最近在学习AI大模型应用开发,一些学习记录会以博客的形式记录在这里
什么是大模型
现在我们说的大模型,一般指定都是LLM,全称是Large Language Model,也就是大语言模型。比如我们常用的ChatGPT、DeepSeek、通义千问等等,都是大语言模型。
所谓大语言模型,其实就是用于做和自然语言相关任务的深度学习模型,它是基于海量文本数据训练出来的,能够理解和生成人类的自然语言。
大模型,和以前的模型相比,主要的差异就在于大,所以在大模型出来之后,以前的一些专业模型也被叫做小模型,比如原来的搜索、广告、营销等模型,最容易理解的就是OCR模型,可以说他们是专业模型,也可以说他们是小模型。
大模型的大,体现在几个方面:
参数量大
这是"大"最直接、最核心的含义。模型的"参数"可以理解为模型在训练过程中学到的"知识"或"规则"的内部表示。参数越多,模型理论上能存储和表达的信息就越复杂、越精细。我们常见的一些模型会有xxB的描述,比如Qwen3-72B、LLaMA2-13B,这里的72B指的就是参数量有72Billion,即720亿。
训练数据量大
另外,大模型的大还体现在训练数据量大上面。 大模型需要海量、多样化的文本和代码数据进行训练。这些数据通常来自互联网上的公开网页、书籍、文章、代码仓库、对话记录等。训练数据集通常达到TB甚至PB级别,涵盖了人类知识的广泛领域和多种语言。例如,训练GPT-3的数据集WebText2就包含了数百GB的文本。
如此庞大的数据量是为了让模型学习到语言的统计规律、世界知识、常识、推理模式以及不同任务的通用表示。
随着现在模型越来越大,需要的训练数据也越来越多,已经有研究表明,2026年后可能就没有高质量的数据可以用来训练了。
那在这种情况下怎么办?一个越来越重要的方向,是让模型自己来"造数据"。所谓合成数据,本质上就是由模型生成的文本、代码、问答或推理过程,再拿这些结果反过来作为训练数据使用。通过这种方式,模型可以不断扩充训练样本规模,强化推理能力和任务泛化能力,而不再完全依赖互联网上有限的高质量人工数据。这也意味着,大模型后续的进化重点,正在从"有没有更多数据",转向"如何更高效地利用和生成数据"。
算力需求量大
大模型兴起之后,不炒股的人最明显的感受就是显卡贵了,炒股的人最明显的感受就是英伟达股价涨了。
这背后其实是因为训练一个大模型需要极其强大的计算资源,通常需要成千上万个高性能GPU(如NVIDIA A100/H100)或TPU组成的集群,运行数周甚至数月时间。
所以,做模型训练成本是非常高的。
大模型工作原理
大模型的本质
LLM 最核心、最基础的任务其实很简单:给你一串文字(上下文),它要猜出下一个最可能出现的词是什么?
例子: 输入 "我是个好",LLM 的任务就是猜下一个词,比如 "人"、"东西"、"家伙"、"男人" 等等,并给出每个词出现的可能性(概率)。
它是怎么学会"猜词"的?------ 海量阅读 + 疯狂练习
-
海量阅读(数据)
想象 LLM 在训练时,吞下了整个互联网的文本:书籍、文章、网页、代码、对话记录... 天文数字级别的文字量(TB 甚至 PB 级别)。
它不是在"理解"这些内容,而是在疯狂地寻找词语之间的搭配模式和统计规律。
-
疯狂练习(训练):
训练方法的核心:遮住一部分,让它猜! 就像我们小时候做"完形填空"。
具体操作:
从海量文本中随机截取一段句子,比如 "人工智能正在改变世界"。
遮住其中一个词,比如遮住 "改变",变成 "人工智能正在 MASK 世界"。
让模型猜被遮住的词是什么。它一开始肯定是瞎猜。
揭晓答案("改变"),然后调整模型内部的参数和权重。猜错了就调一点,猜对了也微调让它下次更可能猜对。
重复亿万次: 这个过程在超级计算机上,用海量的句子,对模型内部数万亿个"旋钮"进行微调,重复进行无数次(数天甚至数月)。模型逐渐学会了在特定上下文下,哪些词更常一起出现。
当训练好的 LLM 被要求写文章、聊天或翻译时,它其实是在反复玩"猜下一个词"的游戏:
- 你给提示: 你输入一句话或问题(提示词/Prompt),比如 "写一首关于春天的诗"。
- 模型启动: 模型把这个提示词作为初始的"上下文"。
- 猜第一个词: 模型根据这个上下文,计算所有可能的下一个词("春天"、"微风"、"万物"...)及其概率。
- 选择并添加: 模型不是永远选概率最高的词(那样会太死板),而是按概率随机选一个(可以用temperature参数控制随机性)。比如它选了"春天"。
- 更新上下文: 现在上下文变成了 "写一首关于春天的诗 春天"。
- 猜下一个词: 模型基于新的上下文 "写一首关于春天的诗 春天",再猜下一个词("的"、"里"、"天"...)。假设它选了"的"。
- 循环往复: 上下文变成 "写一首关于春天的诗 春天的",再猜下一个词... 如此循环,直到生成完整的句子或达到长度限制。
- 结果: 最终可能生成:"写一首关于春天的诗 春天的脚步轻轻走来,唤醒了沉睡的大地..."
但是,猜下一个词不是只看前一个词!需要理解整个句子的上下文和词之间的关系。
比如:"苹果很好吃" vs "苹果发布了新手机"。同样是"苹果",下一个词完全不同。而Transformer 的自注意力机制能分辨出第一个"苹果"和"好吃"关系紧密(水果),第二个"苹果"和"发布"、"手机"关系紧密(公司)。
Transformer
2017年,Google的一篇论文《Attention Is All You Need》横空出世,被称为是大语言模型的开山之作,其中介绍了Transformer架构,奠定了大语言模型的基础。
GPT(Generative Pre-trained Transformer,生成式预训练的Transformer 模型)中的T就是Transformer
Transformer通过他的名字大概可以看出来,他最开始是为了提升翻译的质量的。在Transformer推出之前,这个领域在用的是循环神经网络(Recurrent Neural Network, RNN)。
RNN的设计思想就是一个词一个词的阅读并处理文字。这种方式,在读后面的字时,脑子里会努力记住前面读过的内容。读长文章时,很容易忘记开头说了啥("长期依赖"问题),而且只能按顺序读,不能跳着看(难以并行计算)。
就像大家背八股文一样,让你只能从头一道题一道题的背,那么就会不仅效率低,并且容易忘。
而Transformer的方案是,让你一眼扫过整段话,然后瞬间分析这段话里每个词和其他所有词之间的关系有多重要。它不按顺序读,而是同时关注所有词,找出谁和谁联系紧密。
相当于不是按顺序背题了,而是提前给你画好重点,找出来各个题目之间的关系。
自注意力机制
Transformer中有一个非常重要的思想,那就是自注意力机制(Self-Attention)。这里的Attention,就是论文中《Attention Is All You Need》的Attention,足以见得他的重要性及突破性。
通过Attention,我们把原来要关注全部信息,优化成只关注重点信息。就像人类看一张图片的时候,并不会立即关注全部细节,而是会把注意力放在某个焦点上。
Transformer流程
下面是一张完整的Transformer的流程图:
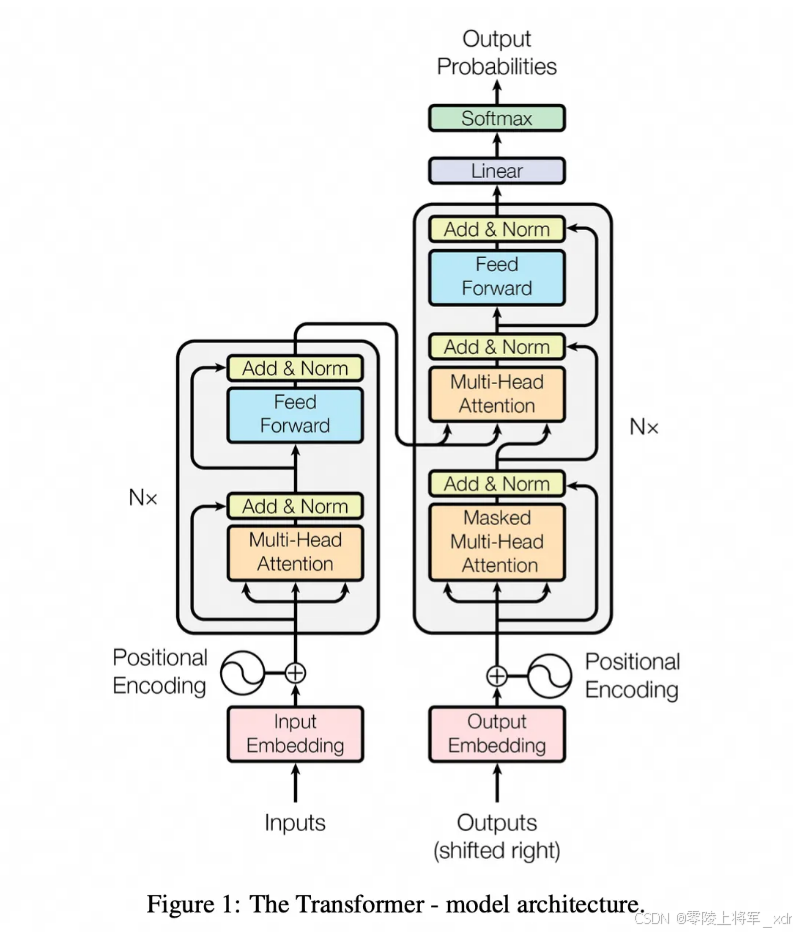
想象 Transformer 是一个多层的大楼,每一层都做类似的事情:
- 输入嵌入(Input Embedding): 把每个词(或字)转换成计算机能理解的数字向量(一串数字),就像给每个词发一个独特的"身份证号"。
- 位置编码(Positional Encoding): 因为 Transformer 是同时看所有词的,它不知道词的顺序(比如"猫追老鼠"和"老鼠追猫"意思不同)。所以需要额外添加一个表示词在句子中位置(是第1个、第2个...)的信息,就像给每个词加上"座位号"。
- 编码器 (Encoder):
- 核心:多头自注意力层(Multi-Head Attention): 这就是上面说的"找关系"游戏。它不止玩一次,而是同时玩好几次(多头),每次关注不同方面的关系(比如一次关注"谁在做什么",一次关注"描述了什么属性"),然后把结果合并起来。这样能更全面地理解词之间的关系。
- 前馈神经网络层(Feed Forward): 对每个词单独进行更复杂的处理(基于自注意力层得到的关系信息)。
- 残差连接 & 层归一化(Add & Norm): 技术细节,主要是让训练更稳定、更容易。想象成在计算过程中加了一些"稳定器"和"平衡器"。
- 这个编码器层会堆叠很多层(比如12层、24层),每一层都让模型对输入的理解更深入一点。
- 解码器(Decoder):
- 也包含多头自注意力层(但这里关注的是已经生成出来的部分)。
还有一个编码器-解码器注意力层:这是关键!解码器在生成下一个词时,会回过头去看编码器对输入的理解结果(比如源语言句子),并决定输入中的哪些部分对生成当前这个词最重要。这就像写作文时,根据题目要求(编码器结果)来构思下一句。
同样有前馈神经网络层、残差连接、层归一化。
解码器也堆叠很多层。
- 也包含多头自注意力层(但这里关注的是已经生成出来的部分)。
- 输出: 最后,解码器会预测下一个最可能的词是什么,然后把这个词作为输入的一部分,继续预测下一个词,直到生成完整的输出(比如翻译后的句子)。
Transformer的优势
Transformer = 同时看所有词 + 疯狂计算词与词之间的关系(自注意力) + 多层深入理解。
- 并行计算能力强: 因为它同时处理所有词,不像 RNN 那样必须按顺序,所以计算速度快很多,特别适合用强大的 GPU 来训练。
- 处理长距离依赖无敌: 自注意力机制让模型能直接关注到句子中任意距离的两个词之间的关系,不管它们隔得多远。解决了 RNN 记不住开头的问题。
- 效果好: 在各种自然语言处理任务(翻译、问答、摘要、文本生成等)上,效果都大幅超越了之前的模型。
- 成为大模型基石: GPT 系列、BERT、T5 等几乎所有现代顶尖的 AI 语言模型,都是基于 Transformer 架构或其变体构建的。ChatGPT 的核心就是 Transformer 的解码器部分。
大模型应用开发常用的平台
ChatGPT、Claude、DeepSeek、通义千问、智普、Kimi
主流的大模型平台,相信大家都用过,都可以直接到他们的网站上面去使用这些模型。
HuggingFace
Hugging Face是一个非常重要的网站,他就像是AI界的GitHub,它是一个开源的社区和平台,集模型库、数据集、协作工具和社区于一体。
里面有很多开源的模型、数据集以及工具等等,都可以快速的获取和使用。
Ollama
Ollama 是一个轻量级、开源的本地大语言模型(LLM)服务框架,旨在帮助开发者和用户快速部署和运行自己的大语言模型。它支持多种主流模型(如 Llama、Qwen、ChatGLM 等),并提供简单易用的命令行工具和 API 接口,实现模型的快速启动、推理和交互。
它并不强依赖 GPU,而是可以基于 CPU 直接运行经过优化和量化的大模型,让个人开发者在普通硬件条件下,也能较低成本地完成本地推理和使用。
ModelScope
HuggingFace在国内存在无法访问,访问慢等问题,ModelScope是阿里巴巴达摩院推出的国内大模型社区,功能和huggingface差不多,上面也有很多开源模型和应用可供选择。
硅基流动
硅基流动,是一个AI模型能力提供商,可以理解为是个中介,他继承了很多模型,你可以通过硅基流动直接调用。
调用的方式可以是通过API调用,所以它的好处是可以帮你快速地接入第三方模型,并且可以做到无缝切换。
FastGPT&Dify&RAGFlow&n8n
都是比较知名的RAG/LLM 工作流平台,可以在上面做RAG检索、搭建workflow等,其实功能大差不差,网上有很多资料对比他们的区别,但是因为现在AI发展很迅猛,很多工具之间也在互相"对齐",所以最后看下来差别真不太大。
目前有的比较多的是dify和n8n,很多公司内部的工作流也都是基于dify搭建的。
n8n的话他的知识库能力相比dify是稍微弱一点的,他比较强的是流程编排。
coze
Coze是字节推出的一个智能体搭建平台,但是他的受众并不是开发者,更适合普通用户来用,可以用coze快速的做一个小应用。
他的低代码做的很好,但是他不是开源的,是字节的商业化产品。
(最近coze3.0发布了,支持Openclaw、Claude Code一键接入,感兴趣可以去试试)
大模型的局限性以及常见解决方案
LLM的擅长方向
- 文本理解:能阅读、总结、分析文章,如 阅读理解、问答系统。
- 文本生成:能撰写高质量 文章、小说、新闻、代码、法律合同 等。
- 机器翻译:可以翻译多种语言,质量接近专业翻译水平(如 DeepL、Google Translate)。
- 信息提取:能从文档中提取关键信息,如 法律、医学、财务报告分析。
- 代码生成:自动编写 Python、JavaScript、C++ 代码,辅助开发者(如 GitHub Copilot、Cursor、Claude Code、Qoder、TRAE)。
- 代码调试:帮助找出代码中的 Bug、优化代码性能。
- 代码解释:能解释复杂代码的逻辑,帮助学习和维护遗留代码。
- 广泛知识问答:大模型掌握 百科知识、历史、科技、医学、经济等 领域的信息。
- 图像识别 & 生成(如 DALL·E、Stable Diffusion、NanoBanana):生成艺术作品、设计海报。
- 语音识别 & 语音合成(如 Whisper、VALL-E):实现 语音转文字(ASR)、AI 语音播报。
- 视频生成(如 Sora):基于文本输入,生成高质量视频。
- 总结长文档(如会议纪要、论文总结)。
- 从非结构化文本中提取信息(如将文章转换成 表格、JSON 数据)。
上面这些,就是大模型比较擅长的一些领域和方向。但是并不代表着在这些方向中他就是完美的了,这些方向的应用上,都存在这个一些共性问题。
LLM的局限性
幻觉问题
关于大模型的幻觉问题,相信大家或多或少也都知道一些,比如举个例子:"我让deepseek帮帮我写一篇使用农业来修仙的论文。"
大家都知道,这俩东西完全不沾边,但是LLM却能一本正经的给你写很多东西:

你看他写的,好像说的很有道理一样,这就是所谓的幻觉问题,因为在前面介绍LLM的原理的时候提过了,LLM的本质是根据上一个词预测下一个词。
它本身是不知道这件事情对不对的,他只能做词的预测,哪个字的概率高,他就输出哪个字。
不擅长精确计算
比如前段时间非常火的,我们问大模型3.9和3.11哪个大?很多大模型都会回答错误。
但是这只是个小学生的问题,如果是人类看这个问题是非常简单的,但是大模型却非常容易出错。
因为还是前面讲过的,大模型本质上还是基于他的海量训练,来预测下一个输出的文字。它本身不具备数据计算的能力。所以涉及到一些数值计算,大模型本身是非常不擅长的。
缺少实时性
我们都知道,模型都是有滞后性的,当一个模型训练好了之后,对外推出的时候,一般都过了很久了。比如我在2026年6月份,问deepseek他的数据训练时间,他回答的时候2025年5月。

知识的局限性
大模型确实用了海量数据来做训练,但是,除了实时性的问题,他还有个问题,那就是他的训练的数据集是有限的。
有限不是说他少,他肯定不少,因为前面我们说过,公开的数据都开被用完了,咋还能少呢,但是这种是公开的数据。而网络上还有很多未公开的数据呀。
比如你们公司的内部的规章制度、你们内部的产品文档、你们内部的代码等等,这些资料都不是在公网上面的,那么这些数据大模型就是没有见过的。
所以,大模型是不知道一些私有数据的。