文章目录
-
- 前言
- [一、查看 GPU:显卡型号、显存和进程占用](#一、查看 GPU:显卡型号、显存和进程占用)
-
- [1.1 使用 nvidia-smi 查看 GPU](#1.1 使用 nvidia-smi 查看 GPU)
- [1.2 查看 GPU 上有哪些进程](#1.2 查看 GPU 上有哪些进程)
- [1.3 案例分析](#1.3 案例分析)
- [二、查看 CPU:核心数和线程数](#二、查看 CPU:核心数和线程数)
-
- [2.1 使用 lscpu 查看 CPU 详情](#2.1 使用 lscpu 查看 CPU 详情)
- [2.2 只查看 CPU 逻辑核心数](#2.2 只查看 CPU 逻辑核心数)
- [2.3 案例](#2.3 案例)
- [三、查看内存:RAM 和 Swap](#三、查看内存:RAM 和 Swap)
-
- [3.1 使用 free -h 查看内存](#3.1 使用 free -h 查看内存)
- [3.2 free 很小不一定代表内存不足](#3.2 free 很小不一定代表内存不足)
- [3.3 Swap 是什么](#3.3 Swap 是什么)
- [3.4 案例](#3.4 案例)
- 四、查看磁盘空间
-
- [4.1 使用 df -h 查看分区空间](#4.1 使用 df -h 查看分区空间)
- [4.2 查看当前目录属于哪个磁盘](#4.2 查看当前目录属于哪个磁盘)
- [4.3 查看当前目录占用大小](#4.3 查看当前目录占用大小)
- [4.4 案例](#4.4 案例)
- 五、查看磁盘挂载结构
-
- [5.1 使用 lsblk 查看磁盘结构](#5.1 使用 lsblk 查看磁盘结构)
- [5.2 案例](#5.2 案例)
- [六、查看系统版本和 CUDA 环境](#六、查看系统版本和 CUDA 环境)
-
- [6.1 查看 Linux 系统版本](#6.1 查看 Linux 系统版本)
- [6.2 查看内核版本](#6.2 查看内核版本)
- [6.3 查看 CUDA 驱动支持版本](#6.3 查看 CUDA 驱动支持版本)
- [6.4 查看 PyTorch 是否能使用 GPU](#6.4 查看 PyTorch 是否能使用 GPU)
- 七、结合实际服务器做一个简要判断
- [八、一键查看服务器资源的 Bash 脚本](#八、一键查看服务器资源的 Bash 脚本)
-
- [8.1 创建脚本](#8.1 创建脚本)
- [8.2 给脚本执行权限](#8.2 给脚本执行权限)
- [8.3 一键运行](#8.3 一键运行)
- 九、脚本输出怎么看
-
- [9.1 看 GPU](#9.1 看 GPU)
- [9.2 看 CPU](#9.2 看 CPU)
- [9.3 看内存](#9.3 看内存)
- [9.4 看磁盘](#9.4 看磁盘)
- 总结
前言
在服务器上跑大模型、深度学习实验、代码仓库分析任务时,第一步不是马上运行代码,而是先确认服务器资源是否够用。
常见需要查看的资源包括:
text
GPU 型号和显存
CPU 型号和核心数
内存 RAM 和 Swap
磁盘空间
系统版本
CUDA 驱动
Python / PyTorch 是否能使用 GPU这些信息决定了服务器能不能跑模型、能不能加载数据集、能不能支撑并发任务。
可以把服务器理解成一台"实验机器":
- GPU:主要负责大模型推理和训练
- CPU:负责数据处理、代码解析、进程调度
- 内存:负责临时存放数据
- 磁盘:负责存模型、数据集、代码仓库和实验结果
一、查看 GPU:显卡型号、显存和进程占用
1.1 使用 nvidia-smi 查看 GPU
最常用命令是:
bash
nvidia-smi它可以查看:
text
显卡型号
显存总量
显存占用
GPU 使用率
CUDA 驱动版本
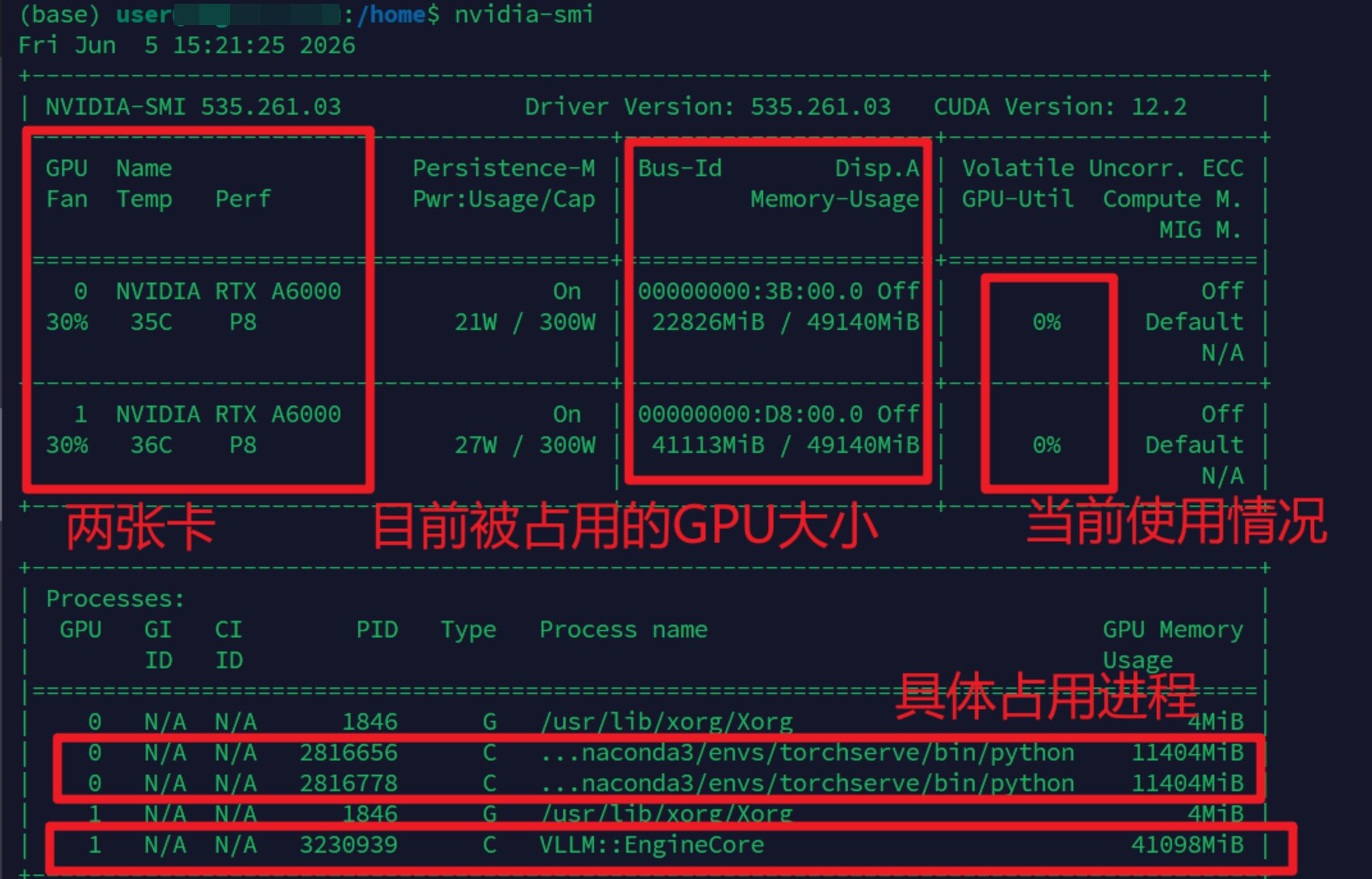
正在占用 GPU 的进程例如输出中看到:
text
NVIDIA RTX A6000
Memory-Usage: 22826MiB / 49140MiB
GPU-Util: 0%表示:
text
显卡型号:NVIDIA RTX A6000
总显存:约 48GB
当前已用显存:约 22.8GB
当前 GPU 计算利用率:0%注意:
text
GPU-Util 0% 不代表 GPU 完全空闲。
它只表示当前这一瞬间没有进行计算。
如果 Memory-Usage 很高,说明显存仍然被程序占着。可以理解为:
text
显存占用高:有人把座位占住了
GPU-Util 低:这个人现在没干活1.2 查看 GPU 上有哪些进程
nvidia-smi 底部会显示类似:
text
PID Process name GPU Memory
2816656 python 11404MiB
3230939 VLLM::EngineCore 41098MiB这表示:
text
某个 Python 程序占用了约 11GB 显存
某个 vLLM 服务占用了约 41GB 显存如果想看这些进程详情,可以执行:
bash
ps -fp 2816656
ps -fp 3230939如果进程是自己的,并且确定不用了,可以结束:
bash
kill 进程PID如果普通 kill 无效,再谨慎使用:
bash
kill -9 进程PID不要随便 kill 别人的进程。
1.3 案例分析
二、查看 CPU:核心数和线程数
2.1 使用 lscpu 查看 CPU 详情
bash
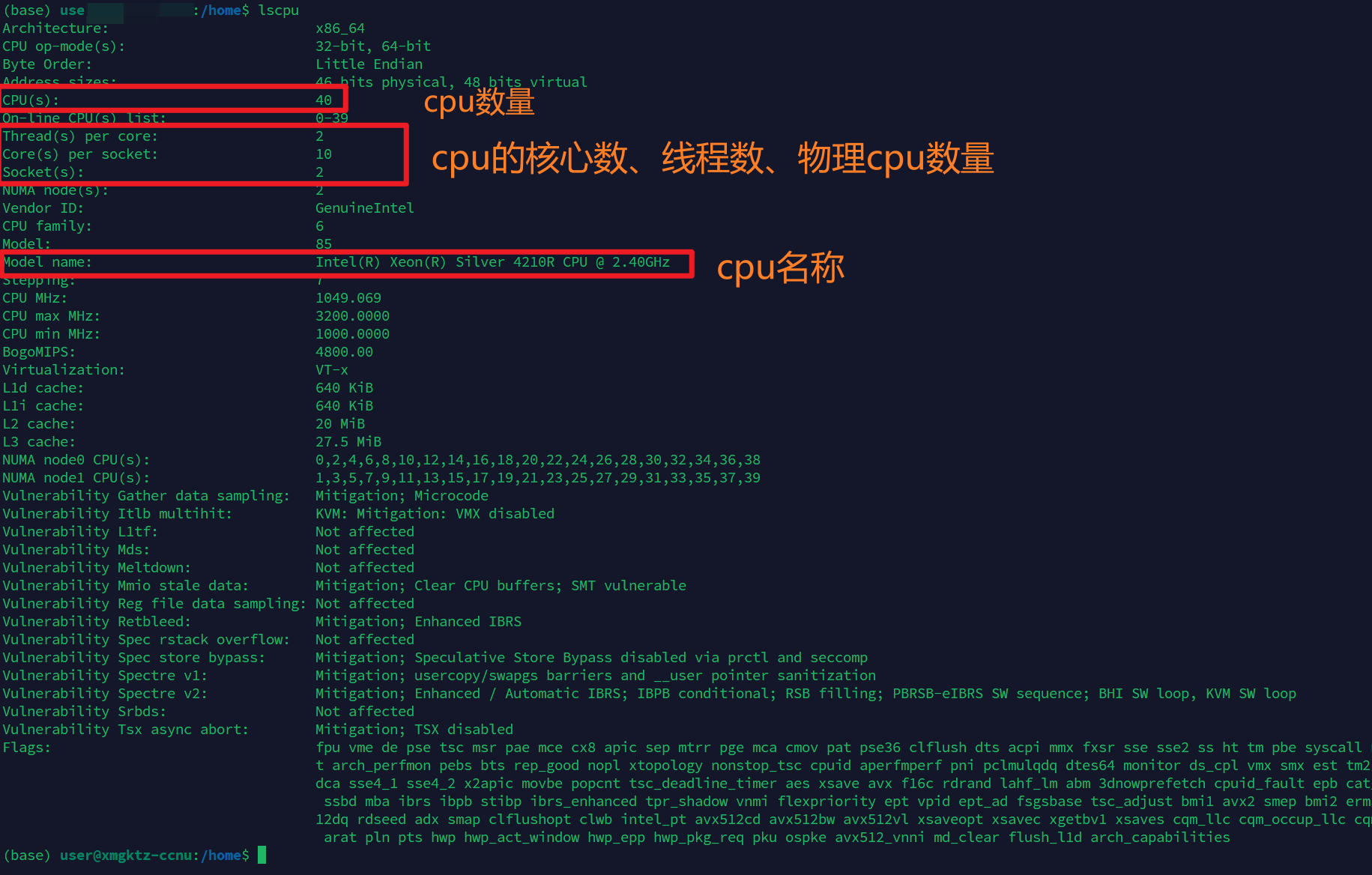
lscpu重点看这些字段:
text
Model name:CPU 型号
CPU(s):逻辑线程数
Socket(s):物理 CPU 数量
Core(s) per socket:每颗 CPU 的物理核心数
Thread(s) per core:每个物理核心的线程数例如:
text
Model name: Intel(R) Xeon(R) Silver 4210R CPU @ 2.40GHz
CPU(s): 40
Socket(s): 2
Core(s) per socket: 10
Thread(s) per core: 2可以理解为:
text
有 2 颗物理 CPU
每颗 CPU 有 10 个物理核心
每个物理核心有 2 个线程
所以总共有 2 × 10 × 2 = 40 个逻辑线程2.2 只查看 CPU 逻辑核心数
bash
nproc如果输出:
text
40表示当前系统可用 40 个逻辑 CPU 线程。
CPU 对下面这些任务比较重要:
text
代码仓库解析
数据预处理
编译项目
多进程并发
运行测试用例
构建索引但对于大模型推理和训练来说,最关键的通常还是 GPU 显存。
2.3 案例
三、查看内存:RAM 和 Swap
3.1 使用 free -h 查看内存
bash
free -h输出类似:
text
total used free buff/cache available
Mem: 30Gi 14Gi 1.2Gi 15Gi 16Gi
Swap: 47Gi 16Gi 30Gi重点看:
text
Mem total:物理内存总量
Mem used:已使用内存
Mem available:当前大概还能用的内存
Swap used:已经使用的交换分区其中最重要的是:
text
available它表示当前系统大概还能给新程序使用多少内存。
3.2 free 很小不一定代表内存不足
Linux 会把空闲内存拿来做缓存,所以有时 free 很小,但 available 仍然比较大。
例如:
text
free: 1.2Gi
available: 16Gi这表示完全空闲的内存只有 1.2GB,但系统实际还能给程序释放出约 16GB 使用。
3.3 Swap 是什么
Swap 可以理解为"硬盘上的临时内存"。
当物理内存不够用时,系统会把一部分数据临时放到硬盘上。
但是硬盘速度比内存慢很多,所以 Swap 用得太多,程序可能会变慢。
如果看到:
text
Swap used: 16Gi说明系统已经有一定内存压力。
3.4 案例

四、查看磁盘空间
4.1 使用 df -h 查看分区空间
bash
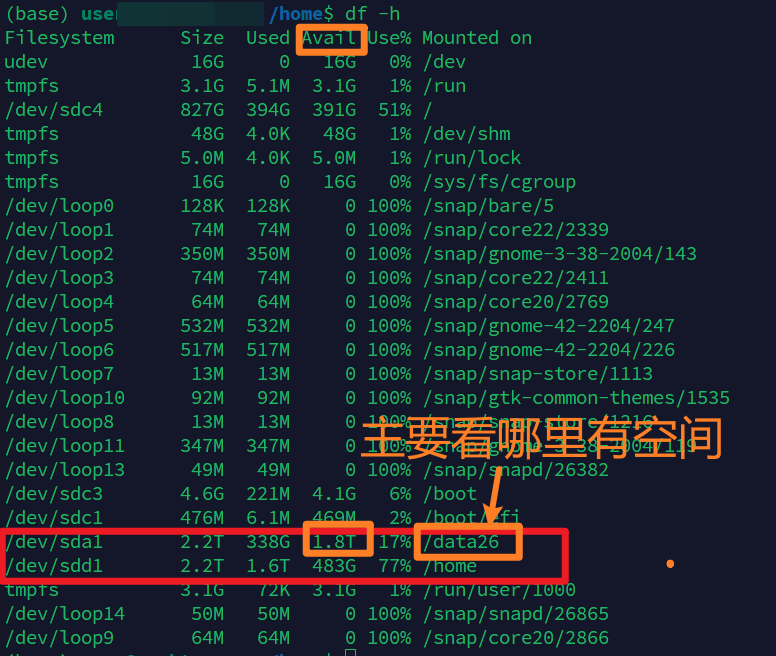
df -h重点看这些列:
text
Size:总容量
Used:已使用
Avail:剩余空间
Use%:使用率
Mounted on:挂载位置例如:
text
/dev/sdc4 827G 394G 391G 51% /
/dev/sda1 2.2T 338G 1.8T 17% /data26
/dev/sdd1 2.2T 1.6T 486G 77% /home表示:
text
根目录 / 剩余约 391GB
/data26 剩余约 1.8TB
/home 剩余约 486GB如果要存放大模型、数据集、代码仓库和实验输出,优先选择剩余空间更大的数据盘,例如:
bash
/data264.2 查看当前目录属于哪个磁盘
bash
df -h .如果你当前在 /home/likecodebase,输出一般会显示它属于 /home 分区。
4.3 查看当前目录占用大小
bash
du -sh .查看当前目录下每个文件夹大小:
bash
du -h --max-depth=1 | sort -hr这个命令很适合找哪个目录最占空间。
4.4 案例
五、查看磁盘挂载结构
5.1 使用 lsblk 查看磁盘结构
bash
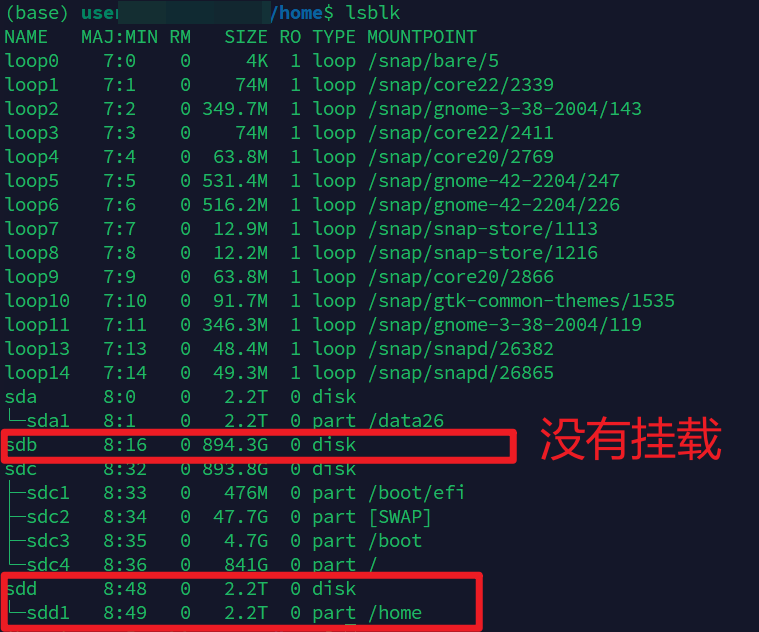
lsblk输出类似:
text
sda 2.2T
└─sda1 2.2T /data26
sdc 893.8G
├─sdc1 476M /boot/efi
├─sdc2 47.7G [SWAP]
├─sdc3 4.7G /boot
└─sdc4 841G /
sdd 2.2T
└─sdd1 2.2T /home可以理解为:
text
sda:数据盘,挂载到 /data26
sdc:系统盘,包含 /、/boot、swap
sdd:用户目录盘,挂载到 /home如果某块盘没有挂载点,比如:
text
sdb 894.3G说明它目前没有挂载到系统目录中。普通用户一般不要随便操作这种磁盘,避免误删数据。
5.2 案例
六、查看系统版本和 CUDA 环境
6.1 查看 Linux 系统版本
bash
cat /etc/os-release6.2 查看内核版本
bash
uname -a6.3 查看 CUDA 驱动支持版本
bash
nvidia-smi在顶部可以看到:
text
Driver Version: 535.261.03
CUDA Version: 12.2这里的 CUDA Version 表示当前显卡驱动支持的 CUDA 版本。
6.4 查看 PyTorch 是否能使用 GPU
bash
python - <<'PY'
import torch
print("torch version:", torch.__version__)
print("cuda available:", torch.cuda.is_available())
print("gpu count:", torch.cuda.device_count())
if torch.cuda.is_available():
for i in range(torch.cuda.device_count()):
print(i, torch.cuda.get_device_name(i))
PY如果输出:
text
cuda available: True
gpu count: 2
0 NVIDIA RTX A6000
1 NVIDIA RTX A6000说明 PyTorch 可以正常识别 GPU。
七、结合实际服务器做一个简要判断
以当前这台服务器为例,可以总结为:
text
GPU:
2 张 NVIDIA RTX A6000,每张约 48GB 显存。
CPU:
2 颗 Intel Xeon Silver 4210R。
总共 20 个物理核心,40 个逻辑线程。
内存:
30GB RAM,另有 47GB Swap。
RAM 不算特别大,运行大数据任务时要注意内存压力。
磁盘:
/home 剩余约 486GB。
/data26 剩余约 1.8TB,最适合放模型、数据集、仓库和实验结果。
CUDA:
驱动支持 CUDA 12.2。如果要运行 Qwen 7B 模型:
text
只做推理:不吃力。
LoRA / QLoRA 微调:可以,但最好清理 GPU 显存。
全参数微调:不太建议,显存、内存和优化器开销都比较大。需要注意:
text
GPU 显存是否已经被其他进程占用。
系统内存只有 30GB,加载大数据集时不要一次性全部读入内存。
模型和数据建议放到 /data26。八、一键查看服务器资源的 Bash 脚本
8.1 创建脚本
在服务器终端执行:
bash
vim check_server_info.sh然后粘贴下面脚本。
bash
#!/usr/bin/env bash
# ============================================
# check_server_info.sh
# 一键查看 Linux 服务器基础资源信息
# 包括:系统、CPU、内存、GPU、磁盘、Python/PyTorch GPU
# ============================================
set -u
REPORT_FILE="server_info_$(date +%Y%m%d_%H%M%S).txt"
print_section() {
echo
echo "============================================================"
echo "$1"
echo "============================================================"
}
run_cmd() {
local title="$1"
local cmd="$2"
print_section "$title"
echo "\$ $cmd"
eval "$cmd" 2>&1 || echo "[WARN] command failed: $cmd"
}
{
print_section "基础信息"
echo "当前时间: $(date)"
echo "主机名: $(hostname)"
echo "当前用户: $(whoami)"
echo "当前路径: $(pwd)"
if [ -f /etc/os-release ]; then
print_section "系统版本"
cat /etc/os-release
fi
run_cmd "内核版本" "uname -a"
if command -v lscpu >/dev/null 2>&1; then
print_section "CPU 信息"
lscpu | grep -E "Architecture|Model name|CPU\\(s\\)|Thread\\(s\\) per core|Core\\(s\\) per socket|Socket\\(s\\)|NUMA node\\(s\\)" || lscpu
echo
echo "逻辑 CPU 核心数: $(nproc 2>/dev/null || echo unknown)"
else
echo "[WARN] lscpu command not found"
fi
run_cmd "内存信息" "free -h"
if command -v nvidia-smi >/dev/null 2>&1; then
print_section "GPU 信息:nvidia-smi"
nvidia-smi
print_section "GPU 简要信息"
nvidia-smi --query-gpu=index,name,memory.total,memory.used,memory.free,utilization.gpu,temperature.gpu --format=csv
print_section "GPU 进程信息"
nvidia-smi --query-compute-apps=gpu_uuid,pid,process_name,used_memory --format=csv || true
else
print_section "GPU 信息"
echo "未检测到 nvidia-smi,可能没有 NVIDIA GPU,或者驱动未安装。"
fi
run_cmd "磁盘空间 df -h" "df -h"
if command -v lsblk >/dev/null 2>&1; then
run_cmd "磁盘挂载结构 lsblk" "lsblk"
fi
print_section "当前目录磁盘占用"
echo "\$ df -h ."
df -h . 2>&1 || true
echo
echo "\$ du -sh ."
du -sh . 2>&1 || echo "[WARN] 当前目录过大或无权限,统计失败。"
print_section "Python / PyTorch GPU 检测"
if command -v python >/dev/null 2>&1; then
python - <<'PY'
try:
import sys
print("python executable:", sys.executable)
print("python version:", sys.version.replace("\n", " "))
import torch
print("torch version:", torch.__version__)
print("cuda available:", torch.cuda.is_available())
print("gpu count:", torch.cuda.device_count())
if torch.cuda.is_available():
for i in range(torch.cuda.device_count()):
print(f"GPU {i}:", torch.cuda.get_device_name(i))
except ImportError:
print("未安装 PyTorch,跳过 torch.cuda 检测。")
except Exception as e:
print("PyTorch GPU 检测失败:", repr(e))
PY
else
echo "未检测到 python 命令。"
fi
print_section "检查完成"
echo "报告文件: $REPORT_FILE"
} | tee "$REPORT_FILE"保存并退出,键盘按下
bash
按 i 进入编辑模式
粘贴脚本
按 Esc
输入 :wq
回车保存退出8.2 给脚本执行权限
bash
chmod +x check_server_info.sh8.3 一键运行
bash
./check_server_info.sh运行后,它会在当前目录生成一个报告文件,例如:
text
server_info_20260604_224500.txt以后如果想发给别人分析服务器配置,直接发这个 txt 文件即可。
九、脚本输出怎么看
9.1 看 GPU
重点看:
text
GPU name
memory.total
memory.used
memory.free
utilization.gpu例如:
text
NVIDIA RTX A6000, 49140 MiB, 22826 MiB, 26314 MiB, 0 %表示:
text
总显存约 48GB
已用约 22.8GB
剩余约 26GB
当前计算利用率 0%9.2 看 CPU
重点看:
text
Model name
CPU(s)
Thread(s) per core
Core(s) per socket
Socket(s)例如:
text
CPU(s): 40
Socket(s): 2
Core(s) per socket: 10
Thread(s) per core: 2表示:
text
2 颗 CPU
每颗 10 个物理核心
每核 2 线程
总共 40 个逻辑线程9.3 看内存
重点看:
text
Mem total
Mem available
Swap used如果 available 很小,说明可用内存紧张。
如果 Swap used 很大,说明系统可能已经发生过内存压力。
9.4 看磁盘
重点看:
text
Mounted on
Avail
Use%例如:
text
/data26 Avail 1.8T
/home Avail 486G说明大数据更适合放到 /data26。
总结
查看服务器资源时,最常用的命令可以记住这几个:
bash
nvidia-smi
lscpu
free -h
df -h
lsblk它们分别对应:
text
nvidia-smi:查看 GPU 和显存
lscpu:查看 CPU
free -h:查看内存
df -h:查看磁盘空间
lsblk:查看磁盘挂载结构对于大模型实验来说,最重要的是:
text
显存够不够
GPU 是否被别人占用
内存是否紧张
磁盘是否有足够空间存模型和数据以当前服务器为例,2 张 RTX A6000 是非常好的 GPU 配置,运行 Qwen 7B 推理基本不吃力;但系统内存只有 30GB,运行大规模数据处理或训练时要注意内存压力。
一句话总结:
text
跑实验之前,先看资源;显存决定模型能不能跑,内存决定数据能不能撑住,磁盘决定模型和数据能不能放得下。