文章目录
- 一、Softmax回归是什么?
- 二、实现方式详解
-
- [2. 模型输出](#2. 模型输出)
- [3.Softmax 函数:把分数变成概率](#3.Softmax 函数:把分数变成概率)
- [4. 预测过程](#4. 预测过程)
-
- [2. 损失函数:交叉熵损失](#2. 损失函数:交叉熵损失)
- 三、优缺点分析
- 四、和逻辑回归的关系
- [Softmax 回归,为啥不直接比较分数,还再转成概率,比较概率?](#Softmax 回归,为啥不直接比较分数,还再转成概率,比较概率?)
-
- [补充:Softmax 指数还有两个关键作用](#补充:Softmax 指数还有两个关键作用)
- [最后:Softmax 回归完整流程](#最后:Softmax 回归完整流程)
一、Softmax回归是什么?
Softmax回归,也叫多项逻辑回归,是逻辑回归在多分类问题上的直接扩展。
- 逻辑回归只能处理二分类(是/否、正/负);
- Softmax回归可以直接处理多分类(比如三分类、十分类,甚至更多类别)。
它的核心思想是:用一个模型,把输入映射成每个类别的概率分布(所有类别的概率和为 1),然后选概率最大的类别作为预测结果。
二、实现方式详解
2. 模型输出
如果有 C C C 个类别,模型会对每个输入 x x x 输出 C C C 个"分数"(也叫 logits),记为 s 1 , s 2 , ... , s C s_1, s_2, \ldots, s_C s1,s2,...,sC,其中:
s j = β j T x s_j = \beta_j^T x sj=βjTx
这里的 β j \beta_j βj 就是第 j j j 个类别对应的模型参数向量。
3.Softmax 函数:把分数变成概率
为了把这些分数变成合法的概率(非负、和为 1),用 Softmax 函数做归一化:
P ( y = c ∣ x ) = e β c T x ∑ j = 1 C e β j T x P(y = c|x) = \frac{e^{\beta_c^T x}}{\sum_{j=1}^{C} e^{\beta_j^T x}} P(y=c∣x)=∑j=1CeβjTxeβcTx
- 分子:当前类别 c c c 的分数取指数 e β c T x e^{\beta_c^T x} eβcTx;
- 分母:所有 C C C 个类别的分数取指数后求和,起到归一化的作用;
- 结果:得到的 P ( y = c ∣ x ) P(y = c|x) P(y=c∣x) 就是输入 x x x 被预测为类别 c c c 的概率,且 ∑ c = 1 C P ( y = c ∣ x ) \sum_{c=1}^{C} P(y = c|x) ∑c=1CP(y=c∣x)
4. 预测过程
对输入 x x x,用模型算出所有类别的概率,直接选概率最大的类别作为预测结果:
y ^ = arg max c = 1 , ... , C P ( y = c ∣ x ) \hat{y}=\arg\max_{c=1,\dots,C} P(y = c|x) y^=argc=1,...,CmaxP(y=c∣x)
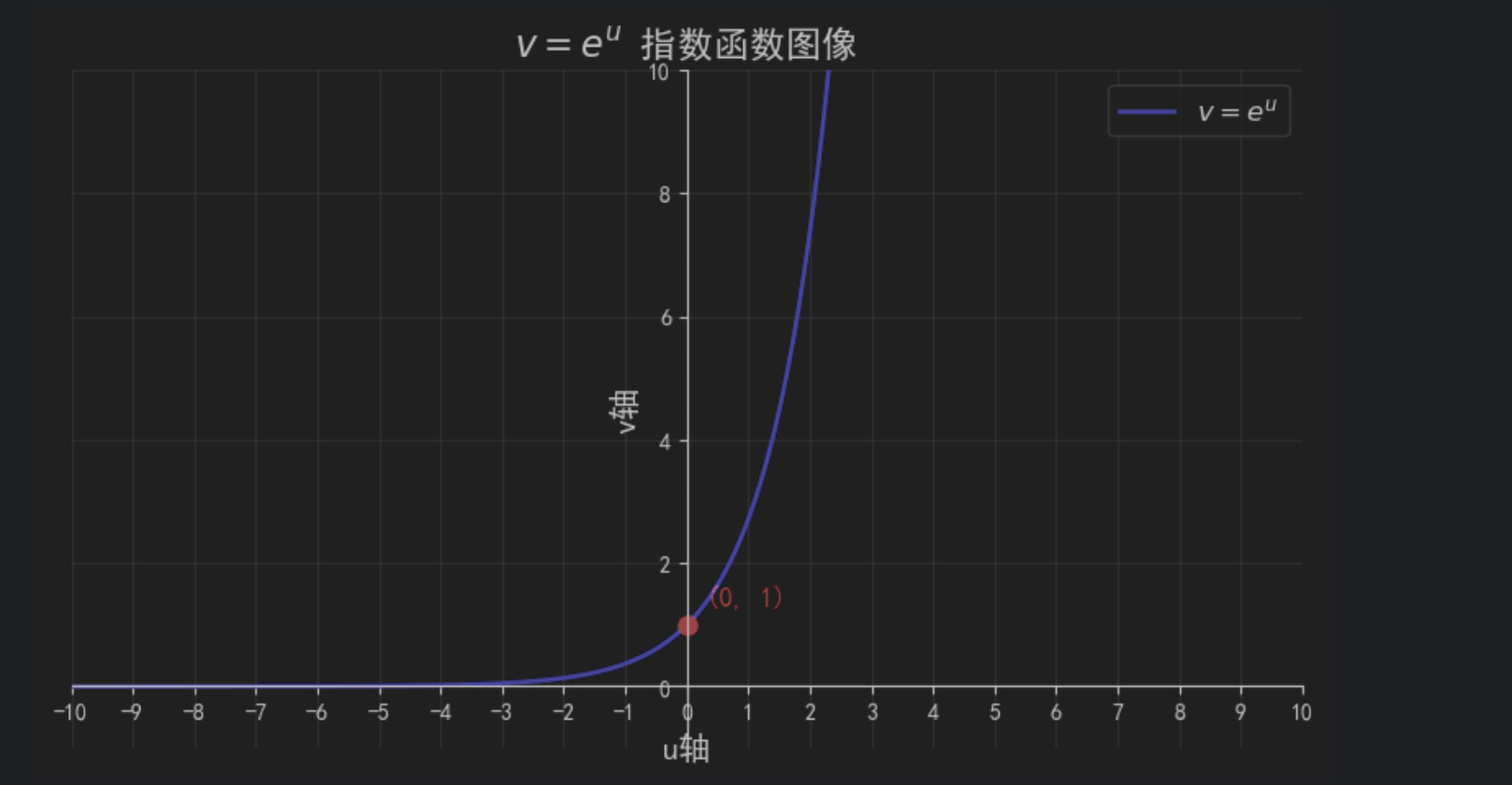
结合指数函数图像,已知 v = e u v = e^u v=eu, 另 u u u = β j T x \beta_j^T x βjTx, u u u表示打的分数,通过以e为底的指数函数转换后,保证及时是负数和或0的分数,对应的转换后的分数值都在0到1的区间内,对于 u u u为正数的分数,以e为底的指数函数会放大,分数大的值,让原始分数高的值,经过指数转换后进行了放大。这样就能保证原始分数在 ( − ∞ , + ∞ ) (-\infty, +\infty) (−∞,+∞)的区间内,经过指数函数转换后都能映射到 ( 0 , + ∞ ) (0, +\infty) (0,+∞)。结合指数函数图像特点,在定义域 ( − ∞ , + ∞ ) (-\infty, +\infty) (−∞,+∞)内单调递增,而且在 ( − ∞ , 0 ) (-\infty, 0) (−∞,0)上,将大负数分数或小正数分数的分数进行惩罚(进行抑制)(将其转换为(0,1]的分数范围内),在 ( 0 , + ∞ ) (0, +\infty) (0,+∞)上,对大正数分数进行奖励(进行放大)(对应的指数函数值,也就是转换后的分数值越大),所以说这是此处使用指数函数的原因。
这里的分数:指的就是打的分数。
2. 损失函数:交叉熵损失
Softmax 回归用的是多分类交叉熵损失,公式如下:
L o s s = − 1 n ∑ i = 1 n ∑ c = 1 C I ( y i = c ) log P ( y i = c ∣ x i ) Loss = -\frac{1}{n} \sum_{i=1}^{n} \sum_{c=1}^{C} I(y_i = c) \log P(y_i = c | x_i) Loss=−n1i=1∑nc=1∑CI(yi=c)logP(yi=c∣xi)
我们把它拆开来解释:
-
n n n:样本总数;
-
I ( y i = c ) I(y_i = c) I(yi=c):示性函数,当第 i i i 个样本的真实标签 y i y_i yi 等于类别 c c c 时,值为 1;否则为 0;
-
内层求和 ∑ c = 1 C I ( y i = c ) log P ( y i = c ∣ x i ) \sum_{c=1}^{C} I(y_i = c) \log P(y_i = c | x_i) ∑c=1CI(yi=c)logP(yi=c∣xi):
因为只有当 c = y i c = y_i c=yi 时,示性函数才为 1,所以这个求和其实只保留了真实类别对应的概率的对数,也就是 log P ( y i ∣ x i ) \log P(y_i | x_i) logP(yi∣xi);
-
外层求和 ∑ i = 1 n \sum_{i=1}^{n} ∑i=1n:把所有样本的损失加起来;
-
前面的负号和平均: − 1 n -\frac{1}{n} −n1 是为了让损失为正数,并做样本平均,方便梯度下降优化。
简单来说,这个损失函数的目标就是:让模型对真实类别的预测概率尽可能接近 1 。当预测完全正确时, P ( y i ∣ x i ) = 1 P(y_i | x_i) = 1 P(yi∣xi)=1,损失为 0;预测越不准,损失越大。
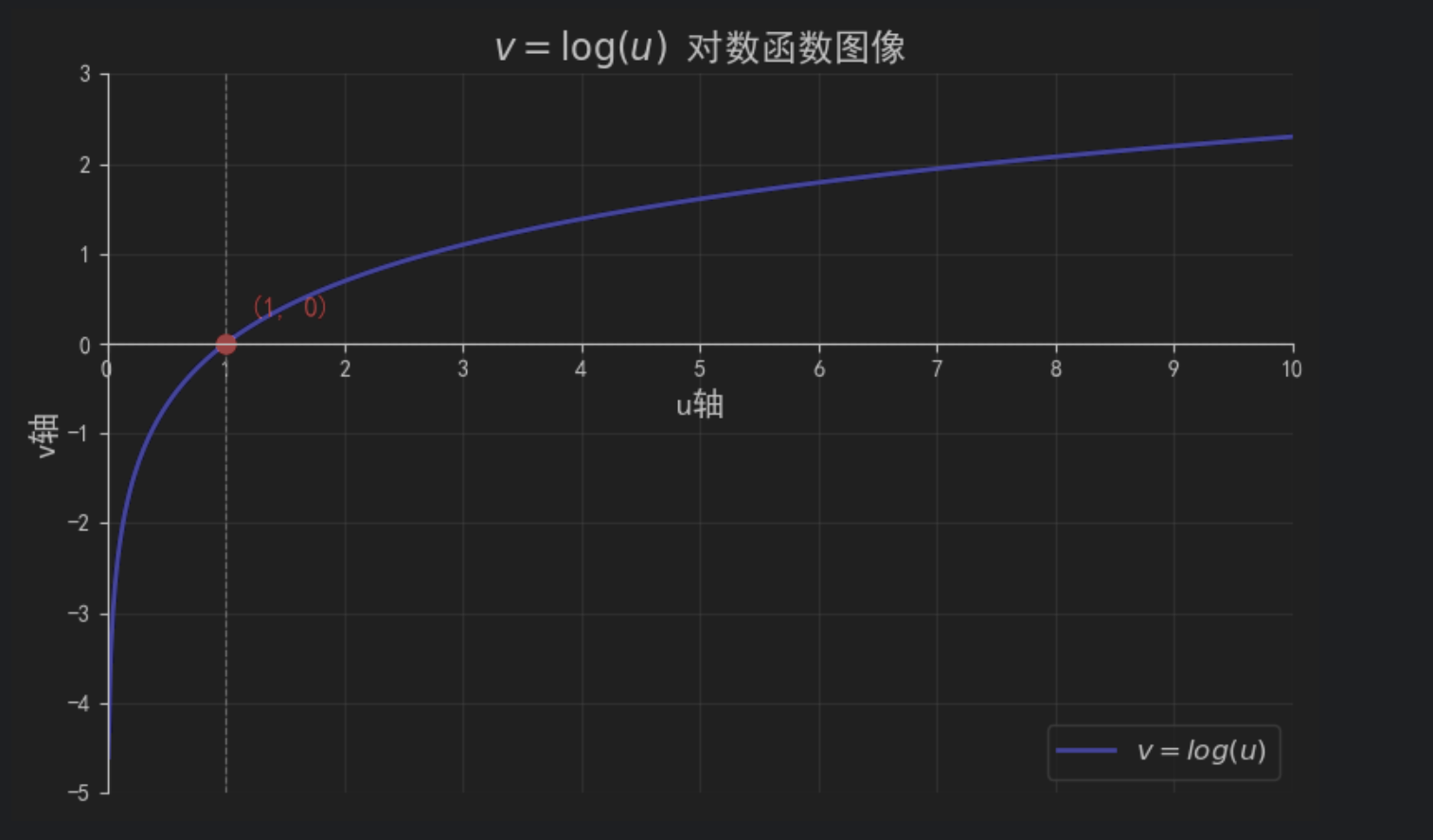
这里的 u = log v u = \log v u=logv,令 v v v = P ( y i = c ∣ x i ) \ P(y_i = c | x_i) P(yi=c∣xi), 因为 P ( y i = c ∣ x i ) \ P(y_i = c | x_i) P(yi=c∣xi)是分数归一化后的概率,其值在0,1区间内,结合对数函数的图像,其对应的 v v v在 ( − ∞ , 0 ) (-\infty, 0) (−∞,0),故使用 v v v来 表示损失,因为 v v v在0,1区间内,越靠近0时,表示其此时的概率越低,对应的 u u u的标量值越大(先不考虑负号),当 v v v在0,1区间内,越靠近1时,表示其此时的概率越高,对应的 u u u的标量值越小(先先不考虑负号)。因为Loss中的, 1 n \frac{1}{n} n1前有一个负号,故累计后的负值的损失函数的值也是正值,所以损失函数还是一个向下凸的一个碗型,通过梯度下降法的迭代训练,可以学到最优的一组 β \beta β。
三、优缺点分析
优点
1. 只训练 1 个模型,计算高效
相比一对多需要训练 C C C 个二分类器,Softmax 回归只训练 1 个模型,训练和预测时的计算量、存储成本都更低。
2. 分类一致性更好
一对多策略可能会出现多个分类器同时判定为正类的冲突情况;而 Softmax 回归直接输出所有类别的概率分布,天然保证"有且只有一个最优类别",不会出现冲突。
缺点
1. Softmax 计算的开销
计算 Softmax 时,需要对所有类别 的分数取指数再求和。当类别数 C C C 很大时(比如上千个类别),指数运算和求和的计算量会显著增加。
(补充)对"不相关类别"敏感:如果数据集中混入了完全不相关的类别,会拉低所有类别的概率,影响模型表现。
四、和逻辑回归的关系
- 当类别数 C = 2 C = 2 C=2 时,Softmax 回归就退化成了普通的二分类逻辑回归:
P ( y = 1 ∣ x ) = e β 1 T x e β 1 T x + e β 2 T x = 1 1 + e ( β 2 − β 1 ) T x P(y = 1|x) = \frac{e^{\beta_1^T x}}{e^{\beta_1^T x}+e^{\beta_2^T x}} = \frac{1}{1+e^{(\beta_2-\beta_1)^T x}} P(y=1∣x)=eβ1Tx+eβ2Txeβ1Tx=1+e(β2−β1)Tx1
这和逻辑回归的 sigmoid 形式完全一致,只是参数表示方式不同而已。
Softmax 回归,为啥不直接比较分数,还再转成概率,比较概率?
一句话结论:选类别时确实可以直接比原始分数 (logits),不用算 Softmax 概率;但算损失、做模型训练、表达置信度必须转成概率



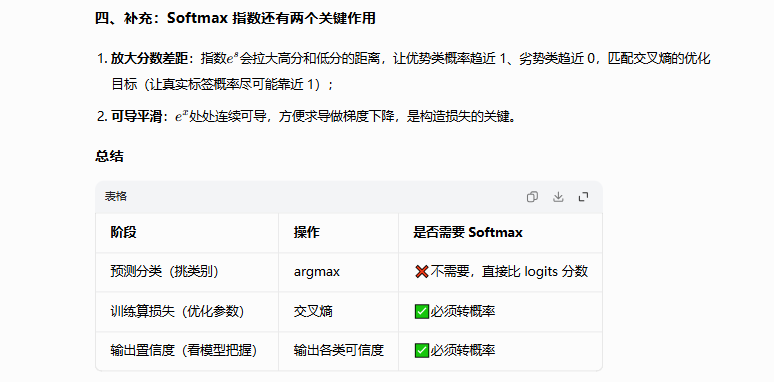
补充:Softmax 指数还有两个关键作用
最后:Softmax 回归完整流程
下面用一张流程图展示 Softmax 回归从输入到输出概率的完整过程:
#mermaid-svg-qJJPbuMetrNIcGcw{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-qJJPbuMetrNIcGcw .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-qJJPbuMetrNIcGcw .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-qJJPbuMetrNIcGcw .error-icon{fill:#552222;}#mermaid-svg-qJJPbuMetrNIcGcw .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-qJJPbuMetrNIcGcw .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-qJJPbuMetrNIcGcw .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-qJJPbuMetrNIcGcw .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-qJJPbuMetrNIcGcw .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-qJJPbuMetrNIcGcw .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-qJJPbuMetrNIcGcw .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-qJJPbuMetrNIcGcw .marker{fill:#333333;stroke:#333333;}#mermaid-svg-qJJPbuMetrNIcGcw .marker.cross{stroke:#333333;}#mermaid-svg-qJJPbuMetrNIcGcw svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-qJJPbuMetrNIcGcw p{margin:0;}#mermaid-svg-qJJPbuMetrNIcGcw .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-qJJPbuMetrNIcGcw .cluster-label text{fill:#333;}#mermaid-svg-qJJPbuMetrNIcGcw .cluster-label span{color:#333;}#mermaid-svg-qJJPbuMetrNIcGcw .cluster-label span p{background-color:transparent;}#mermaid-svg-qJJPbuMetrNIcGcw .label text,#mermaid-svg-qJJPbuMetrNIcGcw span{fill:#333;color:#333;}#mermaid-svg-qJJPbuMetrNIcGcw .node rect,#mermaid-svg-qJJPbuMetrNIcGcw .node circle,#mermaid-svg-qJJPbuMetrNIcGcw .node ellipse,#mermaid-svg-qJJPbuMetrNIcGcw .node polygon,#mermaid-svg-qJJPbuMetrNIcGcw .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-qJJPbuMetrNIcGcw .rough-node .label text,#mermaid-svg-qJJPbuMetrNIcGcw .node .label text,#mermaid-svg-qJJPbuMetrNIcGcw .image-shape .label,#mermaid-svg-qJJPbuMetrNIcGcw .icon-shape .label{text-anchor:middle;}#mermaid-svg-qJJPbuMetrNIcGcw .node .katex path{fill:#000;stroke:#000;stroke-width:1px;}#mermaid-svg-qJJPbuMetrNIcGcw .rough-node .label,#mermaid-svg-qJJPbuMetrNIcGcw .node .label,#mermaid-svg-qJJPbuMetrNIcGcw .image-shape .label,#mermaid-svg-qJJPbuMetrNIcGcw .icon-shape .label{text-align:center;}#mermaid-svg-qJJPbuMetrNIcGcw .node.clickable{cursor:pointer;}#mermaid-svg-qJJPbuMetrNIcGcw .root .anchor path{fill:#333333!important;stroke-width:0;stroke:#333333;}#mermaid-svg-qJJPbuMetrNIcGcw .arrowheadPath{fill:#333333;}#mermaid-svg-qJJPbuMetrNIcGcw .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-qJJPbuMetrNIcGcw .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-qJJPbuMetrNIcGcw .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-qJJPbuMetrNIcGcw .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-qJJPbuMetrNIcGcw .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-qJJPbuMetrNIcGcw .labelBkg{background-color:rgba(232, 232, 232, 0.5);}#mermaid-svg-qJJPbuMetrNIcGcw .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-qJJPbuMetrNIcGcw .cluster text{fill:#333;}#mermaid-svg-qJJPbuMetrNIcGcw .cluster span{color:#333;}#mermaid-svg-qJJPbuMetrNIcGcw div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-qJJPbuMetrNIcGcw .flowchartTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-qJJPbuMetrNIcGcw rect.text{fill:none;stroke-width:0;}#mermaid-svg-qJJPbuMetrNIcGcw .icon-shape,#mermaid-svg-qJJPbuMetrNIcGcw .image-shape{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-qJJPbuMetrNIcGcw .icon-shape p,#mermaid-svg-qJJPbuMetrNIcGcw .image-shape p{background-color:rgba(232,232,232, 0.8);padding:2px;}#mermaid-svg-qJJPbuMetrNIcGcw .icon-shape .label rect,#mermaid-svg-qJJPbuMetrNIcGcw .image-shape .label rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-qJJPbuMetrNIcGcw .label-icon{display:inline-block;height:1em;overflow:visible;vertical-align:-0.125em;}#mermaid-svg-qJJPbuMetrNIcGcw .node .label-icon path{fill:currentColor;stroke:revert;stroke-width:revert;}#mermaid-svg-qJJPbuMetrNIcGcw :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} 输入特征 x
线性层
z = βᵀx
分数向量 z
(每个类别一个分数)
Softmax 归一化
P(c|x) = e^z_c / Σ e^z_j
概率分布
(非负且和为 1)
取最大概率类别
作为预测结果
流程说明:
- 输入特征 :将样本的特征向量 x x x 输入模型。
- 线性层 :每个类别对应一组权重 β c \beta_c βc,计算线性得分 z c = β c T x z_c = \beta_c^T x zc=βcTx,得到长度为 C C C(类别数)的分数向量。
- Softmax 归一化 :对分数向量应用 Softmax 函数,将每个分数转换为 ( 0 , 1 ) (0,1) (0,1) 区间内的概率值,且所有类别的概率之和为 1。
- 输出概率 :得到每个类别的预测概率 P ( y = c ∣ x ) P(y=c|x) P(y=c∣x)。
- 预测决策:选择概率最大的类别作为最终的分类结果。