在深度学习以及大模型算法中使用最为广泛的损失函数是交叉熵。这个概念最早起源于信息论,他由信息论的创建者想香浓提出,核心目标就在于如何使用数学来定义和量化"信息"。信息的本质是什么呢?信息的本质是如何度量"不确定性"。 如果如果给定信息让你掌握后,你一下子获得了很大的确定性,那么它的"信息量"就大,如果它让你感觉无关紧要,那么"信息量"就小。对于如何针对给定事物进行分类是深度学习和LLM需要经常解决的厂家。给定一张图片,里面是猫还是狗。给定一个句子前5个单词,那么第六个单词应该是哪个?这些情况的选择都具有不确定性。
对于给定图片,模型可能无法非常确切的认定它是狗,因为有些地方看起来又像是猫的特征,于是模型就会给"狗"这个结论设置一个概率,然后给"猫"这个结论设置一个概率。如果事后确定图片里的是狗,那么我们就需要修改模型内部参数,让模型看到类似图片后,给出"狗"的概率要尽可能的高,然后给出"猫"的概率要尽可能的低。
这里又涉及到如何"修改模型内部参数"的问题。做法是"微调"模型内部。所谓的"微调",实际上是通过对模型内每个参数求导,然后根据导数结果来修改当前参数的数值。这就需要损失函数要"平滑,可微",它不仅能反映预测的对错,例如对预测的种类给出正确概率。同时还能提醒预测的置信度,例如模型预测狗的概率为0.6或者0.9都是正确的,但是我们希望通过奖励后者,惩罚前者的方式让模型加深当前图片中对应狗的特性。
交叉熵损失函数完美的契合了上面需求。交叉熵函数具有以下良好的数学属性能够非常契合"分类"场景: 1.与最大似然估计(MLE)等价。所谓最大似然估计就是在得知结论后,修改模型内部参数以便让针对结论所描述的类别对应的概率尽可能增大。 2.梯度优良。也就是针对交叉熵函数求导后,对应的参数求导所得的结果跟预测误差成正比。当误差严重偏离真实数值时,参数求导后所得结果偏大,这样就能对参数进行较大规模的修正从而快速修正模型。当预测接近真实数值时,梯度变小,也就是求导后的结果数值较小,于是对参数的调整幅度就比较小,有利于精细调优。 3.凸性。交叉熵损失函数是凸函数,通过梯度下降法能有效找到全局最优解。
要理解交叉熵,我们先理解其"前辈",也就是"信息熵"如何计算。假设某个事件或者事物处于某种状态遵守概率函数P,例如丢一枚硬币,结果是正面还是反面对应的概率函数就是P(正面)=0.5,P(反面)=0.5.于是我们用来度量这个事件,首先我们看信息熵的计算公式:
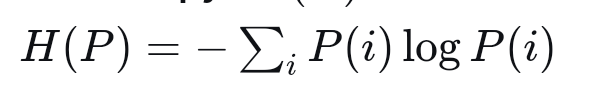
上面公式中H(p)表示事件概率函数为P时的信息熵,右边的i对应所有可能的情况,例如丢硬币而言,i=1,2,i=1表示硬币是正面,i=2表示硬币是反面。上面公式对应离散概率函数的情况。注意看上面公式计算结果是一个常亮,因为他遍历了所有可能的情况,然后针对每种情况对应的概率进行了计算,所以最终结果是一个常量。实际上交叉熵是我们前面研究过的KL散度损失函数中的变量部分,KL散度损失函数除了上面部分外,还有如下部分:
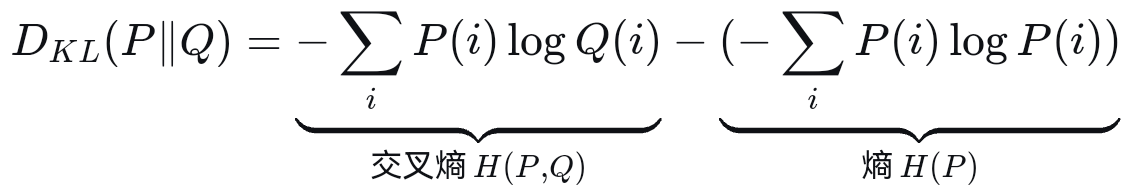
从上面公式看出,交叉熵其实就是将熵函数中事件自己对应的概率函数换成模型模拟的概率函数,因此该损失函数的目标就是,当事件发生了情况i对应的结果后,我们让模型模拟的概率函数Q(i)取值尽可能的大。
在实际的分类应用中,我们经常需要对数据做好标注以便让模型进行有监督的学习。假设我们要判断三种类型的图片,分别是猫,狗,鸟,那么我们使用one-hot向量来表示当前图片属于哪个类别,如果第一张图片是猫,那么对应的向量就是1,0,0,第二张图片如果是狗,那么对应的向量就是0,1,0,如果第三张图片时鸟,那么向量对应0.0,1.这样一个one-hot向量本质上对应一个概率分布,其中一种类别的概率是100%,也就是分量取值为1的那个,其他类别概率就是0,这个对应的就是概率函数P。当你输入一种猫的图片,模型给出的概率向量可能是0.7,0.2,0.1,这个对应的就是概率函数Q,交叉熵损失函数就是要训练模型将第一个分量的数值尽可能的提供,然后其他两个分量的值尽可能的减少。
对于只有两种分类的情形,也就是"是"或者"否",那么真实分布对应的P要么取值1(正类)要么取值0(负类),而模型对应的概率函数Q就会给出一个0到1之间的取值,例如0.75,我们就可以设置一个阈值,大于0.7我们认为就是正类,小于我们认为就是负类,如果用y来表示训练数据的标签,它取值0或者1,然后y^表示模型给出的概率数值,那么交叉熵损失函数如下: 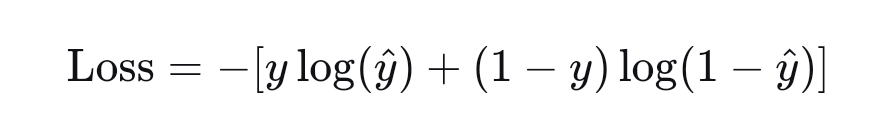
当输入给模型的数据属于正类时,y=1,于是上损失函数简化为Loss=-log(y^),要想让该函数结果尽可能小,那么y^值就要尽可能趋向于1,也就是要训练模型尽可能将当前的数据识别为正类。如果输入给模型的数据为负类,那么y=0,公式化简为Loss=-Log(1-y^),要让该函数取值尽可能小,那么y^要尽可能趋向0,也就是训练网络尽可能将当前数据失败为负类。
对于多分类的情况,就是前面我们提到过的识别猫,狗,鸟的情况,假设总共的类别数量为C,那么给定一张训练图片,它对应的表情就是y_1,y_2,...y_C,这些分量重只有一个取值1,其他都取值0,那么交叉熵损失函数如下:
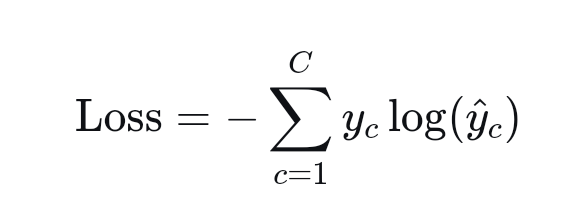
由于只有一个分量取值为1,因此公式就会简化为:Loss=-log(y^_c),这就迫使模型将对应分类的输出值尽可能提高趋向于1,将其他分量尽可能降低趋向于0.
最后我们使用代码示例将交叉熵函数实现一遍加深印象:
import numpy as np
def binary_cross_entropy(y_true, y_pred):
"""
只有两种分类的交叉熵。y_true当前数据分类,取值0(负类)或1(正类)。
y_pred为预测分类,取值[0,1]之间
"""
#防止Log(0)
eps=1e-12
y_pred=np.clip(y_pred,eps, 1-eps)
#二分类交叉熵loss = -[y*log(y^)+(1-y)*log(1-y^)]
losses = -(y_true*np.log(y_pred)+(1-y_true)*np.log(1-y_pred))
return np.mean(losses)
#多分类的交叉熵
def softmax(logits):
#减去每行最大值,防止指数爆炸
shifted = logits-np.max(logits, axis=1,keepdims=True)
exp_logits=np.exp(shifted)
return exp_logits/np.sum(exp_logits, axis=1,keepdims=True)
def categorical_cross_entropy(y_true, logits):
"""
多分类交叉熵,y_true:当前数据属于哪个类别,取值0 ~ C-1,也就是类别索引
logits:模型给出的每个分类对应的概率向量
"""
N=logits.shape[0]
#计算每个类别对应的概率
probs=softmax(logits)
#根据多类别交叉熵公式,把每个类别对应的结果向量中,正确类别对应的概率值单独抽取出来
correct_probs=probs[np.arange(N),y_true]
#使用非常接近0的非0数值,防止计算log(0)
correct_probs=np.clip(correct_probs, 1e-12, 1.0)
losses = -np.log(correct_probs)
return np.mean(losses)
print("=====binary cross entropy======")
y_true_bin=np.array([1,0,1,0,1])
y_pred_bin=np.array([0.9,0.2,0.8,0.3,0.7])
loss_bin=binary_cross_entropy(y_true_bin,y_pred_bin)
print(f"Loss (binary):{loss_bin}")
print("\n====multiple category cross entropy=====")
#3个样本4个类别
logits=np.array([
[2.0, 1.0, 0.1, 0.5],
[0.5,2.0,1.0,0.2],
[0.1,0.3,3.0,1.0]
])
#每个样本对应类别的索引
y_true_multi=np.array([0,1,2])
loss_multi=categorical_cross_entropy(y_true_multi, logits)
print(f"Loss (categorical): {loss_multi:.4f}")上面代码运行后所得结果如下:
=====binary cross entropy======
Loss (binary):0.2529995012327421
====multiple category cross entropy=====
Loss (categorical): 0.4489
``