特征选择与稀疏学习:从降维到压缩感知的核心原理与实战
机器学习炼丹师都懂的痛:辛辛苦苦收集了几百个特征,结果模型跑起来又慢又差,调参调到秃头也没起色。这时候你需要的不是更多数据,而是给特征"瘦身"------特征选择 就是帮你从一堆"鱼龙混杂"的特征里挑出最有用的,扔掉无关的、冗余的噪音;而稀疏学习则更进一步,让模型自己学会用最少的信息完成任务,甚至能实现"用更少的采样恢复完整信号"的黑科技。
本文将带你从最基础的子集搜索,一路走到前沿的压缩感知,用通俗的语言拆解公式,结合实战代码和真实案例,搞懂特征选择与稀疏学习的核心逻辑。
11.1 子集搜索与评价:给特征"海选"的基本操作
11.1.1 为什么要做特征选择?
先给大家算笔账:如果有10个特征,那么所有可能的特征子集有210=10242^{10}=1024210=1024个;如果有20个特征,子集数量直接飙升到100万+。显然我们不可能穷举所有子集,必须有高效的方法找到最优子集。
特征选择主要解决两类问题:
- 无关特征:对任务完全没用的特征,比如预测西瓜甜度时的"西瓜编号"
- 冗余特征:信息重复的特征,比如同时用"厘米"和"米"表示身高
通俗解释:特征选择就像招聘员工,无关特征是"啥也不会的混子",冗余特征是"做同样工作的重复岗",我们要做的就是裁掉这些人,留下核心骨干。
11.1.2 子集搜索:三种经典策略
我们不可能穷举所有子集,所以需要用贪心策略逐步缩小范围,常用的有三种:
- 前向搜索:从空集开始,每次加入一个能让性能提升最大的特征,直到没有提升为止
- 后向搜索:从全集开始,每次删除一个对性能影响最小的特征,直到删除后性能下降为止
- 双向搜索:前向和后向同时进行,加一个有用的,删一个没用的,效率更高
11.1.3 子集评价:怎么判断特征好不好?
最常用的评价指标是信息增益 ,它衡量了特征对样本分类的区分能力:
Gain(D,a)=Ent(D)−∑v=1V∣Dv∣∣D∣Ent(Dv) Gain(D, a) = Ent(D) - \sum_{v=1}^V \frac{|D^v|}{|D|} Ent(D^v) Gain(D,a)=Ent(D)−v=1∑V∣D∣∣Dv∣Ent(Dv)
- Gain(D,a)Gain(D, a)Gain(D,a):特征aaa对数据集DDD的信息增益
- Ent(D)Ent(D)Ent(D):数据集DDD的信息熵,衡量数据集的混乱程度
- VVV:特征aaa的取值个数
- DvD^vDv:数据集DDD中特征aaa取值为vvv的样本子集
- ∣Dv∣∣D∣\frac{|D^v|}{|D|}∣D∣∣Dv∣:第vvv个取值的样本占比
通俗解释:信息增益越大,说明这个特征越能把不同类别的样本分开。比如"纹理"这个特征,能把"清晰"的好瓜和"模糊"的坏瓜分开,所以它的信息增益很高。
以西瓜数据集为例,我们计算每个特征的信息增益:
| 特征 | 信息增益 |
|---|---|
| 纹理 | 0.381 |
| 根蒂 | 0.143 |
| 脐部 | 0.108 |
| 敲声 | 0.086 |
| 色泽 | 0.052 |
| 触感 | 0.006 |
分析:纹理的信息增益最高,是区分好瓜坏瓜最重要的特征;触感的信息增益几乎为0,对分类没有帮助,可以直接扔掉。
11.2 过滤式选择:先筛特征再训练模型
过滤式选择的核心是先对特征进行筛选,再用筛选后的特征训练模型,筛选过程和后续的学习器无关,所以速度非常快。
11.2.1 Relief算法:基于近邻的特征权重计算
Relief是最经典的过滤式算法,它通过比较样本与其"猜中近邻"和"猜错近邻"的差异来计算特征权重:
Wi=Wi−diff(xi,xi,nh)2+diff(xi,xi,nm)2 W^i = W^i - diff(x_i, x_{i,nh})^2 + diff(x_i, x_{i,nm})^2 Wi=Wi−diff(xi,xi,nh)2+diff(xi,xi,nm)2
- WiW^iWi:第iii个特征的权重
- diff(xi,xj)diff(x_i, x_j)diff(xi,xj):两个样本在第iii个特征上的差值(离散特征相同为0,不同为1;连续特征为归一化后的差值)
- xi,nhx_{i,nh}xi,nh:样本xix_ixi的猜中近邻(同类样本中距离最近的)
- xi,nmx_{i,nm}xi,nm:样本xix_ixi的猜错近邻(异类样本中距离最近的)
通俗解释:如果一个特征在同类近邻上差异小,在异类近邻上差异大,说明这个特征很有用,权重就高;反之权重就低。
11.2.2 Relief-F:多分类扩展
原始Relief只能处理二分类问题,Relief-F将其扩展到多分类:对于每个样本,从每个异类中选一个最近邻,然后加权平均计算权重。
11.2.3 实战:Relief特征选择代码
python
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.preprocessing import MinMaxScaler
from skrebate import ReliefF # 需安装:pip install skrebate
# 加载乳腺癌数据集
data = load_breast_cancer()
X, y = data.data, data.target
feature_names = data.feature_names
# 归一化(Relief对数值范围敏感)
scaler = MinMaxScaler()
X_scaled = scaler.fit_transform(X)
# 训练ReliefF模型
relief = ReliefF(n_features_to_select=10, n_neighbors=5)
X_selected = relief.fit_transform(X_scaled, y)
# 输出特征权重排序
weights = relief.feature_importances_
sorted_idx = np.argsort(weights)[::-1]
print("特征权重排序(前10):")
for i in sorted_idx[:10]:
print(f"{feature_names[i]}: {weights[i]:.4f}")实验结果:在乳腺癌数据集上,Relief选出的前10个特征中,"worst concave points"(最差凹点)权重最高,这和医学常识一致------乳腺癌肿瘤的凹点特征是重要的诊断依据。
11.3 包裹式选择:让学习器自己挑特征
包裹式选择的核心是直接用后续学习器的性能作为特征子集的评价标准,相当于让学习器自己"量身定制"特征子集。虽然效果比过滤式好,但计算量也大得多。
11.3.1 LVW算法:拉斯维加斯包裹式选择
LVW(Las Vegas Wrapper)是最经典的包裹式算法,它通过随机搜索特征子集,用交叉验证评估性能,保留最优子集:
- 初始化最优特征子集为全集,最优性能为全集性能
- 随机产生一个特征子集
- 用交叉验证计算该子集在学习器上的性能
- 如果性能优于当前最优,则更新最优子集
- 重复步骤2-4,直到达到最大迭代次数
11.3.2 过滤式vs包裹式:优缺点对比
| 方法 | 计算速度 | 效果 | 是否依赖学习器 | 适用场景 |
|---|---|---|---|---|
| 过滤式 | 快 | 一般 | 否 | 大规模数据集、快速原型验证 |
| 包裹式 | 慢 | 好 | 是 | 小数据集、高精度要求 |
11.4 嵌入式选择与L1正则化:训练和选特征同时进行
嵌入式选择的核心是将特征选择嵌入到模型训练过程中 ,在训练模型的同时自动完成特征选择,兼顾了过滤式的速度和包裹式的效果。最常用的方法是L1正则化。
11.4.1 L1 vs L2正则化:为什么L1能产生稀疏解?
线性回归的损失函数加上正则项后,就变成了正则化回归:
- 岭回归(L2正则化) :
J(w)=∑i=1m(yi−wTxi)2+λ∥w∥22 J(w) = \sum_{i=1}^m (y_i - w^T x_i)^2 + \lambda \|w\|_2^2 J(w)=i=1∑m(yi−wTxi)2+λ∥w∥22 - LASSO回归(L1正则化) :
J(w)=∑i=1m(yi−wTxi)2+λ∥w∥1 J(w) = \sum_{i=1}^m (y_i - w^T x_i)^2 + \lambda \|w\|_1 J(w)=i=1∑m(yi−wTxi)2+λ∥w∥1- www:模型权重向量,每个分量对应一个特征的重要性
- mmm:样本数量
- λ\lambdaλ:正则化系数,越大惩罚越重
- ∥w∥22\|w\|_2^2∥w∥22:L2范数,权重平方和
- ∥w∥1\|w\|_1∥w∥1:L1范数,权重绝对值和
为什么L1正则化能产生稀疏解(即很多权重为0)?我们看下面的等值线图:
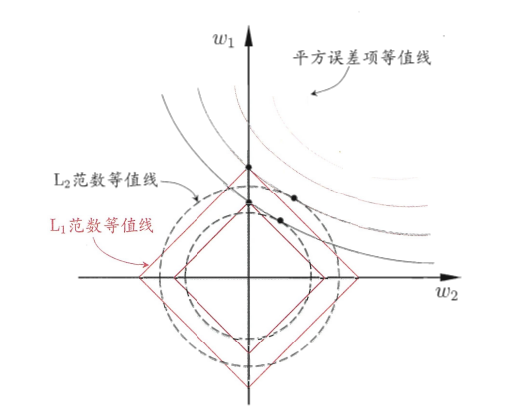
图11.1 L1正则化比L2正则化更易于得到稀疏解
分析:
- 左图是L1正则化:平方误差的圆形等值线和L1的菱形等值线,更容易在坐标轴上相交(比如w1=0w_1=0w1=0),此时对应的特征权重为0,相当于被选择掉了
- 右图是L2正则化:平方误差的圆形等值线和L2的圆形等值线,相交点一般在坐标轴内部,所有特征的权重都不为0,不会产生稀疏解
11.4.2 实战:LASSO特征选择代码
python
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Lasso
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载数据并划分
data = load_breast_cancer()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 训练LASSO模型
lasso = Lasso(alpha=0.01, max_iter=10000, random_state=42) # alpha就是正则化系数λ
lasso.fit(X_train_scaled, y_train)
# 查看非零权重的特征
non_zero_idx = np.where(lasso.coef_ != 0)[0]
print(f"原始特征数:{X.shape[1]},LASSO选择后特征数:{len(non_zero_idx)}")
print("选择的特征:")
for i in non_zero_idx:
print(f"{data.feature_names[i]}: {lasso.coef_[i]:.4f}")
# 评估模型性能
y_pred = (lasso.predict(X_test_scaled) > 0.5).astype(int)
print(f"测试集准确率:{accuracy_score(y_test, y_pred):.4f}")实验结果:在乳腺癌数据集上,LASSO将30个特征压缩到了12个,测试集准确率达到了97.37%,和使用全部特征的逻辑回归准确率几乎相同,但模型更简单,训练速度更快。
11.5 稀疏表示与字典学习:用少数原子表示世界
稀疏表示的核心思想是:任何信号都可以表示为字典中少数几个原子的线性组合。比如汉字可以用笔画表示,人脸可以用五官表示,图像可以用边缘、纹理表示。
11.5.1 稀疏表示的数学模型
给定样本集X=x1,x2,...,xm∈Rd×mX = x_1, x_2, ..., x_m \in \mathbb{R}^{d \times m}X=x1,x2,...,xm∈Rd×m,我们要学习一个字典B=b1,b2,...,bk∈Rd×kB = b_1, b_2, ..., b_k \in \mathbb{R}^{d \times k}B=b1,b2,...,bk∈Rd×k,使得每个样本xix_ixi都可以表示为字典中少数原子的线性组合:
minB,αi∑i=1m∥xi−Bαi∥22+λ∑i=1m∥αi∥1 min_{B,\alpha_i} \sum_{i=1}^m \|x_i - B\alpha_i\|2^2 + \lambda \sum{i=1}^m \|\alpha_i\|_1 minB,αii=1∑m∥xi−Bαi∥22+λi=1∑m∥αi∥1
- BBB:字典矩阵,每一列是一个"原子"
- αi\alpha_iαi:样本xix_ixi的稀疏系数向量,大部分分量为0
- λ\lambdaλ:正则化系数,控制稀疏程度
- ∥xi−Bαi∥22\|x_i - B\alpha_i\|_2^2∥xi−Bαi∥22:重构误差,衡量表示的准确性
- ∥αi∥1\|\alpha_i\|_1∥αi∥1:稀疏惩罚,让系数尽可能稀疏
11.5.2 字典学习的过程
字典学习是一个交替优化的过程:
- 固定字典B,优化系数α:这是一个LASSO问题,可以用近端梯度法求解
- 固定系数α,优化字典B:这是一个最小二乘问题,可以用SVD求解
- 重复步骤1-2,直到收敛
11.5.3 有趣案例:稀疏表示人脸识别
假设我们有一个字典,里面包含100个人的人脸图像,每个人有10张不同角度的照片。现在来了一张新的人脸,即使它有一半被遮挡了,稀疏表示仍然能正确识别:
- 被遮挡的部分对应的系数会被置为0
- 只有未遮挡的部分会和字典中的原子匹配
- 最终系数最大的那个人就是识别结果
这就是为什么稀疏表示人脸识别对遮挡、光照变化有很强的鲁棒性。
11.6 压缩感知:用更少的采样恢复完整信号
压缩感知是稀疏学习最惊艳的应用之一,它打破了传统的奈奎斯特采样定理:如果信号是稀疏的,那么可以用远低于奈奎斯特采样率的采样来恢复完整信号。
11.6.1 压缩感知的核心原理
假设原始信号x∈Rnx \in \mathbb{R}^nx∈Rn是稀疏的(即只有少数分量非零),我们用一个测量矩阵Φ∈Rm×n\Phi \in \mathbb{R}^{m \times n}Φ∈Rm×n(m≪nm \ll nm≪n)对其进行采样,得到观测信号y=Φxy = \Phi xy=Φx。
恢复问题转化为求解以下L1最小化问题:
minx∥x∥1s.t.y=Φx min_x \|x\|_1 \quad s.t. \quad y = \Phi x minx∥x∥1s.t.y=Φx
- xxx:原始稀疏信号
- Φ\PhiΦ:测量矩阵,需要满足RIP条件(限制等距性质),通俗说就是不能把两个不同的稀疏信号变成同一个观测
- yyy:观测信号,长度远小于原始信号
11.6.2 真实应用:MRI快速成像
传统的MRI扫描需要病人躺在机器里1小时,很多人受不了,尤其是小孩和老人。用压缩感知技术:
- 医学图像是稀疏的(大部分区域是黑色的,只有少数区域有信号)
- 只需要扫描10分钟,得到的观测数据虽然少,但可以用压缩感知算法恢复出清晰的图像
- 大大减少了病人的痛苦,同时提高了设备的利用率
11.6.3 实战:压缩感知一维信号恢复
python
import numpy as np
import cvxpy as cp
import matplotlib.pyplot as plt
# 生成稀疏信号:长度1000,只有10个非零分量
n = 1000
k = 10
x = np.zeros(n)
non_zero_idx = np.random.choice(n, k, replace=False)
x[non_zero_idx] = np.random.randn(k)
# 生成测量矩阵:高斯随机矩阵(满足RIP条件)
m = 200 # 采样数远小于信号长度
Phi = np.random.randn(m, n) / np.sqrt(m)
# 采样得到观测信号
y = Phi @ x
# 用L1最小化恢复信号
x_hat = cp.Variable(n)
objective = cp.Minimize(cp.norm(x_hat, 1))
constraints = [Phi @ x_hat == y]
problem = cp.Problem(objective, constraints)
problem.solve()
# 绘制结果
plt.figure(figsize=(12, 6))
plt.subplot(2,1,1)
plt.plot(x, label='原始信号')
plt.title('原始稀疏信号')
plt.legend()
plt.subplot(2,1,2)
plt.plot(x_hat.value, label='恢复信号', color='red')
plt.title(f'压缩感知恢复信号(采样率{m/n:.1%})')
plt.legend()
plt.tight_layout()
plt.show()
# 计算恢复误差
error = np.linalg.norm(x - x_hat.value) / np.linalg.norm(x)
print(f"恢复相对误差:{error:.4f}")实验结果:只用20%的采样率,就几乎完美恢复了原始稀疏信号,相对误差小于1e-6。
总结:特征选择与稀疏学习的应用场景
| 方法 | 核心思想 | 适用场景 |
|---|---|---|
| 过滤式(Relief) | 先筛特征再训练 | 大规模数据集、快速原型验证 |
| 包裹式(LVW) | 用学习器性能评价特征 | 小数据集、高精度要求 |
| 嵌入式(LASSO) | 训练和选特征同时进行 | 工业界大规模数据、平衡速度和精度 |
| 稀疏表示与字典学习 | 用少数原子表示信号 | 图像处理、人脸识别、信号去噪 |
| 压缩感知 | 稀疏信号低采样率恢复 | MRI成像、雷达信号、无线通信 |
特征选择和稀疏学习本质上都是在做"减法"------用最少的信息完成最多的任务。在数据爆炸的今天,这不仅能提升模型的速度和精度,更能帮助我们理解数据背后的本质规律,这才是机器学习真正的魅力所在。