PointPillars 3D 目标检测详解
适用场景:自动驾驶、低速无人车、移动机器人、园区/地铁站巡检机器人等 LiDAR 3D 感知任务。
核心思想:把稀疏无序点云转换成 BEV 伪图像,再用高效 2D CNN 完成 3D 目标检测。
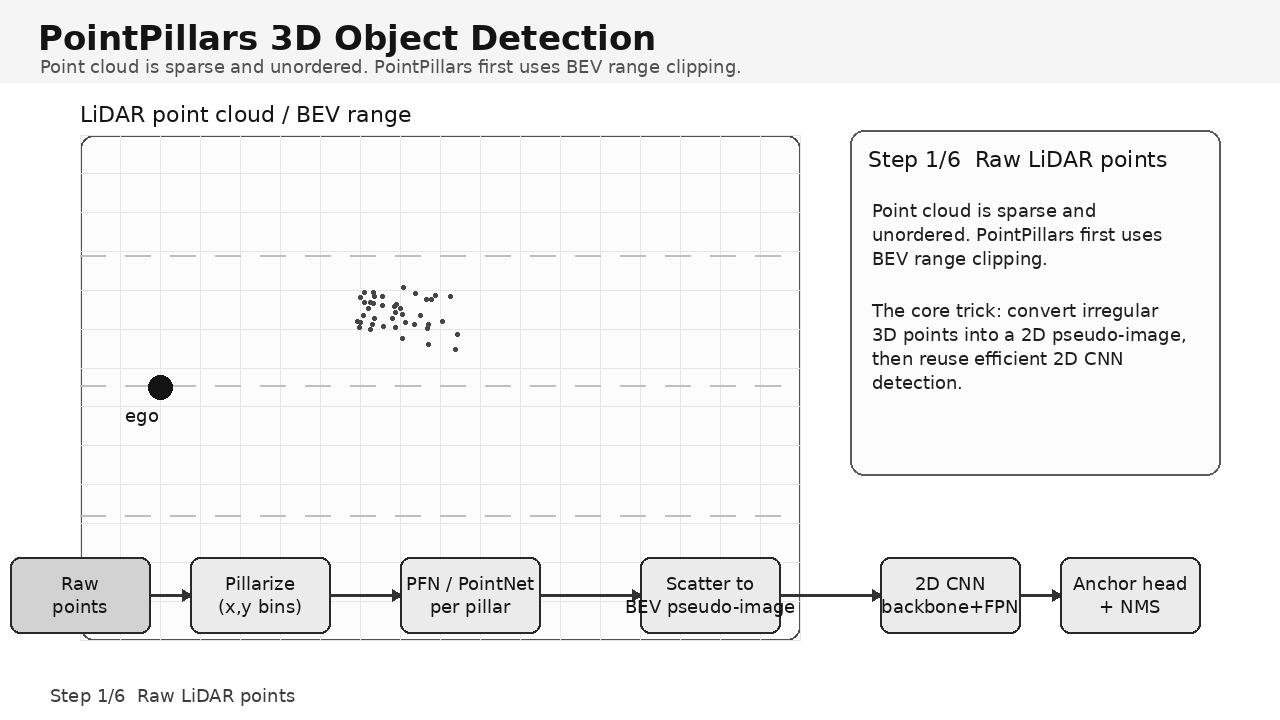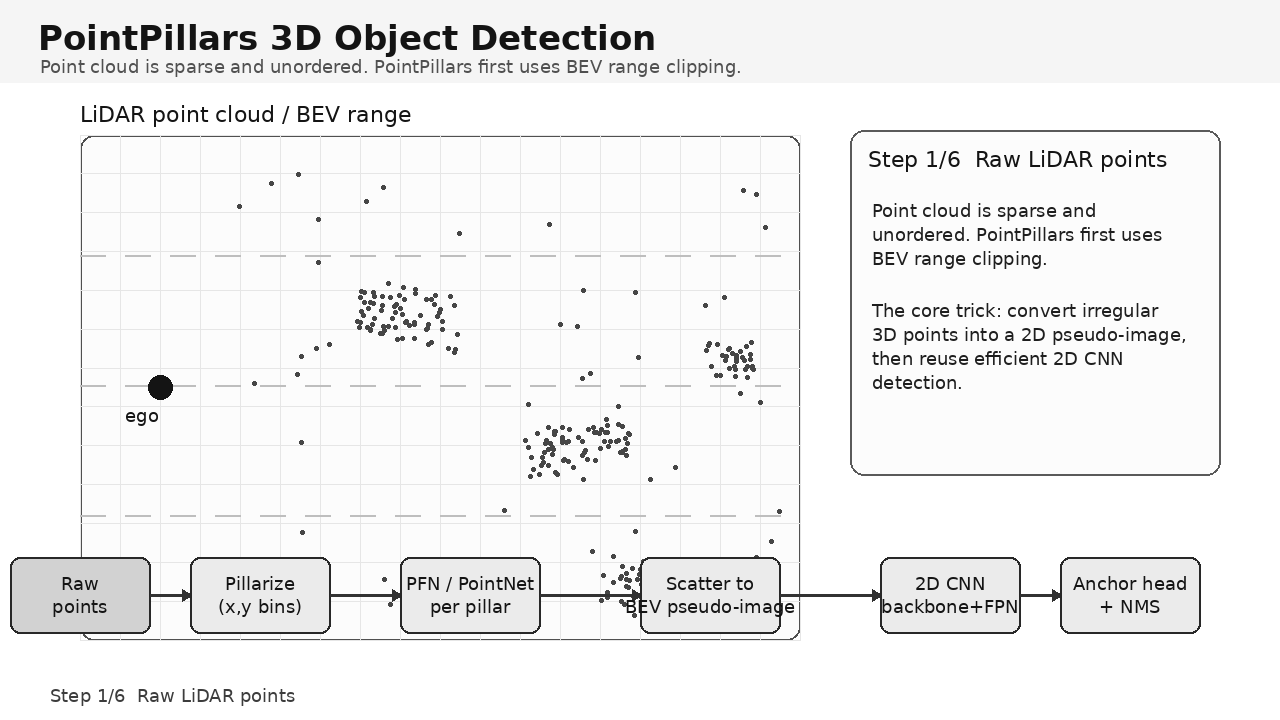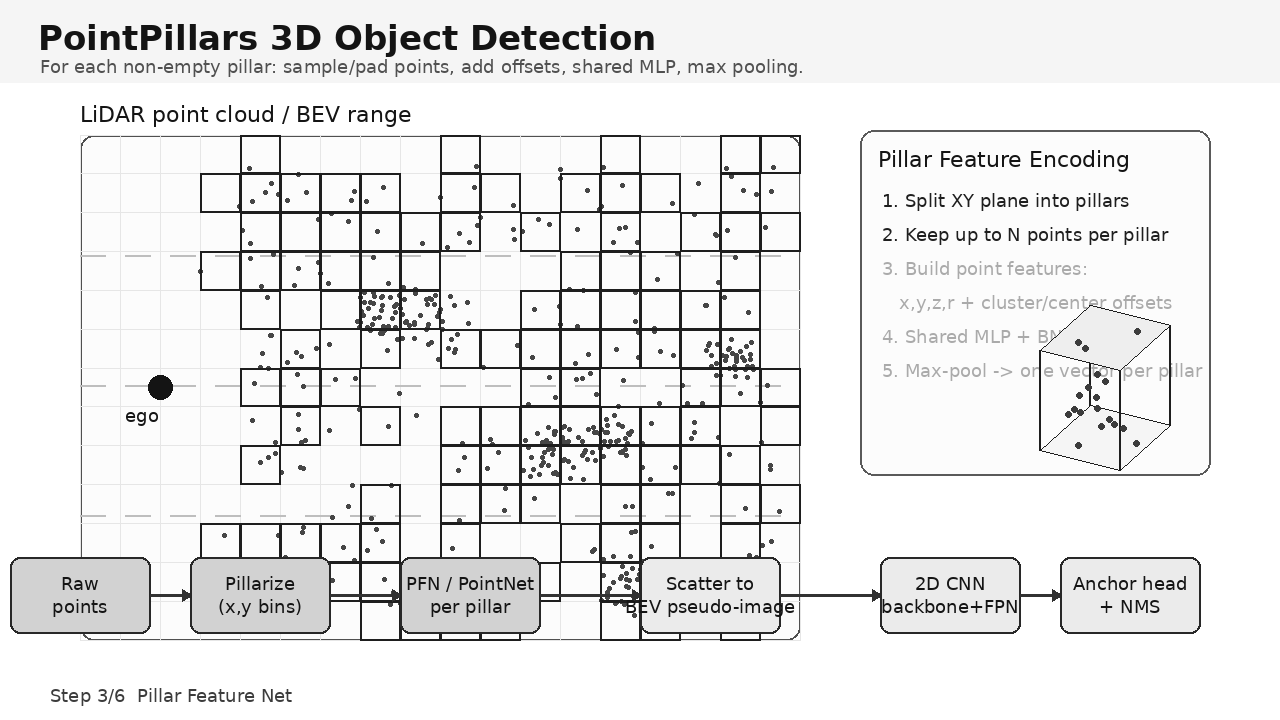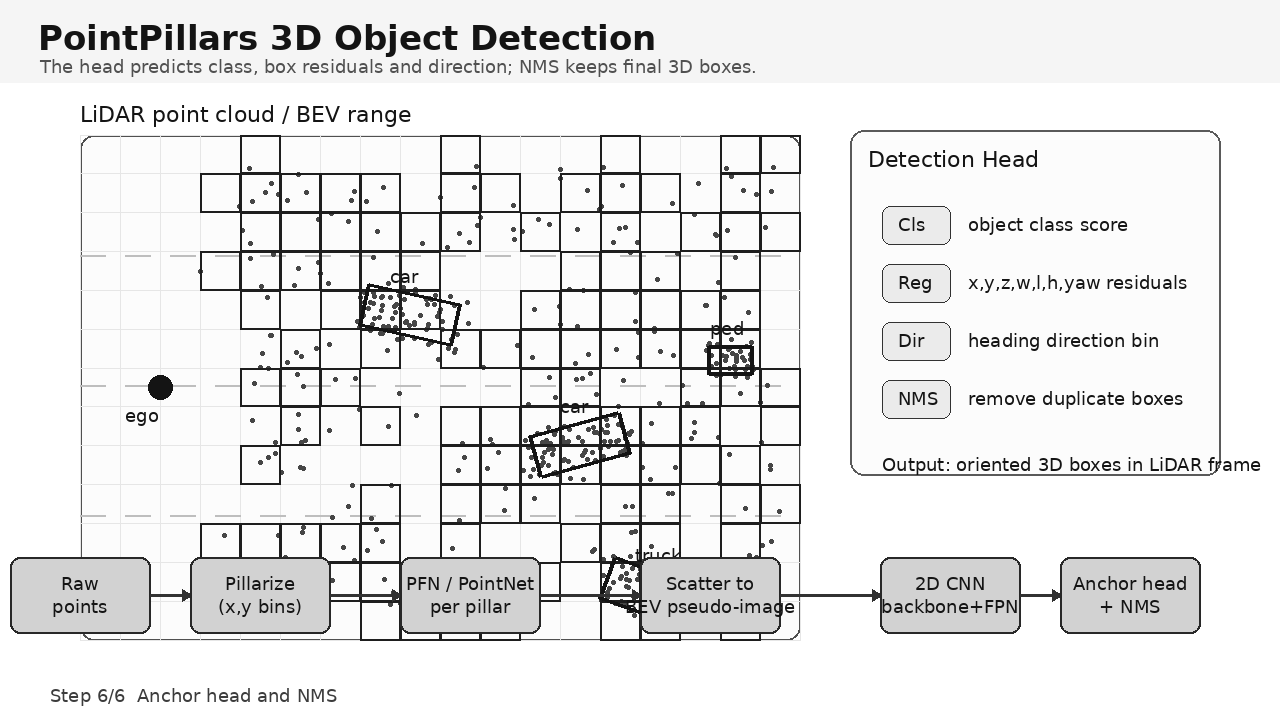
1. PointPillars 解决什么问题?
激光雷达点云天然是稀疏、无序、点数可变的数据。传统 3D 检测常见路线包括:
| 路线 | 表示方式 | 优点 | 缺点 |
|---|---|---|---|
| Point-based | 直接处理点 | 几何细节保留好 | 邻域搜索/采样较慢 |
| Voxel-based | 3D 体素 | 结构规则,适合 3D CNN / sparse CNN | 3D 计算量较大 |
| BEV-based | 俯视图网格 | 快,适合 2D CNN | 高度信息容易损失 |
| PointPillars | XY 柱体 + PointNet 编码 | 快,端到端,部署友好 | 对垂直结构表达弱于完整 3D voxel |
PointPillars 的关键创新是:
不在 Z 方向切分体素,而是在 XY 平面划分柱体 pillar,每个 pillar 覆盖整个高度范围。
这样做可以避免 3D 卷积,把问题压缩成 2D BEV 伪图像检测。
2. 总体网络结构
text
LiDAR points
|
| 1. Range filter
v
Valid points in detection range
|
| 2. Pillarization on XY plane
v
Non-empty pillars
|
| 3. Pillar Feature Net / PFN
v
One feature vector per pillar
|
| 4. Scatter
v
BEV pseudo-image: C x H x W
|
| 5. 2D Backbone + Neck
v
Multi-scale BEV feature map
|
| 6. Detection Head
v
Class score + 3D box residual + direction
|
| 7. Decode + rotated NMS
v
Final 3D detection boxes3. 输入点云与坐标范围
单帧 LiDAR 点云通常表示为:
text
P = {p_i}, p_i = [x_i, y_i, z_i, r_i]其中:
x, y, z:LiDAR 坐标系下的三维位置;r:反射强度 intensity / reflectance;- 点数
N每帧不固定; - 检测前会做范围裁剪,例如只保留车前方或机器人有效感知区域内的点。
典型检测范围可写成:
text
x ∈ [x_min, x_max]
y ∈ [y_min, y_max]
z ∈ [z_min, z_max]4. Pillarization:点云柱体化
PointPillars 在 XY 平面划分网格:
text
pillar_size = [dx, dy]
H = (y_max - y_min) / dy
W = (x_max - x_min) / dx每个网格单元对应一个垂直柱体 pillar:
text
pillar = all points whose x,y fall into the same BEV grid cell与 VoxelNet 不同:
- VoxelNet:
x, y, z三个方向都划分体素; - PointPillars:只划分
x, y,Z 方向不切分。
优点:
- 减少 3D 稀疏卷积或 3D CNN 的计算;
- 输出天然是 2D 网格,适合 2D CNN;
- 对部署更友好,尤其适合 TensorRT / ONNX / C++ 推理。
5. Pillar Feature Net / PFN
每个 pillar 内有若干点。为了批处理,通常设置:
text
P = max_num_pillars
N = max_num_points_per_pillar
D = point_feature_dim形成张量:
text
pillars: [P, N, D]5.1 点特征构造
原始点特征一般包含:
text
[x, y, z, r]PointPillars 会加入相对位置信息:
text
x_c = x - mean_x_of_pillar
y_c = y - mean_y_of_pillar
z_c = z - mean_z_of_pillar
x_p = x - pillar_center_x
y_p = y - pillar_center_y常见增强后特征:
text
[x, y, z, r, x_c, y_c, z_c, x_p, y_p]其中:
cluster offset:点相对 pillar 内点簇中心的偏移;center offset:点相对 pillar 几何中心的偏移;- 这些特征帮助网络理解 pillar 内局部几何形状。
5.2 Shared MLP + Max Pool
每个点经过共享 MLP:
text
point_feature -> shared MLP -> high dimensional feature然后对同一 pillar 内所有点做 max pooling:
text
pillar_feature = max_pool(point_features_in_same_pillar)最终每个非空 pillar 得到一个向量。
6. Scatter:散射成 BEV 伪图像
PFN 输出是稀疏的 pillar 特征:
text
non_empty_pillar_features: [P, C]
pillar_coords: [P, 2]scatter 操作把每个 pillar 特征放回对应的 BEV 网格位置:
text
pseudo_image: [C, H, W]没有点的 pillar 位置填 0。
这一步是 PointPillars 的核心转换:
text
irregular sparse points -> regular dense BEV feature map得到 BEV 伪图像后,后续就可以使用成熟的 2D CNN 检测结构。
7. 2D Backbone + Neck
PointPillars 使用轻量 2D CNN 对 BEV 伪图像提取特征,常见结构为:
text
Block1: Conv2D + BN + ReLU, stride 2
Block2: Conv2D + BN + ReLU, stride 2
Block3: Conv2D + BN + ReLU, stride 2
DeBlock1: upsample
DeBlock2: upsample
DeBlock3: upsample
concat multi-scale featuresBackbone 的作用:
- 扩大感受野;
- 融合局部目标结构与大范围上下文;
- 输出统一尺度的 BEV 特征图给检测头。
8. Anchor-based Detection Head
PointPillars 原始设计使用 anchor-based head。每个 BEV 位置预设若干 anchor:
text
anchor = [x_a, y_a, z_a, w_a, l_a, h_a, yaw_a]检测头通常输出三类信息:
| 分支 | 输出 | 作用 |
|---|---|---|
| Classification | class score | 判断目标类别 |
| Regression | box residual | 回归 3D 框位置、尺寸、朝向 |
| Direction | heading bin | 解决 yaw 角周期性问题 |
3D box 常表示为:
text
box = [x, y, z, w, l, h, yaw]解码后再经过 rotated NMS 得到最终检测框。
9. 损失函数
PointPillars 常用多任务损失:
text
L = L_cls + beta * L_loc + gamma * L_dir其中:
L_cls:分类损失,常用 focal loss;L_loc:3D 框回归损失,常用 Smooth L1;L_dir:方向分类损失;beta、gamma:权重系数。
9.1 分类损失
Focal Loss 常用于缓解正负样本不均衡:
text
FL(p_t) = - alpha_t * (1 - p_t)^gamma * log(p_t)9.2 框回归损失
回归目标一般是 anchor residual:
text
Δx = (x - x_a) / d_a
Δy = (y - y_a) / d_a
Δz = (z - z_a) / h_a
Δw = log(w / w_a)
Δl = log(l / l_a)
Δh = log(h / h_a)
Δθ = sin(θ - θ_a)其中:
text
d_a = sqrt(w_a^2 + l_a^2)10. 推理流程
text
1. 读取 .bin / PointCloud2 点云
2. 坐标范围裁剪
3. 生成 pillars 与 pillar indices
4. PFN 编码每个 pillar
5. Scatter 成 BEV pseudo-image
6. 2D Backbone 提取 BEV 特征
7. Head 输出 cls/reg/dir
8. Decode anchors
9. Score filter
10. Rotated NMS
11. 输出 3D boxes11. 为什么 PointPillars 快?
主要原因:
-
不做 Z 方向 voxel 切分
只在 XY 上划分柱体,减少稀疏结构复杂度。
-
PointNet 编码局部点集
每个 pillar 内用共享 MLP + max pooling,结构简单。
-
转成 2D BEV 伪图像
后续使用高度优化的 2D CNN,比完整 3D CNN 更容易加速。
-
适合工程部署
ONNX / TensorRT / CUDA / C++ 推理路径成熟。
12. 总结
PointPillars 的本质是:
text
用 PointNet 学习每个垂直柱体的局部点云特征,
再把这些 pillar feature 散射成 BEV 伪图像,
最后用高效 2D CNN 做 3D 检测。它不是精度最强的 3D 检测架构,但因为结构简单、速度快、部署友好,非常适合作为机器人和自动驾驶 LiDAR 3D 检测的工程 baseline。