大家好,我是锋哥。最近连载更新《LangChain4j 视频教程,开发Java Agent智能体》技术专题。

本课程主要介绍和讲解 LangChain4j 简介,阿里云百炼大模型平台接入,Ollama简介以及安装和使用,HelloWorld 实现,日志配置,集成SpringBoot,Ai Service 使用,对话与提示词工程(Prompt),结构化输出,会话记忆,工具调用(Function Calling),嵌入模型与向量数据库,RAG(检索增强生成),MCP(模型上下文协议),多模态支持。同时也配套视频教程 《2027版本 LangChain4j 视频教程,开发Java Agent智能体》
一,什么是嵌入模型
1.1 什么是嵌入?
简单来说,嵌入(Embedding)是一种将非数字数据(如单词、句子、图像、甚至整个文档)转换为计算机能够理解的数字向量的技术。
向量是数学、物理学及工程科学中的基础概念,指同时具有大小和方向的量,与只有大小没有方向的标量(如温度、质量)相对。
- 数据:比如一句话:"我喜欢吃苹果"。
- 向量 :经过嵌入模型处理后,这句话会变成一个由数百个浮点数组成的数组,例如:
[0.125, -0.342, 0.987, ..., 0.045]。
这个向量不是随机生成的,它通过复杂的神经网络模型训练得出,能够捕获原始数据的语义信息。
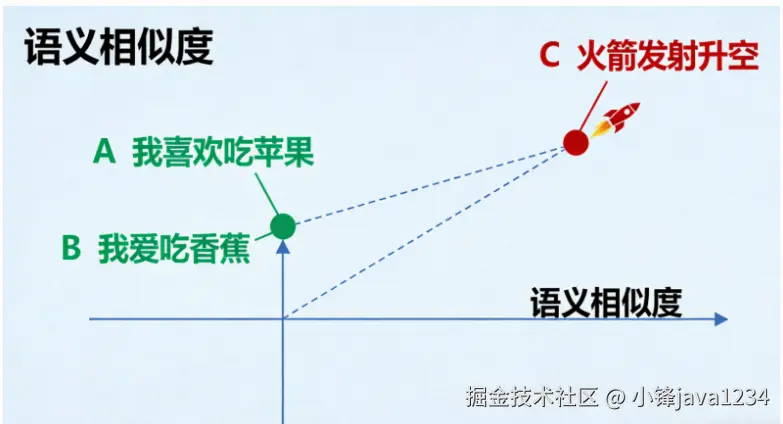
1.2 嵌入模型的核心作用:将"意义"映射到"向量空间"
嵌入模型最关键的特性是,它会把相似的语义内容映射到向量空间中的相近位置。
-
例子:
- 句子A:"我喜欢吃苹果"
- 句子B:"我爱吃香蕉"
- 句子C:"火箭发射升空"
经过嵌入模型后,在向量空间中:
- 句子A和句子B的距离会非常近(因为都是表达对水果的喜爱)。
- 句子C与A、B的距离会非常远(因为讨论的是完全不同的主题)。
1.3 为什么需要嵌入模型?
- 语义搜索:传统的搜索引擎依赖关键词匹配(比如搜索"苹果"只会返回包含"苹果"这两个字的结果)。而基于嵌入的搜索是语义上的理解和匹配,即使搜索"一种富含维生素的水果",也能找到关于"苹果"的文档。
- 信息压缩与表示:将一个复杂的对象(图片、长文本)压缩成一个固定长度的、富含语义信息的向量。
- 作为大模型的"外部记忆" :这是最广泛的应用之一。大模型的知识是静态的(训练到某个时间点),且上下文窗口有限。通过嵌入,我们可以将海量的私有知识(公司文档、产品手册)向量化,然后在需要时检索出最相关的部分,再"喂"给大模型,让它基于这些知识回答问题,从而解决模型的知识局限和幻觉问题。
1.4 常见嵌入模型
- OpenAI 的 text-embedding-3-small 和 text-embedding-3-large:目前性能强大的通用文本嵌入模型。
- BAAI/bge- 系列*:北京智源研究院开源的优秀中英文嵌入模型。
- sentence-transformers:一个非常流行的Python库,提供了大量预训练的句子、段落嵌入模型。
- 多模态嵌入模型 :如
CLIP,可以将图片和文本嵌入到同一个向量空间,实现文本搜图、图搜图等功能。
阿里百炼平台的嵌入模型,
项目里,application.yml里我们指定下嵌入模型和维度
yaml
langchain4j:
open-ai:
embedding-model:
api-key: ${OPENAI_API_KEY}
model-name: text-embedding-v4
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
dimensions: 1024 # 可选;v4 支持 64/128/256/512/768/1024/1536/2048
log-requests: true
log-responses: true然后controller包下,新建MyEmController,以及注入embeddingModel,新建em测试方法。
kotlin
package com.java1234.controller;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.output.Response;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.Arrays;
@RestController
public class MyEmController {
@Autowired
private EmbeddingModel embeddingModel;
@RequestMapping("/em")
public String em() {
Response<Embedding> response=embeddingModel.embed("学java上java1234.com");
float[] vector = response.content().vector(); // 浮点数组
int dim = response.content().dimension(); // 维度,应与 dimensions 配置一致
System.out.println(Arrays.toString(vector) +":"+vector.length+":"+dim);
return "OK";
}
}浏览器运行测试:http://localhost:8080/em

我们在看一个示例,求下欧氏距离,距离越小,说明越相似:
scss
@RequestMapping("/em2")
public String em2(){
float[] textVector1=embeddingModel.embed("学java上java1234.com").content().vector();
float[] textVector2=embeddingModel.embed("java1234.com网站教学Java质量真不错").content().vector();
float[] textVector3=embeddingModel.embed("我喜欢吃苹果").content().vector();
double dist12 = euclideanDistance(textVector1, textVector2);
double dist13 = euclideanDistance(textVector1, textVector3);
System.out.println("textVector1 与 textVector2 欧氏距离: " + dist12);
System.out.println("textVector1 与 textVector3 欧氏距离: " + dist13);
return "OK";
}
/**
* 计算两个向量的欧式距离
* @param a
* @param b
* @return
*/
public static double euclideanDistance(float[] a, float[] b) {
if (a.length != b.length) {
throw new IllegalArgumentException("向量维度不一致");
}
double sum = 0;
for (int i = 0; i < a.length; i++) {
double d = a[i] - b[i];
sum += d * d;
}
return Math.sqrt(sum);
}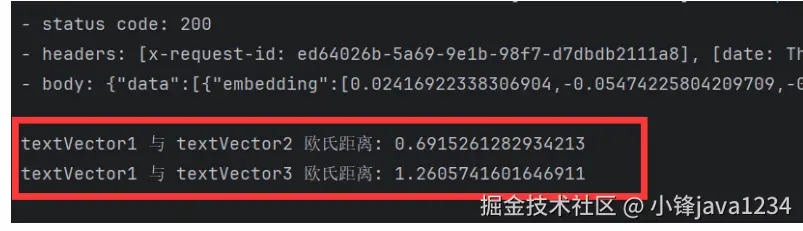
越相似,距离值越小。
二,什么是向量数据库

2.1 什么是向量数据库?
向量数据库是一种专门设计用来存储、索引和查询向量数据的数据库。
传统的关系型数据库擅长存储和查询结构化数据(如表格中的姓名、年龄),但它们无法高效处理向量的"相似性检索"需求。
2.2 向量数据库的核心功能:相似性搜索
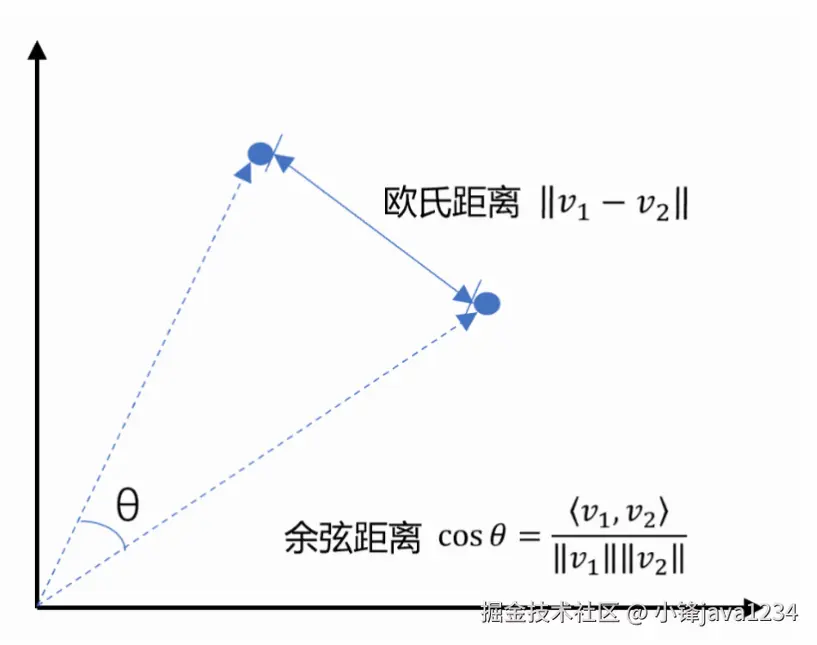
向量数据库的核心能力是近似最近邻检索。
-
任务:给定一个查询向量,在数据库中快速找到与之最相似的K个向量。
-
算法:它不进行暴力的一一比对,而是使用专门的索引算法(如 HNSW------分层可导航小世界图,IVF------倒排文件索引)来极大地提高搜索效率。即便数据库中有十亿个向量,也能在毫秒级内返回结果。
-
距离度量:通常通过计算向量之间的"距离"来衡量相似度。
- 余弦相似度:衡量方向上的相似度(最常用)。
- 欧氏距离:衡量空间中的直线距离。
- 点积:衡量两个向量的投影。
2.3 为什么需要向量数据库?
- 高效的检索性能:专为大规模向量相似性搜索优化,这是传统数据库无法做到的。
- 元数据过滤:在实际应用中,向量通常还附带元数据。例如,一个商品图片的向量可能还附有"商品ID"、"价格"、"类别"等信息。向量数据库允许你在进行相似性搜索时,先或同时根据这些元数据进行过滤(例如,"找到与这件红色T恤最相似的衣服,且价格低于100元")。
- 数据管理:提供增删改查、数据持久化、备份、容灾等标准的数据库功能。
- 与嵌入模型和大模型的完美集成:它们共同构成了现代AI应用(如RAG------检索增强生成)的数据流水线。
2.4 常用的向量数据库有哪些
以下是5个最常用的向量数据库对比表格:
| 数据库 | 类型 | 特点 | 优点 | 适用场景 |
|---|---|---|---|---|
| Pinecone | 商业SaaS | 全托管云服务 | 上手最快,零运维,提供免费额度 | 快速原型开发,不想自己搭建维护的项目 |
| Milvus | 开源/商业 | 功能最全面的专业向量数据库 | 支持十亿级向量,索引类型丰富,性能强大 | 大规模生产环境,对性能要求高的场景 |
| Qdrant | 开源/商业 | Rust编写,性能优异 | 内存占用低,API友好,支持过滤 | 需要高性能、资源受限的环境 |
| Chroma | 开源 | Python原生,轻量级 | 极简API,与LangChain集成好,本地开发友好 | 本地开发、学习、小型项目 |
| pgvector | PostgreSQL扩展 | 基于PostgreSQL | 支持ACID事务,SQL语法,无需引入新数据库 | 已有PostgreSQL,向量数据量百万级以内 |
三,两者的协同工作 ------ RAG流程示例
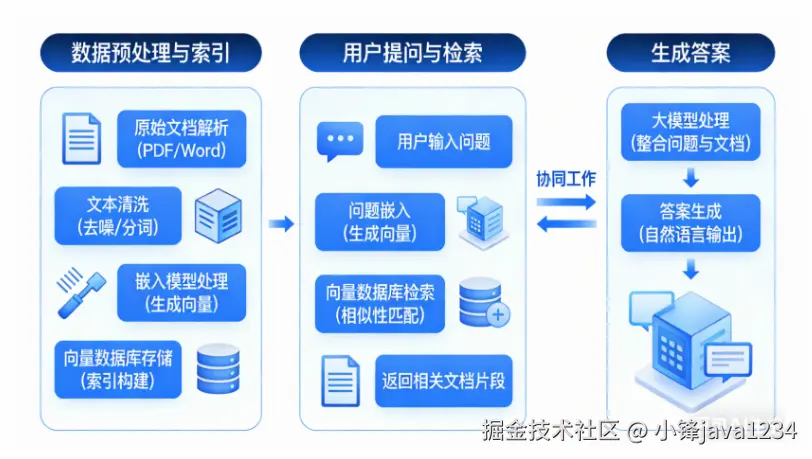
这是目前最经典的AI应用架构,可以清晰地看到嵌入模型和向量数据库是如何配合的。
场景:构建一个基于公司内部知识库的智能问答机器人。
第一步:数据预处理与索引(入库阶段)
- 准备文档:收集所有公司文档(PDF、Word、内部Wiki等)。
- 文本分块:将长文档切分成更小的段落或"块"。
- 生成嵌入 :使用嵌入模型,为每一个文本块生成一个向量。
- 存储 :将生成的向量,连同原始的文本块和相关的元数据(如文档来源、页码),一起存入向量数据库。
第二步:用户提问与检索(查询阶段)
- 用户提问:用户问:"我们公司的年假政策是什么?"
- 问题嵌入 :使用相同的嵌入模型,将用户的这个问题也转换成一个向量。
- 向量检索 :将这个代表问题的向量发送到向量数据库进行查询。数据库会迅速返回与问题向量最相似的K个文本块向量。
- 获取上下文:根据返回的向量ID,取出对应的原始文本块内容。
第三步:生成答案(生成阶段)
- 构建提示词:将用户的问题 + 检索到的相关文本块(作为上下文)组合成一个提示词。
- 调用大语言模型:将提示词发送给大语言模型(如GPT-4),并指示它"请根据提供的上下文回答问题"。
- 返回答案:大模型阅读并理解上下文后,生成一个准确、有据可依的答案返回给用户。
LangChain4j支持的向量数据库还是比较多的。我们课程选用Redis。之前已经在Docker Desktop里安装了redis镜像。

接下来项目里把向量存入Redis-stack向量数据库。
首先启用redis向量配置,修改application.yml
yaml
langchain4j:
community:
redis:
enabled: true # 关闭 Redis 向量库自动配置,仅保留手动配置的会话记忆
host: localhost
port: 6379
dimension: 1024 # 与 text-embedding-v4 一致(也可省略,starter 会从 EmbeddingModel 自动读取)
index-name: embedding-index
prefix: 'java1234:'MyEmController注入embeddingStore嵌入存储
swift
/**
* 嵌入存储
*/
@Autowired
private EmbeddingStore<TextSegment> embeddingStore;添加文档实现
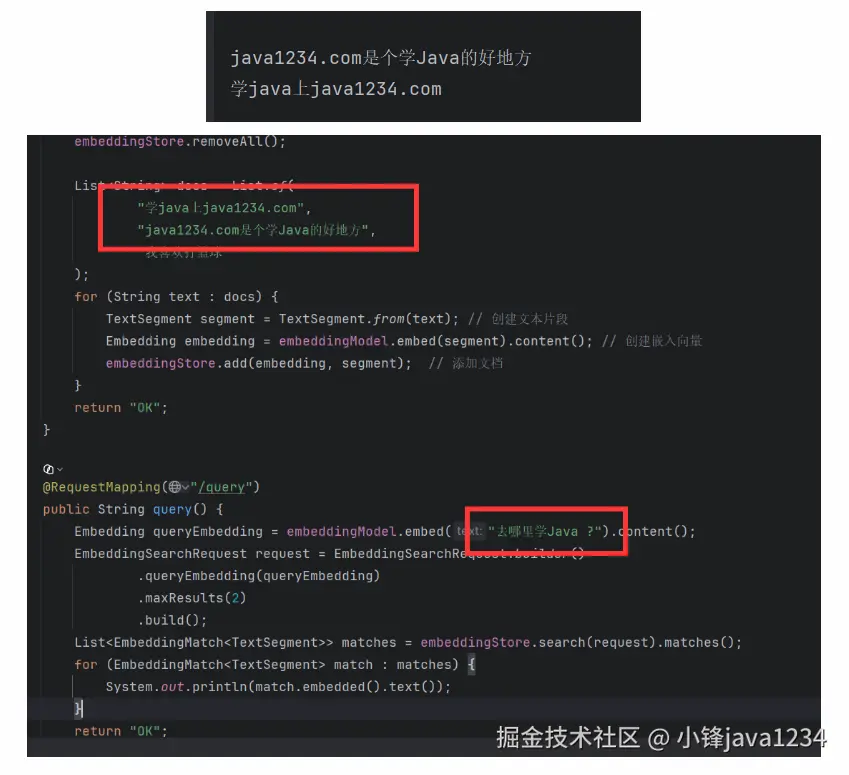
arduino
@RequestMapping("/addDoc")
public String addDoc() {
// 清空旧数据,避免重复调用产生重复文档
embeddingStore.removeAll();
List<String> docs = List.of(
"学java上java1234.com",
"java1234.com是个学Java的好地方",
"我喜欢打篮球"
);
for (String text : docs) {
TextSegment segment = TextSegment.from(text); // 创建文本片段
Embedding embedding = embeddingModel.embed(segment).content(); // 创建嵌入向量
embeddingStore.add(embedding, segment); // 添加文档
}
return "OK";
}查询实现:
scss
@RequestMapping("/query")
public String query() {
Embedding queryEmbedding = embeddingModel.embed("去哪里学Java ?").content();
EmbeddingSearchRequest request = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.maxResults(2)
.build();
List<EmbeddingMatch<TextSegment>> matches = embeddingStore.search(request).matches();
for (EmbeddingMatch<TextSegment> match : matches) {
System.out.println(match.embedded().text());
}
return "OK";
}我们先测试添加文档:http://localhost:8080/addDoc
redis里查看下,已经入库了
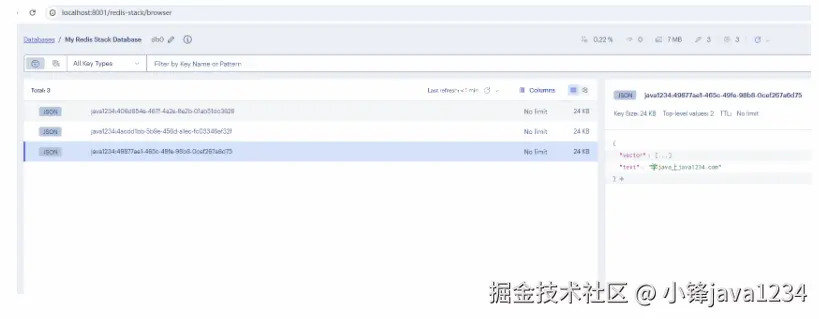
再进行相似性搜索:http://localhost:8080/query