植物免疫的"密码",比我们想象的更复杂
和拥有抗体与免疫细胞的人类不同,植物在面对病原体侵染时,演化出了一套极为精妙且多层级的"先天免疫系统"。
从胞外的初步识别,到胞内的程序性死亡(HR反应),这一整套防御反应由一系列关键功能蛋白串联支配------比如常听到的RLK(类受体激酶)、RLP类受体蛋白,以及深入胞内的cTIR、EDS1、MLKL、NLR和辅助蛋白TNP等。它们就像是植物体内的雷达、通讯兵和敢死队,构成了完整的防卫链路。
但对于从事抗病育种和生信研究的科研工作者来说,这套系统却是一个"硬骨头"。
在浩如烟海的基因库里"大海捞针"
最大的难题在于"多且杂"。拿上面提到的七大类基因家族来说,成员数量庞杂,进化分化多样,不仅基因间存在严重的功能冗余,其调控网络也错综复杂。
过去,要弄清楚某两个基因之间是否有互作关联,主要依赖传统的克隆提取与生化验证手段(如酵母双杂交、BiFC等)。这条路径不仅试验难度大、耗时长,且筛选效率偏低。面对动辄几千上万个潜在候选基因,单纯依靠湿实验去"穷举",很难快速且批量地解析出基因规律,这成为了阻挡抗病分子机理研究与抗性新种质创制的一座大山。
AI算法与底层大数据库的"双向奔赴"
当传统的湿实验走到效率瓶颈时,干实验(计算生物学与生物信息学)的介入就成了破局的关键。近年来,由前沿算法驱动的蛋白互作对接技术,正在为植物抗病研究提供全新的解题思路。
然而,再优异的算法,也需要坚实的数据底座作为支撑。没有全面、标准化的物种基因序列与结构数据,算法就是无源之水。
在这方面,国内一些敏锐的生物技术服务团队已经跑在了前面。以科晶生物为例,为了解决植物免疫研究的底层数据碎片化问题,该团队耗费大量精力,系统性地汇总并完善了上述七大植物免疫关键基因的序列、结构与多层级功能注释数据库。
其数据量级和覆盖面令人瞩目:
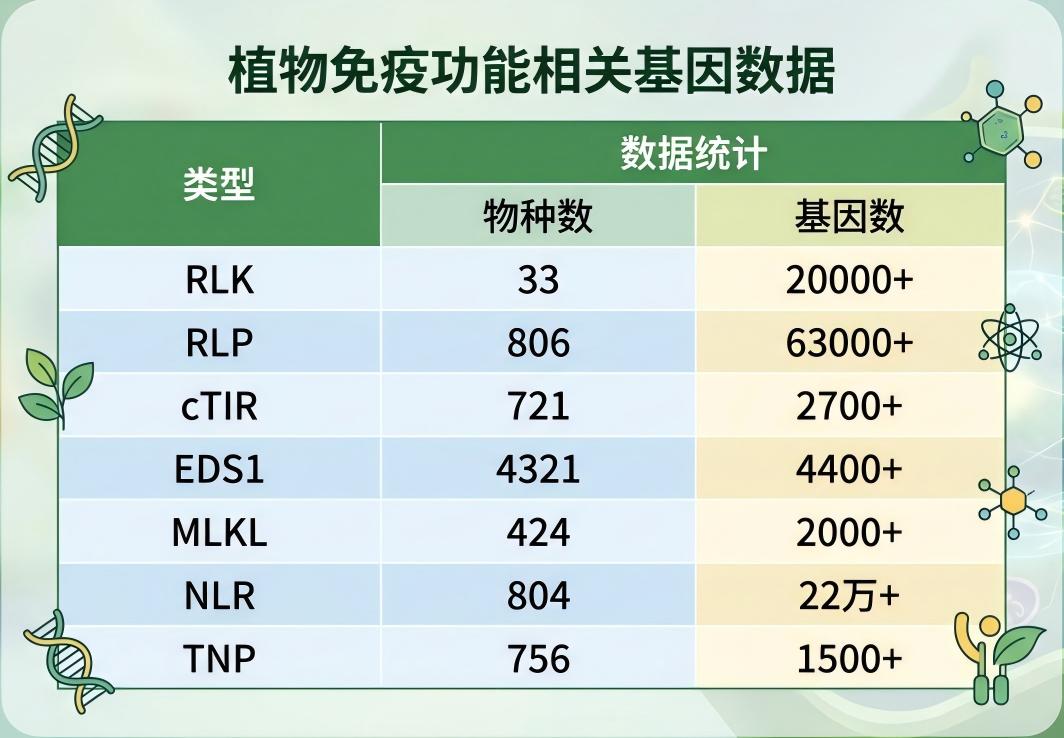
- RLK与RLP家族: 囊括了水稻、小麦等33个物种的超20,000条RLK数据,以及覆盖藻类到被子植物等806个物种的超63,000条RLP数据。
- NLR核心抗病基因: 积累了普通小麦、紫花苜蓿等804个物种中极为庞大的220,000多条有效数据。
- 下游调控与辅助蛋白: 包含了4231个物种的4,400+条EDS1数据,424个物种的2,000+条MLKL数据,721个物种的2,700+条cTIR数据,以及756个物种的1,500+条TNP数据。
这是一个足以让大多数单独实验室感到震撼的"植物免疫基因字典",几乎覆盖了目前已测序的绝大部分模式植物、主要农作物和特殊生境植物。
应用落地:让功能基因筛选从"泥步"走向"快跑"
完善了数据库本身只是第一步,如何将其转化为科研生产力?
依托于上述庞大且结构化的数据库,科晶生物引入了目前结构生物学领域备受瞩目的 Alphafold 3 分子结构预测 以及 HDOCK 高精度分子对接算法。
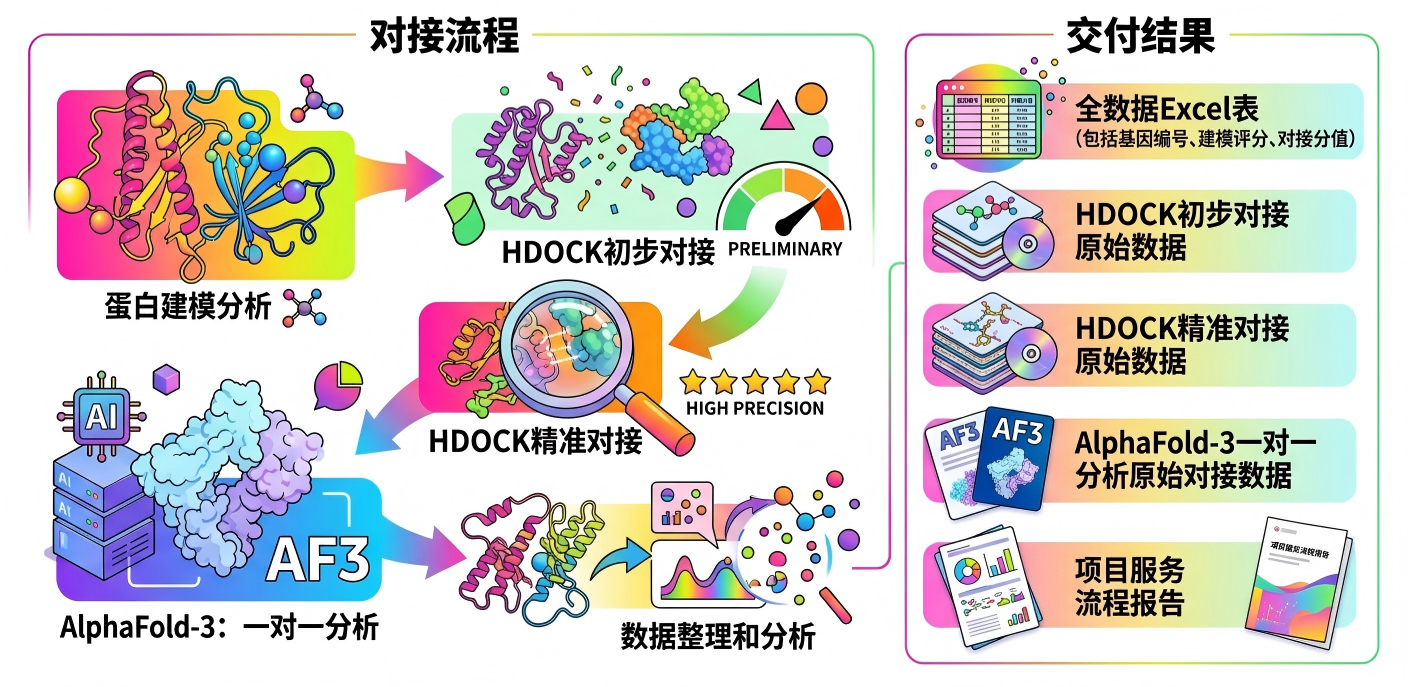
这意味着,当科研人员在探究某种病原互作机理,或是想要筛选特定农作物的抗病基因时,无需再第一时间扎进实验室盲目试错。而是可以通过高精度对接算法,先在系统的数据库中进行大规模的虚拟对接和精准筛选。
这项底层技术服务不仅能快速模拟出蛋白间的互作模式,还能提供全方位完备的结果参数交付。将原本需要数月甚至更久的"候选基因验证阶段",压缩到了可预期的计算时间通道内,大幅提升了后续湿实验的成功率和精确度。
结语
农业生物技术的进步,往往隐藏在这些底层数据的积累与算法的迭代之中。从传统的"盲盒验证"走向AI驱动的"精准预测",这种跨界融合正在深刻改变科研范式。
对于广大生命科学研究者来说,像科晶生物这样提供定制化数据解析与高精度对接筛选的技术下沉,不仅是一次科研工具的升级,更是打开植物抗病机理研究新世界的一把"新钥匙"。