KNN的理解
KD树
跟据KNN每次需要预测⼀个点时,我们都需要计算训练数据集⾥每个点到这个点的 距离,然后选出距离最近的k个点进⾏投票。当数据集很⼤时,这个计算成本⾮常高,针对N个样本,D个特征的数据集,其算法复杂度为O(DN2 )。
kd树:为了避免每次都重新计算⼀遍距离,算法会把距离信息保存在⼀棵树⾥,这样在计算之前从树⾥查询距离信息,尽量避免重新计算。其基本原理是,如果A和B距离很远,B和C距离很近,那么A和C的距离也很远。有了这个信息,就可以在合适的时候跳过距离远的点。
原理
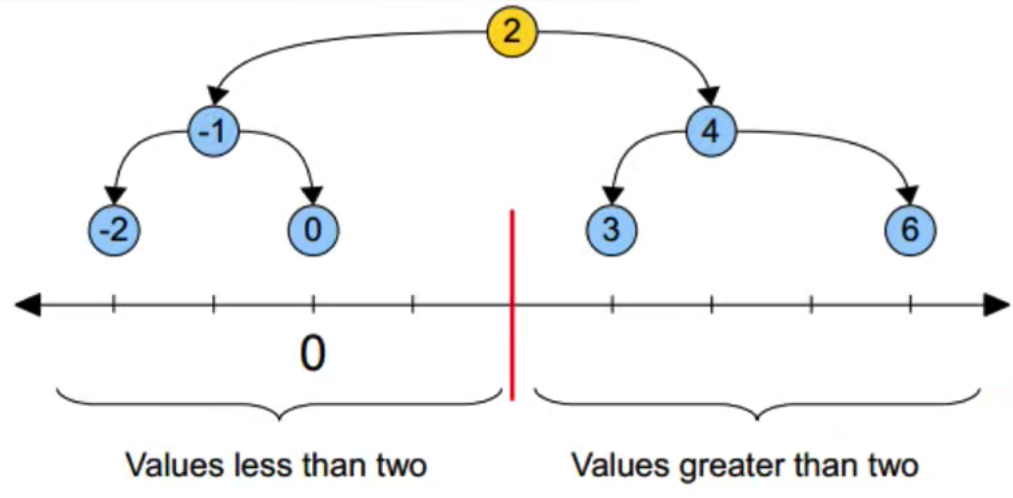
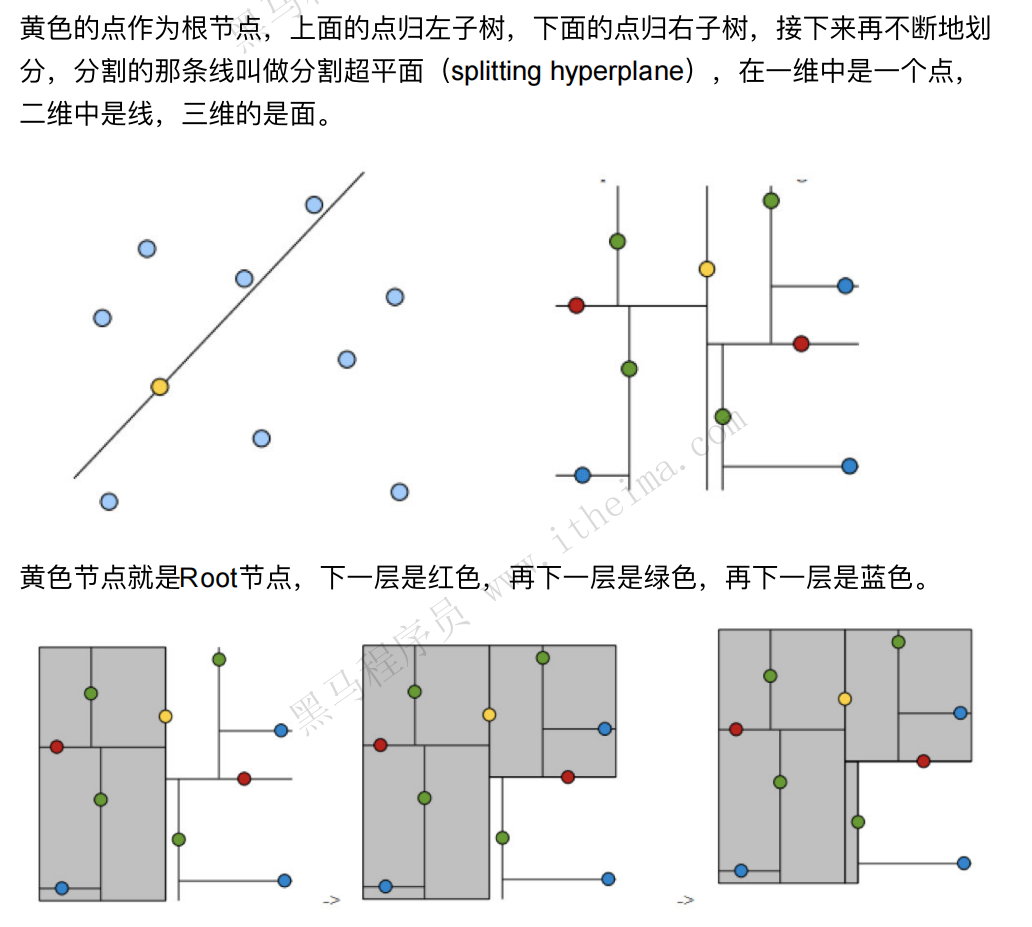

案例分析
树的建立
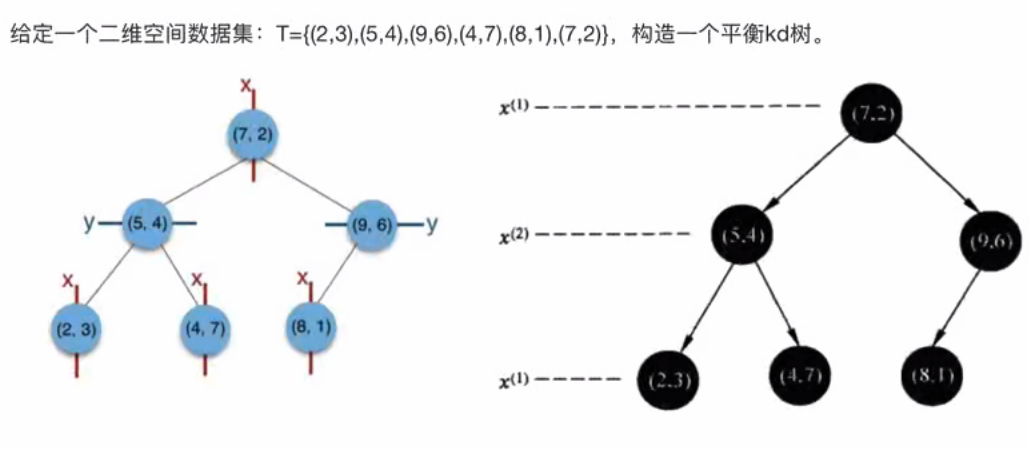


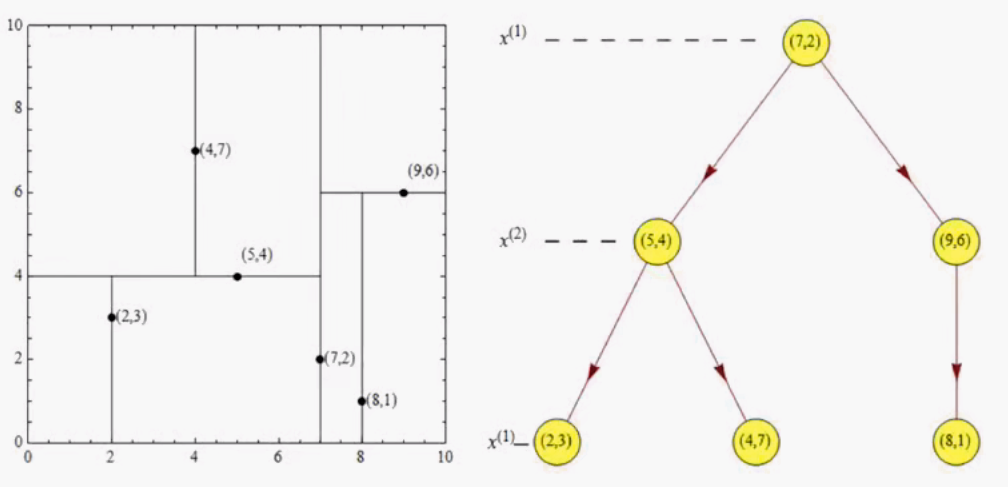
最近领域的搜索
假设标记为星星的点是 test point, 绿⾊的点是找到的近似点,在回溯过程中,需要⽤到⼀个队列,存储需要回溯的点,在判断其他⼦节点空间中是否有可能有距离查询点更近的数据点时,做法是以查询点为圆⼼,以当前的最近距离为半径画圆,这个圆称为候选超球(candidate hypersphere),如果圆与回溯点的轴相交,则需要将轴另⼀边的节点都放到回溯队列⾥⾯来。
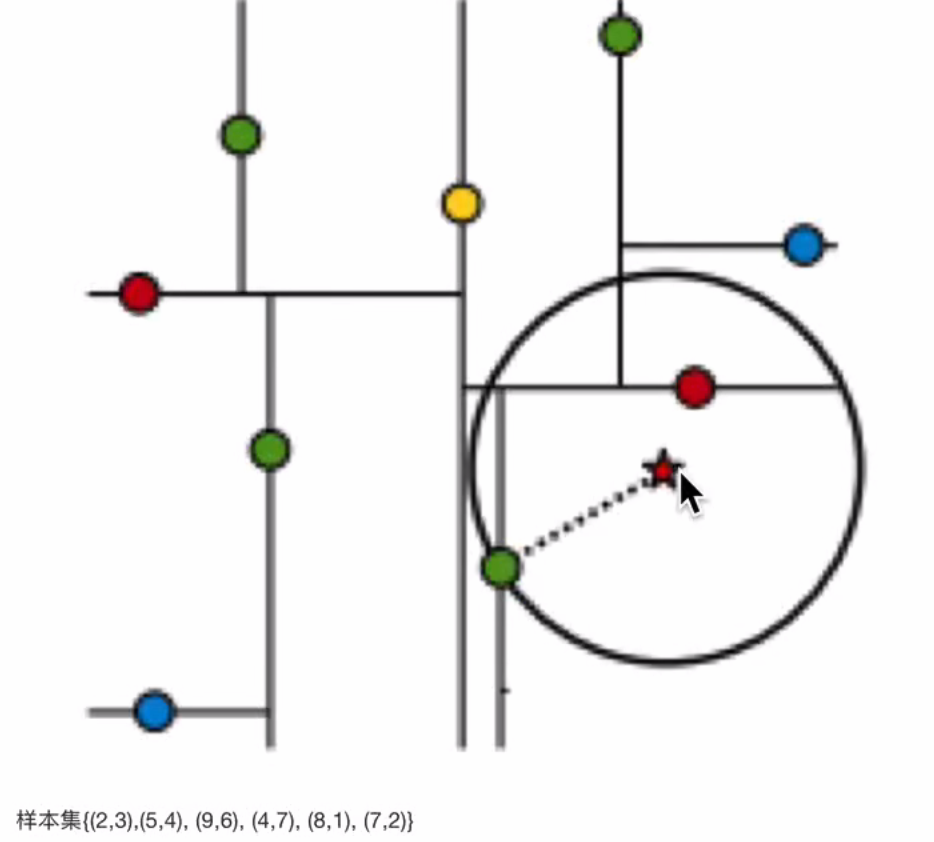
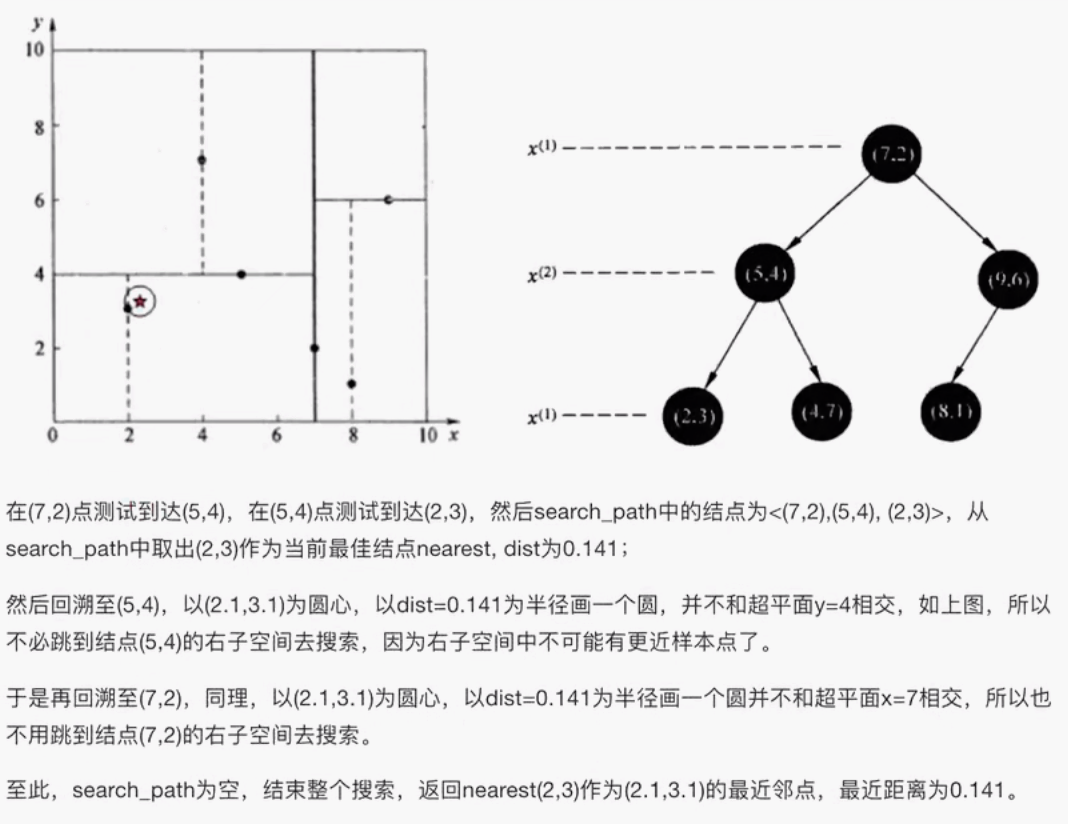
查找(2.1,3.1)
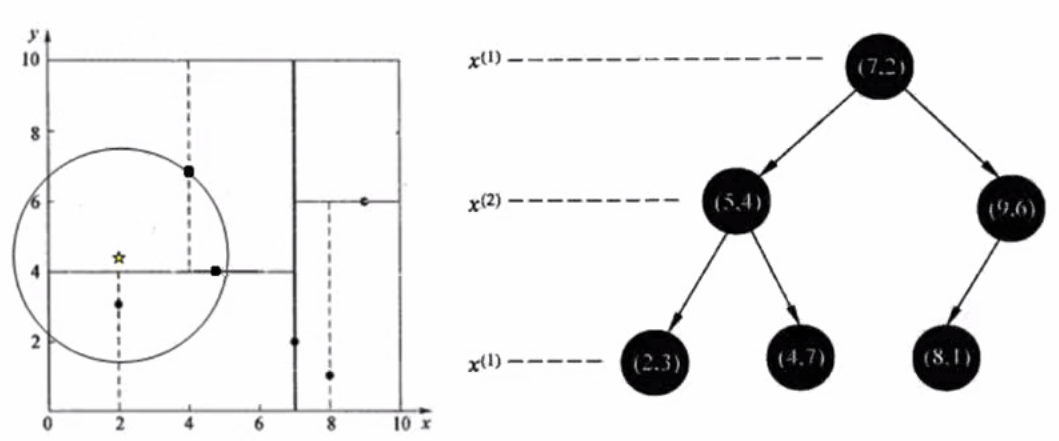
查找(2,4.5)

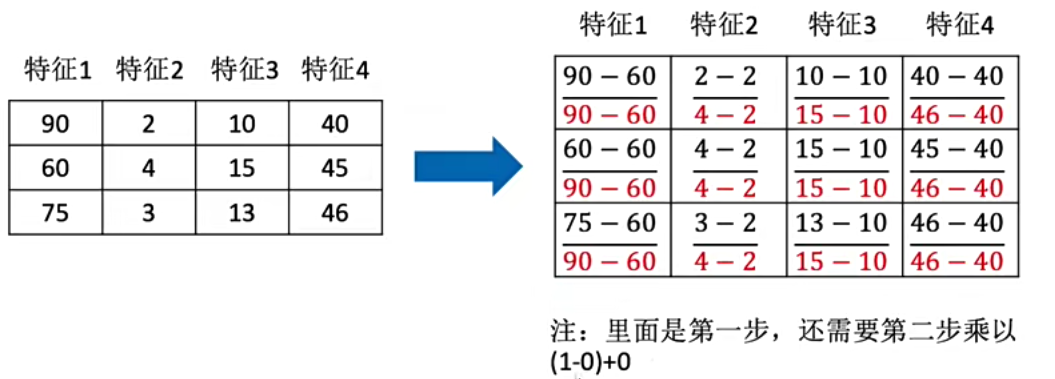
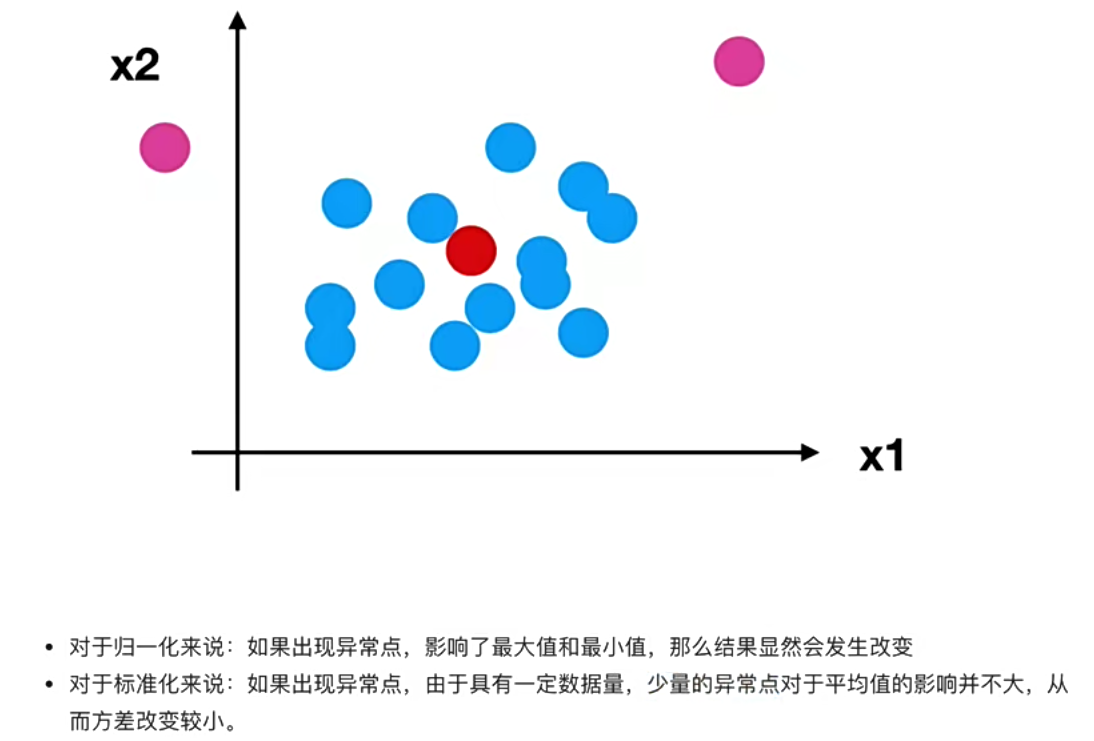
归一化与标准化

-
归一化
-
标准化
API函数
归一化
- sklearn.preprocessing.MinMaxScaler (feature_range=(0,1)... )
- MinMaxScalar.fit_transform(X)
- X:numpy array格式的数据n_samples,n_features
- 返回值:转换后的形状相同的array
- MinMaxScalar.fit_transform(X)
标准化
- sklearn.preprocessing.StandardScaler( )
- 处理之后每列来说所有数据都聚集在均值0附近标准差差为1
- StandardScaler.fit_transform(X)
- X:numpy array格式的数据n_samples,n_features
- 返回值:转换后的形状相同的array
- 处理之后每列来说所有数据都聚集在均值0附近标准差差为1
py
# coding:utf-8
import pandas as pd
from sklearn.preprocessing import MinMaxScaler, StandardScaler
def minmax_demo():
"""
归一化演示
:return:None
"""
data = pd.read_csv("./data/dating.txt")
print(data)
# 1.实例化
transfer = MinMaxScaler(feature_range=(3,5))
# 2.进行转换, 调用fit_transform
ret_data = transfer.fit_transform(data[["milage", "Liters", "Consumtime"]])
print("归一化之后的数据为:\n",ret_data)
'''
milage Liters Consumtime target
0 40920 8.326976 0.953952 3
1 14488 7.153469 1.673904 2
2 26052 1.441871 0.805124 1
3 75136 13.147394 0.428964 1
.. ... ... ... ...
998 48111 9.134528 0.728045 3
999 43757 7.882601 1.332446 3
[1000 rows x 4 columns]
最⼩值最⼤值归⼀化处理的结果:
[[ 2.44832535 2.39805139 2.56233353]
[ 2.15873259 2.34195467 2.98724416]
[ 2.28542943 2.06892523 2.47449629]
...,
[ 2.29115949 2.50910294 2.51079493]
[ 2.52711097 2.43665451 2.4290048 ]
[ 2.47940793 2.3768091 2.78571804]]
'''
def stand_demo():
"""
标准化演示
:return:None
"""
data = pd.read_csv("./data/dating.txt")
print(data)
# 1.实例化
transfer = StandardScaler()
# 2.进行转换, 调用fit_transform
ret_data = transfer.fit_transform(data[["milage", "Liters", "Consumtime"]])
print("标准化之后的数据为:\n",ret_data)
print("每一列的方差为:\n", transfer.var_)
print("每一列的平均值为:\n", transfer.mean_)
# minmax_demo()
stand_demo()
'''
milage Liters Consumtime target
0 40920 8.326976 0.953952 3
1 14488 7.153469 1.673904 2
2 26052 1.441871 0.805124 1
.. ... ... ... ...
997 26575 10.650102 0.866627 3
998 48111 9.134528 0.728045 3
999 43757 7.882601 1.332446 3
[1000 rows x 4 columns]
标准化的结果:
[[ 0.33193158 0.41660188 0.24523407]
[-0.87247784 0.13992897 1.69385734]
[-0.34554872 -1.20667094 -0.05422437]
...,
[-0.32171752 0.96431572 0.06952649]
[ 0.65959911 0.60699509 -0.20931587]
[ 0.46120328 0.31183342 1.00680598]]
每⼀列特征的平均值:
[ 3.36354210e+04 6.55996083e+00 8.32072997e-01]
每⼀列特征的⽅差:
[ 4.81628039e+08 1.79902874e+01 2.46999554e-01]
'''鸢尾花种类预测


K-近邻算法API
- sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
- n_neighbors:
- int,可选(默认= 5),k_neighbors查询默认使⽤的邻居数
- algorithm:{'auto','ball_tree','kd_tree','brute'}
- 快速k近邻搜索算法,默认参数为auto,可以理解为算法⾃⼰决定合适的搜索算法。除此之外,⽤户也可以⾃⼰指定搜索算法ball_tree、kd_tree、brute⽅法进⾏搜索,
- brute是蛮⼒搜索,也就是线性扫描,当训练集很⼤时,计算⾮常耗时。
- kd_tree,构造kd树存储数据以便对其进⾏快速检索的树形数据结构,kd树也就是数据结构中的⼆叉树。以中值切分构造的树,每个结点是⼀个超矩形,在维数⼩于20时效率⾼。
- ball tree是为了克服kd树⾼维失效⽽发明的,其构造过程是以质⼼C和半径r分割样本空间,每个节点是⼀个超球体。
- n_neighbors:
鸢尾花数据集介绍
Iris数据集是常⽤的分类实验数据集


py
# coding:utf-8
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
# 1.获取数据
iris = load_iris()
# 2.数据基本处理
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2,random_state=22) # random_state为随机数种子
# 3.特征工程 - 特征预处理
transfer = StandardScaler() # 实例化对象
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4.机器学习-KNN
# 4.1 实例化一个估计器
estimator = KNeighborsClassifier(n_neighbors=5)
# 4.2 模型训练
estimator.fit(x_train, y_train)
# 5.模型评估
# 5.1 预测值结果输出
y_pre = estimator.predict(x_test)
print("预测值是:\n", y_pre)
print("预测值和真实值的对比是:\n", y_pre==y_test)
# 5.2 准确率计算
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)交叉验证
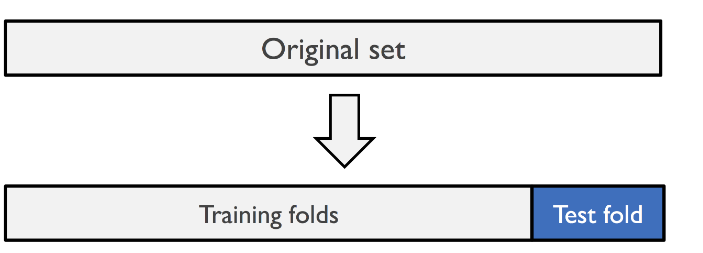
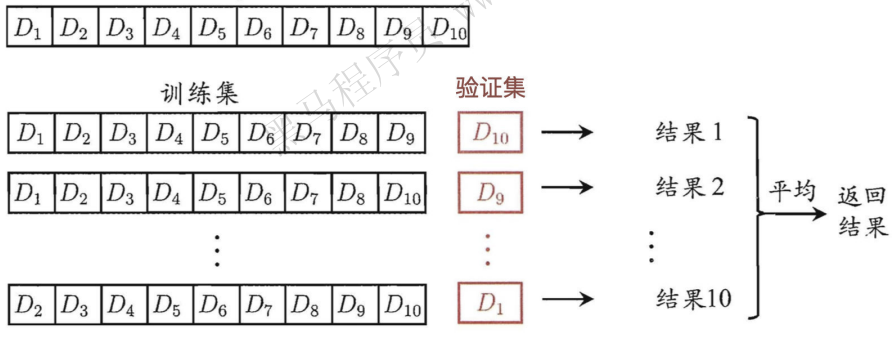
将拿到的训练数据,分为训练和验证集。
以下图为例:将数据分成10份,其中⼀份作为验证集。然后经过10次(组)的测试,每次都更换不同的验证集。即得到10组模型的结果,取平均值作为最终结果。⼜称10折交叉验证。
分析
我们之前知道数据分为训练集和测试集,但是为了让从训练得到模型结果更加准确。做以下处理
- 训练集:训练集+验证集
- 测试集:测试集
交叉验证⽬的:为了让被评估的模型更加准确可信
网格搜索
通常情况下,有很多参数是需要⼿动指定的(如k-近邻算法中的K值),这种叫超参数。但是⼿动过程繁杂,所以需要对模型预设⼏种超参数组合。每组超参数都采⽤交叉验证来进⾏评估。最后选出最优参数组合建⽴模型。

API函数
sklearn.model_selection.GridSearchCV(estimator,param_grid=None,cv=None)
- 解释:对估计器的指定参数值进⾏详尽搜索
参数: - estimator:估计器对象
- param_grid:估计器参数(dict){"n_neighbors":1,3,5}
- cv:指定⼏折交叉验证
- ⽅法:
- fit:输⼊训练数据
- score:准确率
- 结果分析:
- bestscore__:在交叉验证中验证的最好结果
- bestestimator:最好的参数模型
- cvresults:每次交叉验证后的验证集准确率结果和训练集准确率结果
增加K值调优
使⽤GridSearchCV构建估计器
py
# coding:utf-8
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
# 1.获取数据
iris = load_iris()
# 2.数据基本处理
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
# 3.特征工程 - 特征预处理
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4.机器学习-KNN
# 4.1 实例化一个估计器
estimator = KNeighborsClassifier()
# 4.2 模型调优 -- 交叉验证,网格搜索
param_grid = {"n_neighbors": [1, 3, 5, 7]}
estimator = GridSearchCV(estimator, param_grid=param_grid, cv=5)
# 4.3 模型训练
estimator.fit(x_train, y_train)
# 5.模型评估
# 5.1 预测值结果输出
y_pre = estimator.predict(x_test)
print("预测值是:\n", y_pre)
print("预测值和真实值的对比是:\n", y_pre == y_test)
# 5.2 准确率计算
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
# 5.3 查看交叉验证,网格搜索的一些属性
print("在交叉验证中,得到的最好结果是:\n", estimator.best_score_)
print("在交叉验证中,得到的最好的模型是:\n", estimator.best_estimator_)
print("在交叉验证中,得到的模型结果是:\n", estimator.cv_results_)


预测facebook签到位置
项目描述
- 本次⽐赛的⽬的是预测⼀个⼈将要签到的地⽅。
- 为了本次⽐赛,Facebook创建了⼀个虚拟世界,其中包括10公⾥*10公⾥共100平⽅公⾥的约10万个地⽅。
- 对于给定的坐标集,您的任务将根据⽤户的位置,准确性和时间戳等预测⽤户下⼀次的签到位置。
- 数据被制作成类似于来⾃移动设备的位置数据。
- 请注意:您只能使⽤提供的数据进⾏预测。
数据介绍
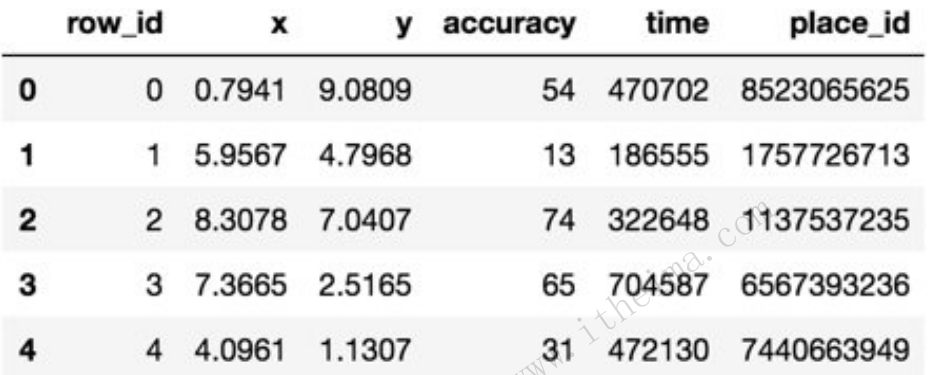
⽂件说明 train.csv, test.csv
row id:签⼊事件的id
x y:坐标
accuracy: 准确度,定位精度
time: 时间戳
place_id: 签到的位置,这也是你需要预测的内容
官⽹:https://www.kaggle.com/c/facebook-v-predicting-check-ins
步骤分析
- 对于数据做⼀些基本处理(这⾥所做的⼀些处理不⼀定达到很好的效果,我们只是简单尝试,有些特征我们可以根据⼀些特征选择的⽅式去做处理)
- 1 缩⼩数据集范围 DataFrame.query()
- 2 选取有⽤的时间特征
- 3 将签到位置少于n个⽤户的删除
- 分割数据集
- 标准化处理
- k-近邻预测
具体步骤:
1.获取数据集
2.基本数据处理
2.1 缩⼩数据范围
2.2 选择时间特征
2.3 去掉签到较少的地⽅
2.4 确定特征值和⽬标值
2.5 分割数据集
3.特征⼯程 -- 特征预处理(标准化)
4.机器学习 -- knn+cv
5.模型评估
代码实现
py
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
# 1.获取数据集
data = pd.read_csv("./data/FBlocation/train.csv")
# 2.基本数据处理
# 2.1 缩⼩数据范围
facebook_data = facebook.query("x>2.0 & x<2.5 & y>2.0 & y<2.5")
# 2.2 选择时间特征
time = pd.to_datetime(facebook_data["time"], unit="s")
time = pd.DatetimeIndex(time)
facebook_data["day"] = time.day
facebook_data["hour"] = time.hour
facebook_data["weekday"] = time.weekday
# 2.3 去掉签到较少的地⽅
place_count = facebook_data.groupby("place_id").count()
place_count = place_count[place_count["row_id"]>3]
facebook_data = facebook_data[facebook_data["place_id"].isin(place_count.index
# 2.4 确定特征值和⽬标值
x = facebook_data[["x", "y", "accuracy", "day", "hour", "weekday"]]
y = facebook_data["place_id"]
# 2.5 分割数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
# 3.特征⼯程--特征预处理(标准化)
# 3.1 实例化⼀个转换器
transfer = StandardScaler()
# 3.2 调⽤fit_transform
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4.机器学习--knn+cv
# 4.1 实例化⼀个估计器
estimator = KNeighborsClassifier()
# 4.2 调⽤gridsearchCV
param_grid = {"n_neighbors": [1, 3, 5, 7, 9]}
estimator = GridSearchCV(estimator, param_grid=param_grid, cv=5)
# 4.3 模型训练
estimator.fit(x_train, y_train)
# 5.模型评估
# 5.1 基本评估⽅式
score = estimator.score(x_test, y_test)
print("最后预测的准确率为:\n", score)
y_predict = estimator.predict(x_test)
print("最后的预测值为:\n", y_predict)
print("预测值和真实值的对⽐情况:\n", y_predict == y_test)
# 5.2 使⽤交叉验证后的评估⽅式
print("在交叉验证中验证的最好结果:\n", estimator.best_score_)
print("最好的参数模型:\n", estimator.best_estimator_)
print("每次交叉验证后的验证集准确率结果和训练集准确率结果:\n",estimator.cv_results_)