整体介绍
在本地搭建一个能听、能说、有形象的 AI 数字人,曾经是只有大型实验室才能玩转的黑科技。但随着开源社区的爆发式增长,现在只要有一台配置尚可的个人电脑,普通开发者也能在几个小时内让虚拟角色"活"起来。很多同学在尝试过程中,往往卡在环境依赖的迷宫里,或者模型加载后迟迟无法开口,甚至因为显存溢出导致程序直接崩溃。这些痛点不仅消磨热情,更让人误以为本地部署高不可攀。
其实,只要理清核心链路,把大语言模型、语音合成与形象驱动这三个模块像搭积木一样精准对接,整个过程并没有想象中那么复杂。关键在于如何选择合适的轻量级模型,以及如何调整参数以适配自己的硬件资源。无论是想做一个个性化的桌面助手,还是为直播互动增加智能 NPC,这套本地化方案都能提供极高的自由度和隐私安全性,完全不需要依赖云端 API。
接下来,我们将一步步拆解从环境检查到最终稳定运行的全流程。我会结合实际操作中遇到的坑,分享具体的配置技巧和调优策略,帮你避开那些隐蔽的兼容性问题。无论你是刚接触本地 AI 的新手,还是希望优化现有项目的进阶用户,都能从中找到落地的解决方案,让你的虚拟形象真正具备实时交互的灵魂。
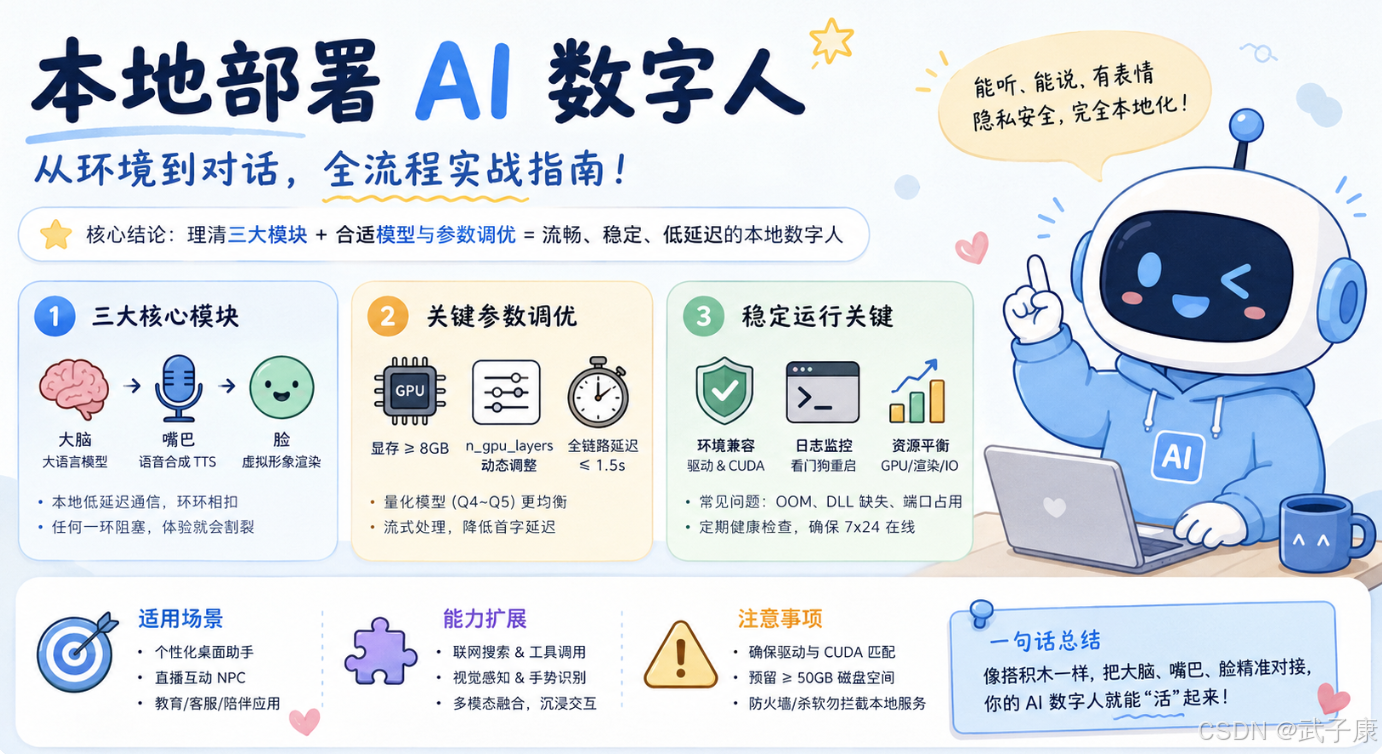
① 核心功能解析与环境前置检查
在动手之前,我们必须先搞清楚整个系统的运作骨架。一个完整的本地交互式数字人系统,本质上是由三个核心引擎协同工作的:大脑(大语言模型)、嘴巴(语音合成 TTS)和脸(虚拟形象渲染)。大脑负责理解你的输入并生成回复文本;嘴巴将文本转化为自然的音频流;而脸则根据音频的口型数据或预设动作,驱动 3D 或 2D 模型进行表情演绎。这三者之间通过本地 socket 或共享内存进行低延迟通信,任何一环的阻塞都会导致互动体验的割裂。
工欲善其事,必先利其器。硬件层面,显卡是绝对的核心。虽然 CPU 也能运行量化后的模型,但为了保证实时对话的流畅度,建议至少拥有一张显存大于 8GB 的 NVIDIA 显卡。如果你打算运行参数量较大的模型或高分辨率的实时渲染,12GB 乃至 16GB 显存会更从容。软件层面,操作系统的选择直接影响驱动兼容性,Windows 10/11 专业版或 Ubuntu 20.04 以上版本是目前社区支持最完善的两个平台。
此外,必须提前确认 CUDA toolkit 的版本是否与你的显卡驱动匹配。很多初学者忽略了这一点,直接安装最新版框架,结果导致底层调用失败。你可以使用 nvidia-smi 命令查看当前驱动支持的 CUDA 最高版本,并确保后续安装的 PyTorch 或其他深度学习框架与之对应。同时,检查磁盘空间,预留至少 50GB 的可用空间用于存放模型权重文件和缓存,避免下载中途因空间不足而报错。
② 一键安装脚本执行与依赖配置
面对繁杂的 Python 依赖库,手动逐个安装不仅效率低下,还极易引发版本冲突。目前主流的开源自托管项目都提供了标准化的一键安装脚本,这是启动项目最稳妥的方式。这些脚本通常会自动检测系统环境,创建独立的虚拟环境(如 Conda 或 venv),并按顺序安装经过验证的依赖包。
在执行脚本前,建议先清理掉系统中可能存在的旧版冲突库。以 Linux 环境为例,你可以创建一个名为 digital-human 的独立环境:
bash
conda create -n digital-human python=3.10 -y
conda activate digital-human激活环境后,运行项目根目录下的 install.sh 或 setup.bat。脚本内部通常会执行类似以下的逻辑来锁定关键库的版本:
bash
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install -r requirements.txt这里需要特别注意 requirements.txt 中的版本约束。如果脚本执行过程中出现某些库编译失败的情况,大概率是因为缺少系统级的构建工具。在 Ubuntu 上,你可能需要预先运行 sudo apt-get install build-essential cmake ffmpeg 来补齐基础工具链;而在 Windows 上,确保安装了最新的 Visual C++ Redistributable 运行库。一旦依赖安装完成,务必进行一次简单的导入测试,运行 python -c "import torch; print(torch.cuda.is_available())",若输出 True,则说明环境已就绪,可以进入下一步。
③ 大语言模型本地加载与参数调优
模型的选择直接决定了数字人的"智商"和响应速度。在本地资源受限的情况下,盲目追求大参数量模型是不明智的。目前,7B 到 14B 参数量级的量化模型(如 Q4_K_M 或 Q5_K_M 格式)在消费级显卡上表现最为均衡。它们既能保持不错的逻辑推理能力,又能将显存占用控制在合理范围,留出余量给语音和渲染模块。
加载模型时,我们通常使用 llama.cpp 或 vLLM 等推理后端。以下是一个基于 Python 调用本地模型的最小化示例,展示了如何设置上下文长度和生成参数:
python
from llama_cpp import Llama
# 加载量化后的模型文件
llm = Llama(
model_path="./models/qwen2.5-7b-instruct-q4_k_m.gguf",
n_ctx=4096, # 上下文窗口大小
n_threads=8, # CPU 线程数,辅助处理
n_gpu_layers=35 # 卸载到 GPU 的层数,根据显存动态调整
)
def generate_response(prompt):
output = llm(
prompt,
max_tokens=256, # 限制单次回复长度,降低延迟
temperature=0.7, # 创造性参数,过高会导致胡言乱语
top_p=0.9, # 核采样概率
stop=["User:", "\n\n"]
)
return output['choices'][0]['text']参数调优是提升体验的关键。n_gpu_layers 是最需要精细调整的项:如果你的显存充裕,可以将该值设为模型总层数以实现全 GPU 加速;若显存紧张,适当减少该数值,让部分层在 CPU 上运行,虽然会略微增加延迟,但能防止显存溢出导致的崩溃。temperature 参数建议设置在 0.6 到 0.8 之间,过低会让回答显得呆板机械,过高则容易产生幻觉。对于对话场景,max_tokens 不宜过大,控制在 200-300 字以内能保证互动的节奏感。
④ 虚拟形象绑定与实时语音驱动
有了聪明的"大脑",接下来要赋予它生动的"外表"和"声音"。虚拟形象的驱动主要依赖于面部捕捉算法或音素对口型技术(Viseme)。在本地部署中,基于音频驱动口型的方式更为常见且资源消耗更低。我们需要选择一个支持实时推流的渲染引擎,如 Unity 配合 Live2D 或 Unreal Engine 的 MetaHuman,亦或是轻量级的 WebGL 方案。
语音合成部分,推荐使用开源的 VITS 或 Coqui TTS 架构,它们能够生成情感丰富且自然的语音。关键在于如何将 TTS 生成的音频流实时传递给渲染引擎。大多数方案采用 WebSocket 或共享内存队列来传输音频数据和对应的口型时间戳。
配置时,需在设置文件中指定麦克风输入设备和扬声器输出设备,避免回声干扰。如果是使用预录制的音色,确保采样率与渲染引擎一致(通常为 22050Hz 或 48000Hz)。在绑定环节,需要将特定的音素映射到模型的面部 Blendshapes 权重上。例如,当检测到"a"音时,自动增加下巴下沉和嘴巴张开的权重。现在的开源项目通常内置了通用的映射表,但你仍需在配置文件中进行微调,以确保不同语种下的口型同步率。如果发现口型滞后,可以尝试减小音频缓冲区的 size,但这可能会增加卡顿的风险,需要在流畅度和同步性之间找到平衡点。
⑤ 构建首个交互式对话测试场景
环境就绪、模型加载、形象绑定完成后,我们来构建第一个完整的闭环测试场景。这个场景的目标很简单:用户对着麦克风说话,系统识别语音,大模型思考并回复,TTS 合成声音,最后数字人张嘴说话并伴随表情。
为了验证链路通畅,我们可以编写一个简单的串联脚本。首先启动语音识别服务(如 Whisper 本地版),监听麦克风输入;一旦检测到静音片段结束,立即将音频转为文本发送给大模型;拿到回复文本后,立刻推送给 TTS 引擎;TTS 生成音频的同时,解析出音素序列发送给渲染端。
python
# 伪代码示例:展示核心交互流程
def interaction_loop():
while True:
# 1. 监听并识别语音
user_audio = record_audio()
user_text = speech_to_text(user_audio)
if not user_text:
continue
print(f"用户说:{user_text}")
# 2. 大模型生成回复
bot_text = generate_response(f"User: {user_text}\nAssistant:")
print(f"AI 回:{bot_text}")
# 3. 语音合成与驱动
audio_stream, visemes = text_to_speech(bot_text)
play_audio_and_animate(audio_stream, visemes)在首次运行时,请密切观察控制台日志。重点关注每个环节的耗时:语音识别是否在 1 秒内完成?模型生成首字延迟(TTFT)是否在可接受范围内?音频播放是否有断裂?如果某个环节耗时过长,整个对话就会显得极其不自然。此时不要急于优化代码,先确认是否是硬件瓶颈,比如 GPU 是否被其他程序占用,或者磁盘 IO 是否成为了读取模型的瓶颈。
⑥ 自定义人设提示词与行为逻辑
一个没有个性的数字人只是冰冷的复读机。要让角色鲜活起来,必须精心设计 System Prompt(系统提示词)。这不仅包括角色的背景故事、性格特征,还应包含对话的风格规范和禁忌事项。
在提示词工程中,采用"角色 + 任务 + 约束 + 示例"的结构效果最佳。例如,如果你想打造一个幽默的极客助手,提示词可以这样写:
"你是一个拥有 10 年经验的资深程序员,性格幽默风趣,喜欢用代码梗开玩笑。回答问题时要简洁明了,避免长篇大论的说教。如果用户问的问题太简单,可以适度调侃但不要冒犯。严禁讨论政治敏感话题。
示例:
用户:'Hello World'怎么写?
你:'print("Hello World")',看,就是这么简单,就像你早上起床刷牙一样自然。"
除了语言风格,还可以定义行为逻辑。比如在检测到用户情绪低落时,主动切换为安慰模式;或者在长时间无交互时,主动发起闲聊。这可以通过在提示词中加入状态判断指令来实现,或者在外层代码中根据情感分析结果动态插入额外的上下文信息。记得在每次对话开始时,将这些人设指令作为固定的前缀发送给模型,确保其始终保持在角色设定中,不会随着对话轮数的增加而"失忆"或偏离人设。
⑦ 常见启动报错与兼容性排查
在本地部署过程中,报错是家常便饭。最常见的问题莫过于显存不足(OOM)。当程序抛出 CUDA out of memory 错误时,首先检查是否同时加载了多个大模型,或者开启了过高的分辨率渲染。解决方法包括减小模型的量化精度(从 Q8 降到 Q4)、减少 n_gpu_layers 的数量,或者关闭不必要的后台图形特效。
其次是动态链接库缺失问题,特别是在 Windows 环境下,经常遇到 DLL load failed。这通常是因为缺少对应的 VC++ 运行库或 CUDA 组件。此时不要盲目重装系统,建议使用 Dependency Walker 等工具检查具体缺失的 DLL 文件,并根据提示信息安装对应的运行库。
还有一个容易被忽视的问题是端口占用。数字人系统通常涉及多个服务(WebUI、API 服务、渲染引擎),它们默认可能都监听 8000 或 5000 端口。启动前,使用 netstat -ano | findstr :端口号 检查端口占用情况,并在配置文件中修改冲突服务的端口号。如果遇到模型加载缓慢甚至卡死,检查防火墙是否拦截了本地回环请求,或者杀毒软件是否误删了某些推理引擎的动态库文件。
⑧ 互动延迟优化与资源占用平衡
实时交互的核心指标是延迟。从用户说完话到数字人开始发声,理想的全链路延迟应控制在 1.5 秒以内。要实现这一目标,必须采用流式处理(Streaming)策略。不要让大模型生成完全部文本后再交给 TTS,而是每当模型生成出一个完整的句子或标点符号,就立即截取这段文本发送给 TTS 引擎进行预合成。
同样,TTS 也不需要等整段音频生成完毕再播放,而是采用边生成边播放的模式。这种流水线作业能显著降低首字延迟。在资源占用方面,需要监控 GPU 的显存和算力分配。如果渲染占据了过多的 CUDA 核心,会导致推理速度下降。可以尝试在渲染设置中限制最大帧率(如锁定 30fps),或者将渲染任务切换到集成显卡(如果系统支持多 GPU 调度),从而将独立显卡的计算力完全留给 AI 推理。
此外,调整音频缓冲区大小也是优化手段之一。较小的缓冲区能降低延迟,但会增加 CPU 中断频率,可能导致音频卡顿;较大的缓冲区则相反。建议从默认的 512 样本开始测试,逐步下调直到听到爆音,然后回调一档,找到当前硬件的最佳平衡点。
⑨ 进阶插件扩展与多模态融合
当基础对话跑通后,我们可以通过插件系统赋予数字人更多能力。最常见的扩展是联网搜索和工具调用。通过 Function Calling 机制,大模型可以识别用户意图,主动调用本地脚本去查询天气、控制智能家居,甚至在数据库中检索信息。
多模态融合则是另一个进阶方向。除了语音和文本,还可以引入视觉感知。接入摄像头后,利用开源的人脸识别或手势识别模型,让数字人能"看"到用户的动作。例如,当检测到用户挥手时,数字人自动打招呼;当检测到用户皱眉时,主动询问是否需要帮助。这种双向的感知交互能极大提升沉浸感。实现这一点通常需要引入额外的视觉推理管道,并将识别结果作为上下文的一部分实时注入到大模型的 Prompt 中。
⑩ 长期运行稳定性维护策略
搭建好系统只是第一步,如何让数字人 7x24 小时稳定运行才是考验。内存泄漏是长期运行的大敌,尤其是 Python 编写的胶水代码,长时间运行后容易积累碎片。建议采用容器化部署(如 Docker),并设置看门狗脚本(Watchdog),定期监测进程的内存占用。一旦发现超过阈值,自动重启服务,确保持续可用。
日志管理也至关重要。不要将所有日志无限追加到一个文件中,应按天切割,并设置保留策略,只保留最近一周的详细日志,避免磁盘被撑爆。对于模型文件,定期校验完整性,防止因硬盘坏道导致权重文件损坏。最后,建立一个简单的健康检查接口,每隔几分钟自动发送一个心跳请求,验证从语音输入到形象输出的全链路是否畅通,一旦发现问题立即报警通知,这样才能确保你的数字人伙伴始终在线,随时待命。