一、扣子没有 try-catch
在软件开发里,异常处理是基本功。try-catch-finally 是几乎所有语言的标准配置,但在扣子工作流的代码节点里,这些统统不存在。你写的 function main 就是一个纯函数------输入对象进来,输出对象出去,中间如果抛了异常,不会跳到任何 catch 块,而是直接把工作流标红。对于习惯了写代码的开发者来说,这可能是最不适应的一点。但换个角度想:扣子在逼你用更显式的方式处理异常------用条件分支和兜底节点,把每一个可能的失败路径都画在流程图里。最终生成的是一条「所有分支都看得见」的流水线,而不是一堆看不见的 try-catch 嵌套。
先看一个经典崩溃场景:
[开始] → [插件:搜索] → [代码:解析] → [大模型:生成] → [结束]
↑
API 超时,返回空
→ 代码节点报错
→ 整条工作流变红你的工作流可能 90% 的时间跑得很好,但某次搜索超时、某次大模型返回格式异常、某次变量没传进来------直接挂掉。
扣子没有 try-catch。代码节点报错就是报错,不会跳到 catch 块。但你用条件分支+代码节点的组合,可以模拟出和 try-catch 等价的效果。
核心思路:每个可能出错的环节后面都跟一个条件判断,根据结果走正常路径或兜底路径。
[节点] → [条件判断]
├→ 成功(继续)
└→ 失败 → [兜底节点] → 结束(优雅降级)有些同学可能会问:加这么多条件判断,工作流节点不是越堆越多?确实,一条简单的 5 节点流水线加了错误处理后可能膨胀到 15 个节点。但这是值得的------一个节点挂掉导致的排查时间(尤其线上环境),远超过多加几个分支节点的成本。而且条件判断节点本身不消耗调用额度,只是路由逻辑。
下面四个模式按照「成本从低到高、收益从显著到极致」排序。你可以根据流水线的关键程度,选择性叠加:内部工具可以只加模式 1+2,面向用户的产品最好四个都加上。
二、4 种错误处理模式
以下四种模式从简单到复杂,可以逐层叠加。建议先在前两个节点加模式1和2------这两个成本最低,收益最大。等流水线稳定了再上模式3和4,逐步加码。
模式 1:前置校验------数据进门先过关
建议把这作为所有流水线第一个节点后面的标配配置。投入产出比最高------5 行校验代码就能拦截 50% 以上的运行时错误,尤其是用户手动输入场景。
场景: 开始节点的变量可能为空,直接传下去会炸。
连线:
[开始] → [代码:校验] → [条件判断]
├→ valid=true → [后续节点]
└→ valid=false → [代码:返回默认值] → [结束]代码节点:校验
function main({ topic, maxResults }) {
// 校验每一个输入
const errors = [];
if (!topic || topic.trim().length === 0) {
errors.push('topic 不能为空');
}
if (!maxResults || Number(maxResults) <= 0) {
errors.push('maxResults 必须为正整数');
}
return {
valid: errors.length === 0,
errors: errors.join('; '),
topic: topic || '',
maxResults: Number(maxResults) || 10
};
}条件判断配置:
- 条件 1:{{校验.valid}} == true
- 条件 2:{{校验.valid}} == false
分支 2 的兜底代码:
function main({ topic, errors }) {
return {
message: `输入校验失败:${errors}。已使用默认参数继续。`,
topic: topic || '默认主题',
maxResults: 10
};
}扣子工作流的代码节点虽然不支持 try-catch,但 function main 的返回值本身就是一种错误信号。把错误信息和状态码打包返回,交给条件判断分发------这就是扣子世界的异常处理范式。理解了这一点,前三种模式都是同一个思路的不同应用。
🔑 前置校验是最低成本防崩溃手段。一个 10 行的校验节点,能避免 50% 的运行时错误。
模式 2:状态检查------API 调完先看返回码
插件节点(搜索结果、HTTP 请求、知识库查询)是工作流里最不稳定的环节------它们依赖外部服务,完全不在你的控制范围内。模式 2 的核心原则很简单:任何外部数据进工作流之前,先看一眼有没有不对劲的地方。哪怕只是检查一个字段是否存在,也好过直接传给下游让它炸。
场景: 插件节点(搜索/HTTP请求)可能返回空、超时、或被限流。不检查直接处理会炸。
连线:
[插件:搜索] → [代码:检查状态] → [条件判断]
├→ status=ok → [代码:正常处理]
└→ status=empty/timeout → [兜底]代码节点:检查搜索结果状态
function main({ searchResult }) {
// 检查是否返回了有效数据
const hasData = searchResult &&
(searchResult.webPages?.value?.length > 0 ||
searchResult.value?.length > 0 ||
(Array.isArray(searchResult) && searchResult.length > 0));
if (!hasData) {
return {
status: 'empty',
reason: '搜索未返回有效结果'
};
}
// 检查是否被限流
if (searchResult.error || searchResult.code === 429) {
return {
status: 'ratelimit',
reason: 'API 限流,请稍后重试'
};
}
return {
status: 'ok',
data: searchResult
};
}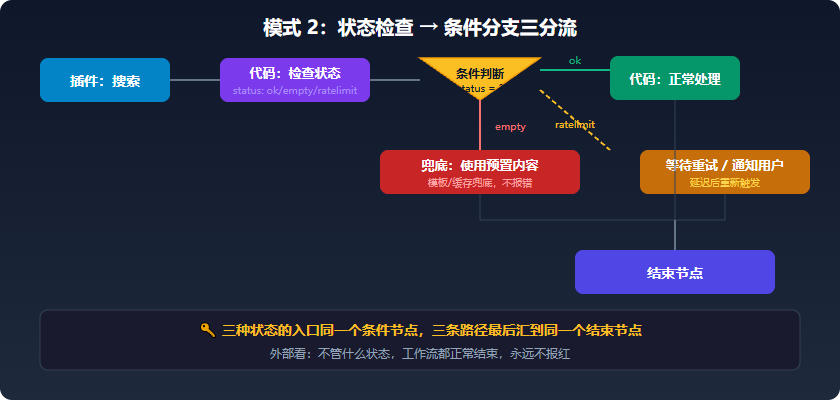
条件判断配置:
- 条件 1:{{状态检查.status}} == "ok"
- 条件 2:{{状态检查.status}} == "empty"
- 条件 3:{{状态检查.status}} == "ratelimit"
这样你可以对三种情况分别处理------正常流程继续跑,空结果用缓存或默认内容兜底,限流则等待后重试。
模式 3:超时兜底------给每个节点设一个死线
前两个模式解决的是「数据对不对」的问题,模式 3 解决的是「数据有没有」的问题。代码节点和大模型节点虽然不能直接设定超时时长,但你可以通过输出侧的反向推断来判断是否超时。这个模式更适合放在整条流水线的中间靠后位置------前面的校验和检查都通过了,数据格式正确,但处理本身花了太久。
场景: 代码节点没有原生超时机制,但你可以手动计时 + 条件判断模拟。
写法:
function main({ input }) {
const startTime = Date.now();
// 你的业务逻辑
let result;
try {
result = JSON.parse(input);
} catch (e) {
// 解析失败 → 提前返回错误状态
return {
timedOut: false,
parseError: true,
error: e.message,
result: null
};
}
const elapsed = Date.now() - startTime;
return {
timedOut: elapsed > 30000, // 30 秒算超时
elapsed: elapsed,
parseError: false,
result: result
};
}然后接条件判断:{{解析.timedOut}} == true → 走简化流程,false → 走正常流程。
对于大模型节点,虽然没有代码接口,但你可以通过观察输出长度间接判断:
function main({ llmOutput }) {
// 如果输出特别短,可能超时了
if (!llmOutput || llmOutput.length < 50) {
return { status: 'suspected_timeout', output: '内容生成超时,使用摘要版本' };
}
if (llmOutput.includes('timeout') || llmOutput.includes('超时')) {
return { status: 'timeout', output: llmOutput };
}
return { status: 'ok', output: llmOutput };
}为什么是 50 个字符和 "超时/ timeout" 关键词?因为扣子大模型节点如果超时,通常返回极短字符串或包含异常关键词。虽然这不是精确的超时检测,但作为兜底判断绰绰有余------宁可误判为超时走简化流程,也好过把异常输出送到下游导致更大范围的崩溃。
模式 4:降级策略------与其崩溃,不如给个次优结果
这是四种模式中最强的一条------把错误处理的粒度从「单节点」提升到「整条业务流程」。不需要每个环节都完美,只需要保证坏了一条路还有另一条。
场景: 主流程依赖某个外部 API,但它挂了。此时用本地静态数据或简化逻辑兜底,而不是直接报错。
完整连线图:
┌→ [大模型A(主)] → [条件:输出是否有效] → 有效 → ┐
[开始] → [代码:校验] →┤ ├→ [结束]
└→ [条件:主路失败] → [大模型B(备用)] → ──────┘核心代码------接管节点:
function main({ primaryOutput, primaryValid }) {
// primaryValid 来自条件判断
if (primaryValid && primaryOutput) {
// 主路成功,直接用
return {
source: 'primary',
content: primaryOutput
};
}
// 主路失败 → 走备用
// 这里调用备用模型或使用模板生成
return {
source: 'fallback',
content: `(主模型暂时不可用,已启用备用方案生成简化版内容)`
};
}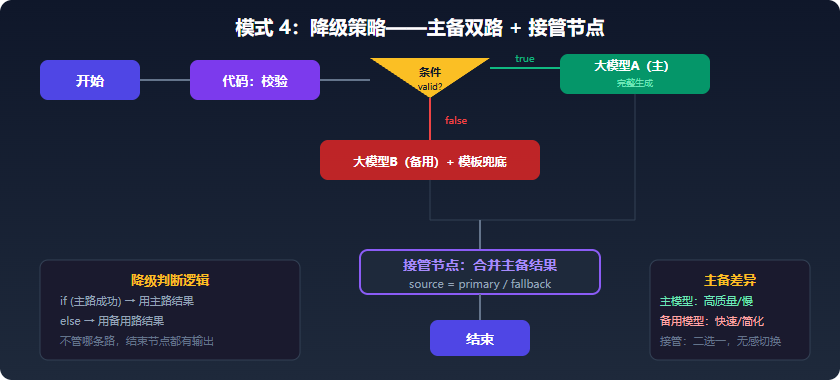
降级不是「凑合」,而是保证工作流永远不中断。对用户来说,得到一个简化版结果远比一个红色报错好。
三、实战:串联 4 种模式,打造零崩溃流水线
理论知识讲完了,接下来是落地的关键------怎么把四个模式塞进同一条流水线里。顺序很重要:先校验输入(模式1),再检查外部依赖状态(模式2),然后防处理超时(模式3),最后做业务降级(模式4)。这个顺序对应了数据流的自然方向------从入口到出口逐步加码防御。
把 4 种模式串到一起,组成一条内容生成流水线:
[开始]
↓
[代码:输入校验] → 模式1:前置校验
↓
[条件:valid?]
├→ false → [兜底:默认参数] → [结束]
└→ true
↓
[插件:搜索] → 模式2:状态检查
↓
[代码:检查状态]
↓
[条件:status?]
├→ empty → [兜底:使用预置内容]
├→ ratelimit → [兜底:等待5秒后重试]
└→ ok
↓
[代码:解析+计时] → 模式3:超时检查
↓
[条件:timedOut?]
├→ true → [简化处理]
└→ false
↓
[大模型:生成文章(主)]
↓
[条件:有效?] → 模式4:降级
├→ false → [大模型:备用方案]
└→ true
↓
[结束]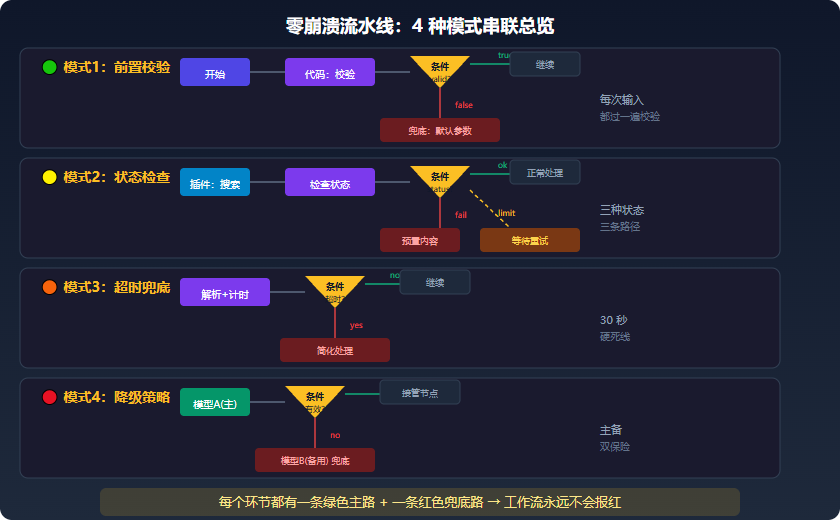
每条分支路径都由条件判断节点精确控制。实际搭建时建议先画好这个总览图再开始拖节点------一旦确定了每个环节的主路和兜底路,后面只是机械的连线工作。
每个环节都有兜底,整条流水线理论上永远不会报红。
四、调试技巧:模拟故障
写完所有节点和条件分支之后,摆在面前的问题就是:怎么知道每条兜底路径是通的?最简单的办法是模拟故障------在代码节点里加一个临时开关,逐个触发异常场景。
在本地调试时,你可以在校验节点的开头加一行临时代码,模拟各种故障场景:
// ===== 调试开关:模拟故障 =====
const SIMULATE = {
emptyInput: false, // 模拟空输入
searchFail: false, // 模拟搜索失败
timeout: false, // 模拟超时
};
if (SIMULATE.searchFail) {
return { status: 'empty', reason: '[模拟] 搜索失败' };
}
// ===== 调试开关结束 =====上线前把所有开关设为 false。这样你每条分支路径都测试过,心里有底。
这种模拟故障的调试方式带来的另一个好处是:当你把工作流分享给团队其他人时,他们也能快速理解每条分支的触发条件。而不是面对一整片条件判断节点,不知道哪个什么时候生效。
五、总结
这些模式本质上是在回答一个问题:当工作流的某个环节不可控时,你能做到的最好结果是什么?扣子没有原生异常处理,但条件分支给了你手动编排容错逻辑的能力。最终的效果是------即使插件挂了、大模型超时了、用户没填参数,流水线依然可以优雅收场。
| 模式 | 适用场景 | 核心机制 |
|---|---|---|
| 前置校验 | 用户输入/开始节点变量 | 条件判断 + valid 标记 |
| 状态检查 | 插件/API 返回 | 检查返回结构是否有效 |
| 超时兜底 | 代码节点/大模型节点 | 手动计时 / 输出长度判断 |
| 降级策略 | 任何外部依赖 | 主备双路 + 接管节点 |
记住三句话:
- 每个节点后面都可以加条件判断------成本为零,收益是消灭了随机崩溃
- 兜底不是「凑合」,是保证用户永远能看到结果
- 线上工作流的第一原则不是「做得好」,是「别挂」
说到底,错误处理的核心心态是接受一个事实:工作流里一定会出问题。不是「如果出问题怎么办」,而是「问题来了怎么优雅收场」。把本文的四种模式按需组合,你的工作流就从一个脆弱的脚本变成一个健壮的服务------这才是自动化的真正模样。
关于作者 :专注扣子工作流稳定性与自动化实战,更多模板和进阶教程可搜索「米核AI易山」或访问 miheaii.com。
本文部分内容由 AI 辅助完成。