PromptHash: Affinity-Prompted Collaborative Cross-Modal Learning for Adaptive Hashing Retrieval
- 摘要
- 1.引言
- 2.相关工作
-
- [2.1 深度跨模态哈希](#2.1 深度跨模态哈希)
- [2.2 提示学习](#2.2 提示学习)
- [2.3. 对比学习](#2.3. 对比学习)
- [2.4 状态空间模型](#2.4 状态空间模型)
- [3. 方法](#3. 方法)
-
- [3.1 符号说明与问题定义](#3.1 符号说明与问题定义)
- [3.2 特征提取](#3.2 特征提取)
- [3.3 面向文本亲和度的提示学习](#3.3 面向文本亲和度的提示学习)
- [3.4 自适应门控状态空间融合模块](#3.4 自适应门控状态空间融合模块)
- [3.5 提示对齐对比学习](#3.5 提示对齐对比学习)
-
- [3.5.1 跨模态提示对齐](#3.5.1 跨模态提示对齐)
- [3.5.2 亲和度感知损失函数](#3.5.2 亲和度感知损失函数)
- [3.6 哈希学习](#3.6 哈希学习)
- 4.实验
-
- [4.1 数据集](#4.1 数据集)
- [4.2 实验细节](#4.2 实验细节)
- [4.3 实验结果分析](#4.3 实验结果分析)
- [5. 总结](#5. 总结)
摘要
跨模态哈希是一种可实现高效数据检索与存储优化的热门技术。但现有方法在语义留存、上下文完整性以及冗余信息处理方面存在明显短板,限制了检索效果。
本文提出 PromptHash 创新框架,依托亲和提示协同学习实现自适应跨模态哈希。本文构建端到端亲和提示协同哈希框架,主要创新点如下:
(1) 文本亲和提示学习机制,在保证参数量高效的同时完整保留上下文信息;
(2) 自适应门控筛选融合结构,结合状态空间模型与 Transformer 网络,精准完成跨模态特征融合;
(3) 提示亲和对齐策略,通过分层对比学习消除模态异构鸿沟。
据我们所知,本文首次将亲和提示思想应用于协同自适应跨模态哈希学习,为提升跨模态语义一致性提供了新思路。在三个主流多标签基准数据集上开展大量实验,结果表明 PromptHash 相比现有算法性能提升显著。在 NUS-WIDE 数据集上,以图搜文、以文搜图检索精度分别提升 18.22%、18.65%。项目开源代码详见:https://github.com/ShiShuMo/PromptHash。
1.引言
(背景)随着社交媒体平台飞速普及,多模态数据呈爆炸式增长,跨模态检索由此成为发展前景广阔、潜力日益凸显的研究领域。
(挑战->引出跨模态哈希-》介绍-》存在优化区间)然而,多模态数据与生俱来的模态异构特性带来了巨大挑战,意味着跨模态检索在学术研究与落地应用层面仍有较大优化空间 45。跨模态哈希依托表征能力优异的共享哈希函数,将不同模态的数据映射至同一哈希空间。语义相近的跨模态数据会被编码为取值邻近的二进制哈希码,以此有效弥合模态间的语义鸿沟,实现高效精准的跨模态检索 1,9,12,16,17,26,31,33,41。现有跨模态哈希算法主要分为无监督与有监督两类,有监督方法依靠成对相似矩阵、语义标签等监督信息,整体性能优于无监督方案。尽管深度有监督跨模态哈希已取得长足发展,该领域依旧存在亟待攻克的核心难题。
(引出CLIP->存在不足)得益于出色的零样本学习能力以及图文表征对齐特性,CLIP(对比式图文预训练模型)27近来成为众多哈希算法提取跨模态特征的主流骨干网络。但直接使用CLIP仍存在关键缺陷,制约了算法在实际场景中的检索性能。
(存在的两个不足)一个突出难题是 CLIP 预训练模型存在文本上下文长度限制 :其最大输入长度仅 77 个字符,而现实场景中的文本数据往往远超该上限。这种不匹配会造成上下文缺失与语义截断问题,在文本检索任务中表现尤为明显。除此之外,跨模态特征的高效融合仍是悬而未决的难点,如何提高检索相关语义特征权重、抑制无效冗余信息十分棘手。以常用的 MS COCO 数据集 22 为例,该数据集文本长度在 169 至 625 字符之间,大幅超出 CLIP 的 77 字符编码上限
(提出解决CLIP的不足)为突破 CLIP 的长度约束,本文将检索所需的前景目标文本构造为自适应亲和提示,并在提示文本与原始文本之间搭建动态加权机制。该方案既能保留关键语义,又避开 77 字符限制,完整处理超长真实文本、避免语义截断。
(现有解决CLPI思路的不足)现有方案的解决思路各有弊端:词袋模型(BoW)忽略单词上下文关联;ViT、BERT 等预训练 Transformer 7,6 依旧存在文本截断;VTPH 4 借助大语言模型重构提示文本,但计算开销过大,也无法彻底解决语义截断。
(另一个难点)另一项难点在于多模态特征融合:现有跨模态哈希大多借助对比学习实现模态间语义统一,但跨模态检索常用基准数据集普遍存在上下文缺失、语义冗余问题,文本表征方面尤为突出。例如 MIRFLICKR25K 13 与 NUS-WIDE 5 数据集的文本由标签直接拼接而成,上下文信息匮乏;而 MS COCO 数据集文本由多条人工标注描述整合得到,极易产生语义冗余。
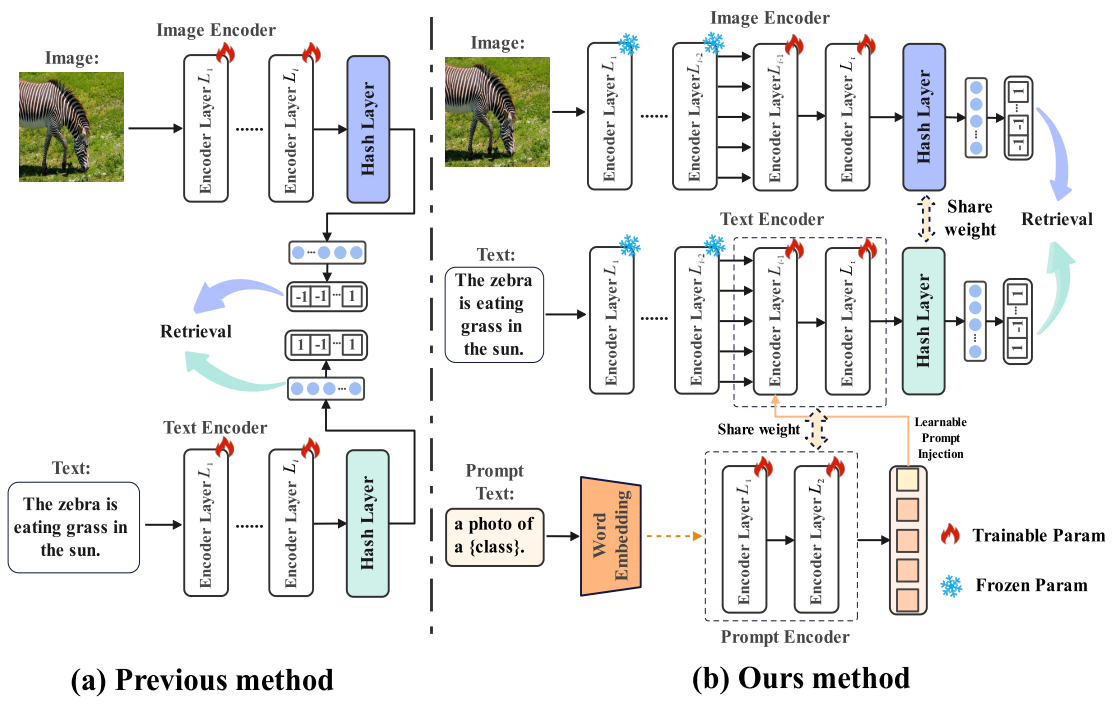
针对上述难题,本文提出一种面向哈希检索的自适应亲和提示协同跨模态学习框架 PromptHash(见图 1)。该框架融合文本亲和提示、状态空间模型(SSM)与基于 Transformer 的自适应门控筛选融合结构,并依托全新设计的提示亲和对比损失(PACL)优化跨模态语义对齐效果。本文主要创新点总结如下:
- 为缓解 CLIP 文本长度限制带来的语义截断问题,本文引入融合检索关键前景目标文本的自适应文本提示,在提示特征与原始文本特征间构建动态加权策略,在突破长度约束的同时保留核心语义,提升检索效果。
- 该框架引入 SSM-Transformer 自适应门控筛选融合模块优化跨模态特征融合,在保留有效语义信息的同时剔除冗余特征。
- 为平衡提示语义与原始图文语义,本文提出全新的提示亲和对比损失(PACL),通过全局与局部双层提示对比学习,消除模态异构、弥合语义鸿沟。
- 在三个基准数据集上开展的大量实验表明,所提 PromptHash 框架性能显著优于现有主流算法,验证了其在跨模态检索任务上的有效性。
2.相关工作
2.1 深度跨模态哈希
跨模态哈希通过哈希函数将异构数据映射至统一汉明空间,在信息检索领域取得长足发展。现有研究通常将相关算法划分为无监督与有监督两大类。
无监督方法利用跨模态关联关系,在无需显式标签监督的前提下维持数据语义相似度。代表性算法包括采用深度自适应增强的DAEH30、基于师生架构的UKD10以及依托CLIP完成特征提取的UCMFH40。除此之外,UCCH11针对二值-连续松弛约束进行优化,NRCH37则借助鲁棒对比损失与动态噪声分离技术实现性能提升。
有监督方法借助标签信息,在公共哈希空间中构建语义一致性。DCMH16首创端到端深度跨模态哈希,后续出现采用焦点损失的CMHH3、融合注意力机制与对抗学习的AGAH9。近年代表性研究有采用联合优化的DCHUC34、构建模态不变网络的MIAN42以及引入图卷积网络的GCDH2;DCHMT32与MITH23则基于CLIP实现细粒度特征提取。
代理学习是另一重要研究方向:DAPH35采用数据感知网络,DSPH14挖掘细粒度语义关联,DHaPH15引入分层学习;CMCL39实现多比特协同优化,VTPH4基于大模型完成算法改进。不同于上述现有方法,本文融合全局、局部双层级提示对齐策略,通过缩减特征差异缓解模态异构与语义隔阂。
2.2 提示学习
提示学习起源于自然语言处理领域,通过将人工设计的模板嵌入输入数据以适配下游任务。近年来该思想被拓展至视觉-语言模型:CoCoOp43提出条件上下文优化,MaPLe18实现多模态提示学习,CoPrompt28依靠一致性约束提升模型性能。PromptKD20探究无监督提示蒸馏,但提示学习在跨模态哈希领域的应用价值仍缺少深入研究。
2.3. 对比学习
对比学习通过拉大负样本相似度、拉近正样本相似度,在特征表征学习上效果突出。不少跨模态哈希算法采用该框架:UCCH11率先实现无监督对比学习,UniHash38面向实例层级优化,CMCL39依靠token对齐完成优化。但现有方法普遍缺少细粒度的token显式语义对齐。本文基于提示构造对比学习,从实例与token两个层级实现特征对齐,弥补该缺陷。
2.4 状态空间模型
尽管对比学习能够有效对齐不同模态的语义表征,但在多模态场景中区分前景(有效相关)与背景(无关冗余)信息 依旧存在难点。状态空间模型(SSM)8凭借线性复杂度的选择性序列建模能力,为此提供了可靠的解决思路。Transformer对所有令牌均等分配注意力,与之不同,SSM的选择性扫描机制可动态聚焦有效特征、滤除噪声干扰。
Vim44率先将SSM应用于视觉领域,验证了其筛选视觉信息的能力;VMamba24依托二维选择性扫描技术,实现前景目标与背景内容的有效分离;Jamba21进一步证实:将SSM选择性注意力与Transformer层融合,能够提升序列特征的处理效率。
尽管相关研究已取得上述进展,但SSM结合对比学习 用于解决跨模态哈希检索中前景、背景信息混淆问题的研究仍处于空白。本文融合两种技术范式:借助SSM精准区分前景与背景特征,依靠对比学习实现跨模态语义精细对齐。
3. 方法
3.1 符号说明与问题定义
本文沿用传统跨模态哈希的框架,以图文配对数据作为双模态输入。
设 O = { o i } i = 1 N O=\{o_{i}\}{i=1}^{N} O={oi}i=1N 为包含 N N N 组训练样本对的数据集,单个样本 o i = ( x i v , x i t , l i , p i ) o{i}=(x_{i}^{v}, x_{i}^{t}, l_{i}, p_{i}) oi=(xiv,xit,li,pi) 由四部分组成:
视觉特征向量 x i v ∈ R d v x_{i}^{v} \in \mathbb{R}^{d^{v}} xiv∈Rdv、文本特征向量 x i t ∈ R d t x_{i}^{t} \in \mathbb{R}^{d^{t}} xit∈Rdt、多标签标注 l i ∈ { 0 , 1 } 1 × C l_{i} \in\{0,1\}^{1 \times C} li∈{0,1}1×C(若样本 o i o_i oi 属于第 c c c 类,则 l i , c = 1 l_{i,c}=1 li,c=1,否则 l i , c = 0 l_{i,c}=0 li,c=0)以及提示词 p i p_i pi。
构造相似度矩阵 S \boldsymbol{S} S:当两个样本至少共享一个类别标签时, S i j = 1 S_{ij}=1 Sij=1,代表二者具备语义关联性;反之 S i j = 0 S_{ij}=0 Sij=0。
算法核心目标是通过两组哈希映射函数,将异构特征映射至同一个 K K K 比特汉明空间:
b i v = H v ( f i v ; θ v ) ∈ { − 1 , + 1 } K , b i p t = H t ( f i p t ; θ t ) ∈ { − 1 , + 1 } K b_{i}^{v}=H^{v}(f_{i}^{v};\theta^{v}) \in\{-1,+1\}^{K},\quad b_{i}^{pt}=H^{t}(f_{i}^{pt};\theta^{t}) \in\{-1,+1\}^{K} biv=Hv(fiv;θv)∈{−1,+1}K,bipt=Ht(fipt;θt)∈{−1,+1}K
其中 b i v b_{i}^{v} biv、 b i p t b_{i}^{pt} bipt 分别为图像模态、提示-文本融合模态的哈希码, θ v \theta^{v} θv、 θ t \theta^{t} θt 是对应哈希网络的可学习参数。
全文符号约定: M M M 代表小批量样本尺寸, D D D 为特征嵌入维度;
符号 f f f 用于指代原始输入特征(如 f i v , f i t , f i p , f i p t f_{i}^{v},f_{i}^{t},f_{i}^{p},f_{i}^{pt} fiv,fit,fip,fipt);
符号 h h h 代表量化前的连续型哈希表征(如 h i v , h i p t , h i p h_{i}^{v},h_{i}^{pt},h_{i}^{p} hiv,hipt,hip);
符号 b b b 代表二值哈希编码(如 b i v , b i p t b_{i}^{v},b_{i}^{pt} biv,bipt)。
相似度度量定义: Θ i j \Theta_{ij} Θij 为提示-图像相似度, Φ i j \Phi_{ij} Φij 为图像-提示相似度, Ω i j \Omega_{ij} Ωij 为模态内提示特征相似度。
3.2 特征提取
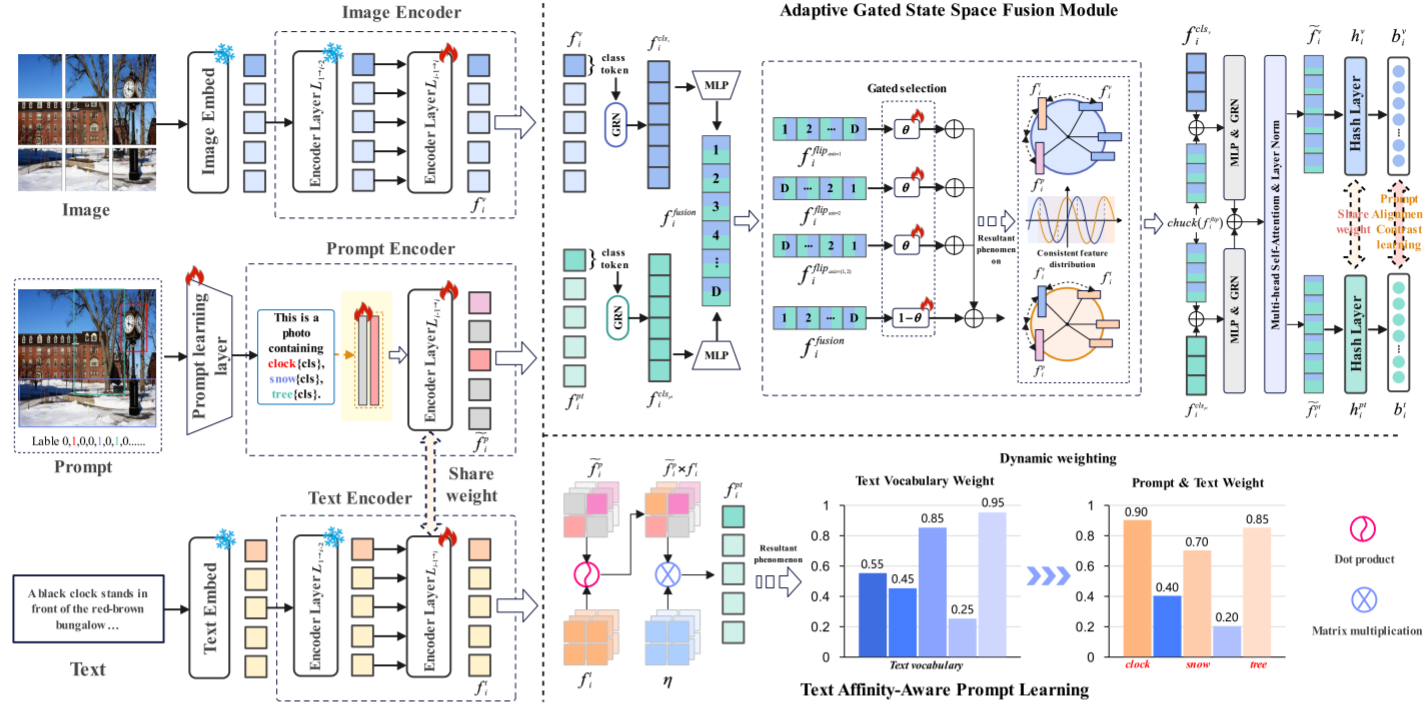
图 2. PromptHash 总体框架。 我们的框架由五个关键组件组成:1)用于模态特定特征提取的图像和文本编码器; 2)自适应门状态选择和融合模块,用于图像特征和混合提示增强文本特征之间的特征过滤和跨模态融合; 3)文本亲和力感知提示,动态学习和区分有利于检索的前景信息,同时通过动态提示机制优化文本特征表示; 4)跨模态提示对齐机制,结合了全局和局部对齐,其中全局对齐有利于图像到文本和图像到提示表示的对齐,并具有类内和类间亲和力损失; 5)具有量化和重构损失的哈希学习。
图2详细展示了本文提出的PromptHash框架整体流程。为充分借鉴深度神经网络与Transformer模型的前沿技术,本文采用双分支Transformer架构分别提取图像、文本特征。除此之外,单独搭建一路Transformer网络提取提示特征,依靠该特征计算提示加权相似度。
为进一步提升图文表征效果,分别采用预训练ViT作为图像编码器、预训练BERT作为文本编码器。
经编码器得到图像嵌入 f i v = { G i v } ∈ R L v × D f_{i}^{v}=\{G_{i}^{v}\}\in\mathbb{R}^{L^v\times D} fiv={Giv}∈RLv×D、文本嵌入 f i t = { G i t } ∈ R L t × D f_{i}^{t}=\{G_{i}^{t}\}\in\mathbb{R}^{L^t\times D} fit={Git}∈RLt×D。
同理,构建带掩码的融合提示嵌入 f i p t = { G i p } ∈ R L p × D f_{i}^{pt}=\{G_{i}^{p}\}\in\mathbb{R}^{L^p\times D} fipt={Gip}∈RLp×D,用以表征融合后的提示特征。
3.3 面向文本亲和度的提示学习
在跨模态哈希任务中,无效负样本文本特征会干扰前景与背景信息的区分,大幅降低检索性能。针对该问题,本文提出文本亲和感知提示(TAAP)模块:该模块动态学习并筛选有利于检索的前景有效信息,依托动态提示机制优化文本特征表征。
设 l i l_i li代表图文样本对 o i o_i oi、 o t o_t ot对应的类别标签集合。本文采用固定模板生成提示文本:"This is an image containing {类别名称i}" ,式中{类别名称i}与标签 l i l_i li匹配。完整提示文本表示为 prompt i = \text{prompt}i= prompti="This is an image containing {class name i}",再通过字节对编码(BPE)进行分词,计算公式: token prompt i = Tokenizer ( prompt i ) \text{token}{\text{prompt}_i}=\text{Tokenizer}(\text{prompt}_i) tokenprompti=Tokenizer(prompti)
将token序列编码为嵌入向量 p i p_{i} pi:
p i = embed ( token_prompt i ) , p i ∈ R D (1) p_{i}= \text{embed}(\text{token\prompt}{i} ),\ p_{i} \in \mathbb{R}^{D} \tag{1} pi=embed(token_prompti), pi∈RD(1)
式中 D D D代表CLIP的嵌入维度。之后将该向量与可学习上下文向量 C c t x C_{ctx} Cctx相加得到 f i p f_{i}^{p} fip:
f i p = p i + C c t x (2) f_{i}^{p}=p_{i}+C_{ctx} \tag{2} fip=pi+Cctx(2)
bash
(CSDN 平台 **$$ $$是兼容性最优行间公式标记 **,\[ \]新版编辑器偶发渲染故障,之后所有公式统一用$$ $$包裹即可。)该动态提示机制借助可学习掩码有效区分前景与背景特征,优化检索任务的特征表征。生成的提示特征 f i P f_{i}^{P} fiP送入TAAP模块的Transformer编码器层处理,与原始文本特征 f i t f_{i}^{t} fit完成特征融合:
f i P ~ = TransformerLayer ( f i P ) (3) \tilde{f_{i}^{P}}= \text{TransformerLayer} \left(f_{i}^{P}\right) \tag{3} fiP~=TransformerLayer(fiP)(3)
最终通过逐元素相乘与全局平均池化得到加权特征表征:
f i p t = ( f i p ~ × f i t ) ⊗ η , f i p t ∈ R D (4) f_{i}^{p t}=\left(\tilde{f_{i}^{p}} × f_{i}^{t}\right) \otimes \eta,\ f_{i}^{p t} \in \mathbb{R}^{D} \tag{4} fipt=(fip~×fit)⊗η, fipt∈RD(4)
式中 η \eta η为可学习权重, ⊗ \otimes ⊗表示矩阵乘法。该融合策略可在有效保留前景信息的同时抑制背景噪声,大幅提升跨模态哈希检索性能。
3.4 自适应门控状态空间融合模块
在本研究中,本文将状态空间模型(SSM)与自适应门控机制结合,构建自适应滤波特征融合模块,命名为自适应门控状态空间融合模块(AGSF)。文本特征经过前文的提示学习模块加权后,得到优化后的文本特征。图像特征则需要与融合后的提示-文本混合特征完成滤波与融合处理,计算公式如下:
f i c l s = SiLU ( MLP ( GRN ( f i m ) ) ) , m ∈ { v , p t } f i f u s i o n = Concat ( f i c l s v , f i c l s p t ) \begin{aligned} & f_{i}^{cls }=\text{SiLU}\left(\text{MLP}\left(\text{GRN}\left(f_{i}^{m}\right)\right)\right),\ m \in\{v, p t\} \\ & f_{i}^{fusion }=\text{Concat}\left(f_{i}^{cls {v}}, f{i}^{cls _{pt}}\right) \end{aligned} ficls=SiLU(MLP(GRN(fim))), m∈{v,pt}fifusion=Concat(ficlsv,ficlspt)
式中 Concat \text{Concat} Concat代表拼接操作, GRN \text{GRN} GRN为全局响应归一化, MLP \text{MLP} MLP是多层感知机, SiLU \text{SiLU} SiLU为激活函数。在全局响应归一化(GRN)层中,给定输入 x ∈ R B × N × D x \in \mathbb{R}^{B ×N ×D} x∈RB×N×D,依次计算L2范数 G x G_{x} Gx与归一化系数 N x N_{x} Nx:
G x = ∥ x ∥ 2 = ∑ d = 1 D x d 2 , N x = G x 1 N ∑ i = 1 N G x i G_{x}=\| x\| {2}=\sqrt{\sum{d=1}^{D} x_{d}^{2}},\ N_{x}=\frac{G_{x}}{\frac{1}{N} \sum_{i=1}^{N} G_{x_{i}}} Gx=∥x∥2=d=1∑Dxd2 , Nx=N1∑i=1NGxiGx
引入可学习参数 λ \lambda λ、 κ \kappa κ后得到模块最终输出:
G R N ( x ) = λ ⋅ ( x ⋅ N x ) + κ + x (7) GRN(x)=\lambda \cdot\left(x \cdot N_{x}\right) +\kappa +x \tag{7} GRN(x)=λ⋅(x⋅Nx)+κ+x(7)
得到融合特征后,将其送入SSM自适应筛选模块,计算公式如下:
f i f l i p a x i s = ψ = F l i p a x i s = ψ T ( S S M ( F l i p a x i s = ψ ( f i f u s i o n ) ) ) f_{i}^{flip {axis }=\psi}=Flip{axis =\psi}^{T}\left(SSM\left(Flip_{axis =\psi}\left(f_{i}^{fusion }\right)\right)\right) fiflipaxis=ψ=Flipaxis=ψT(SSM(Flipaxis=ψ(fifusion)))
式中 ψ ∈ { 1 , 2 , ( 1 , 2 ) } \psi \in\{1,2,(1,2)\} ψ∈{1,2,(1,2)}。 F l i p a x i s = ψ Flip _{axis =\psi} Flipaxis=ψ代表沿指定轴进行翻转操作, F l i p T Flip ^{T} FlipT为其逆变换,SSM即状态空间模型。获取三组翻转特征后执行自适应加权滤波,可学习温度系数 τ \tau τ用于平衡原始特征与多维度翻转特征的权重:
f i f i t = θ τ ∑ j ∈ ω f i f l i p a x i s = j + ( 1 − θ ) f i f u s i o n , ω = { 1 , 2 , ( 1 , 2 ) } (9) f_{i}^{fit}=\theta \tau \sum_{j \in \omega} f_{i}^{flip {axis =j}}+(1-\theta) f{i}^{fusion }, \omega=\{1,2,(1,2)\} \tag{9} fifit=θτj∈ω∑fiflipaxis=j+(1−θ)fifusion,ω={1,2,(1,2)}(9)
其中 θ \theta θ为可学习参数。滤波后的特征送入Transformer编码器层,计算结果为:
f i v ~ , f i p t = S p l i t ( T r a n s f o r m e r L a y e r ( M L P ( f i f i t ) ) ) (10) \tilde{f_{i}^{v}}, f_{i}^{pt}=Split\left(TransformerLayer \left(MLP\left(f_{i}^{fit}\right)\right)\right) \tag{10} fiv~,fipt=Split(TransformerLayer(MLP(fifit)))(10)
所得特征 f i v ~ \tilde{f_{i}^{v}} fiv~与 f i p t ~ \tilde{f_{i}^{pt}} fipt~为自适应SSM门控筛选融合模块的输出结果。其中Split操作用于从融合特征中拆分出独立的视觉特征与文本特征。通过上述一系列运算,本模型能够对图像与文本中的冗余信息同步完成自适应滤波和动态加权,有效提升检索效果与特征质量。
3.5 提示对齐对比学习
为有效弥补不同模态间的语义鸿沟,本文提出提示对齐对比学习(PACL),该学习机制可实现模态间细粒度特征对齐。该机制由跨模态提示对齐与亲和度感知损失函数两部分构成。
3.5.1 跨模态提示对齐
针对全局提示对齐,本文采用对称InfoNCE损失实现图像表征与文本、提示表征之间的对齐:
L i a → b = − log exp ( ( f i a ~ ) T f i b ~ / τ 1 ) ∑ c = 1 M exp ( ( f i a ~ ) T f c b ~ / τ 1 ) L g p a = 1 M ∑ i = 1 M ∑ a , b ∈ { v , p t } a ≠ b L i a → b \begin{aligned} \mathcal{L}{i}^{a \to b} & =-\log \frac{\exp \left(\left(\tilde{f{i}^{a}}\right)^{T} \tilde{f_{i}^{b}} / \tau_{1}\right)}{\sum_{c=1}^{M} \exp \left(\left(\tilde{f_{i}^{a}}\right)^{T} \tilde{f_{c}^{b}} / \tau_{1}\right)} \\ \mathcal{L}{gpa } & =\frac{1}{M} \sum{i=1}^{M} \sum_{\substack{a, b \in\{v, p t\} \\ a \neq b}} \mathcal{L}_{i}^{a \to b} \end{aligned} Lia→bLgpa=−log∑c=1Mexp((fia~)Tfcb~/τ1)exp((fia~)Tfib~/τ1)=M1i=1∑Ma,b∈{v,pt}a=b∑Lia→b
式中 τ 1 \tau_{1} τ1为温度超参数,下标 c c c遍历批次内全部样本; a 、 b ∈ { v , p t } a、b\in\{v,pt\} a、b∈{v,pt}且 a ≠ b a\neq b a=b,分别代表视觉特征与文本提示融合特征。
针对局部提示对齐,本文采用由模态分布动态调控的温度系数机制:
τ 2 = τ × 1 1 + JS-div ( f i v , f i p ) \tau_{2}=\tau × \frac{1}{1+\text{JS-div}\left(f_{i}^{v}, f_{i}^{p}\right)} τ2=τ×1+JS-div(fiv,fip)1
式中 τ \tau τ为基础温度系数, JS-div \text{JS-div} JS-div用于计算两种模态分布间的JS散度; τ \tau τ与 τ 1 \tau_1 τ1均为温度超参数,默认取值为 0.07 0.07 0.07。
由此构建局部对齐损失函数:
L i e → f = − log exp ( ( f i e ~ ) T f i f ~ / τ 2 ) ∑ c = 1 M exp ( ( f i e ~ ) T f c f ~ / τ 2 ) L l p a = 1 M ∑ i = 1 M ∑ e , f ∈ { v , p } e ≠ f L i e → f \begin{aligned} \mathcal{L}{i}^{e \to f} & =-\log \frac{\exp \left(\left(\tilde{f{i}^{e}}\right)^{T} \tilde{f_{i}^{f}} / \tau_{2}\right)}{\sum_{c=1}^{M} \exp \left(\left(\tilde{f_{i}^{e}}\right)^{T} \tilde{f_{c}^{f}} / \tau_{2}\right)} \\ \mathcal{L}{lpa} & =\frac{1}{M} \sum{i=1}^{M} \sum_{\substack{e, f \in\{v, p\} \\ e \neq f}} \mathcal{L}_{i}^{e \to f} \end{aligned} Lie→fLlpa=−log∑c=1Mexp((fie~)Tfcf~/τ2)exp((fie~)Tfif~/τ2)=M1i=1∑Me,f∈{v,p}e=f∑Lie→f
式中 e , f ∈ { v , p } e,f\in\{v,p\} e,f∈{v,p}且 e ≠ f e\neq f e=f,分别代表视觉特征与提示特征; τ \tau τ、 τ 1 \tau_1 τ1为温度超参数,默认取值 0.07 0.07 0.07。
3.5.2 亲和度感知损失函数
为保证语义一致性,本文设计类间与类内亲和损失:
L i n t e r = − 1 M N ∑ i = 1 N ∑ j = 1 M ∑ k = 1 Q ( S i j k − log ( 1 + e Θ i j ) ) \mathcal{L}{inter }=-\frac{1}{M N} \sum{i=1}^{N} \sum_{j=1}^{M} \sum_{k=1}^{Q}\left(\mathcal{S}{i j k}-\log \left(1+e^{\Theta{i j}}\right)\right) Linter=−MN1i=1∑Nj=1∑Mk=1∑Q(Sijk−log(1+eΘij))
式中 Q ∈ { Θ i j , Φ i j } Q \in\{\Theta_{i j}, \Phi_{i j}\} Q∈{Θij,Φij}、 Θ i j ≠ Φ i j \Theta_{i j} \neq\Phi_{i j} Θij=Φij; Θ i j = 1 2 ( h i p ) T h j v \Theta_{i j}=\frac{1}{2}(h_{i}^{p})^{T} h_{j}^{v} Θij=21(hip)Thjv与 Φ i j = 1 2 ( h i v ) T h j p \Phi_{i j}=\frac{1}{2}(h_{i}^{v})^{T} h_{j}^{p} Φij=21(hiv)Thjp为跨模态相似度。 h i p h_{i}^{p} hip、 h j v h_{j}^{v} hjv分别是提示特征、视觉特征经过符号函数前的实值哈希编码; N N N为样本数量, S i j ∈ { 0 , 1 } \mathcal{S}_{ij}\in\{0,1\} Sij∈{0,1}是真实相似度标签矩阵。
类内亲和损失定义如下:
L i n t r a = − 1 M N ∑ i = 1 N ∑ j = 1 M ( S i j Ω i j − log ( 1 + e Ω i j ) ) \mathcal{L}{intra }=-\frac{1}{M N} \sum{i=1}^{N} \sum_{j=1}^{M}\left(\mathcal{S}{i j} \Omega{i j}-\log \left(1+e^{\Omega_{i j}}\right)\right) Lintra=−MN1i=1∑Nj=1∑M(SijΩij−log(1+eΩij))
式中 Ω i j = 1 2 ( h i p ) T h j p \Omega_{i j}=\frac{1}{2}(h_{i}^{p})^{T} h_{j}^{p} Ωij=21(hip)Thjp表示提示特征之间的同模态相似度。
3.6 哈希学习
- 1)量化损失
量化损失用于学习统一语义表征并生成区分度优异的高质量哈希码,其表达式如下:
L q u a n = 1 N M ∑ i = 1 M ( ∥ b i v − 1 2 ( h i v + f i v ) ∥ 2 2 + ∥ b i p t − 1 2 ( h i p t + f i p t ) ∥ 2 2 ) \mathcal{L}{quan }=\frac{1}{N M} \sum{i=1}^{M}\left(\left\| b_{i}^{v}-\frac{1}{2}\left(h_{i}^{v}+f_{i}^{v}\right)\right\| {2}^{2}+\left\| b{i}^{p t}-\frac{1}{2}\left(h_{i}^{p t}+f_{i}^{p t}\right)\right\| {2}^{2}\right) Lquan=NM1i=1∑M( biv−21(hiv+fiv) 22+ bipt−21(hipt+fipt) 22)
式中: b i v b{i}^{v} biv、 b i p t b_{i}^{pt} bipt为二值哈希编码; h i v h_{i}^{v} hiv、 h i p t h_{i}^{pt} hipt、 f i v f_{i}^{v} fiv、 f i p t f_{i}^{pt} fipt分别为对应模态的实值哈希特征与原始特征, L 2 L_2 L2范数约束实值特征向离散二值码逼近。
该损失函数约束哈希码 b i v \boldsymbol{b_{i}^{v}} biv、 b i p t \boldsymbol{b_{i}^{pt}} bipt逼近视觉与文本特征表征的均值,从而学习具备统一性与区分性的语义嵌入。
- 2)重构损失
重构损失通过约束生成的哈希码具备更强区分性、贴近原始语义特征,提升哈希编码的表征能力与检索性能,损失公式如下:
L r e c o n = 1 M ∑ i = 1 M ( ∥ h i v − b i v ∥ 2 2 + ∥ h i p t − b i p t ∥ 2 2 ) \mathcal{L}{recon }=\frac{1}{M} \sum{i=1}^{M}\left(\left\| h_{i}^{v}-b_{i}^{v}\right\| {2}^{2}+\left\| h{i}^{p t}-b_{i}^{p t}\right\| {2}^{2}\right) Lrecon=M1i=1∑M(∥hiv−biv∥22+ hipt−bipt 22)
式中: h i v 、 h i p t h{i}^{v}、h_{i}^{pt} hiv、hipt为视觉、提示-文本实值特征, b i v 、 b i p t b_{i}^{v}、b_{i}^{pt} biv、bipt为对应二值哈希码, M M M代表样本总数,该项利用L2距离约束实值特征与哈希码尽可能接近。
重构损失最小化哈希码与其对应特征表征之间的误差,促使生成的哈希码有效保留语义信息,进而实现精准检索。
最终,本文所提PromptHash方法的总损失函数由各分项损失加权求和得到,其中 α 、 β 、 γ 、 μ 、 σ 、 ζ \alpha、\beta、\gamma、\mu、\sigma、\zeta α、β、γ、μ、σ、ζ为加权超参数:
L T o t a l = α L g p a + β L l p a + γ L i n t e r + μ L i n t r a + σ L q u a n + ζ L r e c o n \begin{aligned} \mathcal{L}{Total } & =\alpha \mathcal{L}{gpa }+\beta \mathcal{L}{lpa }+\gamma \mathcal{L}{inter } \\ & +\mu \mathcal{L}{intra }+\sigma \mathcal{L}{quan }+\zeta \mathcal{L}_{recon } \end{aligned} LTotal=αLgpa+βLlpa+γLinter+μLintra+σLquan+ζLrecon
4.实验
为严谨验证所提PromptHash算法的有效性,本文在三个主流跨模态多标签检索数据集(MIRFLICKR-25K、NUS-WIDE、MS COCO)上开展了充分实验。将PromptHash与十二种前沿跨模态哈希检索算法进行对比,包括DCMH 16、CMHH 3、GCDH 2、DCHMT 32、MITH 23、DSPH 14、TwDH 33、DNpH 26、DHaPH 15、CMCL 39以及VTPH 4。所有对比算法均在统一实验环境下测试,数据集划分、检索库与查询集均保持和本文实验配置一致。
下文将对十一种对比算法的实验结果展开全面分析;同时详细介绍训练与测试所用的三个数据集、PromptHash专属实验流程,并说明模型性能评价指标。本文还记录实验环境配置,保障实验可复现、结果可追溯。
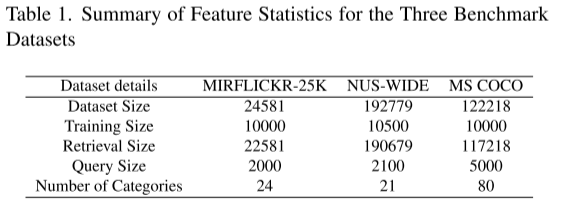
4.1 数据集
表1汇总了实验所用数据集信息,并详述各数据集划分方案。本文在MIRFLICKR-25K、NUS-WIDE、MS COCO三个大规模多标签数据集上采用统一采样规则,全部数据集划分为训练集、测试集与检索库。所有数据集的图文预处理标准保持一致:图像统一缩放至224×224像素,文本数据经字节对编码(BPE)后送入网络。
4.2 实验细节
本研究选用CLIP-B16作为骨干网络,基于单张NVIDIA RTX 4090(24GB)显卡、PyTorch V2.3.1框架完成实验。所有数据集输入图像统一缩放至224×224像素;骨干网络学习率设置为 1 e − 6 1\mathrm{e}{-6} 1e−6,提示模块与特征融合模块学习率均为 1 e − 5 1\mathrm{e}{-5} 1e−5,批次大小(batch size)设为128。
各损失项对应超参数定义: α \alpha α为全局提示对齐损失权重, β \beta β为局部提示对齐损失权重, γ \gamma γ为类间亲和损失权重, μ \mu μ为类内亲和损失权重, σ \sigma σ为量化损失权重, ζ \zeta ζ为重构损失权重。
在MIRFLICKR-25K、NUS-WIDE数据集上,上述超参数依次取值:5.0、5.0、0.005、5.0、0.1、0.001;
MS COCO数据集对应取值:5.0、5.0、0.005、20.0、1.0、0.001。
文中所有表格里,加粗数值代表最优结果,带下划线数值代表次优结果。
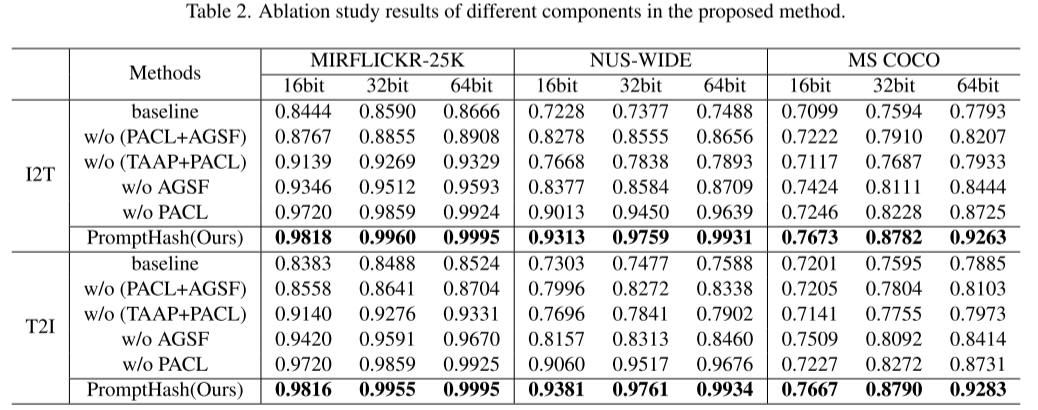
本文开展完备的消融实验,系统性验证所提 PromptHash 框架中各个模块的有效性,实验结果如表 2 所示。实验设置 5 种不同模型变体:
(a) 基准模型:仅使用 CLIP 特征提取网络与哈希映射层,移除 TAAP、AGSF、PACL 全部模块;
(b) 去除 PACL 与 AGSF 模块的 PromptHash:仅保留 TAAP 模块;
© 去除 TAAP 与 PACL 模块的 PromptHash:仅保留 AGSF 模块;
(d) 去除 AGSF 模块的 PromptHash:保留 TAAP、PACL 两个模块;
(e) 去除 PACL 模块的 PromptHash:保留 TAAP、AGSF 两个模块。
4.3 实验结果分析
- 消融实验
实验结果表明,嵌入 TAAP 模块能够显著提升检索性能:该模块对原始文本语义特征做自适应加权,有效改善文本语义截断问题,保留和检索相关的语义信息,同时抑制无关特征的负面影响。
引入 AGSF 模块的实验证明,该跨模态语义融合模块可选择性保留有效语义、滤除冗余上下文信息。
TAAP 与 PACL 组合实验表明:PACL 以图像语义为核心对齐全局、局部提示令牌,优化提示文本与原始文本语义,最终生成高质量哈希码。
消融结果可见,TAAP 与 AGSF 在高比特哈希编码任务上性能提升明显,但对低比特编码场景增益有限。
整套集成三大模块的 PromptHash 模型充分利用各模块的互补优势,在所有哈希码位长下均提升检索效果,验证了本文模块设计的优越性。 - 超参数分析
本文对所提 PromptHash 模型开展全面的超参数分析,总损失函数中六项超参数的实验结果如图 3 所示。实验表明,超参数配置({\alpha=5.0,\beta=5.0,\gamma=0.005,\mu=5.0,\sigma=0.1,\zeta=0.001})在全部数据集上均可取得最优性能。分析规律:固定其余参数为默认值、单一逐步上调某一超参数时,模型在三个数据集上的平均精度均值(mAP)能够达到最优;但若将量化损失权重(\sigma)下调至 0.1 同时增大(\gamma),mAP 指标会出现下滑。此外,若针对每个数据集单独逐一调优全部超参数,得到的平均 mAP 不如仅把(\sigma)设置为 0.1 的效果。补充实验显示,继续将(\sigma)降至 0.05 同样会造成平均 mAP 下降。综上结论:除量化损失权重(\sigma)取 0.1 外,其余超参数采用默认取值,可让模型在三个数据集上获得最优平均 mAP。分析成因:PromptHash 依托 CLIP 完成图文特征有效对齐,在汉明公共空间内,同类图文对天然具备高相似度、异类图文对天然区分度充足,因此量化损失无需设置过高权重。

- 与现有最优算法对比
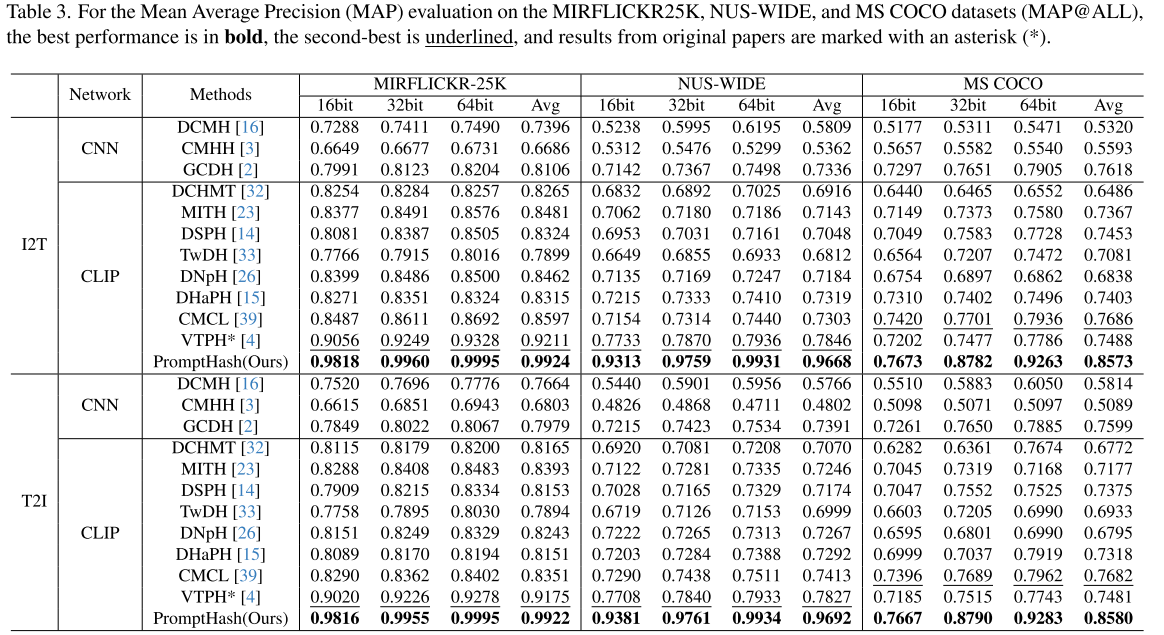
由表 3 实验结果可得,本文提出的 PromptHash 算法在三个公开数据集的各项评价指标上性能均优于对比方法。以全库检索平均精度 mAP@all 作为核心评价指标,相较于现有最优 SOTA 算法,本文方法性能提升幅度显著。
在 MIRFLICKR-25K 数据集上,相比于次优算法 VTPH,图像检索文本(I2T)任务提升 7.13%,文本检索图像(T2I)任务提升 7.47%;
在 NUS-WIDE 数据集上性能提升更为突出,相对 VTPH,I2T 提升 18.22%、T2I 提升 18.65%;
在 MS COCO 数据集上,对比最优基线 CMCL,I2T、T2I 任务分别取得 8.87%、8.98% 的性能增益。
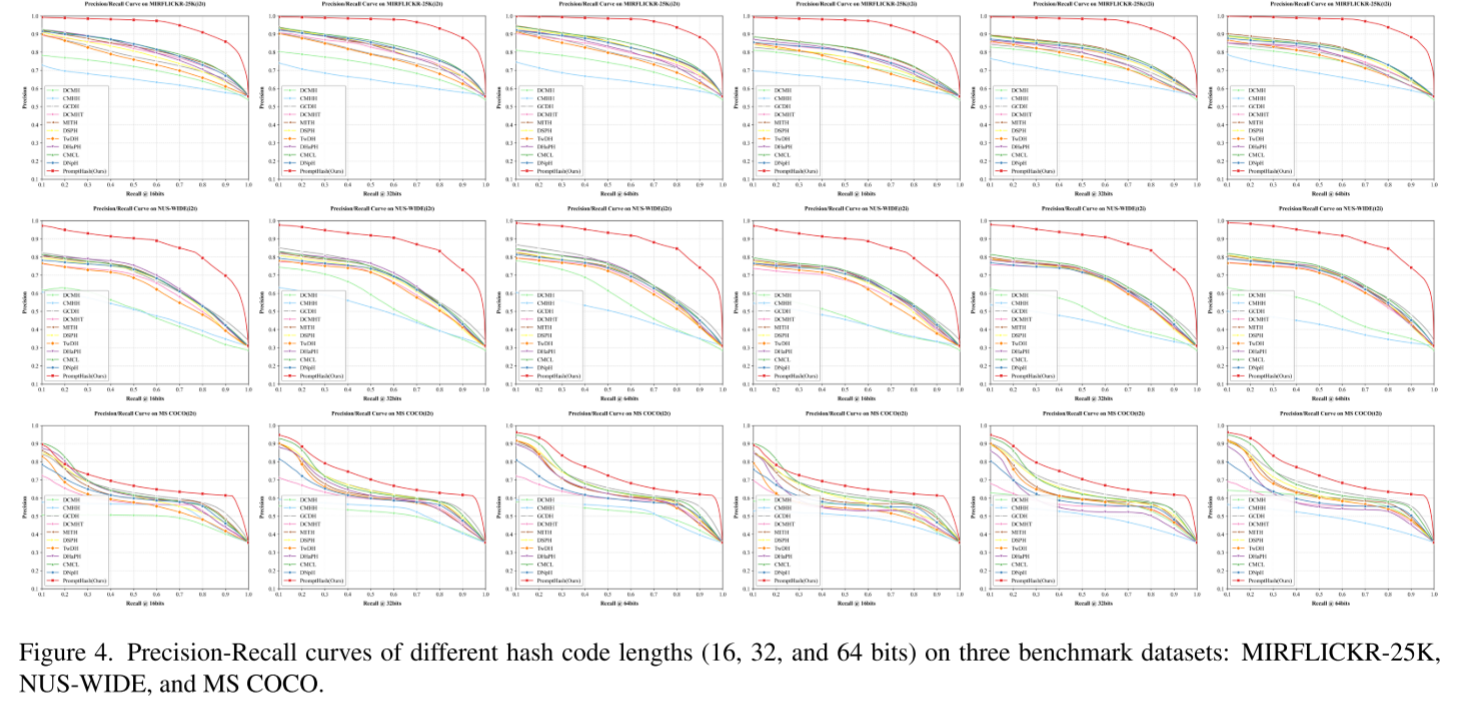
图 4 的精确率 - 召回率(P-R)曲线表明:在 MIRFLICKR-25K 与 NUS-WIDE 数据集上,PromptHash 性能提升效果尤为突出,大幅优于现有对比算法。该优异结果得益于算法借助亲和提示学习与自适应加权模块高效处理离散分词文本,同时以图像为中心区分检索前景目标与背景特征。
而在 MS COCO 数据集上模型提升幅度相对有限,原因源于该数据集自身特点:其文本标注为完整语句而非零散单词,单条标注最长可达 625 个词,但其中仅 3~5 个关键词和检索目标相关。这类高噪声数据带来了较大优化难点,后续可通过文本重构方案进一步改进。
5. 总结
现有多数跨模态哈希算法侧重于哈希函数设计与样本间距离优化,却忽略数据集样本本身存在的固有缺陷。具体而言,样本集中普遍存在的文本语义截断、无效负面语义干扰等问题,会大幅制约模型检索性能。
本文提出的 PromptHash 框架通过两项核心创新解决了上述缺陷:第一,引入提示学习对截断文本语义开展自适应加权学习,在字符编码长度受限的条件下有效提升检索效果;第二,融合 SSM 与 Transformer 结构并搭配自适应门控筛选融合机制,实现融合特征的高效筛选与权重分配。此外,本文所设计的全新提示亲和对比学习模块(PACL)能够均衡提示特征、文本特征与图像特征,借助特征对齐消除模态异构差异,显著提升检索精度。