1.死锁导致的现象:
1.用户明显感觉接口没有反应
2.线程池明显被耗尽
3.CPU使用率大幅度的下降
4.进程存活,但不干活
5.请求堆积
6.客户端卡死
排查:
- jps -l :根据 jar 包 / 启动类名,找到异常 SpringBoot 服务的进程 PID。
- jstack PID :抓取该进程内全部线程的堆栈信息。
- 检索关键字
Found one Java-level deadlock,若存在,会明确列出互相等待的两条线程。 - 顺着线程栈的调用链路,直接定位到具体类、方法、代码行,找到死锁位置。
2.慢sql排查:
通过Druid或者开启慢查询日志,或者普罗米修斯等监控工具进行排查
解决方法:
一、索引优化(最常见)
-
缺失索引 对
where、order by、group by、join on字段建单列 / 联合索引。 -
索引失效
-
避免
like %xxx、字段隐式类型转换、or两侧无索引、not in/not exists -
索引列不做运算、函数、类型转换
-
-
联合索引 遵循最左匹配原则,高频查询字段放左侧。
-
禁用冗余 / 低效索引索引越多写入越慢,删除长期不用、重复索引。
二、SQL 语句改写
-
杜绝
select *,只查需要字段,减少 IO 与网络传输。 -
分页优化
- 深分页:
limit 10000,10改成主键分页 :where id>10000 limit 10
- 深分页:
-
大表分页 / 查询限制单次查询数据量,避免一次性拉取全表。
-
替换低效语法能用
in不用not in;能用join优化子查询;减少多层嵌套子查询。 -
拆分大 SQL单条 SQL 逻辑过杂、关联表过多,拆成分多条简单 SQL。
三、业务 & 架构优化
-
读写分离读压力大:主库写,从库读,分摊查询压力。
-
缓存兜底 热点数据(字典、配置、高频列表)加 Redis,直接拦截查询,不走 DB。
-
分库分表 单表数据量超千万:按 ID / 时间 / 区域做水平分表。
-
限制返回行数接口层面做分页、条数限制,禁止全表遍历。
四、数据库配置优化
-
调大
join_buffer_size、sort_buffer_size、tmp_table_size,减少临时表、文件排序。 -
合理设置连接池、最大连接数,避免连接耗尽。
-
定期 analyze table 更新表统计信息,保证
explain执行计划准确。
五、特殊场景处理
-
批量操作:用批量
insert/update,代替循环单条执行。 -
大批量统计:离线走定时任务 / 数仓,线上不做复杂聚合统计。
-
锁等待 / 阻塞:缩短事务时长,事务内不做耗时业务,避免长事务锁表。
六、排查→修复标准流程
-
Druid / 慢日志拿到慢 SQL
-
explain看执行计划,定位:全表扫描、索引失效、临时表、文件排序 -
优先加索引、改写 SQL
-
高并发热点加缓存;大数据量表做分表 / 读写分离
-
复测耗时,验证优化效果
一、先确认问题现象(第一步必做)
1. 看监控指标
- FGC 次数 / 频率:短时间内持续上涨,比如每分钟触发多次
- FGCT(Full GC 总耗时):持续增长,单次耗时超过 1 秒就要警惕
- 老年代使用率(O):持续高于 80%,且每次 Full GC 后下降不明显(说明内存泄漏)
- 元空间使用率(MU):持续升高,可能是动态类加载导致的元空间溢出
2. 用工具实时验证
jstat -gcutil <pid> 1000
重点看:OGCMN/OGCMX(老年代容量)、OC(当前使用)、YGC/FGC(回收次数)
二、看 GC 日志,判断触发原因
先在 JVM 参数里开启日志(线上提前配置):
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:gc.log
日志里重点关注这些触发场景:
- Allocation Failure:年轻代空间不足,对象频繁晋升到老年代,撑爆老年代
- Metadata GC Threshold:元空间不足触发 Full GC,多和动态代理、反射、类加载器泄漏有关
- System.gc() :代码里主动调用了 System.gc (),建议加上
-XX:+DisableExplicitGC屏蔽 - CMS/Old GC 相关错误:比如 CMS 回收失败、晋升失败、并发模式失败
三、导出堆快照,定位内存泄漏
如果 GC 日志显示老年代回收后使用率依然很高,基本可以判定是内存泄漏,下一步导出堆快照:
导出当前堆内存快照(live参数会先触发一次Full GC,确保只存存活对象) jmap -dump:live,format=b,file=heapdump.hprof <pid>
然后用工具分析:
- MAT(Memory Analyzer Tool):分析大对象、对象占比、引用链,找出泄漏源
- JProfiler/Arthas:在线实时分析对象实例数、内存占用
常见泄漏场景
- 静态集合类(HashMap/List)持有对象不释放
- 未关闭的资源连接(数据库连接、文件流、网络连接)
- 长生命周期对象持有短生命周期对象引用(比如 ThreadLocal 未 remove)
- 第三方框架 / 中间件的内存泄漏(比如 MyBatis、Dubbo 老版本)
3.mysql死锁
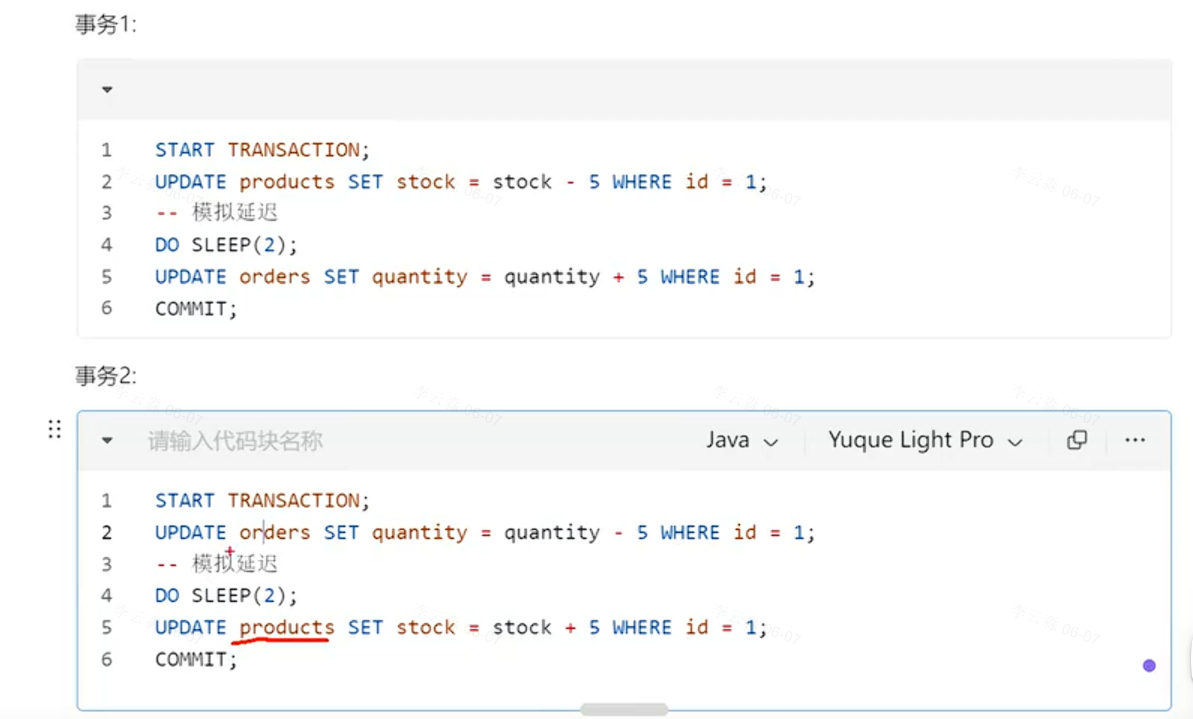
一、死锁核心成因
多个事务互相持有对方需要的排他锁,又循环等待对方释放,且事务不提交锁就不会释放,最终形成死锁。你演示场景的直接原因:
- 事务 1:先锁表 A → 再请求表 B 的锁
- 事务 2:先锁表 B → 再请求表 A 的锁
SLEEP拉长事务、锁持有时间,确保双方都拿到第一把锁,死锁必现。
二、快速排查步骤
- 执行命令查看最近死锁详情
SHOW ENGINE INNODB STATUS;
- 找到
LATEST DETECTED DEADLOCK区块,重点看:- 两个事务分别执行的 SQL
- 各自已持有锁 、正在等待的锁
- 判断类型:锁顺序乱 / 索引失效 / 长事务。
三、常见场景 + 对应修复方案
场景 1:多表更新,加锁顺序不一致(你当前案例,最常见)
- 问题:不同事务操作多张表时,更新顺序相反。
- 修复:全局统一所有事务的表操作顺序 例:所有代码都固定 先改
products,再改orders。
场景 2:单表更新多行,主键 / 行顺序混乱
- 问题:事务 1 更新 id (1,2),事务 2 更新 id (2,1)。
- 修复:更新同表多条数据,按主键 / 索引升序统一执行。
场景 3:事务太长、内部包含耗时操作
- 问题:事务里有接口调用、循环、休眠、大查询,锁长期不释放。
- 修复:
- 事务做到短小快,尽快提交;
- 把非 DB 耗时逻辑移出事务。
场景 4:WHERE 条件无有效索引,行锁升级为表锁
- 问题:
UPDATE/DELETE没走索引,InnoDB 行锁变表锁,冲突范围急剧扩大。 - 修复:
- 给查询条件建立索引(优先主键 / 唯一索引);
- 用
EXPLAIN校验 SQL,杜绝全表扫描更新。
四、通用兜底优化方案
- 优先使用乐观锁(版本号 / 时间戳),规避悲观行锁竞争;
- 适当调低事务隔离级别(RC),缩小锁范围(业务允许时使用);
- 线上严禁事务内写
SLEEP、人为拉长事务。