第三期:应用问题与面试精讲------从线上故障到架构选型
免责声明:本文中所有 CloudMart 场景均为虚拟教学系统,仅用于串联技术知识点,不代表任何真实业务平台。
注意:本期篇目较长,各位按需点击目录跳转到需要的章节即可
目录
-
- [1.1 CloudMart 双十一故障现场](#1.1 CloudMart 双十一故障现场)
- [1.2 堆积根因分析框架](#1.2 堆积根因分析框架)
- [1.3 诊断三步法](#1.3 诊断三步法)
- [1.4 Lazy Queue 原理深度走读](#1.4 Lazy Queue 原理深度走读)
- [1.5 CloudMart 实战:三步解除堆积危机](#1.5 CloudMart 实战:三步解除堆积危机)
- [1.6 面试追问 6 问](#1.6 面试追问 6 问)
-
- [2.1 CloudMart 第二次事故:单节点宕机全站瘫痪](#2.1 CloudMart 第二次事故:单节点宕机全站瘫痪)
- [2.2 集群拓扑原理](#2.2 集群拓扑原理)
- [2.3 集群搭建实操](#2.3 集群搭建实操)
- [2.4 镜像队列](#2.4 镜像队列)
- [2.5 网络分区处理四大策略](#2.5 网络分区处理四大策略)
- [2.6 Quorum Queue 深度走读](#2.6 Quorum Queue 深度走读)
- [2.7 面试追问 6 问](#2.7 面试追问 6 问)
-
- [3.1 CloudMart 事故复盘:没有监控的代价](#3.1 CloudMart 事故复盘:没有监控的代价)
- [3.2 关键监控指标体系](#3.2 关键监控指标体系)
- [3.3 Prometheus + Grafana 方案](#3.3 Prometheus + Grafana 方案)
- [3.4 告警规则设计](#3.4 告警规则设计)
- [3.5 运维命令速查表](#3.5 运维命令速查表)
- [3.6 面试追问 5 问](#3.6 面试追问 5 问)
-
[模块四:RabbitMQ vs Kafka 终极对比](#模块四:RabbitMQ vs Kafka 终极对比)
- [4.1 CloudMart 技术选型评审](#4.1 CloudMart 技术选型评审)
- [4.2 架构级对比表](#4.2 架构级对比表)
- [4.3 性能场景决斗](#4.3 性能场景决斗)
- [4.4 Stream Queue 简介](#4.4 Stream Queue 简介)
- [4.5 选型决策树](#4.5 选型决策树)
- [4.6 面试追问 5 问](#4.6 面试追问 5 问)
开篇:从两个线上故障说起
20xx 年 11 月 11 日凌晨 0:03,CloudMart 双十一大促刚开闸 3 分钟,运维群炸了。
监控大屏上,订单服务的 RabbitMQ 队列消息堆积量从日常的 200 条暴拉到 50 万条,消费者处理延时从毫秒级飙升到 30 分钟。用户付完款看不到订单状态,客服电话被打爆。这是 CloudMart 遇到的第一次 RabbitMQ 生产事故。
祸不单行。第二周凌晨 3:00,运维对单节点 RabbitMQ 进行安全补丁重启,结果整个 CloudMart 订单链路全部中断------原因很简单:RabbitMQ 当时是单节点部署,没有任何高可用方案。
这两次事故暴露的问题,恰恰是 RabbitMQ 面试中最核心的两大主题:消息堆积诊断与处理 ,以及集群与高可用架构。本文将以 CloudMart 的真实故障为线索,逐一穿透这两个模块,并附上源码级走读和面试追问链。
模块一:消息堆积诊断与处理
1.1 CloudMart 双十一故障现场
故障时间线:
| 时间 | 事件 |
|---|---|
| 0:00 | 双十一开闸,流量瞬间涌入 |
| 0:03 | 订单队列 cloudmart.order.create 堆积突破 10W |
| 0:10 | 单个消费者 CPU 100%,处理速率从 500条/s 跌至 80条/s |
| 0:20 | 堆积达到 50W,消息延时超过 30 分钟 |
| 0:30 | 运维临时扩容消费者实例,堆积开始下降 |
初诊判断:消息生产速率远超消费速率,且消费者本身存在下游瓶颈(库存服务数据库连接池耗尽),形成"消费慢 → 堆积 → 内存压力 → 更慢"的恶性循环。
1.2 堆积根因分析框架
消息堆积的本质公式只一个:
堆积量 = 生产速率 * 时间 - 消费速率 * 时间当生产速率持续大于消费速率时,堆积必然发生。但根因需要逐层下钻,归纳为四类:
根因一:消费者处理慢(最常见)
消费者本身业务逻辑耗时长,典型场景如 CloudMart 订单创建需要同步调用库存扣减 + 积分计算 + 短信通知,单条处理耗时 200ms,单个消费者 QPS 上限仅 5。
代码示例------低效消费者:
java
// 反例:同步串行,单条耗时 200ms+
@RabbitListener(queues = "cloudmart.order.create")
public void onOrderCreate(OrderMessage msg) {
inventoryService.deductSync(msg.getSkuId(), msg.getQty()); // 80ms
pointsService.addPointsSync(msg.getUserId(), msg.getAmount()); // 60ms
smsService.sendSync(msg.getPhone(), "下单成功"); // 50ms
}根因二:prefetch 设置不当
RabbitMQ 默认无限制 prefetch(channel.basicQos(0)),消费者会一次性拉取所有未确认消息到本地缓冲区。当消费者处理慢时,大量消息堆积在客户端内存而非队列中,导致:
- 队列监控看起来"没堆积",但消息实际已被分发且未 ACK
- 消费者重启后消息全部 requeue,引发二次冲击
正确做法:
java
// 设置 prefetch = 50,公平分发
@Bean
public SimpleRabbitListenerContainerFactory rabbitListenerContainerFactory(
ConnectionFactory connectionFactory) {
SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();
factory.setConnectionFactory(connectionFactory);
factory.setPrefetchCount(50); // 每个消费者最多预取 50 条
return factory;
}根因三:队列无限增长(无 TTL / 无 max-length)
消息没有过期机制,也没有队列长度上限。一旦消费停滞,消息永久保留,堆积只增不减。
解决思路 :设置队列级别的 x-max-length 或消息级 x-message-ttl。但需要注意------溢出策略(overflow)默认是 drop-head,即丢弃队列头部最旧消息。CloudMart 对此做了定制化处理(见 1.5 节)。
根因四:下游依赖故障传导
消费者内部调用下游服务(数据库、缓存、第三方 API)超时或不可用,导致消息处理阻塞。这是 CloudMart 双十一故障的真正根因------库存服务的数据库连接池被秒杀流量打满,订单消费者内部 inventoryService.deductSync() 调用一直阻塞。
关键判断:如果消费者未 ACK 且未崩溃,RabbitMQ 不会将该消息重新投递给其他消费者,形成死锁式堆积。
1.3 诊断三步法
当监控报警"队列堆积"时,推荐以下诊断流程:

第一步:定位堆积队列
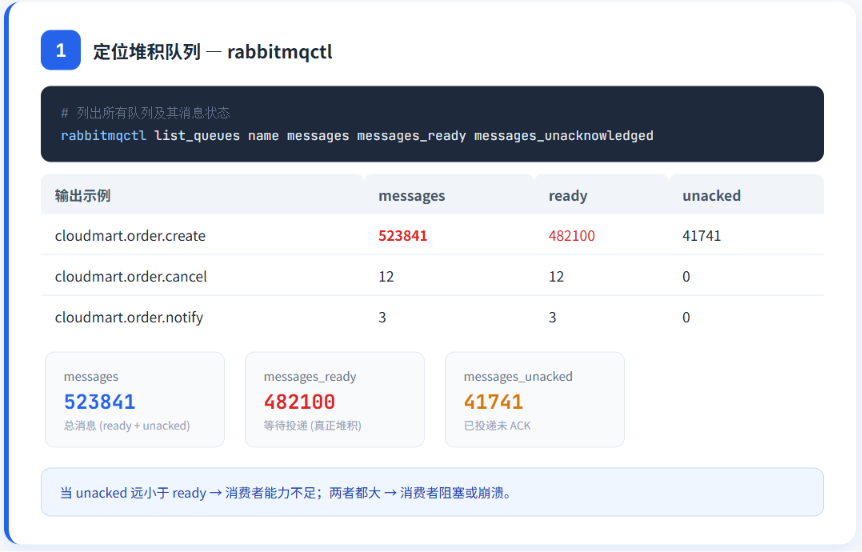
bash
# 列出所有队列及其消息数量
rabbitmqctl list_queues name messages messages_ready messages_unacknowledged输出示例(CloudMart 故障时):
cloudmart.order.create 523841 482100 41741
cloudmart.order.cancel 12 12 0
cloudmart.order.notify 3 3 0关键指标解读:
| 字段 | 含义 |
|---|---|
messages |
队列中总消息数(ready + unacknowledged) |
messages_ready |
等待投递的消息(真正意义的"堆积") |
messages_unacknowledged |
已投递但消费者未 ACK 的消息 |
当 messages_unacknowledged 远小于 messages_ready 时,说明消费者能力不足;当两者都很大时,说明消费者已经崩溃或被阻塞。
第二步:查看消费者速率
通过 Management API 获取队列的实时消费速率:
bash
curl -u admin:admin http://localhost:15672/api/queues/%2F/cloudmart.order.create | jq '.consumer_details[].channel_details'
关注 consumer_details 中的 prefetch_count 和 ack_required。如果 prefetch_count 为 0(无限制)且 ack_required 为 true,大量消息可能已被分发但未 ACK。
第三步:结合 Prometheus 趋势分析
RabbitMQ 内置 Prometheus 插件,关键指标:
# 队列消息数量趋势
rabbitmq_queue_messages{queue="cloudmart.order.create"}
# 消息发布速率
rabbitmq_queue_messages_published_total{queue="cloudmart.order.create"}
# 消息消费速率(手动 ACK 模式)
rabbitmq_queue_messages_delivered_total{queue="cloudmart.order.create"}
# 无 ACK 消息数
rabbitmq_queue_messages_unacked{queue="cloudmart.order.create"}通过 Grafana 面板对比 published 和 delivered 速率曲线,可以直观判断是生产端暴增还是消费端骤降。

1.4 Lazy Queue 原理深度走读
为什么 Lazy Queue 是消息堆积的克星?
普通队列将消息尽可能存储在内存中(目的是低延迟),但内存是有限的。当内存水位超过 vm_memory_high_watermark(默认 0.4,即 40%)时,RabbitMQ 会触发 Flow Control,阻塞所有生产者连接,导致整个集群的写入能力瘫痪。对于 CloudMart 双十一这种突发流量,Flow Control 会让故障从"一个队列堆积"扩散为"整个集群不可写"。
Lazy Queue 的设计哲学反其道而行之:消息尽可能存储在磁盘上,仅在消费时才加载到内存。
触发条件:内存水位
普通队列与 Lazy Queue 在内存行为上的差异:

换入换出机制:queue_index + segment 文件
Lazy Queue 的存储依赖两个核心文件组件:

消息发布到 Lazy Queue 时,RabbitMQ 直接将消息追加写入 segment 文件末尾,并在 queue_index 中插入一条索引记录。整个过程不涉及内存消息缓存,因此即使单队列堆积到千万级别,内存占用也极低。
消费时,消费者请求消息,RabbitMQ 通过 queue_index 定位到 segment 文件的对应偏移量,读取消息体并加载到内存交付给消费者。消费完成后,内存中的副本立即释放。
源码走读:rabbit_lazy_queue.erl
Lazy Queue 的实现入口在 deps/rabbit/src/rabbit_lazy_queue.erl(RabbitMQ 3.12+ 源码路径),关键函数:
函数 init/1(初始化回调):
erlang
%% deps/rabbit/src/rabbit_lazy_queue.erl
init([QueueName, State]) ->
%% 打开 segment 文件,初始化 queue_index 句柄
{ok, Segments} = rabbit_queue_index:init(QueueName, State),
%% 标记队列模式为 lazy
{ok, State#lazy_state{segments = Segments, mode = lazy}}.函数 publish/5(消息发布回调):
erlang
%% deps/rabbit/src/rabbit_lazy_queue.erl
publish(Msg, MsgProps, IsDelivered, ChPid, State) ->
%% 直接将消息写入 segment 文件,不入内存缓存
{ok, SegmentRef} = rabbit_queue_index:publish(Msg, MsgProps, State#lazy_state.segments),
%% 仅更新队列统计,不触碰内存消息体
NewState = update_stats(Msg, State),
{ok, NewState}.函数 fetch/2(消息拉取回调):
erlang
%% deps/rabbit/src/rabbit_lazy_queue.erl
fetch(AckRequired, State) ->
case rabbit_queue_index:next_segment_entry(State#lazy_state.segments) of
empty -> {empty, State};
{ok, Entry} ->
%% 从 segment 文件按偏移量读取消息体到内存
{ok, Msg} = rabbit_queue_index:read_entry(Entry),
{ok, Msg, State}
end.关键点总结:
- publish 阶段完全不走内存,直接落盘
- fetch 阶段按需从 segment 文件读入单条消息,消费后释放
- 内存中仅保留
queue_index的元数据(偏移量、长度),内存开销极低
深入:queue_index 的段文件管理------rabbit_queue_index.erl
Lazy Queue 的磁盘效率取决于 queue_index 模块对段文件(segment)的管理。其核心函数 publish/6 负责将消息追加到当前活跃的 segment 文件并更新索引:
erlang
%% deps/rabbit/src/rabbit_queue_index.erl
publish(Msg, MsgProps, IsDelivered, ChPid, JournalSizeHint, State) ->
%% 检查当前 segment 是否已满(默认 512MB)
case should_rollover(State, JournalSizeHint) of
true ->
%% 关闭当前 segment,创建新 segment 文件
{ok, NewState} = rollover_segment(State),
do_publish(Msg, MsgProps, NewState);
false ->
do_publish(Msg, MsgProps, State)
end.
do_publish(Msg, MsgProps, State) ->
%% 将消息序列化后追加写入 segment 文件末尾
SegEntry = rabbit_msg_store:write(State#qidx_state.msg_store, Msg, MsgProps),
%% 在 queue_index 中插入一条索引记录(segment_offset, msg_size)
ok = rabbit_queue_index:insert_entry(State#qidx_state.index, SegEntry),
{ok, State}.rollover_segment/1 和 should_rollover/2 负责段文件的轮转逻辑------当 segment 达到 512MB 上限时,关闭当前文件并打开新文件。这种设计避免了单个文件过大导致的随机读写性能衰减,同时让过期消息的删除可以以整个 segment 文件为单位进行(直接删除整个 segment 文件,而非逐条标记删除)。
深入:普通队列何时触发 page-out------rabbit_variable_queue.erl

普通队列(非 Lazy)并非完全不做磁盘写入。当消息量超过内存水位时,rabbit_variable_queue 模块的 maybe_page_out_to_disk/1 会被调用:
erlang
%% deps/rabbit/src/rabbit_variable_queue.erl
maybe_page_out_to_disk(State) ->
%% 计算当前内存中的消息总字节数
MemUsed = sum_msg_sizes(State#vq_state.memory_msgs),
%% 检查是否超过内部阈值(与 vm_memory_high_watermark 联动)
case MemUsed > State#vq_state.target_ram_count of
true ->
%% 批量将部分消息从内存迁移到磁盘(page-out)
{ToPage, Remaining} = split_for_paging(State#vq_state.memory_msgs),
ok = write_batch_to_disk(ToPage, State#vq_state.msg_store),
{ok, State#vq_state{memory_msgs = Remaining}};
false ->
{ok, State}
end.与 Lazy Queue "消息始终在磁盘"的策略不同,普通队列的 page-out 是被动触发的------仅在内存压力达到阈值时才将部分消息刷盘。这种机制的缺陷在于:刷盘本身消耗 IO,如果此时生产者速率仍然很高,内存写入和磁盘刷出同时发生,可能形成"IO 风暴",进一步拖慢整个 Broker。这也是 CloudMart 双十一场景下普通队列迅速陷入恶性循环的根本原因之一。
1.5 CloudMart 实战:三步解除堆积危机
回到双十一故障现场,CloudMart 运维团队执行了以下三步组合方案:
Step 1:扩容消费者
bash
# Spring Boot 应用扩容命令(Kubernetes 环境)
kubectl scale deployment cloudmart-order-consumer --replicas=20从原来的 3 个 Pod 扩容到 20 个,同时调整 prefetch 为合理值:
yaml
# application.yml
spring:
rabbitmq:
listener:
simple:
prefetch: 50 # 每消费者限预取 50 条
concurrency: 5 # 每 Pod 5 个消费者线程等效消费能力:20 Pods * 5 线程 * 20 QPS/线程 = 2000 QPS,匹配峰值生产速率。
Step 2:启用 Lazy Queue
对 cloudmart.order.create 队列重建(或通过 Policy 动态变更):
bash
# 方式一:声明队列时指定
rabbitmqadmin declare queue name=cloudmart.order.create \
durable=true \
arguments='{"x-queue-mode":"lazy"}'
# 方式二:通过 Policy 动态变更(推荐,无需删除重建)
rabbitmqctl set_policy LazyOrderCreate "^cloudmart\.order\.create$" \
'{"queue-mode":"lazy"}' --apply-to queuesPolicy 方式的好处是不需要删除已有队列,RabbitMQ 会自动将现有队列转换为 Lazy 模式。
Step 3:max-length 兜底 + 生产端限流
bash
# 设置队列最大长度 100W,溢出策略为 reject-publish(拒绝新消息而非丢弃头部)
rabbitmqctl set_policy OrderMaxLen "^cloudmart\.order\.create$" \
'{"max-length":1000000,"overflow":"reject-publish"}' --apply-to queuesoverflow: reject-publish 策略下,队列满时直接拒绝新消息并返回 basic.nack,生产端收到后进入限流等待或降级处理:
java
// 生产端收到 nack 后的处理
rabbitTemplate.setConfirmCallback((correlationData, ack, cause) -> {
if (!ack) {
// 限流:等待 100ms 后重试
Thread.sleep(100);
rabbitTemplate.convertAndSend(exchange, routingKey, message);
}
});效果对比:
| 指标 | 优化前 | 优化后 |
|---|---|---|
| 高峰期堆积 | 50W+ | < 2000 |
| 消息延时 | 30 分钟 | < 1 秒 |
| 消费者 CPU | 100% | 45% |
| 内存消耗 | 触发 Flow Control | 稳定在 30% |
1.6 面试追问 6 问
Q1:消息堆积和消息积压是一回事吗?
是的。堆积/积压均指队列中 messages_ready 持续增长的现象。面试中更常用"消息堆积"。
追问层 :如何区分是生产太快还是消费太慢?
答:看 Prometheus 的 published 和 delivered 两条曲线------如果 published 暴涨而 delivered 平稳,是生产突发;如果 delivered 骤降而 published 稳定,是消费者瓶颈。
Q2:Lazy Queue 的代价是什么?
吞吐量下降约 20%-30%(每次消费需要磁盘 IO),延迟从微秒级增加到毫秒级。适合高堆积、低延迟不敏感的场景(如订单异步处理),不适合低延迟场景(如实时竞价)。
追问层 :Lazy Queue 和普通队列可以动态切换吗?
答:可以通过 Policy 动态切换。Policy 生效后,新到达的消息立即按新模式存储;已有消息的存储方式不变(仍在内存或磁盘上保持原状),消费完成后自然过渡。
Q3:prefetch=1 是否最佳实践?
不是。prefetch=1 保证公平分发但严重浪费网络带宽和处理能力。推荐值:处理耗时的任务设 10-50,轻量任务设 100-250。需要压测调优。
追问层 :prefetch 和 consumer concurrency 的关系?
答:prefetch 是 channel 级别,控制单个 channel 未 ACK 消息上限;concurrency 是消费者线程数。总内存占用 = prefetch * concurrency * 平均消息大小。
Q4:消息堆积到磁盘满了怎么办?
设置 disk_free_limit 阈值,低于该值时 RabbitMQ 会阻塞生产者(默认 50MB)。同时建议设置 max-length 或 max-length-bytes 硬限制队列大小。
追问层 :堆积消息可以迁移到另一个队列吗?
答:可以使用 Shovel 插件将堆积消息从源队列转移到另一个队列(或另一个节点),但 Shovel 本身也是消费者,会逐条消费和重发布,速度取决于消费速率。
Q5:为什么不用 TTL + 死信来清理堆积?
TTL 清理的效果是"过期丢弃"或"转发到死信队列",并不能加速处理有效消息。适合清理超时无效消息(如 30 分钟未支付的订单),不适合清理需要正常处理的堆积。
Q6:prefetch=0 时 unack 消息算堆积吗?
严格来说不算队列堆积(队列中 messages_ready 可能为 0),但算"客户端堆积"------消息已在消费者内存中但未处理完成。风险在于消费者崩溃后全部 requeue,形成二次冲击。
模块小结 :消息堆积的解决不是改一个参数就能搞定的事。从
rabbitmqctl list_queues定位问题队列,到 Management API 判断消费者能力,再到 Prometheus 看趋势------三步诊断覆盖了排查的全链路。Lazy Queue 通过"消息尽量落盘"的策略,以约 20% 的吞吐代价换来了堆积极限场景下的稳定性。记住根因四分类和流程:诊断→扩容+Lazy Queue→max-length 兜底。
模块二:集群与高可用架构
2.1 CloudMart 第二次事故:单节点宕机全站瘫痪
双十一故障刚平息一周,CloudMart 又遭遇了第二次事故。
2025 年 11 月 18 日凌晨 3:00,运维执行 RabbitMQ 安全补丁重启。由于 RabbitMQ 是单节点部署,重启期间所有队列、交换机、绑定关系全部不可用。CloudMart 订单创建、库存扣减、物流通知等 6 个核心服务同时中断,持续时间 12 分钟。
直接后果:期间产生的 3200 笔订单消息全部丢失(消息未开启持久化 + 无镜像节点),需要人工从数据库日志逐条补录。
教训:生产环境 RabbitMQ 必须有集群 + 镜像/Quorum Queue 保障。这也是本节要讨论的全部内容。
2.2 集群拓扑原理
Disk Node vs RAM Node
RabbitMQ 集群中有两种节点类型:
| 类型 | 元数据存储 | 重启后 | 适用场景 |
|---|---|---|---|
| Disk Node | 磁盘(Mnesia) | 元数据保留 | 至少保留 1 个,作为元数据锚点 |
| RAM Node | 内存(Mnesia) | 元数据丢失,需从 Disk Node 同步 | 纯消息处理节点,性能更好 |
关键规则 :集群中至少有一个 Disk Node,否则重启后全部元数据丢失。
Mnesia 元数据同步
RabbitMQ 使用 Erlang 内置的分布式数据库 Mnesia 来存储所有元数据------队列定义、交换机定义、绑定关系、用户权限等。但消息本身不存储在 Mnesia 中,消息存储在各节点的本地消息存储系统(msg_store)。
Mnesia 的工作机制:

这意味着:队列的"定义"全集群可见,但队列的"消息体"仅在队列 master 所在节点。这也是为什么单节点宕机会导致该节点上的队列消息全部不可用------消息体没有副本。
Erlang Cookie
集群节点之间的通信基于 Erlang 的分布式协议,认证依赖于 Erlang Cookie ------一个存放在 $HOME/.erlang.cookie 文件中的字符串。集群中所有节点的 Cookie 必须一致,否则节点间无法建立连接。
bash
# 查看当前 Cookie
cat ~/.erlang.cookie
# 或者
rabbitmqctl eval 'io:format("~s~n", [erlang:get_cookie()]).'2.3 集群搭建实操
以三节点集群为例(node1 为 Disk Node,node2、node3 为 RAM Node):
环境假设:
| 节点 | 主机名 | 类型 |
|---|---|---|
| node1 | rmq-node1.cloudmart.internal | Disk Node |
| node2 | rmq-node2.cloudmart.internal | RAM Node |
| node3 | rmq-node3.cloudmart.internal | RAM Node |
步骤一:同步 Erlang Cookie
bash
# 在 node1 上获取 Cookie
cat /var/lib/rabbitmq/.erlang.cookie
# 将 Cookie 内容复制到 node2、node3 的同一路径
# 注意:文件权限必须为 400
chmod 400 /var/lib/rabbitmq/.erlang.cookie步骤二:启动各节点 RabbitMQ 服务
bash
# 三台节点分别执行
systemctl start rabbitmq-server
rabbitmq-plugins enable rabbitmq_management步骤三:组建集群
bash
# 在 node2 上执行------将 node2 加入 node1 的集群(作为 RAM Node)
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster rabbit@rmq-node1 --ram
rabbitmqctl start_app
# 在 node3 上执行------同理
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster rabbit@rmq-node1 --ram
rabbitmqctl start_app步骤四:验证集群状态
bash
rabbitmqctl cluster_status输出示例:
Cluster status of node rabbit@rmq-node1 ...
Basics
Cluster name: rabbit@rmq-node1.cloudmart.internal
Total memory used: 256 MB
Disk Nodes
rabbit@rmq-node1
RAM Nodes
rabbit@rmq-node2
rabbit@rmq-node3
Running Nodes
rabbit@rmq-node1
rabbit@rmq-node2
rabbit@rmq-node3步骤五:设置高可用策略
bash
# 对所有以 "cloudmart." 开头的队列启用镜像到所有节点
rabbitmqctl set_policy ha-cloudmart "^cloudmart\." \
'{"ha-mode":"all","ha-sync-mode":"automatic"}' \
--priority 1 --apply-to queues2.4 镜像队列
集群搭建完成并不等于高可用。普通集群中,队列的消息体仅存储在创建该队列的节点(master)。master 宕机后,该队列的消息在 master 恢复前完全不可用。
镜像队列(Mirrored Queue) 解决了这个问题:每个队列有一个 master 和多个 mirror(镜像),消息写入 master 后同步复制到所有 mirror。
Master-Slave 同步机制
Publisher → Master → GM 组播 → Mirror-1
→ Mirror-2
→ Mirror-N
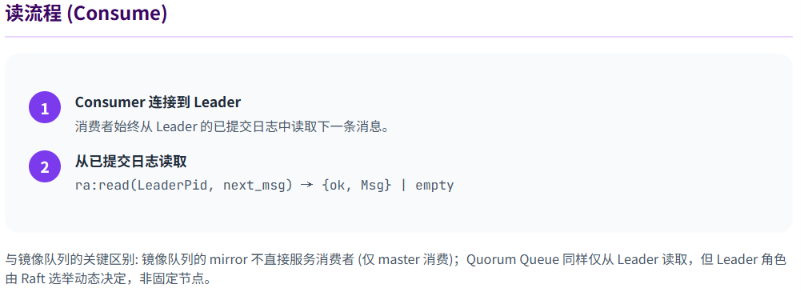
Consumer ← Master (仅从 master 消费)关键规则:
- 消息发布到 master,由 master 负责同步到所有 mirror
- 消费者仅从 master 拉取消息,mirror 不直接服务消费者
- master 宕机后,资格最老的 mirror 自动提升为新的 master
GM 组播协议
镜像队列使用 Erlang 的 GM(Guaranteed Multicast) 协议进行 master 到 mirror 的消息广播。GM 协议保证:
- 原子性:一条消息要么同步到所有在线 mirror,要么一个都不同步
- 有序性:mirror 接收到消息的顺序与 master 发布顺序一致
- 成员变更:当 mirror 加入或离开时,协议自动处理视图变更
同步阻塞问题:
GM 协议的代价是同步阻塞。当 ha-sync-mode 设置为 automatic 时,新加入的 mirror 需要全量同步已有消息,同步期间整个队列会被阻塞。对于堆积量大的队列(如 CloudMart 双十一后的 50W 堆积),同步可能耗时数分钟,期间队列不可用。
配置参数:
| 参数 | 可选值 | 说明 |
|---|---|---|
ha-mode |
all / exactly / nodes |
all=全节点镜像 / exactly=指定数量镜像 / nodes=指定节点镜像 |
ha-sync-mode |
automatic / manual |
automatic=新 mirror 自动同步 / manual=手动触发同步 |
ha-params |
数字或节点列表 | 配合 exactly/nodes 使用 |
ha-sync-batch-size |
整数(默认 40000) | 同步时每批次消息数量 |
CloudMart 推荐配置:
bash
rabbitmqctl set_policy ha-cloudmart "^cloudmart\." \
'{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic","ha-sync-batch-size":10000}' \
--priority 1 --apply-to queues说明:每条消息在 2 个节点有副本(master + 1 个 mirror),牺牲一定冗余换取同步性能(同步节点越多,GM 组播延迟越大)。
2.5 网络分区处理四大策略
集群环境中最棘手的问题不是节点宕机,而是网络分区(Network Partition / Split-Brain)。当集群节点之间的网络出现中断,集群分裂为两个或多个互相不可达的子集群,每个子集群都以为自己是"唯一的集群",继续独立接收消息。网络恢复后,双方的数据如何合并?
RabbitMQ 提供四种分区处理策略:
策略一:ignore(忽略)
行为:不检测分区,各子集群独立运行,网络恢复后也不自动合并。
后果:网络恢复后会出现两个独立的集群,数据不一致,需手动处理。决策建议:仅适用于网络极度可靠的局域网环境,生产环境不建议使用。
策略二:pause-minority(暂停少数派)
检测到分区 → 判断当前节点所在子集群是否包含多数节点(> N/2)
├── 是多数派 → 继续运行
└── 是少数派 → 暂停所有连接(TCP 监听关闭),等待网络恢复决策树:
3 节点集群,分区为 [A, B] | [C]:
[A, B]:2 节点 = 多数 → 继续服务
[C]: 1 节点 = 少数 → 暂停,等待恢复
网络恢复后:[C] 发现自己落后,从 [A, B] 同步数据,自动恢复。适用场景:奇数节点集群。如果节点数为偶数(如 4 节点),可能出现 2 vs 2 平局,双方都暂停,集群完全不可用------这是 pause-minority 在偶数节点集群中的致命缺陷。
策略三:autoheal(自动修复)
检测到分区 → 各子集群独立运行
网络恢复 → 选择"赢家"子集群(客户端连接最多的),其他子集群重启并入赢家关键问题 :autoheal 的重启不是节点进程重启,而是将所有队列数据丢弃 后重新从赢家同步。这意味着输家子集群中在网络分区期间接收的消息全部丢失。CloudMart 评估后认为不可接受------分区期间恰好是订单高峰期时,丢消息是灾难级的。
策略四:pause-if-all-down(全部不可达时暂停)
检测到分区 → 列出配置的"关键节点列表"
├── 列表中所有节点都不可达 → 暂停当前节点
└── 列表中至少一个节点可达 → 继续运行默认的关键节点列表为空,此策略退化为永远不暂停(等价于 ignore)。需要显式配置:
bash
# 配置:如果 rabbit@rmq-node1 和 rabbit@rmq-node2 都不可达,当前节点暂停
rabbitmqctl set_cluster_handling_strategy pause_if_all_down \
recovery_nodes=["rabbit@rmq-node1","rabbit@rmq-node2"]CloudMart 的选择:
| 策略 | 评估 | 结论 |
|---|---|---|
| ignore | 网络恢复后数据不一致,手动处理风险高 | 淘汰 |
| pause-minority | 3 节点集群,少数派暂停保证数据一致 | 待选 |
| autoheal | 输家数据丢失 | 淘汰 |
| pause-if-all-down | 灵活性高但配置复杂,依赖人工判断关键节点 | 备选 |
最终选择 pause-minority,配合 3 节点集群(奇数节点避开平局)。
2.6 Quorum Queue 深度走读
镜像队列的 GM 组播协议存在天然缺陷:同步阻塞、脑裂风险、网络分区后数据合并复杂。RabbitMQ 3.8 引入的 Quorum Queue(仲裁队列) 从根本上改变了设计------基于 Raft 共识协议,以"大多数节点确认即提交"替代"全部镜像同步"。
Raft 协议在 Quorum Queue 中的角色
Raft 协议将节点分为三种角色:
| 角色 | 职责 |
|---|---|
| Leader | 处理所有读写请求,日志复制到 Followers |
| Follower | 被动接收 Leader 的日志复制 |
| Candidate | Leader 失联期间的竞选过渡状态 |
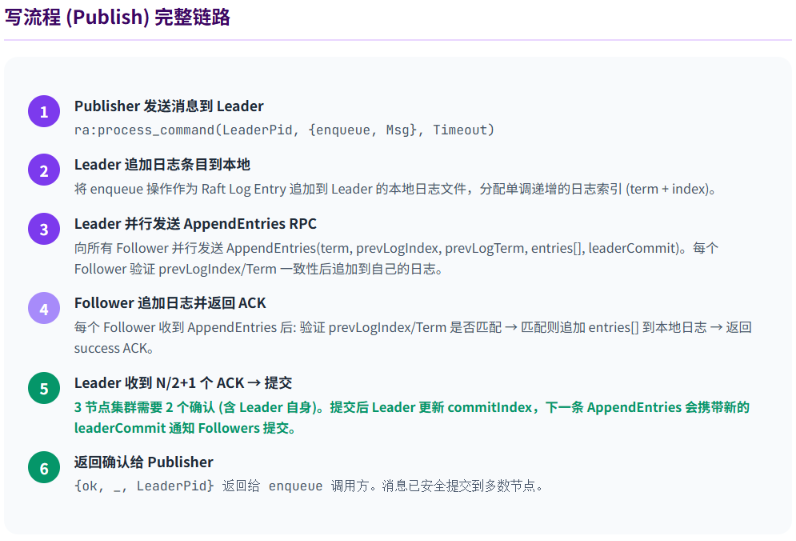
Quorum Queue 的读写流程:
与镜像队列的关键区别:
| 维度 | 镜像队列 | Quorum Queue |
|---|---|---|
| 共识协议 | GM 组播(全量同步) | Raft(多数确认) |
| 写确认条件 | 所有 mirror 确认 | N/2+1 节点确认 |
| 同步阻塞 | 新 mirror 加入时全量同步,阻塞队列 | 新节点增量追赶,不阻塞 |
| 脑裂处理 | 依赖集群分区策略(pause-minority 等) | Raft 内置 Leader 选举,自动拒绝少数派 |
| 消息持久化 | 可选 | 强制(每条消息 fsync 落盘) |
| 适用版本 | 3.6+(3.12 已不推荐) | 3.8+(推荐) |
源码走读:rabbit_mirror_queue_master.erl
镜像队列的发布流程核心在 rabbit_mirror_queue_master.erl 的 handle_cast({publish, ...}) 中:
erlang
%% deps/rabbit/src/rabbit_mirror_queue_master.erl
handle_cast({publish, Msg, MsgProps, ChPid, Flow},
State = #state{slaves = Slaves}) ->
%% 1. 先写入 master 本地
{ok, NewState} = rabbit_amqqueue_process:publish_local(Msg, MsgProps, State),
%% 2. 通过 GM 协议广播到所有 slave
case Slaves of
[] ->
%% 无 slave,直接返回确认
gen_server2:reply(ChPid, ok);
_ ->
%% 构造 GM 广播消息
GMMsg = {publish, Msg, MsgProps, ChPid},
%% 组播到所有 slave,等待全部确认
ok = rabbit_mirror_queue_slave:publish_to_all(Slaves, GMMsg),
NewState
end,
{noreply, NewState}.这个函数揭示了镜像队列的写放大问题:一条消息需要串行 写入 master 本地 → 再并行 广播到 N 个 slave → 等待全部 slave 确认后才返回 Publisher ACK。当 ha-mode=all 且集群有 5 个节点时,每条消息需要等待 5 次磁盘写入完成。这也是为什么官方推荐 ha-mode=exactly + ha-params=2(只需 2 个副本)而非全节点镜像。
深入:Raft 日志应用到状态机------rabbit_fifo_index.erl
Quorum Queue 的 Raft 日志提交后,需要通过 rabbit_fifo_index 模块的 apply_entries/2 将日志条目应用于状态机(即队列的实际消息状态):
erlang
%% deps/rabbit/src/rabbit_fifo_index.erl
apply_entries([], State) ->
{ok, State};
apply_entries([{Idx, {enqueue, Msg, MsgProps}} | Rest], State) ->
%% 将已提交的消息追加到队列索引
NewState = append_to_index(Idx, Msg, MsgProps, State),
apply_entries(Rest, NewState);
apply_entries([{Idx, {dequeue, ConsumerTag}} | Rest], State) ->
%% 将消费进度更新到索引(标记消息为已消费)
NewState = mark_consumed(Idx, ConsumerTag, State),
apply_entries(Rest, NewState).
append_to_index(Idx, Msg, MsgProps, State) ->
%% 追加到内存中的 segment 索引结构
Entry = #{idx => Idx, msg => Msg, props => MsgProps},
State#fifo_state{entries = gb_trees:insert(Idx, Entry, State#fifo_state.entries)}.apply_entries/2 是 Raft 状态机的核心------它将已提交的 Raft 日志条目({enqueue, Msg} 或 {dequeue, ConsumerTag})转化为对内存中 gb_trees 索引的增删操作。因为 Raft 保证日志的顺序性和一致性,apply_entries 只需按日志索引顺序执行即可,无需额外的冲突检测。随着消息量增长,gb_trees 会自动转为磁盘索引(类似 Lazy Queue 的 queue_index),保持内存可控。
源码走读:rabbit_fifo_client.erl
Quorum Queue 的客户端实现位于 deps/rabbit/src/rabbit_fifo_client.erl(RabbitMQ 3.12+),关键函数:
函数 enqueue/4(入队):
erlang
%% deps/rabbit/src/rabbit_fifo_client.erl
enqueue(LeaderPid, QueueName, Msg, Timeout) ->
%% 构造 Raft 日志条目
Entry = #{op => enqueue, msg => Msg},
%% 发起 Raft 提案,等待多数节点确认
case ra:process_command(LeaderPid, Entry, Timeout) of
{ok, _, LeaderPid} ->
%% 多数节点确认 → 提交成功
ok;
{error, timeout} ->
%% 等待超时 → 可能 Leader 已宕机,触发重选举
{error, timeout};
{error, not_leader} ->
%% 当前节点不是 Leader → 重定向到新 Leader
{error, not_leader}
end.函数 dequeue/2(出队):
erlang
%% deps/rabbit/src/rabbit_fifo_client.erl
dequeue(LeaderPid, ConsumerTag) ->
%% 从 Leader 的已提交日志中取出下一条消息
case ra:read(LeaderPid, next_msg) of
{ok, Msg} ->
{ok, Msg};
empty ->
empty
end.Raft 日志复制入口(ra 模块):
ra:process_command/3 内部触发 Raft 日志复制流程:
Leader 将 Entry 追加到本地日志
→ 并行发送 AppendEntries RPC 到所有 Follower
→ 每个 Follower 收到后追加到自己的日志并返回 ACK
→ Leader 收到 N/2+1 个 ACK(含自身)→ 提交
→ Leader 返回 {ok, _, LeaderPid} 给调用方注意事项:
- Quorum Queue 的消息强制持久化(每条消息 fsync 到磁盘),无法关闭。不适合低延迟 + 高吞吐的临时数据场景。
x-quorum-initial-group-size仅在队列首次创建时生效,已创建的队列无法修改。- Quorum Queue 不支持 TTL 和 max-length(消息生命周期由应用层管理)。
2.7 面试追问 6 问
Q1:RabbitMQ 集群中,任意节点可以访问任意队列吗?
路由层面可以------任意节点知道所有队列的元数据(通过 Mnesia 同步)。但消息体层面不可以------如果消费者连接到 node2,但目标队列的 master 在 node1,请求会被内部路由到 node1 获取消息。这带来额外的集群内部网络开销。
追问层 :如何避免跨节点消费?
答:使用队列主定位(Queue Master Locator)策略,如 client-local------让队列的 master 优先创建在第一个连接该队列的客户端所在节点。
Q2:镜像队列的同步阻塞如何缓解?
三个方向:① 设置 ha-sync-batch-size 减小每批同步消息数,降低 CPU 峰值;② 在低峰期手动触发同步(rabbitmqctl sync_queue);③ 切换到 Quorum Queue(增量追赶,无全量同步阻塞)。
追问层 :同步期间队列是否可用?
答:ha-sync-mode=automatic 下,同步期间队列不可用 (阻塞)。ha-sync-mode=manual 下,手动触发同步期间队列同样不可用。
Q3:Quorum Queue 为什么比镜像队列更抗脑裂?
镜像队列依赖外部分区策略(pause-minority / autoheal),而 Quorum Queue 的 Raft 协议内置了 Leader 选举和少数派拒绝。当网络分区发生时,少数派子集群中无法获得多数票,无法选出 Leader,自动拒绝所有读写。不需要依赖 RabbitMQ 集群级别的分区策略。
Q4:Quorum Queue 3 节点,允许几个节点宕机?
允许 1 个节点宕机(3/2+1 = 2 个节点确认即可提交)。宕 2 个节点时,仅剩 1 个节点无法形成多数,队列不可用但数据不丢失(已提交日志在磁盘上保留)。
追问层 :宕机节点恢复后数据如何同步?
答:Raft 的日志追赶机制:恢复节点向 Leader 发送自己的最后日志索引,Leader 将缺失的日志增量发送过去,无需全量同步。
Q5:Disk Node 宕机后 RAM Node 还能工作吗?
可以。RAM Node 将元数据缓存在内存中,Disk Node 宕机后已有元数据不受影响。但无法创建新的队列/交换机/绑定(写入操作需要 Disk Node 确认)。这提示生产环境应该保留多个 Disk Node。
Q6:网络分区期间 pause-minority 策略下,少数派节点上的消息会丢失吗?
不会。少数派节点暂停后停止接收新消息,但已有消息被持久化保留在磁盘。网络恢复后,少数派节点重新加入集群并从多数派同步元数据,期间收到的消息不会丢失(因为根本没收到)。但存在一个问题:如果分区期间,生产者的 publish 操作在少数派暂停前刚好投递了一条消息并被 broker 确认------这条消息实际上没有被多数派复制,但生产端已收到确认。这种情况极少但理论上存在,Quorum Queue 的 Raft 协议通过多数确认机制彻底规避了此风险。
模块小结:集群不等于高可用------普通集群的消息体无副本,master 宕机队列即不可用。镜像队列通过 GM 组播实现全量副本同步,但同步阻塞和脑裂是其痛点。Quorum Queue 用 Raft 协议的多数确认机制从根本上解决了脑裂问题,是 RabbitMQ 3.8+ 的高可用首选。网络分区场景下,pause-minority + 奇数节点是对大多数生产环境最安全的选择。
模块三:监控与运维体系
3.1 CloudMart 事故复盘:没有监控的代价
两次事故后,CloudMart CTO 召开了复盘会议。一个尖锐的问题被抛出来:
"双十一当天,队列堆积到 30 万的时候,为什么没有人知道?"
答案很残酷:当时 CloudMart 根本没有 RabbitMQ 监控体系。运维团队靠用户投诉感知故障,靠经验拍脑袋扩容。从发现问题到开始处理,实际耗时 27 分钟------其中 25 分钟浪费在"确认是不是真的故障"上。
事故后,运维团队花了两周时间搭建了完整的 RabbitMQ 监控+告警体系。本模块就是这份血泪经验的总结。
3.2 关键监控指标体系
RabbitMQ 监控不是越多越好,而是要在海量指标中抓住真正会引发故障的核心信号。CloudMart 最终圈定了以下 9 个一级指标:
吞吐量类
| 指标 | Prometheus Metric | 正常范围 | 告警阈值 | 超标后果 |
|---|---|---|---|---|
| 消息发布速率 | rabbitmq_queue_messages_published_total |
参照基线 | 偏离基线 ±200% | 生产者异常暴增或断流 |
| 消息投递速率 | rabbitmq_queue_messages_delivered_total |
参照基线 | 偏离基线 -50% | 消费者处理能力骤降 |
| 消息确认速率 | rabbitmq_queue_messages_acked_total |
接近 deliver rate | ack_rate / deliver_rate < 0.8 | 大量消息未确认,消费者阻塞 |
解读方法 :以 CloudMart 日常基线(00:00-06:00 低谷期约 200 msg/s,10:00-22:00 高峰期约 2000 msg/s)为参考。Prometheus 中使用 rate() 函数计算每秒速率:
rate(rabbitmq_queue_messages_published_total{queue="cloudmart.order.create"}[5m])积压类
| 指标 | Prometheus Metric | 正常范围 | 告警阈值 | 超标后果 |
|---|---|---|---|---|
| 队列深度 | rabbitmq_queue_messages |
< 5000 | > 100000(Warning) / > 500000(Critical) | 消息延时增加,内存压力上升 |
| Ready 消息数 | rabbitmq_queue_messages_ready |
接近队列深度 | 持续增长(斜率 > 0 持续 10 分钟) | 消费者停止拉取或能力不足 |
| Unacked 消息数 | rabbitmq_queue_messages_unacked |
< 1000 | 持续增长 | 消费者阻塞或 crash |
关键技巧 :不要只看绝对值,还要看一阶导数(变化率)。一条队列深度从 100 涨到 5000 用了一周,不需要告警;从 100 涨到 5000 用了 10 秒,必须立即响应。
资源类
| 指标 | Prometheus Metric | 正常范围 | 告警阈值 | 超标后果 |
|---|---|---|---|---|
| 内存水位 | rabbitmq_resident_memory_limit_bytes / rabbitmq_process_resident_memory_bytes |
< 0.5(50%) | > 0.8(Warning) / > 0.95(Critical) | 触发 Flow Control,阻塞所有生产者 |
| 磁盘剩余 | rabbitmq_disk_space_available_bytes |
> 5GB | < 2GB(Critical) | 触发磁盘告警,阻塞所有生产者 |
| 文件描述符 | rabbitmq_process_open_fds |
< 50% of limit | > 80% of limit | 无法接受新连接,集群不可用 |
| Socket 连接数 | rabbitmq_connections_total |
参照基线 | 下降 > 50%(10 分钟内) | 消费者批量掉线 |
| GC 次数与耗时 | erlang_vm_gc_reclaimed_bytes_total 的 rate |
稳定 | GC 耗时 > 500ms/次 | Erlang VM 内存压力大,响应变慢 |
内存告警与磁盘告警的区别:
| 维度 | 内存告警 | 磁盘告警 |
|---|---|---|
| 触发条件 | 内存使用超过 vm_memory_high_watermark(默认 0.4) |
磁盘剩余低于 disk_free_limit(默认 50MB) |
| 影响范围 | 阻塞所有生产者连接(Flow Control) | 阻塞所有生产者连接 |
| 恢复条件 | 内存回落至 watermark 以下 | 磁盘空间回升至 limit 的 2 倍 |
| 应急手段 | 启用 Lazy Queue / 扩容节点 | 清理日志 / 扩容磁盘 / 迁移队列 |
GC 指标的特殊性 :RabbitMQ 运行在 Erlang VM 上,Erlang 的 GC 是进程级而非全局 STW。但高 GC 耗时通常意味着 Erlang 进程堆积了大量消息引用(消息体在内存中),这是"队列模式选错(未用 Lazy Queue / Quorum Queue)"的典型信号。
深入:Management API 的指标采集链路------rabbit_mgmt_wm_queue_status.erl
读者可能会问:Prometheus 插件暴露的 rabbitmq_queue_messages_ready 指标,和 rabbitmqctl list_queues 看到的数据来自同一个数据源吗?是的------它们都通过 Management 插件的内部 API 获取,核心入口在 rabbit_mgmt_wm_queue_status.erl 的 to_json/2:
erlang
%% deps/rabbitmq_management/src/rabbit_mgmt_wm_queue_status.erl
to_json(ReqData, Context) ->
%% 解析 URL 中的 vhost 和 queue 名
VHost = cowboy_req:binding(vhost, ReqData),
QueueName = cowboy_req:binding(queue, ReqData),
%% 从 RabbitMQ 内部状态表中读取队列实时统计数据
case rabbit_amqqueue:lookup(rabbit_misc:r(VHost, queue, QueueName)) of
{ok, Q} ->
%% 获取队列的各类统计计数器
Stats = rabbit_amqqueue:stats(Q),
%% 构造成 JSON 返回
{ok, format_stats(Stats, ReqData), Context};
{error, not_found} ->
{halt, rabbit_mgmt_util:not_found(<<"Queue not found">>, ReqData, Context)}
end.
format_stats(Stats, _ReqData) ->
[
{messages, proplists:get_value(messages, Stats, 0)},
{messages_ready, proplists:get_value(messages_ready, Stats, 0)},
{messages_unacked, proplists:get_value(messages_unacknowledged, Stats, 0)},
{consumers, proplists:get_value(consumers, Stats, 0)},
{message_stats, format_message_rates(Stats)}
].这段代码解释了为什么 rabbitmqctl list_queues、Management HTTP API 和 Prometheus 插件输出的指标值完全一致:它们共享同一个数据源------RabbitMQ 内部状态表中维护的队列统计计数器。Prometheus 插件只是将这些计数器按 Prometheus 数据模型重新组织暴露。理解这一点对故障排查至关重要:如果三个入口返回的指标不一致,说明 Erlang 节点之间的 Mnesia 同步出现了延迟或分裂。
3.3 Prometheus + Grafana 方案
Step 1:启用 rabbitmq_prometheus 插件
bash
# 所有集群节点执行
rabbitmq-plugins enable rabbitmq_prometheus
# 验证(访问 metrics 端点)
curl http://localhost:15692/metrics | head -30RabbitMQ 3.12+ 内置 Prometheus 插件,暴露端口 15692。与老旧的 rabbitmq_prometheus 独立进程不同,新版本直接集成在 RabbitMQ 进程中,性能更好。
Step 2:Prometheus 抓取配置
yaml
# prometheus.yml
scrape_configs:
- job_name: 'rabbitmq-cluster'
metrics_path: '/metrics'
static_configs:
- targets:
- 'rmq-node1.cloudmart.internal:15692'
- 'rmq-node2.cloudmart.internal:15692'
- 'rmq-node3.cloudmart.internal:15692'
relabel_configs:
- source_labels: [__address__]
target_label: instance
regex: '(.+):\d+'
replacement: '$1'注意 :Prometheus 应从每个节点独立抓取指标,而非通过负载均衡。因为同一集群不同节点的指标值不同(如 rabbitmq_queue_messages 在 master 节点有值,mirror 节点为 0)。
Step 3:Grafana Dashboard 推荐布局
CloudMart 运维团队设计的 Dashboard 采用"全景 → 聚焦 → 详情"三层布局:
第一行:全局健康概览
| 面板位置 | 内容 | 可视化类型 |
|---|---|---|
| 左上 | 集群节点状态(Online / Offline / Partitioned) | Stat(状态卡片) |
| 中上 | 总消息流入/流出速率(对比双轴折线) | Graph |
| 右上 | 内存使用率 / 磁盘剩余 | Gauge |
第二行:队列聚焦
| 面板位置 | 内容 | 可视化类型 |
|---|---|---|
| 整行 | Top 10 队列深度排行(实时热力图) | Table(按 messages 排序) |
| 下半部 | 选中队列的 ready / unacked / total 趋势 | Graph(堆叠面积图) |
第三行:连接与 Erlang VM
| 面板位置 | 内容 | 可视化类型 |
|---|---|---|
| 左侧 | 各节点 Connections / Channels / Consumers 数量 | Graph |
| 右侧 | Erlang VM 内存分配 / GC 次数 / 进程数 | Graph |
3.4 告警规则设计
告警不是越多越好------告警疲劳比没有告警更危险。CloudMart 遵循"分级 + 可行动"原则:
规则一:队列堆积告警
yaml
# prometheus-alert-rules.yml
groups:
- name: rabbitmq_queue_backlog
rules:
- alert: RabbitMQQueueBacklogWarning
expr: rabbitmq_queue_messages_ready > 100000
for: 5m
labels:
severity: warning
team: cloudmart-sre
annotations:
summary: "队列 {{ $labels.queue }} 堆积超过 10 万条"
description: "当前 ready 消息数: {{ $value }},已持续 5 分钟。建议检查消费者状态。"
- alert: RabbitMQQueueBacklogCritical
expr: rabbitmq_queue_messages_ready > 500000
for: 1m
labels:
severity: critical
annotations:
summary: "队列 {{ $labels.queue }} 堆积超过 50 万条"
description: "当前 ready 消息数: {{ $value }},属于严重堆积。请立即检查消费者是否存活。"规则二:内存使用告警
yaml
- alert: RabbitMQMemoryHigh
expr: |
(rabbitmq_process_resident_memory_bytes / rabbitmq_resident_memory_limit_bytes) > 0.8
for: 2m
labels:
severity: critical
annotations:
summary: "节点 {{ $labels.node }} 内存使用率超过 80%"
description: "当前使用率: {{ printf "%.1f%%" (mul $value 100) }}。即将触发 Flow Control,建议启用 Lazy Queue 或扩容。"规则三:磁盘空间告警
yaml
- alert: RabbitMQLowDiskSpace
expr: rabbitmq_disk_space_available_bytes < 2 * 1024 * 1024 * 1024
for: 1m
labels:
severity: critical
annotations:
summary: "节点 {{ $labels.node }} 磁盘剩余不足 2GB"
description: "当前剩余: {{ $value | humanize }}B。低于 disk_free_limit 时将阻塞所有生产者。"规则四:消费者连接骤降
yaml
- alert: RabbitMQConsumerDrop
expr: |
(rabbitmq_consumers_total offset 10m) - rabbitmq_consumers_total >
(rabbitmq_consumers_total offset 10m) * 0.5
for: 2m
labels:
severity: warning
annotations:
summary: "消费者连接数 10 分钟内下降超过 50%"
description: "可能原因:消费者应用批量崩溃或网络分区。当前消费者数: {{ $value }}。"3.5 运维命令速查表
| 分类 | 命令 | 用途 |
|---|---|---|
| 状态诊断 | rabbitmq-diagnostics status |
节点整体健康状态 |
rabbitmq-diagnostics check_port_connectivity |
端口可达性检查 | |
rabbitmq-diagnostics memory_breakdown |
内存使用明细(连接/队列/插件) | |
rabbitmq-diagnostics observer |
启动 Erlang Observer 图形界面(需 GUI) | |
| 队列管理 | rabbitmqctl list_queues name messages consumers |
列出队列及消费者数 |
rabbitmqctl list_queues name messages_ready messages_unacknowledged |
查看堆积详情 | |
rabbitmqctl purge_queue <queue_name> |
清空队列所有消息(不可逆) | |
rabbitmqadmin delete queue name=<queue_name> |
删除队列 | |
| 集群管理 | rabbitmqctl cluster_status |
集群拓扑状态 |
rabbitmqctl stop_app / start_app |
暂停/恢复单节点应用 | |
rabbitmqctl forget_cluster_node <node> |
从集群中移除节点 | |
rabbitmqctl set_cluster_name <name> |
设置集群名称 | |
| 策略管理 | rabbitmqctl list_policies |
列出所有策略 |
rabbitmqctl set_policy <name> <pattern> <definition> |
创建/更新策略 | |
rabbitmqctl clear_policy <name> |
删除策略 | |
| 用户管理 | rabbitmqctl list_users |
列出所有用户及角色 |
rabbitmqctl add_user <name> <password> |
添加用户 | |
rabbitmqctl set_permissions -p / <user> ".*" ".*" ".*" |
设置 vhost 权限 |
3.6 面试追问 5 问
Q1:内存告警时 RabbitMQ 会怎么做?
RabbitMQ 检测到内存使用超过 vm_memory_high_watermark(默认 0.4,即 40%)时,会触发 Flow Control。具体行为:对所有生产者连接(TCP Connection 级别)暂停读取------本质上是停止从生产者 Socket 读取数据,TCP 缓冲区满后生产端自然阻塞。此时消费者不受影响,继续拉取消息。当内存回落至 watermark 以下,生产者连接自动恢复。
追问层 :为什么默认是 40% 而不是 80%?
答:Erlang VM 本身有一定内存开销(atom table、ETS 表、进程堆等),40% 给 RabbitMQ 的消息体缓存留出了合理空间,剩下的 60% 预留给系统和其他 Erlang 进程。生产环境可根据节点内存大小调整,如 64GB 内存的节点可设为 0.6。
Q2:磁盘告警和内存告警的区别是什么?
核心区别:内存告警有恢复机制 (消费者处理消息后内存释放,Flow Control 自动解除);磁盘告警必须手动干预(消息持久化写入磁盘后不会自动删除,只有消费并 ACK 后才会从磁盘移除)。因此磁盘告警通常意味着消息堆积已严重到吃光磁盘,需要:
- 检查消费者是否存活(消费才能释放磁盘空间)
- 清理过期日志(
rabbitmqctl rotate_logs) - 必要时 purge_queue(丢弃消息换取集群恢复)
Q3:为什么 Prometheus 要从每个节点独立抓取指标?
因为 RabbitMQ 集群中,队列级别的指标(如 rabbitmq_queue_messages)只在队列的 master 节点上有实际值,mirror 节点上该队列指标为 0。如果通过负载均衡随机抓取某个节点,数据会出现"时有时无"的假象。独立抓取每个节点后,在 Grafana 中对多节点做 max 聚合即可获得真实值。
Q4:RabbitMQ 的监控插件有哪些选择?
| 插件/方案 | 适用场景 | 优缺点 |
|---|---|---|
rabbitmq_prometheus |
已有 Prometheus 技术栈 | 官方维护、性能好、3.12+ 内置 |
rabbitmq_management + HTTP API |
脚本巡检或轻量监控 | 全功能但需自行编写采集逻辑 |
rabbitmq_tracing |
调试特定消息流向 | 性能开销大,不适合生产全量开启 |
| 第三方(Datadog / NewRelic) | 全托管监控 | 接入成本低但费用高 |
Q5:如何用一条命令快速判断集群是否健康?
bash
rabbitmq-diagnostics check_running \
&& rabbitmq-diagnostics check_port_connectivity \
&& rabbitmqctl list_queues name messages_ready | awk '$2>100000{print "QUEUE_BACKLOG:"$0}' \
&& echo "CLUSTER_HEALTHY"如果 check_running 失败------节点未启动;check_port_connectivity 失败------可能存在网络分区;list_queues 返回堆积队列------需要排查消费端。
模块小结 :监控的核心不是堆指标,而是抓住"真正会引发故障的信号"------队列深度、内存水位、磁盘剩余、消费者连接数。Prometheus + Grafana 方案通过三层 Dashboard 布局(吞吐→积压→资源)实现了从全局到聚焦的监控视角。告警规则必须遵循"分级 + 可行动"原则,避免告警疲劳。
rabbitmq-diagnostics系列命令是日常运维的第一入口。
模块四:RabbitMQ vs Kafka 终极对比
4.1 CloudMart 技术选型评审
2026 年 1 月,CloudMart CTO 主持了一场技术选型评审会。
背景是 CloudMart 同时运行着两套 MQ:订单/库存/物流链路用 RabbitMQ,日志采集/用户行为分析链路用 Kafka。有工程师质疑:"为什么一个公司要维护两套 MQ?全部迁移到 Kafka 不是更简单?"
CTO 的回答定义了评审的基调:
"RabbitMQ 和 Kafka 不是替代关系。它们分别解决了消息系统两个截然不同的问题------业务指令的路由 和事件流的存储。评审的目的不是合并,而是搞清楚每条链路的消息语义,然后选择正确的工具。"
本节将从架构维度完成这个评审,给出可落地的选型决策树。
去重声明 :第二期已在可靠性维度对比过确认/持久化/Ack 等机制(7 维度表),本期聚焦架构模型、使用模式和选型决策等新维度,不重复二期内容。
4.2 架构级对比表
路由模型
| 维度 | RabbitMQ | Kafka |
|---|---|---|
| 核心抽象 | Exchange + Binding + Routing Key | Topic + Partition |
| 路由方式 | 灵活的多级路由(Direct / Topic / Fanout / Headers) | 固定路由:Key → Partition hash |
| 典型场景 | "订单创建后通知库存、物流、积分三个服务,同时按订单类型分发到不同处理链路" | "所有用户点击日志写入 user_click topic,下游按需消费" |
| 灵活性 | 极高------一个消息经过 Exchange 可以被路由到多个不同队列 | 较低------消息写入特定 Partition,消费者组内均分 Partition |
| 协议保证 | AMQP 0-9-1------标准化,所有语言的 AMQP 客户端均可互通 | 自定义二进制协议------高效但绑定 Kafka SDK |
深度解读 :RabbitMQ 的路由模型本质是一次发布,多方分发 ------Exchange 根据 Binding 规则将消息复制 到多个队列,适合需要广播/多路分发的业务指令。Kafka 的模型是一次写入,单点消费------消息写入 Partition 后由 Consumer Group 内的一个消费者独占,适合需要顺序和流式处理的事件日志。
代码层面的差异:
java
// RabbitMQ:通过 Routing Key 实现灵活路由
// 日志系统:error → 同时发到企业微信告警队列 + 日志归档队列
rabbitTemplate.convertAndSend("log.exchange", "error.payment", logMsg);
// Binding: "error.*" → alert.queue, "*.payment" → archive.payment.queue
// Kafka:消息固定写入 Topic + Partition
producer.send(new ProducerRecord<>("user_click", userId, clickEvent));
// userId 决定 Partition,同一用户的所有点击进入同一 Partition消费者模型
| 维度 | RabbitMQ | Kafka |
|---|---|---|
| 消费模式 | Push(服务端推送)+ 可选 Pull(basicGet) | Pull(客户端拉取) |
| 分发策略 | Fair dispatch(轮询或按 prefetch 公平分发) | Consumer Group 内按 Partition 独占 |
| 确认机制 | 逐条 ACK(可自动或手动) | offset 提交(批量,可自动或手动) |
| 消费进度 | 服务端维护(unacked 状态) | 客户端维护(__consumer_offsets topic) |
| 消息重放 | 不支持(消费即删除) | 支持(重置 offset 即可重放历史) |
Push vs Pull 的工程取舍:
RabbitMQ Push 模型:
优势:低延迟(消息到达立即推送),实现简单
劣势:需要 prefetch 限流防止客户端被打爆;无法按消费能力自适应拉取
Kafka Pull 模型:
优势:消费者按自身能力拉取,不会被打爆;天然支持批量拉取提升吞吐
劣势:需要长轮询(long polling)避免空转;延迟略高(拉取间隔 + 网络往返)存储模型
| 维度 | RabbitMQ | Kafka |
|---|---|---|
| 消息存储 | 基于索引的独立消息文件(msg_store + queue_index) | 基于 Partition 的分段日志(Segment Log) |
| 持久化保证 | 可选(delivery_mode=2 时开启) | 必选------所有消息写入 Page Cache + 磁盘 |
| 删除策略 | 消费后立即删除(从 msg_store 标记删除) | 按时间/大小策略保留(默认 7 天),与消费进度无关 |
| Page Cache | 不使用(Erlang 自行管理内存) | 深度依赖 OS Page Cache 做读写加速 |
| 磁盘吞吐 | 随机读写为主(每条消息独立索引定位) | 顺序追加写(追加到 Partition 日志末尾) |
协议与标准化
| 维度 | RabbitMQ | Kafka |
|---|---|---|
| 协议 | AMQP 0-9-1(ISO/IEC 19464 标准) | 自定义二进制协议(Kafka Wire Protocol) |
| 客户端生态 | 通过 AMQP 标准,任何语言都可实现客户端(30+ 语言) | 官方 Java 客户端为主,社区维护其他语言(librdkafka 是 C/C++ 事实标准) |
| 版本兼容 | AMQP 版本稳定,客户端长期兼容 | 协议随版本演进,跨版本兼容需注意 |
运维复杂度
| 维度 | RabbitMQ | Kafka |
|---|---|---|
| 部署语言 | Erlang(运维人员普遍不熟悉) | Java/Scala(运维人员更熟悉) |
| 依赖组件 | 无外部依赖(Mnesia 内置) | ZooKeeper(3.3+ 可切换 KRaft) |
| 插件管理 | 插件体系丰富(Management / Shovel / Federation / MQTT 等) | 插件较少,核心功能已内置 |
| 扩容方式 | 增加消费者(无状态,即时生效) | 增加 Partition(有状态,触发 rebalance,有短暂不可用窗口) |
| 监控 | Prometheus 插件丰富指标 | JMX + Prometheus JMX Exporter 或 Kafka Exporter |
深度解读------扩容方式差异:
RabbitMQ 扩容消费者:
→ 启动新的消费者实例
→ 立即参与公平分发(round-robin)
→ 对已有消费者零影响
→ 适合应对突发流量
Kafka 扩容消费者:
→ 消费者组内消费者数不能超过 Partition 数(超过的闲置)
→ 扩容前需要先增加 Partition(需预先规划)
→ Partition 再均衡期间,Consumer Group 短暂不可消费
→ 适合可预期的长期流量增长4.3 性能场景决斗
"RabbitMQ 和 Kafka 谁更快"是一个没有标准答案的问题------取决于消息大小、批量模式和使用场景。
场景一:低延迟小消息(< 1KB)
CloudMart 订单消息(平均 800 字节),延迟敏感(用户期望秒级反馈)。
| 指标 | RabbitMQ | Kafka |
|---|---|---|
| 端到端延迟(P99) | 微秒级(Push 模式,消息到达立即推送) | 毫秒级(Pull 模式,消费者轮询间隔 + 网络往返) |
| 单机 TPS | 5~10 万(非持久化)/ 2~5 万(持久化) | 20~50 万(批量发送 + Page Cache) |
| 推荐场景 | 在线业务指令 | 日志流式处理 |
结论:低延迟小消息场景,RabbitMQ 的 Push 模型在延迟上占优。Kafka 的 Pull + 批量适合吞吐不关心单条延迟。
场景二:高吞吐大批量(> 10KB)
CloudMart 用户行为日志(平均 15KB),吞吐优先,延迟容忍分钟级。
| 指标 | RabbitMQ | Kafka |
|---|---|---|
| 单机 TPS(1KB) | 5~10 万 | 100 万+ |
| 单机 TPS(10KB) | 2~3 万 | 50 万+ |
| 核心优势 | Push 低延迟 | 顺序写磁盘 + Page Cache + 零拷贝 |
| 瓶颈 | 内存拷贝次数多(Erlang 消息传递语义) | 磁盘 IO 带宽(顺序写接近磁盘物理上限) |
结论:高吞吐大批量场景,Kafka 的顺序写 + 零拷贝 + Page Cache 三重优化碾压 RabbitMQ。RabbitMQ 的消息路由(Exchange → Binding → Queue)每一步都涉及内存拷贝,不适合单队列百万级吞吐。

4.4 Stream Queue 简介
RabbitMQ 3.9 引入了 Stream Queue------它试图在 RabbitMQ 中提供类似 Kafka 的能力:消息持久化保留、支持 offset 回放、支持多消费者独立消费(非竞争消费模式)。
Stream Queue 的核心特性
| 特性 | Stream Queue | 普通/Quorum Queue | Kafka Topic |
|---|---|---|---|
| 消费模式 | 非破坏性消费(消费后不删除) | 破坏性消费(消费后删除) | 非破坏性消费 |
| Offset 重放 | 支持 | 不支持 | 支持 |
| 消息保留 | 按时间/大小策略 | 消费即删除 | 按时间/大小策略 |
| Fan-out | 支持(多消费者独立 offset) | 需绑定多个队列 | 支持(不同 Consumer Group) |
| 协议 | RabbitMQ Stream Protocol(二进制) | AMQP 0-9-1 | Kafka Wire Protocol |
为什么 Stream Queue 不替代 Kafka
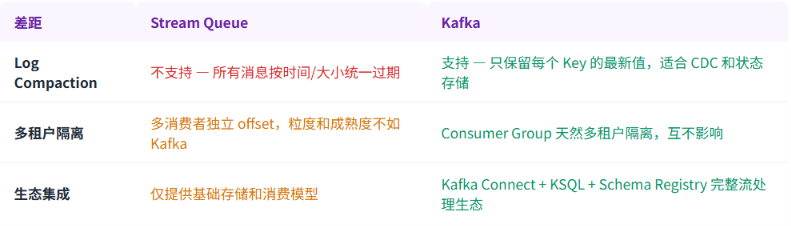
尽管 Stream Queue 让 RabbitMQ 具备了"Kafka-like"能力,但有三个硬伤:
-
无 Log Compaction(日志压缩):Kafka 的 Log Compaction 可以只保留每个 Key 的最新值,适合 CDC(Change Data Capture)和状态存储。Stream Queue 没有此特性,所有消息按时间/大小统一过期。
-
无多租户隔离:Kafka 通过 Topic + Consumer Group 实现了天然的多租户隔离(不同消费者组独立 offset,互不影响)。Stream Queue 的多消费者独立 offset 类似但粒度和成熟度不如。
-
生态集成:Kafka Connect + KSQL + Schema Registry 构成了完整的流处理生态。Stream Queue 目前仅提供基础的存储和消费模型。
CloudMart 的使用建议:如果已有 RabbitMQ 且需要轻量级的事件回放能力(如订单审计、操作日志查询),Stream Queue 是不错的补充。但如果需要完整的流处理能力(实时 ETL、Flink 集成),仍选 Kafka。
4.5 选型决策树
以下决策树基于 CloudMart 的真实需求抽象而来,覆盖 90% 的企业 MQ 选型场景:

CloudMart 最终决策:
| 业务链路 | MQ 选型 | 理由 |
|---|---|---|
| 订单创建 → 库存扣减 → 物流通知 | RabbitMQ | 灵活路由(一条订单触发多个下游)+ 延迟队列(30 分钟未支付取消) |
| 用户行为日志 → 实时分析 → HDFS | Kafka | 高吞吐 + 消息重放(分析模型迭代需回溯历史数据) |
| 订单审计日志(3 天追溯) | RabbitMQ Stream Queue | 轻量回放 + 复用现有 RabbitMQ 基础设施 |

4.6 面试追问 5 问
Q1:一个公司是否可以只用一种 MQ?
可以,但通常不是最优解。如果能满足以下条件之一,统一是合理的:
- 所有消息场景同质化(如全公司只有日志采集,没有业务指令类)
- 运维资源极度紧张(维护两套 MQ 的边际成本 > 架构不适配的损失)
- 团队对某一 MQ 的理解深度足以绕过其设计短板(如用 Kafka 的 Compact Topic + 自定义路由层模拟 RabbitMQ 交换机的功能)
CloudMart 选择双轨的原因是两套场景差异足够大:订单链路需要路由灵活性和低延迟,日志链路需要吞吐和重放能力。强行用 Kafka 做订单路由会让代码入侵大量"手动路由"逻辑,得不偿失。
追问层 :用 RabbitMQ 替代 Kafka 做日志采集可行吗?
答:小规模(< 1 万条/秒)可以用 RabbitMQ Stream Queue 勉强替代。但超过此量级,Kafka 的顺序写 + 零拷贝优势是 RabbitMQ 架构性的差距(见 4.3 节),无法通过参数调优弥补。
Q2:Stream Queue 和 Kafka Topic 的本质区别是什么?
三条核心区别:
- 存储引擎:Stream Queue 基于 RabbitMQ 的 msg_store(分段文件 + 索引),Kafka 基于 Partition Segment Log(纯顺序追加)。后者在大数据量下更高效。
- 消费隔离:Stream Queue 的多消费者 Offset 仅在同一 Queue 内共享存储,Kafka 的 Consumer Group 是逻辑隔离(各自维护 offset),隔离性更好。
- 生态:Kafka 有 Connect / Streams / KSQL / Schema Registry 完整生态,Stream Queue 仅提供基础协议和客户端。
Q3:RabbitMQ 的 Fanout Exchange 和 Kafka 的一对多消费有什么区别?
Fanout Exchange 是队列级别的分发 ------消息复制到所有绑定队列,每个队列独立消费(即"一份数据多份存储")。Kafka 的一对多消费是Consumer Group 级别的分发------消息存储一份,不同 Consumer Group 各自维护 offset 独立消费(即"一份数据多份视角")。
代码层面:
java
// RabbitMQ Fanout:消息被复制到 3 个独立队列
// 适合:不同下游对消息有不同的处理逻辑和消费速率
channel.exchangeDeclare("order.fanout", "fanout");
// 绑定 3 个队列 → 消息物理复制 3 份
// Kafka Consumer Group:消息存储一份,3 个 Group 独立消费
// 适合:同一份数据被不同分析引擎使用(实时 + 离线 + 审计)
kafkaConsumer1.subscribe("order_events"); // Consumer Group: realtime
kafkaConsumer2.subscribe("order_events"); // Consumer Group: batchQ4:什么时候 RabbitMQ 比 Kafka 更快?
当满足以下条件时 RabbitMQ 更快:
- 消息大小 < 1KB
- 需要单条消息的低延迟投递(P99 < 1ms)
- 消费者数量动态变化频繁(Kafka rebalance 有停顿,RabbitMQ 即时加入分发)
- 需要灵活路由(Exchange + Binding 原语 vs Kafka 需要手动实现)
追问层 :RabbitMQ 能做百万 QPS 吗?
答:单机不行(架构瓶颈,内存拷贝次数多)。但通过集群 + 分片(Consistent Hash Exchange),可以将不同消息哈希到不同队列,每个队列独立消费,整体集群可达百万 QPS。这与 Kafka Partition 的思路类似,但路由灵活性更高。
Q5:如果团队只会 Java,RabbitMQ 运维会不会有障碍?
RabbitMQ 3.12+ 已大幅改善:
- Management 插件提供了完整的 Web UI,日常操作(队列查看、消息预览、策略配置)不需要 Erlang 知识
- rabbitmq-diagnostics 命令已抽象掉 Erlang 运行时细节,输出人类可读
- 真正的 Erlang 调优场景极少(如 GC 参数、分布式协议参数),绝大多数生产环境使用默认配置即可
追问层 :什么情况下必须懂 Erlang?
答:① 源码级故障排查(如查看 crash dump);② 编写自定义插件(RabbitMQ 插件只能用 Erlang);③ 性能极限调优(修改 VM 参数、进程调度等)。这三点在日常运维中占比 < 5%,且 RabbitMQ 社区文档已覆盖常见参数。
运维命令速查
| 场景 | 命令 |
|---|---|
| 查看节点状态 | rabbitmq-diagnostics status |
| 查看集群状态 | rabbitmqctl cluster_status |
| 查看队列堆积 | rabbitmqctl list_queues name messages_ready messages_unacknowledged |
| 清空队列 | rabbitmqctl purge_queue <queue_name> |
| 启用 Prometheus | rabbitmq-plugins enable rabbitmq_prometheus |
| 创建策略 | rabbitmqctl set_policy <name> "<pattern>" '<definition>' --apply-to queues |
| 列出策略 | rabbitmqctl list_policies |
| 设置分区策略 | rabbitmqctl set_cluster_handling_strategy pause_minority |
| 加入集群 | rabbitmqctl join_cluster rabbit@<node> --ram |
配置清单速查
| 配置项 | 推荐值 | 说明 |
|---|---|---|
vm_memory_high_watermark |
0.4(生产 64GB+ 可调至 0.6) | 触发 Flow Control 的内存阈值 |
disk_free_limit |
2GB(比默认 50MB 保守) | 触发磁盘告警阈值 |
prefetch |
50(耗时任务)/ 250(轻量任务) | 消费者预取数量 |
ha-mode |
exactly + ha-params: 2 |
每消息 2 副本(mirror 队列) |
x-quorum-initial-group-size |
3 | Quorum Queue 复制因子 |
queue-mode |
lazy(高堆积队列) |
启用 Lazy Queue |
max-length |
1000000(100 万) | 队列长度硬限制 |
overflow |
reject-publish |
队列满时拒绝而非丢弃 |
ha-sync-batch-size |
10000 | 镜像队列同步批次大小 |
面试核心回答模板
Q:消息堆积怎么处理?
先定位根因(四种:消费者慢 / prefetch 不当 / 无 TTL / 下游故障),然后三步走:① 扩容消费者 + 调 prefetch;② 启用 Lazy Queue 避免 Flow Control;③ max-length 兜底。组合方案,不是一个参数能解决。
Q:RabbitMQ 集群如何保证高可用?
两层:集群层面用至少 3 节点(奇数节点 + pause-minority 分区策略)防止脑裂;队列层面用镜像队列或 Quorum Queue 提供数据冗余。Quorum Queue 的 Raft 协议天然抗脑裂,推荐 3.8+ 使用。
Q:RabbitMQ 和 Kafka 怎么选?
看消息语义:业务指令/路由/延迟/低延迟 → RabbitMQ;事件流/日志/重放/高吞吐 → Kafka。如果两样都要,双轨不是浪费,是务实。
下期预告
本文是 RabbitMQ 面试系列三期中的终篇。三期内容覆盖了 RabbitMQ 面试中 90% 的高频考点:
- 第一期:MQ 核心概念、选型决策、RabbitMQ 架构与工作模式快速上手
- 第二期:可靠性全链路(消息 0 丢失)、死信与延迟队列、消费端限流与事务
- 第三期(本文):消息堆积诊断、集群高可用、监控运维、Kafka 终极对比
感谢各位的阅读,阅读至此想必已经过了很久,休息一会吧,感谢辛苦付出的自己,祝各位早日拿到offer,共勉!