问题:朴素方式管 KV cache,浪费巨大
回忆模块一:每个请求在 decode 时,KV cache 会不断增长 (每生成一个 token 就追加一份 K、V)。问题来了------你事先不知道一个请求最终会生成多长。用户可能问一句话答 50 token 就结束,也可能让它写篇文章答 2000 token。
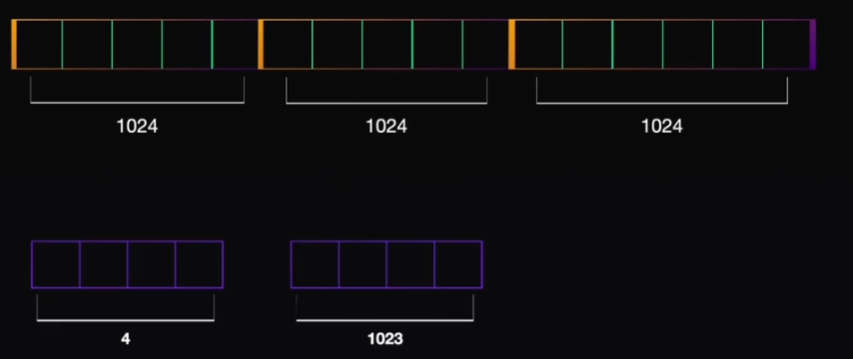
朴素的做法(vLLM 之前的框架就是这么干的):为每个请求预先分配一块连续的、按最大可能长度算的显存 。比如模型支持最大 2048 token,那就给每个请求都预留能装 2048 token 的 KV cache 连续空间。
这会造成两种严重浪费,记住这两个词,面试要用:
内部碎片(internal fragmentation) :你给一个请求预留了 2048 的空间,但它实际只生成了 50 token 就结束了------剩下 1998 个 token 的空间白占着、用不了。绝大部分预留空间都浪费了。
外部碎片(external fragmentation) :因为每个请求都要一块连续 的大空间,显存被切成大小不一的块,新请求来了即使总空闲显存够,却找不到一块足够大的连续空间塞进去------空间散落各处用不上。
研究测过,这种朴素方式下,KV cache 显存的实际利用率可能只有 20%-40%,六七成显存被碎片浪费了。而显存又是推理的命根子(还记得吗,KV cache 越大越能支持长序列和高并发)。浪费显存 = 直接限制了你能同时服务多少请求、能支持多长的对话。
这个问题你其实见过
想想阶段一你装系统、阶段二算显存------"要一块连续的大空间,但用不满"这个问题,和操作系统早期管内存遇到的问题一模一样 。早期程序也要连续内存,也面临碎片浪费。操作系统是怎么解决的?分页(paging)。PagedAttention 的名字就来自这里------它把 OS 的分页思想搬过来了。
方案:像 OS 分页一样管 KV cache
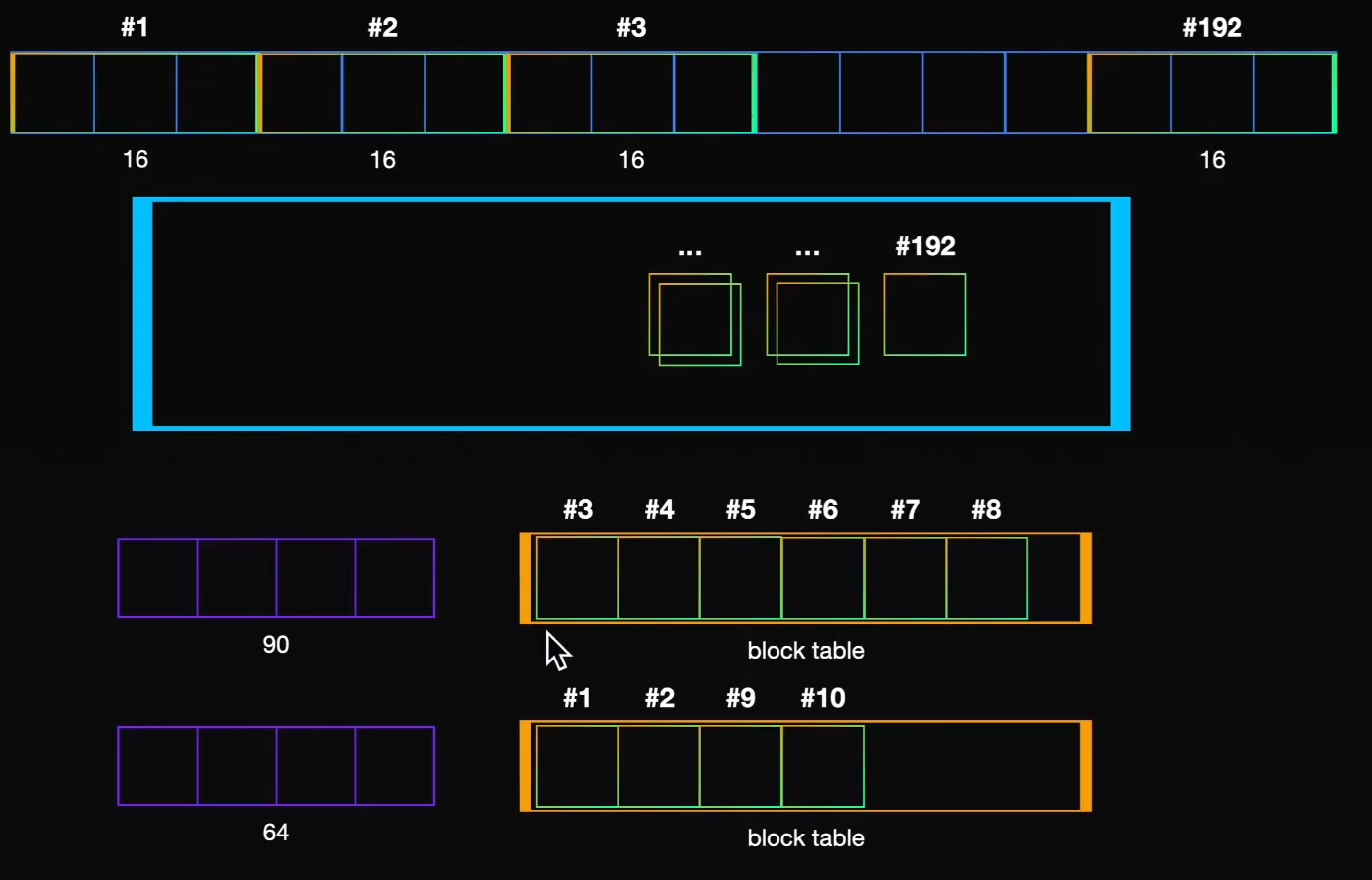
OS 分页的核心思想:不要求连续 。把内存切成固定大小的小块(页 page),程序需要多少就给多少页,这些页在物理内存里可以是分散的 ,用一张"页表"记录逻辑顺序到物理位置的映射。
PagedAttention 把这套照搬到 KV cache 上:
把 KV cache 切成固定大小的块(block) ,每块存固定数量 token 的 K、V(比如每块存 16 个 token)。一个请求的 KV cache 不再是一整块连续空间,而是按需一块一块地分配------生成了 16 个 token 就占一块,再生成 16 个再要一块。请求结束,它占的块立刻释放,还给别的请求用。
这些块在显存里物理上可以是分散的,vLLM 用一张**块表(block table)**记录"这个请求的第 N 段 token 在哪个物理块"------这就是 OS 页表的翻版。
为什么这样就解决了浪费
消灭内部碎片:按需分配,生成多少给多少块。一个请求只答 50 token,就占 4 块(50÷16≈4),不会预留 2048 的空间。浪费最多就是最后一块没填满的一点点(几个 token),从"浪费 1998"降到"浪费几个"。
消灭外部碎片:因为块是固定大小的,显存被切成一堆等大的块,任何空闲块都能拿给任何请求用------不存在"找不到连续大空间"的问题。新请求来了,凑几块空闲块就能跑。
结果:KV cache 显存利用率从 20%-40% 飙到接近 100% 。同样的显存,能装下多得多的请求的 KV cache → 能支持的并发量、序列长度大幅提升 → 吞吐大幅提高。这就是 vLLM 高吞吐的根本来源之一。
把它收成一张图,对照着记:

图里最后那行就是面试时的标准答法,背下来:PagedAttention 把 KV cache 切成固定块、按需非连续分配、用块表做映射,借鉴 OS 分页消除碎片,利用率接近 100%,从而支撑更高并发和更长序列。
再补一个额外的好处 ,它很重要、也常被追问------块可以共享 。既然 KV cache 是一块块的、靠块表映射,那如果多个请求有相同的前缀 (比如都用同一段 system prompt 开头),它们这段前缀的 KV 完全一样,就可以共用同几个物理块 ,不用各存一份。这就是你 vLLM 日志里看到的 enable_prefix_caching=True 的底层原理。它直接省显存、还省了重复计算前缀的时间。你看,PagedAttention 不只解决碎片,还顺带开启了"共享"这个新可能------这是分块设计带来的意外红利,跟 OS 里多个进程共享同一物理页(如共享库)又是一个对应。
PagedAttention 你现在理解到的层次,已经能在面试里讲透了:问题(两种碎片、利用率低)→ 方案(照搬 OS 分页、分块按需非连续 + 块表)→ 效果(利用率近 100%、高并发长序列)→ 红利(块共享 = prefix caching)。这套逻辑链比单纯说"它管理 KV cache 很高效"强太多,因为你能说清每一步的"为什么"。
而且你应该感受到了------这块之所以学得顺,是因为你前面的底子全用上了:阶段二的显存账(知道 KV cache 是什么、为什么占显存、为什么宝贵)、阶段一的 OS 概念(分页)。知识在这里复利了,这正是系统学习的回报。