管理学有个著名的"人月神话":给延期的项目加人,只会让它更延期。Agent领域也有类似的陷阱------给搞不定的任务加Agent,只会让系统更不可控。
多Agent协作是当前AI最火的叙事之一。AutoGen、CrewAI、LangGraph都在推多Agent方案。但在你动手搞"Agent团队"之前,先想清楚一个问题:你真的需要多个Agent吗?
01 先问自己:单Agent真的搞不定吗?
90%的场景,单Agent + 好的工具就够了。多Agent的合理场景只有三种:
1. 需要不同的系统提示:同一个Agent没法同时扮演"严格的代码审查员"和"创意的架构师"。角色冲突时,拆成两个Agent。
2. 需要并行执行:同时做A和B,单Agent只能串行。但注意------如果A和B没有依赖,用并行工具调用就能解决,不一定需要多Agent。
3. 需要权限隔离:Agent A只能读数据库,Agent B只能写文件。安全隔离要求拆Agent。
判断标准
如果你的"多Agent"只是在同一个LLM实例上切换不同prompt------那你需要的不是多Agent,是更好的工具设计。
真正需要多Agent的信号:
- · 两个角色的system prompt互相矛盾
- · 需要物理级别的隔离(不同进程/机器)
- · 需要独立的token预算和步数限制
02 多Agent的3种协作模式
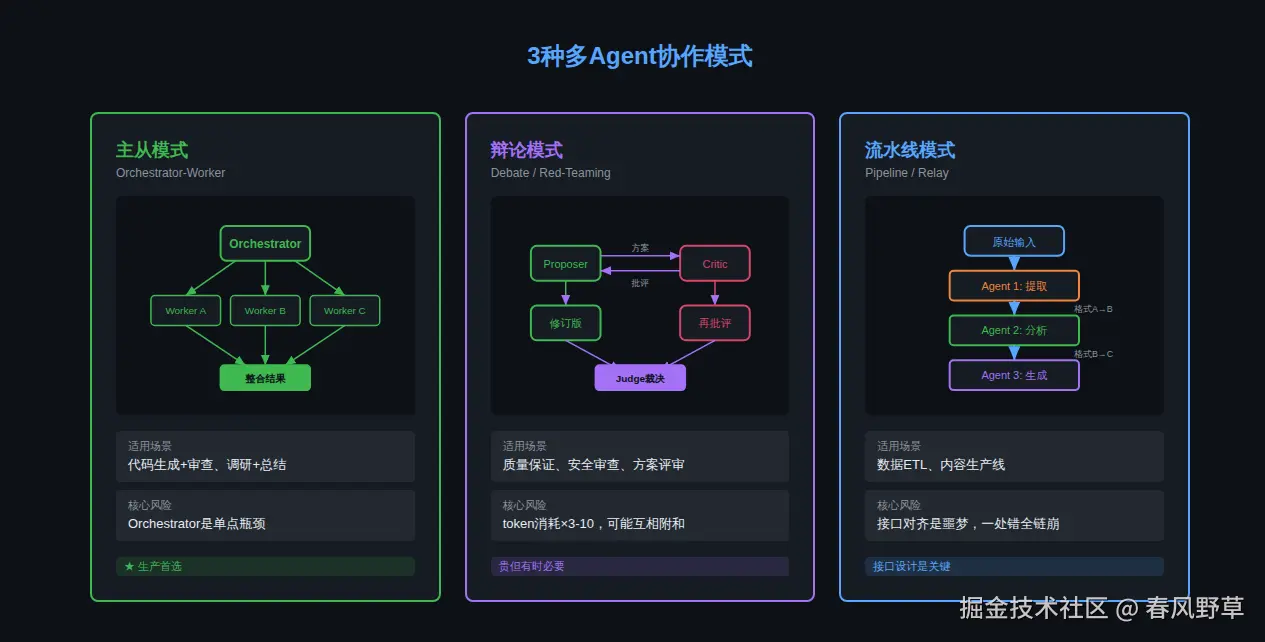
模式1:主从模式(Orchestrator-Worker)
最实用的模式:一个"老板"Agent负责任务拆解和结果整合,多个"工人"Agent负责具体执行。
python
class Orchestrator:
def run(self, task):
subtasks = self.decompose(task)
results = []
for subtask in subtasks:
worker = self.select_worker(subtask)
result = worker.execute(subtask)
results.append(result)
return self.synthesize(results)优点:结构清晰、容易追踪、人类能理解流程
缺点:Orchestrator是单点瓶颈------如果它拆任务拆错了,后面全错
模式2:辩论模式(Debate / Red-Teaming)
让多个Agent对同一问题给出不同观点,通过"辩论"逼近更好的答案。
python
proposer = Agent(role="方案提出者")
critic = Agent(role="批评者")
judge = Agent(role="裁判")
proposal = proposer.generate(task)
critique = critic.critique(proposal)
revised = proposer.revise(proposal, critique)
decision = judge.evaluate([proposal, revised])优点:能发现单Agent的盲点,输出质量更高
缺点:token消耗×3,延迟×3,而且"辩论"经常变成"互相附和"------如果基础模型相同,偏见也会相同
⚠️ ⚠️ 辩论模式的隐藏成本:不是3倍token,是3倍×多轮。3轮辩论可能消耗10倍单Agent的token。除非任务价值匹配,否则是过度工程。
模式3:流水线模式(Pipeline / Relay)
任务像流水线一样经过多个Agent,每个Agent处理一个阶段。
python
class Pipeline:
def run(self, input_data):
data = input_data
for agent in self.agents:
data = agent.process(data)
# 关键问题:每个Agent的输出是下一个的输入
return data优点:每个Agent职责单一、容易优化
缺点:接口对齐是噩梦------Agent之间的数据格式必须严格约定
03 多Agent最大的坑:通信开销
单Agent内部,所有信息都在上下文窗口里。多Agent之间,信息必须序列化传输------这就带来了3个问题:
1. 信息压缩损失 Agent A的处理结果有2000 token,传给Agent B时只能给摘要(500 token),否则B的上下文装不下。但摘要意味着信息丢失------B可能看不到A发现的关键细节。
2. 格式对齐 Agent A输出JSON,Agent B期望Markdown。Agent C返回代码块,Agent D只会读纯文本。接口设计比Agent本身更难。
3. 上下文膨胀 N个Agent协作,每个Agent需要理解其他Agent的输出。上下文大小 = 原始任务 + N×中间结果。很快就会超出窗口限制。

通信开销公式
单Agent总token ≈ 任务长度 + N步 × 单步消耗
多Agent总token ≈ 任务长度 + N步 × 单步消耗 × Agent数 + 通信token × 通信次数 3个Agent协作,总token通常是单Agent的3-5倍,不是3倍。
04 接口设计:多Agent的真正难点
多Agent系统的质量,取决于Agent之间的接口设计。这不是AI问题,是软件工程问题。
接口设计3原则:
原则1:结构化输出 Agent之间的通信必须用结构化格式(JSON Schema),不要用自然语言。
| ❌ ❌ 自然语言通信 | ✅ ✓ 结构化通信 |
|---|---|
| Agent A: "我找到了3个竞品, | Agent A: { |
| 第一个叫X,定价99, | "competitors": [ |
| 第二个叫Y,定价199..." | {"name":"X","price":99}, |
| Agent B要自己解析这段话 | {"name":"Y","price":199} |
| ] | |
| } | |
| Agent B直接用数据 |
原则2:最小必要信息 不要把Agent A的全部上下文传给B,只传B需要的信息。否则上下文会爆炸。
原则3:错误契约 约定Agent失败时返回什么格式。不是每个Agent都能成功------错误处理是接口设计的一部分。
python
class AgentResult:
status: Literal["success", "error", "partial"]
data: Optional[dict]
error: Optional[str]
confidence: float # 0.0-1.0
if result.status == "error":
# 不要继续流水线,上报错误
handle_error(result.error)
elif result.confidence < 0.5:
# 低置信度,人类介入
request_human_review(result)05 什么时候该用多Agent?决策树
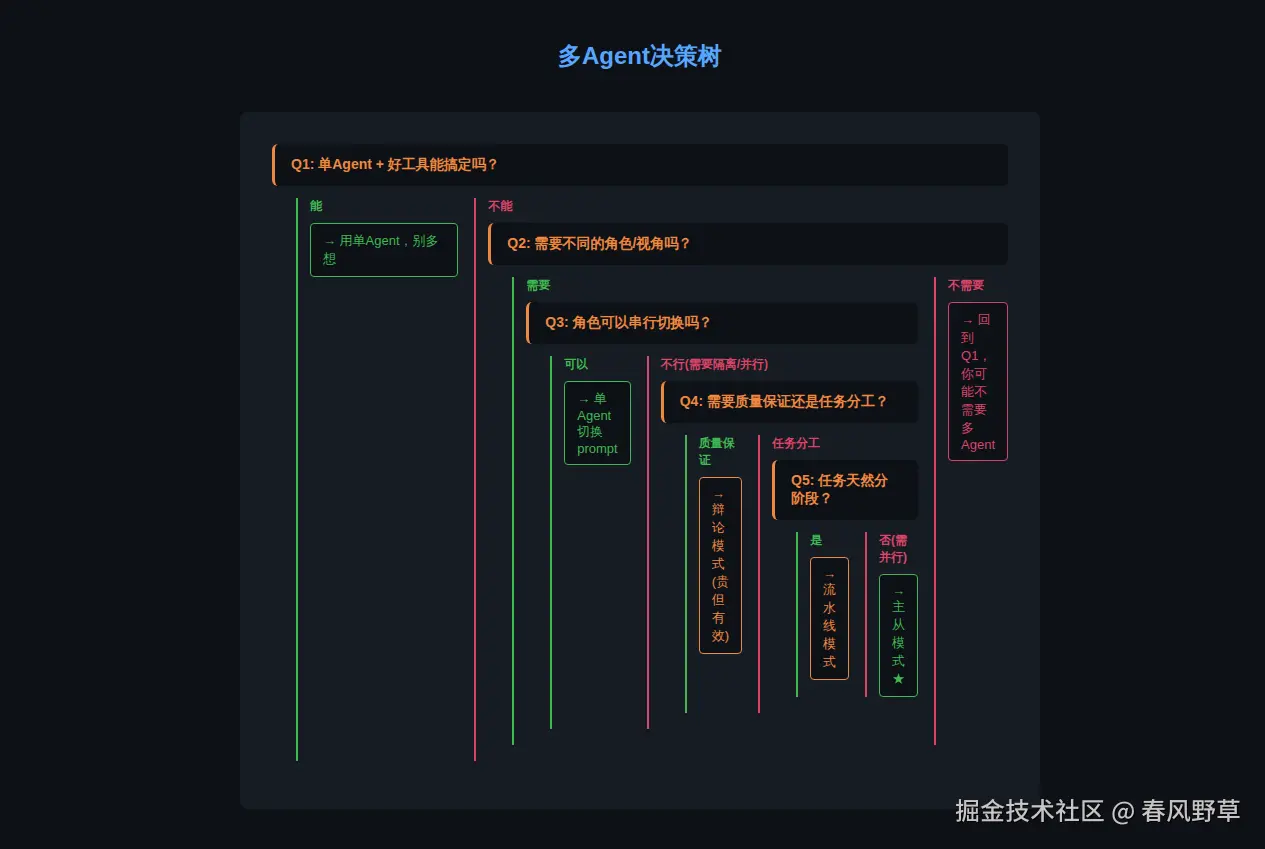 简单来说:
简单来说:
- 单Agent + 好工具能搞定 → 不用多Agent
- 需要不同角色但可以串行 → 单Agent切换prompt
- 需要并行 + 角色隔离 → 主从模式
- 需要质量保证 + 预算充足 → 辩论模式
- 任务天然分阶段 → 流水线模式
06 实战:多Agent的成本陷阱
来看一个真实案例:调研竞品并生成报告。
方案A:单Agent 1个Agent,4步:搜索→提取→分析→生成 总token ≈ 8000,耗时 ≈ 30秒
方案B:3个Agent流水线 Agent1(搜索) → Agent2(分析) → Agent3(生成) 每个Agent需要理解前一个的输出 总token ≈ 8000×3 + 3000(通信) = 27000,耗时 ≈ 60秒
方案B的优势在哪? 如果3个Agent可以并行(比如同时搜索3个竞品),时间是优势。但如果必须串行,B比A慢、贵、复杂,结果不一定更好。
多Agent ROI公式
多Agent值得 ⇔ 并行收益 > 通信开销 + 协调成本
- · 并行收益:时间缩短 × 任务价值/秒
- · 通信开销:额外token成本 × token单价
- · 协调成本:接口维护 + 调试 + 错误处理
07 新变量:A2A协议与OpenAI Agents SDK
多Agent领域有两个关键变化:
- Google发布A2A协议(Agent-to-Agent Protocol):Agent之间的通信标准
- OpenAI发布Agents SDK:官方的多Agent编排框架
这两个东西解决的是同一个问题的不同层面------A2A解决"不同厂商的Agent怎么互相对话",Agents SDK解决"同一个团队里的Agent怎么协作"。
A2A协议:Agent的HTTP
A2A要解决的问题是:Agent A(用LangGraph写的)想调用Agent B(用CrewAI写的),怎么办?
答案是:自己写适配器。每个框架的Agent接口都不一样,A2A之间要互相调用,就得写N×(N-1)个适配器。
A2A的思路和HTTP一样------定义一个标准协议,所有Agent都讲同一种语言。
markdown
A2A协议核心概念:
Agent Card(名片):每个Agent暴露一个JSON描述文件
- 我能做什么(capabilities)
- 我需要什么输入(input schema)
- 我返回什么格式(output schema)
- 我的认证方式(authentication)
Task(任务):Agent之间的交互单位
- 发送方创建Task,指定目标Agent
- 接收方执行Task,返回结果
- 支持流式返回、中间状态更新
Message(消息):Task内的通信
- 文本、结构化数据、文件
- 支持多轮交互(不是一次性请求-响应)A2A和MCP的区别:
| 维度 | MCP | A2A |
|---|---|---|
| 解决什么 | Agent访问工具/数据 | Agent访问Agent |
| 类比 | USB接口(设备连接) | HTTP协议(服务通信) |
| 通信模式 | 请求-响应 | 多轮对话 |
| 发现机制 | 配置文件 | Agent Card |
| 典型场景 | Agent调用数据库、文件系统 | Agent A委托Agent B做子任务 |
A2A对架构师的影响:
- Agent可以跨框架组合:用LangGraph写的规划Agent + 用CrewAI写的执行Agent,通过A2A互相对话,不需要改代码
- Agent可以跨组织组合:你的Agent调用供应商的Agent做报价查询,通过A2A标准接口
- Agent市场成为可能:Agent Card就是"商品详情页",用户可以搜索、选择、组合不同Agent
但A2A还在早期:目前A2A仍处于协议推广阶段,真正支持A2A的Agent框架不多。Google自家的ADK(Agent Development Kit)率先支持,LangChain、CrewAI等第三方框架正在适配。协议本身也可能在社区反馈中迭代变化。
架构师该做什么 :现在不需要全面迁移到A2A,但设计多Agent系统时,Agent之间的接口应该按A2A的思路设计------结构化的输入输出、标准化的错误处理、可发现的Agent描述。这样等A2A成熟后,迁移成本最低。
OpenAI Agents SDK:官方的编排方案
OpenAI发布了Agents SDK------一个轻量级的Python多Agent编排框架。它的设计哲学和LangGraph/CrewAI完全不同:不抽象,只编排。
python
from agents import Agent, Runner
# 定义Agent
researcher = Agent(
name="researcher",
instructions="你负责调研,只做调研",
model="gpt-5.1",
tools=[web_search, read_file]
)
writer = Agent(
name="writer",
instructions="你负责写作,只做写作",
model="gpt-5.1",
tools=[write_file]
)
# Agent之间的交接(handoff)
# researcher调研完后,把结果交接给writer
orchestrator = Agent(
name="orchestrator",
instructions="协调researcher和writer",
handoffs=[researcher, writer] # 可以把任务交接给这些Agent
)
# 运行
result = Runner.run_sync(orchestrator, "调研AI Agent框架并写报告")Agents SDK的核心概念:
- Agent:一个有instructions + tools + handoffs的LLM实例
- Handoff:Agent之间的任务交接。不是"调用",是"交接"------当前Agent把上下文传给下一个Agent,自己退出
- Guardrails:输入/输出检查器,在Agent执行前后做安全校验
- Tracing:内置的执行追踪,每一步都有记录
和LangGraph/CrewAI的对比:
| 维度 | Agents SDK | LangGraph | CrewAI |
|---|---|---|---|
| 设计哲学 | 最小抽象 | 图抽象 | 角色抽象 |
| 编排方式 | Handoff(LLM自主决策) | 图节点+边(开发者定义) | 任务流程(开发者定义) |
| 灵活性 | 高(LLM决定交接给谁) | 最高(图可以任意复杂) | 中(预定义流程) |
| 可控性 | 低(LLM可能交接错) | 高(流程完全确定) | 中 |
| 学习曲线 | 低 | 高 | 中 |
| MCP支持 | 原生 | 需适配 | 需适配 |
| 适合场景 | 快速原型、简单编排 | 复杂流程、生产级 | 团队模拟、角色扮演 |
Agents SDK的"Handoff陷阱":
Handoff让LLM自己决定什么时候交接、交接给谁。这很灵活,但也意味着:
- LLM可能把任务交接给错误的Agent
- LLM可能在不需要交接时频繁交接(增加token消耗)
- LLM可能忘记交接(一直自己干,超出能力范围)
解法:在instructions中明确约定交接规则------"当你完成了调研部分,必须交接给writer,不要自己写"。用Guardrails做硬性校验。
多Agent架构的推荐形态
综合A2A和Agents SDK,多Agent系统设计有了新的选择:
arduino
┌─────────────────────────────────────────────────────┐
│ 编排层 │
│ ┌──────────────┐ ┌──────────────┐ │
│ │ Agents SDK │ │ LangGraph │ │
│ │ (简单场景) │ │ (复杂场景) │ │
│ └──────────────┘ └──────────────┘ │
│ ↕ Handoff / Graph Edges │
├─────────────────────────────────────────────────────┤
│ Agent层 │
│ Agent A ←→ Agent B ←→ Agent C │
│ ↕ A2A Protocol(跨框架/跨组织通信) │
├─────────────────────────────────────────────────────┤
│ 工具层 │
│ MCP Server ←→ MCP Server ←→ MCP Server │
└─────────────────────────────────────────────────────┘选型决策:
| 场景 | 编排方案 | 通信方案 | 原因 |
|---|---|---|---|
| 2-3个Agent,同框架 | Agents SDK | Handoff | 最简单,开箱即用 |
| 复杂流程,需要精确控制 | LangGraph | Graph Edges | 流程可控,可调试 |
| 跨框架Agent协作 | 任意 | A2A | 标准化通信 |
| 跨组织Agent协作 | 任意 | A2A | 唯一选择 |
| 需要MCP工具集成 | Agents SDK | MCP原生 | SDK原生支持MCP |
一句话总结:A2A解决了"Agent之间怎么说话"的标准化问题,Agents SDK解决了"同框架Agent怎么协作"的简化问题。两者叠加,多Agent系统的集成成本在下降,但核心难题------接口设计、通信开销、错误处理------仍然需要架构师自己解决。