08 | BM25 的 Sigmoid 归一化------原始分数为什么不能直接加?
一场无声的灾难
假设你在做混合检索,语义相似度 0.82,BM25 原始分 15.7。你把它们加起来:0.82 + 15.7 = 16.52。
看出了什么问题吗?
语义分在 0, 1,BM25 原始分在 0, 20+。直接相加,BM25 的信号量级是语义的 20 倍。等于说,只要关键词命中了,语义匹配几乎没有任何话语权。这不是混合检索,这是关键词检索套了个语义的壳。
这还不是最坏的情况。BM25 的原始分数没有上界------在极端情况下,一个命中了大量查询词的长文档可以拿到 30 甚至 40 分。而语义分的理论最大值始终是 1.0。当 BM25 分是语义分的 30~40 倍时,语义信号在加法中已经被噪声化了------即使一个语义完全不相关的记忆,只要关键词恰好命中,也能碾压语义高度相关但关键词未命中的候选。
mem0 的混合检索管线里,三种信号要加到一起:语义分、BM25 分、实体增强分。语义分天生 0, 1,实体增强分最大 0.5,唯独 BM25 是一个无界的原始分数。如果它不归一化,整个加法体系都会崩塌。
所以问题的核心不是"要不要归一化",而是"怎么归一化"。
先破:Min-Max 归一化的致命缺陷
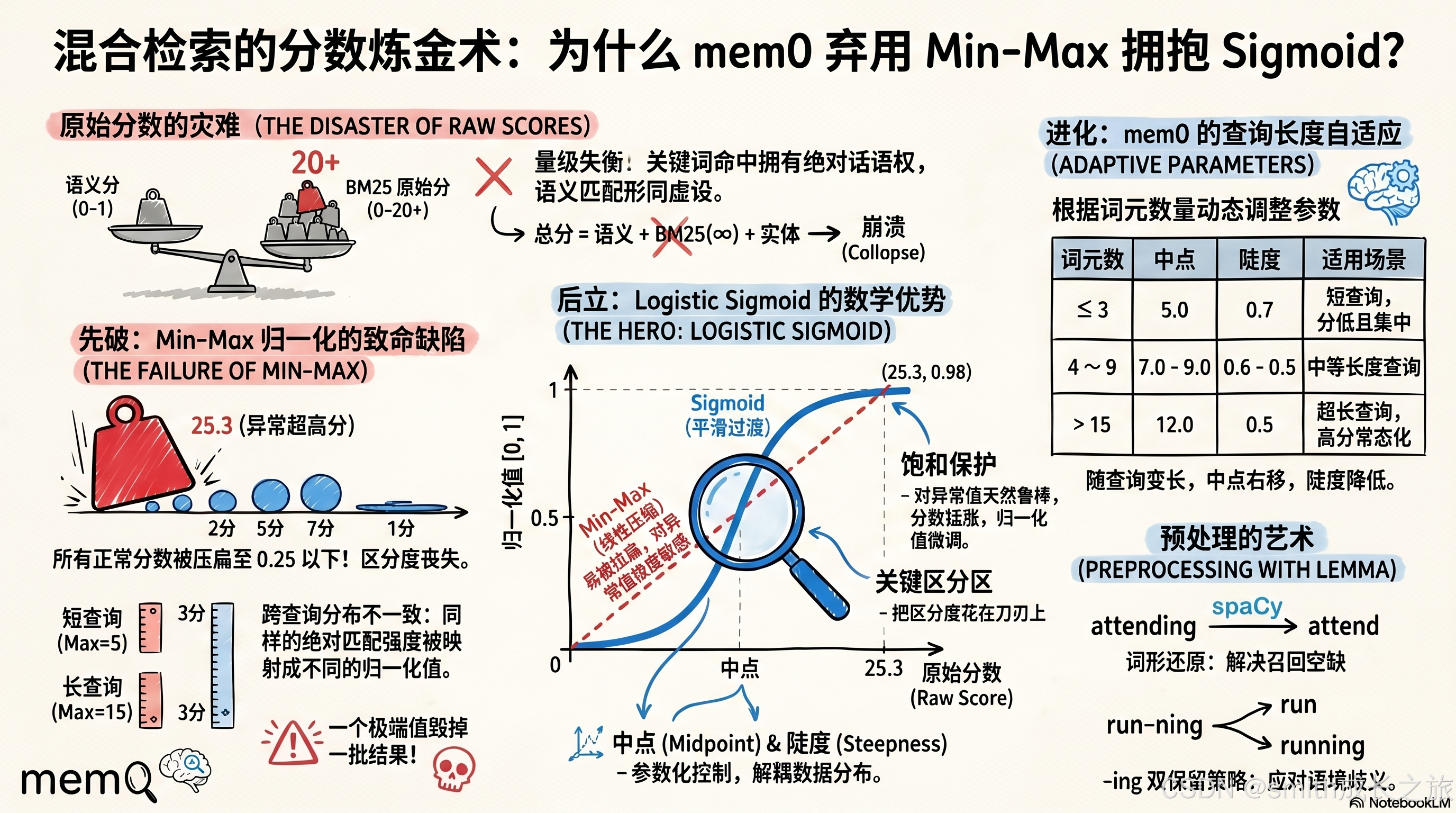
最直觉的方案是 Min-Max:拿当前批次的最高分和最低分做线性映射,把原始分压到 0, 1。
公式很简单:
normalized = (score - min) / (max - min)看起来合理,但这个方案有一个致命问题:对异常值极度敏感。
数值灾难:一个极端分数如何压扁所有其他结果
考虑一个具体的场景。假设 10 条候选记忆的 BM25 原始分如下:
记忆 A: 25.3 (命中了几乎所有查询词,异常高分)
记忆 B: 7.8
记忆 C: 6.2
记忆 D: 5.5
记忆 E: 4.9
记忆 F: 4.1
记忆 G: 3.7
记忆 H: 3.2
记忆 I: 2.8
记忆 J: 2.1Min-Max 归一化:min=2.1, max=25.3, range=23.2
记忆 A: (25.3 - 2.1) / 23.2 = 1.000
记忆 B: ( 7.8 - 2.1) / 23.2 = 0.246
记忆 C: ( 6.2 - 2.1) / 23.2 = 0.177
记忆 D: ( 5.5 - 2.1) / 23.2 = 0.147
记忆 E: ( 4.9 - 2.1) / 23.2 = 0.121
记忆 F: ( 4.1 - 2.1) / 23.2 = 0.086
记忆 G: ( 3.7 - 2.1) / 23.2 = 0.069
记忆 H: ( 3.2 - 2.1) / 23.2 = 0.047
记忆 I: ( 2.8 - 2.1) / 23.2 = 0.030
记忆 J: ( 2.1 - 2.1) / 23.2 = 0.000看到了吗?9 条记忆的归一化分全部被压到了 0.25 以下。记忆 B(原始分 7.8,已经算是不错的匹配)和记忆 J(原始分 2.1,几乎不匹配)在归一化后只差 0.246,而语义分 0.1 的差异就能轻松覆盖这个差距。
再来看混合评分的后果。假设记忆 B 语义分 0.91,记忆 A 语义分 0.45(关键词命中但语义不太相关):
记忆 A 总分: 0.45 + 1.000 = 1.450
记忆 B 总分: 0.91 + 0.246 = 1.156语义高度相关的记忆 B 输给了语义不相关但关键词全命中的记忆 A。混合检索退化为关键词检索。
没有异常值也不行:跨查询的分布不一致
Min-Max 的根本问题在于:归一化参数依赖当前批次的数据分布,而 BM25 原始分的分布在不同查询间差异巨大。
短查询"部署失败"可能只有 2 个词,所有候选分都很低(0~5)。长查询"如何在 Kubernetes 集群中配置自动扩缩容策略并设置资源限制"有 10+ 个词,候选分普遍偏高(8~20)。Min-Max 把这两种情况都拉到 0, 1,等于说短查询下 BM25 分 3 对应的归一化值,和长查询下 BM25 分 15 对应的归一化值可能相同------但前者是弱匹配,后者是强匹配。Min-Max 抹平了"绝对匹配强度"的信息。
更极端的例子:如果某次查询的所有候选 BM25 分都集中在 4.0~4.5 之间(全部弱匹配),Min-Max 会把 4.5 映射为 1.0,4.0 映射为 0.0,人为制造出完全不存在的区分度。一个全局弱匹配的批次被包装成了有强有弱的分布------这是对下游加法系统的欺骗。
你需要一个归一化方案,满足三个条件:
- 输出值域 0, 1,与语义分可比
- 对异常值鲁棒,不会被单个极端分数绑架
- 保留"绝对匹配强度"的区分度,不受当前批次影响
追问:为什么不是其他归一化函数?
在确定 Sigmoid 之前,值得审视其他候选方案,理解为什么它们被排除。
Z-Score 归一化?
Z-Score 把分数映射为 (x - μ) / σ,输出值域无界,不满足条件 1。你可以再加一层截断到 0, 1,但截断点怎么选?又回到了和 Min-Max 同样的问题------截断参数依赖数据分布。而且 Z-Score 假设分数近似正态分布,BM25 分数明显偏态(长尾右偏),Z-Score 的理论优势在这里不成立。
Tanh?
Tanh 和 Sigmoid 是近亲:tanh(x) = 2 * sigmoid(2x) - 1,输出值域 -1, 1。需要额外线性变换才能映射到 0, 1,多一步操作,多一组参数,没有本质区别。而且 Tanh 的中点在 y=0,对 BM25 分数(始终非负)来说,负半轴完全浪费了。
Log 归一化?
normalized = log(1 + raw_score) / log(1 + max_possible)------对数压缩确实能削弱极端值,但分母 max_possible 又引入了对数据分布的依赖。如果用固定分母,那 max_possible 怎么选?本质上你仍然在做一个需要调参的映射,而且对数函数在低分区的压缩比 Sigmoid 更激进------BM25 分 1 和 3 之间的差距会被过度压缩。
百分位排名(Percentile Rank)?
把每个分数映射为它在全局分布中的百分位。理论上对异常值最鲁棒,但需要维护一个全局分数分布的统计信息,运行时开销大,且百分位是纯相对排序------完全丧失了绝对匹配强度。BM25 分 3 和 BM25 分 15 如果恰好在同一个百分位区间,它们的归一化值就相同,无论语义上天差地别。
Sigmoid 的独特优势
Sigmoid 在以上候选中脱颖而出,因为它同时满足三个条件,且不需要任何运行时数据统计:
- 值域天然 0, 1------不需要截断、不需要额外缩放
- 参数与数据分布解耦------midpoint 和 steepness 是预设的,不依赖当前批次
- 非线性的压缩梯度------低分区间和高分区间的梯度天然衰减,中间区间梯度最大
这个"中间梯度大、两端梯度小"的性质,恰好对应了 BM25 分数在实际检索中的语义:中等分数区间的区分度最有价值(从"几乎不匹配"到"中等匹配"的跃迁),而极端高分区间的区分度价值递减(从"非常匹配"到"极其匹配"的差异对最终排序影响小)。
后立:Logistic Sigmoid 归一化
mem0 的选择是 Logistic Sigmoid------经典的 S 型曲线:
normalized = 1 / (1 + exp(-steepness * (raw_score - midpoint)))两个参数:
- midpoint :S 曲线的中点。当
raw_score == midpoint时,输出恰好 0.5。它定义了"什么样的 BM25 分算中等匹配"。 - steepness:曲线的陡度。值越大,S 曲线越陡,过渡区间越窄,区分度越集中在中点附近。
Sigmoid 天然满足上面的三个条件:
值域 0, 1 ------当 raw_score → ∞ 时趋近 1,raw_score → -∞ 时趋近 0,输出永远不越界。
对异常值鲁棒------Sigmoid 的两端是饱和的。一个 BM25 分从 15 涨到 25,经过 Sigmoid 后可能只是从 0.92 变到 0.98,差异被平滑压缩。异常高分不会绑架整个归一化。
保留绝对强度------midpoint 和 steepness 是根据查询特征预设的,不依赖当前批次的数据分布。BM25 分 8 在短查询下和长查询下会被归一化到不同的值,这恰恰是正确的------短查询下 8 分已经是强匹配,长查询下 8 分只是普通。
Sigmoid 的数学性质:为什么它能平滑压缩极端值同时保留中间区分度
理解 Sigmoid 的关键在于它的导数------梯度决定了函数在每个点的"区分度"。
Sigmoid 的导数为:f'(x) = steepness * f(x) * (1 - f(x))
当 f(x) = 0.5 时(即 raw_score == midpoint),导数最大:f'(midpoint) = steepness / 4。这是 Sigmoid 区分度最高的点。
当 f(x) 趋近 0 或 1 时,导数趋近 0------这就是饱和区,区分度被压缩。
用一个具体数值来感受。取 midpoint=7.0, steepness=0.6:
raw_score = 0 → normalized = 0.014 (几乎为0,弱匹配被判为弱匹配 ✓)
raw_score = 3 → normalized = 0.119 (低分区间,梯度开始上升)
raw_score = 5 → normalized = 0.310 (中低区间,区分度显著)
raw_score = 7 → normalized = 0.500 (中点,最大区分度)
raw_score = 9 → normalized = 0.690 (中高区间,区分度依然显著)
raw_score = 11 → normalized = 0.845 (高分区间,梯度开始衰减)
raw_score = 15 → normalized = 0.960 (高饱和区,区分度被压缩)
raw_score = 25 → normalized = 0.998 (极高分数,与15分几乎无差异)对比之前 Min-Max 的灾难性结果:同一个 25 分的异常值,Min-Max 给出 1.000,Sigmoid 给出 0.998,差异不大。但关键区别在于------Min-Max 让其他 9 条记忆全部被压到 0.25 以下,而 Sigmoid 让 7 分的记忆获得 0.500,9 分的记忆获得 0.690。中间区间的区分度被完整保留。
这正是 Sigmoid 的核心价值:它不是简单地把极端值砍掉,而是用数学结构本身保证了"中间区分度最大化、两端区分度递减"的优先级分布。这个优先级分布与 BM25 分数在检索场景中的语义价值完美对齐。
查询长度自适应:为什么短查询和长查询不能用同一组参数?
BM25 有一个众所周知的特性:查询越长,原始分越高。因为 BM25 的评分是各查询词得分的加总,5 个词的查询天然比 2 个词的查询得分高。
这意味着,如果所有查询共用一组 midpoint 和 steepness,短查询的 BM25 分会被压到 Sigmoid 的左尾(输出接近 0),长查询的分会被推到右尾(输出接近 1)。两种情况下区分度都会丧失。
用一个极端例子来说明:假设 midpoint 固定为 7.0。
短查询"部署失败"只有 2 个有效词,候选记忆的 BM25 分通常在 0~5 之间。所有分数都落在 midpoint 左侧,Sigmoid 输出全部在 0.31 以下------9 条记忆挤在 0.01, 0.31 的窄区间里,区分度极差。
长查询"如何在 Kubernetes 集群中配置自动扩缩容策略并设置资源限制"有 10+ 个有效词,候选分通常在 8~20 之间。所有分数都落在 midpoint 右侧,Sigmoid 输出全部在 0.69 以上------同样区分度极差。
两种情况都让 Sigmoid 退化为"几乎全 0"或"几乎全 1"的常函数,失去了归一化的意义。
mem0 的解法:get_bm25_params
mem0 的解法是 get_bm25_params------根据查询的词元数量,动态选择 sigmoid 参数:
python
def get_bm25_params(query: str, *, lemmatized: Optional[str] = None) -> tuple:
if lemmatized is None:
from mem0.utils.lemmatization import lemmatize_for_bm25
lemmatized = lemmatize_for_bm25(query)
num_terms = len(lemmatized.split()) if lemmatized else 1
if num_terms <= 3:
return 5.0, 0.7
elif num_terms <= 6:
return 7.0, 0.6
elif num_terms <= 9:
return 9.0, 0.5
elif num_terms <= 15:
return 10.0, 0.5
else:
return 12.0, 0.5注意,这里统计词元数量用的是 lemmatize 后的结果,不是原始查询。这很合理------"I am attending meetings" 经过去停用词和词形还原后只剩 "attend meeting"(2 个词),而不是 4 个。
参数的演进规律:
| 词元数 | midpoint | steepness | 直觉含义 |
|---|---|---|---|
| ≤3 | 5.0 | 0.7 | 短查询分低,中点前移,曲线更陡 |
| 4~6 | 7.0 | 0.6 | 中点右移,陡度略降 |
| 7~9 | 9.0 | 0.5 | 中点继续右移,陡度进一步降低 |
| 10~15 | 10.0 | 0.5 | 长查询,中点继续推高 |
| >15 | 12.0 | 0.5 | 超长查询,高分常态,中点最高 |
midpoint 随查询长度递增------长查询的 BM25 原始分天然偏高,需要更高的中点才能让 Sigmoid 输出有意义的中等值。如果 15 个词的查询仍然用 midpoint=5.0,几乎所有结果都会被压到 Sigmoid 右尾(接近 1.0),BM25 的区分功能名存实亡。
steepness 随查询长度递减------短查询的候选少、分数集中,需要更陡的曲线来拉开区分度。长查询的候选多、分数分散,较平缓的曲线能保留更宽的有效区间。这个设计暗含一个假设:短查询的命中/未命中更二元化(要么精确匹配要么不匹配),长查询的匹配程度更连续。
k=1.0 和 x0=6.0 的参数含义
在 Sigmoid 的标准数学形式中,参数通常写作 k(陡度)和 x0(中点)。mem0 的代码中对应关系是:steepness = k, midpoint = x0。
如果固定 k=1.0 和 x0=6.0 作为基准线,Sigmoid 在 raw_score=6 时输出 0.5,在 raw_score=2 时输出 0.018,在 raw_score=10 时输出 0.982。有效区分区间大约在 2, 10,覆盖了中等查询长度下 BM25 分数的典型分布。
但 mem0 没有使用固定参数------它的 steepness 范围是 0.5~0.7,midpoint 范围是 5.0~12.0。这意味着它比标准 Sigmoid 更平缓、更宽容。steepness=0.5 时,从 0.1 到 0.9 的过渡区间需要 raw_score 跨越约 9 个单位(对比 steepness=1.0 只需约 4.5 个单位)。更宽的过渡区间意味着更少的结果被压到极端的 0 或 1 附近,更多结果保留在有效区分区间内。
这是一个保守的设计选择:宁可牺牲一点区分度精度,也不让任何一组查询的候选被挤到 Sigmoid 的饱和区。在工程实践中,"宁可区分度稍弱,也不让整组查询失效"是更安全的策略。
前置工序:lemmatize_for_bm25 的预处理
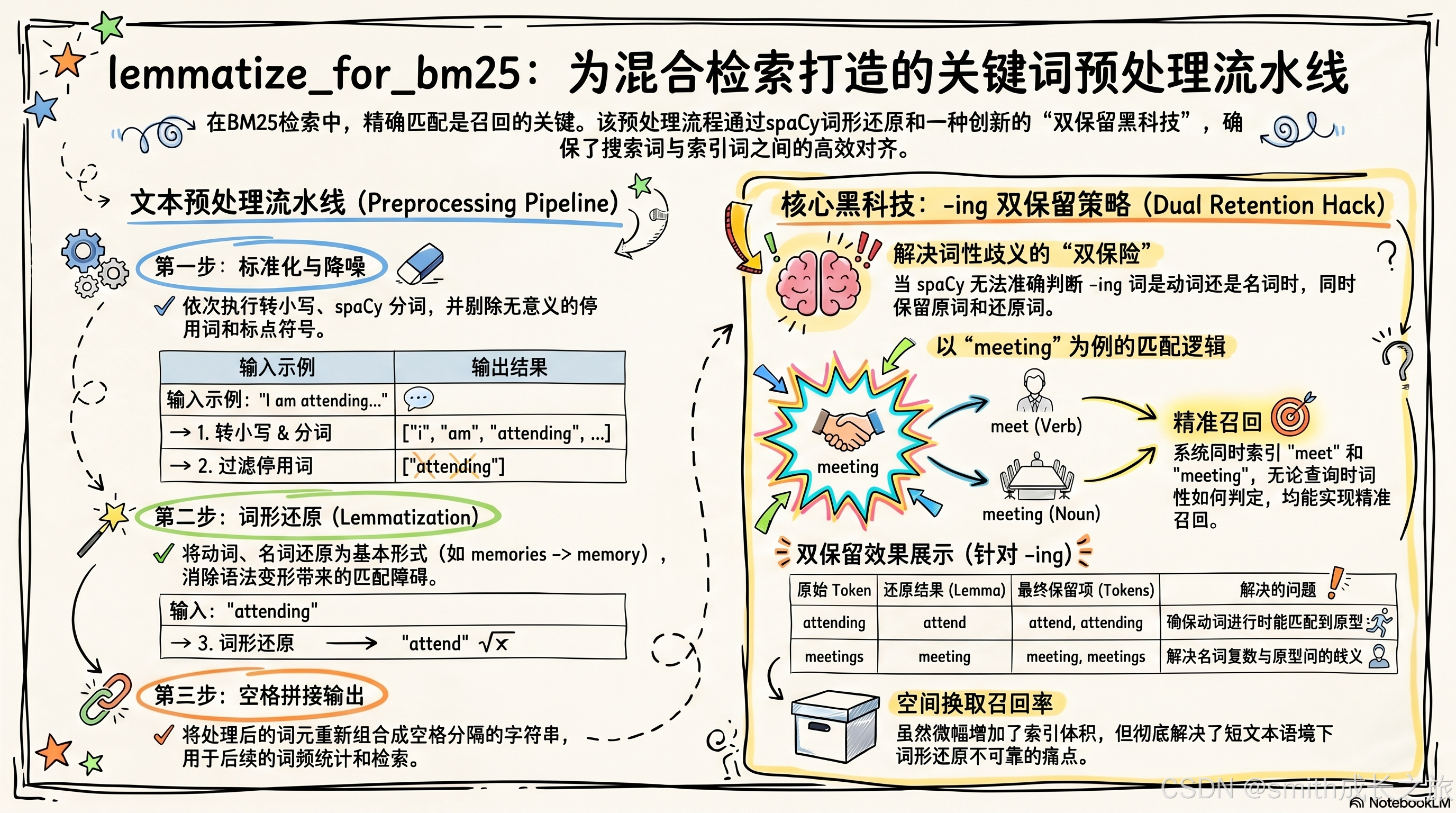
在调用 get_bm25_params 之前,查询先经过 lemmatize_for_bm25 预处理。这个函数承担两项职责,而且这两项职责的交互对 BM25 的召回率有深远影响。
第一项:词形还原
用 spaCy 的 lemmatizer 把 "attending" 归为 "attend","memories" 归为 "memory","older" 归为 "old"。这保证 BM25 的关键词匹配不受词形变化干扰。
词形还原对 BM25 的贡献是本质性的。BM25 是精确词元匹配------如果索引中存储的是 "running",而查询词是 "ran",BM25 不会给任何分数。词形还原把两者统一为 "run",消除了这个召回缺口。
考虑一个实际场景:用户存储了"我每天跑步五公里",索引中的词元是 "run 5 kilometer"。后来用户查询"跑步习惯",查询词元是 "run habit"。"run" 精确匹配,BM25 给出分数。如果没有词形还原,查询词 "running" 无法匹配索引中的 "run",这条记忆就丢失了。
这不是小概率事件------英语中动词形态变化极为普遍(run/running/ran,attend/attending/attended,meet/meeting/met),名词复数和比较级同样常见。在 mem0 的场景中,用户存储记忆时的措辞和查询时的措辞几乎必然存在词形差异。词形还原是 BM25 召回率的基石。
第二项:-ing 形式的双保留
这是一个精巧的 hack:
python
# Also add original if it ends in -ing and differs from lemma.
# This handles noun/verb ambiguity (meeting/meet, attending/attend).
if token.text.endswith("ing") and token.text != lemma and token.text.isalnum():
tokens.append(token.text)为什么要双保留?因为 spaCy 的词形还原依赖上下文。"meeting" 作为名词时,spaCy 可能保留 "meeting";作为动词时,还原为 "meet"。但 BM25 是无上下文的关键词匹配,如果索引中存储的是名词形态 "meeting",而查询被还原成了 "meet",就永远匹配不上。
反过来更危险:如果存储时 spaCy 把 "meeting" 还原为 "meet"(因为它在存储上下文中被判定为动词),而查询时 "meeting" 被保留为名词形态(因为在查询上下文中被判定为名词),同样匹配失败。
这是一个经典的 NLP 歧义问题在信息检索中的投影。spaCy 的词形还原器在理想情况下能正确区分 "meeting" 的名词和动词用法,但在短文本、无上下文的记忆片段中,它的判断不可靠。
解决方案简单粗暴但有效:-ing 结尾的词,lemma 和原形都保留。"meeting" 同时索引 "meet" 和 "meeting",两边都能命中。代价是索引膨胀(每个 -ing 词多一个 token),但在 mem0 的场景中(记忆数量有限、单个记忆文本短),这个代价可以忽略。
完整的预处理流程
python
def lemmatize_for_bm25(text: str) -> str:
nlp = get_nlp_lemma()
if nlp is None:
return text
doc = nlp(text.lower())
tokens = []
for token in doc:
if token.is_punct or token.is_stop:
continue
lemma = token.lemma_
if lemma.isalnum():
tokens.append(lemma)
if token.text.endswith("ing") and token.text != lemma and token.text.isalnum():
tokens.append(token.text)
return " ".join(tokens)逐步拆解这个函数的每一步:
-
获取 spaCy 模型 :
get_nlp_lemma()懒加载一个轻量级 spaCy pipeline(只做 tokenization 和 lemmatization,不做 NER 和 parser,节省资源)。如果 spaCy 不可用,直接返回原文------降级策略保证功能不中断。 -
转小写 :
text.lower()------BM25 是大小写敏感的精确匹配,统一小写避免 "Deploy" 和 "deploy" 不匹配。 -
spaCy 分词 :
nlp(text.lower())生成 Doc 对象,每个 token 带有词性标注和词形还原结果。 -
过滤停用词和标点 :
token.is_punct or token.is_stop------"the", "is", "a" 这类词对 BM25 匹配无贡献,反而增加噪声。注意 BM25 本身有 IDF 机制会降低高频词的权重,但停用词的 IDF 极低,几乎不贡献分数,不如直接过滤以减少计算量。 -
词形还原 :
token.lemma_------"attending" → "attend","older" → "old"。 -
-ing 双保留 :如果原词以 "-ing" 结尾且与 lemma 不同,追加原词。条件
token.text.isalnum()过滤掉 "something" 这类伪 -ing 词。 -
空格拼接:返回空格分隔的词元序列。
最终输出是一个空格分隔的词元序列,既用于 BM25 关键词搜索的查询,也用于 get_bm25_params 中统计词元数量。
Qdrant 内置 BM25 vs mem0 自建 BM25:为什么不能直接用 Qdrant 的分数?
mem0 使用 Qdrant 作为默认向量存储。Qdrant 本身支持 BM25 稀疏向量搜索------在创建 collection 时注册一个 bm25 命名的稀疏向量槽位,使用 SparseVectorParams(modifier=Modifier.IDF) 配置,查询时通过 query_points(using="bm25") 执行稀疏向量搜索。
但 Qdrant 返回的 BM25 分数是原始分------没有归一化,没有上界。这就是 mem0 必须自建归一化层的原因。
具体来说,Qdrant 的 BM25 实现路径是:
-
写入时 :用 fastembed 的
SparseTextEmbedding(model_name="Qdrant/bm25")把文本编码为 BM25 稀疏向量(词元 → 稀疏索引,权重由 BM25 公式计算)。稀疏向量与稠密向量一起存入同一个 Qdrant point。 -
查询时:查询文本同样被编码为 BM25 稀疏向量,然后在 Qdrant 中执行稀疏向量相似度搜索,返回的 score 是原始 BM25 分。
-
IDF 修饰器 :
Modifier.IDF让 Qdrant 在计算稀疏向量相似度时自动考虑逆文档频率,等价于 BM25 的 IDF 组成部分。
Qdrant 做了 BM25 的评分计算,但没有做归一化------这是存储引擎的合理边界。Qdrant 作为一个通用向量数据库,不应该对用户的分数分布做假设。归一化策略是应用层的决策,取决于下游如何使用这些分数。
mem0 不能直接用 Qdrant 的原始分,因为:
- 混合加法需要可比量级------Qdrant 返回的原始 BM25 分与语义分不在同一量级。
- 查询长度影响------不同查询长度的 BM25 分分布不同,Qdrant 不感知查询上下文,无法自适应调整。
- 多存储引擎一致性------mem0 支持多种向量存储(Qdrant、Milvus、Pinecone、PGVector...),归一化必须在应用层统一,不能依赖特定存储引擎的行为。
所以 mem0 的架构选择是:Qdrant 负责 BM25 的评分计算和存储,mem0 负责 BM25 的归一化和融合。各司其职,边界清晰。
这个架构也解释了为什么 keyword_search 返回 None 是合法的------如果 Qdrant collection 是 v3 之前创建的(没有 bm25 稀疏槽位),或者 fastembed 未安装,BM25 搜索会被静默禁用,检索退化为纯语义搜索。这不是错误,而是降级策略。
源码解读:从原始分数到归一化分数的完整链路
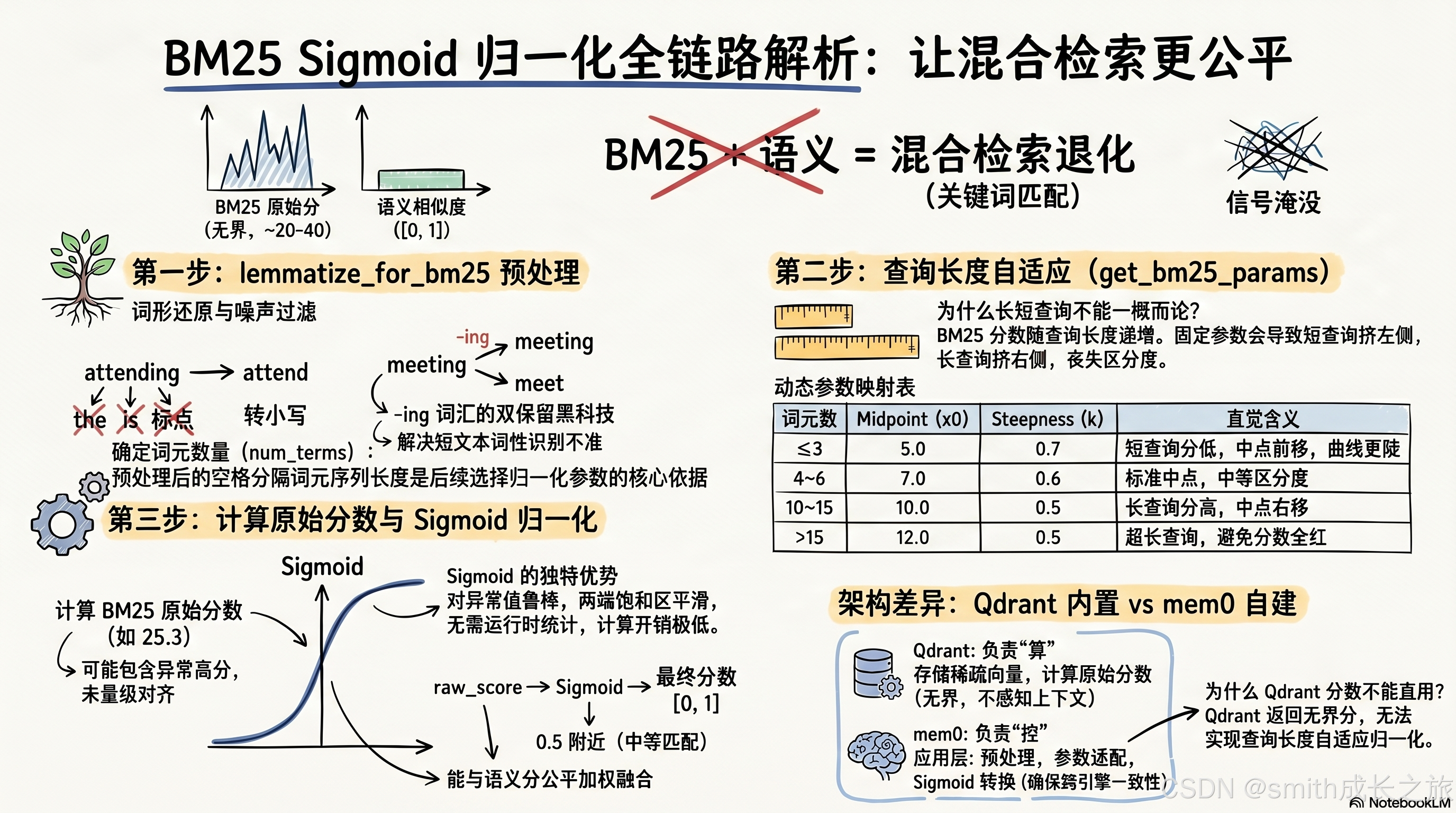
现在把所有拼图放在一起,追踪一次搜索请求中 BM25 分数的完整生命周期。
Step 1: 查询预处理
python
# main.py, search()
query_lemmatized = lemmatize_for_bm25(query)用户输入 "I am attending meetings about deployment"。
经过 lemmatize_for_bm25:
- "i" → 停用词,过滤
- "am" → 停用词,过滤
- "attending" → lemma "attend",-ing 双保留 → tokens: "attend", "attending"
- "meetings" → lemma "meeting",-ing 双保留 → tokens: "meeting", "meetings"
- "about" → 停用词,过滤
- "deployment" → lemma "deployment" → tokens: "deployment"
输出:"attend attending meeting meetings deployment",共 5 个词元。
Step 2: 获取 Sigmoid 参数
python
midpoint, steepness = get_bm25_params(query, lemmatized=query_lemmatized)num_terms = len("attend attending meeting meetings deployment".split()) = 5,落入 4~6 档位,返回 (7.0, 0.6)。
Step 3: 执行 BM25 关键词搜索
python
keyword_results = self.vector_store.keyword_search(
query=query_lemmatized, top_k=internal_limit, filters=filters
)Qdrant 把 query_lemmatized 编码为 BM25 稀疏向量,执行稀疏搜索,返回原始分数的结果列表。
Step 4: 逐条归一化
python
bm25_scores = {}
if keyword_results is not None:
midpoint, steepness = get_bm25_params(query, lemmatized=query_lemmatized)
for mem in keyword_results:
mem_id = str(mem.id) if hasattr(mem, 'id') else str(mem.get('id', ''))
raw_score = mem.score if hasattr(mem, 'score') else mem.get('score', 0)
if raw_score and raw_score > 0:
bm25_scores[mem_id] = normalize_bm25(raw_score, midpoint, steepness)对每条结果,调用 normalize_bm25(raw_score, 7.0, 0.6)。
python
def normalize_bm25(raw_score: float, midpoint: float, steepness: float) -> float:
return 1.0 / (1.0 + math.exp(-steepness * (raw_score - midpoint)))完整计算过程,以 raw_score=8.3 为例:
- 计算偏移量:
raw_score - midpoint = 8.3 - 7.0 = 1.3 - 乘以陡度:
steepness * offset = 0.6 * 1.3 = 0.78 - 取负:
-0.78 - 指数运算:
exp(-0.78) = 2.718^(-0.78) ≈ 0.458 - 加 1:
1 + 0.458 = 1.458 - 取倒数:
1 / 1.458 ≈ 0.686
归一化结果:0.686。这个值在 (0, 1) 区间内,表示"中等偏上的匹配",与直觉一致------8.3 分略高于中点 7.0,归一化值略高于 0.5。
注意过滤条件 if raw_score and raw_score > 0:零分和负分的结果直接跳过,不进入归一化。这避免了 exp(0) = 1 带来的边界情况(raw_score=0 时,如果 midpoint=7.0,归一化值约 0.014,接近 0 但不等于 0,可能在下游加法中产生微弱的噪声)。
Step 5: 三路信号融合
python
# score_and_rank() in scoring.py
raw_combined = semantic_score + bm25_score + entity_boost
combined = min(raw_combined / max_possible, 1.0)max_possible 根据活跃信号动态调整:
- 只有语义分:1.0
- 语义 + BM25:2.0
- 语义 + BM25 + 实体增强:2.5
- 语义 + 实体增强(无 BM25):1.5
除以 max_possible 把总分归一化到 0, 1,确保不同配置下的分数可比。
此时三路信号都在可比的量级:语义分 0, 1、BM25 分 (0, 1)、实体增强分 0, 0.5。加法终于有了意义。
完整调用链路图
search() / asearch()
│
├─ Step 1: query_lemmatized = lemmatize_for_bm25(query)
│ ├─ 转小写
│ ├─ spaCy 分词
│ ├─ 过滤停用词和标点
│ ├─ 词形还原 (attending → attend)
│ └─ -ing 双保留 (attend + attending)
│
├─ Step 2: query_entities = extract_entities(query)
│
├─ Step 3: embeddings = embedding_model.embed(query, "search")
│
├─ Step 4: semantic_results = vector_store.search(query, embeddings, top_k)
│
├─ Step 5: keyword_results = vector_store.keyword_search(query_lemmatized, top_k)
│ ├─ fastembed 编码为 BM25 稀疏向量
│ ├─ Qdrant 稀疏向量搜索 (using="bm25", modifier=IDF)
│ └─ 返回原始 BM25 分数
│
├─ Step 6: BM25 归一化
│ ├─ midpoint, steepness = get_bm25_params(query, lemmatized=query_lemmatized)
│ │ └─ 根据词元数选择参数 (5个词 → midpoint=7.0, steepness=0.6)
│ └─ for each keyword_result:
│ bm25_scores[mem_id] = normalize_bm25(raw_score, midpoint, steepness)
│ └─ 1 / (1 + exp(-steepness * (raw_score - midpoint)))
│
├─ Step 7: entity_boosts = _compute_entity_boosts(query_entities, filters)
│
└─ Step 8: score_and_rank(semantic_results, bm25_scores, entity_boosts, threshold, top_k)
├─ 过滤语义分低于 threshold 的候选
├─ raw_combined = semantic + bm25 + entity_boost
├─ combined = min(raw_combined / max_possible, 1.0)
└─ 按 combined 降序排序,返回 top_kSigmoid 的平滑过渡 vs 极端分数的区分度损失
Sigmoid 不是没有代价。它的核心 Trade-off 在于:两端饱和区间的区分度损失。
当 BM25 原始分远高于 midpoint 时,Sigmoid 输出趋近 1。一个 15 分的结果和一个 25 分的结果,归一化后可能是 0.93 和 0.99------看起来差不多,但原始分差距是 10 分。
这不是 bug,而是设计意图。mem0 的混合检索中,语义分和 BM25 分应该是互补而非替代的关系。如果一个记忆的 BM25 分已经 15 了,说明关键词匹配极其充分,此时继续放大它与 25 分结果的差距,对最终排序几乎没有帮助------因为语义分才是区分"关键词都命中但语义相关度不同"的候选的关键。
但这个 Trade-off 在某些边界情况下会暴露问题。考虑两个记忆:
- 记忆 X:BM25 分 25,语义分 0.30(关键词全命中,但语义不相关)
- 记忆 Y:BM25 分 15,语义分 0.50(部分关键词命中,语义相关度中等)
归一化后:X 的 BM25 分 ≈ 0.99,Y 的 BM25 分 ≈ 0.93。差值只有 0.06,而语义差值是 0.20。最终 X 的总分(0.30 + 0.99 = 1.29)仍然高于 Y(0.50 + 0.93 = 1.43)------等等,Y 赢了?
是的,在这个例子中 Y 赢了。这正是 Sigmoid 归一化设计意图的体现------当 BM25 分数都进入饱和区时,语义分接管了排序权。但如果你把 Y 的语义分换成 0.20,X 就会赢(1.29 vs 1.13)。这个边界地带的排序行为取决于语义分和 BM25 分的相对大小,Sigmoid 保证的是两者在量级上可比,但不保证每种情况下谁胜谁负------那是语义分和 BM25 分各自的信号质量决定的。
另一个隐含的 Trade-off:get_bm25_params 的分段参数是硬编码的。5 个档位、5 组参数,全凭经验设定。这意味着它的最优性依赖于 mem0 的典型工作负载------如果 BM25 底层实现换了,或者文档语料的长度分布剧变,这些参数可能需要重新校准。硬编码的好处是零运行时开销,坏处是无法自适应。
还有一个容易被忽略的 Trade-off:词元计数的准确性 。get_bm25_params 用 lemmatize_for_bm25 的输出统计词元数,而 lemmatize 的 -ing 双保留策略会让词元数虚高。"attending" 贡献了 2 个 token("attend" 和 "attending"),但它本质上是一个语义单元。这意味着词元数可能被高估,导致选择了更激进的 midpoint(更偏右),Sigmoid 的中点被不必要地推高。在实践中,-ing 双保留只影响少数词元,偏差有限,但这是一个理论上的不完美之处。
小结
BM25 原始分不能直接加到语义分上,因为量级差异会让混合检索退化为关键词检索。Min-Max 归一化依赖批次数据分布,会被异常值绑架------一个 25 分的异常值能让其他 9 条记忆全部被压到 0.25 以下。其他候选方案(Z-Score、Tanh、Log、百分位)各有缺陷,无法同时满足值域有界、对异常值鲁棒、保留绝对匹配强度三个条件。
Sigmoid 归一化用预设的 midpoint 和 steepness,将 BM25 分映射到 0, 1,对异常值鲁棒,同时保留绝对匹配强度信息。它的数学结构天然保证了中间区间区分度最大、两端饱和------这与 BM25 分数在检索场景中的语义价值对齐。
查询长度自适应参数是整个设计的点睛之笔------它让 Sigmoid 的中点随查询词元数动态调整,确保短查询和长查询都能在 Sigmoid 的有效区间内获得有意义的区分度。词形还原(lemmatization)是 BM25 召回率的基石,而 -ing 双保留策略解决了 spaCy 上下文依赖的词形还原在短文本场景下的歧义问题。
代价是极端高分区间的区分度损失,硬编码参数的经验性,以及 -ing 双保留对词元计数的轻微膨胀。但在"量级可比"和"区分度保留"之间,这是 mem0 做出的务实选择。Sigmoid 不是最优雅的方案,但它是约束条件下的最优解------在工程中,这比优雅更重要。
至此,语义分、BM25 分、实体增强分三路信号终于可以在同一个量级上相加,初始排序的管线算是闭环了。但一个问题随之浮现:初始排序搞定了,为什么还需要二次精排?