摘要
MateClaw v1.5.0 的核心不是简单增加几个功能入口,而是把 Agent 运行时里的三个关键状态结构化:目标从完成度评分变成 checklist 验收;LLM Wiki 从检索型知识库升级为可互联、可分层、可触发流水线的知识引擎;Memory 增加 owner/scope,支持多人使用时的记忆隔离。本文从设计思路、源码模块和运行截图三个角度拆解这次更新。

1. 为什么 v1.5.0 要改"运行时状态"
过去很多 Agent 系统的问题,不在于模型不会回答,而在于系统很难回答下面几个工程问题:
- 目标到底完成了吗,依据是什么?
- 知识库里的结论是否已经过期?
- 同一个 Agent 服务多人时,私人记忆会不会串台?
- 工具调用、文件生成、MCP 超时这些生产细节是否可控?
MateClaw v1.5.0 的更新主线可以理解成一句话:
把原来藏在 prompt、聊天记录和模型判断里的状态,尽量落成可查询、可迁移、可治理的数据结构。
这也是本版三个关键词的来源:
text
Checklist / Layers / Owner- Checklist:目标验收项;
- Layers:知识分层;
- Owner:记忆归属。
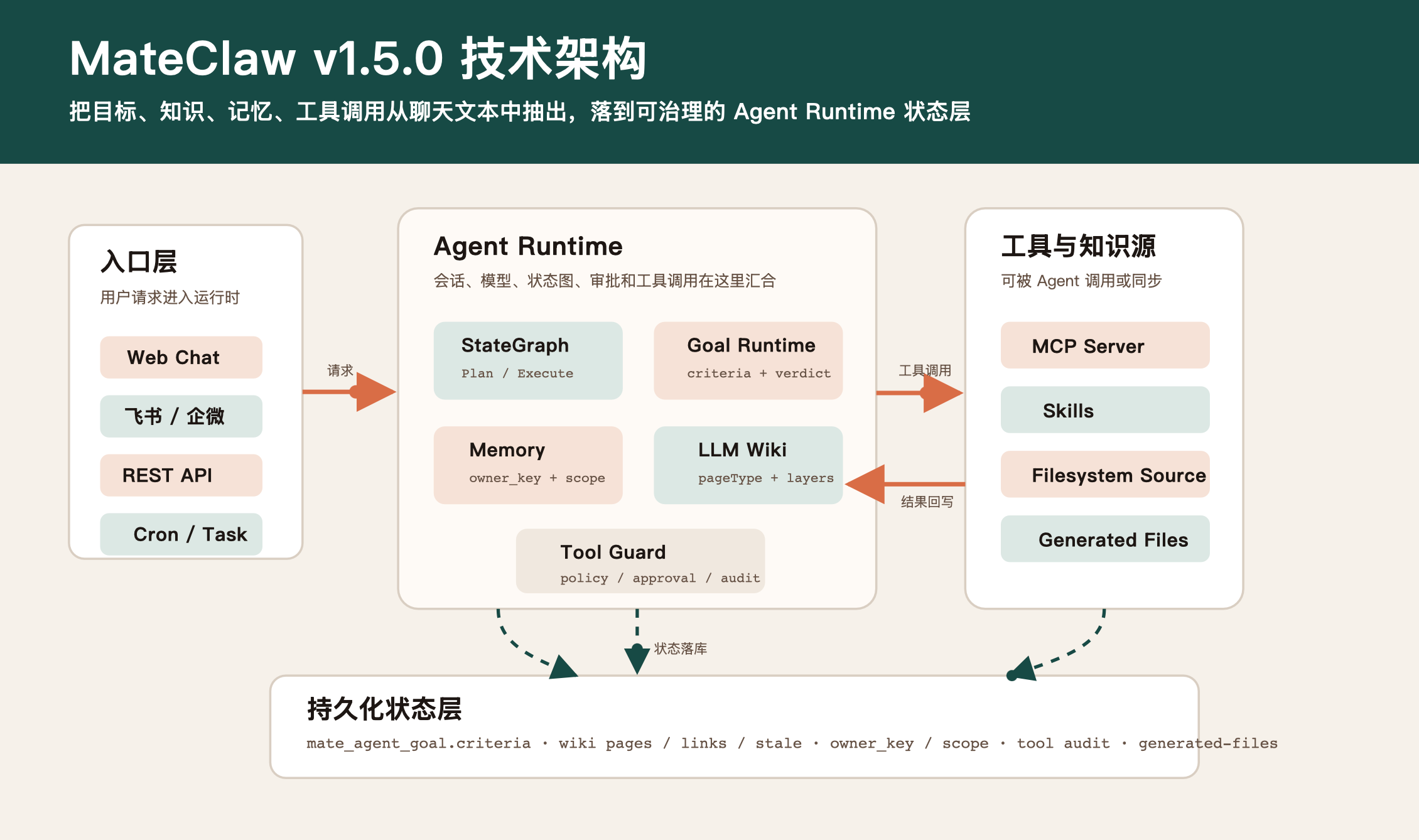
技术架构总览:入口、运行时、工具和状态层
从源码结构看,v1.5.0 的变化集中在几个运行时边界:
- 入口层:Web Chat、IM 渠道、第三方 API、Cron/Task 都会进入统一的会话与 Agent 执行链路;
- Agent Runtime:StateGraph / Plan-Execute 负责拆解与执行,Goal Runtime 负责目标状态,Tool Guard 负责工具策略和审批;
- 知识与记忆层 :LLM Wiki 维护页面、链接、分层、权限和流水线;Memory 通过
owner_key和scope做可见性隔离; - 工具层:MCP Server、Skills、Filesystem Source、Generated Files 都是 Agent 可触达或可同步的外部能力;
- 持久化状态层:Goal criteria、Wiki link/stale、Memory owner/scope、工具审计、生成文件等都从临时上下文变成可落库状态。
如果用更工程化的方式看,这一版不是单纯给 Agent 多塞上下文,而是把上下文拆成了几类可治理状态:
| 状态类型 | v1.5.0 的处理方式 | 技术价值 |
|---|---|---|
| 目标状态 | criteria、passed、evidence |
完成条件可验收 |
| 知识状态 | wikilink、fact/experience、stale |
关系和过期状态可追踪 |
| 权限状态 | pageType 权限、approval policy | 知识写入可治理 |
| 记忆状态 | owner_key、scope |
多人使用不串台 |
| 工具状态 | Tool Guard、MCP timeout、audit | 工具执行可控、可追溯 |
| 文件状态 | generated-files 落盘与保留期 | 生成结果不依赖进程内存 |
这也是 MateClaw v1.5.0 相比"聊天增强工具"更偏 Agent Runtime 的原因:它把运行过程中的关键判断从自然语言里抽出来,变成后端服务、数据库字段、工具策略和 UI 可见状态。
2. Goal Checklist:目标完成从"评分"变成"验收"
v1.4.0 已经支持持久化 Goal。用户可以给 Agent 设置目标,系统会记录目标状态、预算、LLM 调用次数,并在每轮之后进行评估。
但如果 evaluator 只返回一个 0~1 的完成度,系统仍然会遇到解释问题:
text
completionScore = 0.8这个 0.8 到底代表什么?
- 是文章写完了但没发布?
- 是发布了但没验证?
- 是测试没过?
- 还是模型认为"差不多"?
v1.5.0 通过 checklist 把这个问题拆开。
2.1 数据结构:Goal 里增加 criteria
Goal 不再只依赖标题、描述和完成分数,而是增加一组 criteria。
可以理解成:
json
[
{
"id": "C1",
"text": "文章正文已完成",
"passed": false,
"evidence": ""
},
{
"id": "C2",
"text": "本地构建验证通过",
"passed": false,
"evidence": ""
}
]对应到后端模块,核心逻辑集中在 goal 相关服务中,例如:
GoalServiceImpl:目标创建、状态更新、准则追加;GoalEvaluationService:目标评估;GoalCriteriaCodec:criteria 的序列化、解析、重排;GoalFollowupService:根据剩余准则生成自动跟进上下文;GoalController:提供目标相关 REST API。
这几个类的分工比较清楚:service 负责状态变化,codec 负责 criteria 数据处理,evaluation 负责模型裁决,controller 对外暴露接口。
更细一点看,Goal 这条链路大致是:
text
创建 Goal
-> 持久化 GoalEntity
-> 如果没有 criteria,首次评估进入 bootstrap
-> GoalEvaluationService 生成 checklist
-> GoalCriteriaCodec 规范化并写回
-> 后续每轮进入 verdict
-> 合并 passed / evidence
-> 全部通过后更新 status = completed这里的关键设计是"评估结果不直接等于完成状态"。模型只负责给出结构化裁决,最终完成状态由服务端根据 criteria 是否全部通过来确定。这样可以减少自由文本判断带来的不确定性。
2.2 Evaluator 两种模式
v1.5.0 的 evaluator 有两种模式:
| 模式 | 触发条件 | 输出 |
|---|---|---|
| bootstrap | 目标还没有 criteria | 拆出 checklist |
| verdict | 目标已有 criteria | 判断每条是否通过 |
bootstrap 模式解决"目标如何拆"的问题;verdict 模式解决"这条是否完成"的问题。
完成判定也更硬:
text
所有 criteria.passed == true
=> Goal completed这比单个完成度分数更适合真实工作验收。因为真实团队通常不是问"你觉得完成 80% 了吗",而是问"上线检查项都过了吗"。
2.3 API 与工具
v1.5.0 增加了两个比较实用的入口:
http
POST /api/v1/goals/{id}/criteria用于给进行中的目标追加一条准则。
同时也提供 Agent 工具:
text
addGoalCriterion这意味着目标清单不一定只能在创建时一次性确定。执行过程中,如果 Agent 或人发现遗漏项,可以追加验收条件。
2.4 auto-followup 变得更具体
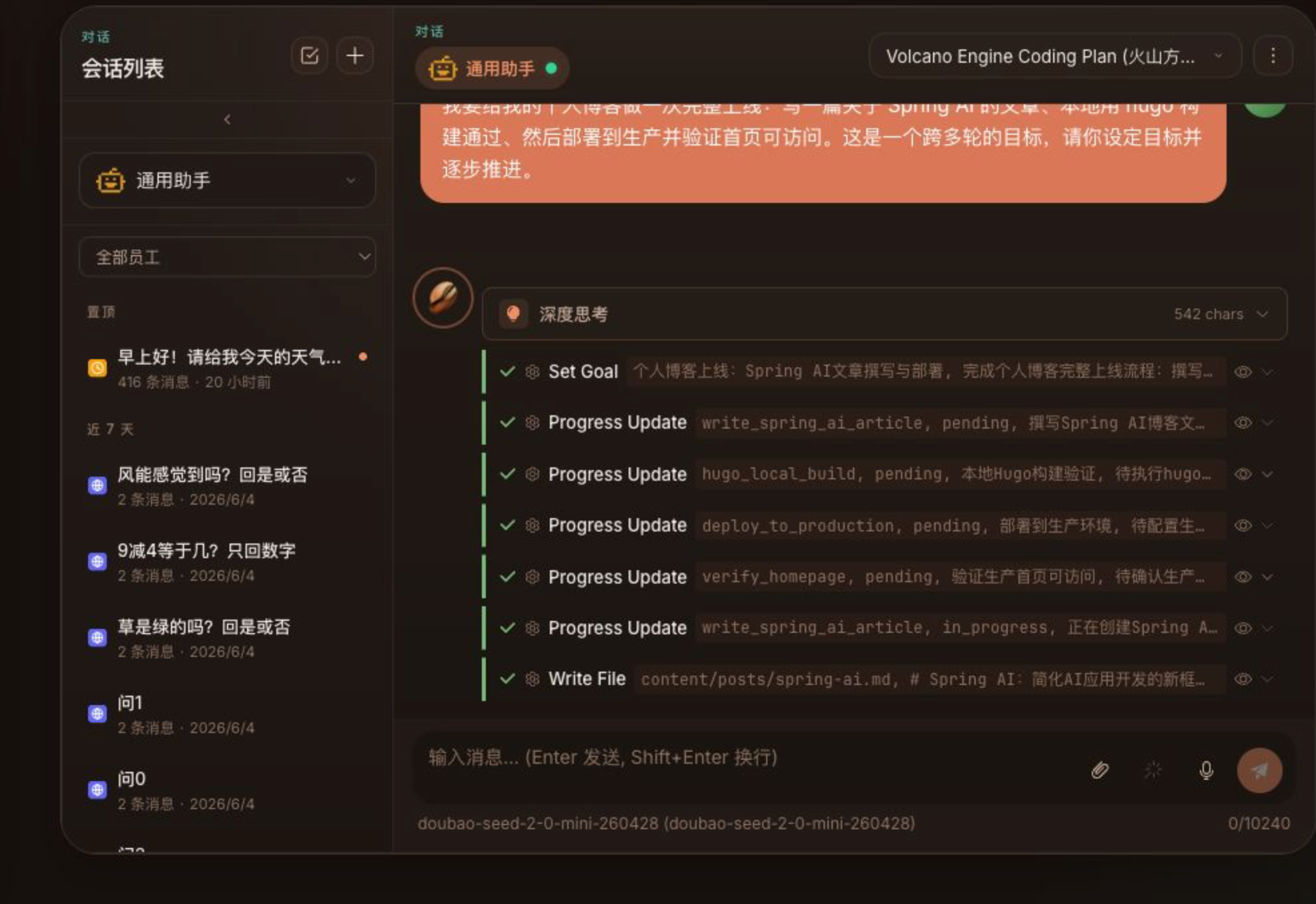
以前 auto-followup 可能只知道"目标还没完成"。现在它可以知道"还剩哪几条没完成"。
例如:
text
已完成:2/4
剩余:
- 部署到生产环境
- 验证首页访问这会直接影响下一轮 Agent 的上下文,使自动继续不再是泛泛地"继续做",而是围绕剩余准则推进。
3. LLM Wiki:不只是 RAG,而是知识运行层
很多知识库系统的核心是 RAG:上传文档、切块、向量化、召回。这个路线能解决"查资料",但不一定能解决"维护知识"。
MateClaw 的 LLM Wiki 在 v1.5.0 中继续往结构化知识运行层演进。

从工程实现上,LLM Wiki 的重点不是"多一种检索方式",而是把知识库拆成几种状态对象:
| 对象 | 作用 |
|---|---|
| Knowledge Base | 工作空间内的知识容器 |
| Wiki Page | 结构化页面,包含 slug、pageType、layer、metadata |
| Wiki Link | 页面之间的引用关系 |
| Stale Mark | 事实变更后对经验页的待复核标记 |
| PageType Profile | 页面类型、schema、模板和提示词配置 |
| Permission Rule | 某员工对某类页面的读写策略 |
| Pipeline Definition / Run | 页面事件触发的处理流程和运行记录 |
| Ingest Source | 外部知识源,例如文件系统目录 |
这些对象合在一起,才构成"自维护知识引擎"。如果只有向量召回,知识库很难知道页面之间是什么关系,也不知道哪些结论应该因为事实变化而复核。
4. Wikilink:页面关系进入系统
Wiki 页面支持两种链接写法:
markdown
[[target-slug]]
[[target-slug|显示文字]]关键点不在于语法,而在于维护逻辑:
- slug 优先解析;
- 不解析代码块和行内代码中的
[[...]]; - 页面改名时级联改写引用;
- 页面删除时清理引用;
- 坏链扫描结果持久化;
- 聊天回答中的 wikilink 可以跳转。
这让页面关系从"文本里看起来像链接"变成系统可理解的引用关系。
对长期知识库来说,坏链扫描和改名级联很重要。否则页面越多,知识关系越容易变成不可维护的文本碎片。
5. Fact / Experience:知识分层与失效传播
v1.5.0 把 Wiki 页面分成两类知识层:
| 层级 | 含义 | 例子 |
|---|---|---|
| fact | 基础事实 | 产品参数、接口定义、事故时间线 |
| experience | 总结经验 | 排障结论、复盘建议、最佳实践 |
经验页可以依赖事实页。一旦事实页更新,依赖它的经验页会自动标记为 stale。
这个设计解决的是企业知识库常见问题:
事实变了,但基于旧事实写出的结论还在被继续引用。
在 v1.5.0 中,系统开始显式记录这种依赖关系。事实更新后,经验页会进入待复核状态,wiki_stale_pages 工具可以列出这些页面。
这比单纯"重新向量化文档"更接近知识维护。
6. PageType Profile:让不同类型页面有不同结构
LLM 生成 Wiki 页面时,如果完全自由发挥,页面结构很容易不稳定。
v1.5.0 引入 pageType profile。一个知识库可以定义多种页面类型,例如:
- 概念;
- 教程;
- 决策记录;
- 产品说明;
- 事故复盘;
- 操作手册。
每种 pageType 可以配置:
- schema;
- route 阶段提示词;
- create 阶段提示词;
- merge 阶段提示词;
- Markdown 模板;
- 元数据校验状态。
这相当于把"这类知识应该长什么样"从 prompt 习惯变成知识库配置。
7. PageType 权限:知识写入也需要治理
知识库一旦允许 Agent 写入,就必须面对权限问题。
v1.5.0 的 pageType 权限可以按以下维度配置:
text
员工 + 知识库 + 页面类型控制项包括:
- read;
- create;
- update;
- delete;
- writePolicy。
writePolicy 有三种:
| 策略 | 含义 |
|---|---|
| allow | 直接允许 |
| approval_required | 需要审批 |
| deny | 禁止 |
这里有一个值得注意的设计:写权限一旦开始配置规则,未匹配页面类型默认拒绝写入。
也就是说,系统默认兼容旧行为;但当管理员开始收紧某个 KB 后,它会进入更保守的 fail-safe 模式。
这对企业内部知识库是合理的。因为"少写一点"通常比"错误写入敏感页面"风险更低。
8. Wiki Pipeline:知识变化后自动处理
v1.5.0 新增 Wiki Pipeline,用于让知识库在页面事件发生后自动触发处理流程。
触发器包括:
page_type_count:某类页面数量达到阈值;page_created:新页面创建;stale_marked:页面被标记待复核。
步骤执行器包括:
llm:调用模型处理;skill:调用受限技能。
每次运行和每一步都有持久化记录,并通过 (definition, trigger, subject, bucket) 去重,避免同一事件重复执行。
从工程角度看,Pipeline 让 Wiki 从"被动查询"变成"状态变化后可自动处理"。比如:
- 新增一批事故复盘后自动生成月度总结;
- 某类页面达到数量阈值后自动整理索引;
- 经验页 stale 后触发复核任务。
9. Ingest-Source SPI:知识源可插拔
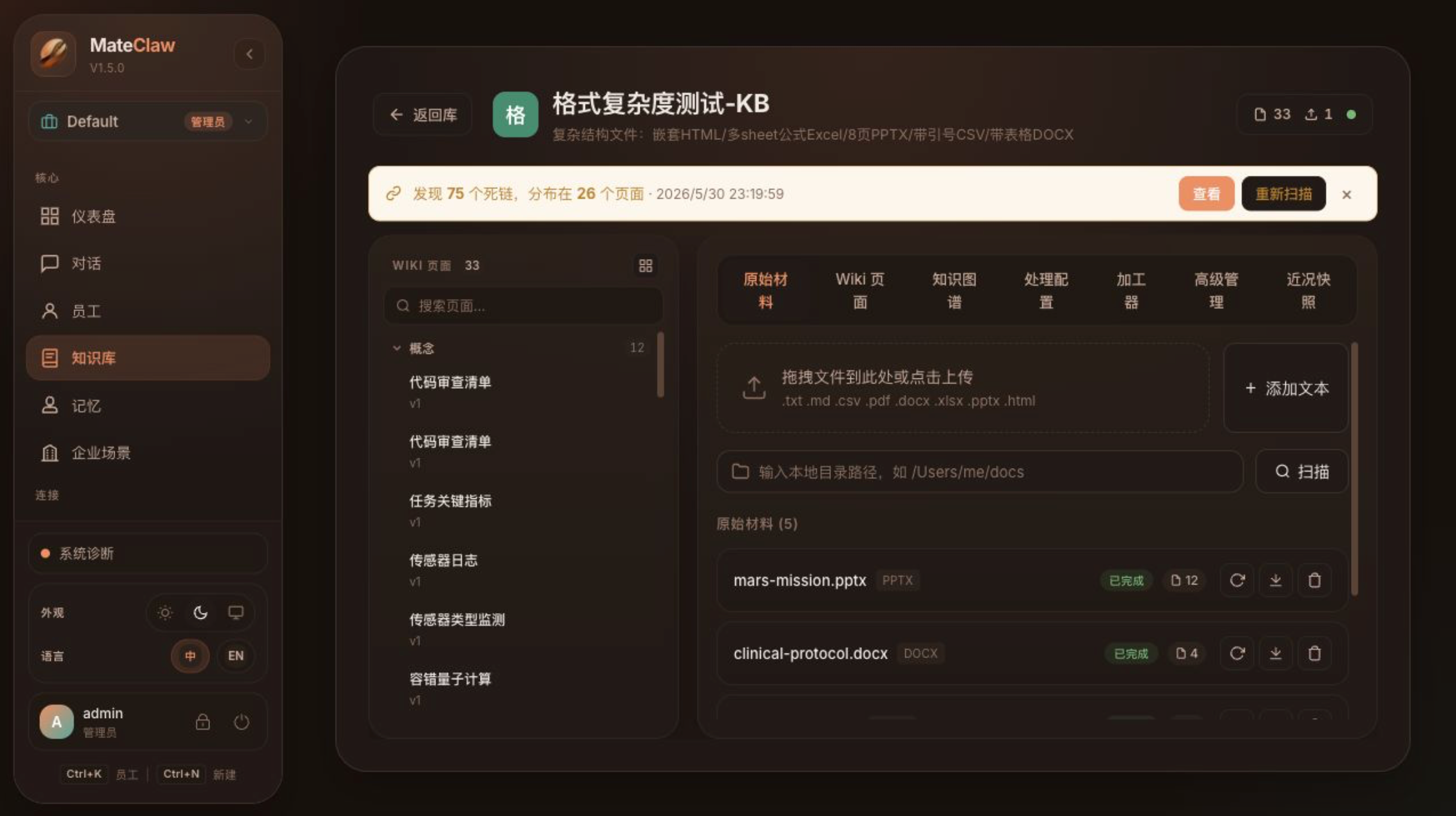
v1.5.0 把知识源做成 SPI,内建文件系统实现。
配置 source_directory 后,知识库可以同步指定目录里的文件。同步过程支持:
- 定时扫描;
- 内容哈希检测;
- 只处理新增或变更文件;
- 文本和二进制文件检测;
- 多节点调度锁;
- watcher 状态查询;
- 手动 scan。
安全上,生产环境路径策略是 fail-closed:
- 规范化路径;
- 解析软链;
- 允许根目录白名单;
- 空白名单默认拒绝。
这适合团队文档目录、项目资料目录、内部手册等场景。
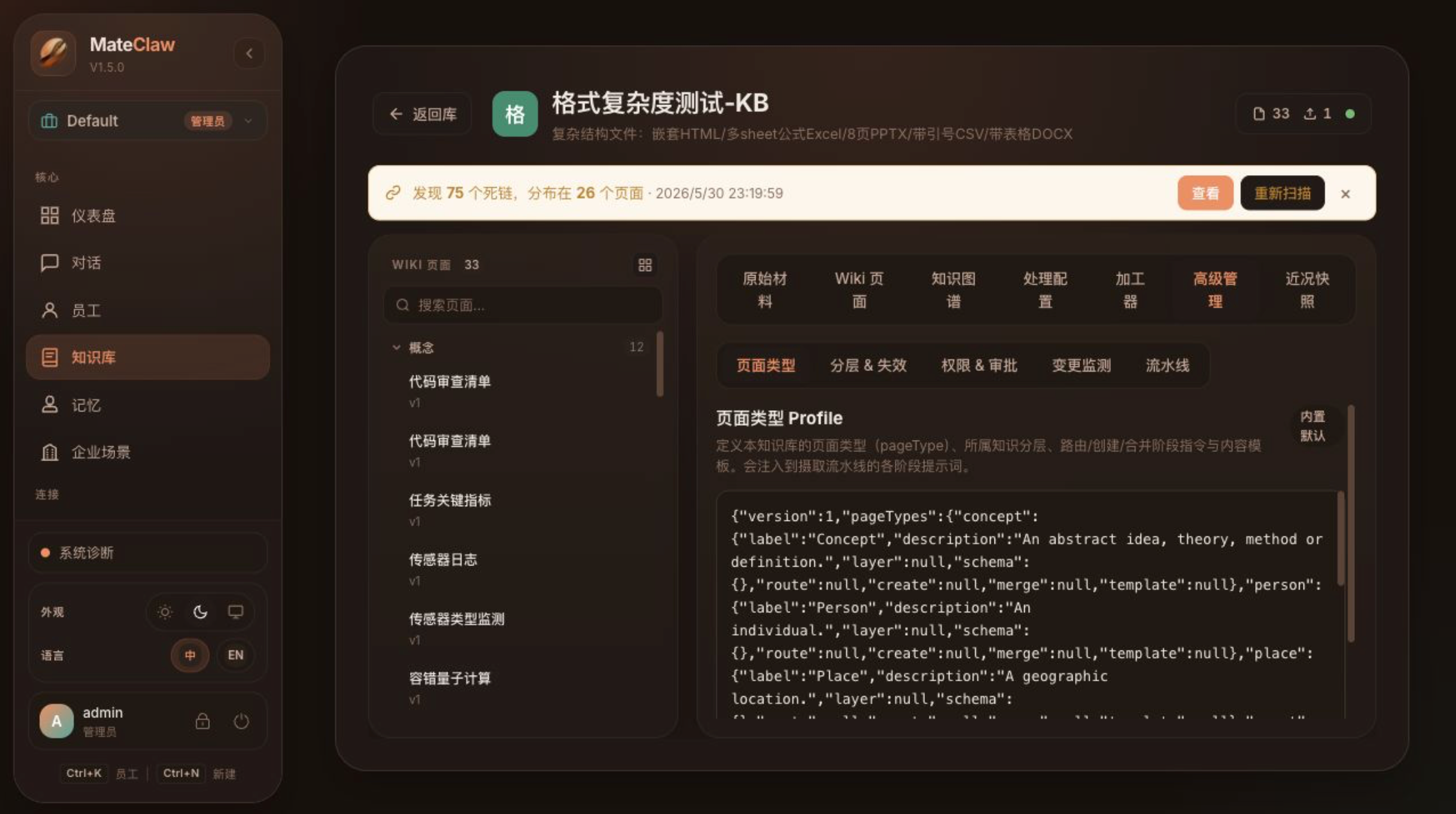
10. Memory per-owner:长期记忆需要"认人"
Agent 如果只服务一个人,记忆可以简单一点。但如果一个 Agent 服务一个团队,记忆隔离就很关键。
v1.5.0 给记忆加了两个概念:
text
owner_key
scopeowner_key 表示"这条记忆属于谁":
| 来源 | owner_key |
|---|---|
| Web 控制台 | user:<用户id> |
| IM 渠道 | <渠道>:<发送者id> |
| 第三方 API | api:<endUserId> |
| 系统任务 | system |
scope 表示"谁能看到":
| scope | 含义 |
|---|---|
| PERSONAL | 个人可见 |
| TEAM | 团队可见 |
| GLOBAL | 全局可见 |
这样,同一个 Agent 可以给多人使用,但每个人的私人记忆只按自己的 owner_key 召回。
第三方 API 的请求体也新增了可选字段:
json
{
"message": "帮我总结今天的工作",
"endUserId": "user-001"
}一个 PAT 接入方可以代表一个 MateClaw 用户调用接口,但不同终端用户通过 endUserId 进行记忆隔离。
迁移层面,历史数据会回填为 TEAM,避免升级后旧记忆突然不可见。随发行版打包的配置中,记忆隔离默认开启。
这条链路的关键是 owner 归一,而不是简单地给不同渠道写不同文件。可以把它理解成:
text
请求来源
-> 解析用户身份
-> 归一成 owner_key
-> 写入 PERSONAL / TEAM / GLOBAL
-> 下一轮对话按 owner_key + scope 过滤召回这样做的好处是 Web、飞书、企业微信、第三方 API 走的是同一套记忆可见性模型。渠道只是 owner 的来源之一,不会把记忆隔离逻辑散落在每个 channel adapter 里。
11. 主知识库:减少工具调用歧义
v1.5.0 支持为每个员工绑定主知识库。
这个绑定不是独占关系。知识库仍然是工作空间共享资源。
它的作用是:
text
如果 wiki 工具调用没有显式传 kbId / kbName
=> 默认使用该员工的 primary_kb_id这能减少工具调用时的歧义。尤其是一个工作空间里有多个知识库时,Agent 不需要每次都猜"应该写到哪个 KB"。
12. 模型选择链路:偏好提供商进入主路由
v1.5.0 调整了模型选择优先级:
text
会话钉选模型
> Agent modelName
> 全局默认模型
> 偏好提供商路由偏好提供商路由还会看技能声明的模型能力。例如某个技能需要 vision 能力,系统会优先选择满足能力要求的 provider。
本版还新增 Claude Opus 4.8 / Opus 4.8 Fast 模型条目,覆盖 Anthropic、OpenRouter 和 Claude Code OAuth 通道,并支持 xhigh thinking tier。
注意:这些模型条目不会自动成为默认模型,需要管理员显式指定。
13. 生产可靠性改进
v1.5.0 还修复了一批真实使用中容易遇到的问题。
13.1 生成文件落盘
工具生成的文件现在落盘到:
text
data/generated-files/默认保留 7 天,6 小时定时清理。
这解决了服务重启后生成文件下载链接失效的问题。前端也增加了下载拦截,失效时提示 toast,不再让 SPA 卡住。
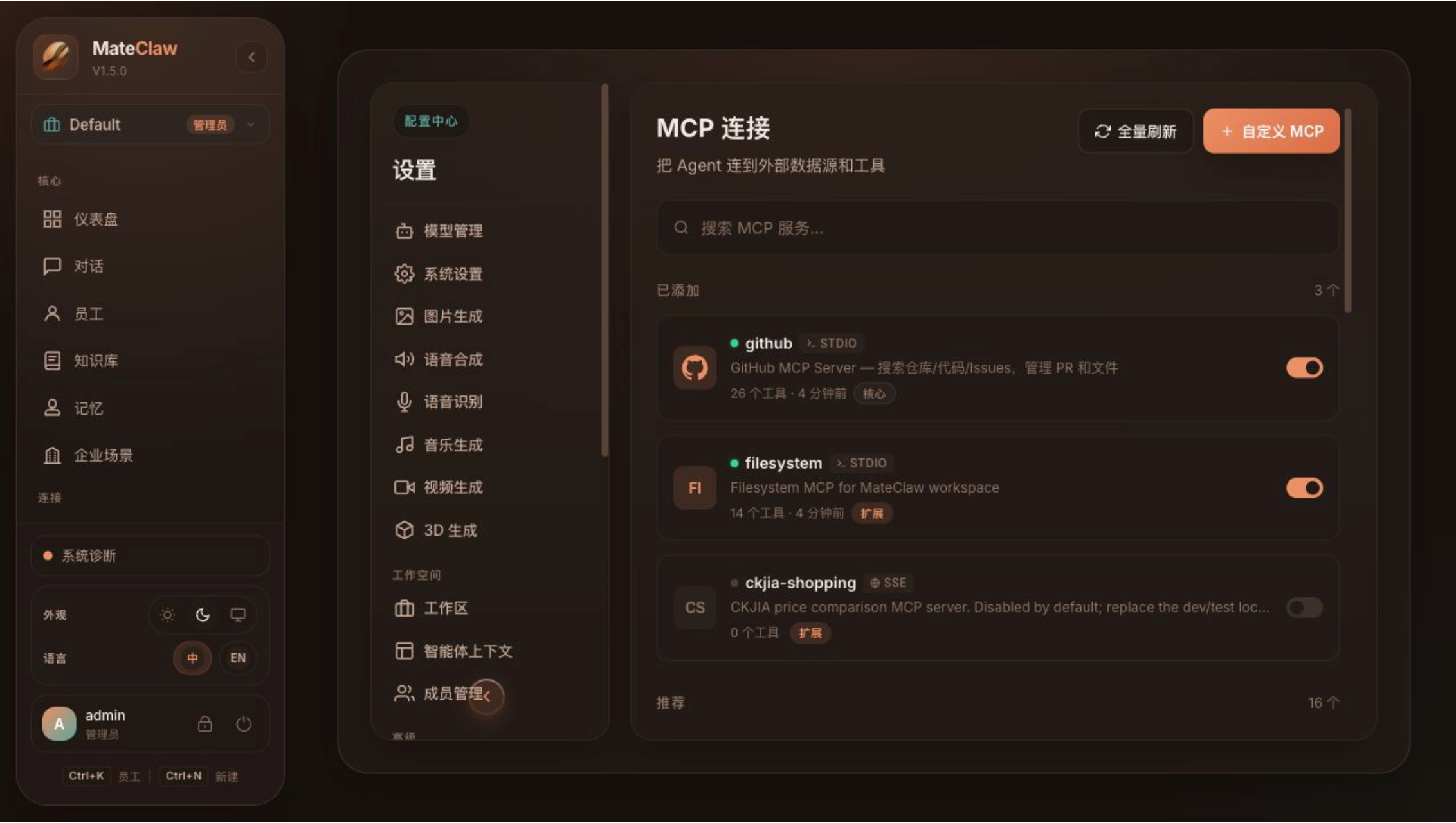
13.2 MCP 超时默认 60 秒
MCP 工具读超时从 30 秒调整为 60 秒。
对需要联网、读仓库、跑文件处理的 MCP 工具来说,30 秒经常偏短。新默认值更接近生产场景,同时每个 MCP 服务仍可单独配置。
这类改动看起来小,但对 Agent Runtime 很关键。因为工具调用通常是 Agent 从"回答问题"进入"执行任务"的边界。边界上的默认超时、错误分类、审计和审批策略如果不稳,Agent 的可用性会被工具层拖垮。
13.3 入站媒体管线
微信和企业微信已接入统一入站媒体管线:
- 媒体下载;
- magic-byte 类型识别;
- 指数退避重试;
- 按内容字节判断文件类型。
这比只看 MIME 声明更稳,尤其是 IM 平台上传文件时类型声明不稳定的情况。
13.4 飞书最近文件跟进
飞书场景里,用户经常先发一个文件,再补一句"帮我看下这个"。
v1.5.0 会缓存最近文件,并在后续文本消息中自动带上这些文件作为内容片段。
规则是:
text
每个聊天最多 5 个文件
TTL 60 分钟13.5 DashScope 与 Plan-Execute
DashScope 工具调用修复主要包括:
- 避免
search保留字导致请求被拒; - 错误分类更精确;
- 非法工具名不再误判为模型不可用。
Plan-Execute 的拆解判据也做了调整:是否拆成多步,更看任务是否有多个独立子任务,而不是只看难度。
14. 升级注意事项
v1.5.0 与 v1.4.0 配置兼容。已有内容会保留:
- agent;
- skill;
- wiki;
- channel;
- cron;
- workflow;
- trigger;
- goal。
新增 schema 由 Flyway 自动迁移。
升级时建议关注:
| 项目 | 行为 |
|---|---|
| 现有 Goal | 保持旧逻辑;新 Goal 使用 checklist |
| Memory | 默认开启 owner/scope 隔离;历史数据回填 TEAM |
| Wiki 权限 | 未配置规则时保持开放;配置后写入更保守 |
| Source watcher | 只有配置后才扫描 |
| MCP 超时 | 旧记录保留原值;新建默认 60 秒 |
生产环境如果启用本地目录知识源,建议配置允许根目录,避免扫描范围不可控。
15. 小结
MateClaw v1.5.0 的技术价值,不在于"又多了几个功能",而在于它把 Agent Runtime 的关键状态继续结构化:
- Goal checklist:目标完成可验收;
- LLM Wiki layers:知识变化可追踪;
- PageType permission:知识写入可治理;
- Wiki Pipeline:知识事件可处理;
- Memory owner/scope:多人使用不串记忆;
- 生成文件、MCP、IM 管线:生产细节更稳。
如果说 v1.4.0 解决的是"Agent 能围绕目标持续工作",那么 v1.5.0 解决的是"这种持续工作如何被验收、被治理、被多人安全使用"。