Gemma-4-31B是Google发布的开源旗舰模型,307亿参数在多项基准测试中超越参数量远超自身的闭源模型。但62GB的显存需求让大多数消费级显卡望而却步。本文聚焦31B模型的推理加速,从量化压缩、框架选型、MTP推测解码、DFlash块扩散加速四个维度给出实战方案。
量化方案:把62GB压到20GB以内
量化是降低显存门槛的核心手段。Gemma-4-31B在BF16精度下需要约62GB显存才能完整加载,通过将参数从高精度浮点数压缩为低精度整数,可以大幅降低硬件要求。
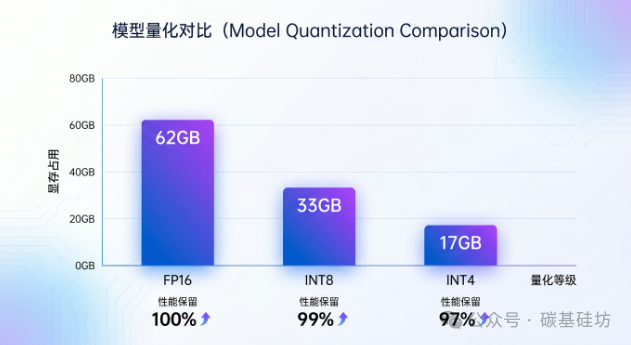
不同量化级别的显存占用与性能保留
| 量化级别 | 模型大小 | 显存占用 | 推理速度 | MMLU保留 | 推荐场景 |
|---|---|---|---|---|---|
| BF16(原始) | 62GB | 基准 | 8-12 tok/s | 100% | H100/A100 |
| INT8(Q8_0) | 33GB | ~36GB | 18-25 tok/s | 99.2% | RTX 4090 |
| INT4(Q4_K_M) | 17GB | ~20GB | 35-48 tok/s | 97.1% | RTX 4060 Ti |
从实测数据来看,INT8量化几乎无损,MMLU准确率保持在99.2%,日常使用中与BF16没有体感差异。INT4量化虽然速度最快,但在复杂数学推理和工具调用任务上会有明显下降。
**重要提醒:**INT4量化在函数调用(Function Calling)任务中存在约15%的格式错误率。如果你的业务依赖工具调用,建议至少使用INT8量化。
MTP推测解码:让推理速度提升3倍
Google在2026年5月为Gemma4系列推出了MTP(Multi-Token Prediction,多词元预测)草稿模型。这项基于推测解码架构的技术,可以在不损失输出质量的前提下,将推理速度提升至原来的3倍。
技术原理
传统大语言模型采用自回归方式生成文本:每次输出一个词,然后把这个词加到输入里,再预测下一个词。这个过程就像"挤牙膏"------必须等前一个词出来,才能生成后一个词。速度受限于内存带宽,处理器总是在等待数据从显存搬运到计算单元。
MTP的思路是引入"双模型协作"机制:用一个轻量级的草稿模型(Draft Model)利用闲置算力,快速猜出接下来几个词可能是什么。主模型拿到这些"草稿"后,一次性并行验证。如果猜对了,一次性接受多个词,效率大幅提升;如果猜错了,丢弃草稿,主模型正常输出就行。
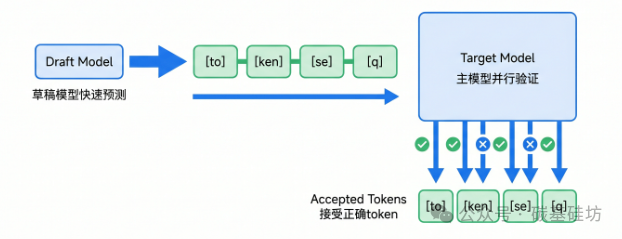
MTP推测解码工作流程------草稿预测+主模型并行验证
gemma-4-31B-it-assistant 草稿模型
Google官方发布了专门的MTP草稿模型 gemma-4-31B-it-assistant,这是一个仅4.7亿参数的轻量级模型,专门用于加速Gemma-4-31B的推理。
| 模型 | 参数量 | 文件大小 | 角色 |
|---|---|---|---|
| gemma-4-31B-it(目标模型) | ~307亿 | 62GB(FP16) | 生成最终答案 |
| gemma-4-31B-it-assistant(草稿模型) | 4.7亿 | 970MB | 预测候选token |
关键设计
-
**轻量级草稿模型:**gemma-4-31B-it-assistant 仅469M参数,专门为预测任务优化,计算开销极小
-
**共享KV缓存:**草稿模型与主模型共享键值缓存,减少重复计算开销
-
**主模型保留最终验证权:**质量不受影响,只是加速了生成过程
-
**嵌入层聚类技术:**针对小模型优化内存使用
性能数据
根据Google官方测试数据,在Apple Silicon芯片上,当batch sizes设置为4至8时,Gemma 4 31B模型实现了显著的本地加速效果。在NVIDIA RTX PRO 6000上运行Gemma 4 31B模型时,MTP草稿器使输出质量相同的情况下等待时间减少一半。
**MTP适用场景:**聊天机器人、编程助手、自主智能体、移动端应用。对低延迟要求极高的场景特别有效。
如何启用MTP
MTP草稿模型已采用Apache 2.0协议全面开源,原生支持Transformers、vLLM、SGLang等主流框架。
# Transformers 启用 MTP(推荐)
from transformers import AutoModelForCausalLM, AutoTokenizer
target_model = AutoModelForCausalLM.from_pretrained("google/gemma-4-31B-it")
assistant_model = AutoModelForCausalLM.from_pretrained("google/gemma-4-31B-it-assistant")
outputs = target_model.generate(**inputs, assistant_model=assistant_model, max_new_tokens=256)
# Ollama 启用MTP
ollama run gemma4:31b-it
# vLLM 启用推测解码
vllm serve google/gemma-4-31b-it \
--speculative-config '{"method": "target", "model": "google/gemma-4-31b-it-assistant"}'
# SGLang 启用推测解码
python -m sglang.launch_server --model-path google/gemma-4-31b-it --speculative-algorithm MTPDFlash块扩散:超越MTP的6倍加速
DFlash(Block Diffusion for Flash Speculative Decoding)是Z Lab团队推出的新一代推理加速方案。与MTP基于自回归草稿模型不同,DFlash创新性地使用块扩散模型(Block Diffusion)作为草稿生成器,在Qwen3-8B等模型上实现了超过6倍的无损加速,比EAGLE-3快近2.5倍。
核心技术
传统推测解码的草稿模型仍是自回归的------生成8个token需要8步串行生成。DFlash的创新在于:使用块级扩散模型,在一次前向传播中并行生成整个token块(block size = 16)。
关键对比:
-
**EAGLE-3(自回归草稿):**生成8个token需要8步
-
**DFlash(块扩散草稿):**生成16个token仅需1步
-
**加速效果:**6倍以上无损加速
技术原理
DFlash的核心创新包括:KV注入(KV Injection) ------将目标模型多层隐藏层特征融合后注入到草稿模型的KV缓存中,让草稿模型能"看到"目标模型的推理结果,预测更准确;并行扩散起草------使用块级扩散过程预测下一个token块,block内所有掩码位置通过单次前向传播并行解码。
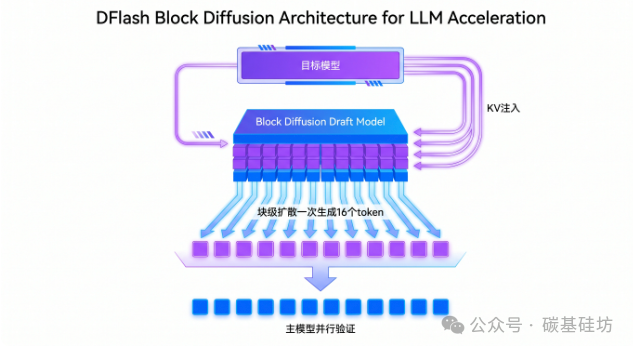
DFlash块扩散加速架构一次前向传播生成16个token草稿
性能对比
| 方案 | Draft方式 | 加速比 | 接受率 |
|---|---|---|---|
| 纯自回归 | - | 1x(基准) | 100% |
| EAGLE-3 | 自回归 | 2-3x | 70-80% |
| DFlash | 块级扩散 | 6x+ | 85%+ |
**注意:**DFlash目前已支持Gemma-4-31B,Hugging Face上有官方草稿模型 z-lab/gemma-4-31B-it-DFlash。
使用方法
# SGLang 启用 DFlash
python -m sglang.launch_server \
--model-path google/gemma-4-31b-it \
--speculative-algorithm DFLASH \
--speculative-draft-model-path z-lab/gemma-4-31B-it-DFlash
# vLLM 启用 DFlash
vllm serve google/gemma-4-31b-it \
--speculative-config '{"method": "dflash", "model": "z-lab/gemma-4-31B-it-DFlash"}'
# MLX(Apple Silicon)启用 DFlash
pip install dflash-mlx实测性能:31B到底有多强
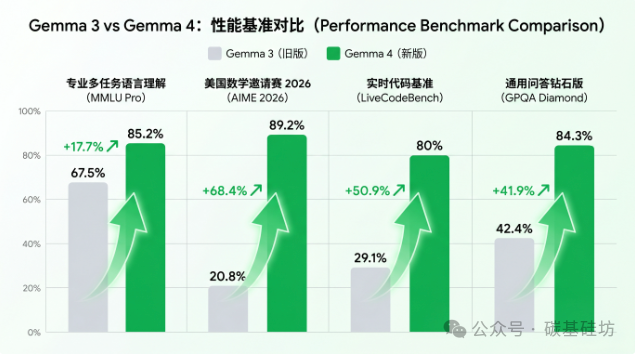
Gemma-4-31B基准测试成绩
Gemma-4-31B在多项基准测试中实现了对前代产品的碾压式超越。在Arena AI全球开放模型排行榜上,以Elo评分1452位列第三,仅次于600B+参数的GLM-5和超过1000亿参数的Kimi 2.5。
| 基准测试 | 得分 | 说明 |
|---|---|---|
| AIME 2026(数学) | 89.2% | 进入闭源旗舰第一梯队 |
| LiveCodeBench(编程) | 80.0% | Codeforces ELO 2150 |
| GPQA Diamond(科学) | 84.3% | 博士级专业知识推理 |
| MMLU Pro(知识) | 85.2% | 系统性多学科知识 |
| τ²-bench(智能体) | 86.4% | 多步工具调用能力 |
实践总结
Gemma-4-31B的出现,标志着开源大模型本地部署进入了新时代。用不到三十分之一的参数量打平600B级别的模型,Apache 2.0开源许可彻底扫清了商业部署的法律障碍。
对于大多数用户,INT4量化版是性价比最优的选择------只需20GB显存,就能在RTX 4060 Ti上获得接近旗舰模型的体验。如果追求极致质量且有高端显卡,INT8量化几乎没有损失。
进阶用户可以尝试MTP或DFlash推测解码------前者实现约3倍加速,后者更进一步可达6倍以上的无损加速。关键是根据自己的硬件条件和延迟需求,选择最适合的方案。
加速技术总结:MTP利用推测解码实现3倍加速,DFlash用块扩散替代自回归草稿可达6倍加速。两者的核心都是"预测+验证"机制,主模型始终保留最终验证权,确保输出质量不打折。