一.变量
1.不用定义变量类型
和C++,Java和C等语言不同,Python变量的类型不需要显示指定,而是在赋值的时候确定。
例:
(1)在C++,Java和C等语言中
int a = 10;
print(a);//或者是Java中的System.out.print(a);
(2)在Python中
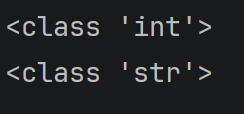
a=10
print(type(a))
a="shushu"
print(type(a))
运行结果:
2.变量类型个数
Python中只有int,float,str,bool四种会比其他语言少。
(1)其中int类型与其他语言的int有很大区别,Python中int类型变量表示的数据范围是没有上限的,只要内存足够大,理论上就能表示无限大小的数。但并不是说它的int是无限字节,只是说明它的上限由电脑决定,并且它可以动态变化,如果数字变大,它可以动态扩容。
(2)和 C++ / Java 等语言不同, **Python 的小数只有 float 一种类型, 没有 double 类型,**但是实际上 Python 的 float 就相当于 C++ / Java 的 double, 表示双精度浮点数。
(3)str表示的是字符串类型,Java中是String,C中没有字符串类型,只有char的字符类型。
例:
a="hello world"
print(type(a))
使用 **' '或者" "**引起来的, 称为字符串,可以用来表示文本。在 Python 中, 单引号构成的字符串和双引号构成的字符串, 没有区别。 'hello' 和 "hello" 是完全等价的,如果说你文本内容本身就带有双引号或者单引号,这种时候就要靠另一种引号来进行语法规范,更极端的是文本内容双引号和单引号都有,此时可以用三引号来进行规范。
常见用法:
可以使用 len 函数来获取字符串的长度
a = 'hello'
print(len(a))#Java中是a.length(),a.length是表示数组长度
可以使用 + 针对两个字符串进行拼接
a = 'hello'
b = 'world'
print(a + b)
此处是两个字符串相加,不能拿字符串和整数/浮点数相加,后面会详细讲述字符串类型中的一些用法。
(4)bool类型表示的真和假注意是True和False,必须首字母要大写,这点与Java完全相反。
3.动态特性
在 Python 中, 一个变量是什么类型, 是可以在 "程序运行" 过程中发生变化的,这个特性称为 "动态类型" 。C++/Java 这样的语言则不允许这样的操作,一个变量定义后类型就是固定的了,这种特性则称为 "静态类型",动态类型特性是一把双刃剑。
例:
a = 10
print(type(a))#用来打印变量a的类型
a = 'hello'
print(type(a))
运行结果:
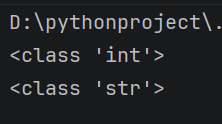
在程序执行过程中, a 的类型刚开始是 int, 后面变成了 str
二.注释风格
(1)采用**#**做单行注释,与Java中的//一样
(2)采用三引号做多行注释,**""" 或者 '''**均可,用法与Java中的/*....*/一样
三.输入和输出
1.输入
(1)Python 使用 input 函数, 从控制台读取用户的输入。
例:
a = input('请输入一个整数: ')#input(提示文本) 括号里的中文,就是控制台输入前的提示语,程序运行时会先把这段文字打印出来,再等待用户输入内容
print(f'你输入的整数是 {a}')#这个输出有个f后面会讲
运行结果:

此时我们尝试打印出a的数据类型
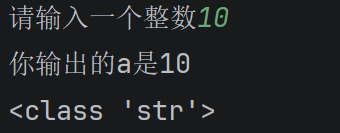
会发现明明输入的是数字却变成了字符串类型,这是因为**input() 接收的所有内容,默认都是字符串**。如果要输入数字做计算,必须用 **int()/float()**转换,如a=int(input())或者b=float(input())
(2)Java中:
利用Scanner scanner = new Scanner(System.in);
String str = sc.nextLine();//同样还有sc.nextInt等,记得要用sc.nextLine();吃掉换行
(3)C中:
利用scanf("格式符",变量地址);
例:
int a;
scanf("%d",&a);
2.输出
(1)在Python中
print("Hello World") # 直接打印
print("姓名:", name, "年龄:", age) # 多内容打印,用逗号隔开
**print(f"姓名:{name},年龄:{age}") # 推荐格式化打印,使用 f 作为前缀的字符串, 称为 f-string,**里面可以使用 { } 来内嵌一个其他的变量/表达式
pi = 3.14159
print(f"圆周率:{pi**:.2f**}") #格式化输出,保留2位小数
print("姓名:" + name + " 年龄:" + str(age))#拼接打印,要把整数先转成字符串类型
(2)Java中
利用System.out.println();//换行版
System.out.print();//不换行版
(3)C中
printf("Hello World\n"); // 打印字符串
printf("年龄:%d\n", 18); // 打印整数
printf("小数:%.2f\n", 3.14); // 打印小数(保留2位)
四.运算符
1.算术运算符
(1)******在Python中是乘方的意思
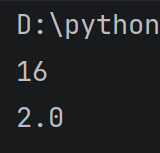
例:
print(4**2)#计算4的平方
print(4**0.5)#计算4的1/2次方
运行结果:
(2)/的用法与Java,C的差异
在Python中整数/整数结果可能是小数,不会被截断。
例:
print(3/2)
运行结果:
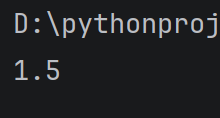
而在Java和C中,这个小数位是会被去掉的。
(3)//用法
在Python叫取整除法,跟Java和C中的/用法一样,向下取整,舍弃小数部分,但Java和C中没有这个运算符,它们用这个当注释。
例:
print(3//2)
print(-7//2)#负数也可以
运行结果:
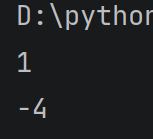
2.关系运算符
<= 是 "小于等于" ,>= 是 "大于等于" ,== 是 "等于" ,!= 是 "不等于"
如果关系符合, 则表达式返回 True. 如果关系不符合, 则表达式返回 False
(1)==在Python中
可以直接使用 == 或者 != 即可对字符串内容判定相等(这一点和 C / Java 不同)。
(2)在Java中
==是比较对象地址的,要比较内容需要用equals方法
(3)在C中
没有字符串类型,字符串是字符数组/指针,比较的也是地址,比较内容要用strcmp函数
特别注意点:不要用==去比较浮点数表达式,如:print(0.1 + 0.2 == 0.3)
运行结果:
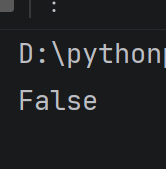
浮点数在计算机中的表示并不是精确的! 在计算过程中, 就容易出现非常小的误差,主流语言都是如此。
3.逻辑运算符
(1)像 and,or,not 这一系列的运算符称为逻辑运算符.
and并且,两侧操作数均为 True, 最终结果为 True. 否则为 False. (一假则假),对应其它语言**&&**
or 或者,两侧操作数均为 False, 最终结果为 False. 否则为 True. (一真则真),对应其它语言的**||**
not 逻辑取反,操作数本身为 True, 则返回 False. 本身为 False, 则返回 True,对应其它语言的**!**
(2)同样要注意逻辑短路问题
(3)在Python中可以写a<b<c的形式等价于a < b and b < c和其它语言的a < b && b < c
4.赋值运算符
(1)=
Python可以多元赋值,也就是可以写
a, b = 10, 20
这意味着它在交换两个变量值就不用临时变量来当容器了,但C和Java不可以
a = 10
b = 20
a, b = b, a
(2)复合赋值运算符
+=,-=,*= ,/= ,%=用法和其它语言差不多。但Python是没有++,--这样的自增/自减运算符,
如果需要使用, 则直接使用+=1或者-=1
五.条件语句和代码块
顺序语句与其它主流语言没有差异。
1.条件语句
(1)在Python条件语句与C和Java有一些差异
纯if展示:
if expression:
do_something1#与上面语句差四个缩进,代码块问题后面会讲
do_something2
next_something
if-else:
if expression:
do_something1
else:
do_something2
if-else-if:
if expression1:
do_something1
elif expression2:
do_something2
else:
do_something3
注意: Python中的条件语句写法, 和很多编程语言不太一样。
if 后面的条件表达式,没有 ( ), 使用**: 作为结尾**
if / else 命中条件后要执行的 "语句块", 使用 缩进 (通常是 4 个空格或者 1 个 tab)来表示, 而不是 { }
对于多条件分支, 不是写作 else if, 而是elif (合体了)
例:
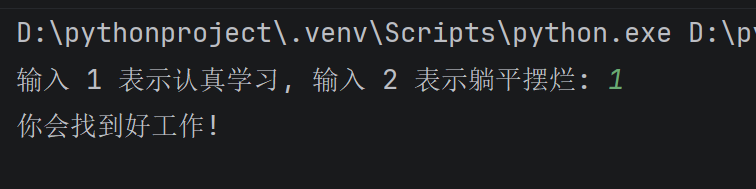
choice = input("输入 1 表示认真学习, 输入 2 表示躺平摆烂: ")
if choice == "1":
print("你会找到好工作!")
elif choice == "2":
print("你可能毕业就失业了!")
else:
print("你的输入有误!")
运行结果:
(2)C和Java
还有个switch语句,大部分还是if用的多
if(条件) {
} else if(条件) {
} else {
}
2.缩进和代码块
代码块指的是一组放在一起执行的代码。在 Python 中使用缩进表示代码块,不同级别的缩进,程序的执行效果是不同的。
例:
代码1
a = input("请输入一个整数: ")
if a == "1":
print("hello")
print("world")
运行结果:

当你输入1时两个都会打印,不输入1两个都不会打印
代码2
a = input("请输入一个整数: ")
if a == "1":
print("hello")
print("world")
运行结果:
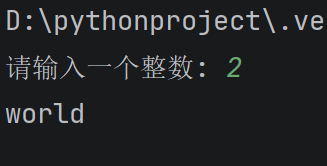
当你输入1时两个也都会打印,但输入其它数时,hello就不会被打印。
在代码1 中,print("world") 有一级缩进, 这个语句属于 if 内的代码块, 意味着条件成立, 才执行, 条件不成立, 则不执行。
在代码2 中, print("world") 没有缩进, 这个语句是 if 外部的代码, 不属于 if 内部的代码块. 意味着条件无论是否成立, 都会执行。
同时,代码块内部还能嵌套代码块。
例:
a = input("请输入第一个整数: ")
b = input("请输入第二个整数: ")
if a == "1":
if b == "2":
print("hello")
print("world")
print("python")
在这个代码中,
print("hello") 具有两级缩进, 属于 if b == "2" 条件成立的代码块
print("world") 具有一级缩进, 属于 if a == "1" 条件成立的代码块
print("python") 没有缩进, 无论上述两个条件是否成立, 该语句都会执行
3.空语句pass
例:输入一个数字, 如果数字为 1, 则打印 hello
a = int(input("请输入一个整数:"))
if a == 1:
print("hello")
这个代码也可以等价写成
a = int(input("请输入一个整数:"))
if a != 1:
pass
else:
print("hello")
其中 pass 表示空语句, 并不会对程序的执行有任何影响, 只是占个位置, 保持 Python 语法格式符合要求
六.循环语句
1.while
(1)在Python中格式为
while 条件:
循环体
例:
num = 1
while num <= 10:
print(num)
num += 1
依旧是注意缩进来划分,并且没有{}和()
(2)在C中
// 先判断条件,再执行循环体
while(条件表达式) {
循环体代码;
}
例:
// 输出 0~4
int i = 0;
while(i < 5) {
printf("%d ", i);
i++;
}
还有个do-while循环
(3)在Java中
// 先判断条件,再执行循环体
while(条件表达式) {
循环体代码;
}
和C一致
2.for
(1)在Python中
for 循环变量 in 可迭代对象:
循环体
python 的 for 和其他语言不同, 没有 "初始化语句", "循环条件判定语句", "循环变量更新语句", 而是 更加简单
所谓的 "可迭代对象", 指的是 "内部包含多个元素, 能一个一个把元素取出来的特殊变量"
例:
for i in range(1, 11):
print(i)
使用 range 函数, 能够生成一个可迭代对象,生成的范围是 1, 11), 也就是 \[1, 10,是前闭后开的,在没有指定步长的情况下,默认+1
#这里的2相当于起始位置,等于12时是终止条件,2是每次循环改变量
for i in range(2,12,2):
print(i)
通过 range 的第三个参数, 可以指定迭代时候的 "步长",也就是一次让循环变量加几
同样可以设定为负数步长,这里是打印10到1
for i in range(10, 0, -1):
print(i)
(2)C和Java一样
for(初始化; 条件判断; 步进) {
循环体;
}
3.continue
continue 表示结束这次循环, 进入下次循环
for i in range(1, 6):
if i == 3:
continue #i加到3时,跳出此次循环,不会执行print语句,也就是会少打一个吃完第3个包子
print(f"吃完第 {i} 个包子")
运行结果:

4.break
break 表示结束整个循环
for i in range(1, 6):
if i == 3:
break #i加到3时,跳出循环,不会再执行print语句,也就是只会打吃完第1个包子和吃完第二个包子
print(f"吃完第 {i} 个包子")
运行结果:
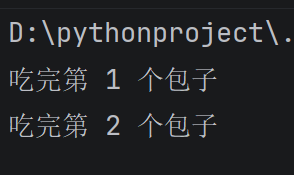
七.函数
1.语法形式
def 函数名(形参列表):
函数体
return 返回值
调用函数/使用函数:
函数名(实参列表) #不考虑返回值
返回值 = 函数名(实参列表) #考虑返回值
2.特殊注意点
和 C++ / Java 不同, Python 是动态类型的编程语言,函数的形参不必指定参数类型,换句话说, 一个****函数可以支持多种不同类型的参数
例:
def test(a):
print(a)
test(10)
test('hello')
test(True)
运行结果:
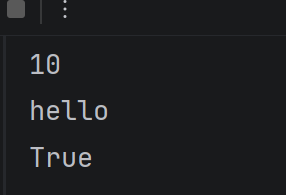
3.返回值
def calcSum(beg, end):
sum = 0
for i in range(beg, end + 1):
sum += i
print(sum)
calcSum(1, 100)
可以转换成
def calcSum(beg, end):
sum = 0
for i in range(beg, end + 1):
sum += i
return sum
result = calcSum(1, 100)
print(result)
这两个代码的区别就在于, 前者直接在函数内部进行了打印, 后者则使用 return 语句把结果返回给函数调用者, 再由调用者负责打印。更推荐第二种,逻辑与用户分离
(1)一个函数可以有多个return语句
判定是否是奇数
def isOdd(num):
if num % 2 == 0:
return False
else:
return True
result = isOdd(10)
print(result)
(2)执行到 return 语句, 函数就会立即执行结束, 回到调用位置
判定是否是奇数
def isOdd(num):
if num % 2 == 0:
return False
return True
result = isOdd(10)
print(result)
如果 num 是偶数, 则进入 if 之后, 就会触发 return False , 也就不会继续执行 return True
(3)一个函数是可以一次返回多个返回值的,使用**", "** 来分割多个返回值,如果只想关注其中的部分返回值, 可以使用**"_ "**来忽略不想要的返回值
原来版本:
def getPoint():
x = 10
y = 20
return x, y
a, b = getPoint()
用了_
def getPoint():
x = 10
y = 20
return x, y
_, b = getPoint()
4.变量作用域
(1)函数内部定义的变量只能在所在的函数内部生效
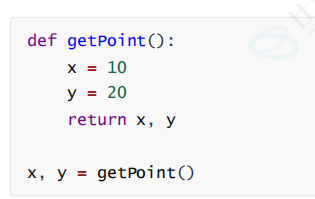
在这个代码中, 函数内部存在 x, y, 函数外部也有 x, y,但是这两组 x, y 不是相同的变量, 而只是恰好有一样的名字

运行结果:
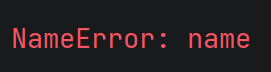
函数外面并没有定义x,y就不能调用函数内部的去执行操作
(2)在不同的作用域中, 允许存在同名的变量
 在函数内部的变量, 也称为 "局部变量" ,不在任何函数内部的变量, 也称为 "全局变量
在函数内部的变量, 也称为 "局部变量" ,不在任何函数内部的变量, 也称为 "全局变量
(3)如果函数内部尝试访问的变量在局部不存在, 就会尝试去全局作用域中查找
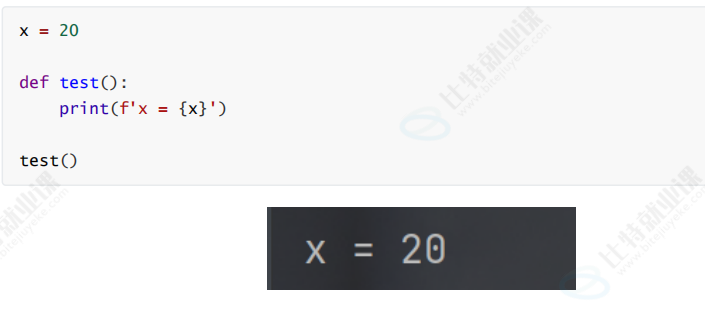
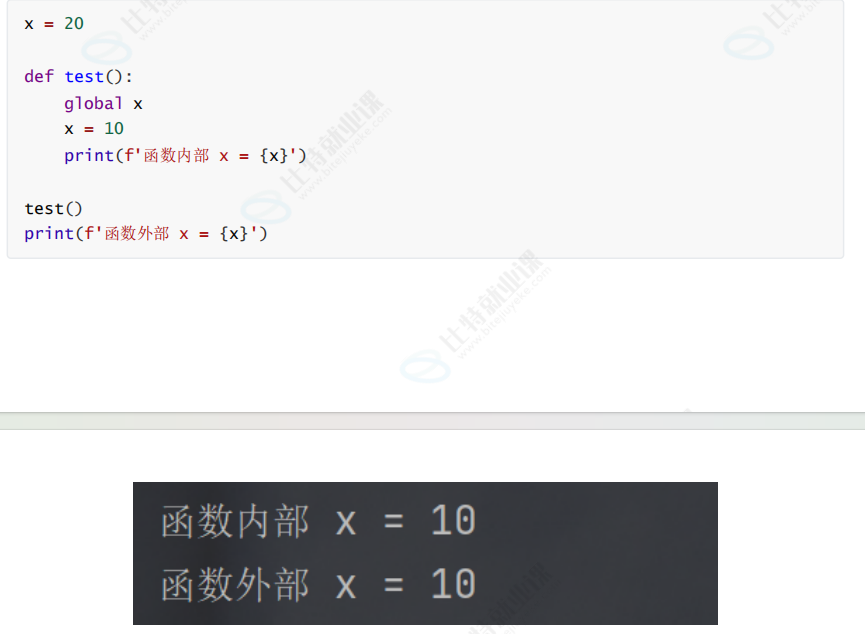
(4)如果是想在函数内部, 修改全局变量的值, 需要使用 global 关键字声明
5.函数递归
经典的例子就是计算阶乘

注意: 递归代码务必要保证
(1)存在递归结束条件. 比如 if n == 1 就是结束条件. 当 n 为 1 的时候, 递归就结束了;
(2)每次递归的时候, 要保证函数的实参是逐渐逼近结束条件的。
如果上述条件不能满足, 就会出现 "无限递归" . 这是一种典型的代码错误。
6.参数默认值
Python 中的函数, 可以给形参指定默认值,带有默认值的参数, 可以在调用的时候不传参。
例:
def add(x, y, debug=False):
if debug:
print(f'调试信息: x={x}, y={y}')
return x + y,debug
print(add(10, 20))
print(add(10, 20, True))
运行结果:

print(add(10, 20))对应第一句结果,因为此处 debug=False 即为参数默认值,当我们不指定第三个参数的时候, 默认 debug 的取值即为 False,不会执行调试信息语句打印
print(add(10, 20, True)),对应二三句结果
注意:带有默认值的参数需要放到没有默认值的参数的后面
7.关键字参数
在调用函数的时候, 需要给函数指定实参。一般默认情况下是按照形参的顺序, 来依次传递实参的,
但是我们也可以通过关键字参数, 来调整这里的传参顺序, 显式指定当前实参传递给哪个形参。
例:
def test(x, y):
print(f'x = {x}')
print(f'y = {y}')
test(10, 20)
test(y=100, x=200)
运行结果
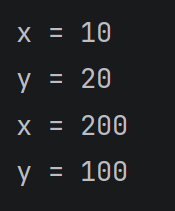
形如上述 test(x=10, y=20) 这样的操作, 即为关键字参数
八.列表、元组
编程中, 经常需要使用变量, 来保存/表示数据。如果代码中需要表示的数据个数比较少, 我们直接创建多个变量即可。但是有的时候, 代码中需要表示的数据特别多, 甚至也不知道要表示多少数据,这个时候, 就需要用到列表 。
列表是一种让程序猿在代码中批量表示/保存数据的方式
就像我们去超市买辣条, 如果就只是买一两根辣条, 那咱们直接拿着辣条就走了。但是如果一次买个十根八根的, 这个时候用手拿就不好拿, 超市老板就会给我们个袋子,这个袋子, 就相当于列表****。
元组和列表相比, 是非常相似的, 只是列表中放哪些元素可以修改调整, 元组中放的元素是创建元组的时候就设定好的, 不能修改调整。
列表就是买散装辣条, 装好了袋子之后, 随时可以把袋子打开, 再往里多加辣条或者拿出去一些辣条,元组就是买包装辣条, 厂家生产好了辣条之后, 一包就是固定的这么多, 不能变动了。

1.列表
(1)创建列表
创建列表主要有两种方式, 表示一个空的列表。
第一种是\[\]字面创建
alist1 = #空列表创建
alist2 = 1, 2, 3, 4#设置了初始值的列表
print(alist2)#可以print直接打印
第二种是依靠list()函数转换创建
alist1=list()
alist2=list((1,2,3,4))#将元组转换成列表
alist3=list("hello world")#将字符串转换成列表
print(alist2)
print(alist3)
运行结果:

(2)访问下标
修改下标为2的元素,再打印整个列表
alist = 1, 2, 3, 4
alist2 = 100
print(alist)
获取整个列表长度,会用到len()
alist = 1, 2, 3, 4
print(len(alist))#Java中获取字符串长度为int len = str.length();获取数组长度为int len = arr.length;
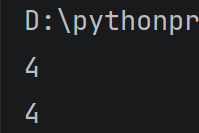
特殊用法:下标取负数,表示倒数第几个数
alist = 1, 2, 3, 4
print(alist3)#表示4
print(alist-1)#也表示4,指倒数第一个数
运行结果:
(3)切片操作
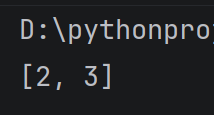
通过下标操作是一次取出里面第一个元素,通过切片, 则是一次取出一组连续的元素, 相当于得到一个子列表, 使用** : **的方式进行切片操作。
例:
alist = 1, 2, 3, 4
print(alist1:3)#切片操作依旧是前闭后开区间,打印的是下标1和下标2的元素
运行结果:
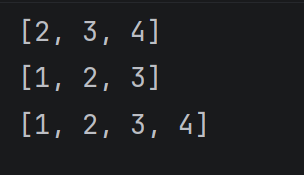
切片操作中可以省略前后边界
alist = 1, 2, 3, 4
print(alist1:) # 省略后边界, 表示获取到列表末尾
print(alist:-1) # 省略前边界, 表示从列表开头获取到倒数第一个截止,但不包括倒数第一个
print(alist:) #省略两个边界, 表示获取到整个列表
运行结果:
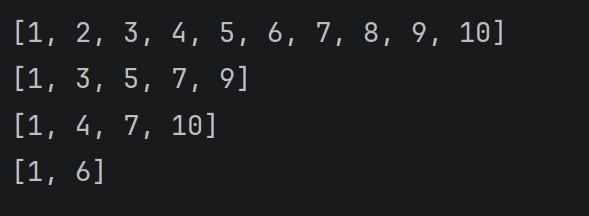
切片操作还可以指定 "步长" , 也就是 "每访问一个元素后, 下标自增几步"
alist = 1, 2, 3, 4, 5, 6, 7, 8, 9, 10
print(alist::1)
print(alist::2)
print(alist::3)
print(alist::5)#都是上面的省略两个边界,获取到整个列表,再加上步长来进行获取
运行结果:
切片操作指定的步长还可以是负数, 此时是从后往前进行取元素,表示 "每访问一个元素之后, 下标自减几步
alist = 1, 2, 3, 4, 5, 6, 7, 8, 9, 10
print(alist::-1)
print(alist::-2)
print(alist::-3)
print(alist::-5)
运行结果:
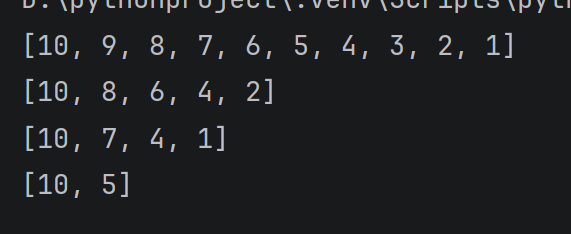
如果切片中填写的数字越界了, 不会有负面效果. 只会尽可能的把满足条件的元素过去到。
(4)遍历列表
三种方式:
最简单的办法就是使用 for 循环
alist = 1, 2, 3, 4
for elem in alist:
print(elem)
运行结果:

也可以使用 for 按照范围生成下标, 按下标访问
#这是for对列表下标进行循环,也可以修改步长
alist = 1, 2, 3, 4
for i in range(0, len(alist)):
print(alisti)
运行结果:
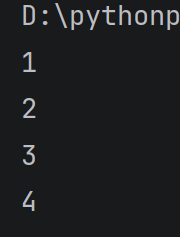
#修改步长版
alist = 1, 2, 3, 4
for i in range(0, len(alist),2):
print(alisti)
运行结果:

还可以使用 while 循环,手动控制下标的变化
alist = 1, 2, 3, 4
i = 0
while i < len(alist):
print(alisti)
i += 1
(5)列表的基本操作
新增元素:
使用 append 方法, 向列表末尾插入一个元素**(尾插)**
alist = 1, 2, 3, 4
alist.append('hello')
print(alist)
运行结果:
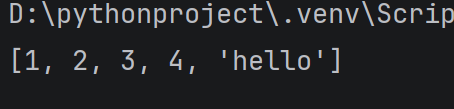
使用insert 方法, 向任意位置插入一个元素,insert 第一个参数表示要插入元素的下标
alist = 1, 2, 3, 4
alist.insert(1, 'hello')#在下标1的地方插入新元素,后面元素往后移
print(alist)
运行结果:
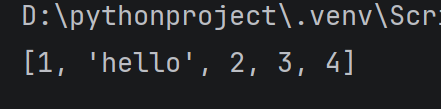
查找元素:
使用 in 操作符, 判定元素是否在列表中存在,返回值是布尔类型
alist = 1, 2, 3, 4
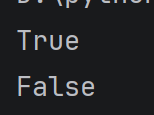
print(2 in alist)
print(10 in alist)
运行结果:
使用 index 方法, 查找元素在列表中的下标,返回值是一个整数,如果元素不存在, 则会抛出异常
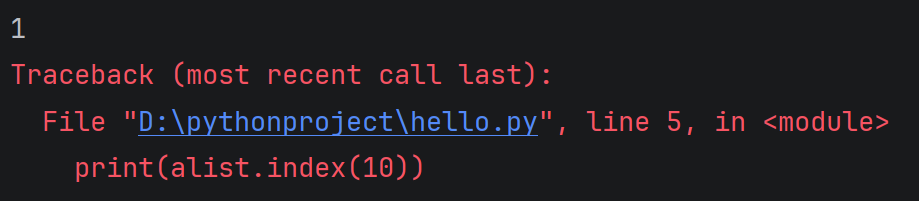
alist = 1, 2, 3, 4
print(alist.index(2))#返回下标1
print(alist.index(10))#会报异常
运行结果:
删除元素:
使用 pop 方法删除最末尾元素
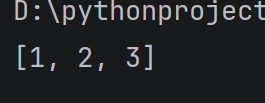
alist = 1, 2, 3, 4
alist.pop()
print(alist)
运行结果:
pop 也能按照下标来删除元素
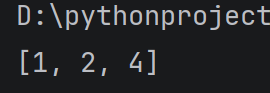
alist = 1, 2, 3, 4
alist.pop(2)
print(alist)
运行结果:
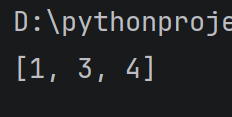
使用 remove 方法, 按照值删除元素
alist = 1, 2, 3, 4
alist.remove(2)
print(alist)
运行结果:
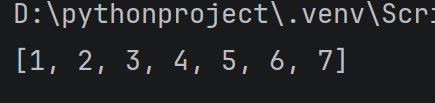
连接列表:
使用 + 能够把两个列表拼接在一起,此处的 + 结果会生成一个新的列表,而不会影响到旧列表的内容
alist = 1, 2, 3, 4
blist = 5, 6, 7
print(alist + blist)
运行结果:
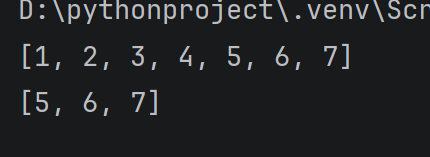
使用extend 方法, 相当于把一个列表拼接到另一个列表的后面,a.extend(b) , 是把 b 中的内容拼接****到 a 的末尾,不会修改 b, 但是会修改 a
alist = 1, 2, 3, 4
blist = 5, 6, 7
alist.extend(blist)
print(alist)
print(blist)
运行结果:
2.元组
元组的功能和列表相比, 基本是一致的,元组使用 ( ) 来表示
(1)创建元组
atuple = ( )
atuple = tuple()
(2)相同点,相异点
元组不能修改里面的元素, 列表则可以修改里面的元素,因此, 像读操作,比如访问下标, 切片, 遍历, in, index, + 等, 元组也是一样支持的。但是, 像写操作, 比如修改元素, 新增元素, 删除元素, extend 等, 元组则不能支持
(3)元组在 Python 中很多时候是默认的集合类型
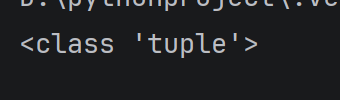
例如, 当一个函数返回多个值的时候
def getPoint():
return 10, 20
result = getPoint()
print(type(result))
运行结果:
如何理解?return 10,20 看似返回两个数字,Python 底层自动封装成元组 (10,20),所以变量**result是元组类型,一个变量接收多个值,在没有指定它是列表还是元组时候,会默认为元组类型**
(4)既然已经有了列表, 为啥还需要有元组?
元组相比于列表来说, 优势有两方面:
第一,当你有一个列表, 现在需要调用一个函数进行一些处理,但是你有不是特别确认这个函数是否会把你的列表数据弄乱,那么这时候传一个元组就安全很多;
第二,后面马上要讲的字典, 是一个键值对结构,要求字典的键必须是 "可hash对象" (字典本质上也是 一个hash表),而一个可hash对象的前提就是不可变,因此元组可以作为字典的键, 但是列表不行
3.总结
列表和元组都是日常开发最常用到的类型,最核心的操作就是根据 来按下标操作。
在需要表示一个 "序列" 的场景下, 就可以考虑使用列表和元组,
如果元素不需要改变, 则优先考虑元组,如果元素需要改变, 则优先考虑列表。
九.字典
字典是一种存储键值对的结构。
啥是键值对? 这是计算机/生活中一个非常广泛使用的概念。
把 键(key) 和 值(value) 进行一个一对一的映射, 然后就可以根据键, 快速找到值。举个例子,学校的每个同学,都会有一个唯一的学号,知道了学号,就能确定这个同学,此处"学号"就是"键",这个同学就是"值"。
1.创建字典
创建一个空的字典,使用 { } 表示字典
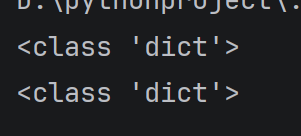
a = { }
b = dict()
print(type(a))
print(type(b))
运行结果:
也可以在创建的同时指定初始值,键值对之间使用**","分割, 键和值之间使用":"**分割(冒号后面推荐加一个空格),使用 print 来打印字典内容
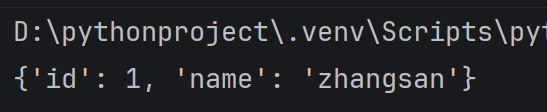
student = { 'id': 1, 'name': 'zhangsan' }#id是1的键,name是zhangsan的键
print(student)
运行结果:
为了代码更规范美观, 在创建字典的时候往往会把多个键值对, 分成多行来书写
例:
student = {
'id': 1,
'name': 'zhangsan'
}#最后一个键值对, 后面可以写","也可以不写
student = {
'id': 1,
'name': 'zhangsan',
}
2.查找key(键)
使用in可以判定 key(键)是否在字典中存在,返回布尔值
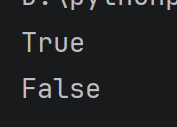
student = {
'id': 1,#这里不用缩进也行
'name': 'zhangsan',
}
print('id' in student)
print('score' in student)
运行结果:
3.查找value
使用** 通过类似于取下标的方式, 获取到元素的值**,只不过此处的 "下标" 是 key(可能是整数, 也
可能是字符串等其他类型)
例:
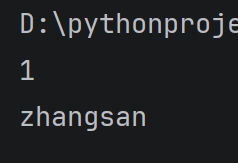
student = {
'id': 1,#这里不用缩进也行
'name': 'zhangsan',
}
print(student'id')
print(student'name')
运行结果:
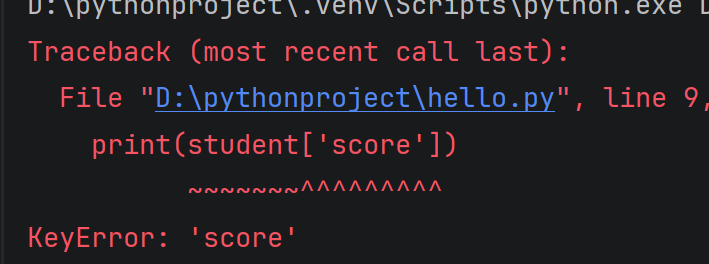
如果key在字典中不存在,则会抛出异常
student = {
'id': 1,
'name': 'zhangsan',
}
print(student'score')
运行结果:
4.基础操作
(1)新增元素
使用** 可以根据key来新增value**
新增:
如果 key 不存在, 对取下标操作赋值, 即为新增键值对
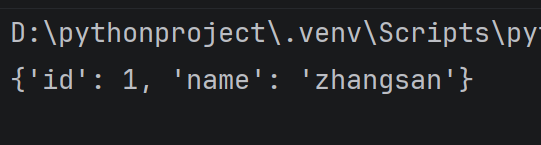
student = {
'id': 1,
'name': 'zhangsan',
}
student'score' = 90
print(student)
运行结果:

(2)修改元素
使用 可以根据key来修改value
在key 已经存在的时候, 对取下标操作赋值, 即为修改键值对的值
student = {
'id': 1,
'name': 'zhangsan',
'score': 80
}
student'score' = 90
print(student)
运行结果:

(3)删除元素
使用 pop 方法根据 key 删除对应的键值对
student = {
'id': 1,
'name': 'zhangsan',
'score': 80
}
student.pop('score')
print(student)
运行结果:
(4)遍历字典元素
直接使用 for 循环能够获取到字典中的所有的 key, 进一步的就可以取出每个值了
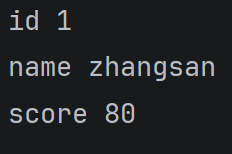
student = {
'id': 1,
'name': 'zhangsan',
'score': 80
}
for key in student:
print(key, studentkey)
运行结果:
(5)取出所有key
使用keys方法可以获取到字典中的所有的 key
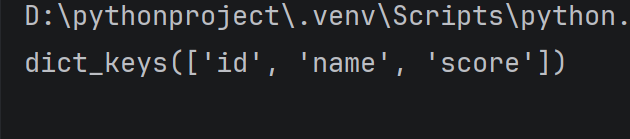
student = {
'id': 1,
'name': 'zhangsan',
'score': 80
}
print(student.keys())
运行结果:
(6)取出所有的value
使用values方法可以获取到字典中的所有value
student = {
'id': 1,
'name': 'zhangsan',
'score': 80
}
print(student.values())
运行结果:
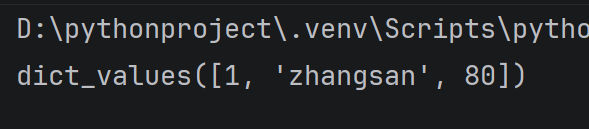
(7)获取所有的键值对
使用items方法可以获取到字典中所有的键值对
student = {
'id': 1,
'name': 'zhangsan',
'score': 80
}
print(student.items())
运行结果:

5.合法的key类型
不是所有的类型都可以作为字典的 key,字典本质上是一个哈希表, 哈希表的 key 要求是 "可哈希的", 也就是可以计算出一个哈希值
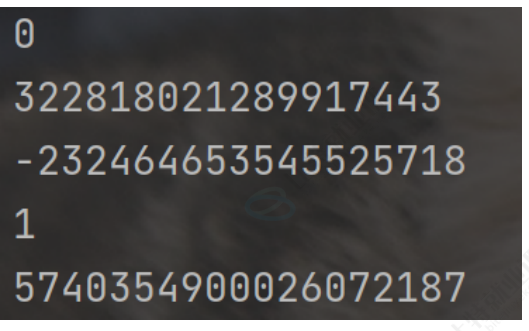
可以使用 hash 函数计算某个对象的哈希值,但凡能够计算出哈希值的类型, 都可以作为字典的 key
print(hash(0))
print(hash(3.14))
print(hash('hello'))
print(hash(True))
print(hash(()))
运行结果:
列表无法计算哈希值
print(hash(1, 2, 3))
运行结果:

字典也无法计算哈希值
print(hash({ 'id': 1 }))
运行结果:

6.总结
字典也是一个常用的结构,字典的所有操作都是围绕 key 来展开的,需要表示 "键值对映射" 这种场景时就可以考虑使用字典
十.文件
1.文件是什么
变量是把数据保存到内存中。如果程序重启/主机重启, 内存中的数据就会丢失,要想能让数据被持久化存储, 就可以把数据存储到硬盘中,也就是在文件中保存,在 Windows "此电脑" 中, 看到的内容都是文件

2.文件路径
一个机器上, 会存在很多文件, 为了让这些文件更方面的被组织, 往往会使用很多的 "文件夹"(也叫做目录 ) 来整理文件,实际一个文件往往是放在一系列的目录结构之中的,为了方便确定一个文件所在的位置, 使用文件路径来进行描述
上述截图中的 QQ.exe 这个文件, 描述这个文件的位置, 就可以使用路径D:\program\qq\Bin\QQ.exe 来表示
(1)D: 表示**盘符,**不区分大小写
(2)每一个 \ 表示一级目录,当前 QQ.exe 就是放在 "D 盘下的 program 目录下的 qq 目录下的 Bin目录中"
(3)目录之间的分隔符, 可以使用 \ 也可以使用 / ,一般在编写代码的时候使用 / 更方便
3.文件操作
要使用文件, 主要是通过文件来保存数据, 并且在后续把保存的数据读取出来,但是要想读写文件, 需要先 "打开文件", 读写完毕之后还要 "关闭文件"
(1)打开文件
使用内建函数 open 打开一个文件
f = open('d:/test.txt', 'r')
第一个参数是一个字符串, 表示要打开的文件路径
第二个参数是一个字符串, 表示打开方式,其中r 表示按照读方式打开,w 表示按照写方式打开,a
表示追加写方式打开
如果打开文件成功, 返回一个文件对象(用变量f去承接了),后续的读写文件操作都是围绕这个文件对象展开
如果打开文件失败(比如路径指定的文件不存在), 就会抛出异常

(2)关闭文件
使用 close 方法关闭已经打开的文件
f.close()# f是上面例子打开的文件对象
注意:一个程序能同时打开的文件个数, 是存在上限的
(3)写文件
文件打开之后, 就可以写文件了,写文件, 要使用写方式打开, open 第二个参数设为**'w' 或者'a',使用 write方法写入文件**
当参数为w时
f = open('d:/test.txt', 'w')
f.write('hello')
f.close()
运行结果:
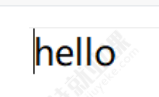
使用 'w' 一旦打开文件成功, 就会清空文件原有的数据
当参数为a时
f = open('d:/test.txt', 'w')
f.write('hello')
f.close()
f = open('d:/test.txt', 'a')
f.write('world')
f.close()
运行结果:

使用 'a' 实现的是"追加写", 此时原有内容不变, 写入的内容会存在于之前文件内容的末尾
(4)读文件
读文件内容需要使用 'r' 的方式打开文件,使用 read 方法完成读操作,参数表示 "读取几个字符"
f = open('d:/test.txt', 'r')
result = f.read(2)
print(result)
f.close()
运行结果:

如果文件是多行文本, 可以使用 for 循环一次读取一行
多行文件:

开始读多行文件:
f = open('d:/test.txt', 'r')
for line in f:
print(f'line = {line}')
f.close()
运行结果:
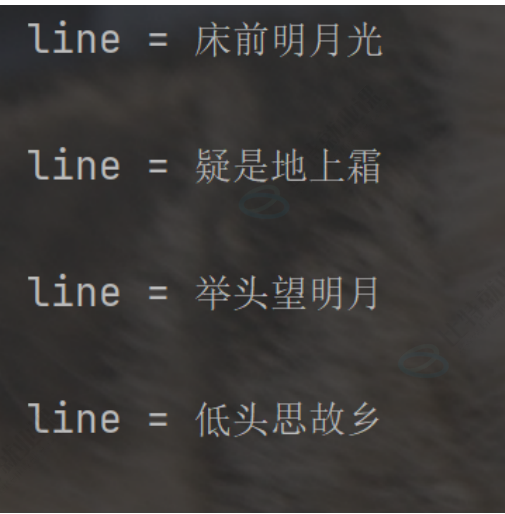
注意:由于文件里每一行末尾都自带换行符, print 打印一行的时候又会默认加上一个换行符, 因此
打印结果看起来之间存在空行,使用 print(f'line = {line}', end=' ') 手动把 print 自带的换行符去掉
使用 readlines 直接把文件整个内容读取出来, 返回一个列表,每个元素即为一行
f = open('d:/test.txt', 'r')
lines = f.readlines()
print(lines)
f.close()
运行结果:

\n是换行符
4.中文问题
当文件内容存在中文的时候, 读取文件内容不一定就顺利,同样上述代码, 有的人执行时可能会出现异常
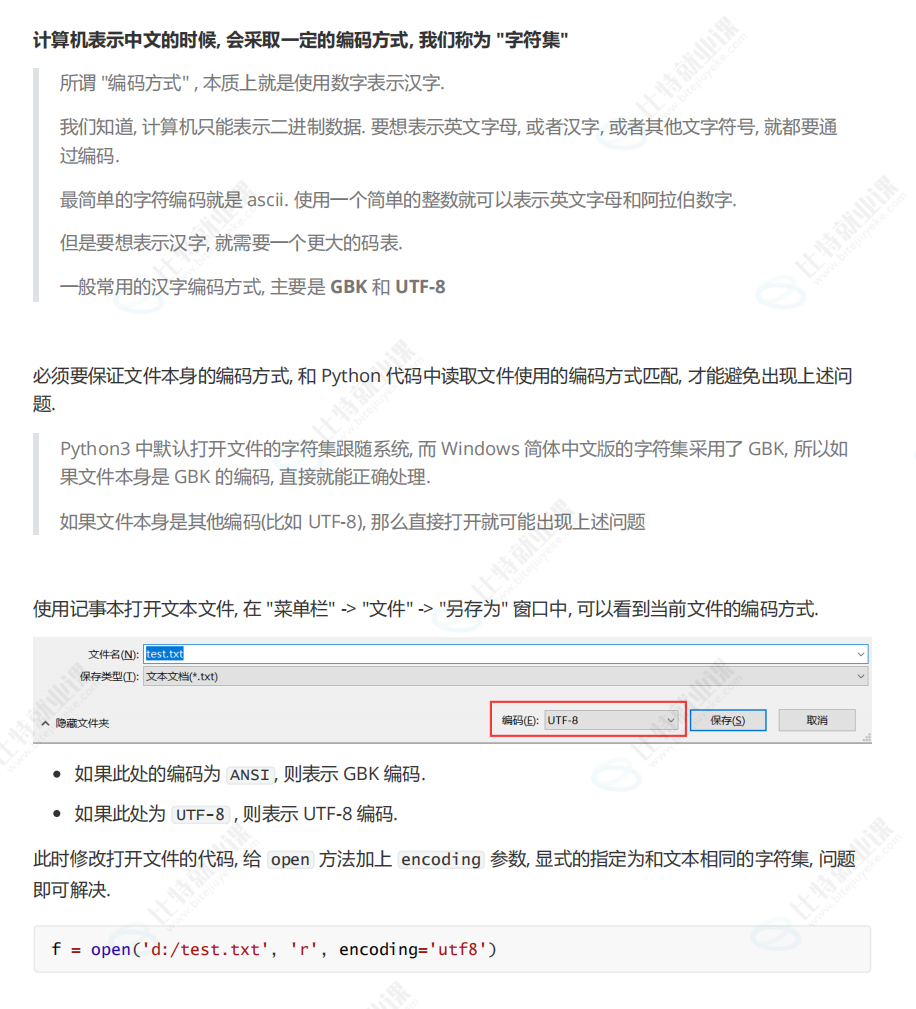
5.上下文管理器
打开文件之后, 是容易忘记关闭的,Python 提供了上下文管理器 , 来帮助我们自动关闭文件
使用 with 语句打开文件,当 with 内部的代码块执行完毕后, 就会自动调用关闭方法
with open('d:/test.txt', 'r', encoding='utf8') as f:
lines = f.readlines()
print(lines)