3.2 卷积流程
我们现在设计一个卷积神经网络的实验,比如识别一张图片是猫还是狗。
3.2.1 输入层
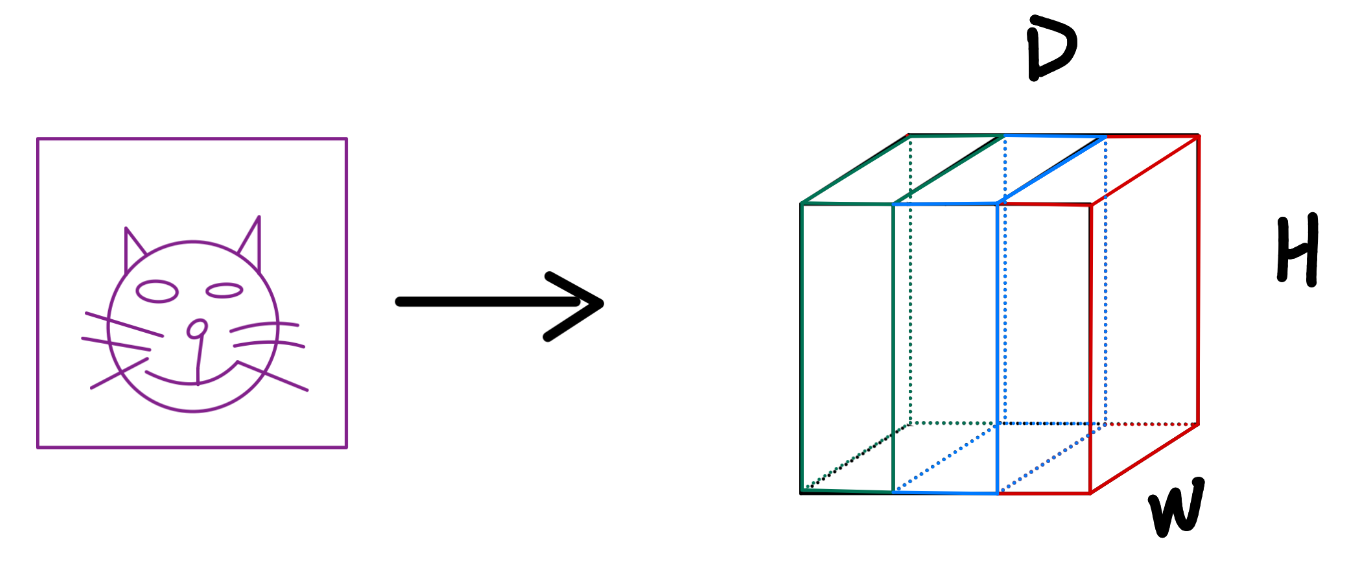
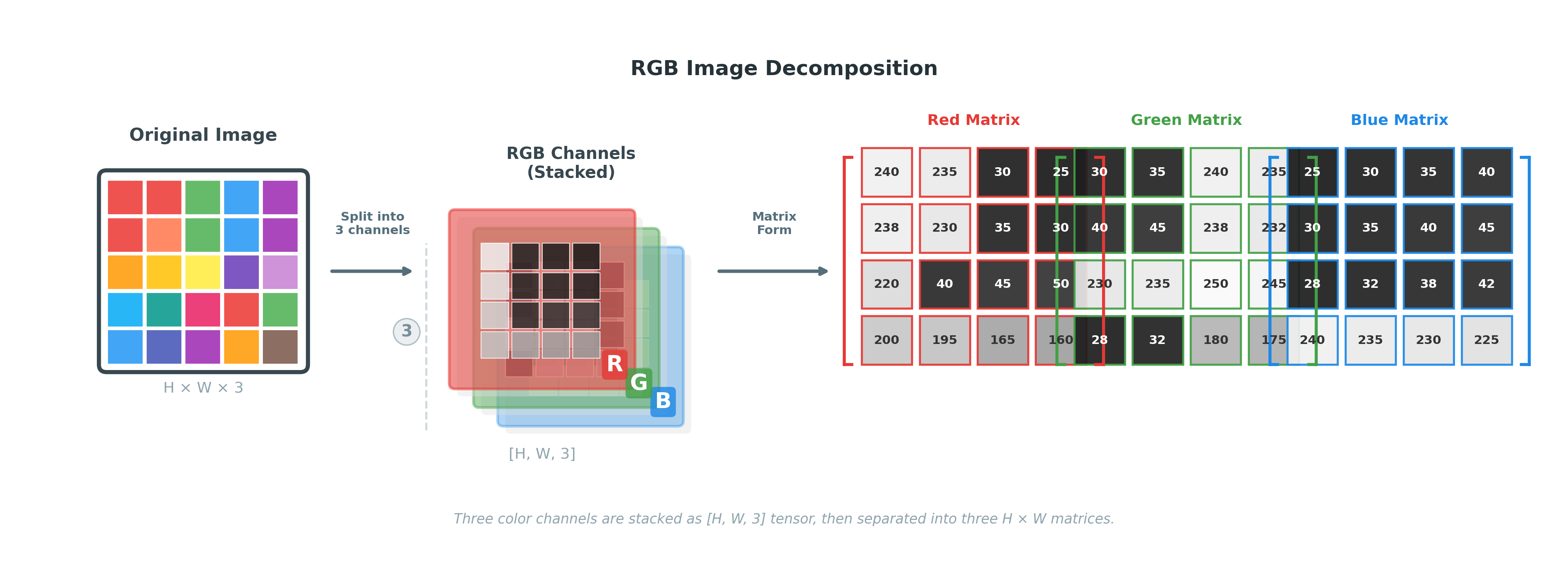
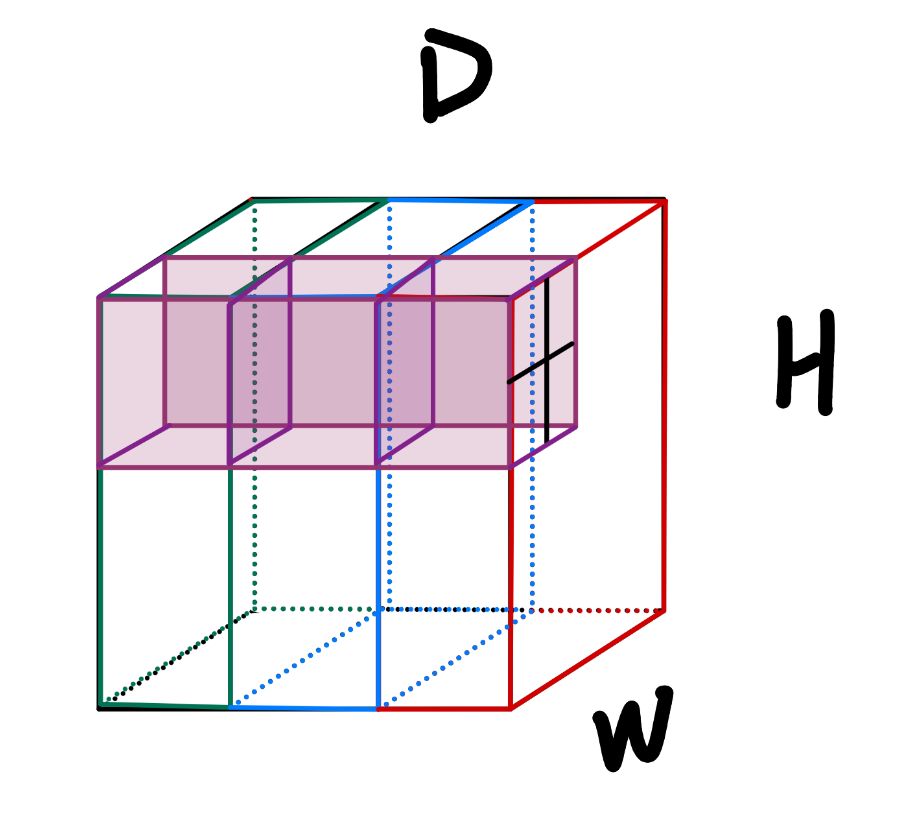
现在我们有一张n*n大小的RGB图片的输入,RGB图片是三通道的,这代表这张图片在输入时就包含红、绿、蓝三个维度的信息。所以一张RGB图片输入给模型的输入层实际上是输入了一个n*n*3的tensor(张量)。
所以实际上一张RGB图片在输入层应该长这样:
H*W*D = n*n*3,图片的RGB三个通道的数据是不同的
3.2.2 卷积层
那如何从一张初始的RGB图片提取浅层、中层、深层语义信息呢?就是用卷积。
书中已经提到的一维卷积和二维卷积是具体的计算方法
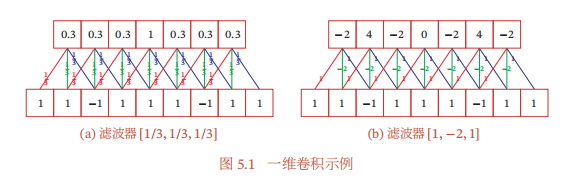
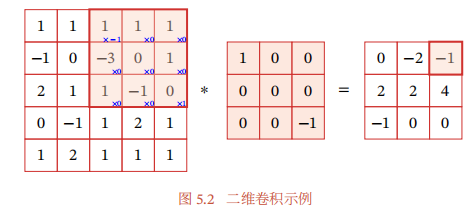
而实际上我们会发现,一张初始RGB图片是三维的,是3通道的n维矩阵,二维卷积核只能在n维矩阵上进行卷积,那3通道怎么处理?
实际上,卷积核也是三维的,卷积核的第三维是和输入图像的通道数匹配的。下面我们来解释这个三维体现在哪。
例如,就本实验的猫狗识别任务,初始输入一张RGB图像,现在我们来设计第一层卷积:
本质上,通道就是特征,RGB三通道就代表着我们现在有红绿蓝三个维度的特征信息。现在,我们想利用这三个维度的信息,去挖掘更多维度的信息(比如外形、毛发、耳朵等等)。
注:一个卷积核是专门提取一个特征的,解释如下:
卷积运算可以从图像中提取自己关注的抽象特征,一个卷积核就是一组固定的权重 。它在图像上滑动时,做的是模板匹配(互相关运算)。
如果核的权重设计成"检测垂直边缘",那么:
遇到垂直边缘 → 输出大值(激活)
遇到水平边缘 → 输出小值(抑制)
遇到空白区域 → 输出接近 0
一个核只有一套固定权重,所以它只能匹配一种固定模式。 但它能检测这个特征的所有位置,虽然一个核只提取一种 特征,但它在所有空间位置扫描。同一个"垂直边缘检测器",在图像左上角检测到就激活左上角,在右下角检测到就激活右下角。
所以一个核 = 一种特征 + 全图位置。输出特征图上的每个像素,都是该核在对应位置的反应强度。
比如,有一个卷积核K专注于找尖角(比如猫耳朵,当然实际不是这样,这牵扯到可解释性的问题)。K扫描全图(图可能是多通道的)得到一个二维特征图(一个二维的矩阵),这个特征图就表示了尖角这个新的特征,即一个新的维度(通道)。
想挖掘更多维度就要更多的卷积核。
现在,既然我们想从三个维度挖掘更多维度,我们就需要设计更多个卷积核。假设第一层卷积包含4个卷积核,就是想从RGB三个颜色维度提取出4种全新的特征。假设4个全新的特征是:
核1:边缘
核2:颜色边界
核3:颜色斑点
核4:简单纹理。
卷积核是如何工作的?如下:
以核1(2*2*3的卷积核)为例,核1应该长这样:
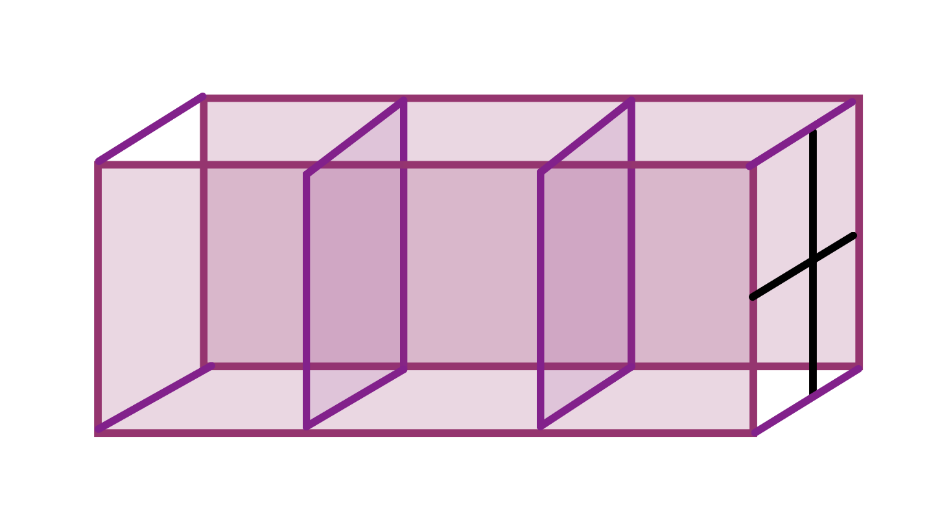
解释一下:
核1是2*2*3的,2*2是卷积核每层的大小,3是对应3通道的深度。
左半部分卷积核每一层我画成立体的矩阵是为了好看,实际上每层是没有深度的,就是二维矩阵(就像右边一样)。
核的每层数值是不同的(具体是多少是由反向传播决定的),是因为每层所提取的通道是不同的。
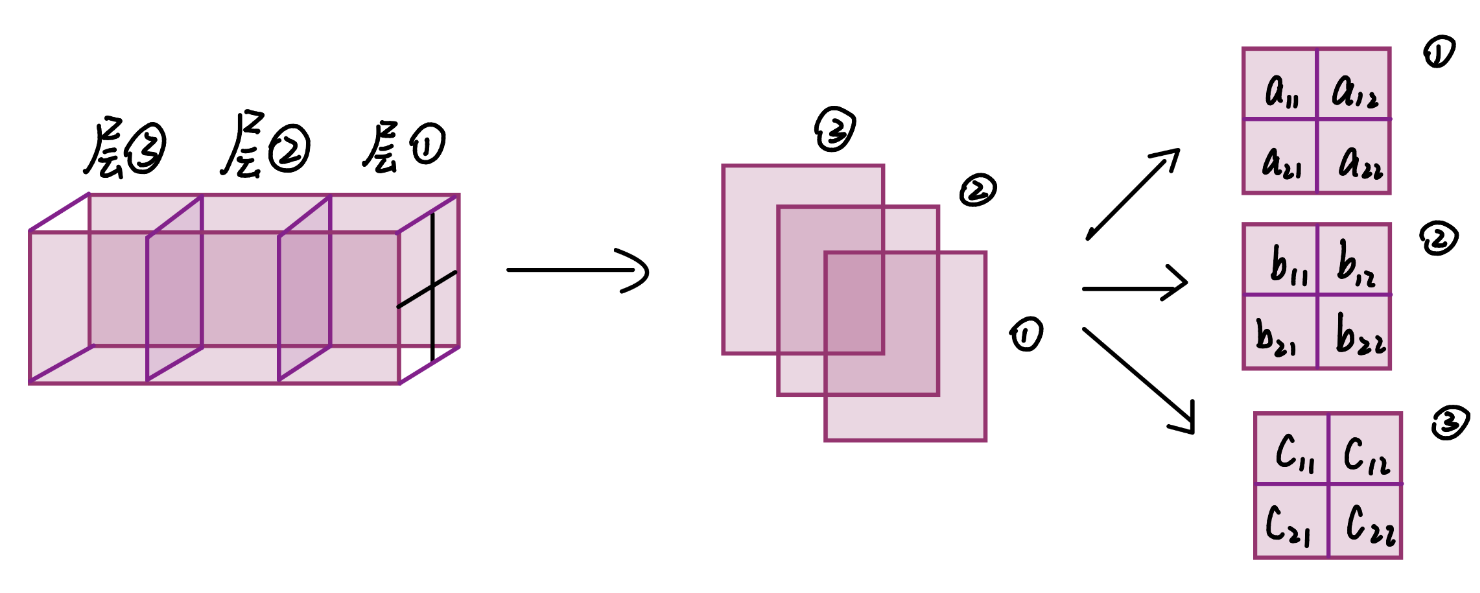
每层所提取的通道是不同,即在RGB图中卷积应该是这样,然后扫描整个图像:
就比如这里,卷积核1的层1只与R通道卷积,层2只与G通道卷积,层3只与B通道卷积。
核1的目的是从RGB三个特征的信息中,提取一个新的特征:边缘信息。而边缘信息在三个特征中的表现应该是不一样的 (由模型自己学习,如果一样的话模型会自行将三层的数值统一),所以每层都只与对应通道进行卷积,并且每层的数值也不一样(不同通道对边缘信息都有各自的表现,所以卷积核的每层数值也应不一样,使得核的每层都能在对应的通道中学习到边缘特征)
所以,核1对RGB图像的卷积过程是这样的:
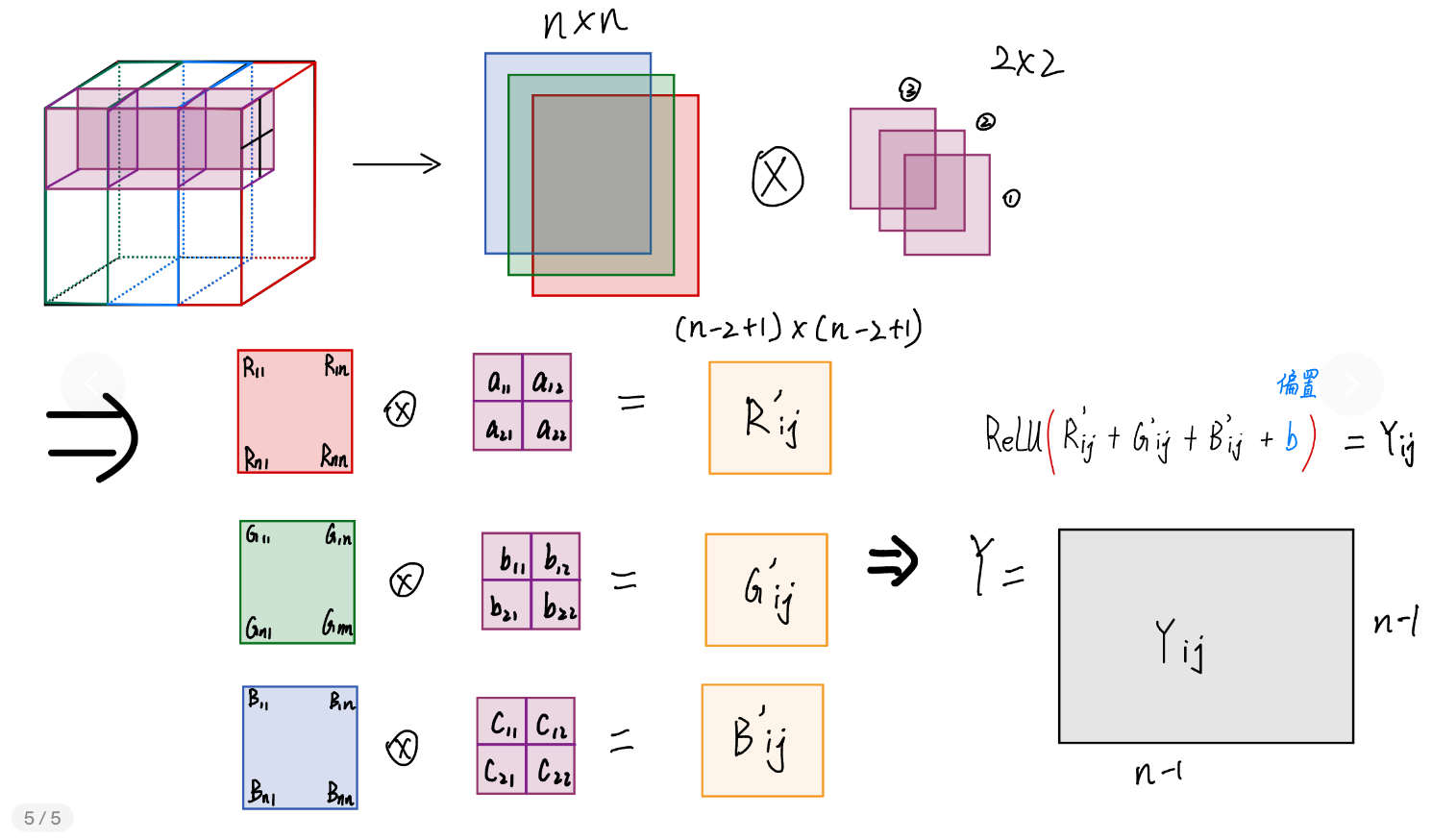
每层各自与对应通道卷积后,对结果求和并加上偏置b,再加上非线性ReLU得到最终结果:特征矩阵Y。Y是二维的,即Y只是一个通道(切片矩阵)。
补充:
不同特征融合为一个新的特征不应该是更复杂的计算吗?为什么是简单的不同通道经卷积后求和?
解答:
这个求和其实不是简单的 1+1=2,而是"带系数的线性组合":
输出 = w_r · R特征 + w_g · G特征 + w_b · B特征 + b
具体例子:求和如何实现"复杂融合"
假设在某一层,网络想检测"黄色物体"(红+绿=黄):
通道 卷积核权重设计(训练学出来的) 效果 R 全为 +1 红色强烈支持 G 全为 +1 绿色强烈支持 B 全为 0 蓝色不参与 输出 = 1×R + 1×G + 0×B = R+G
求和的结果就是"黄色检测器"。
再假设网络想检测"红色边缘,但抑制蓝色背景":
通道 权重 效果 R +2 红色信号放大 G -0.5 绿色信号轻微抑制 B -1 蓝色背景强烈抑制 输出 = 2×R - 0.5×G - 1×B
这不是简单求和,这是"选择性增强与抑制"的融合策略。
并且,非线性在激活函数里。
卷积层的完整运算其实是:
输出 = ReLU( 卷积结果 )
= ReLU( w_r·R + w_g·G + w_b·B + b )
k×k×3的三层卷积核确实各自提取各自通道的特征,但"求和"不是粗暴相加,而是"用学习到的权重做线性组合"。这个权重可以是正的、负的、大的、小的,本质上就是一个微型分类器在做决策:"R 通道给我多少分,G 通道给我多少分,B 通道给我多少分,加起来够不够激活"。再加上 ReLU 的非线性裁剪,这种简单的设计已经足够表达"只看红色""只看亮度""抑制背景"等复杂融合策略。你可以把它理解为:64 个卷积核就是 64 个"微型投票委员会",每个委员会里有 3 个委员(RGB),它们各自打分,最后加起来看总分够不够。委员会的成员权重是训练出来的,所以不同的委员会会自动演化出不同的投票策略。
这里可参考教材理解:

这只是从初始输入的RGB图像中提取一个新的特征(特征映射Y),而我们想提取四个新的特征,所以我们要用到四个卷积核,**每个卷积核重复上面的步骤,**最后我们得到了四个特征映射:
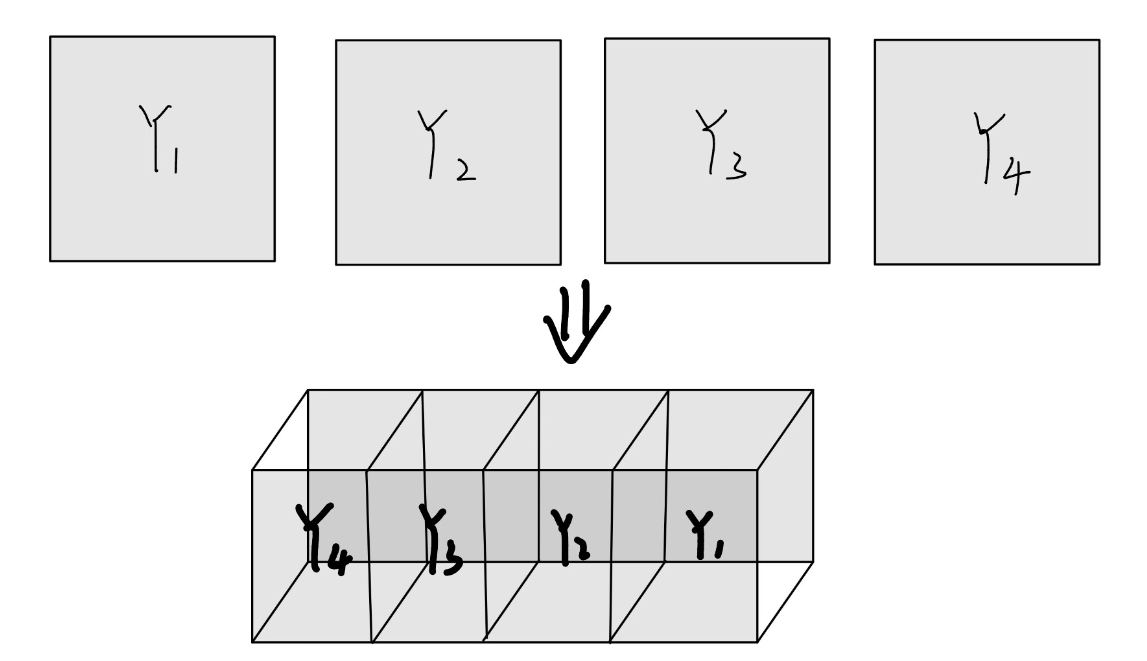
即输出特征映射组 ,传递给下一层。
3.2.3 汇聚层/池化层

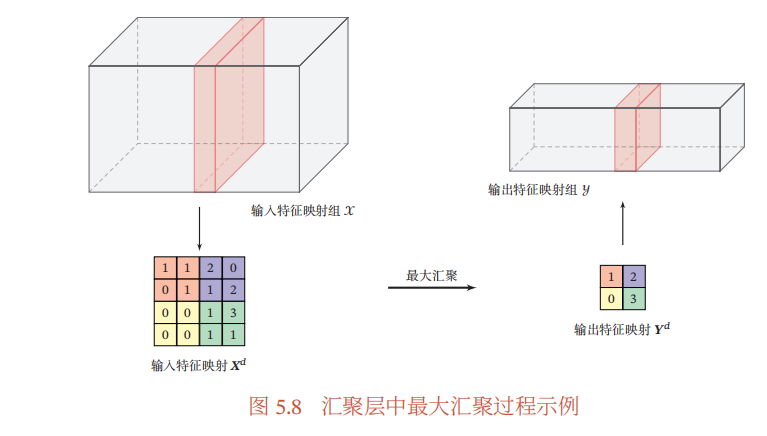

这不难理解。
3.2.4 全连接层核决策头
这里就需要具体模型具体分析,不同的任务中是不一样的。
传统做法:展平 + 全连接层
早期网络(LeNet、AlexNet、VGG)的标准流程:
卷积层输出: batch, 512, 7, 7 ← 512通道,7×7空间尺寸
↓
Flatten(展平): batch, 512×7×7 = batch, 25088 ← 拉成一维向量
↓
全连接层 FC1: batch, 4096
↓
全连接层 FC2: batch, 4096
↓
输出层 FC3: batch, num_classes ← 1000 类(ImageNet)或 2 类(猫狗)
为什么要展平? 全连接层的数学定义是 y = Wx + b,其中 W 是二维矩阵。它要求输入必须是一维向量 。卷积输出是 4 维张量 [batch, channel, H, W],所以必须展平才能送进全连接层。
现代替代:全局平均池化(GAP)
从 Network in Network(2013)和 ResNet(2015)开始,很多网络不用全连接层:
卷积层输出: batch, 512, 7, 7
↓
Global Average Pooling: 对 7×7 空间维度取平均 → batch, 512, 1, 1
↓
squeeze: batch, 512 ← 不需要展平,直接变成一维
↓
全连接层(或 1×1 卷积): batch, num_classes
GAP 的优势:
-
参数极少:没有 25088×4096 这种巨大权重矩阵,抗过拟合
-
保留空间语义:512 个通道每个对应一种高级特征,取平均后保留特征强度
-
可接受任意输入尺寸 :全连接层要求固定输入维度(因为权重矩阵尺寸固定),而 GAP 后总是输出
channel个数,与输入图大小无关
CNN 的最后输出层可以 是全连接层,也可以不是。展平操作是配合全连接层的权宜之计,现代网络更倾向于用池化或卷积来避免这一步骤,从而减少参数并增强鲁棒性。