高可用之路-闲聊监控指标的局限
前言
在我和GPT探讨了很多天的人生之后,他终于说动了我,让我开启迟迟不想动笔的高可用系列。感谢GPT们让我从大量繁琐技术文档中解放出来,让我有时间进行真正的思考。写博客对我来说最大的收益是强制自己思考,如果连博客本身都被GPT代劳,那还不如不写。所以本文文字AI含量基本为0,纯手敲,顶多听取了一些AI在文字表达上的建议。
为什么首先聊监控指标
作为高可用系列的第一篇。一开始我是想写一个非常宏大的体系大纲,但一方面我还没想好怎么设计,另一方面我觉得首篇只抛一个框架出来其实有点空泛。所以我就先写一点实际的,也是我这几年认识比较深刻的地方吧。熟悉我的人都知道,我非常喜欢troubleshooting,这几年令我印象深刻的问题都是对于监控指标的解读出了问题,所以在高可用这一块认识监控指标的局限性其实是非常重要的,毕竟监控是我们的眼睛:)
监控指标反映的只是真实的投影
监控指标通常是展示采集的数据(Count/Guage等)或对采集的数据运算(QPS/TPS等)。例如我们最常见的指标QPS,其含义是平均一秒内有多少次请求。其公式就是:
ini
QPS=请求总数/总时间这么简单的一个公式其实就蕴含着不小的复杂性。 在公式的分子上-请求总数就很有说法,这个请求总数是分布在一台机器上还是在多台机器上。用总数来表达其实就丢失了空间上的分布信息,从向量坍缩成了标量,是一种投影,如下图所示:
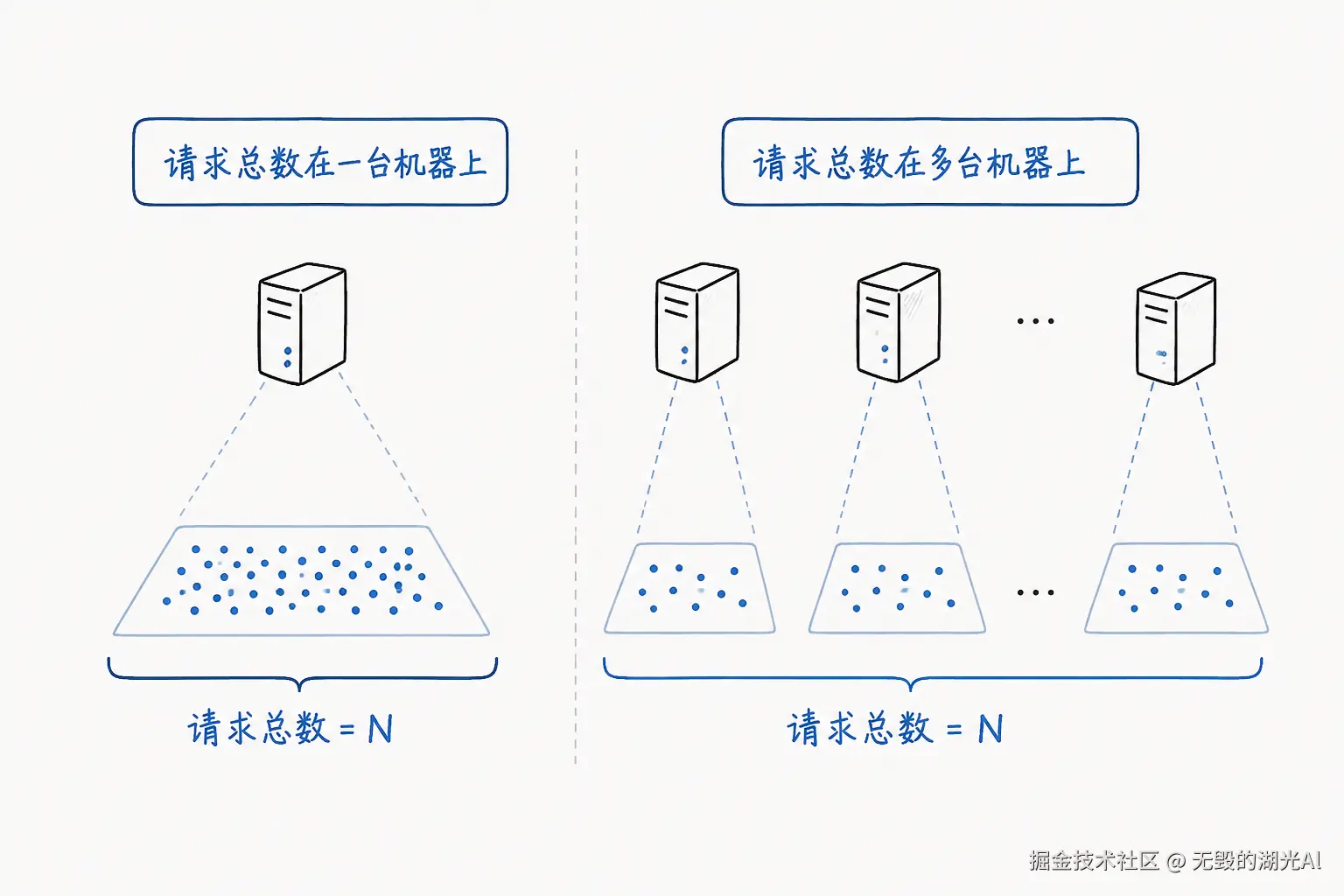
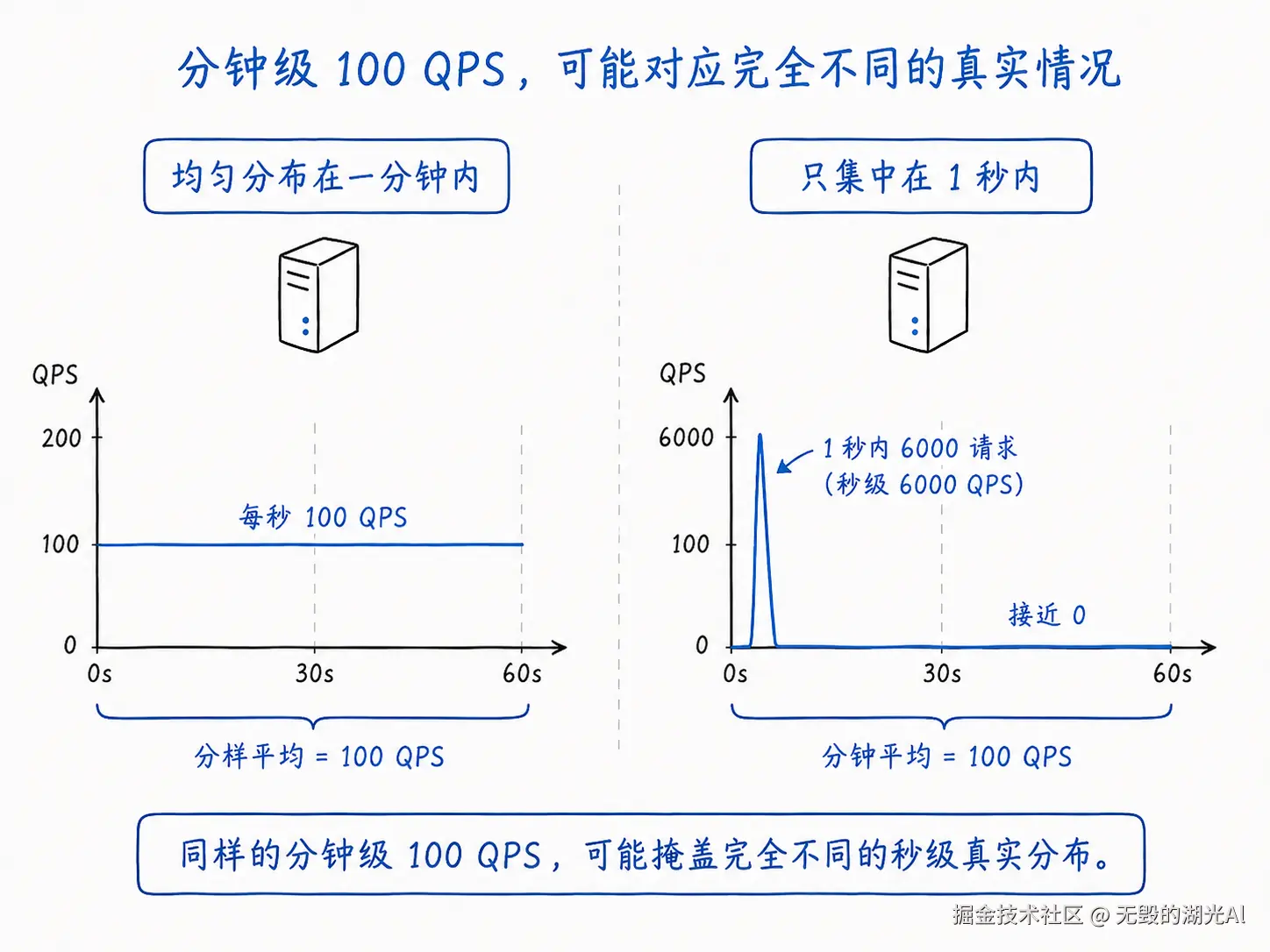
在公式的分母上-总时间这个也有说法,很多监控系统都做不到秒级监控而是分钟级,那么100qps可能是均匀的分布在一分钟之内(秒级100)也有可能是仅仅只分布在一秒(秒级6000)内。用60s来计算其实就丢失了时间上的分布信息,又是从向量坍缩成了标量,又是一种投影,如下图所示:
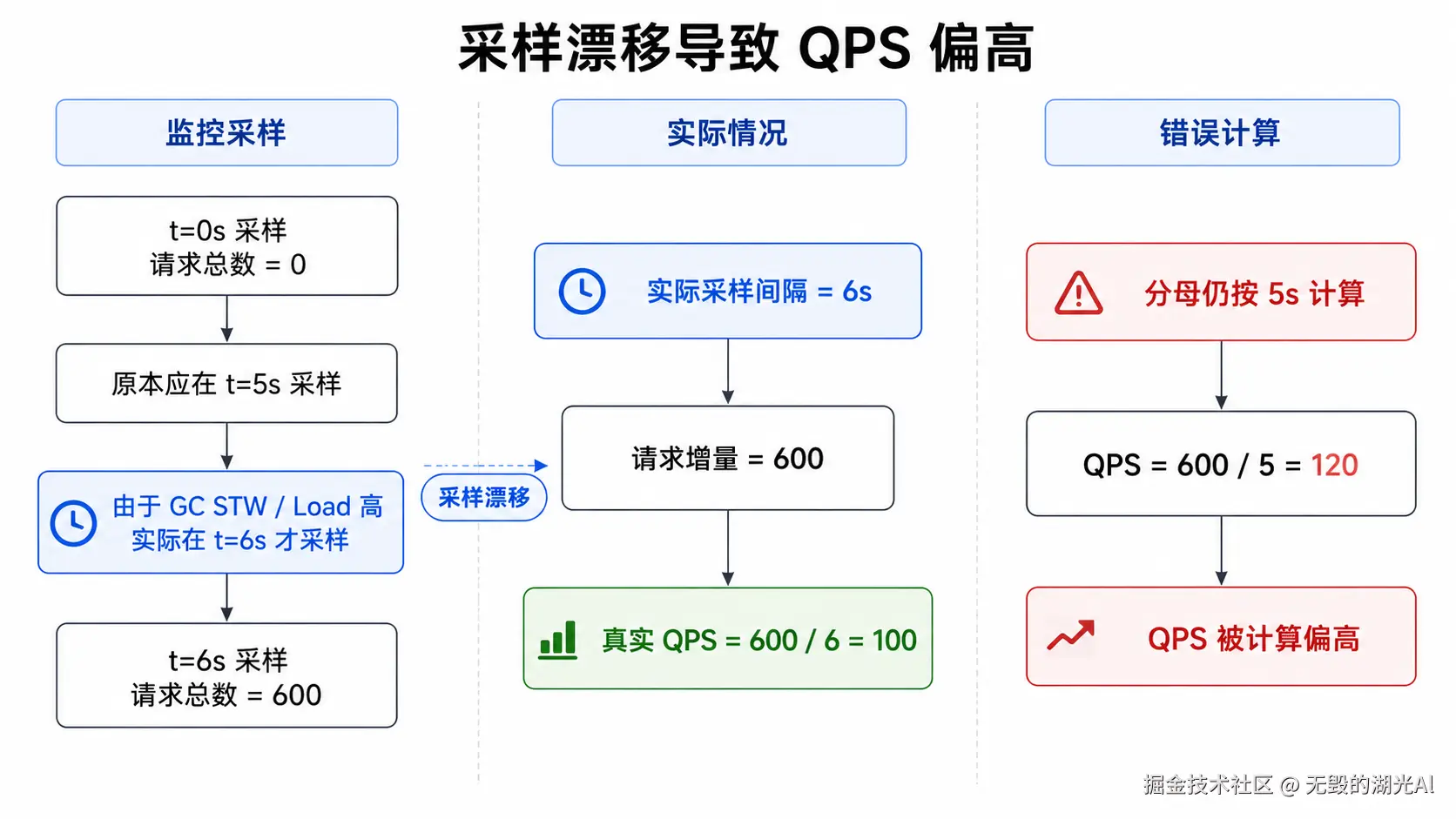
在公式的分母上-总时间其实还有其它的变化。例如,监控系统每5s采样一次计算出请求总数。但是监控系统本身由于GC的STW或者load高等原因并不是5s精确采样,而是漂移到第6s。但分母依旧是用5s来进行计算,那么毫无疑问,QPS会被计算的偏高,如下图所示:
为了避免这种现象,我们的公式可以修改为:
ini
QPS=请求总数/时间差如果这个时间差的计算采用墙上时钟(也就是WallClock),那么会由于和NTP授时同步的时候由于时钟跳变(往前或往后拨数秒)而导致QPS的运算出现偏差,如下图所示:
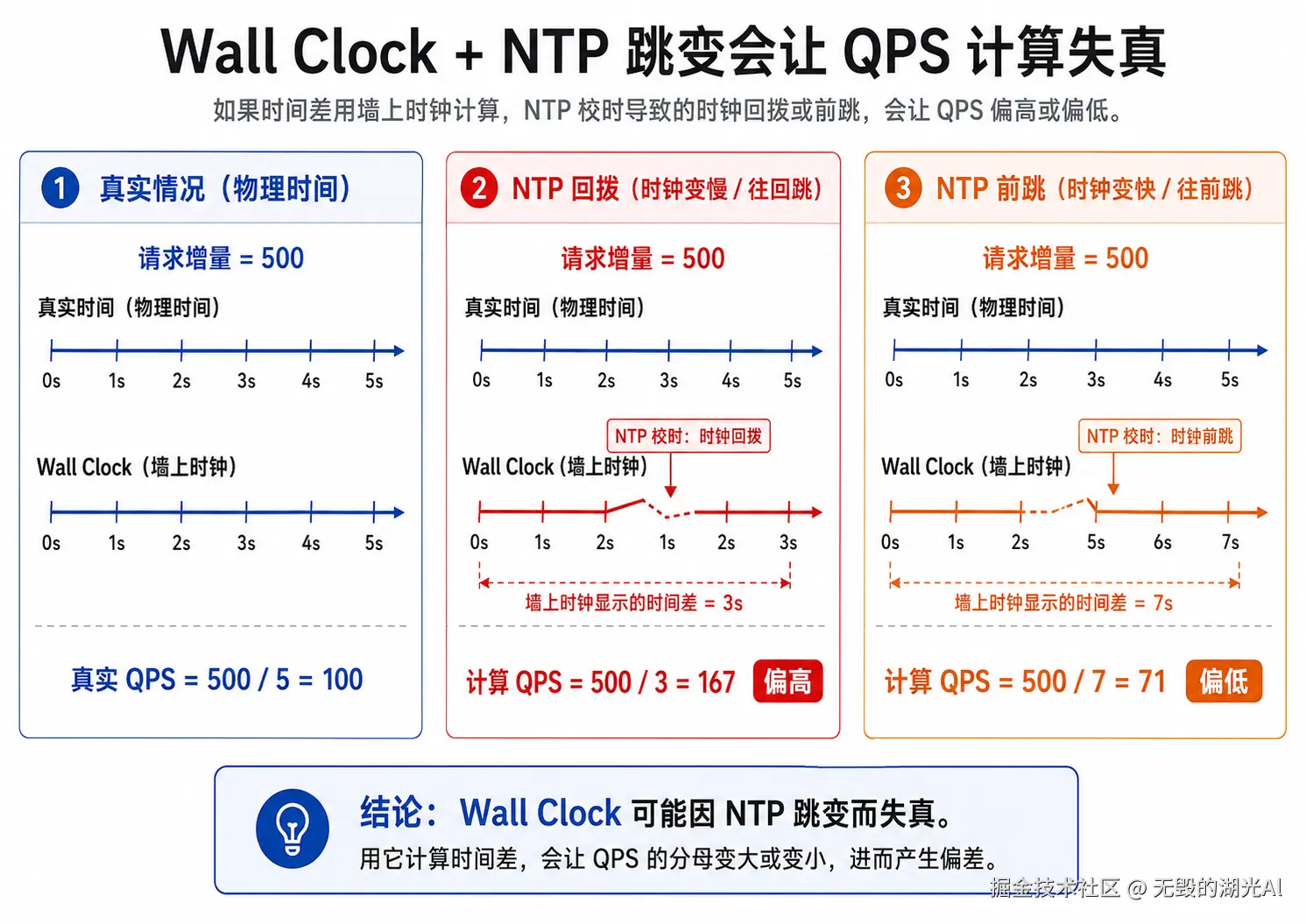
所以我们需要使用monotonic clock(单调时钟来进行计算)。但即使是如此,也无法保证采样任务一定在精确的5s后运行。
请求总数丢失了空间分布,总时间丢失了时间分布。一旦做了 QPS 这个运算,原本"机器维度 × 时间维度"的二维矩阵,就被压缩成了一个标量。这个标量当然有用,但它已经不是系统真实运行过程本身,它只是真实的投影。
监控指标无法衡量超出它精度的真实
那么如果仅仅只记录数据本身而不做计算是不是能够精确的反映系统的运行过程呢。有时候也不行,因为数据本身是有精度的,超过这个数据的精度能表达的上限依旧无法反映真实。例如我们最常用的主从延迟指标Seconds_behind_master,它的精度是秒。无论监控如何踩点,它的原始数据只有0/1/2等整数,例如下图所示:
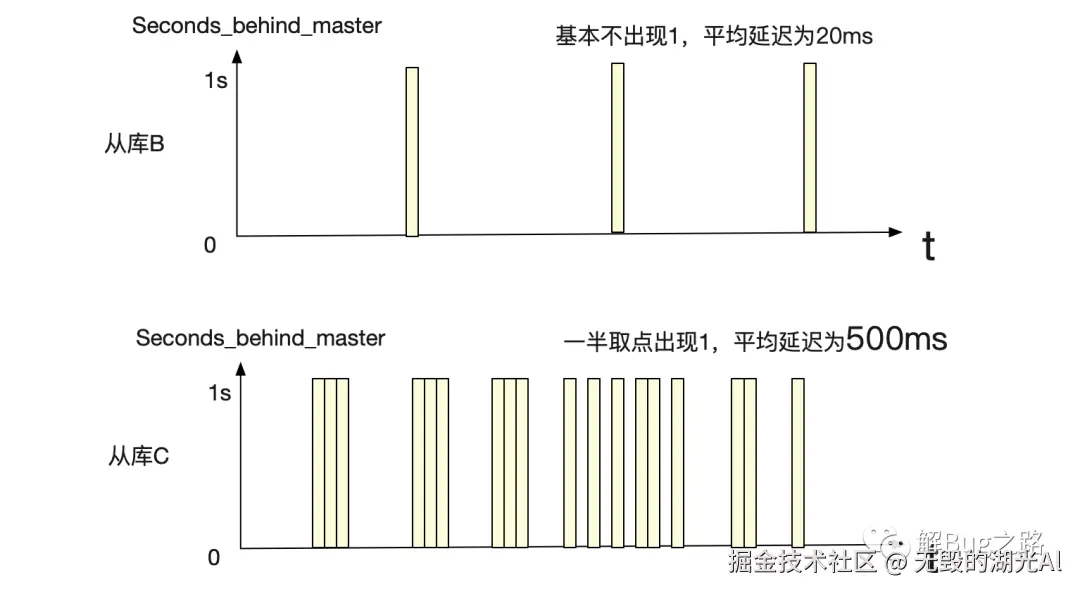
笔者就遇到过这样的现象,两个一模一样的从库,一个从库采样取点基本是0,看上去去平均延迟为20ms,另一个从库一半的取点为1,看上平均延迟为500ms。实际这两的主库延迟是基本一样的,远没有(500-20)=480ms这样的差距。这其实就和Seconds_behind_master精度只到秒有关。
让我们自己观察一下Seconds_behind_master的计算公式:
ini
long time_diff= ((long)(time(0) - mi->rli->last_master_timestamp) - mi->clock_diff_with_master);关键点在于这个clock_diff_with_master。这边需要先引入一个容易被忽略的常识,那就是不同机器的时间戳是不一致的。所以我们在计算Seconds_behind_master的时候需要去掉时间戳不一致的影响,也即减去clock_diff_with_master。这个clock_diff_with_master的精度也是秒,那么在处理毫秒为单位的时间戳的时候势必存在精度损失。同时这个clock_diff_with_master只会在主从连上的那一刻只计算一次。计算完之后,这个精度损失导致的数据差距会一直存在!
例如,我们假设在计算clock_diff_with_master的那一瞬间。从库的clock是0.5s,主库的clock是1.0s,那么他们的时间差就会由于精度的原因从0.5s放大到1s(MySQL源码中会进行四舍五入)。而这0.5s就会导致实际主从延迟为0的从库在监控指标看来是500ms。计算过程如下图所示:
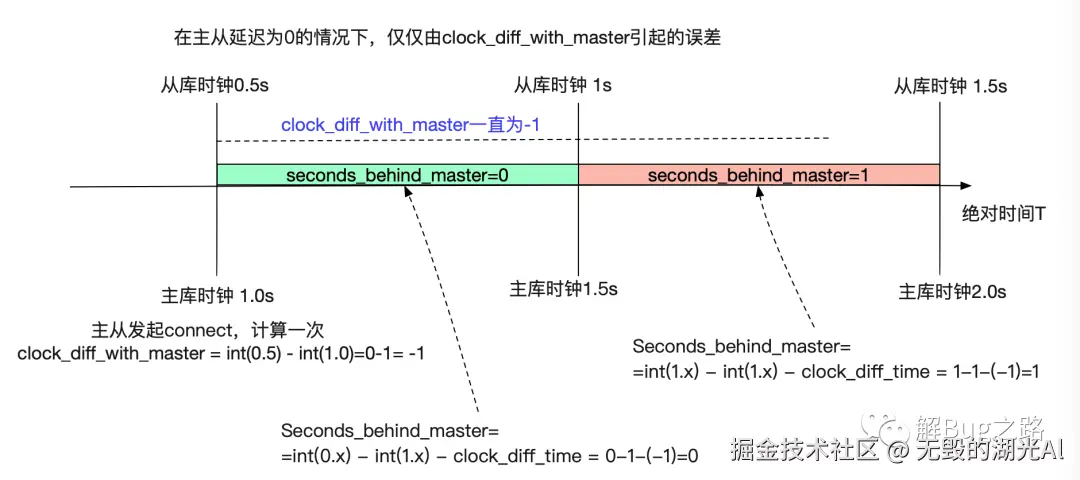
在上图中我们可以看到,在我们取从库时钟[0.5,1.5)这个1s的时间段范围内。在前0.5s,也就是[0.5,1)这个区间中我们计算出来的Seconds_behind_master是-1然后由MySQL源码强行校正为0,而在[1,1.5)区间计算的确是1 。那我们的平均值就可以计算出来为(0.5*0+0.5*1)/(1.5-0.5)=0.5=500ms!
从上面这个例子就可以看到,用只有秒级的监控指标来观测毫秒级的主从延迟差距完全没有意义,Seconds_behind_master这个指标只能反映秒级的变化。它只能回答"有没有秒级延迟"这个问题,不能拿来回答"有没有几百毫秒延迟"这个问题。指标一旦被拿去回答超出它表达精度的问题,就会从工具变成误导。如果想看详细的分析,可以看笔者之前的文章:
arduino
https://mp.weixin.qq.com/s/YBLxEPbaNAYxjUYGhmIl_g监控指标无法突破采集环境的边界
那么如果我拥有无限的精度能否精确的反映系统的运行过程呢?有时候也不能做到,因为指标是在环境中采集的,环境本身限制了它的表达。例如在容器中cpu busy的计算是 :
css
容器运行的时间/总时间
注:实际可能是
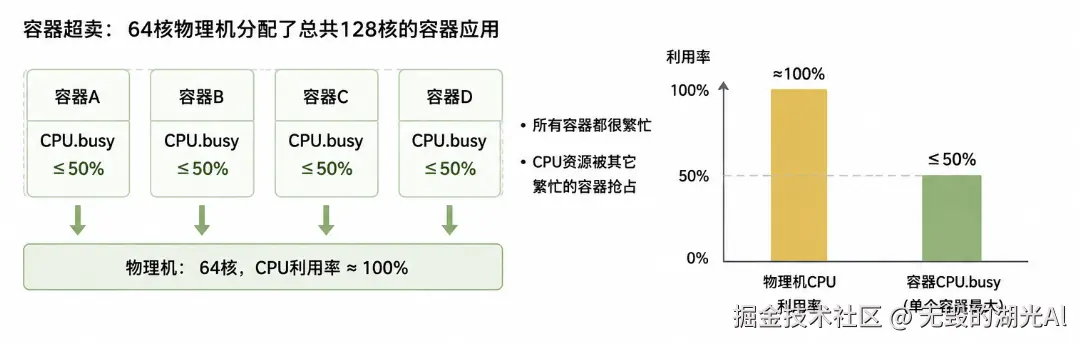
CPU.busy = (cpuacct.usage(T秒) - cpuacct.usage(T-5秒))/((5秒)*CPU核数)如果容器中监控指标CPU.busy=50%就认为系统还处于健康水位就很有可能被误导。在容器超卖(例如64核的物理机分配了总共128核的容器应用)。在所有应用都很繁忙的情况下,容器中的CPU.busy最多只能达到50%就被其它繁忙的容器抢占。物理机CPU利用率可能已经到了100%,而容器的CPU只能到50%。如下图所示:
那如果我在物理机上直接采集机器指标那么是不是就完全准确呢?也不一定,以x86为例,会有一些SMM(System Management Mode)中断,一旦进入了这种中断(一般是温控/ECC检查/电源管理等),Kernel会被强行block,完全感知不到,那么Kernel管理的user/system time都不会有变化。但可能真实时间已经100ms过去了,唯一的感觉可能只有应用的超时报错,但仅仅从Kernel本身的监控完全不知道发生了什么,如下图所示:
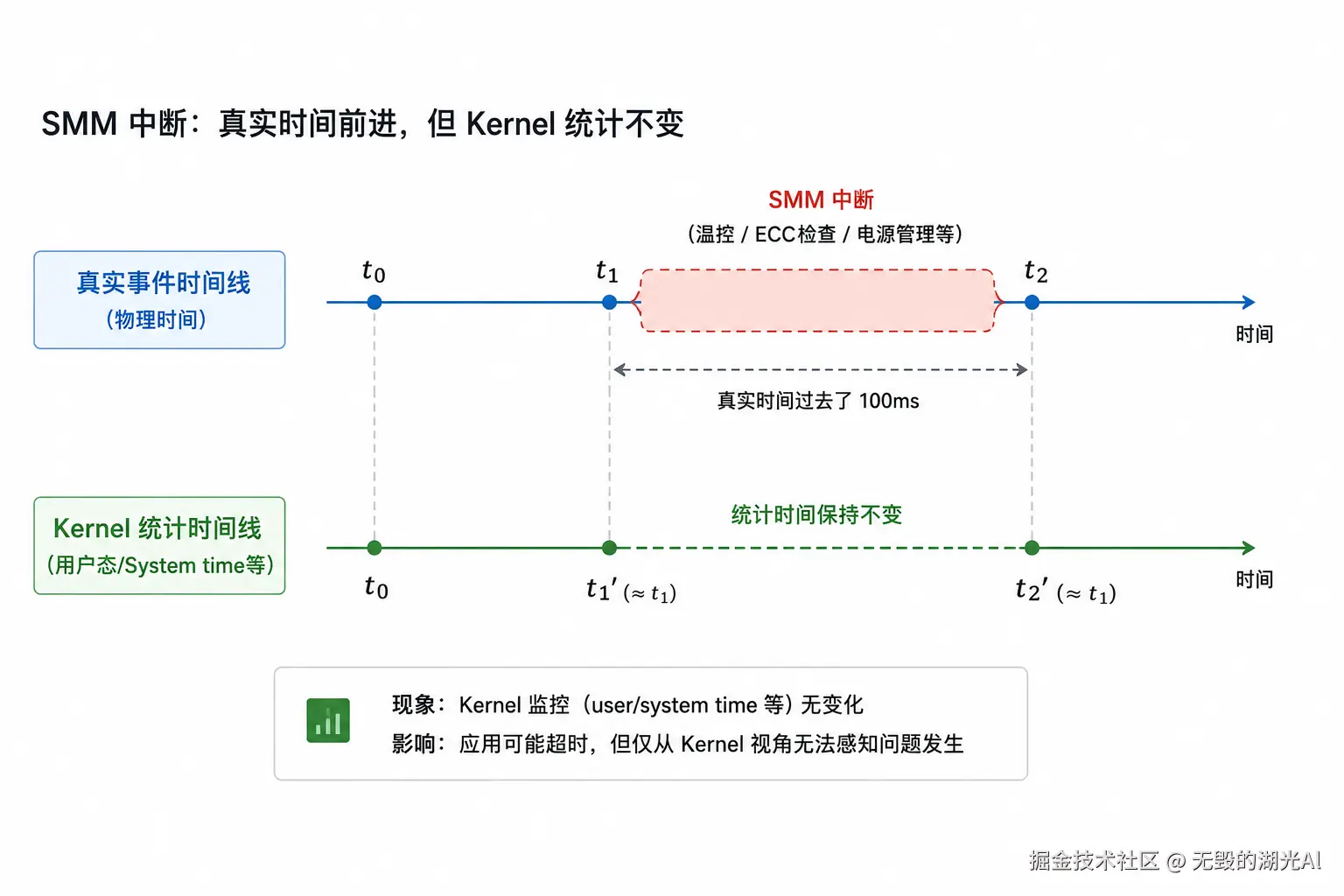 笔者就有一次发现线上应用出现报错尖刺,看了所有监控指标都没有异常,但奇怪的是都落在一台宿主机上。最后发现那台宿主机的温度监控值有变化,推断是 SMM在执行温控/电源管理之类的操作。但Kernel完全不知道这段时间发生了什么,user/system time 没有任何记录。 唯一能感知到的就只用应用层的超时报错。
笔者就有一次发现线上应用出现报错尖刺,看了所有监控指标都没有异常,但奇怪的是都落在一台宿主机上。最后发现那台宿主机的温度监控值有变化,推断是 SMM在执行温控/电源管理之类的操作。但Kernel完全不知道这段时间发生了什么,user/system time 没有任何记录。 唯一能感知到的就只用应用层的超时报错。
监控指标无法无限的逼近真实
真实的物理世界肯定是无法观测完全的。这里定义的真实其实是能够知道系统在任意时刻所有的状态。例如对于一段时间的请求,我们能够拿到这个请求走过的所有代码路径以及所有的耗时,那么我们其实就可以进行任意的剖析。但很可惜的是,这些数据太过于庞大,如果硬要收集,反而让系统本身消耗在大量的指标计算和收集上,进而导致了性能极度恶化。也就是观测的越深入越全面,观测本身所造成的干涉越大,直到测量本身成为了更大的问题,观测到的真实已经和想观测的真实相去甚远。
在这里举一个例子。MySQL 的监控非常依赖 show processlist 和 show status 这些命令,而这些命令对线上实际执行的 SQL 有不小的影响。具体过程如下图所示:
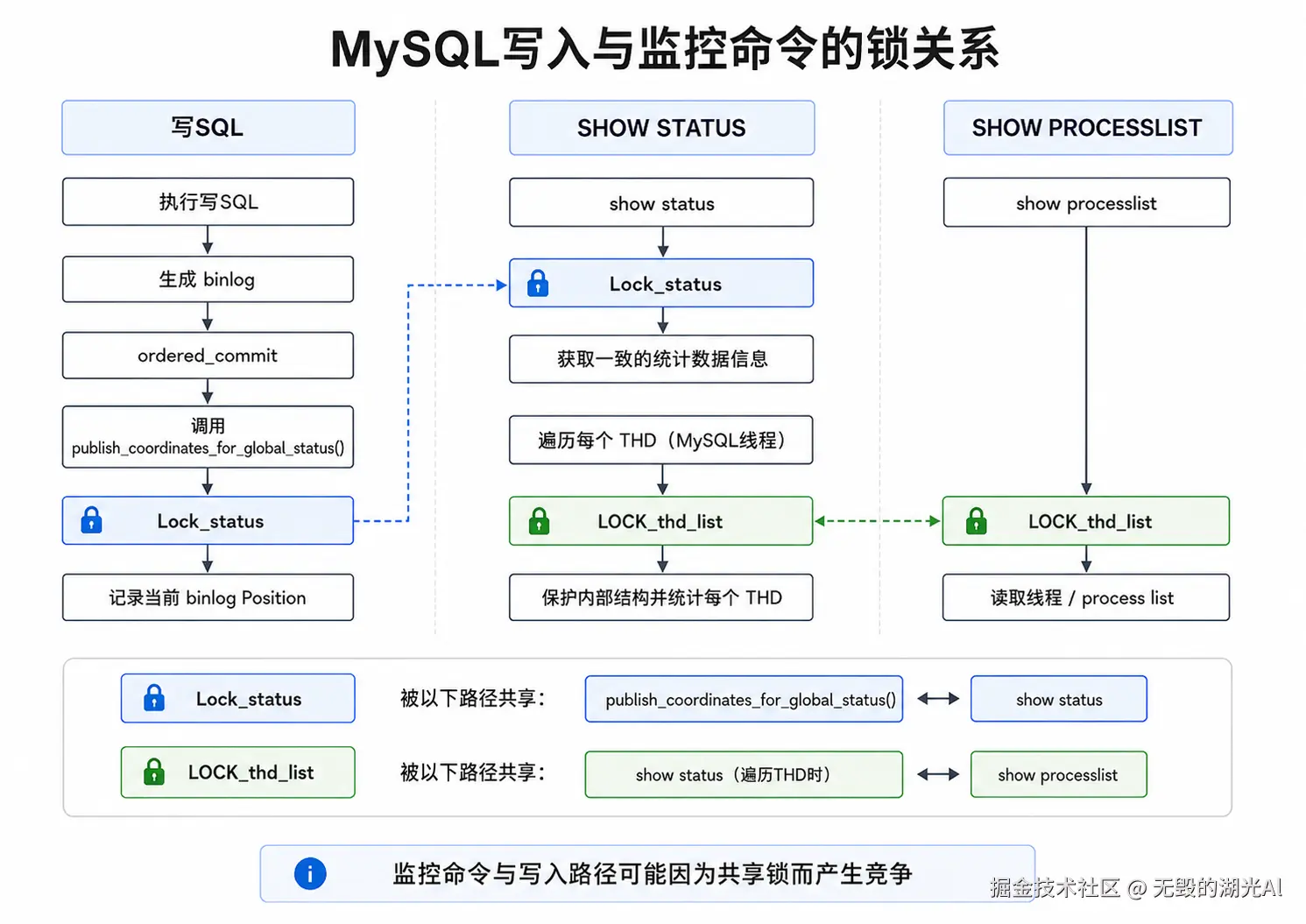
写SQL在执行的时候会生成binlog并进行组提交,在组提交内部会调用publish_coordinates_for_global_status来记录当前binlog的Position此时需要加锁Lock_status。在MySQL监控命令show status的时候也会加锁Lock_status来获取一致的统计数据信息。尤其是在其对每一个thd(MySQL线程)做统计的时候为了保护内部结构也需要加锁LOCK_thd_list而在MySQL的另一个监控命令show processlist时候也是会对LOCK_thd_list加锁。
一旦监控脚本执行过于频繁,就极其容易导致 SQL 执行被 block 住。,甚至线上因此产生过主从切换,在我们线下复现的过程中,发现高频率的show processlist对于性能有超高幅度的影响(会使得TPS从9000跌到3000甚至一度出现跌0的现象)。
监控指标的准确性受制于监控系统
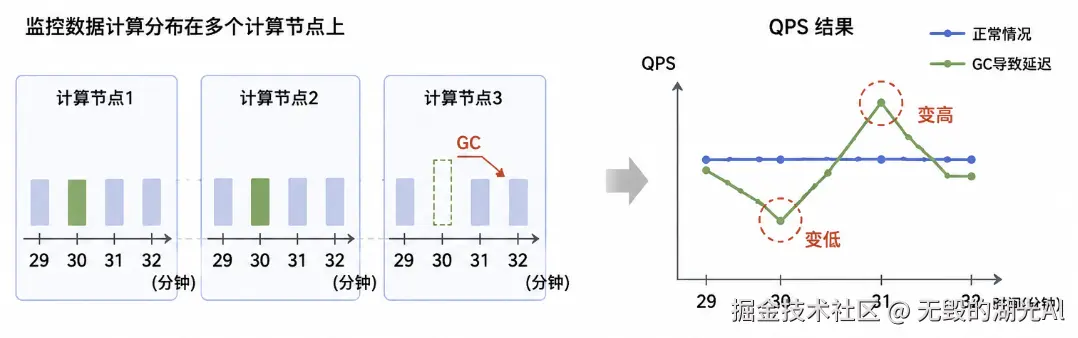
在微服务的今天,监控指标基本都是通过数据采集并上报给监控系统,并由监控系统统一运算得出。而海量的监控数据收集与运算必须分布在多台计算节点上最后再进行统一的汇总。那么计算节点本身也会出现宕机/GC/block等现象,一旦出现这种情况,势必会导致不准确,例如本因在第30分钟计算的数据在第31分钟才计算完毕,导致第30分钟的QPS变低而第31分钟的QPS变高。亦或者直接宕机丢了部分监控数据,这都会让我们的监控指标无法准确,如下图所示:
总结
监控指标只是事实的投影,由于代价的存在它无法无限的逼近真实。搞清楚监控指标本身导致测量的是什么,表达的是什么,在什么情况下超出了它的表达范围。监控指标只能是真实的投影,这样的局限会导致它有时候反映不出问题/有时候又会过度反映问题/甚至会"误导"我们偏离问题的根因从而作出错误的判断。在后续的文章中,笔者会逐一讨论这种局限性导致的种种问题。