一、引言:为什么需要哈希表?
在学习了红黑树并亲手封装出 map 和 set 之后,我们已经了解了 O(log N) 时间复杂度的有序容器。但现实世界中有大量场景不需要有序,只追求极致的速度------比如:
-
编译器的符号表查找
-
数据库的索引缓存
-
编程语言的字典/对象属性访问
-
去重、计数、频率统计
这些场景的核心诉求是:增删查改尽可能快,最好是 O(1)。
哈希表(Hash Table)正是为此而生。
二、哈希的核心思想:从"比较"到"映射"
2.1 两种查找哲学的对比

| 数据结构 | 查找方式 | 时间复杂度 | 核心操作 |
|---|---|---|---|
| 数组(有序) | 二分查找 | O(log N) | 比较大小 |
| 红黑树 | 二叉搜索 | O(log N) | 比较大小,旋转平衡 |
| 哈希表 | 直接定位 | O(1) 平均 | 哈希函数计算 |

本质区别:红黑树通过"比较"缩小范围;哈希表通过"计算"直接定位。
2.2 哈希函数:Key → 位置的桥梁

理想情况下,每个 Key 都有唯一的"座位"。但现实是:不同的 Key 可能算出同一个位置 ,这就是哈希冲突 。
三、哈希冲突:不可避免的挑战
3.1 冲突的本质

冲突不可避免,因为 Key 的空间远大于数组空间。我们能做的是:
-
设计好的哈希函数 → 让 Key 均匀分布,减少冲突
-
设计冲突解决方案 → 冲突了怎么办
3.2 负载因子:衡量冲突的标尺

| 负载因子 | 冲突概率 | 空间利用率 | 适用场景 |
|---|---|---|---|
| α → 0 | 极低 | 极浪费 | 几乎不用 |
| α = 0.5 | 低 | 较浪费 | 开放定址法 |
| α = 0.7 | 中等 | 平衡 | 开放定址法推荐值 |
| α = 1.0 | 较高 | 高效 | 链地址法常用值 |
| α > 1.0 | 高 | 满负荷 | 链地址法可接受 |

工程经验:
-
开放定址法:α 必须 < 1,通常控制在 0.7 以下
-
链地址法:α 可以 > 1 ,STL 控制在 1.0 左右,超过就扩容
3.3 直接定址法
当关键字的范围比较集中时,直接定址法就是非常简单高效的方法,比如一组关键字都在0,99之间,那么我们开一个100个数的数组,每个关键字的值直接就是存储位置的下标。 再比如一组关键字值都在a,z的小写字母,那么我们开一个26个数的数组,每个关键字acsii码-aascii码就是存储位置的下标**。也就是说直接定址法本质就是用关键字计算出一个绝对位置或者相对位置。**这个方法我们在计数排序部分已经用过了,其次在string章节的下面0J也用过了。
387. 字符串中的第一个唯一字符 - 力扣(LeetCode)

class Solution {
public:
int firstUniqChar(string s) {
int count[26] = {0};
for(auto ch:s)
{
count[ch - 'a']++;
}
for(size_t i = 0;i<s.size();++i)
{
if(count[s[i] - 'a'] == 1)
return i;
}
return -1;
}
};四、哈希函数设计:让分布更均匀
4.1 除法散列法(最常用)
h(key) = key % M
M 的选择是关键:
| M 的选择 | 问题 | 示例 |
|---|---|---|
M = 2^x |
只保留 key 的后 x 位,高位信息丢失 | 63 % 16 = 15, 31 % 16 = 15(冲突) |
M = 10^x |
只保留十进制后 x 位 | 112 % 100 = 12, 12312 % 100 = 12(冲突 |
推荐 :M 取不太接近 2 的整数次幂的质数。
为什么质数更好? 质数与任何数互质,取模后的余数分布更均匀,减少周期性冲突。
4.2 Java HashMap 的"位运算优化"(了解)
Java 的 HashMap 用 M = 2^n(方便位运算),但做了特殊处理:
// 不是直接 hash % M,而是让高位也参与
hash = hash(key) ^ (hash(key) >>> 16);
index = hash & (M - 1); // 等价于 hash % M,但用位运算更快核心思想 :即使 M 是 2 的幂,也要让 key 的所有位都参与计算,避免只取低位导致冲突。
4.3 非整数 Key 的哈希转换
哈希函数需要整数输入,所以必须转换:
// 默认:能强转 size_t 的直接转
template<class K>
struct HashFunc {
size_t operator()(const K& key) {
return (size_t)key;
}
};
// string 特化:BKDR 哈希算法
template<>
struct HashFunc<string> {
size_t operator()(const string& key) {
size_t hash = 0;
for (auto e : key) {
hash *= 131; // 乘质数,让每位都影响结果
hash += e;
}
return hash;
}
};BKDR 哈希的核心 :让每个字符的 ASCII 码都"层层叠加"影响最终结果,类似进制转换:

五、冲突解决方案一:开放定址法
5.1 核心思想
所有元素都存在哈希表数组内。冲突时,按照某种规则找下一个空位。

5.2 线性探测
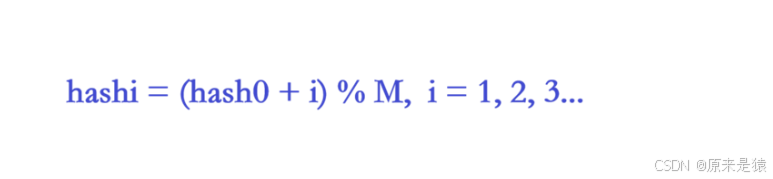
问题:群集/堆积(Clustering)
连续冲突的元素会形成"扎堆",导致后续插入都要跳过这一坨,效率急剧下降。

5.3 二次探测

跳跃式探测,缓解堆积:
-
i=1: hash0 ± 1
-
i=2: hash0 ± 4
-
i=3: hash0 ± 9
注意 :二次探测要求负载因子 < 1,否则可能找不到空位(探测序列可能覆盖不了所有位置)


5.4 开放定址法的核心难点:删除
为什么不能直接删除?

解决方案:状态标记
enum State {
EMPTY, // 从未插入过
EXIST, // 有有效数据
DELETE // 有数据但被删除了
};
5.5 开放定址法的局限性
| 问题 | 原因 |
|---|---|
| 删除复杂 | 需要 DELETE 标记,逻辑绕 |
| 堆积问题 | 冲突元素互相抢占位置,效率退化 |
| 负载因子受限 | 必须 < 1,空间利用率不高 |
| 扩容代价大 | 所有元素重新计算哈希位置 |
结论 :开放定址法适合小数据量、装载率低 的场景;大数据量场景下,链地址法更优。
六、冲突解决方案二:链地址法(拉链法)
6.1 核心思想
哈希表存指针,冲突的元素链成链表挂在同一个桶下。
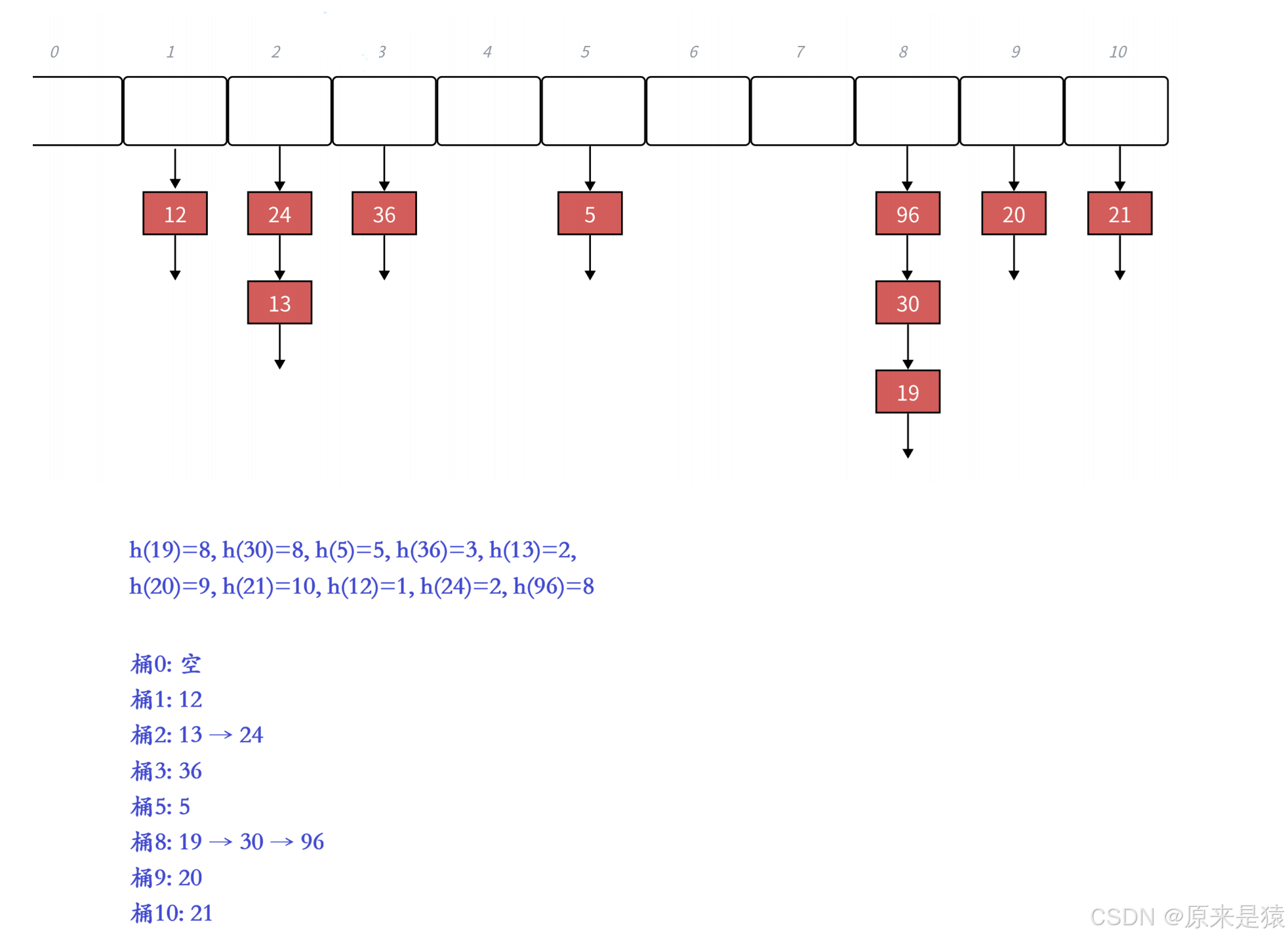
优势:
负载因子可以 > 1
删除简单(链表删除)
不会互相影响(每个桶独立)
扩容时只需移动指针,不用重新申请结点

6.2 数据结构
namespace hash_bucket {
template<class K, class V>
struct HashNode {
pair<K, V> _kv;
HashNode<K, V>* _next;
HashNode(const pair<K, V>& kv)
: _kv(kv), _next(nullptr) {}
};
template<class K, class V, class Hash = HashFunc<K>>
class HashTable {
typedef HashNode<K, V> Node;
vector<Node*> _tables; // 指针数组
size_t _n = 0; // 有效元素个数
};
} // namespace hash_bucket6.3 插入:头插法 O(1)
bool Insert(const pair<K, V>& kv) {
Hash hs;
size_t hashi = hs(kv.first) % _tables.size();
// 检查是否已存在
Node* cur = _tables[hashi];
while (cur) {
if (cur->_kv.first == kv.first) return false;
cur = cur->_next;
}
// 头插
Node* newnode = new Node(kv);
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
++_n;
return true;
}为什么头插? 新结点直接挂到链表头部,O(1) 操作,不需要遍历。
6.4 扩容:移动旧结点(关键优化)
// 负载因子 == 1 时扩容
if (_n == _tables.size()) {
vector<Node*> newtables(__stl_next_prime(_tables.size() + 1), nullptr);
for (size_t i = 0; i < _tables.size(); i++) {
Node* cur = _tables[i];
while (cur) {
Node* next = cur->_next;
// 重新计算在新表中的位置
size_t newhashi = hs(cur->_kv.first) % newtables.size();
// 头插到新表
cur->_next = newtables[newhashi];
newtables[newhashi] = cur;
cur = next;
}
_tables[i] = nullptr;
}
_tables.swap(newtables);
}关键优化 :不创建新结点,直接移动旧结点的指针。对比开放定址法需要重新申请内存,效率更高。
6.5 查找与删除
Node* Find(const K& key) {
Hash hs;
size_t hashi = hs(key) % _tables.size();
Node* cur = _tables[hashi];
while (cur) {
if (cur->_kv.first == key) return cur;
cur = cur->_next;
}
return nullptr;
}
bool Erase(const K& key) {
Hash hs;
size_t hashi = hs(key) % _tables.size();
Node* prev = nullptr;
Node* cur = _tables[hashi];
while (cur) {
if (cur->_kv.first == key) {
if (prev == nullptr) {
_tables[hashi] = cur->_next; // 头删
} else {
prev->_next = cur->_next; // 中间删
}
delete cur;
--_n;
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}6.6 析构:释放所有结点
~HashTable() {
for (size_t i = 0; i < _tables.size(); i++) {
Node* cur = _tables[i];
while (cur) {
Node* next = cur->_next;
delete cur;
cur = next;
}
_tables[i] = nullptr;
}
}七、两种方法的完整对比
| 特性 | 开放定址法 | 链地址法 |
|---|---|---|
| 存储结构 | 数组,元素直接存表里 | 数组+链表,表存指针 |
| 冲突处理 | 找下一个空位 | 链表挂在同一桶 |
| 负载因子 | 必须 < 1(通常 0.7) | 可以 > 1(通常 1) |
| 删除 | 复杂,需要 DELETE 标记 | 简单,链表直接删除 |
| 内存开销 | 预分配,可能浪费 | 动态分配,链表指针开销 |
| 缓存友好性 | 好(数据连续) | 差(链表跳跃访问) |
| 极端冲突 | 堆积严重,查找退化 | 链表过长,可转红黑树 |
| 扩容效率 | 重新申请+拷贝所有元素 | 移动指针,不重新申请 |
| STL 采用 | ❌ | ✅ unordered_map/set |
八、工程细节:质数表与扩容策略
8.1 为什么用质数表?
// SGI-STL 的质数表
static const unsigned long __stl_prime_list[] = {
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473, 4294967291
};不用 2 倍的原因:
-
2 倍可能是偶数、合数,取模分布不均匀
-
质数保证与大多数数互质,哈希值分布更均匀
8.2 扩容时机
| 方法 | 触发条件 | 新大小 |
|---|---|---|
| 开放定址法 | 负载因子 ≥ 0.7 | 下一个质数 |
| 链地址法 | 负载因子 ≥ 1.0 | 下一个质数 |