大家好,我是HLAIA光子。
LLM API调用是AI应用最大的运营成本。举个栗子,同样10万次日均查询,不做缓存优化一年花265万美元,做了之后只要65万,差出来的这200w就靠缓存拉差价。
我在开发我的OpenMMV项目时,把 DeepSeek v4 flash 接入了平台。一开始我没有在意缓存的设置,平台运行了几天后,发现缓存率居然低于 40% ??最低只有 15% ???
这篇文章就来讲清楚LLM缓存在缓存什么,以及怎么在应用层搭多层缓存体系把成本压到最低。
有同学问:光子gg光子gg,LLM缓存的是什么东西啊?
所有主流LLM的缓存,缓存的都不是最终输出,而是模型处理输入 时产生的中间计算状态。缓存命中之后,模型输出仍然是有随机性的,不会变成复读鸡。
KV Cache
LLM处理输入时,先把文字切成Token,然后一层层做注意力计算。每一层会生成Key和Value两个矩阵,合起来叫KV Cache。
可以把它理解成:模型"读完"你的Prompt之后,把理解的结果存了一份备忘录。下次如果Prompt前半部分没变,模型直接翻备忘录,不用从头再读一遍。

所以缓存只影响输入处理阶段的延迟和成本,输出阶段该算还是得算,temperature、top_p该怎么采样还怎么采样。所以即使输入有缓存,输出还是随机的。
前缀匹配
所有主流LLM的缓存命中规则都是前缀精确匹配。
第一次请求包含System Prompt加一篇长文档加一个问题,模型处理完后KV Cache被存下来。第二次换了问题但前面内容完全一样,System Prompt和文档对应的KV Cache直接复用,只有新问题的部分需要重新算。
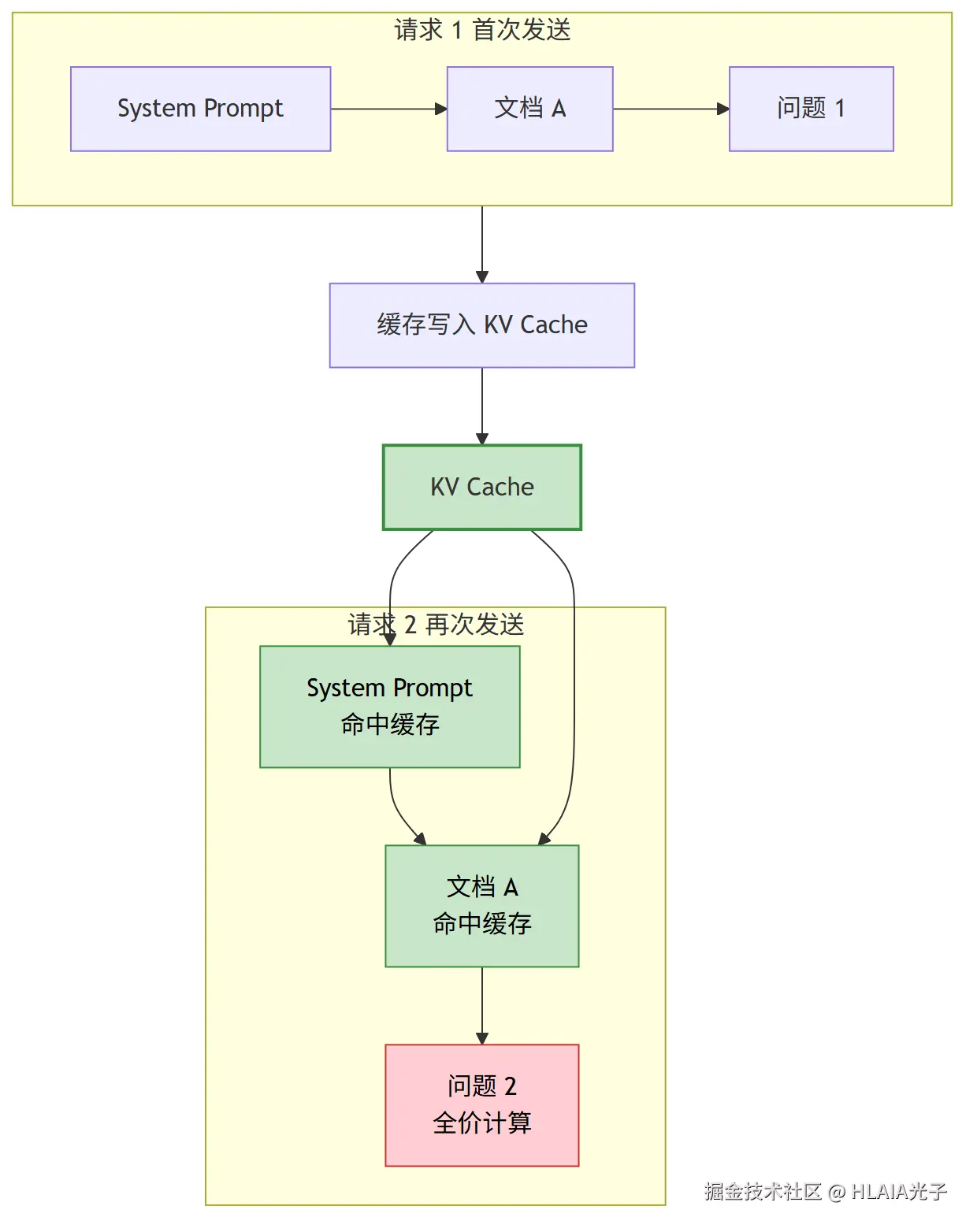
这条规则有一个严格的前提,就是前缀中任何一个字节变了,从变化点开始往后的缓存全部失效。在System Prompt开头加了个时间戳或者随机ID,每次请求前缀都不一样,那就等于白缓存了。
DeepSeek 缓存机制
OpenMMV 就接入的 deepseek api。
DeepSeek的缓存叫Context Caching,基于磁盘存储,对所有用户默认开启。不需要改代码,不需要加参数,API调用该怎么做还怎么做,缓存自动生效。
不过对于我们这样的第三方开发者来说,几乎没有任何控制权,不能指定缓存边界,不能设置TTL,不能手动清除。缓存在几小时到几天后自动过期,命中率不保证100%。
DeepSeek的缓存以"缓存前缀单元"为单位,每个单元是独立完整的块。后续请求必须完整匹配整个单元才算命中,部分匹配不算。多轮对话场景下,系统会自动检测多个请求的公共前缀并落盘。通常到第三次请求时命中率就上来了。
很多AI厂家的缓存机制都是类似的
我给出一个建议:稳定内容放前面,变化内容放后面。
System Prompt在最前面,接着是固定规则和长文档,然后是历史上下文,用户问题在最后。
Claude Code
Claude Code的Prompt Caching对于缓存机制就比较开放,会给你精细的控制权。
开发者通过cache_control标记显式指定缓存断点。你可以精确控制哪部分内容被缓存、缓存多长时间。Claude提供两种TTL:5分钟和1小时。5分钟的写入价格是基础输入的1.25倍,1小时是2倍。但命中后只收0.1倍,大约命中一两次就回本了。
cc 的缓存也是这个原则:静态内容在前,动态内容在后。
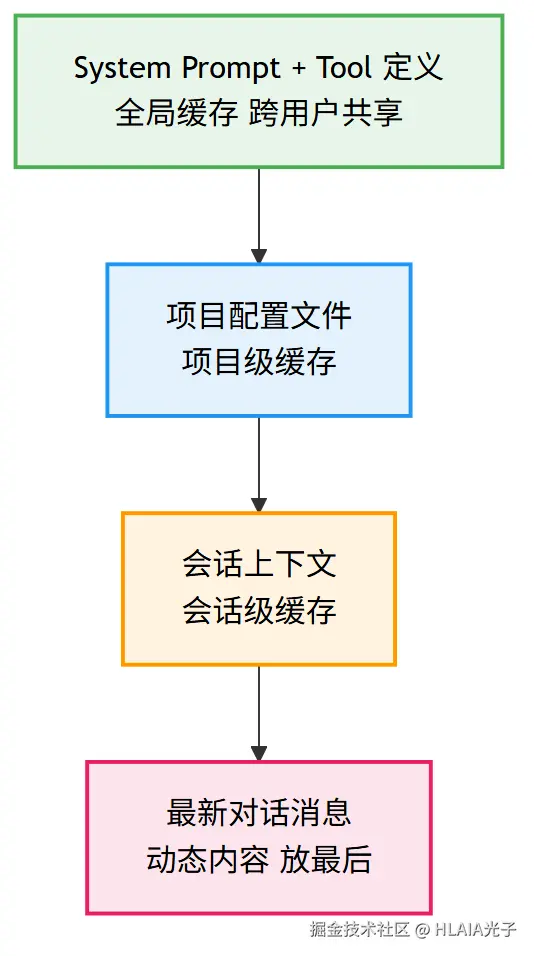
最新的用户消息永远在最后,只有不匹配的后缀部分按全价计费,所以末尾新增的消息不会让前面的缓存失效。
可以看看 cc 团队对缓存的态度:
"像监控服务可用性一样监控缓存命中率。缓存命中率的几个百分点的下降会显著影响成本和延迟。我们将缓存断裂视为事故来处理。"
cc 团队总结了一些在开发中缓存方面的坑,可以参考参考
会话中途修改静态内容。 原因上文也说了,这里就不赘述了。对策是开始会话前规划好指令,需要修改就重开一个新会话。
动态内容放在前缀里。 不要把时间戳、随机ID写在System Prompt中,因为这样每次请求都会Cache Miss。这样的动态信息直接放末尾user message里就好。
会话中途切换模型。 缓存按模型隔离,切了模型,之前的缓存通通洗白。不过给子代理设置别的模型不会,因为子代理会有与主会话独立的会话。
中途增删工具定义。 工具也是是缓存前缀的一部分。Claude Code的做法是始终包含所有工具,用工具状态转换代替工具集切换。
应用层缓存
这部分比较偏开发了。
除了厂商的KV缓存以外,在实际业务中有大量语义相似但文本不完全相同的查询。这时可以在应用层搭自己的缓存体系。
一套完整的缓存架构分三层。
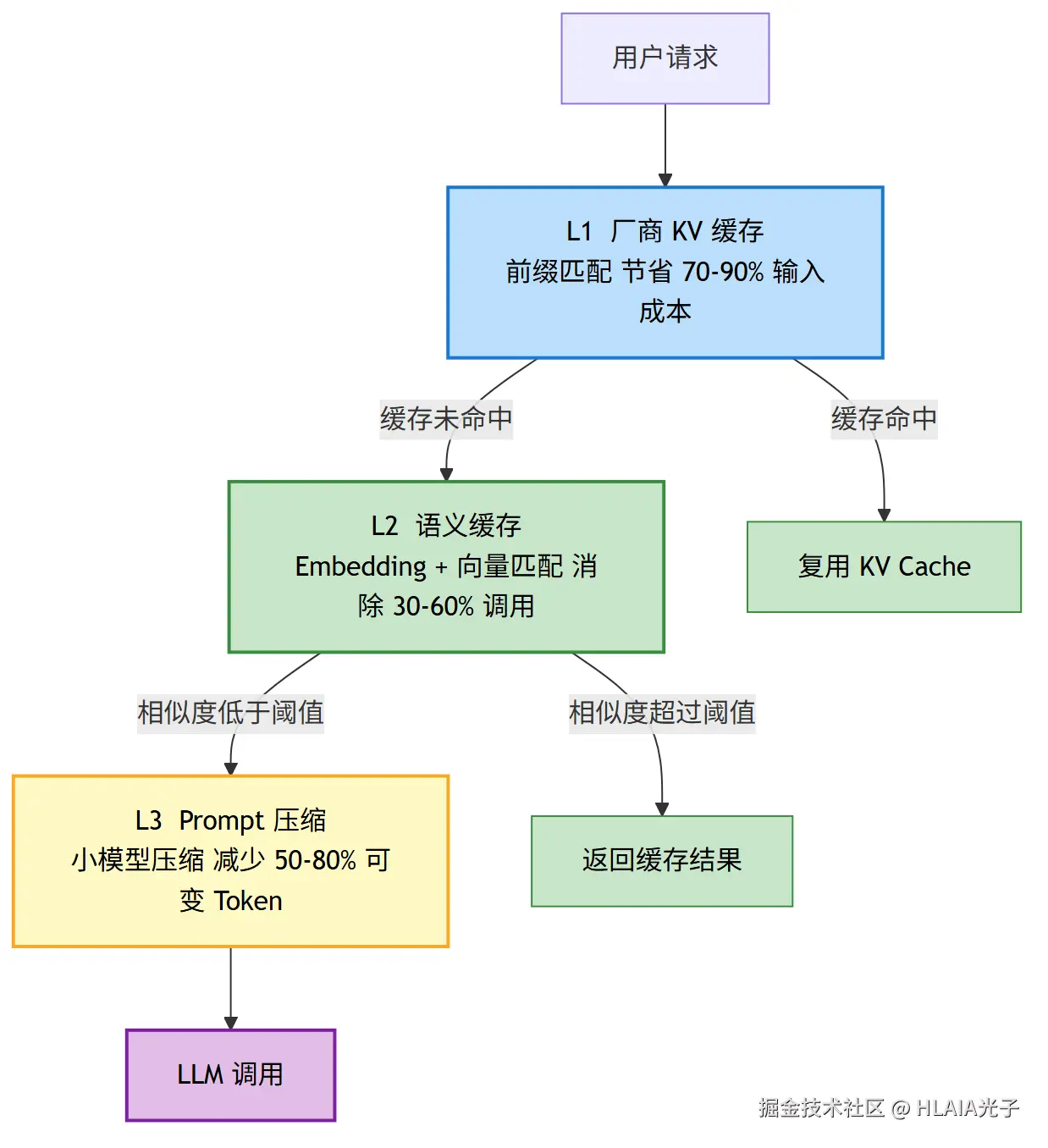
L1是厂商的KV缓存。 就是你刚看到的DeepSeek、Claude等自带的前缀匹配缓存。主要负责System Prompt、工具定义这些固定大块内容的复用,能省70到90%。
L2是语义缓存。 对用户查询做Embedding,和历史上的查询做向量相似度匹配。相似度超过阈值就返回缓存的答案,跳过LLM调用。这一层能消除30到60%的重复调用。2026年一个用"小模型验证加大模型回退"的方案,实现了68%的成本节省,误差率1.1%。
L3是Prompt压缩。 用小型语言模型把Prompt中的冗余信息压掉,保留关键内容,能减少50到80%的可变Token。
其实吧,大多数 AI 项目都只用了 L1,因为 AI 厂商的 KV 缓存都够用了,真的。
写在最后
LLM缓存这个话题是比较偏底层的,它关系到AI应用的运营成本,对开发者来说是非常建议学习的。
实际项目中缓存策略建议根据业务场景来调整,绝大多数情况下 厂商自带的 KV 缓存已经够用了。
如果你觉得这篇文章有帮助,点赞关注,点点赞~