文章目录
- 引言
- [一、SimpleKV (Demo) vs Redis:](#一、SimpleKV (Demo) vs Redis:)
- [二、整数数组和压缩列表:Redis "省内存"的秘密武器](#二、整数数组和压缩列表:Redis "省内存"的秘密武器)
- [三、Redis 单线程模型的性能瓶颈在哪里?](#三、Redis 单线程模型的性能瓶颈在哪里?)
- [四、AOF 重写的两个隐藏阻塞风险](#四、AOF 重写的两个隐藏阻塞风险)
-
- [风险一:fork 操作本身的阻塞](#风险一:fork 操作本身的阻塞)
- 风险二:写时复制导致的内存分配阻塞
- [五、高写入场景下 RDB 持久化的内存与 CPU 风险](#五、高写入场景下 RDB 持久化的内存与 CPU 风险)
-
- 内存不足风险
- [CPU 竞争风险](#CPU 竞争风险)
- [六、主从复制为什么用 RDB 而不用 AOF?](#六、主从复制为什么用 RDB 而不用 AOF?)
- 七、主从切换时客户端怎么办?
- [八、哨兵集群:quorum 和多数派投票的微妙关系](#八、哨兵集群:quorum 和多数派投票的微妙关系)
- [九、Redis Cluster 为什么用哈希槽而不用映射表?](#九、Redis Cluster 为什么用哈希槽而不用映射表?)
- 深度探讨:四个高频疑难问题
-
- [1. Rehash 的触发时机与渐进式执行](#1. Rehash 的触发时机与渐进式执行)
- [2. 主线程、子进程和后台线程](#2. 主线程、子进程和后台线程)
- [3. 写时复制的底层实现](#3. 写时复制的底层实现)
- [4. replication buffer 与 repl_backlog_buffer](#4. replication buffer 与 repl_backlog_buffer)
- 总结
引言
在学习 Redis 的过程中,很多开发者都会遇到一些共性的困惑: 整数数组和压缩列表为什么能省内存?AOF 重写时会不会阻塞主线程?RDB 持久化在高写入场景下有什么隐患?这些问题看似零散,实则串起了 Redis 从底层数据结构到高可用架构的核心知识脉络。
本文围绕 Redis 核心技术中最具代表性的九个问题展开深度解析,并在最后探讨 rehash 机制、写时复制原理、主线程与子进程的关系等高频疑难点,帮助你建立起对 Redis 更加系统和深入的理解。
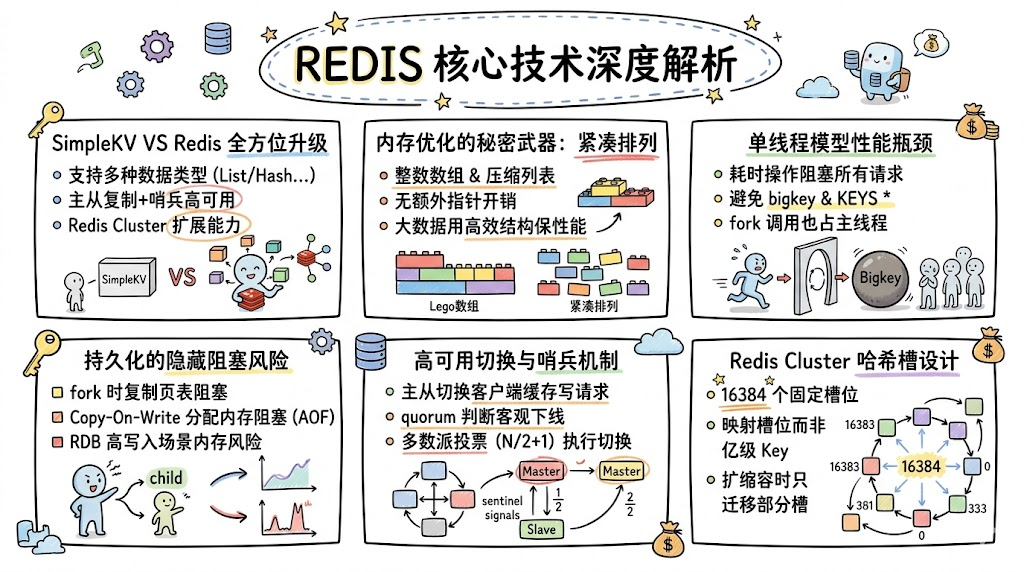
一、SimpleKV (Demo) vs Redis:
很多人在初学 Redis 时,会先接触到一个简化版的键值存储模型------SimpleKV。它能完成基本的 PUT/GET/DELETE 操作,但距离生产级的 Redis,差距是全方位的。
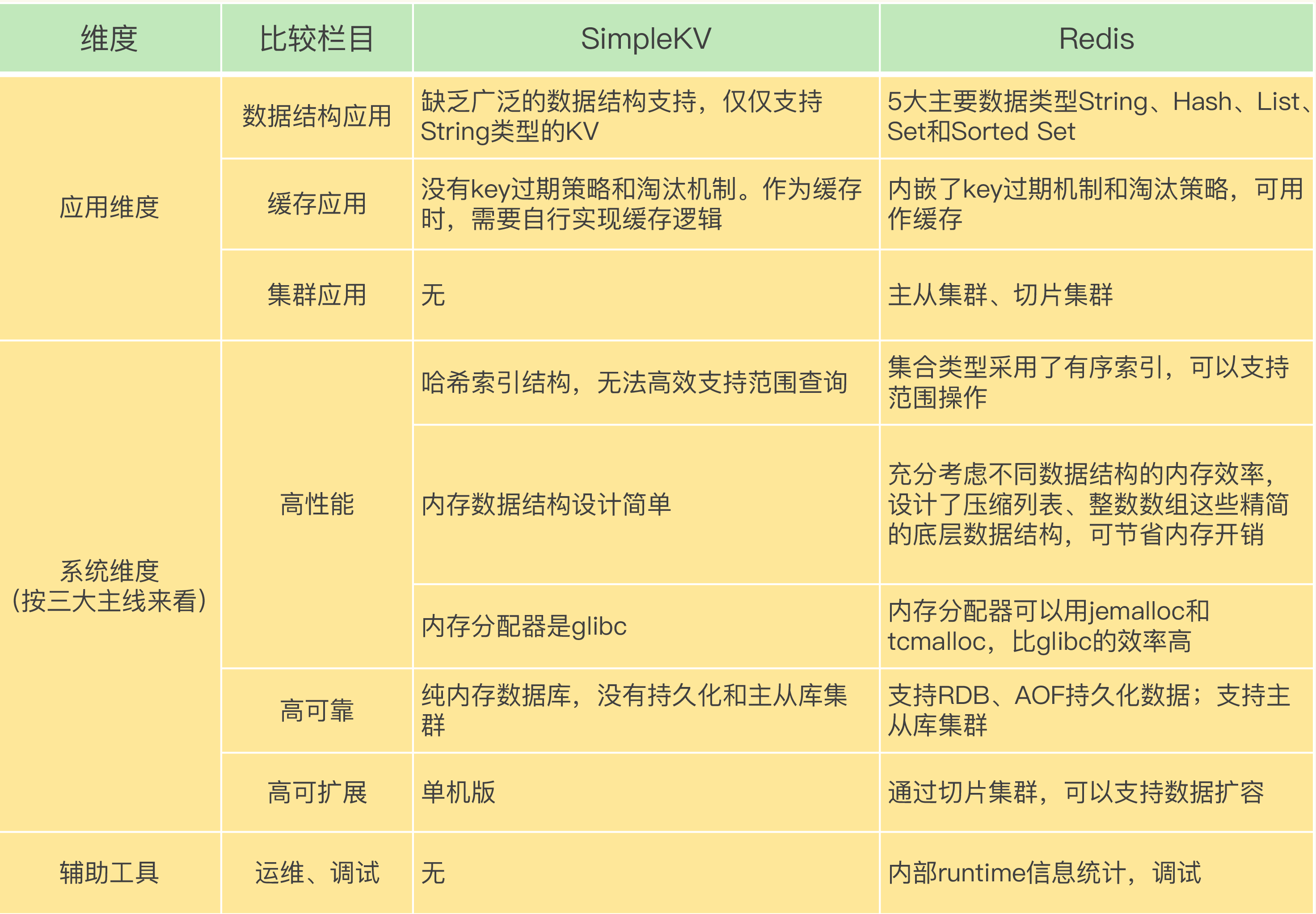
我们可以从"两大维度、三大主线"来做对比分析:
数据结构维度:
- SimpleKV 只支持简单的键值映射,而 Redis 提供了 String、List、Hash、Set、Sorted Set、Stream 等丰富的数据类型
- Redis 的底层实现还包含了 SkipList、压缩列表、整数数组等经过精心优化的数据结构,在内存效率和查询性能之间取得了极佳的平衡
系统架构维度:
- 高可用:SimpleKV 没有主从复制、哨兵机制,单点故障就意味着服务中断;Redis 通过主从复制 + 哨兵集群实现了自动故障转移
- 横向扩展:SimpleKV 无法分片,数据量受限于单机内存;Redis Cluster 通过哈希槽机制,支持数据在多个实例间的自动分布
- 内存管理:SimpleKV 没有内存淘汰策略,内存用满后只能报错;Redis 提供了 LRU、LFU 等多种淘汰算法,还通过压缩型数据结构提升内存利用率
功能与运维维度:
- 缺乏过期机制、事务支持、Lua 脚本能力
- 没有统计模块、慢查询日志、通知机制等运维辅助工具
- 不具备数据持久化能力(RDB/AOF)
简而言之,SimpleKV 是一个"能用"的键值存储,而 Redis 是一个"好用且可靠"的生产级数据库。从 SimpleKV 到 Redis 的距离,就是从玩具到工业级产品的距离。
二、整数数组和压缩列表:Redis "省内存"的秘密武器
Redis 在底层数据结构的选择上,始终在性能 和内存效率之间做权衡。整数数组(intset)和压缩列表(ziplist)就是"省"这一设计哲学的典型体现。
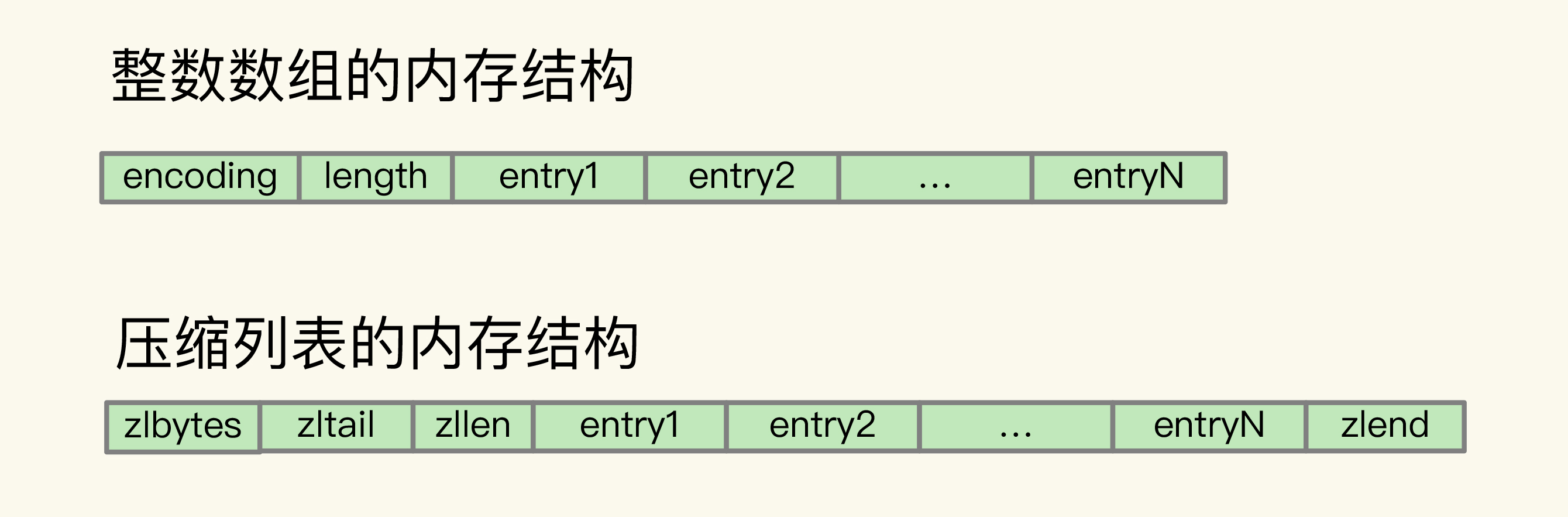
这两种数据结构有一个共同特点:在内存中分配一块地址连续的空间,元素挨个紧凑排列。
java
整数数组:| encoding | length | elem1 | elem2 | elem3 | ...
压缩列表:| zlbytes | zltail | zllen | entry1 | entry2 | ... | zlend |与链表、哈希表等结构相比,它们的优势在于:
- 无额外指针开销:链表中每个节点都需要前驱/后继指针(64 位系统上每个指针占 8 字节),而紧凑排列的结构完全不需要这些指针
- 缓存友好:连续内存布局对 CPU 缓存更加友好,顺序访问时 cache hit rate 更高
- 内存分配开销小:一次分配一整块空间,而非为每个元素单独申请内存
当然,这种设计也有代价------插入和删除操作的时间复杂度为 O(N),因为需要移动后续元素。所以 Redis 只在数据量较小时使用这些结构,当元素数量或大小超过阈值后,会自动转换为哈希表、跳表等更适合大规模数据的结构。
这正是 Redis 设计哲学的精髓:小数据用紧凑结构省内存,大数据用高效结构保性能。
三、Redis 单线程模型的性能瓶颈在哪里?
Redis 的核心网络 IO (6.x版本之前)和命令执行采用单线程模型,这意味着任何耗时操作都会成为性能瓶颈,因为它会阻塞整个事件循环,影响所有客户端的请求处理。
常见的性能瓶颈包括:
- bigkey 操作 :对包含大量元素的集合类型执行
DEL、HGETALL、SMEMBERS等操作,会长时间占用主线程 - 全量返回 :一次性返回大量数据(如
KEYS *、LRANGE 0 -1),网络传输和序列化都需要时间 - 复杂度高的命令 :如
SORT、SUNION等需要大量计算的命令 - 持久化相关的 fork 操作 :虽然 RDB 生成和 AOF 重写本身由子进程完成,但
fork系统调用是在主线程中执行的
理解这一点对于 Redis 的生产使用至关重要:不是 Redis 慢,而是你给它的某个操作太重了。
四、AOF 重写的两个隐藏阻塞风险
AOF 重写看起来是由后台子进程完成的,主线程不受影响------但事实并非如此简单。这里有两个容易被忽略的阻塞风险。
风险一:fork 操作本身的阻塞
Redis 主线程通过 fork 创建 bgrewriteaof 子进程时,操作系统内核需要完成以下工作:
- 创建子进程的进程控制块(PCB)
- 复制主线程的页表
这两步都在内核态执行,主线程会被阻塞直到 fork 完成。关键在于,页表的大小与 Redis 实例的内存使用量成正比------如果实例内存达到数十 GB,页表会非常大,fork 的耗时可能达到秒级。
风险二:写时复制导致的内存分配阻塞
fork 之后,子进程和主线程共享物理内存页。当主线程执行写操作时,操作系统会触发写时复制(Copy-On-Write),为修改的数据分配新的物理内存页。
如果写操作涉及的是 bigkey(例如一个包含百万元素的 Hash),主线程需要申请较大的连续内存空间。操作系统在分配大块内存时,需要查找合适的空闲区域并获取相关锁,这个过程可能造成主线程阻塞。
补充:为什么 AOF 重写不直接共用原来的 AOF 文件?
如果主线程和 bgrewriteaof 子进程同时写同一个 AOF 文件,它们会竞争文件系统的锁,直接影响主线程的写入性能。所以 Redis 选择让子进程写入一个新的 AOF 文件,完成后再进行原子替换。
五、高写入场景下 RDB 持久化的内存与 CPU 风险
考虑一个真实的场景:2 核 CPU、4GB 内存的云主机,Redis 数据量约 2GB,写读比例 8:2。在这种条件下使用 RDB 持久化,风险是什么?
内存不足风险
Redis 执行 bgsave 时,fork 出子进程进行 RDB 写入。由于写时复制机制的存在,主线程每执行一次写操作,都需要为被修改的数据分配新的物理内存。
在 8:2 的写读比例下,持久化期间大约 80% 的数据会被修改,写时复制需要额外分配约 1.6GB 内存。加上原来的 2GB 数据,系统内存使用量将接近 3.6GB------在 4GB 内存的机器上已经接近极限。
如果此时还有新的 key 写入:
- 开启了 Swap:部分数据会被换到磁盘,访问这些数据时性能急剧下降
- 未开启 Swap:直接触发 OOM(Out Of Memory),Redis 进程可能被系统 kill
CPU 竞争风险
bgsave 子进程需要 CPU 来完成 RDB 文件的序列化和写入,主线程需要 CPU 来处理客户端请求,如果还启用了后台线程(异步删除等),多个执行单元都在争夺仅有的 2 个 CPU 核心,主线程的请求处理速度必然受到影响。
实践建议:对于高写入场景,应当为 Redis 实例预留足够的内存余量(建议数据量不超过物理内存的 50%),并确保有足够的 CPU 核心。
六、主从复制为什么用 RDB 而不用 AOF?
Redis 主从库之间进行全量复制时,选择 RDB 而非 AOF 作为数据传输格式,原因有二:
- IO 效率更高:RDB 是紧凑的二进制格式,文件体积远小于 AOF 的文本格式。无论是写入磁盘还是网络传输,二进制格式的 IO 效率都显著优于文本格式
- 恢复速度更快:从库加载 RDB 时,直接将二进制数据映射到内存数据结构;而加载 AOF 则需要逐条解析和执行命令,速度慢得多
简单来说,RDB 在"传得快"和"恢复快"这两个关键指标上都优于 AOF,这对于需要尽快完成同步的主从复制场景尤为重要。
七、主从切换时客户端怎么办?
在采用读写分离的主从集群中,主库故障后:
- 读请求:仍然可以发送给从库处理,服务不中断
- 写请求:无法执行,因为从库默认是只读的
要让应用程序尽可能"无感知"地度过主从切换过程,需要客户端和哨兵的配合:
- 客户端缓存写请求:在主库不可用期间,客户端将写请求暂存到本地缓冲区,给应用层返回确认。等新主库就位后,再将缓存的写请求重新发送
- 哨兵推送新主库信息:哨兵通过发布/订阅频道广播新主库的地址,客户端订阅该频道即可自动感知切换
- 客户端主动查询:客户端也可以主动向哨兵询问当前主库的信息,实现更灵活的连接管理
八、哨兵集群:quorum 和多数派投票的微妙关系
考虑一个具体场景:5 个哨兵实例,quorum 设为 2,运行过程中有 3 个哨兵故障,只剩 2 个存活。此时主库如果故障:
能否判定"客观下线"?------能。 因为判定客观下线只需要 quorum(2)个哨兵认为主库主观下线即可,而当前正好还有 2 个存活的哨兵。
能否执行主从切换?------不能。 因为执行主从切换需要获得半数以上哨兵的投票赞成(即至少 3 票),而当前只有 2 个哨兵存活,无法满足这个条件。
这个例子清晰地展示了 quorum 和多数派投票是两个独立的机制:
- quorum 控制"是否认定故障",阈值可以自行设定
- 多数派投票 控制"是否执行切换",阈值固定为 N/2 + 1
哨兵越多越好吗?
不一定。哨兵数量增加确实能降低误判率,但也带来代价:
- 判定下线和选举 Leader 时,需要收集更多的投票,等待时间更长
- 主从切换的总耗时增加,期间客户端的写请求会堆积
- 如果业务对响应时间有严格要求,切换时间过长可能导致超时告警
类似地,调大 down-after-milliseconds 虽然能减少因网络抖动导致的误判,但也会延迟对真实故障的发现------主库可能已经挂了很久,哨兵才姗姗来迟地判定故障。
最佳实践:通常部署 3 或 5 个哨兵实例,quorum 设置为 N/2 + 1,在误判率和切换速度之间取得平衡。
九、Redis Cluster 为什么用哈希槽而不用映射表?
一个直觉性的方案是:用一张表直接记录每个 key 对应哪个实例。为什么 Redis 不这样做?
原因在于规模和变更成本:
- 存储开销大:键值对的数量可能达到亿级,为每一个 key 维护映射关系需要巨大的额外存储空间
- 变更代价高:当集群扩缩容或数据重新分布时,需要更新大量映射记录。单线程更新太慢,多线程更新则涉及加锁开销
- 一致性难保证:多个节点之间同步这张巨大的映射表,本身就是一个分布式一致性难题
而哈希槽方案巧妙地解决了这些问题:
- Redis Cluster 固定使用 16384 个哈希槽,无论数据量多大,槽的数量恒定不变
- 只需维护"哈希槽 → 实例"的映射关系(16384 条记录),而非"key → 实例"的映射关系
- 扩缩容时只需迁移部分哈希槽,映射表的更新量很小
本质上,哈希槽是在 key 和实例之间引入了一层固定大小的中间映射,用有限的管理开销覆盖了无限增长的 key 空间。
深度探讨:四个高频疑难问题
1. Rehash 的触发时机与渐进式执行
Redis 的哈希表采用装载因子(load factor = 已有 entry 数 / 哈希桶数)来决定是否 rehash:
| 条件 | 是否触发 rehash |
|---|---|
| 装载因子 ≥ 1,且当前允许 rehash(无 RDB/AOF 子进程) | 触发 |
| 装载因子 ≥ 5 | 立即触发(无论是否有子进程) |
| 装载因子 < 1 | 不触发 |
| 装载因子 1~5,但正在执行 RDB/AOF | 不触发 |
为什么装载因子 ≥ 5 时要"强制"rehash?因为此时哈希桶中的链表已经非常长,查询退化为 O(N),性能已经不可接受。
渐进式 rehash 的一个细节:即使没有新请求到来,Redis 也不会停止 rehash。它会通过定时任务(默认每 100ms 执行一次),每次最多花费 1ms 来推进 rehash 过程,确保即使在空闲期,rehash 也能稳步完成。
2. 主线程、子进程和后台线程
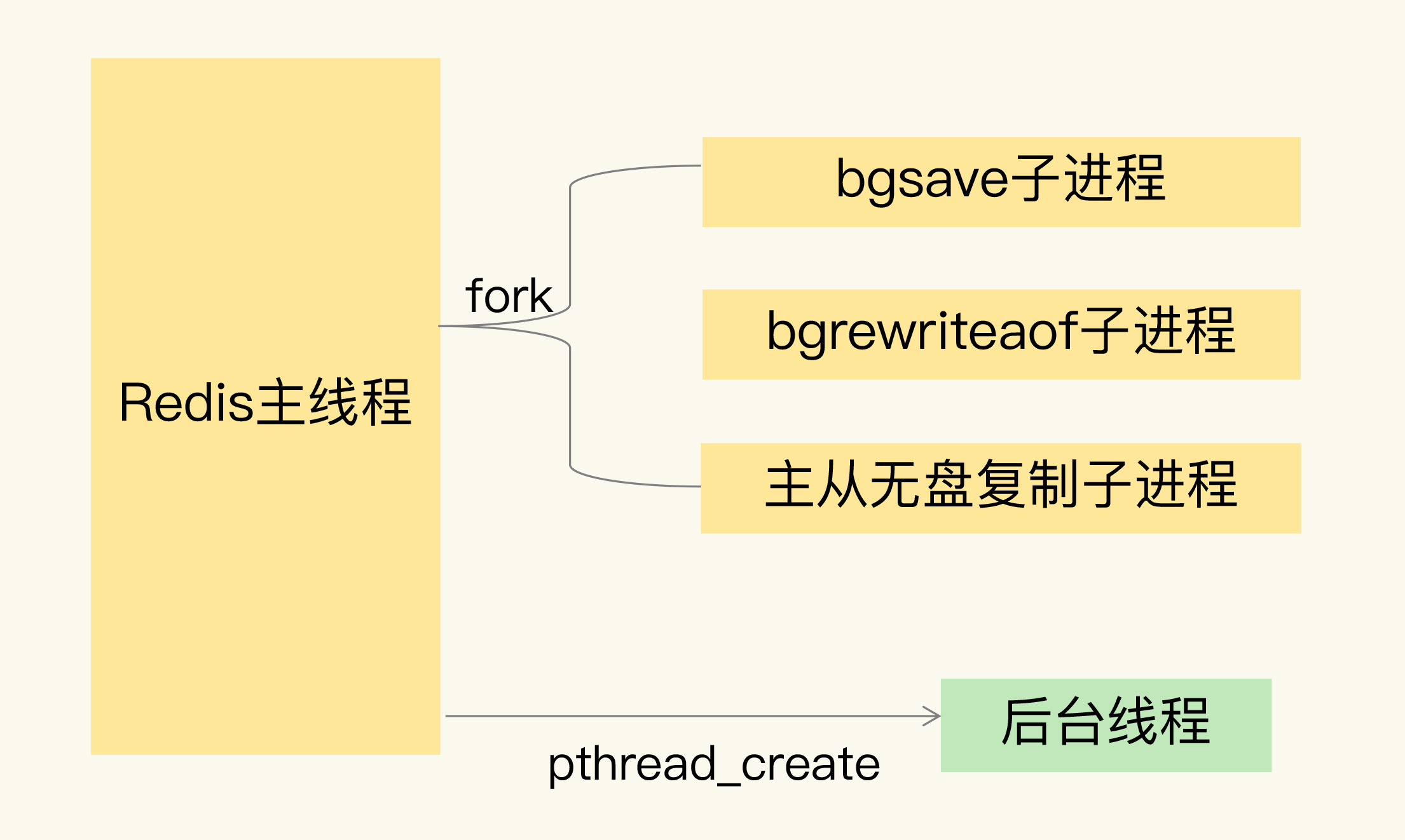
这三个概念经常被混淆,梳理一下:
主线程(主进程):Redis 启动后的进程本身,负责接收客户端连接、执行命令、返回结果。它是 Redis 的核心执行单元。
子进程 :通过 fork 系统调用创建,拥有独立的内存空间(通过页表共享物理内存)。Redis 中的子进程主要包括:
- bgsave 子进程(生成 RDB)
- bgrewriteaof 子进程(重写 AOF)
- 无盘复制时传输 RDB 的子进程
后台线程 :通过 pthread_create 创建,与主线程共享同一进程的内存空间。从 Redis 4.0 开始引入,主要用于:
- 异步删除大 key(
UNLINK命令) - 异步关闭文件描述符
- AOF 的 fsync 操作
核心区别在于:子进程有独立的地址空间,不会影响主线程的数据;后台线程共享地址空间,需要通过锁或无锁队列与主线程协调。
3. 写时复制的底层实现
写时复制(Copy-On-Write)是 Redis 持久化的关键机制。很多人知道它的效果------"子进程保存原始数据,主线程修改不影响子进程"------但对底层实现不够清楚。
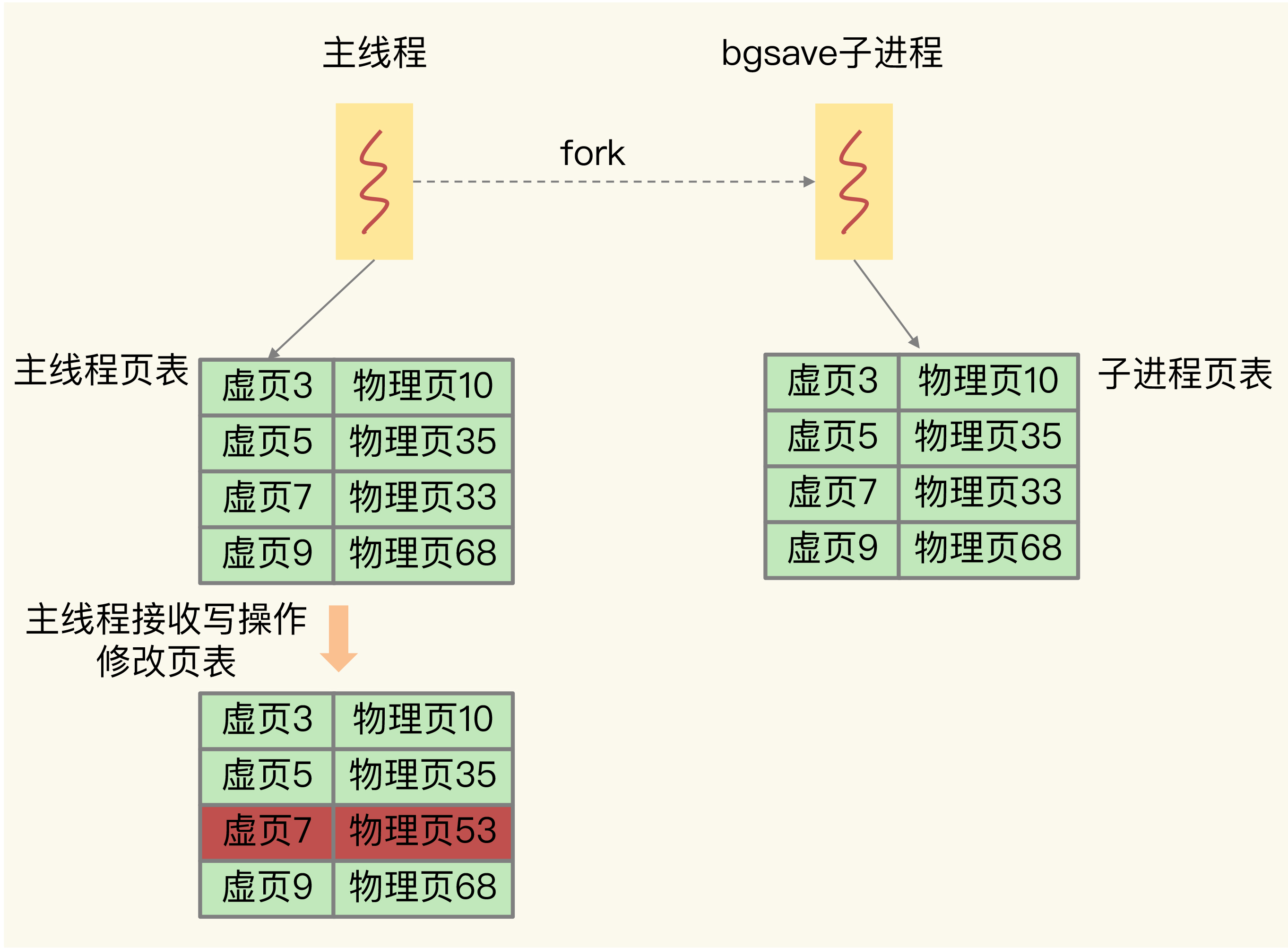
具体过程如下:
- 主线程
fork出 bgsave 子进程后,子进程实际上只是复制了主线程的页表,并没有复制物理内存中的数据。此时,父子进程的页表指向相同的物理内存页 - bgsave 子进程根据页表读取数据,写入 RDB 文件
- 如果主线程此时执行了写操作(比如修改了虚页 7 的数据):
- 操作系统分配一个新的物理页(比如物理页 53)
- 主线程将修改后的数据写入新的物理页
- 主线程的页表更新:虚页 7 → 物理页 53
- 子进程的页表不变:虚页 7 → 物理页 33(原始数据)
这样,bgsave 子进程始终能读到 fork 那一刻的数据快照,而主线程可以继续处理写请求,互不干扰。
需要注意的是,fork 只复制了页表,没有复制数据,所以 fork 操作本身是相对轻量的。但页表的大小与实例内存成正比,内存越大、fork 越慢------这也是为什么大实例的 bgsave 和 bgrewriteaof 可能导致明显卡顿的原因。
4. replication buffer 与 repl_backlog_buffer
这两个 buffer 在主从复制中各司其职,但名字相近,容易混淆:
| 特性 | replication buffer | repl_backlog_buffer |
|---|---|---|
| 用途 | 全量复制期间,缓存要发给从库的写命令 | 持续保存写命令,支持增量复制 |
| 生命周期 | 全量复制时创建,复制完成后释放 | Redis 启动后一直存在 |
| 是否共享 | 每个从库独立一个(每个从库对应一个客户端连接) | 所有从库共享同一个环形缓冲区 |
| 配置项 | client-output-buffer-limit |
repl-backlog-size |
| 溢出后果 | 从库连接被断开,需要重新全量复制 | 旧数据被覆盖,可能触发全量复制 |
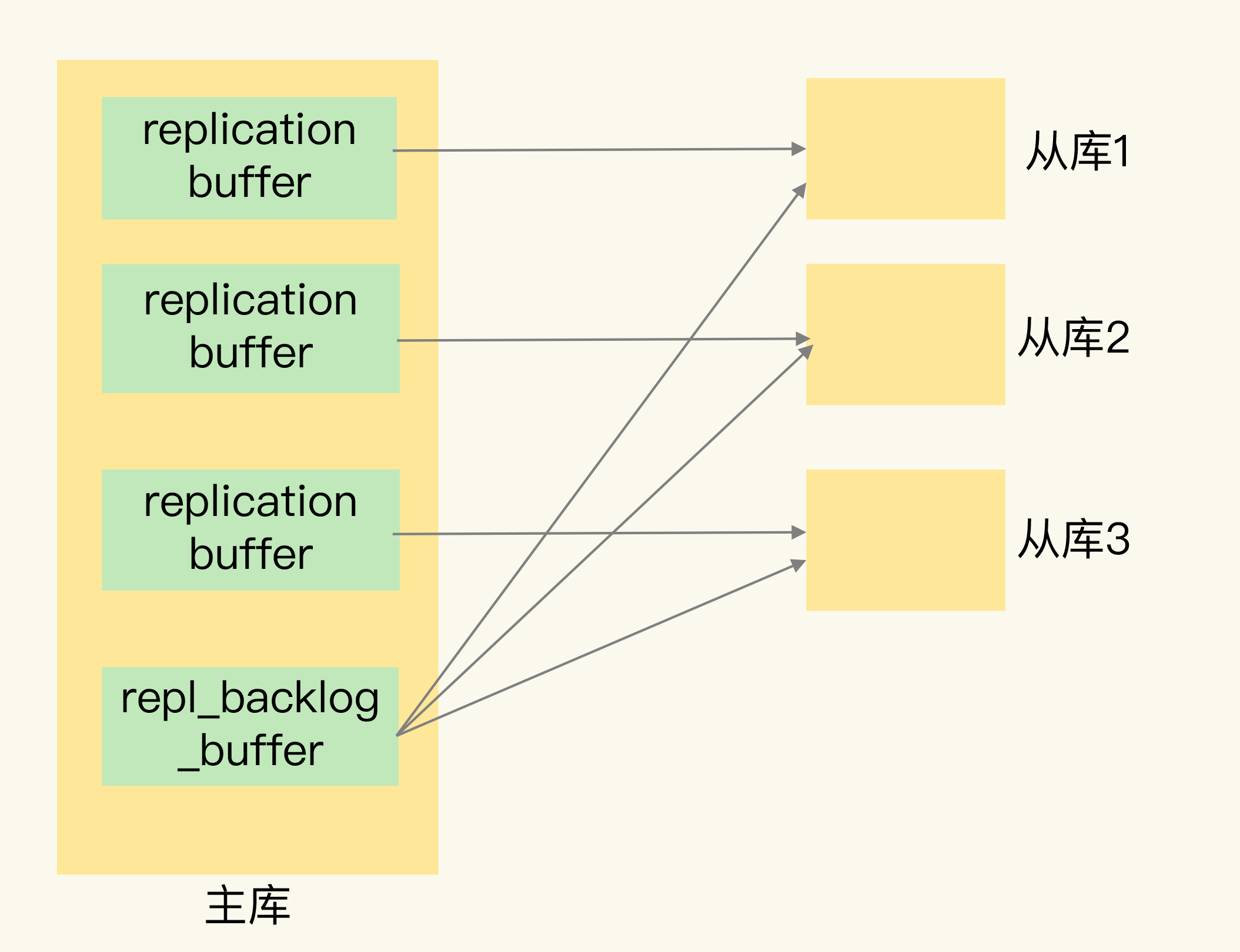
简单理解:
replication buffer是"全量复制的管道"------主库一边生成 RDB,一边把新的写命令存到这个 buffer 里,等 RDB 传完后再把 buffer 里的命令也发给从库repl_backlog_buffer是"增量复制的记忆"------它记住了最近一段时间的所有写命令,当从库短暂断连后,可以只从断点开始追赶,而不必重新全量复制
总结
Redis 的设计处处体现着工程上的权衡:
- 内存 vs 性能:小数据用紧凑结构省内存,大数据换用高效结构保性能
- 简单 vs 可靠:单线程模型简单高效,但通过子进程和后台线程补齐了持久化和异步操作的能力
- 一致性 vs 可用性:哨兵机制中 quorum 和多数派投票的分离设计,在故障检测的灵敏度和切换决策的安全性之间做了精细的平衡
- 管理开销 vs 灵活性:哈希槽用固定大小的中间层,将无限增长的 key 空间映射为可管理的有限集合
理解这些设计背后的"为什么",比记住表面的"是什么"更有价值。当你在生产环境中遇到 Redis 相关问题时,这些底层认知会帮助你更快地定位原因、做出正确的技术决策。
