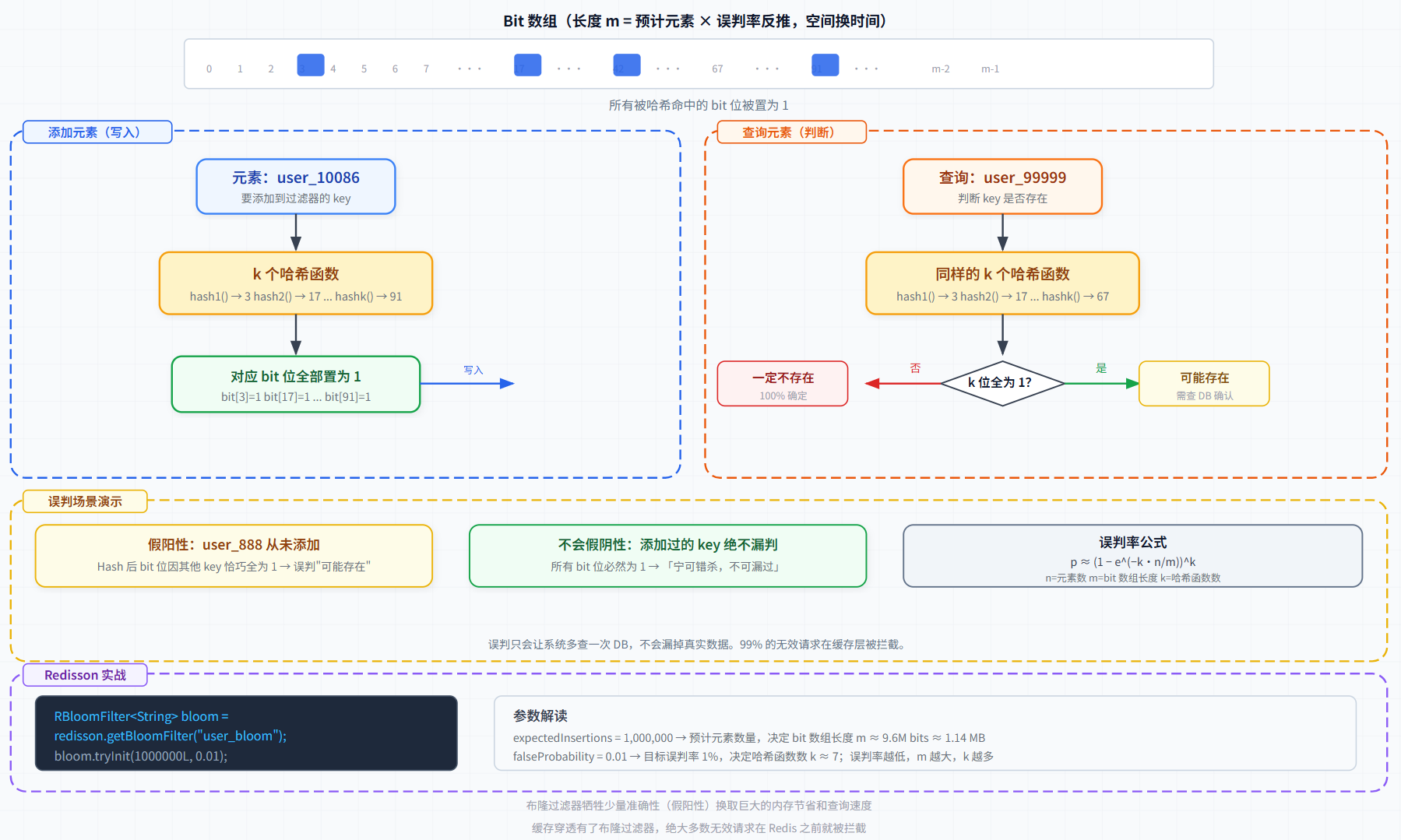
图2:添加元素(左)vs 查询元素(右)的完整流程,含误判场景演示与 Redisson 参数解读
Redisson 实战:
java
@Configuration
public class BloomConfig {
@Bean
public RBloomFilter<String> userBloomFilter(RedissonClient redisson) {
RBloomFilter<String> bloom = redisson.getBloomFilter("user_bloom");
// 预计100万用户,误判率1%
bloom.tryInit(1_000_000L, 0.01);
return bloom;
}
}
// 注册时添加到布隆过滤器
@Transactional
public void register(User user) {
userMapper.insert(user);
userBloomFilter.add("user:" + user.getId());
}
// 查询前先过布隆
public User getUser(Long userId) {
String key = "user:" + userId;
if (!userBloomFilter.contains(key)) {
return null; // 一定不存在,直接返回,不查 DB
}
// 可能存在,正常走缓存→DB 流程
User cached = (User) redisTemplate.opsForValue().get(key);
if (cached != null) return cached;
User dbUser = userMapper.selectById(userId);
if (dbUser != null) {
redisTemplate.opsForValue().set(key, dbUser, 30, TimeUnit.MINUTES);
}
return dbUser;
}核心参数推导:
误判率 p ≈ (1 - e^(-k·n/m))^k
n = 预期元素数量(100万)
m = bit 数组长度
k = 哈希函数数量
当 p = 0.01 时,Redisson 自动算出:
m ≈ 9,585,058 bits ≈ 1.14 MB
k ≈ 7 个哈希函数注意:布隆过滤器不能删除元素(删除需要计数型布隆,Redisson 不内置支持)。数据迁移或用户注销时,需要重建布隆过滤器。
2.2 第二件套:缓存空值
即使布隆过滤器判断"可能存在",查到 DB 后也可能真的不存在。此时缓存一个空值,防止短时间内的重复穿透:
java
if (dbUser == null) {
// 缓存空值,TTL 设短(1~5 分钟)
redisTemplate.opsForValue().set(key, null, 2, TimeUnit.MINUTES);
return null;
}为什么 TTL 要短? 因为"不存在"是暂时的------用户可能下一秒就注册了。TTL 过长会导致新注册用户长时间查不到。
2.3 第三件套:参数前置校验
在 Controller 层就拦截明显非法的请求:
java
@GetMapping("/user/{userId}")
public Result<User> getUser(@PathVariable Long userId) {
if (userId == null || userId <= 0) {
return Result.fail("非法用户ID");
}
// 继续后续逻辑
}简单、零成本,但很多团队忽略。
2.4 三件套组合拳
请求 → 参数校验(非法拦截) → 布隆过滤器(一定不存在拦截)
→ 缓存查询(命中返回) → DB查询(无数据缓存空值)三件套各司其职,穿透率可以从 100% 降到 1% 以下。
3. 缓存击穿:热点 key 的生死时速
问题本质 :一个热点 key(访问量极高)刚好过期,瞬间大量并发请求全部打到 DB。
穿透 vs 击穿的核心区别:穿透查的是不存在的数据,击穿查的是存在但缓存刚好过期的热点数据。
3.1 互斥锁方案(VibeLoop 首选)
关键思想:缓存 miss 时,不让所有线程都去查 DB,只有抢到分布式锁的线程才能查 DB 并回写缓存,没抢到的自旋等待。
java
public Post getPost(Long postId) {
String cacheKey = "post:" + postId;
String lockKey = "lock:post:" + postId;
Post post = (Post) redisTemplate.opsForValue().get(cacheKey);
if (post != null) return post;
// 抢锁,超时 10 秒
boolean locked = redisTemplate.opsForValue()
.setIfAbsent(lockKey, "1", 10, TimeUnit.SECONDS);
try {
if (locked) {
// 抢到锁,查 DB 并回写
post = postMapper.selectById(postId);
if (post != null) {
redisTemplate.opsForValue()
.set(cacheKey, post, 30 + ThreadLocalRandom.current().nextInt(10),
TimeUnit.MINUTES);
}
return post;
} else {
// 没抢到锁,自旋重试读缓存
TimeUnit.MILLISECONDS.sleep(50);
return getPost(postId); // 递归重试
}
} finally {
if (locked) {
redisTemplate.delete(lockKey);
}
}
}关键细节:
setIfAbsent即SET NX EX,加锁与设过期时间原子完成,防止死锁- 缓存 TTL 加了随机值
ThreadLocalRandom.current().nextInt(10),避免大量 key 同时过期(顺便防雪崩) - 锁的 value 应该用 UUID 标识持有者,避免 A 的锁被 B 误删。上例简化了,生产环境必须加上
3.2 逻辑过期方案
与互斥锁思路相反:缓存永不过期,但在 value 中携带一个逻辑过期时间戳。读取时检查时间戳,如果逻辑已过期,返回旧值(保证可用),同时异步开一个新线程去刷新缓存。
java
@Data
public class PostWithExpire {
private Post data;
private Long expireAt; // 逻辑过期时间戳(ms)
}
public Post getPostV2(Long postId) {
String key = "post:" + postId;
PostWithExpire wrapper = (PostWithExpire) redisTemplate.opsForValue().get(key);
if (wrapper == null) {
// 缓存没有(第一次),必须同步加载
return loadAndCache(postId);
}
if (wrapper.getExpireAt() > System.currentTimeMillis()) {
return wrapper.getData(); // 未过期,直接返回
}
// 逻辑已过期,先返回旧值,异步刷新
executor.execute(() -> {
String lockKey = "lock:refresh:post:" + postId;
if (redisTemplate.opsForValue().setIfAbsent(lockKey, "1", 5, TimeUnit.SECONDS)) {
try {
loadAndCache(postId);
} finally {
redisTemplate.delete(lockKey);
}
}
});
return wrapper.getData(); // 返回旧值,不阻塞用户
}3.3 两种方案对比
| 维度 | 互斥锁 | 逻辑过期 |
|---|---|---|
| 数据一致性 | 强,返回最新数据 | 弱,可能返回旧数据 |
| 性能 | 有等待,部分请求阻塞 | 无等待,全部非阻塞返回 |
| 实现复杂度 | 低 | 中(需维护过期时间戳) |
| 适用场景 | 对一致性要求高的数据 | 对可用性要求高的数据 |
VibeLoop 选择:帖子内容用互斥锁(用户不能看到旧版本),帖子点赞数用逻辑过期(数字差几个无所谓)。
4. 缓存雪崩:多米诺骨牌效应
问题本质 :大量缓存 key 同时过期 ,或 Redis 集群宕机,导致所有请求直接打到 DB。
4.1 随机 TTL 打散过期时间
最简单有效的方案:给过期时间加随机抖动量。
java
// 基础 TTL 30 分钟,加上 0~10 分钟的随机值
int ttl = 30 * 60 + ThreadLocalRandom.current().nextInt(10 * 60);
redisTemplate.opsForValue().set(key, value, ttl, TimeUnit.SECONDS);这行代码的价值远超你的想象:把一条陡峭的过期线打散成一条平滑曲线,DB 压力均匀分布。
4.2 多级缓存降级
请求 → 本地缓存 (Caffeine) → Redis → DB当 Redis 不可用时,本地缓存还能撑一阵:
java
@Configuration
public class MultiLevelCacheConfig {
@Bean
public Cache<String, Post> localCache() {
return Caffeine.newBuilder()
.maximumSize(10000)
.expireAfterWrite(5, TimeUnit.MINUTES)
.build();
}
}
public Post getPostMultiLevel(Long postId) {
String key = "post:" + postId;
// L1: 本地缓存
Post local = localCache.getIfPresent(key);
if (local != null) return local;
try {
// L2: Redis
Post redisPost = (Post) redisTemplate.opsForValue().get(key);
if (redisPost != null) {
localCache.put(key, redisPost);
return redisPost;
}
} catch (Exception e) {
log.warn("Redis 不可用,降级到 DB", e);
}
// L3: DB
Post dbPost = postMapper.selectById(postId);
if (dbPost != null) {
localCache.put(key, dbPost);
}
return dbPost;
}4.3 限流熔断
在网关层或服务层加限流,给 DB 留出喘息空间:
java
// Sentinel / Resilience4j 限流
@SentinelResource(value = "getPost", fallback = "getPostFallback")
public Post getPost(Long postId) {
// ...正常逻辑
}
public Post getPostFallback(Long postId, Throwable e) {
// 返回降级数据:默认帖子或提示"服务繁忙"
return Post.builder().title("系统繁忙,请稍后重试").build();
}4.4 Redis 高可用
这是根本性方案,延后到第4期详细展开:主从复制 + 哨兵 + Cluster。
5. 八种淘汰策略选型矩阵
类比:冰箱食材管理 --- FIFO 是"先买先扔",LRU 是"最久没吃的清理掉",LFU 是"吃最少的断舍离"。
Redis 4.0 起提供 8 种淘汰策略:
| 策略 | 行为 | 适用场景 |
|---|---|---|
noeviction |
不淘汰,写满报错 | 绝对不能丢数据的场景(很少用) |
volatile-lru |
在设了 TTL 的 key 中淘汰最近最少使用 | VibeLoop 帖子缓存(默认推荐) |
allkeys-lru |
在所有 key 中淘汰最近最少使用 | 纯缓存场景,数据可从 DB 恢复 |
volatile-lfu |
在设了 TTL 的 key 中淘汰最不频繁使用 | 热点数据保护 |
allkeys-lfu |
在所有 key 中淘汰最不频繁使用 | 有明显冷热数据差异 |
volatile-random |
在设了 TTL 的 key 中随机淘汰 | 所有 key 价值均等 |
allkeys-random |
在所有 key 中随机淘汰 | 同上 |
volatile-ttl |
淘汰最近要过期的 key | 自然淘汰,减少业务影响 |
VibeLoop 选型决策
帖子缓存 → volatile-lru(有过期时间,按访问热度淘汰)
用户 Session → volatile-ttl(自然过期最合理)
计数器(点赞/浏览)→ noeviction(不能丢,单独实例)LRU vs LFU 源码层面区别
Redis 的 LRU 不是精确 LRU(需要维护链表,开销大),而是近似 LRU :随机采样 N 个 key,淘汰其中 idle 时间最长的那个。maxmemory-samples 控制采样数,默认 5。
LFU 在 24 位中拆分为两部分:高 16 位存 last-decrement-time,低 8 位存 logarithmic-counter。计数器不是简单 +1,而是对数增长:
counter = 1 / (1 - p) // p = 1/(counter * lfu_log_factor + 1)这使得 100 次访问和 10000 次访问的计数器差距远小于 100 倍,防止少数热点 key 永远不被淘汰。
6. 双写一致性:最难解的并发题
6.1 先删缓存还是先更新 DB?
这是面试中的经典陷阱题。推演一下:
方案 A:先删缓存,再更新 DB
T1: A 删缓存
T2: B 读缓存 miss → 查 DB 得到旧值 → 写缓存(旧值)
T3: A 更新 DB(新值)
结果:DB 是新值,缓存是旧值 → 不一致方案 B:先更新 DB,再删缓存
T1: 缓存刚好过期
T2: A 读缓存 miss → 查 DB 得到旧值
T3: B 更新 DB 为新值 → 删缓存
T4: A 写缓存(旧值)
结果:DB 是新值,缓存是旧值 → 不一致方案 B 的不一致窗口比方案 A 窄得多(需要在"缓存刚好过期"的极端巧合下才触发),所以先更新 DB 再删缓存是更好的基础方案。
6.2 延迟双删
在方案 A 的基础上加一次延迟删除来兜底:
1. 删除缓存
2. 更新 DB
3. 休眠 N 毫秒(比如 500ms)
4. 再次删除缓存
java
public void updatePostWithDoubleDelete(Long postId, PostDTO dto) {
stringRedisTemplate.delete("post:" + postId); // 1. 删缓存
postMapper.updateById(postId, dto); // 2. 更新 DB
try {
TimeUnit.MILLISECONDS.sleep(500); // 3. 等待
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
stringRedisTemplate.delete("post:" + postId); // 4. 再删缓存
}延迟多久? 大于"读请求查 DB + 写缓存"的时间。这个值需要压测确定,通常 200ms~1s。
6.3 终极方案:Canal + Binlog
延迟双删依赖 sleep,不优雅且有风险。大厂方案:订阅 MySQL Binlog,异步删除/更新缓存。
MySQL 写入 → Binlog → Canal 解析 → 推送变更事件 → 服务消费 → 删除缓存
java
@CanalEventListener
public class PostCacheListener {
@ListenPoint(destination = "vibeloop", schema = "vibeloop", table = "posts")
public void onPostUpdate(CanalEntry.Entry entry) {
// 从 binlog 解析出更新的 postId
Long postId = parsePostId(entry);
stringRedisTemplate.delete("post:" + postId);
}
}优势:即使业务代码忘记删缓存,Canal 也能兜底;适合最终一致性场景。
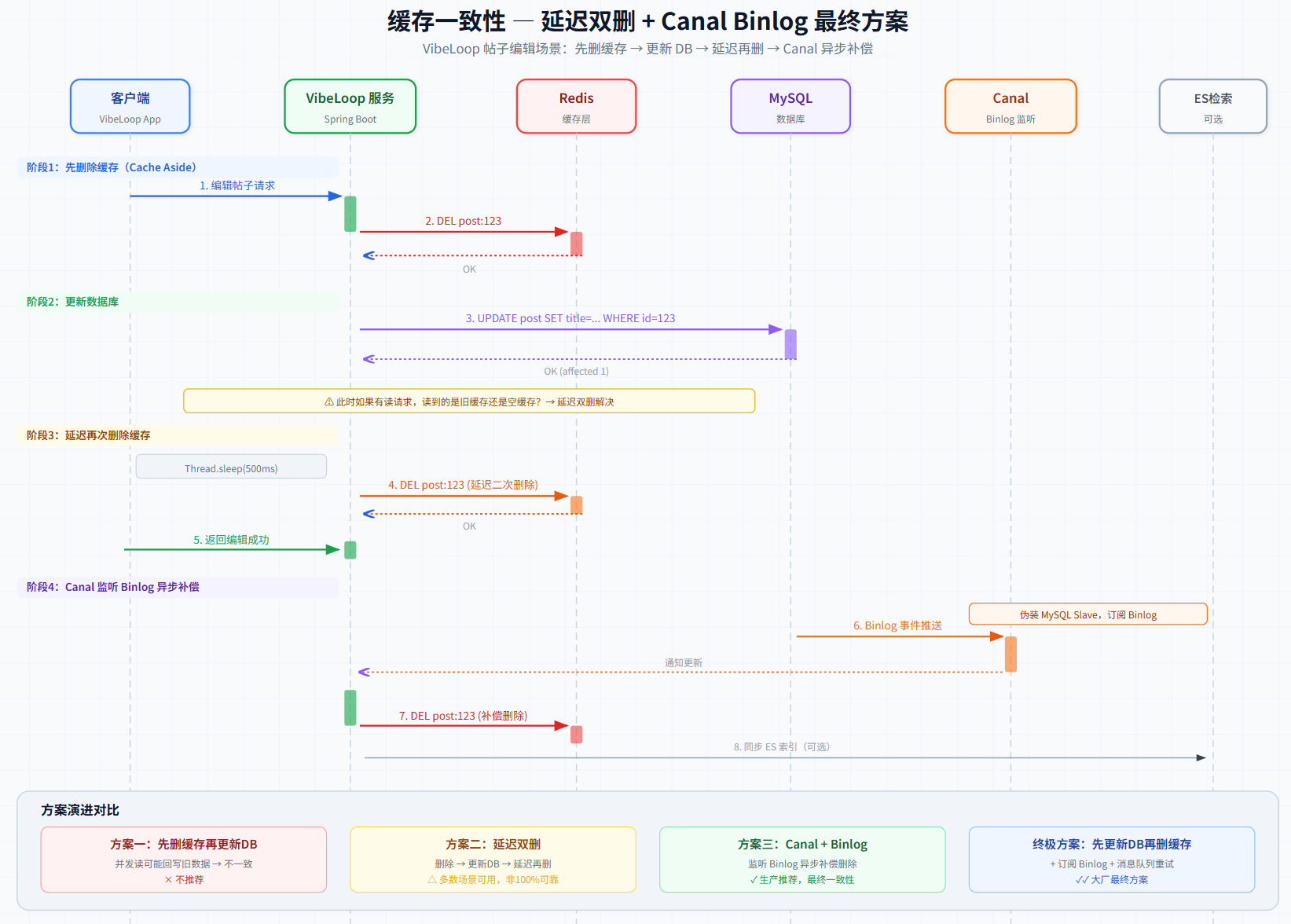
图3:延迟双删 + Canal Binlog 完整时序,底部含四种方案演进对比
6.4 一致性方案金字塔
最强一致性 ── 分布式事务(Seata AT/TCC)
↑
Canal + Binlog + MQ 重试 ← VibeLoop 推荐
↑
延迟双删(99% 场景可用)
↑
先更新 DB 再删缓存(基础方案)7. Spring Cache 注解踩坑实录
7.1 @Cacheable 的 key 生成陷阱
java
// ❌ 错误:默认 key 是所有参数拼接,遇到复杂对象可能抛异常
@Cacheable(value = "post")
public Post getPost(Long postId) { ... }
// ✅ 正确:显式指定 SpEL key
@Cacheable(value = "post", key = "#postId")
public Post getPost(Long postId) { ... }7.2 @CachePut vs @Cacheable 的区别
java
@CachePut(value = "post", key = "#result.id") // 每次都执行方法,强制更新缓存
public Post savePost(Post post) { ... }
@Cacheable(value = "post", key = "#postId") // 有缓存就跳过方法,不执行
public Post getPost(Long postId) { ... }很多人以为 @CachePut 和 @Cacheable 一样,结果缓存一直不生效。记牢:@CachePut = 执行方法 + 更新缓存;@Cacheable = 检查缓存 + 决定是否执行方法。
7.3 @CacheEvict 的 beforeInvocation
java
// 默认:方法执行后删缓存。方法抛异常时不删
@CacheEvict(value = "post", key = "#postId")
public void deletePost(Long postId) { ... }
// beforeInvocation=true:方法执行前删缓存。即使方法抛异常也删
@CacheEvict(value = "post", key = "#postId", beforeInvocation = true)
public void riskyDeletePost(Long postId) { ... }默认行为更安全(不会在操作失败时误删),但如果你需要最快释放缓存空间,可以开 beforeInvocation。
7.4 条件缓存
java
// 结果不为 null 时才缓存
@Cacheable(value = "post", key = "#postId", unless = "#result == null")
// 参数满足条件时才缓存
@Cacheable(value = "post", key = "#postId", condition = "#postId > 1000")7.5 多级嵌套的缓存穿透问题
java
@Cacheable(value = "post", key = "#postId", cacheManager = "redisCacheManager")
@Cacheable(value = "post", key = "#postId", cacheManager = "caffeineCacheManager")
public Post getPost(Long postId) { ... }Spring Cache 默认按注解顺序执行:第一个 @Cacheable 命中就返回,不会走到第二个!多级缓存必须自己实现,不能用嵌套注解。
7.6 序列化坑
默认 JDK 序列化要求类实现 Serializable,忘记实现会导致运行时 NotSerializableException。生产环境务必换成 Jackson/Protobuf:
java
@Bean
public RedisCacheManager cacheManager(RedisConnectionFactory factory) {
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig()
.serializeValuesWith(
RedisSerializationContext.SerializationPair
.fromSerializer(new GenericJackson2JsonRedisSerializer())
);
return RedisCacheManager.builder(factory).cacheDefaults(config).build();
}8. 面试八连问 + 详解
Q1:缓存穿透和缓存击穿有什么区别?
穿透查的是不存在 的数据,击穿查的是存在但刚好过期的热点数据。穿透用布隆过滤器 + 空值缓存,击穿用互斥锁 + 逻辑过期。
Q2:布隆过滤器的误判是怎么回事?能彻底消除吗?
布隆过滤器只会有假阳性(说不存在的一定不存在,说可能存在的可能不存在),不会有假阴性。误判率取决于 m/n 比值和 k。不能彻底消除,但可以降到任意低(代价是更多内存)。
Q3:延迟双删的延迟时间怎么定?
大于"读请求查 DB + 写缓存"的时间。通过压测确定,通常在 200ms~1s。如果追求强一致,应该上 Canal + Binlog。
Q4:Redis 的 LRU 是真的 LRU 吗?
不是。Redis 用的是近似 LRU,随机采样 N 个 key(默认 5 个),淘汰其中 idle 时间最长的。精确 LRU 需要维护双向链表,内存开销大。近似 LRU 在采样数足够大时效果接近精确 LRU。
Q5:先更新 DB 再删缓存,万一删缓存失败了怎么办?
引入重试机制。可以把"删除缓存"这个操作发到消息队列(RocketMQ/Kafka),消费失败时自动重试。或者用 Canal 监听 Binlog 做异步补偿删除。
Q6:为什么 Redis 单线程处理命令,还能扛住高并发?
Redis 6.0 之前命令执行是单线程的(网络 IO 在 6.0 后引入多线程),但:
- 纯内存操作,10 万 QPS 的单条命令只需微秒级
- epoll IO 多路复用,一个线程管理数万个连接
- 无锁竞争,没有线程切换开销
真正的瓶颈通常是网络带宽,不是 CPU。
Q7:Redis 挂了怎么办?数据全丢?
分两层:高可用 和持久化。高可用靠主从复制 + 哨兵自动故障转移(第 4 期详细讲)。持久化靠 RDB 快照 + AOF 日志,即使宕机也能恢复到最近的状态。
Q8:缓存的 TTL 设多长合适?
没有标准答案。考虑因素:
- 数据变更频率:频繁变更的数据 TTL 要短
- 业务容忍度:能接受多长时间的旧数据
- 内存容量:TTL 越长,内存占用越大
VibeLoop 实践:帖子详情 30min,用户资料 1h,配置数据 24h,热点数据不设 TTL(用逻辑过期)。
9. 必背速查表
三大问题速查
| 问题 | 场景 | 根因 | 解法 | 关键词 |
|---|---|---|---|---|
| 穿透 | 查不存在的数据 | 缓存永远 miss | 布隆 + 空值缓存 + 参数校验 | Bloom Filter |
| 击穿 | 热点 key 过期 | 并发回源 DB | 互斥锁 / 逻辑过期 | SET NX EX |
| 雪崩 | 大量 key 同时过期 | 缓存大面积失效 | 随机 TTL + 多级缓存 + 限流 | 抖动过期 |
淘汰策略速查
| 策略 | 淘汰范围 | 淘汰依据 | VibeLoop 用途 |
|---|---|---|---|
| volatile-lru | 有过期时间的 key | 最近最少使用 | 帖子缓存(推荐) |
| allkeys-lru | 所有 key | 最近最少使用 | 纯缓存场景 |
| volatile-lfu | 有过期时间的 key | 最不频繁使用 | 热点保护 |
| volatile-ttl | 有过期时间的 key | 最近要过期 | Session |
| noeviction | 无 | 不淘汰 | 计数器专用实例 |
一致性方案速查
| 方案 | 一致性 | 复杂度 | 可靠性 | 推荐度 |
|---|---|---|---|---|
| 先更新 DB 再删缓存 | 弱 | 低 | 低(删失败则不一致) | ★★ |
| 延迟双删 | 中 | 低 | 中 | ★★★ |
| Canal + Binlog | 最终一致 | 高 | 高 | ★★★★ |
| MQ 重试删除 | 最终一致 | 中 | 高 | ★★★★★ |
配置速查
properties
# Redis 淘汰策略
maxmemory-policy volatile-lru
maxmemory-samples 10
# Spring Cache key 规范
@Cacheable(value = "post", key = "#postId", unless = "#result == null")
# 随机 TTL 防雪崩
int ttl = 30 * 60 + ThreadLocalRandom.current().nextInt(10 * 60);下期预告 --- 第3期「分布式锁从青铜到王者」:从 setnx 的三个致命漏洞出发,逐步演进到 Lua 原子释放 → WatchDog 自动续期 → Redlock 多数派原理,含 Redisson 源码走读。VibeLoop 帖子编辑锁、定时任务 Leader 选举、用户注册唯一性校验三大实战场景。