文章目录
- [1. 认识 pandas:它解决什么问题?](#1. 认识 pandas:它解决什么问题?)
-
- [1.1 数据分析流程中的 pandas](#1.1 数据分析流程中的 pandas)
- [1.2 结构化数据 vs 非结构化数据](#1.2 结构化数据 vs 非结构化数据)
- [2. pandas 核心数据结构](#2. pandas 核心数据结构)
-
- [2.1 Series:一维带标签数组](#2.1 Series:一维带标签数组)
- [2.2 DataFrame:二维带标签表格](#2.2 DataFrame:二维带标签表格)
- [2.3 Series 与 DataFrame 的关系](#2.3 Series 与 DataFrame 的关系)
- [3. Series 详解](#3. Series 详解)
-
- [3.1 Series 的三种创建方式](#3.1 Series 的三种创建方式)
-
- 方法一:传入列表(自动生成索引)
- [方法二:传入元组 + 手动指定 index](#方法二:传入元组 + 手动指定 index)
- [方法三:传入字典(key → 索引,value → 值)](#方法三:传入字典(key → 索引,value → 值))
- 三种方式对比
- [3.2 Series 的核心属性](#3.2 Series 的核心属性)
- [3.3 Series 的数据访问](#3.3 Series 的数据访问)
-
- 按位置索引(iloc)
- [按标签索引(loc 或直接标签)](#按标签索引(loc 或直接标签))
- 布尔过滤
- 访问方式速查
- [3.4 Series 的基本运算与统计](#3.4 Series 的基本运算与统计)
- [4. DataFrame 详解](#4. DataFrame 详解)
-
- [4.1 DataFrame 创建的"核心本质"](#4.1 DataFrame 创建的"核心本质")
- [4.2 DataFrame 的四种创建方式](#4.2 DataFrame 的四种创建方式)
-
- 方法一:listdict(字典列表)
- 方法二:dictlist(列表字典)
- 方法三:二维列表(纯数据)
- [方法四:二维列表 + index + columns(完整控制)](#方法四:二维列表 + index + columns(完整控制))
- 四种方式对比
- [4.3 DataFrame 的核心属性](#4.3 DataFrame 的核心属性)
- [4.4 DataFrame 数据访问](#4.4 DataFrame 数据访问)
-
- [4.4.1 列访问](#4.4.1 列访问)
- [4.4.2 行访问](#4.4.2 行访问)
- [4.4.3 行+列联合访问 & loc vs iloc 核心对比](#4.4.3 行+列联合访问 & loc vs iloc 核心对比)
- [4.5 数据概览方法](#4.5 数据概览方法)
-
- [`df.info()` --- 结构信息](#
df.info()— 结构信息) - [`df.describe()` --- 统计摘要](#
df.describe()— 统计摘要)
- [`df.info()` --- 结构信息](#
- [4.6 布尔过滤与条件筛选](#4.6 布尔过滤与条件筛选)
-
- 核心原理(两步走)
- [4.6.1 单条件筛选](#4.6.1 单条件筛选)
-
- [between() 的 inclusive 参数](#between() 的 inclusive 参数)
- [4.6.2 多条件组合](#4.6.2 多条件组合)
-
- [为什么 & 和 | 必须用小括号?](#为什么 & 和 | 必须用小括号?)
📁 配套代码:Series.ipynb | DataFrame.ipynb
📅 更新日期:2026-06-06
1. 认识 pandas:它解决什么问题?
在进入具体语法之前,我们先把几个容易混淆的概念理清楚
1.1 数据分析流程中的 pandas
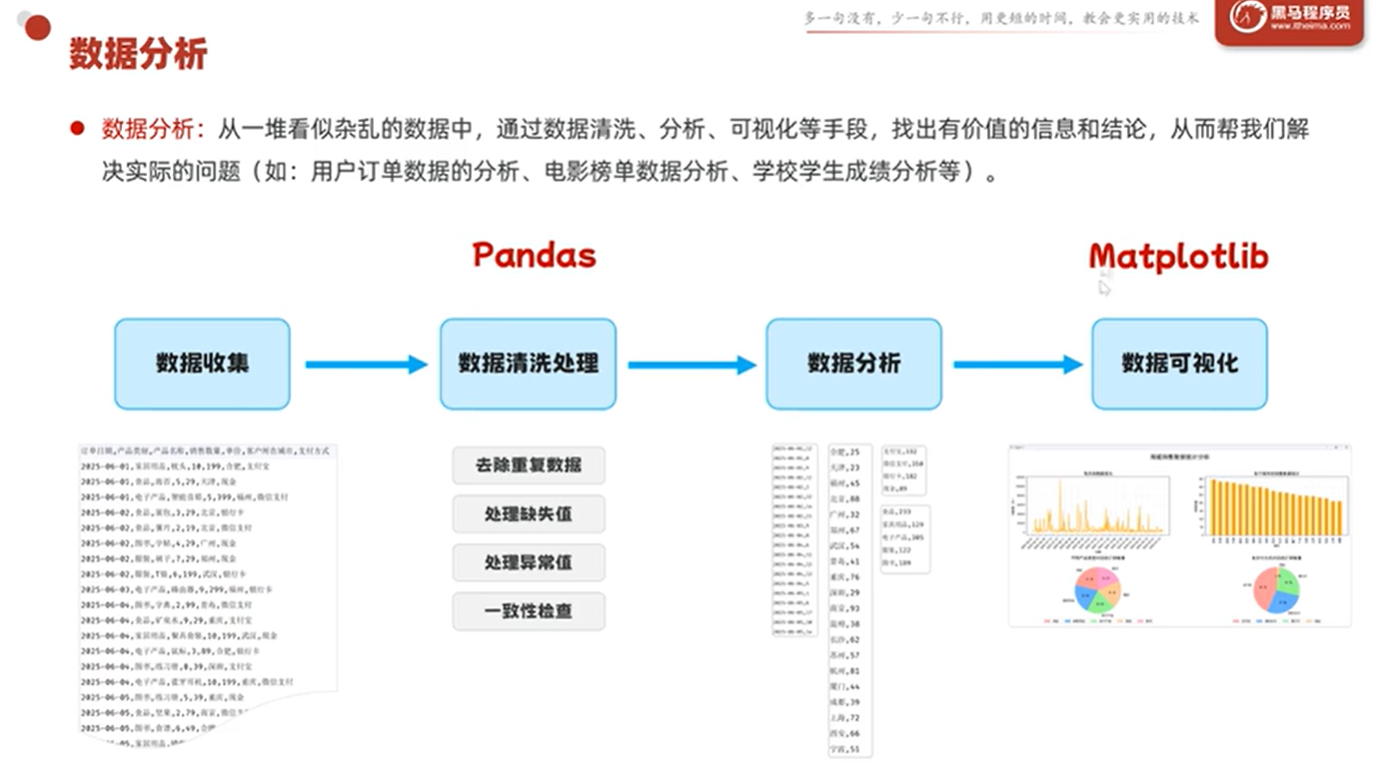
数据分析的本质是:从一堆杂乱的数据中,通过数据清洗、数据分析、可视化等手段,挖掘出有价值的信息和结论,从而帮助我们更好地解决实际问题。
一个完整的数据分析流程通常包含四个阶段:
数据获取 → 数据清洗 → 探索分析 → 可视化 / 建模pandas 的定位 就集中在前三层------数据读取 + 数据清洗 + 探索分析 。它提供了高效的数据结构(Series 和 DataFrame)和丰富的操作方法,让你能轻松地完成筛选、排序、分组、聚合、透视等任务。
pandas 与机器学习数据预处理的关系
提问:"pandas 的数据处理和 PyTorch / TensorFlow 里的数据预处理是不是一回事?"
答案是:它们处于同一条流水线的不同阶段,功能互补但各有侧重。
| pandas | PyTorch / TensorFlow | |
|---|---|---|
| 核心数据结构 | DataFrame(表格) | Tensor(多维数组/张量) |
| 主要用途 | 数据加载、清洗、探索分析 | 构建神经网络、梯度下降、模型训练 |
| 典型操作 | 缺失值填充、类型转换、分组聚合、透视表 | 张量运算、自动求导、GPU 加速 |
| 输入来源 | CSV / Excel / SQL / JSON | pandas 处理好的 NumPy 数组 |
| 输出去向 | 清洗后的数据 → NumPy 数组 → 送入模型 | 训练好的模型 → 预测结果 |
二者的关系可以这样理解:
原始数据 → [pandas] 清洗 + 特征工程 → NumPy 数组 → [PyTorch] 张量 → 模型训练pandas 负责把"脏数据"变成"干净的特征矩阵",PyTorch 负责用这个矩阵去训练模型。 它们是上下游协作关系,而不是同一件事的不同叫法。你之前感觉"类比怪怪的"是正常的,因为它们确实不是同一层面上的概念。
学习 pandas 时你关注的是"怎么操作表格数据";学习 PyTorch 时你关注的是"怎么定义和训练神经网络"。两项技能相辅相成,是数据科学家的基本功。
1.2 结构化数据 vs 非结构化数据
另一个容易混淆的概念是数据的"结构化"程度。
| 特征 | 结构化数据 | 非结构化数据 |
|---|---|---|
| 形式 | 行列整齐的表格 | 文本、图像、音频、视频等 |
| 存储 | 数据库表、CSV、Excel | 文件系统、对象存储(OSS/S3) |
| 典型处理工具 | pandas、SQL | PIL/OpenCV(图像)、NLTK/spaCy(文本)、librosa(音频) |
| 预处理方式 | 缺失值填充、类型转换、异常值处理 | 分词、特征提取、向量化、嵌入表示 |
| 分析流程 | 加载 → 清洗 → 聚合 → 可视化 | 特征工程 → 转为结构化 → 后续分析 |
关键理解 :本文用 pandas 处理讲解的是结构化数据,也就是行列整齐的表格数据。对于非结构化数据(比如一段文本或一张图片),通常需要先经过特征工程(例如用 jieba 分词 + TF-IDF 向量化,或用 CNN 提取图像特征),将其转换为结构化的特征矩阵之后,pandas 才能派上用场。
非结构化数据的分析流程可以概括为:
非结构化原始数据 → 特征提取 → 结构化特征表 → pandas 分析/建模例如,你要分析 1000 条用户评论的情感倾向:
- 用 jieba 对每条评论分词
- 用 TF-IDF 或词向量将文本转为数值特征
- 得到一个"行=评论,列=特征词"的 DataFrame
- 之后就可以用 pandas 进行统计、筛选、可视化
一句话总结 :pandas 主要处理结构化的表格数据,但它也可以作为非结构化数据经过特征工程后的汇总结和后续分析工具。下文我们讨论的所有操作,默认都是针对结构化数据的。
2. pandas 核心数据结构
pandas 是 Python 生态中最核心的数据分析库,属于第三方库,使用前需要通过 pip install pandas 安装。使用时按惯例导入:
python
import pandas as pdpandas 在顶层 __init__.py 中已将核心类导入到包的命名空间,因此我们直接通过 pd.DataFrame 和 pd.Series 即可使用,无需关心内部模块。
pandas 提供了两大核心数据结构,它们是整个库的基石:
2.1 Series:一维带标签数组
Series 可以理解为一个**"有索引的列表"**。它由两部分组成:
- 数据(values):一组值
- 索引(index):每个值对应的标签
可以类比为 Excel 表格中的一列数据 :列中每个单元格的值,以及每个值所在行的行号(索引)。
2.2 DataFrame:二维带标签表格
DataFrame 可以理解为一个二维表格,整体由三部分组成:
| 组成部分 | pandas 术语 | 说明 |
|---|---|---|
| 行标签 | index |
标识每一行,可以是数字、字符串等 |
| 列标签 | columns |
标识每一列,类似 Excel 表格的表头 |
| 数据区域 | values |
表格中实际的数值内容 |
这里澄清一个重要术语 :在 pandas 中,行的标识叫 index(行索引) ,列的标识叫 columns(列名/列标签) 。两者都是 pandas.Index 类型。Series 只有 index(因为它只有一列),没有 columns;DataFrame 两者都有。
columns(列名)
↓
姓名 年龄 城市 性别 ← 列标签
index → ─────────────────────────
row1 张三 25 北京 男
row2 李四 30 上海 女
row3 王五 22 广州 男
...
2.3 Series 与 DataFrame 的关系
DataFrame 的每一列拿出来,就是一个 Series。
python
df['姓名'] # 取出"姓名"这一列 → 返回一个 Series| 维度 | Series | DataFrame |
|---|---|---|
| 形状 | (n,) 一维 |
(m, n) 二维 |
| 行标签 | ✅ 有 index |
✅ 有 index |
| 列标签 | ❌ 没有 columns |
✅ 有 columns |
| 类比 | Excel 中的一列 | Excel 中的一张完整工作表 |
| 取单列 | --- | 返回 Series |
| 创建方式 | pd.Series(...) |
pd.DataFrame(...) |
3. Series 详解
Series基础知识概览:
3.1 Series 的三种创建方式
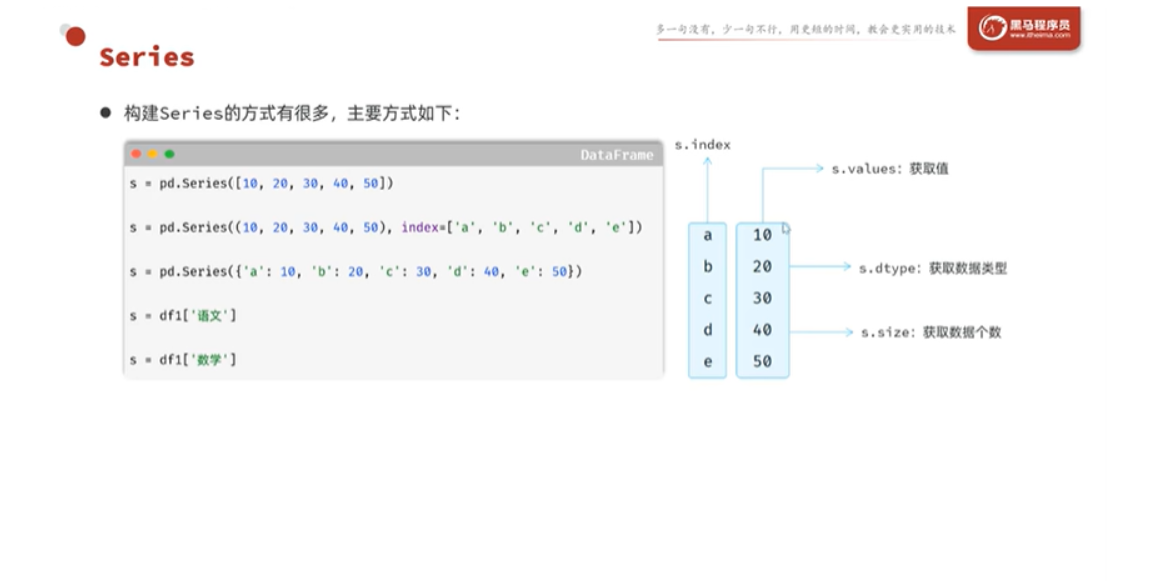
创建 Series 的核心公式很简单:数据 + 可选的索引。
方法一:传入列表(自动生成索引)
python
import pandas as pd
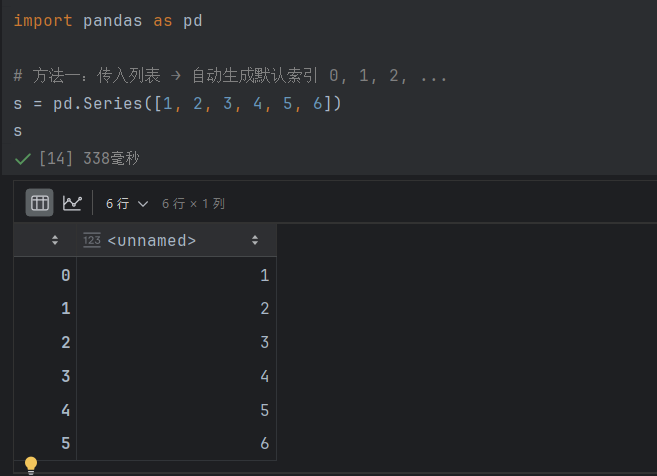
s = pd.Series([1, 2, 3, 4, 5, 6])
# 输出:
# 0 1
# 1 2
# 2 3
# 3 4
# 4 5
# 5 6
# dtype: int64不指定索引时,pandas 会自动生成从 0 开始的整数索引。
方法二:传入元组 + 手动指定 index
python
s = pd.Series((1, 2, 3, 4, 5, 6), index=["a", "b", "c", "d", "e", "f"])
# 输出:
# a 1
# b 2
# c 3
# ...注意:tuple 和 list 在 pandas 中行为几乎相同,区别仅在于元组本身不可变,但这里只是传入数据源,没有实际影响。所以也可以只写元组数据,不设置索引。这里只想说明我们可以通过index来设置索引标签名称。
方法三:传入字典(key → 索引,value → 值)
python
s = pd.Series({"a": 1, "b": 2, "c": 3, "d": 4, "e": 5, "f": 6})字典的 key 自动成为索引,value 成为对应的值。这是最自然的方式,如果当你手头已经有"键→值"映射数据时,直接传入即可。
三种方式对比
| 方法 | 输入类型 | 索引来源 | 适用场景 |
|---|---|---|---|
pd.Series([list]) |
列表 | 自动生成 0, 1, 2... |
简单序列数据 |
pd.Series(data, index=[...]) |
元组/列表 + 索引列表 | 手动指定 | 需要自定义标签名称 |
pd.Series({dict}) |
字典 | dict 的 key | 已有键值对映射数据 |
本质理解:三种方式殊途同归:都是构造"值 + 标签"的一一对应关系,区别仅在于索引是自动生成、手动指定,还是从字典 key 提取。
3.2 Series 的核心属性
创建 Series 后,可以通过以下属性快速了解它的基本情况:
python
print(s.index) # Index(['a', 'b', 'c', 'd', 'e', 'f'], dtype='object')
print(s.values) # [1 2 3 4 5 6]
print(s.dtype) # int64
print(s.size) # 6
print(s.shape) # (6,)| 属性 | 返回类型 | 说明 |
|---|---|---|
s.index |
pandas.Index |
索引对象(标签序列) |
s.values |
numpy.ndarray |
底层数值数组 |
s.dtype |
numpy.dtype |
元素的数据类型 |
s.size |
int |
元素总数 |
s.shape |
tuple |
形状,如 (6,) 表示 6 个元素的一维数据 |
s.name |
str 或 None |
Series 的名称 |
特别说明 s.name :当你用 df['列名'] 从 DataFrame 中取出一列时,返回的 Series 会自动将列名设为 name 属性。这在后续数据处理中非常有用,比如多个 Series 合并时,name 会自动成为列名。
python
# 补充属性:s.name
# 刚创建的 Series 默认没有名字
print(f"s.name = {s.name}")
# 手动设置名称
s.name = "numbers"
print(f"设置后 s.name = {s.name}")
print(s) # 可以看到 Series 上方显示了名称 "numbers"3.3 Series 的数据访问
Series 支持多种索引方式,核心需要区分两个概念:
- 按标签(label) :使用
.loc[]或直接s['标签'] - 按位置(position) :使用
.iloc[]或 Python 切片s[0:3]
按位置索引(iloc)
python
s[0:3] # 同 Python 切片知识点,半开区间 [0,3)
s.iloc[0] # 第 1 个元素 → 1
s.iloc[0:3] # 第 1~3 个(半开区间 [0,3)),同可以切片
s.iloc[[0, 2, 4]] # 第 1、3、5 个元素按标签索引(loc 或直接标签)
python
s['a'] # 标签 'a' 对应的值 → 1
s.loc['a'] # 同上,用 .loc[] 更明确
s.loc['a':'c'] # 标签 'a' 到 'c'(闭区间,包含 'c'!),同可以切片
s[["a", "d"]] # 花式索引(Fancy Indexing):同时取多个标签的值布尔过滤
python
s[s > 3] # 筛选大于 3 的元素
s[s.between(2, 5)] # 值在 2~5 之间(闭区间)
s[s.isin([1, 3, 5])] # 值是 1、3 或 5访问方式速查
| 访问方式 | 语法示例 | 区间类型 |
|---|---|---|
| 按位置(iloc) | s.iloc[0], s.iloc[0:3] |
半开 [start, end) |
| 按标签(loc) | s.loc['a'], s.loc['a':'c'] |
闭区间 [start, end] |
| 布尔过滤 | s[s > 3] |
条件筛选 |
关键区别 :
.loc[]的切片是闭区间 (包含两端),而.iloc[]和 Python 切片是半开区间(左闭右开)。这是 pandas 与其他 Python 库的一个重要差异,它更符合"按标签取值时应该包含两端"的直觉。
3.4 Series 的基本运算与统计
Series 支持向量化运算即对整个 Series 的每个元素同时执行操作,无需写 for 循环。这是 pandas 高效处理数据的核心原因之一。
算术运算(自动广播)
python
s + 10 # 每个元素加 10
s * 2 # 每个元素乘 2
s ** 2 # 每个元素平方常用统计方法
python
s.mean() # 平均值
s.sum() # 总和
s.max() # 最大值
s.min() # 最小值
s.std() # 标准差
s.median() # 中位数实用工具方法
python
s.value_counts() # 每个不同值出现的次数(频次统计)
s.unique() # 去重后的值,返回数组
s.nunique() # 唯一值的个数(去重计数)
s.isnull() # 判断每个元素是否为空,返回布尔 Series4. DataFrame 详解
DataFrame基础知识概览:

4.1 DataFrame 创建的"核心本质"
DataFrame 创建的所有方式,都可以统一为这个公式:
python
pd.DataFrame(data=数据源, index=行标签, columns=列标签)- data:数据源,可以是字典列表、列表字典、二维列表、NumPy 数组等
- index :行标签(不指定则默认
0, 1, 2...) - columns :列标签(不指定则从数据源推断,或默认
0, 1, 2...)
四种创建方法的区别仅在于"数据源的格式不同",pandas 内部解析后统一变成二维表格。 理解这一点,就不会觉得创建方式多而混乱了
4.2 DataFrame 的四种创建方式
方法一:listdict(字典列表)
每个字典是表格的一行,key 自动成为列名,value 成为该行该列的值。
python
df = pd.DataFrame([
{'姓名': '张三', '年龄': 25, '城市': '北京', '性别': '男'},
{'姓名': '李四', '年龄': 30, '城市': '上海', '性别': '女'},
{'姓名': '王五', '年龄': 22, '城市': '广州', '性别': '男'},
])适用场景:从 API 或 JSON 获取的数据,每条记录是一个独立对象,天然就是字典列表的格式。
方法二:dictlist(列表字典)
每个 key 是一列,value 列表是该列从上到下的所有值。
python
df = pd.DataFrame({
'姓名': ['张三', '李四', '王五'],
'年龄': [25, 30, 22],
'城市': ['北京', '上海', '广州'],
'性别': ['男', '女', '男'],
})适用场景:数据按列组织,比如你从数据库各列分别提取出来的统计数据。
方法三:二维列表(纯数据)
每个子列表是一行,列名默认为 0, 1, 2...。
python
df = pd.DataFrame([
['张三', 25, '北京', '男'],
['李四', 30, '上海', '女'],
['王五', 22, '广州', '男'],
])适用场景 :纯数值矩阵、从文本文件读取的原始二维数据。注意此时列名是自动生成的数字,通常需要后续用
df.columns = [...]来设置。
方法四:二维列表 + index + columns(完整控制)
python
df = pd.DataFrame(
data=[
['张三', 25, '北京', '男'],
['李四', 30, '上海', '女'],
['王五', 22, '广州', '男'],
],
index=['row1', 'row2', 'row3'],
columns=['姓名', '年龄', '城市', '性别']
)适用场景:需要完全控制行列标签时------行用什么标签,列用什么名称,全部手动指定。
四种方式对比
| 方法 | 输入格式 | 列名来源 | 适用场景 |
|---|---|---|---|
list[dict] |
字典列表 | dict 的 key | 从 API / JSON 获取数据,每条记录是独立对象 |
dict[list] |
列表字典 | dict 的 key | 数据按列组织,如从数据库列提取 |
二维列表 |
嵌套列表 | 自动 0, 1, 2... |
纯数值矩阵、原始二维数据 |
+ index + columns |
嵌套列表 + 两个参数 | 手动指定 | 需要完全控制行列标签 |
一句话理解 :这四种方式的本质都是向
pd.DataFrame()提供"数据 + 行标签 + 列标签"三要素,区别只在于 pandas 从你的输入格式中智能推断后两者的方式不同。
4.3 DataFrame 的核心属性
python
df.index # 行索引
df.columns # 列名
df.values # 底层二维数组
df.shape # 形状 (行数, 列数)
df.size # 总元素数 = 行数 × 列数
df.dtypes # 每列的数据类型| 属性 | 返回类型 | 说明 |
|---|---|---|
df.index |
pandas.Index |
行索引(行标签序列) |
df.columns |
pandas.Index |
列索引(列名序列) |
df.values |
numpy.ndarray |
底层二维数值数组 |
df.shape |
tuple |
形状 (行数, 列数) |
df.size |
int |
总元素数 = 行数 × 列数 |
df.dtypes |
Series |
每列的数据类型(因为每列类型可能不同) |
区分记忆 :
index是行 标签,columns是列 标签,两者都是pandas.Index类型。而 Series 只有index,没有columns。
4.4 DataFrame 数据访问
DataFrame 是由多个 Series 组成的二维表格。每一列本质上就是一个 Series,因此列访问与 Series 的访问逻辑完全一致;而行访问则需要使用专门的索引器。
**
df['xxx']始终优先查找列!**我思考是不是因为一列就是一个series,而要访问行,必须用.loc[](按标签)或.iloc[](按位置)。
在 DataFrame 中,直接 df[...] 这种写法默认是"列优先"的,它只认列标签,不认行标签或位置。 而行访问必须通过 .loc[] / .iloc[]。下面按"访问行"和"访问列"两大类,再按"标签索引"和"位置索引"细分,重新梳理。
4.4.1 列访问
列访问就是"取出一个或多个 Series"。主要用 df[...] 按列标签 选取,按位置选取则必须借助 .iloc[]。
| 分类 | 方法 | 返回类型 | 说明 |
|---|---|---|---|
| 按标签 | df['姓名'] |
Series | 取单列,列名就是标签 |
df.姓名 |
Series | 属性式写法(列名需为合法标识符) | |
df[['姓名', '年龄']] |
DataFrame | 取多列,注意双层方括号 | |
df.loc[:,"姓名":"性别":2] |
DataFrame | 取多列,可以用loc搭配标签使用,可单列,多列,切片 | |
| 按位置 | df.iloc[:, 0] |
Series | 取第 1 列(列位置从0开始) |
df.iloc[:, [0, 2]] |
DataFrame | 取第 1、3 列 | |
df.iloc[:, 0:2] |
DataFrame | 取第 1~2 列(半开区间 [0,2)) |
python
df['姓名'] # 单列
df[['姓名', '年龄']] # 多列
# df['姓名':"性别"] #df[...] 传入切片时,pandas 会把它理解为对"行"的切片,而不是对"列"的切片。
df.loc[:,"姓名":"性别":2] #多列
# ---- 按位置 ----
df.iloc[:, 0] # 第 1 列
df.iloc[:, 0:2] # 第 1~2 列
df.iloc[:, [0, 2]] # 第 1、3 列 ⚠️ 为什么不能直接用
df[0]取第一列?
df[...]的查找逻辑是优先匹配列名(标签) 。写df[0]时,pandas 会认为你在找列名叫0的列 ,而不是第 1 列。如果没有这个列名,就会报错。所以按位置取列必须使用.iloc[]。
4.4.2 行访问
行访问不能 使用 df[...],必须通过 .loc[](按标签)或 .iloc[](按位置)。
| 分类 | 方法 | 返回类型 | 说明 |
|---|---|---|---|
| 按标签 | df.loc['row1'] |
Series | 取标签为 'row1' 的行 |
df.loc[['row1', 'row3']] |
DataFrame | 取多行(标签列表) | |
df.loc['row1':'row3'] |
DataFrame | 标签切片,闭区间 (包含 'row3') |
|
| 按位置 | df.iloc[0] |
Series | 取第 1 行 |
df.iloc[[0, 2]] |
DataFrame | 取第 1、3 行 | |
df.iloc[0:3] |
DataFrame | 位置切片,半开区间 [0,3),不包含第4行 |
|
| 快捷查看 | df.head(5) / df.tail(3) |
DataFrame | 快速查看前/后 N 行 |
python
# ---- 按标签 ----
df.loc['row1'] # 单行 → Series
df.loc[['row1', 'row3']] # 多行 → DataFrame
df.loc['row1':'row3'] # 标签切片,闭区间,包含 'row3'
# ---- 按位置 ----
df.iloc[0] # 第 1 行 → Series
df.iloc[0:3] # 第 1~3 行(半开区间,不含 iloc[3])
# ---- 快捷方法 ----
df.head(5) # 前 5 行
df.tail(3) # 后 3 行4.4.3 行+列联合访问 & loc vs iloc 核心对比
同时选取行和列,只需把行索引和列索引用逗号隔开,loc 用标签,iloc 用位置。
python
# loc:行按标签,列按标签
df.loc['row1':'row3', ['姓名', '年龄']] # 行标签闭区间 + 列名列表
# iloc:行按位置,列按位置
df.iloc[0:3, 0:2] # 行位置半开区间 + 列位置半开区间4.5 数据概览方法
拿到一个 DataFrame 后,通常先用以下方法快速了解数据全貌:
df.info() --- 结构信息
显示每列的非空计数 、数据类型 和内存占用,是检查缺失值和数据类型是否正确的第一选择。
python
df.info()
# 输出:列数、每列的非空计数、Dtype、内存使用量df.describe() --- 统计摘要
- 默认 (不加参数):只对数值列进行统计(count、mean、std、min、25%、50%、75%、max)
include='all':数值列显示数值统计,字符串列显示 count、unique、top、freq(出现最多的值及其频次)
python
df.describe() # 仅数值列统计
df.describe(include='all') # 所有列的完整摘要小贴士 :用
include='all'后,数值列在unique、top、freq等分类统计项中会显示NaN,这不是数据有问题,而是"这些统计量对数值型不适用"的正常表现。
4.6 布尔过滤与条件筛选
从一个大的 DataFrame 中,按条件筛选出你关心的子集。
核心原理(两步走)
python
# 步骤 1:生成布尔 Series
df['年龄'] > 30 # → 每个元素是否 > 30 的 True/False 序列
# 步骤 2:用布尔 Series 过滤原始 DataFrame
df[df['年龄'] > 30] # → 只保留 True 对应的行df['列名'] 返回的是一个 Series,而 Series 支持向量化的比较运算(>、==、< 等)。比较的结果是一个布尔 Series,再把它传给 df[...],pandas 就会只保留对应位置为 True 的行。
4.6.1 单条件筛选
| 操作 | 语法 | 说明 |
|---|---|---|
| 比较运算 | df[df['年龄'] > 30] |
>, <, >=, <=, ==, != 均可用 |
| 精确匹配 | df[df['城市'] == '北京'] |
字符串用 == 比较 |
| 多值匹配 | df[df['城市'].isin(['北京', '上海'])] |
匹配列表中的任一值 |
| 区间筛选 | df[df['年龄'].between(25, 30)] |
默认闭区间,详见下方 |
between() 的 inclusive 参数
between(left, right, inclusive='both') 的 inclusive 参数控制是否包含左右边界:
| inclusive 值 | 区间类型 | 含义 | 示例:between(25, 30) |
|---|---|---|---|
'both'(默认) |
[left, right] |
闭区间 | 包含 25 和 30 |
'left' |
[left, right) |
左闭右开 | 包含 25,不含 30 |
'right' |
(left, right] |
左开右闭 | 不含 25,包含 30 |
'neither' |
(left, right) |
开区间 | 25 和 30 都不包含 |
python
df[df['年龄'].between(25, 30)] # 默认:25 ≤ 年龄 ≤ 30
df[df['年龄'].between(25, 30, inclusive='left')] # 25 ≤ 年龄 < 30
df[df['年龄'].between(25, 30, inclusive='right')] # 25 < 年龄 ≤ 30
df[df['年龄'].between(25, 30, inclusive='neither')] # 25 < 年龄 < 304.6.2 多条件组合
| 操作 | 语法 | 说明 |
|---|---|---|
| 与(AND) | df[(条件1) & (条件2)] |
两个条件同时满足 |
| 或(OR) | `df[(条件1) | (条件2)]` |
| 非(NOT) | df[~(条件)] |
条件取反 |
python
# AND:年龄在 25 到 30 之间
df[(df['年龄'] >= 25) & (df['年龄'] <= 30)]
# OR:年龄大于 35 或城市是北京
df[(df['年龄'] > 35) | (df['城市'] == '北京')]
# NOT:城市不是北京也不是上海
df[~(df['城市'].isin(['北京', '上海']))]为什么 & 和 | 必须用小括号?
这是一个非常常见的坑。Python 的运算符优先级 中,位运算符 & 和 | 的优先级高于 比较运算符 >、<、==。
python
# ❌ 错误写法
df[df['年龄'] > 30 & df['年龄'] < 35]
# Python 实际解析为:
# df['年龄'] > (30 & df['年龄']) < 35
# 先算 30 & df['年龄'](整数 & Series)→ 报 TypeError
python
# ✅ 正确写法
df[(df['年龄'] > 30) & (df['年龄'] < 35)]
# 先算括号里的比较 → 得到布尔 Series → 再用 & 连接另一个注意事项 :不能用 Python 关键字
and/or代替&/|。因为and/or要求两边是单个布尔值,而df['年龄'] > 30返回的是一个布尔 Series(多个值),and/or无法处理。必须使用位运算符&/|,它们对 Series 执行逐元素的布尔运算。
希望这篇笔记能帮你理清 pandas 的基础框架。配套的 Series.ipynb 和 DataFrame.ipynb 包含了文中所有代码的可运行版本,可以边读边动手实践。
以上为个人学习总结,旨在梳理个人理解。如有疏漏或不当之处,欢迎指正与交流。如果文章对你有帮助,别忘了点个赞、留个言,让更多的小伙伴看到~ 我们下篇再见!
📁 配套代码:Series.ipynb | DataFrame.ipynb
📅 更新日期:2026-06-06