C++ 线程池完整实现指南:从原理到生产级代码
前言
在上一篇文章中,我们全面学习了C++标准线程库的基础用法。但在实际项目中,直接创建大量std::thread对象会带来严重的性能问题:
- 线程创建和销毁的开销巨大(涉及内核态与用户态切换)
- 过多线程会导致CPU频繁切换上下文,降低整体效率
- 无法有效控制并发数量,可能导致系统资源耗尽
线程池正是解决这些问题的最佳方案。它通过预先创建一组可复用的线程,将任务提交到队列中等待执行,从而避免了频繁创建销毁线程的开销,同时能精确控制系统的并发度。
本文将带你从零实现一个生产级可用的C++线程池,涵盖核心原理、完整代码实现、使用示例以及高级优化技巧。
一、线程池核心原理
1.1 线程池的基本架构
一个标准的线程池由以下四个核心组件组成:
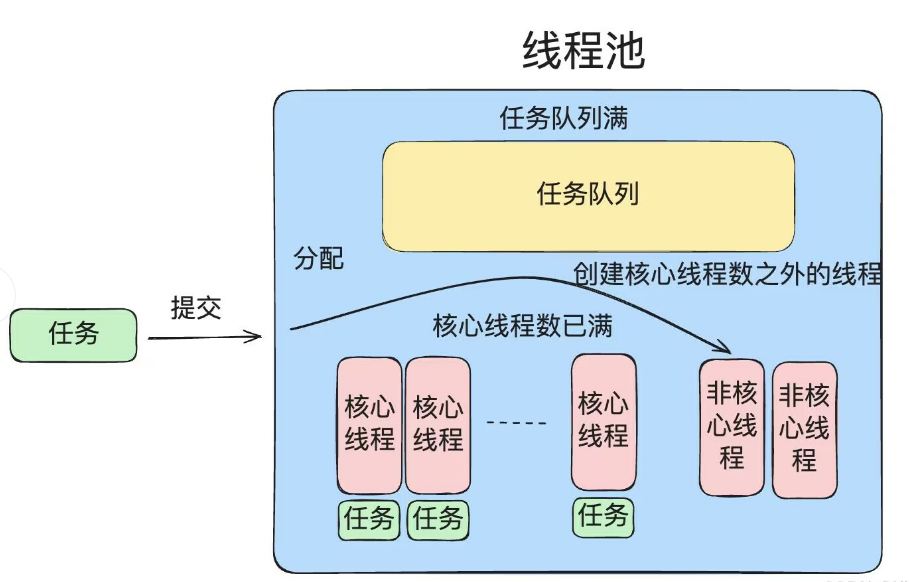
- 任务队列:存储用户提交的待执行任务
- 工作线程:不断从任务队列中取出任务并执行
- 线程池管理器:负责创建、销毁线程池,管理任务队列
- 同步机制:保证任务队列的线程安全,实现线程间的通信
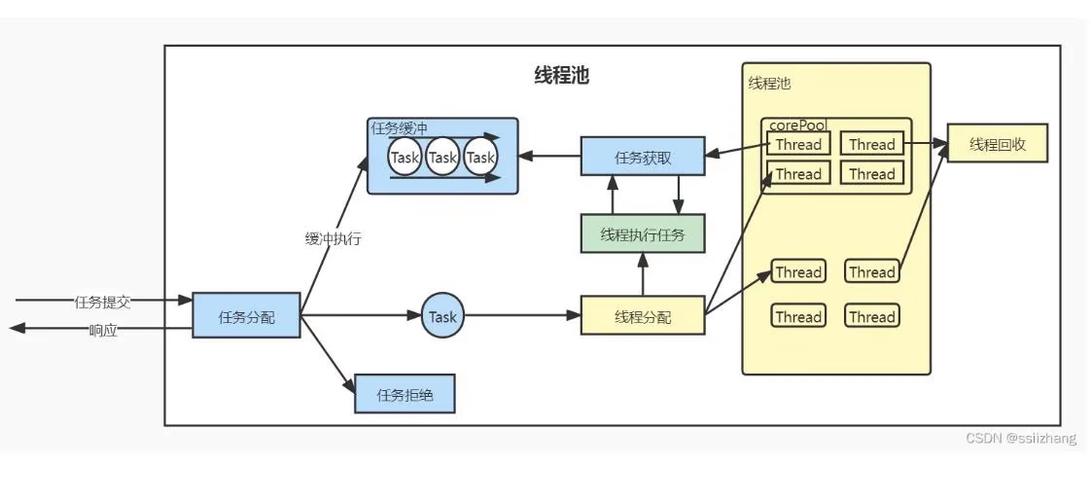
1.2 线程池的工作流程
- 初始化线程池,创建指定数量的工作线程
- 用户提交任务到任务队列
- 空闲的工作线程从队列中取出任务并执行
- 任务执行完毕后,线程继续等待新任务
- 线程池销毁时,先等待所有任务执行完毕,再退出所有线程
二、完整线程池实现
我们将实现一个功能完善、接口友好的线程池,支持:
- 任意类型的可调用对象(函数、lambda、成员函数)
- 获取任务的返回值
- 自动管理线程生命周期
- 线程安全的任务提交和执行
2.1 头文件与前置声明
cpp
#ifndef THREAD_POOL_H
#define THREAD_POOL_H
#include <iostream>
#include <vector>
#include <queue>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <future>
#include <functional>
#include <stdexcept>
class ThreadPool {
public:
// 构造函数:创建指定数量的工作线程
ThreadPool(size_t threads);
// 提交任务到线程池
template<class F, class... Args>
auto enqueue(F&& f, Args&&... args)
-> std::future<typename std::result_of<F(Args...)>::type>;
// 析构函数:等待所有线程执行完毕
~ThreadPool();
private:
// 工作线程容器
std::vector<std::thread> workers;
// 任务队列
std::queue<std::function<void()>> tasks;
// 同步机制
std::mutex queue_mutex;
std::condition_variable condition;
// 线程池停止标志
bool stop;
};
#endif // THREAD_POOL_H2.2 构造函数实现
构造函数的核心是创建指定数量的工作线程,每个线程都运行一个无限循环,不断从任务队列中取出任务执行。
cpp
ThreadPool::ThreadPool(size_t threads) : stop(false) {
for (size_t i = 0; i < threads; ++i) {
workers.emplace_back(
[this]() {
// 工作线程主循环
while (true) {
std::function<void()> task;
{
// 加锁,保护任务队列
std::unique_lock<std::mutex> lock(this->queue_mutex);
// 等待条件:线程池停止 或 任务队列不为空
this->condition.wait(lock,
[this]() { return this->stop || !this->tasks.empty(); });
// 如果线程池停止且任务队列为空,则退出线程
if (this->stop && this->tasks.empty()) {
return;
}
// 取出任务
task = std::move(this->tasks.front());
this->tasks.pop();
}
// 执行任务(注意:执行任务时不持有锁,提高并发性)
task();
}
}
);
}
}关键细节:
- 使用
std::unique_lock而不是std::lock_guard,因为wait()需要解锁和重新加锁的能力 wait()的第二个参数是谓词,用于防止虚假唤醒(spurious wakeup)- 执行任务时不持有锁,这是提高线程池并发性能的关键
2.3 任务提交函数实现
这是线程池最复杂也最核心的部分。我们需要支持任意类型的可调用对象和参数,并返回一个std::future对象用于获取返回值。
cpp
template<class F, class... Args>
auto ThreadPool::enqueue(F&& f, Args&&... args)
-> std::future<typename std::result_of<F(Args...)>::type> {
// 推导任务的返回类型
using return_type = typename std::result_of<F(Args...)>::type;
// 创建一个packaged_task,包装函数和参数
auto task = std::make_shared<std::packaged_task<return_type()>>(
std::bind(std::forward<F>(f), std::forward<Args>(args)...)
);
// 获取future对象,用于返回给调用者
std::future<return_type> res = task->get_future();
{
std::unique_lock<std::mutex> lock(queue_mutex);
// 禁止向已停止的线程池提交任务
if (stop) {
throw std::runtime_error("enqueue on stopped ThreadPool");
}
// 将任务添加到队列中
tasks.emplace([task]() { (*task)(); });
}
// 唤醒一个等待的工作线程
condition.notify_one();
return res;
}核心技术解析:
std::result_of:编译期推导函数调用的返回类型std::packaged_task:将可调用对象包装成一个异步任务,关联一个std::futurestd::bind与完美转发:将函数和参数绑定,支持任意数量和类型的参数std::shared_ptr:因为std::packaged_task是不可复制的,所以用智能指针管理其生命周期
2.4 析构函数实现
析构函数的正确实现至关重要,必须确保所有任务执行完毕,所有线程正常退出,避免资源泄漏和程序崩溃。
cpp
ThreadPool::~ThreadPool() {
{
std::unique_lock<std::mutex> lock(queue_mutex);
stop = true; // 设置停止标志
}
// 唤醒所有等待的线程
condition.notify_all();
// 等待所有线程执行完毕
for (std::thread& worker : workers) {
worker.join();
}
}关键步骤:
- 加锁设置
stop标志为true - 调用
notify_all()唤醒所有等待的工作线程 - 逐个调用
join()等待所有线程退出
三、线程池使用示例
现在我们来看看如何使用这个线程池,它的接口非常简洁易用。
3.1 基本使用:提交普通函数
cpp
#include "thread_pool.h"
#include <chrono>
// 一个简单的计算函数
int calculate(int a, int b) {
std::this_thread::sleep_for(std::chrono::milliseconds(100));
return a + b;
}
int main() {
// 创建一个包含4个工作线程的线程池
ThreadPool pool(4);
// 提交8个任务
std::vector<std::future<int>> results;
for (int i = 0; i < 8; ++i) {
results.emplace_back(pool.enqueue(calculate, i, i*2));
}
// 获取并输出结果
for (auto& res : results) {
std::cout << "Result: " << res.get() << std::endl;
}
std::cout << "All tasks completed" << std::endl;
return 0;
}3.2 提交Lambda表达式
cpp
int main() {
ThreadPool pool(4);
// 提交lambda表达式
auto future1 = pool.enqueue([]() {
std::cout << "Hello from lambda!" << std::endl;
return 42;
});
// 提交带捕获的lambda
int x = 10;
auto future2 = pool.enqueue([x]() {
return x * x;
});
std::cout << "future1: " << future1.get() << std::endl;
std::cout << "future2: " << future2.get() << std::endl;
return 0;
}3.3 提交类的成员函数
cpp
class Calculator {
public:
int multiply(int a, int b) {
return a * b;
}
};
int main() {
ThreadPool pool(4);
Calculator calc;
// 提交成员函数,第一个参数是对象指针
auto future = pool.enqueue(&Calculator::multiply, &calc, 5, 6);
std::cout << "5 * 6 = " << future.get() << std::endl;
return 0;
}3.4 处理异常
如果任务抛出异常,std::future会自动捕获该异常,并在调用get()时重新抛出:
cpp
int main() {
ThreadPool pool(1);
auto future = pool.enqueue([]() {
throw std::runtime_error("Something went wrong!");
});
try {
future.get();
} catch (const std::exception& e) {
std::cout << "Caught exception: " << e.what() << std::endl;
}
return 0;
}四、高级特性与优化
4.1 动态调整线程数量
在实际应用中,我们可能需要根据系统负载动态调整线程池的大小。我们可以添加一个resize()方法:
cpp
void ThreadPool::resize(size_t new_size) {
std::unique_lock<std::mutex> lock(queue_mutex);
if (stop) {
throw std::runtime_error("resize on stopped ThreadPool");
}
if (new_size == workers.size()) {
return;
}
if (new_size > workers.size()) {
// 增加线程
for (size_t i = workers.size(); i < new_size; ++i) {
workers.emplace_back([this]() {
// 工作线程主循环(与构造函数中的相同)
while (true) {
std::function<void()> task;
std::unique_lock<std::mutex> lock(this->queue_mutex);
this->condition.wait(lock,
[this]() { return this->stop || !this->tasks.empty(); });
if (this->stop && this->tasks.empty()) {
return;
}
task = std::move(this->tasks.front());
this->tasks.pop();
lock.unlock();
task();
}
});
}
} else {
// 减少线程(这里简化处理,实际实现需要更优雅的方式)
// 注意:不能直接销毁线程,需要让它们自然退出
// 可以添加一个"待退出"标志,让多余的线程在完成当前任务后退出
}
}4.2 任务优先级队列
如果需要支持不同优先级的任务,可以将任务队列替换为std::priority_queue:
cpp
// 定义带优先级的任务
struct PriorityTask {
int priority;
std::function<void()> task;
bool operator<(const PriorityTask& other) const {
// 注意:priority_queue是大顶堆,所以优先级高的应该排在前面
return priority < other.priority;
}
};
// 修改任务队列类型
std::priority_queue<PriorityTask> tasks;4.3 任务队列大小限制
为了防止任务队列无限增长导致内存耗尽,可以添加队列大小限制:
cpp
// 添加私有成员
size_t max_queue_size;
// 修改enqueue方法
template<class F, class... Args>
auto ThreadPool::enqueue(F&& f, Args&&... args)
-> std::future<typename std::result_of<F(Args...)>::type> {
using return_type = typename std::result_of<F(Args...)>::type;
auto task = std::make_shared<std::packaged_task<return_type()>>(
std::bind(std::forward<F>(f), std::forward<Args>(args)...)
);
std::future<return_type> res = task->get_future();
{
std::unique_lock<std::mutex> lock(queue_mutex);
// 等待队列有空闲位置
condition.wait(lock, [this]() {
return stop || tasks.size() < max_queue_size;
});
if (stop) {
throw std::runtime_error("enqueue on stopped ThreadPool");
}
tasks.emplace([task]() { (*task)(); });
}
condition.notify_one();
return res;
}五、常见问题与最佳实践
5.1 线程池大小如何选择?
线程池的最佳大小取决于任务的类型:
- CPU密集型任务:线程数 = CPU核心数 或 CPU核心数+1
- IO密集型任务:线程数 = CPU核心数 * (1 + 平均等待时间/平均计算时间)
- 混合型任务:可以根据实际情况调整,通常在CPU核心数的2-4倍之间
5.2 避免死锁
- 不要在任务中等待另一个任务的结果,尤其是当线程池大小有限时
- 避免嵌套提交任务
- 不要在持有锁的情况下调用
future.get()
5.3 任务设计原则
- 任务应该尽可能独立,减少对共享资源的依赖
- 避免提交长时间运行的任务,否则会阻塞其他任务
- 对于非常大的任务,可以拆分成多个小任务提交
5.4 资源管理
- 确保所有提交的任务都能正常完成
- 线程池销毁前,确保所有
future都已经被获取 - 避免在线程池中使用全局变量和静态变量
六、总结
我们实现的这个线程池具有以下优点:
- 跨平台:基于C++11标准库,无需依赖第三方库
- 高性能:最小化临界区,充分利用多核CPU
- 易用性:简洁的接口,支持任意类型的可调用对象
- 安全性:完善的异常处理和线程安全保证
这个线程池可以直接用于大多数实际项目中。当然,对于更复杂的场景,你还可以进一步扩展功能,比如:
- 支持任务取消
- 添加任务执行超时机制
- 实现线程池监控和统计
- 支持任务依赖关系
写在最后
线程池是并发编程中最常用的工具之一,掌握它的实现和使用是每个C++开发者的必备技能。本文实现的线程池虽然简洁,但包含了线程池的所有核心思想。
在实际开发中,你不需要每次都自己实现线程池,很多开源库(如Boost.Asio、Abseil、folly)都提供了更完善的线程池实现。但理解线程池的内部原理,能帮助你更好地使用这些工具,避免常见的陷阱。