K8s 中 Pod 的底层架构和容器组成:
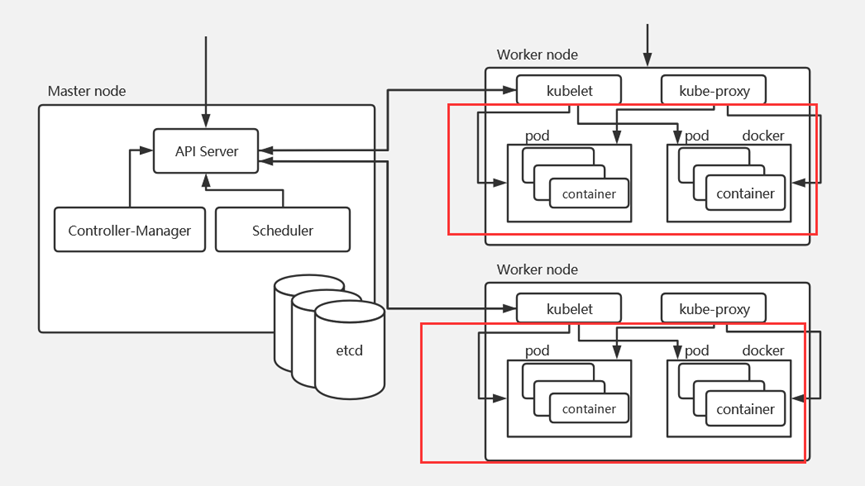
整体架构分层(先看大结构)
这张图分为 2 大区域:
-
**左侧:Master Node(控制平面)** ------ 负责"发号施令"
-
**右侧:Worker Node(工作节点)** ------ 负责"干活执行"
二、 左侧:Master Node(控制平面)组件
控制平面的核心是 "让集群按期望运行" ,所有指令都经过
API Server。
| 组件 | 作用 | 图中位置 |
|---|---|---|
| API Server | K8s 的 唯一入口,所有操作(kubectl、控制器、调度器)都找它 | 中间矩形 |
| Controller-Manager | 运行各种 控制器(Deployment、RS、Node 等),保证"期望状态"="实际状态" | 左下 |
| Scheduler | 调度 Pod,根据资源、亲和性等,选一个合适的 Worker Node | 右下 |
| etcd | 分布式存储,保存集群所有资源的状态(Pod、Service、RS 等) | 下方圆柱 |
📌 控制流逻辑(箭头方向):
-
你用
kubectl发请求 → 打到 API Server -
API Server → 存到 etcd(记录状态)
-
Controller-Manager 监听 API Server,发现"实际状态≠期望状态" → 调谐(比如重建 Pod)
-
Scheduler 监听 API Server,发现新 Pod 没调度 → 选一个 Worker Node → 通知 API Server
三、 右侧:Worker Node(工作节点)组件
工作节点的核心是 "运行 Pod",所有容器都在这里跑。
| 组件 | 作用 | 图中位置 |
|---|---|---|
| kubelet | 每个 Worker Node 一个,监听 API Server,根据 PodSpec 拉镜像、启容器、汇报状态 | 上方矩形 |
| kube-proxy | 维护 iptables/IPVS 规则,实现 Service → Pod 流量转发 | 上方矩形(和 kubelet 并列) |
| pod | K8s 最小调度单位,里面跑 container(容器) | 红色框内 |
| docker(或 containerd) | 真正跑容器的 容器运行时 | 红色框内(pod 旁边) |
📌 运行流逻辑(箭头方向):
-
API Server 收到 Scheduler 的调度结果 → 通知对应 Worker Node 的 kubelet
-
kubelet → 调用 docker → 拉镜像、启容器 → 形成 pod(里面包含 container)
-
kube-proxy → 监听 API Server 的 Service 变化 → 写 iptables/IPVS 规则 → 让外部流量能访问到 Pod
四、 图的"细节亮点"(容易被忽略的点)
1. 红色框:pod和 docker的关系
-
图中红色框内,
pod是 逻辑概念 (K8s 的调度单位),docker是 实际运行环境(容器运行时)。 -
一个
pod里可以有 多个 container (比如 pause + 业务容器 + init 容器),这些 container 都由docker启动。
2. 箭头双向性
-
API Server和etcd之间是 双向箭头:-
API Server → etcd:写状态(比如创建 Pod)
-
etcd → API Server:读状态(比如查询 Pod)
-
-
API Server和kubelet之间也是 双向箭头:-
API Server → kubelet:下发 Pod 配置
-
kubelet → API Server:汇报容器状态(Running、Failed 等)
-
3. 两个 Worker Node 的重复结构
- 图中画了 两个 Worker Node ,说明 K8s 是 多节点集群 ,每个节点都有
kubelet+kube-proxy+pod+docker。
五、 结合"创建 Pod"的流程(串联整张图)
我们拿 **"kubectl create -f pod.yaml"** 来串一遍:
-
kubectl → 调用 API Server(Master 节点)
-
API Server → 把 Pod 对象写入 etcd(存状态)
-
Scheduler 监听 API Server → 发现新 Pod 没调度 → 选一个 Worker Node(比如 Worker 1) → 通知 API Server
-
API Server → 通知 Worker 1 的 kubelet
-
kubelet → 调用 docker → 拉镜像、启容器 → 形成 pod(里面有 container)
-
kubelet → 向 API Server 汇报:"Pod 已 Running"
-
kube-proxy → 监听 API Server,如果 Pod 被 Service 关联 → 写 iptables 规则 → 让外部能访问
一、Pod 内容器的类型(必须掌握)
✅ Pod = 一组共享 Network / IPC / Volume 的容器集合
1️⃣ pause 容器(基础设施容器)
-
第一个启动
-
作用:
-
创建 Linux namespace(network / ipc / pid)
-
为业务容器提供:
-
共享网络栈(同一个 IP / localhost)
-
共享存储卷
-
-
-
特点:
-
不跑业务
-
生命周期 = Pod 生命周期
-
📌 一句话:
pause 容器是 Pod 的"地基",所有容器都站在它上面。
2️⃣ init 容器(InitContainer)
-
在业务容器之前串行执行
-
作用:
-
初始化环境
-
等待依赖服务就绪
-
拉配置、改权限、预检查
-
-
特点:
-
必须 全部成功退出(exit 0)
-
任何一个失败 → Pod 重启 / 卡住
-
📌 常见场景:
-
等数据库 ready
-
下载配置文件
-
初始化数据库表
3️⃣ 业务容器(Container)
-
真正跑服务的
-
并行启动
-
受探针 & 重启策略管理
✅ 启动顺序总结(必考)
纯文本
纯文本
pause 容器
↓
init 容器(串行)
↓
业务容器(并行)二、Pod 的三种类型(重点区分)
| 类型 | 是否受控制器管理 | 是否自动重建 | 典型场景 |
|---|---|---|---|
| 自主式 Pod | ❌ | ❌ | 临时测试 |
| 控制器 Pod | ✅ | ✅ | 99% 生产 |
| 静态 Pod | ❌ | ✅(kubelet) | Master 组件 |
1️⃣ 自主式 Pod
-
直接
kubectl run或 YAML 创建 -
挂了就挂了
-
不会被重建
📌 面试坑:
自主式 Pod 不是"不能恢复",而是没有控制器帮你恢复
2️⃣ 控制器管理的 Pod(最常用)
-
Deployment / StatefulSet / DaemonSet / Job
-
保证副本数、版本、滚动更新
3️⃣ 静态 Pod
-
由 kubelet 直接管理
-
文件路径:
/etc/kubernetes/manifests -
特点:
-
不走 apiserver
-
不调度
-
常用于:
-
kube-apiserver
-
kube-controller-manager
-
kube-scheduler
-
-
📌 面试高频:
静态 Pod 在
kubectl get pods能看到,但删不掉(删了 kubelet 又拉起来)
三、ImagePullPolicy(镜像拉取策略)
| 策略 | 行为 |
|---|---|
| IfNotPresent | 本地有就用,没有就拉 |
| Always | 每次都拉(默认用于 latest) |
| Never | 只用本地,不拉 |
📌 生产规范:
-
非 latest 镜像 →
IfNotPresent -
latest 镜像 →
Always -
离线环境 →
Never
四、RestartPolicy(容器重启策略)
| 策略 | 说明 |
|---|---|
| Always | 只要退出就重启(默认) |
| OnFailure | 非 0 才重启 |
| Never | 永不重启 |
📌 联系 Pod 类型:
-
Deployment → 几乎都是
Always -
Job / CronJob →
OnFailure / Never
五、Harbor 镜像推送
bash
bash
docker tag nginx:latest 192.168.110.141/ruoyi/nginx:ruoyi-vue
docker login -u admin -pHarbor12345 192.168.110.141
docker push 192.168.110.141/ruoyi/nginx:ruoyi-vue📌 K8s 使用:
yaml
yaml
image: 192.168.110.141/ruoyi/nginx:ruoyi-vue
imagePullSecrets:
- name: harbor-secret六、Pod 资源限制(Requests / Limits)
yaml
yaml
resources:
requests:
cpu: 200m
memory: 300Mi
limits:
cpu: 500m
memory: 500Mi📌 核心概念:
-
requests:调度依据(Node 是否有资源)
-
limits:最大可用上限(OOM 杀手依据)
📌 面试必说:
requests 决定能不能调度,limits 决定会不会被 kill
七、K8s 驱逐机制(Eviction)
1️⃣ 驱逐触发条件
-
Node 资源不足:
-
memory.available
-
nodefs.available
-
imagefs.available
-
pid.available
-
📌 硬阈值示例:
yaml
yaml
eviction-hard:
memory.available < 100Mi2️⃣ QoS 等级(决定谁先死)
| QoS | 说明 |
|---|---|
| Guaranteed | requests = limits(最后被杀) |
| Burstable | 有 requests / limits(中间) |
| BestEffort | 无限制(最先被杀) |
✅ 驱逐优先级:
纯文本
纯文本
BestEffort → Burstable → Guaranteed八、容器健康检查(三大探针)
1️⃣ 三种探针的区别(必背)
| 探针 | 作用 | 失败后果 |
|---|---|---|
| startupProbe | 判断"是否启动完成" | Pod 启动失败 |
| livenessProbe | 判断是否活着 | 重启容器 |
| readinessProbe | 是否可接流量 | 从 Service 摘除 |
📌 启动顺序:
纯文本
纯文本
startupProbe → livenessProbe + readinessProbe2️⃣ 探测方式
| 方式 | 说明 |
|---|---|
| HTTPGet | /health返回 200 |
| TCPSocket | 端口能连 |
| Exec | 执行命令返回 0 |
📌 MySQL 示例
bash
bash
mysql -uroot -pabc123 -e "show slave status\G" | grep -c "Yes"九、一句话总结(面试收尾)
Pod 由一个 pause 容器提供基础环境,init 容器做初始化,业务容器跑服务;
Pod 由控制器管理可实现自愈,通过 requests / limits 限制资源,
依靠 startup / liveness / readiness 探针判断容器状态,
在资源不足时,K8s 根据 QoS 等级进行驱逐,保障集群稳定性。