模型的好处和局限
- 好处是解决了 传统架构线性串联导致的误差积累和信息丢失利用率低
- 坏处 因果混淆,只是学习了相关性 没有学习因果性
drivevlm 将决策分解 场景描述 分析 和分层次规划 把相关性 变成因果 - 惯性问题, 训练数据中有大量平稳数据,当需要急停急加速的时候 可能过于迟钝
- 训练数据偏移
- 黑盒子不可解释
- 长尾 受限于数据 且缺乏推理能力 对于未见过的数据只能找最相近物体 无法进行因果推理
VLA
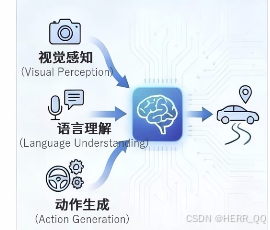
双系统架构 vlm 负责高层的语义理解 传统规划器 负责控规 好处 规划成熟 可控 坏处 系统之间有协同问题
端到端 vlm 直接输出控制规划 以token模式 架构简单 缺点对于模型实时性稳定性 要求高 安全验证难度大
driveVLM
使用 vision transfromer 作为视觉编码器 提取多视角图像特征 对齐到llm的输入空间 构建统一的推理引擎
将决策分为三个阶段 事变关键物体和环境-》推断潜在风险和意图-》输出轨迹点或驾驶指令
alpamayo
提升决策的透明和安全性 为高级别自动驾驶提供农可追溯的逻辑支撑
把感知 推理 动作预测 集成在统一的自回归架构里 支持多模态的传感器输入
引入 因果链条 强制模型在输出动作之前要生成逻辑自洽的推理步骤
世界模型
是对环境动态演变概率分布的建模 允许智能体推演未来可能性 无需在现实中试错 用来生成罕见的长尾场景 极端天气事故现场等 用于训练。
发展从简单环境到生成驾驶视频到加入了占据栅格和物理特性
GAIA
认为自动驾驶系统需要预测环境动态变化的能力
基于transfromer 生成架构 支持视频文本动作进行输入
将视频压缩为离散的潜空间表示 在其中进行自回归预测 可以推理比如加速 刹车之后会发生什么
潜空间
"潜空间(Latent Space)"通常指通过深度学习模型(如自编码器、VAE、扩散模型、BEV特征提取网络等)将高维原始感知数据(图像/点云/LiDAR)压缩映射得到的低维、富含语义信息的特征向量空间。
简单说:潜空间是模型"理解"场景后的内部数学表示,而不是人类看到的原始像素或点云。
为什么自动驾驶要用潜空间?
降维去噪去掉光照、纹理等无关细节,保留驾驶相关语义
统一表征 多传感器(相机+LiDAR+Radar)可映射到同一 latent 空间(BEV Feature)
便于推理 规划/预测模块在低维连续空间运算更高效
泛化能力 相似场景 相近 latent 向量,利于少样本学习
潜空间通常不可直接解释
drive occ world
能同时输出未来的4D占据栅格与自车的规划轨迹
RL
关注智能体 如何在环境中通过试错来学习最优策略
智能体 环境 状态 动作 奖励
智能体观察状态 采取动作 环境反馈及时奖励 并转移到新状态 这一过程不断重复
优势: 模仿学习有上限,受限于人类的水平 通过合适的奖励函数 发现比人类更好的做法
CaRL
在自动驾驶领域面临仿真到真实的鸿沟 通过大规模真实训练数据 解决rl难以处理复杂多变的城市交通博弈
使用nuplan真实交互数据集进行了训练
RAD
传统仿真 保真度低
使用 3DGS 高保真环境
训练过程
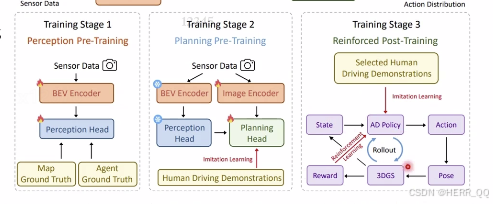
Think2Drive
通过世界模型潜空间中的推演 摆脱对图像渲染的依赖
有一个预训练的世界模型和潜空间规划器组成
规划器直接在世界模型生成的特征向量上进行策略优化
这一部分的系统性教程 有待更新
未来展望
三位一体: vla WM RL
快慢系统协同
对于训练的影响 从 data loop 到 training loop 无需要真实采集和标注而是在生成的交互场景中进行训练
现在还有的问题:算力功耗 可验证性 法律和责任
最后的可能性 AGI是最终目标