在计算机视觉的世界里,视频全景分割(Video Panoptic Segmentation, VPS)一直被视为一项"全能且昂贵"的任务。它不仅要求模型识别出视频中的每一个像素属于什么类别(语义分割),还要区分出不同的个体(实例分割),并且在时间轴上准确地将它们关联起来(目标跟踪)。
然而,高质量的 VPS 标注成本高得惊人。为了解决这一痛点,来自慕尼黑工业大学、达姆施塔特工业大学、英伟达以及牛津大学等研究团队联合推出了 VideoCUPS。它的核心魅力在于:完全不需要人类标注,仅凭普通的单目视频,就能"自学"成才,实现高质量的视频全景理解。
- 机构: 慕尼黑工业大学、达姆施塔特工业大学、英伟达、牛津大学、MCML、ELIZA、hessian.AI
1. 背景与动机:从图像到视频的"跨越"
近年来,无监督学习在图像分割领域取得了长足进步。比如之前的 U2Seg 或 CUPS,已经能在不看标签的情况下把图片里的车、人、树分得有模有样。但当我们把目光转向视频时,情况变得复杂了。
视频多了时间维度,意味着模型不仅要分得准,还要跟得住。现有的无监督方法大多盯着静态图像,或者只能处理简单的、以单个物体为中心的视频。面对复杂的真实驾驶场景(Scene-Centric),如何利用视频自带的运动(Motion)和深度(Depth)线索来构建时序一致的理解?这就是 VideoCUPS 想要回答的问题。
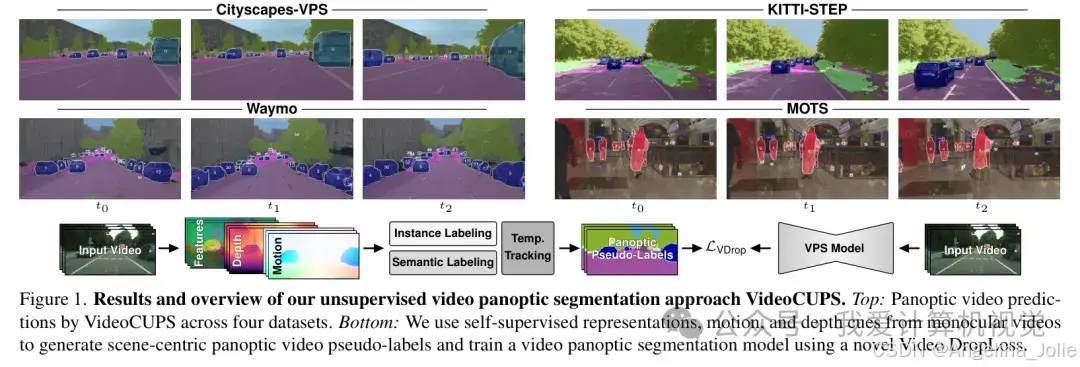
VideoCUPS 效果一览与流程概述
2. 方法详解:如何"无中生有"生成伪标签?
VideoCUPS 的核心逻辑分为两步:第一步是生成高质量的视频全景伪标签;第二步是利用这些伪标签训练一个强大的 VPS 模型。
2.1 伪标签的"三位一体"生成法
为了在没有标注的情况下识别物体,研究者们借鉴了格式塔心理学(Gestalt principles)中的"共同命运"原则:即一起运动的像素通常属于同一个物体。

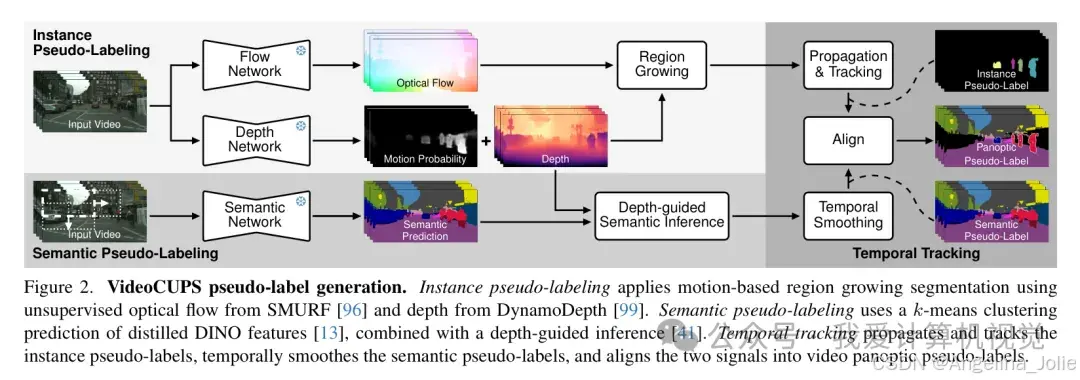
VideoCUPS 伪标签生成流程图
值得注意的是,相比于之前的 CUPS 依赖双目(Stereo)相机提供的深度信息,VideoCUPS 仅需单目视频即可完成上述过程。这种对硬件要求的"降级",实际上是对算法鲁棒性的巨大挑战。
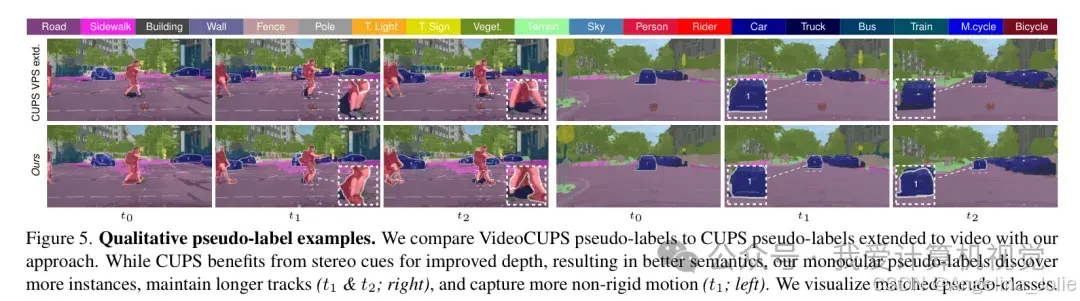
VideoCUPS 伪标签与 CUPS 扩展版的对比
从上图可以看到,VideoCUPS 生成的伪标签在处理非刚性运动(如行人的肢体动作)时表现得更加出色,且跟踪的生命周期更长。
2.2 训练策略:Video DropLoss 与自增强
有了伪标签,接下来的挑战是如何训练模型。伪标签通常是稀疏的------它只能发现那些正在运动的物体,却容易漏掉路边停着的静止车辆。
为此,团队引入了 Video DropLoss。其数学表达式如下:
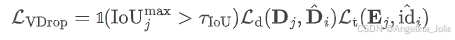
这个损失函数的设计只对那些与伪标签高度重合(IoU 超过阈值)的预测进行强监督,而给模型留出了"自由发挥"的空间。这样,模型在训练过程中就能通过视觉特征的相似性,自动把那些静止的、未被伪标签覆盖的车辆也识别出来。
此外,研究者还设计了自增强视频 Copy-Paste。模型会把自己预测得最自信的物体"抠"出来,随机粘贴到其他视频剪辑中。这种"自我博弈"的方式极大地提升了模型对小物体的检测和跟踪能力。
3. 实验与结果:刷新无监督 VPS 性能上限
研究团队在 Cityscapes-VPS、KITTI-STEP、Waymo 和 MOTS 四个具挑战性的数据集上进行了严苛的测试。
3.1 性能全方位领先
在 Cityscapes-VPS 验证集上,VideoCUPS 表现:
-
STQ 指标(分割与跟踪质量,Segmentation and Tracking Quality)达到了 22.2%。
-
在**关联质量(AQ)和分割质量(SQ)**上均大幅领先于现有的无监督基线。
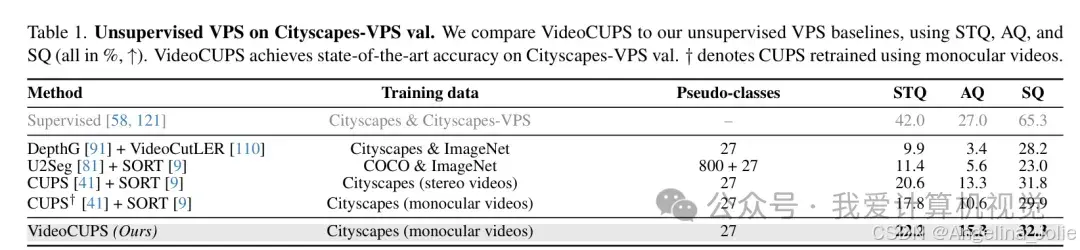
Cityscapes-VPS 上的定量对比
通过消融实验(下表)可以发现,时序跟踪和语义平滑对最终性能的提升贡献巨大,STQ 从 9.3% 一路飙升至 12.1%。

伪标签生成的消融实验
3.2 强大的跨域泛化能力
一个优秀的无监督模型不应该只在训练集上跑得好。实验显示,VideoCUPS 在 KITTI-STEP 和 Waymo 等数据集上的泛化表现同样稳健,STQ 指标均优于所有对比基线。
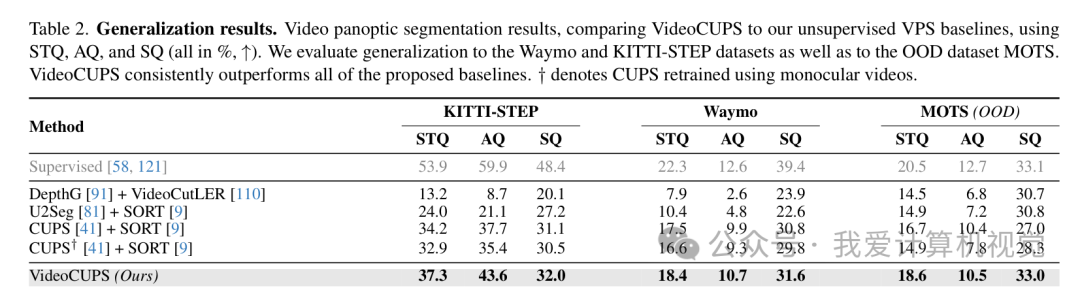
跨数据集泛化结果
从可视化结果来看,VideoCUPS 预测的掩码边缘更加平滑,对复杂背景下的行人识别也更加准确,甚至能处理一定程度的局部遮挡。

定性对比示例
3.3 标签效率:10% 标注即可达到随机初始化全量标注的效果
这可能是最令工业界兴奋的一点。研究发现,如果将 VideoCUPS 作为预训练模型,仅使用 10% 的标注数据进行微调,其性能(STQ 32.5%)就能远超直接从 DINO 初始化微调的效果。这意味着在实际应用中,我们可以极大地减少人工标注的工作量,实现"事半功倍"。
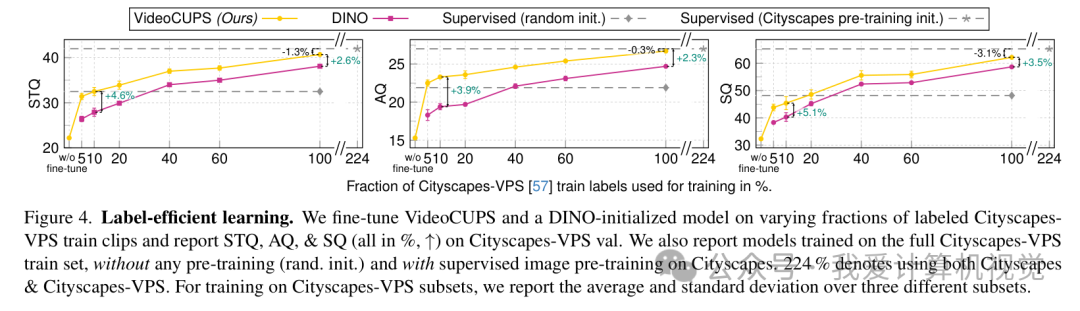
标签效率分析曲线
结论
VideoCUPS 的成功,本质上是人类对"先验知识"的巧妙利用------我们告诉模型"运动一致即物体",模型便以此为支点,撬动了复杂的视频全景理解。说实话,看到无监督模型能把复杂的街景分得这么细致,确实让人感叹自监督表征学习的潜力。如果你正苦于 VPS 标注数据的匮乏,待 VideoCUPS 代码开源后绝对值得一试。