期刊:IJCV 2023
arXiv:https://arxiv.org/abs/2209.05913
代码:https://github.com/IDKiro/gUNet
关联论文:DehazeFormer
- 研究目标,过去以及本文使用的方法,优势及其创新点
1.1 研究目标
本文研究的是单幅图像去雾(Single Image Dehazing):给定一张有雾图像,恢复出对应的清晰无雾图像。
去雾是低层视觉中的经典问题,既可以直接服务于图像美化,也经常作为自动驾驶、视频监控、遥感分析等高层任务的前置增强模块。
去雾问题的物理基础是大气散射模型:
I(x) = J(x) * t(x) + A * (1 - t(x))
各变量含义如下:
| 符号 | 含义 | 特点 |
| I(x) | 有雾图像(观测值) | 输入 |
| J(x) | 无雾清晰图像 | 待恢复的目标 |
| A | 全局大气光 | 全局变量,整张图共享 |
| t(x) | 透射率图 | 局部变量,与空间位置和深度相关 |
| beta | 大气散射系数 | t(x) = exp(-beta * d(x)) |
这个公式揭示了一个关键点:图像退化同时受全局因素(A)和局部因素(t(x))影响。一个好的去雾网络,既需要全局建模能力来估计大气光,也需要局部空间变化建模能力来处理不同区域的雾浓度差异。
所以本文的核心目标不是简单地提出一个新网络去刷指标,而是通过系统性的消融实验,搞清楚去雾网络中到底哪些设计在真正起作用。
1.2 过去常用方法
论文把已有方法分为两大流派:先验方法和学习方法。
1.2.1 传统先验方法
早期方法依赖人工设计的物理或统计先验:
- DCP(Dark Channel Prior,暗通道先验):观察到无雾图像的局部区域至少有一个通道的像素值趋近于零
- Color-Lines / Haze-Lines:利用颜色空间中的几何关系估计雾浓度
- CAP(Color Attenuation Prior,颜色衰减先验):雾会导致颜色饱和度衰减
- Rank-One Prior:利用低秩结构约束
这类方法的流程通常是先估计 t(x) 和 A,再代入大气散射模型反推 J(x)。优点是可解释性强、不需要训练数据;缺点是先验假设并不总成立。比如 DCP 在天空、白色墙壁等场景下容易翻车,产生颜色失真。
1.2.2 有监督深度学习方法
深度学习方法的发展脉络比较清晰:
早期方法延续物理模型思路。DehazeNet、MSCNN、DCPDN 等仍然显式估计透射率或大气光。AOD-Net 通过重新参数化物理公式,让网络只预测一个中间变量,简化了任务。
近期方法如 GridDehazeNet、MSBDN、FFA-Net、AECR-Net、DehazeFormer 等更倾向于直接预测清晰图像或残差。原因是直接恢复图像通常比显式估计 A 和 t(x) 更稳定。
问题在于:近年来很多方法不断引入复杂注意力、多尺度结构、Transformer,网络越来越复杂,但真正带来性能提升的关键机制并不清楚。
1.2.3 非配对
部分方法尝试摆脱对成对训练数据的依赖,使用非配对或弱监督方式训练。这类方法在真实场景中更有实用价值,但性能通常不如有监督方法。
1.3 本文使用的方法
gUNet 是一个 7-stage U-Net 变体,整体结构可以用一句话概括:
用 U-Net 提取多尺度特征,用 gConv Block 替代普通卷积块,用 SK Fusion 替代简单拼接融合,用全局残差学习恢复无雾图像。
具体流程如下:
- 输入图像经过 3x3 卷积进入网络
- 编码阶段通过 stride=2 的 3x3 卷积逐级下采样
- 解码阶段通过 PWConv + PixelShuffle 逐级上采样
- 每一级之间用 SK Fusion 动态融合 skip connection 和主路径特征
- 最后通过 3x3 卷积预测残差 R(x),与输入相加得到输出
输出公式:
J_hat(x) = I(x) + R(x)
这就是全局残差学习。有雾图像和无雾图像在主体结构上高度相似,网络只需要学习两者之间的差异,不需要从零生成完整图像。这个思路在图像恢复领域很常见,可以显著降低学习难度。
1.4 本文优势与创新点
本文的创新点可以概括为四个方面。
第一,提出 gConv 门控卷积块替代传统激活函数
传统去雾网络使用 ReLU 或 GELU 作为激活函数,这些激活函数对所有空间位置施加相同的非线性变换。gUNet 提出用 Sigmoid 门控机制替代传统激活函数,让网络能够生成位置相关、通道相关的权重图,对不同区域进行差异化处理。
门控机制同时充当 pixel attention 和 nonlinear activation 的角色,与去雾任务中空间变化的透射率 t(x) 天然契合。
第二,提出 SK Fusion 动态特征融合替代简单拼接
传统 U-Net 的 skip connection 使用 concat 或简单相加融合浅层和深层特征。gUNet 引入 SK Fusion(Selective Kernel Fusion),根据当前图像的全局特征动态决定两路信息的使用比例。
这样做既保留了浅层细节(边缘、纹理、颜色),又抑制了浅层特征中可能携带的雾残留信息。
第三,极高的计算效率
gUNet 使用 depth-wise separable convolution(DWConv + PWConv)替代普通卷积,大幅降低参数量和计算量。配合 BatchNorm(推理时可与相邻线性层融合)和 FrozenBN(训练后期冻结统计量),实现了很高的推理效率。
gUNet-T 仅用 DehazeFormer-B 约 10% 的计算量就超过了它的 PSNR。
第四,系统性的消融分析
这是这篇论文最有价值的部分。通过大量实验逐个拆解影响去雾性能的关键因素:归一化层选择、卷积核大小、深度与宽度的权衡、Stage 数量、融合方式、额外注意力模块等,为去雾网络设计提供了直接的参考指南。
- 文中算法主要思想
2.1 总体思想
gUNet 的核心观点是:很多看起来是架构创新带来的涨点,可能只是训练策略和基础模块选择的差异。
论文通过大量消融实验发现,去雾性能的关键不在于网络有多复杂,而在于以下几个要素是否合理:
- 多尺度特征提取结构(U-Net 编码器-解码器)
- 全局-局部建模能力(门控机制 + 全局特征融合)
- 高效的非线性激活方式(gConv Block)
- 合理的训练策略(warmup、frozen BN、训练轮数等)
换句话说,与其堆叠复杂的 Transformer 注意力机制,不如把基础模块选对、训练策略调好。
2.2 大气散射模型与去雾的物理直觉
一张图像可以从空间域转换到频域。回到大气散射模型:
I(x) = J(x) * t(x) + A * (1 - t(x))
这个公式的物理含义是:
有雾图像 = 清晰图像经过透射率衰减 + 大气光散射
透射率 t(x) 是空间变化的:远处雾重、近处雾轻
大气光 A 是全局统一的:整张图共享同一个值
这意味着一个好的去雾网络需要同时具备:
局部空间变化建模能力:处理不同区域的雾浓度差异(对应 t(x))
全局信息提取能力:估计大气光 A
gUNet 的 gConv Block 负责前者,SK Fusion 负责后者。
2.3 gUNet 整体架构
gUNet 的整体结构是一个 7 级 U-Net 编码器-解码器网络:
- 编码阶段:通过 stride=2 的 3x3 卷积逐级下采样,提取多尺度特征
- 解码阶段:通过 PWConv + PixelShuffle 逐级上采样,恢复空间分辨率
- Skip Connection:每一级的 encoder 特征通过 SK Fusion 动态融合到 decoder
- 输出:最后通过 3x3 卷积预测残差 R(x),与输入相加得到无雾图像
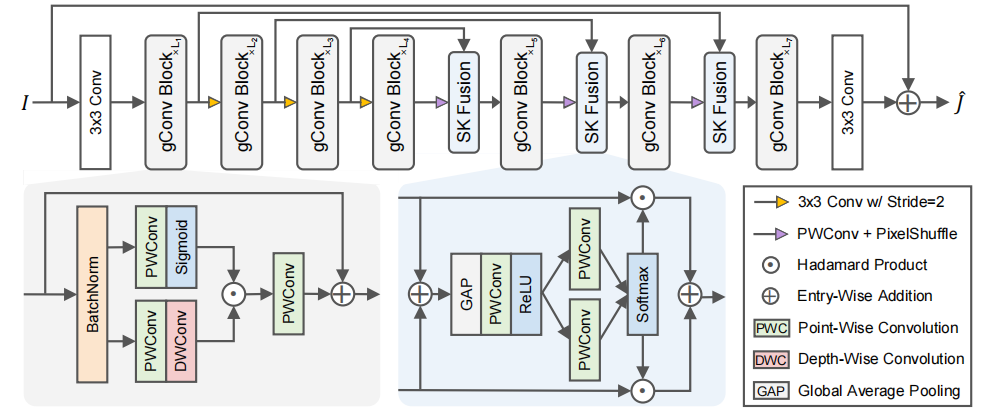 gUNet 整体架构示意图
gUNet 整体架构示意图
7 级 U-Net 结构,编码器逐级下采样,解码器逐级上采样,每级之间通过 SK Fusion 融合 skip connection 特征。
选择 7 个 stage 而不是更多或更少,是通过消融实验确定的:
Stage 数量 RESIDE-IN PSNR
5 stages 36.09
7 stages 38.11
9 stages 部分数据集出现 NaN
5 stages 明显不够,9 stages 训练不稳定。7 stages 是稳定的选择。
2.4 gConv Block:门控卷积块
gConv Block 是本文最核心的模块,也是论文最重要的技术贡献。
给定输入特征 x,先做 BatchNorm:
x_hat = BatchNorm(x)
然后分成两条路径:
门控路径:x1 = Sigmoid(PWConv1(x_hat))
特征路径:x2 = DWConv(PWConv2(x_hat))
两条路径通过逐元素相乘融合:
y = x + PWConv3(x1 * x2)
其中:
PWConv 是 1x1 卷积,用于通道变换
DWConv 是逐通道空间卷积,用于提取局部空间信息
Sigmoid 将特征压到 0 到 1 之间,形成门控权重
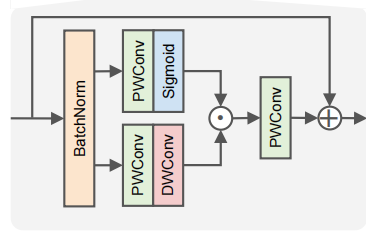 gConv Block 结构图
gConv Block 结构图
输入经过 BatchNorm 后分成门控路径(Sigmoid 门控)和特征路径(DWConv),两路相乘后通过 PWConv 输出并加残差连接。
直觉理解:x2 负责提取局部空间信息,x1 负责生成哪些信息要通过的门控图。两者相乘后,网络可以自动选择哪些位置、哪些通道更重要。
论文指出,gating units 同时充当了pixel attention和nonlinear activation的角色。这意味着 gConv Block 不是简单地在卷积后面加一个激活函数,而是让激活函数本身就具有空间选择性。
2.5 为什么门控机制适合去雾
回到大气散射模型:透射率 t(x) 是空间变化的。一张图里不同区域的雾浓度不同。远处雾重、近处雾轻,天空区域和建筑区域的退化模式也不同。
传统 ReLU / GELU 是统一的非线性变换,不会显式区分不同空间位置的重要性。门控机制则可以生成位置相关、通道相关的权重图,让网络对不同区域进行差异化处理。
论文的消融实验也验证了这一点:

去掉 gating 直接训练甚至会出现梯度爆炸。这说明门控机制不只是锦上添花,而是网络稳定训练的必要条件。
2.6 SK Fusion:动态特征融合
SK Fusion 用于替代 U-Net 中传统的 concat 融合方式。
设 x1 来自 encoder 的 skip connection,x2 来自 decoder 的主路径特征:
- 用 1x1 卷积将 x1 投影到与 x2 相同维度:x1_hat = f(x1)
- 两路特征相加后做全局平均池化:GAP(x1_hat + x2)
- 经过 MLP + Softmax 得到融合权重 a1 和 a2
- 最终融合:y = a1 * x1_hat + a2 * x2
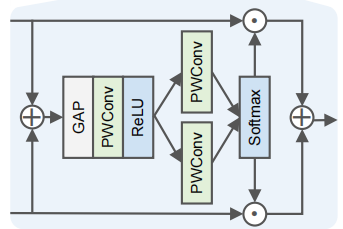 SK Fusion 融合流程图
SK Fusion 融合流程图
两路特征经过全局平均池化和 MLP 生成动态权重,加权求和得到融合结果。
核心意义:网络不是简单地把浅层细节和深层语义拼在一起,而是根据当前图像的全局特征,动态决定两路信息的使用比例。
2.7 为什么 SK Fusion 对去雾重要
普通 U-Net 的 skip connection 有利有弊。浅层特征保留了边缘、纹理、颜色等细节,但也可能携带雾残留。如果直接 concat,雾残留会被无选择地传到 decoder。
SK Fusion 的作用:
保留浅层细节的同时,抑制无用或有害的退化残留
通过全局通道注意力帮助网络建模大气光信息(回忆一下,A 是全局变量)
消融实验中,将 SK Fusion 换成 concat 或 sum 后,性能下降非常明显:

SK Fusion 比 concat 和 sum 高出 3 dB 以上,这在去雾领域是非常显著的差距。
2.8 轻量化设计与训练策略
轻量化设计:
gUNet 使用 depth-wise separable convolution(DWConv + PWConv)替代普通卷积。普通 3x3 卷积的参数量是 C_in * C_out * 9,而 DWConv + PWConv 的参数量是 C_in * 9 + C_in * C_out,大幅降低。
配合 BatchNorm(推理时可与相邻线性层融合)和 FrozenBN(训练后期冻结统计量),实现了很高的推理效率。
训练策略:
论文采用了多项训练技巧:
Warmup:训练前期逐渐增大学习率,避免初始学习率过大导致训练崩溃
SyncBN:多 GPU 训练时同步 BN 统计量,解决单卡 batch 过小的问题
FrozenBN:训练后期冻结 BN 统计量,使训练和推理更一致
Mixed Precision:混合精度训练加速
这些训练策略虽然看起来不起眼,但论文指出它们可能带来 1 到 2 dB 的差异。这也是 gUNet 论文的核心观点之一:训练策略和基础模块选择对性能的影响,可能比架构创新更大。
- 实验结果
3.1 数据集与指标
论文使用了多个常见去雾数据集,覆盖室内合成、室外合成、混合场景和遥感场景:
1)RESIDE
RESIDE 是最常用的单图去雾数据集。论文采用 FFA-Net 的设置,包括:
RESIDE-IN:使用 ITS 训练,共 13,990 对图像;在 SOTS indoor 的 500 对图像上测试RESIDE-OUT:使用 OTS 训练,共 313,950 对图像;在 SOTS outdoor 的 500 对图像上测试。
2)Haze4K
Haze4K 包含 4,000 对图像,其中 3,000 对用于训练,1,000 对用于测试。相比 RESIDE,它混合了室内和室外场景,并且合成流程更加真实。
3)RS-Haze
RS-Haze 是遥感去雾数据集,共 54,000 对图像,其中 51,300 对用于训练,2,700 对用于测试。论文指出,RS-Haze 场景相对单调,但雾分布高度非均匀,与 RESIDE 和 Haze4K 正好相反。
评价指标:PSNR、SSIM、参数量、MACs、Latency
3.2 定量结果:RESIDE-IN 室内去雾
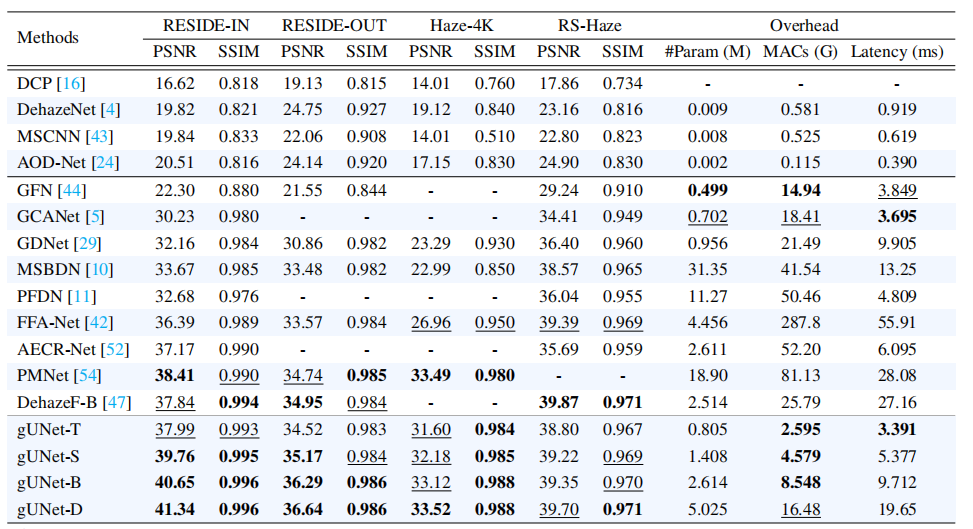 基于不同数据集训练的图像去雾方法的定量比较。对于对比方法,我们使用加粗和下划线分别标示最优方法和次优方法;对于gUNet模型,则通过加粗或下划线表明其性能优于所有对比方法中的最优或次优方案。
基于不同数据集训练的图像去雾方法的定量比较。对于对比方法,我们使用加粗和下划线分别标示最优方法和次优方法;对于gUNet模型,则通过加粗或下划线表明其性能优于所有对比方法中的最优或次优方案。
gUNet-T 用 DehazeFormer-B 约 10% 的计算量就超过了它的 PSNR。gUNet-D 在所有方法中取得最高 PSNR 41.34,同时计算量仅为 FFA-Net 的 17 分之一。
3.3 定性结果

GCANet、PFDN、FFA-Net 在室内图像中会产生伪影;
AOD-Net 虽然伪影较少,但对墙面去雾过强,对地面去雾不足;
gUNet-D 的结果没有明显伪影,各区域亮度和色调更接近 GT;
gUNet 能更好地区分被雾遮挡的浅色物体和深色物体;
在室外场景中,gUNet 的结果比对比方法更接近清晰图像。
不过论文也指出一个问题:RESIDE 和 Haze4K 的合成数据中,有些所谓 clean image 本身仍然含有雾,这导致所有训练出的模型都无法去除这部分"GT 中的雾"。这实际上揭示了合成去雾数据集本身存在真实性不足的问题。
3.4 消融实验:到底什么在起作用
这是这篇论文最有价值的部分。论文通过大量消融实验,逐个拆解影响去雾性能的关键因素。
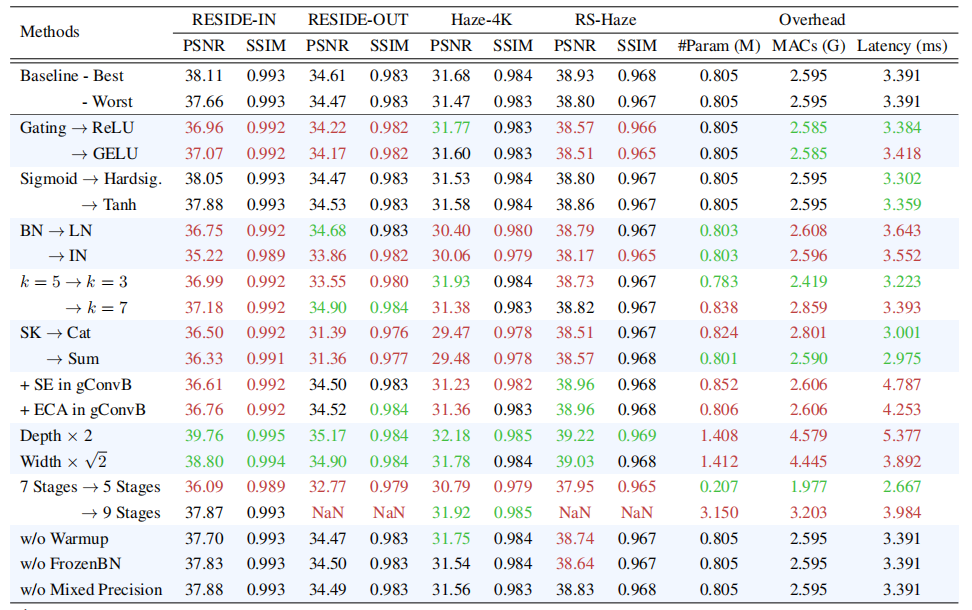 不同数据集上网络架构与训练策略的消融实验结果。标为绿色或红色的结果表示相较于基线模型(gUNet-T)存在性能提升或下降。我们对基线模型进行了五次训练,并取最佳与最差结果
不同数据集上网络架构与训练策略的消融实验结果。标为绿色或红色的结果表示相较于基线模型(gUNet-T)存在性能提升或下降。我们对基线模型进行了五次训练,并取最佳与最差结果
BN 在推理时可以使用训练统计量,而 LN / IN 推理时仍需计算均值方差,速度更慢。这个差距接近 3 dB,非常显著。
k=5 是较好的平衡。大数据集可能偏好较大核,小数据集则较小核有一定正则化作用。
深度与宽度的权衡:在相近参数和计算量下,增加深度比增加宽度更有效。从 gUNet-T 到 gUNet-S(深度翻倍),PSNR 从 38.11 提升到 39.76;宽度扩大根号 2 倍则只到 38.80。
额外通道注意力:在 gConv Block 中加入 SE 或 ECA 没有带来稳定提升,反而在部分数据集上下降。作者认为 SK Fusion 已经承担了全局信息提取功能,再加通道注意力会导致模块冗余。
3.5 与 DehazeFormer 的对比
把这两篇论文放在一起看,能得到一个更完整的图景:
| 维度 | DehazeFormer | gUNet |
| 核心架构 | Swin Transformer(滑窗注意力) | U-Net + gConv 门控 |
| 全局建模 | Self-Attention 天然全局 | SK Fusion 提取全局信息 |
| 局部建模 | Window Attention 局部窗口 | DWConv 局部空间卷积 |
| 计算效率 | 中等 | 极高(DehazeFormer 1/10 MACs) |
| 遥感场景 | 略优(重复场景适合 attention) | 略弱 |
| 普通场景 | 强 | 更强 |
两者不是简单的替代关系,而是代表了两条技术路线:
1.DehazeFormer:Transformer 全局建模路线
2.gUNet:轻量 CNN 门控路线
论文最后可以这样理解:去雾任务真正需要的是合理的多尺度结构、全局-局部建模能力和高效的特征融合机制,不一定非要依赖复杂的 Transformer。但在某些特定场景(如遥感非均匀雾),self-attention 的全局建模优势仍然不可替代。
- 结论
gUNet 这篇论文的思路和常见的提出新 SOTA不同,它更像一份去雾网络的设计指南。通过大量消融实验,把影响去雾性能的关键因素逐个拆开来看,告诉读者到底什么在真正起作用。
具体来说,论文的核心发现包括:
- 门控机制(gConv Block)比 ReLU/GELU 更适合去雾任务,因为它能生成空间变化的激活权重,与透射率的空间变化特性天然契合
- 动态特征融合(SK Fusion)比简单 concat 或 sum 高出 3 dB 以上,说明 skip connection 的融合方式对去雾性能影响巨大
- BatchNorm 在去雾任务上显著优于 LayerNorm 和 InstanceNorm,差距接近 3 dB
- 训练策略(warmup、frozen BN、训练轮数等)可能带来 1 到 2 dB 的差异,不应被忽视
- 在相近计算量下,增加深度比增加宽度更有效
这些发现对复现和改进去雾网络有直接的参考价值。与其堆叠复杂的注意力机制,不如先把基础模块选对、训练策略调好。
专业名词解释
| 名词 | 解释 |
| Global Residual | 网络不直接预测无雾图像,而是预测残差 R(x) = J_hat(x) - I(x) |
| Local Residual | 每个 gConv Block 内部的 shortcut 连接,缓解梯度消失 |
| PWConv | Point-wise Convolution,即 1x1 卷积,用于通道变换 |
| DWConv | Depth-wise Convolution,逐通道空间卷积,参数量远低于普通卷积 |
| BatchNorm | 批归一化,推理时可与线性层融合,适合轻量网络 |
| SyncBN | 多 GPU 训练时同步 BN 统计量,解决单卡 batch 过小的问题 |
| FrozenBN | 训练后期冻结 BN 统计量,使训练和推理更一致 |
| Warmup | 训练前期逐渐增大学习率,避免初始学习率过大导致训练崩溃 |
| SK Fusion | Selective Kernel Fusion,根据全局信息动态决定两路特征的融合比例 |
| PixelShuffle | 亚像素卷积上采样,通过通道到空间的重排实现分辨率放大 |
| GAP | Global Average Pooling,全局平均池化 |
相关资源
论文:https://arxiv.org/abs/2209.05913
代码:https://github.com/IDKiro/gUNet
同作者 DehazeFormer:https://arxiv.org/abs/2204.03883
数据集 RESIDE:https://sites.google.com/view/reside-dehazing-datasets