文章目录
- [1 概要](#1 概要)
- [2 数据结构与缓冲区管理](#2 数据结构与缓冲区管理)
-
- [2.1 rte_mbuf结构体](#2.1 rte_mbuf结构体)
-
- [2.1.1 rte_mbuf 的内存布局(Layout)](#2.1.1 rte_mbuf 的内存布局(Layout))
- [2.1.2 核心字段解析](#2.1.2 核心字段解析)
- [2.1.3 技术串联:rte_mbuf 与你之前学到的 VFIO / IOVA](#2.1.3 技术串联:rte_mbuf 与你之前学到的 VFIO / IOVA)
- [2.1.4 rte_mbuf 的高级特性](#2.1.4 rte_mbuf 的高级特性)
- [2.1 rte_mempool结构体](#2.1 rte_mempool结构体)
-
- [2.1.1 rte_mempool 的内存布局与结构](#2.1.1 rte_mempool 的内存布局与结构)
- [2.1.2 核心优化机制一:本地缓存(Per-lcore Cache)](#2.1.2 核心优化机制一:本地缓存(Per-lcore Cache))
- [2.1.3 核心优化机制二:无锁环形队列(Lockless Ring)](#2.1.3 核心优化机制二:无锁环形队列(Lockless Ring))
- [2.1.4 技术串联:rte_mempool 与 VFIO / IOMMU](#2.1.4 技术串联:rte_mempool 与 VFIO / IOMMU)
- [4 总结](#4 总结)
1 概要
博主最近在想学习RDMA的相关知识,但是无奈于RDMA的教学太少,考虑到DPDK与RDMA有较多技术相关的部分,且DPDK的教程多一些,因此想现将DPDK与RDMA重合的知识部分学习,之后再学习RDMA。
本系列将会分为以下四个部分
- 内存管理模块(最重要:建立硬件直接访问内存的认知)
RDMA 最大的门槛在于理解"为什么网卡可以直接读写用户态内存"。DPDK 的内存管理能帮你完美破局。 - 内核旁路与硬件交互(建立绕过操作系统的认知)
- 数据结构与缓冲区管理(建立零拷贝的认知)
- 并发与队列模型(建立异步事件通信的认知)
2 数据结构与缓冲区管理

2.1 rte_mbuf结构体
简单来说,rte_mbuf 就是 DPDK 里的"数据包载体",每当网卡接收到一个网络报文,或者应用程序准备发送一个报文时,这个报文的数据都会被存放在一个 rte_mbuf 结构体中。
由于 DPDK 追求极致的零拷贝和高吞吐,rte_mbuf 的设计非常精妙。我们可以从它的内存结构、核心字段以及优化机制来深度拆解:
2.1.1 rte_mbuf 的内存布局(Layout)
为了避免频繁的内存分配带来的性能损耗,DPDK 在启动时会预先申请一大块连续内存,并将其划分为一个个固定大小的单元,构成一个内存池(rte_mempool)。每个单元内部的结构如下:
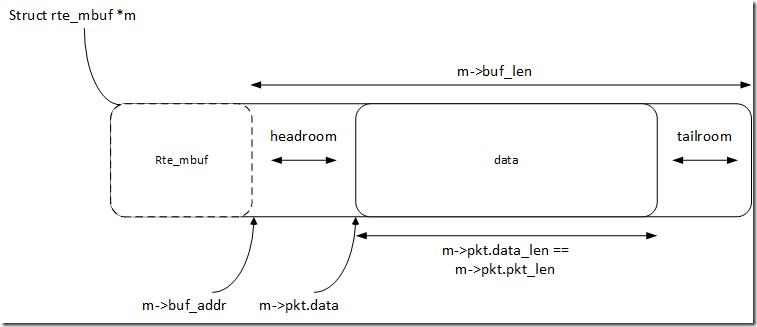

- 结构体本身(Metadata):存放报文的元数据(如报文长度、类型、卸载标志等)。为了极致的性能,这个结构体的大小被严格限制在 128 字节,正好占满 2 个 CPU Cache Line,极大提高了缓存命中率。
- Headroom:这是一块预留的头部空间。当数据包在协议栈中传输时,如果需要封装新的头部(比如加上一层 VLAN 标签或 GRE 隧道头部),驱动可以直接向前移动指针把头写在这里,完全不需要重新分配内存或拷贝数据。
- Data Room:真正存放网络报文(如 Ethernet + IP + TCP)的地方。
- Tailroom:如果报文没有占满整个 Data Room,剩下的部分就是 Tailroom。
2.1.2 核心字段解析
rte_mbuf 内部有很多字段,其中最核心的几个用来精确控制报文的边界和边界移动:
cpp
struct rte_mbuf {
void *buf_addr; /* 指向整个缓冲区(Headroom起始位置)的虚拟地址 (UVA) */
rte_iova_t buf_iova; /* 核心!该缓冲区对应的 IOVA(设备 DMA 使用的虚拟地址) */
uint16_t data_off; /* 从 buf_addr 到实际报文数据起始位置的偏移量 */
uint32_t pkt_len; /* 整个数据包的总长度(如果是链式 mbuf,则是所有分段长度之和) */
uint16_t data_len; /* 当前 mbuf 分段中的实际数据长度 */
uint64_t ol_flags; /* Offload Flags:硬件卸载标志(如校验和计算、TSO等) */
struct rte_mempool *pool; /* 当前 mbuf 所属的内存池,释放时需要还给它 */
struct rte_mbuf *next; /* 指向下一个 mbuf 段的指针(用于处理巨型帧巨包巨幅巨帧 Jumbo Frame) */
...
}结合指针操作理解:
- 实际数据的起始地址 = buf_addr + data_off
- 实际数据的结束地址 = buf_addr + data_off + data_len
2.1.3 技术串联:rte_mbuf 与你之前学到的 VFIO / IOVA
来看一下 rte_mbuf 是如何完美融入这个硬件加速体系的:
- 零拷贝 DMA 注入:
当网卡通过 VFIO 被用户态的 DPDK 接管后,DPDK 提前把整个 rte_mempool(内存池)的物理内存锁定了,并通过 VFIO 在 IOMMU 中建立了映射,生成了对应的 IOVA。
每个 rte_mbuf 里的 buf_iova 字段,就保存了该单元对应的 IOVA 地址。 - 硬件直接写网卡数据:
当网卡收到一个数据包时,它不需要通知内核。网卡直接查找 IOMMU 页表,通过 DMA 把报文内容塞进 buf_iova + data_off 指向的宿主机物理内存中。 - 用户态直接读取:
网卡塞完数据后,用户态的 DPDK 应用程序直接通过 CPU MMU 映射的虚拟地址(buf_addr + data_off)去读取这个报文。从网卡硬件到用户态应用程序,数据只在内存里躺着,期间发生了 0 次内存拷贝!
2.1.4 rte_mbuf 的高级特性
① 巨型帧与链式 mbuf (Chained mbufs)
如果一个内存池里单个 rte_mbuf 的 Data Room 只有 2KB,但网卡收到了一个 9KB 的巨型帧(Jumbo Frame),该怎么办?
rte_mbuf 支持像链表一样串联起来。第一个 mbuf 的 next 指针会指向第二个 mbuf,以此类推。此时,第一个 mbuf 的 pkt_len 记录整条链的总长度(9KB),而每个分段的 data_len 记录各自段的长度(如 2KB)。
② 零拷贝克隆 (Cloning / Shallow Copy)
在网络转发(如多播、广播或防火墙镜像镜像抓包)时,可能需要把同一个数据包发送给多个目的地。
如果复制整个报文内容,性能会很差。DPDK 支持浅拷贝(Shallow Copy):创建一个新的 rte_mbuf 结构体(Metadata),但它的 buf_addr 和 buf_iova 直接指向同一个老报文的 Data Room,同时增加该内存块的引用计数(Reference Count)。只有当引用计数清零时,内存才会真正释放。
小节来说,rte_mbuf 是 DPDK 实现"高吞吐、低延迟"的基石。它通过预先分配内存池(避免动态内存申请)、Cache Line 对齐(保护缓存)、保留 Headroom(避免封装拷贝)、以及天生自带 IOVA(完美契合 VFIO/IOMMU 硬件直通),将现代 CPU 和网卡硬件的性能压榨到了极致。
2.1 rte_mempool结构体
在传统的高并发网络程序中,频繁地调用 malloc() 或 free() 来分配和释放内存会带来巨大的性能灾难(包括内核上下文切换、锁竞争、内存碎片等)。为了在数据平面实现极致的低延迟和高吞吐,DPDK 设计了 rte_mempool(内存池)。
rte_mempool 的核心思想是:在程序启动时,一次性向系统申请一大块连续的物理内存,将其切分成固定大小的多个内存块(Object),并由内存池统一管理。 它的设计极度精妙,完美避开了多核体系下的各种性能瓶颈。我们来拆解它的核心机制.
2.1.1 rte_mempool 的内存布局与结构
一个 rte_mempool 内部包含大量的固定大小的 Object(如果是用来存数据包,这个 Object 就是 rte_mbuf 加上它对应的 Data Room)。
为了防止硬件层面的性能瓶颈,Object 在内存中的排列并不是简单的"紧挨着",而是有特殊的Padding(对齐和填充):
- Cache Line 对齐:每个 Object 的起始地址都会强制对齐到 CPU 的 Cache Line 边界(通常是 64 字节)。这样可以确保 CPU 在加载一个对象时,不会因为跨缓存行而导致多次内存总线访问。
- Channel 对齐(防止内存通道拥堵):现代服务器主板都有多个内存通道(如 4 通道、6通道、8通道内存)。如果大量连续的对象刚好落在了同一个内存通道的闪存芯片上,该通道就会过载。rte_mempool 会在 Object 之间引入微妙的填充(Padding),让对象均匀地分散到不同的物理内存通道上,实现高并发下的带宽最大化。
2.1.2 核心优化机制一:本地缓存(Per-lcore Cache)
这是 rte_mempool 能够支撑数千万 PPS(每秒数据包数)的关键所在。
在多核(Multi-core)系统下,如果所有的 CPU 核心(lcore)在收发数据包时,都去同一个全局队列(Global Ring)里去"抢"或"还"内存块,就必须加锁(或者使用无锁原子操作)。当核心数量变多时,严重的锁竞争/原子冲突会导致性能急剧下降。
为了解决这个问题,rte_mempool 为每个 CPU 核心引入了一个本地缓存(Per-lcore Cache):
-
申请内存(Allocate/Get) :
CPU 核心需要内存时,首先看自己专属的 Local Cache 里有没有闲置的 Object。如果有,直接拿走,全过程无锁、无原子操作,耗时几乎为 0。只有当 Local Cache 空了,才会批量(Bulk)去全局 Ring 里拉取一批对象充能。
-
释放内存(Free/Put):CPU 核心用完内存释放时,直接塞回自己的 Local Cache。只有当 Local Cache 满了,才会批量把对象打包还回全局 Ring。
这就像总公司(Global Ring)在各个分公司(每个 CPU 核心)设立了零用钱金库(Local Cache),大部分日常报销在分公司内部就消化了,只有钱不够或者太多时才去总公司清算,从而彻底解放了并发性能。
2.1.3 核心优化机制二:无锁环形队列(Lockless Ring)
当 Local Cache 满了或者空了,核心必须与全局内存池交互时,rte_mempool 底层使用的是 DPDK 著名的 rte_ring(无锁环形队列)。
它利用了 CPU 的 CAS(Compare-And-Swap,比较并交换) 原子指令,实现了多生产者-多消费者(MPMC)的无锁队列。即使在不得不去全局抢内存的极端情况下,它也通过硬件级的原子指令把软件锁的开销降到了最低。
2.1.4 技术串联:rte_mempool 与 VFIO / IOMMU
rte_mempool 在底层是如何与硬件协作的:
-
大页内存(Hugepages)支持 :
rte_mempool 默认是建立在 Linux 的大页内存(如 2MB 或 1GB 大页)之上的。使用大页可以极大地减少页表项的数量,从而让 CPU 的 TLB(未命中缓存) 保持极高的命中率。
-
物理连续与 IOVA 注册 :
在内存池创建成功后,DPDK 的内存管理模块会通过 VFIO 告诉 IOMMU 硬件:"这一整块几十 GB 的大页内存已经被我包下了。" VFIO 会在 IOMMU 页表中一次性为这个大页内存池建立好连续的 IOVA 到 HPA 的映射。
-
网卡直达 :
因为整个内存池的 IOVA 空间在开机时就已经固定并写入硬件,网卡在后续高并发收包时,可以毫无顾忌地根据 rte_mempool 中分配出去的 IOVA 地址直接做高效的 DMA 传输,中间不再需要内核做任何地址转换。
rte_mbuf是rte_mempool中的内容,两者与VFIO/IOMMU技术关联基本一致。
关于前面的local Cache和全局Ring的理解:



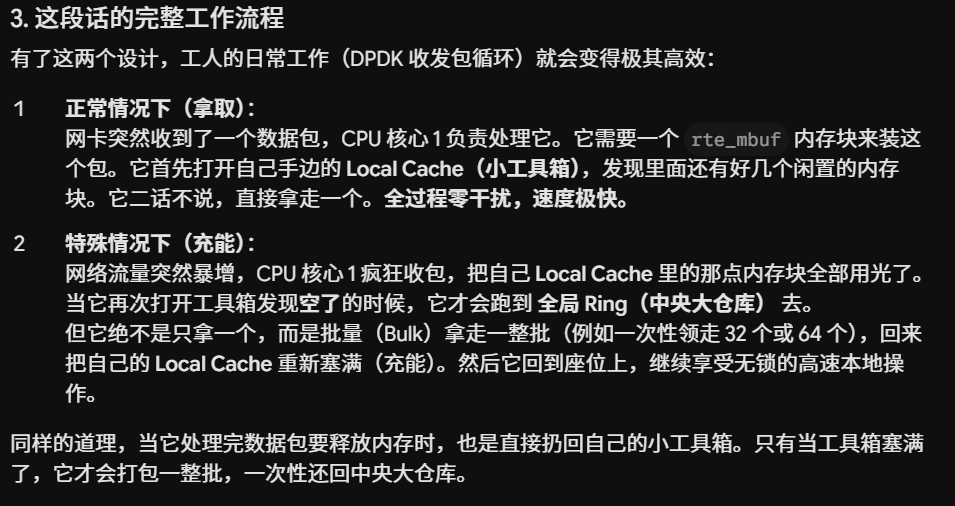
问:可以理解为全局 Ring是备用的吗,当local不够了就会使用全局的?




4 总结
本章节介绍DPDK核心知识中的数据结构与缓冲区管理的基本概念。