在 RAG(检索增强生成)系统中,分块(Chunking)是影响检索质量最关键的一步。文本被切割成多大、怎么切,直接决定了嵌入向量的语义完整性和检索的准确性。
一、引言
在 RAG(Retrieval-Augmented Generation)系统中,文档解析与分块(Chunking)是决定检索质量和生成效果的关键环节。LlamaIndex 提供了一套层次分明、功能丰富的文档解析与分块体系,从最基础的文本切分到语义感知的智能分块,再到结构化文档的层级解析,覆盖了几乎所有常见的文档处理场景。  本文基于 LlamaIndex 源码,深入剖析其文档解析与分块策略的架构设计、核心组件和最佳实践。
本文基于 LlamaIndex 源码,深入剖析其文档解析与分块策略的架构设计、核心组件和最佳实践。
二、核心架构:从 Document 到 Node
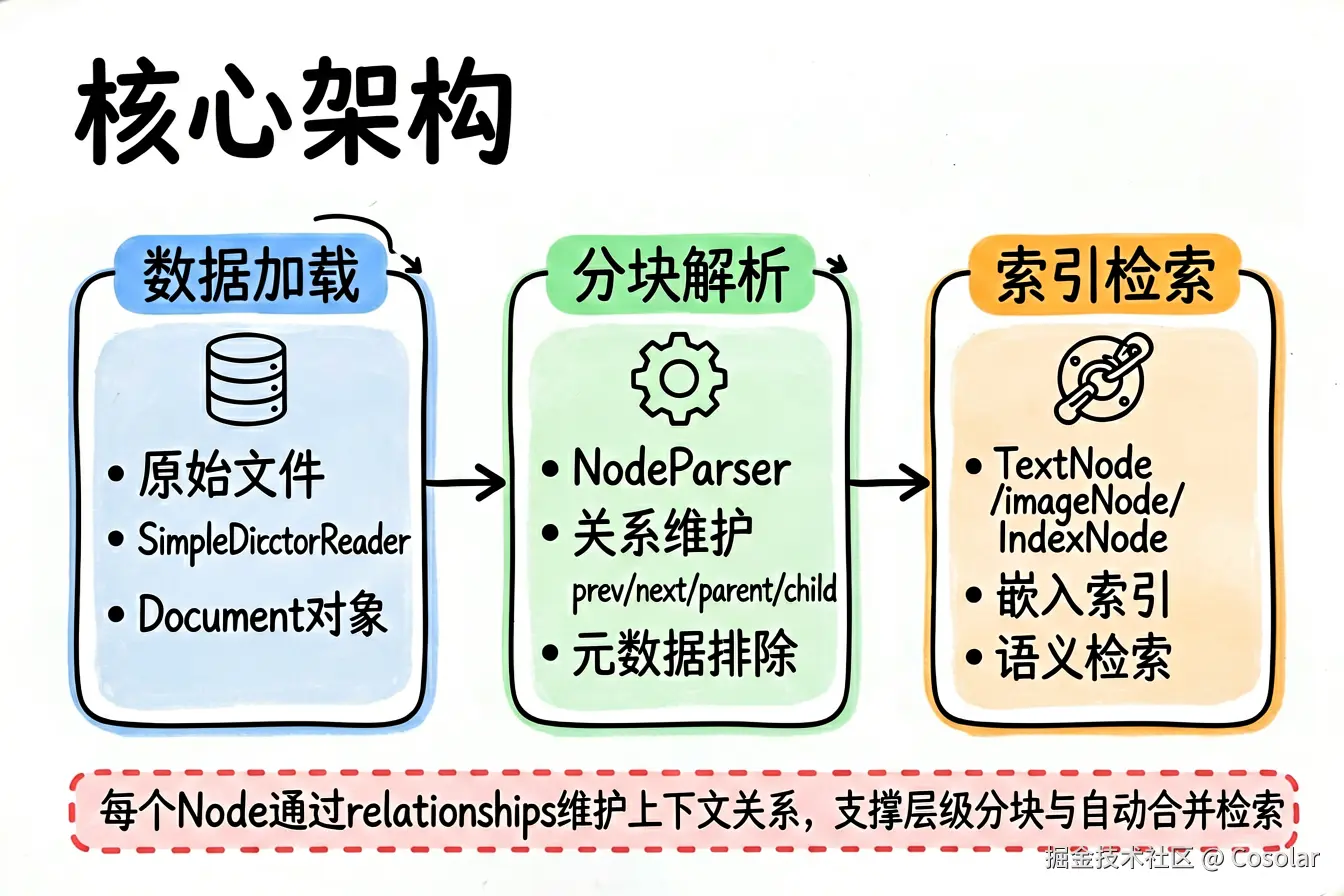
2.1 数据模型层次
LlamaIndex 的文档处理遵循 Document → Node 的转换管线:
原始文件 → SimpleDirectoryReader → Document → NodeParser → Node(TextNode / ImageNode / IndexNode)- Document:代表一个完整的文档,是数据加载的输出单位
- Node:代表文档的一个片段,是索引和检索的基本单位
在 schema.py 中,核心数据模型定义如下:
python
class NodeRelationship(str, Enum):
SOURCE = auto() # 指向源文档
PREVIOUS = auto() # 前驱节点
NEXT = auto() # 后继节点
PARENT = auto() # 父节点(层级分块)
CHILD = auto() # 子节点(层级分块)
class BaseNode(BaseModel):
excluded_embed_metadata_keys: List[str] = Field(default_factory=list)
excluded_llm_metadata_keys: List[str] = Field(default_factory=list)
relationships: Dict[NodeRelationship, RelatedNodeType] = Field(default_factory=dict)关键设计思想 :每个 Node 都通过 relationships 维护与其他节点的关联关系,这为层级分块、上下文窗口、自动合并检索等高级特性奠定了基础。
2.2 元数据排除机制
在 base.py 中,SimpleDirectoryReader 会自动将文件元数据排除在嵌入和 LLM 处理之外:
python
def _exclude_metadata(self, documents: list[Document]) -> list[Document]:
for doc in documents:
doc.excluded_embed_metadata_keys.extend([
"file_name", "file_type", "file_size",
"creation_date", "last_modified_date", "last_accessed_date"
])
doc.excluded_llm_metadata_keys.extend([
"file_name", "file_type", "file_size",
"creation_date", "last_modified_date", "last_accessed_date"
])
return documents这确保了文件系统元数据不会干扰语义嵌入或 LLM 推理,同时仍保留在节点中供元数据过滤使用。
三、文档加载:SimpleDirectoryReader
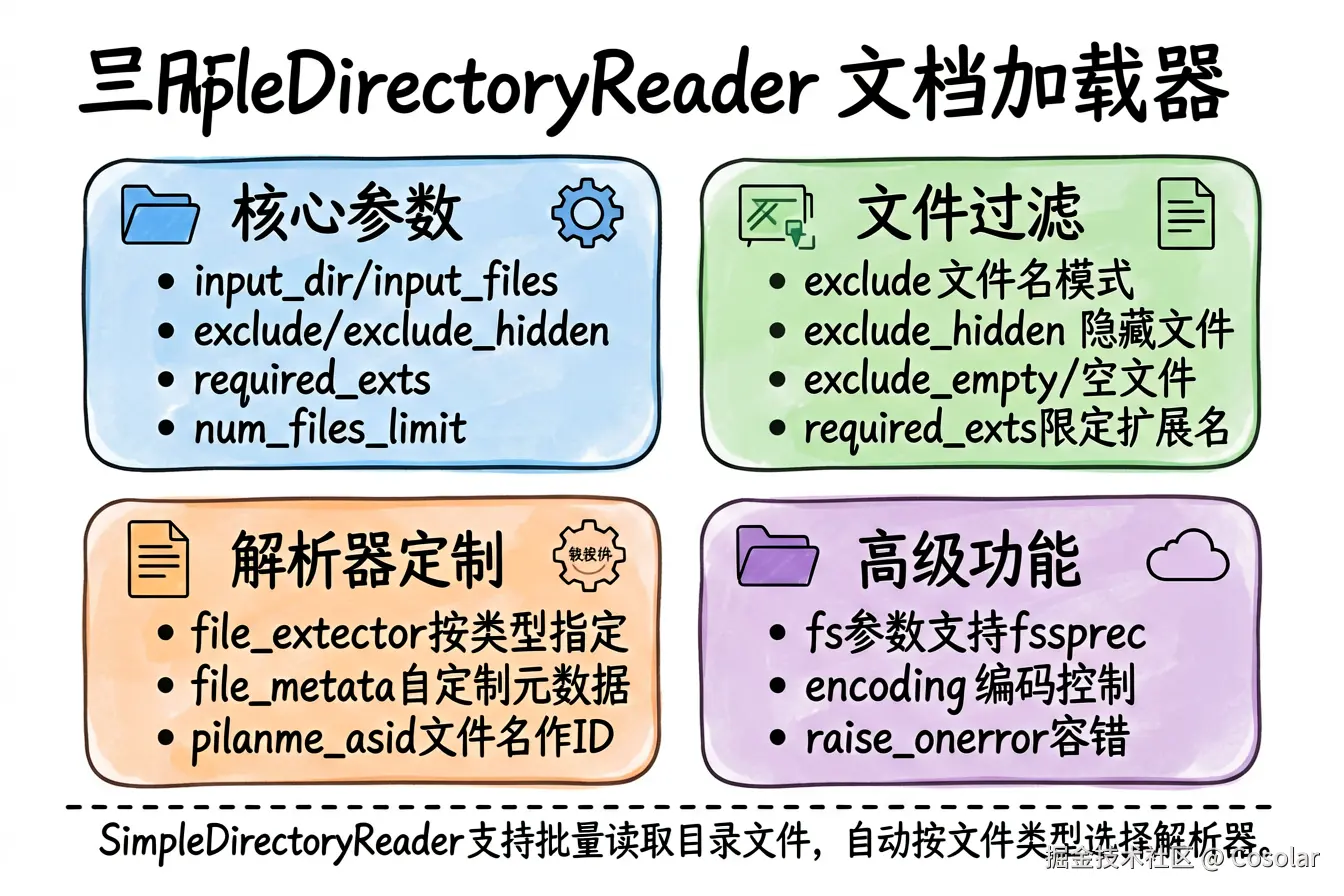
SimpleDirectoryReader 是 LlamaIndex 内置的文档加载器,支持从目录批量读取文件:
python
class SimpleDirectoryReader(BaseReader, ResourcesReaderMixin, FileSystemReaderMixin):
def __init__(
self,
input_dir: Optional[Union[Path, str]] = None,
input_files: Optional[list] = None,
exclude: Optional[list] = None, # 排除的文件模式
exclude_hidden: bool = True, # 排除隐藏文件
exclude_empty: bool = False, # 排除空文件
recursive: bool = False, # 递归读取子目录
required_exts: Optional[list[str]] = None, # 限定文件扩展名
num_files_limit: Optional[int] = None, # 限制文件数量
file_metadata: Optional[Callable[[str], dict]] = None,
filename_as_id: bool = False, # 使用文件名作为文档ID
encoding: str = "utf-8",
errors: str = "ignore",
raise_on_error: bool = False,
file_extractor: Optional[dict[str, BaseReader]] = None, # 按文件类型指定解析器
fs: Optional[fsspec.AbstractFileSystem] = None,
) -> None: ...使用示例:
python
from llama_index.core import SimpleDirectoryReader
# 基础用法
documents = SimpleDirectoryReader("data").load_data()
# 高级用法:指定文件类型、递归读取、自定义解析器
documents = SimpleDirectoryReader(
input_dir="data",
recursive=True,
required_exts=[".pdf", ".md", ".txt"],
file_extractor={".pdf": PDFReader(), ".md": MarkdownReader()}
).load_data()四、分块策略体系总览
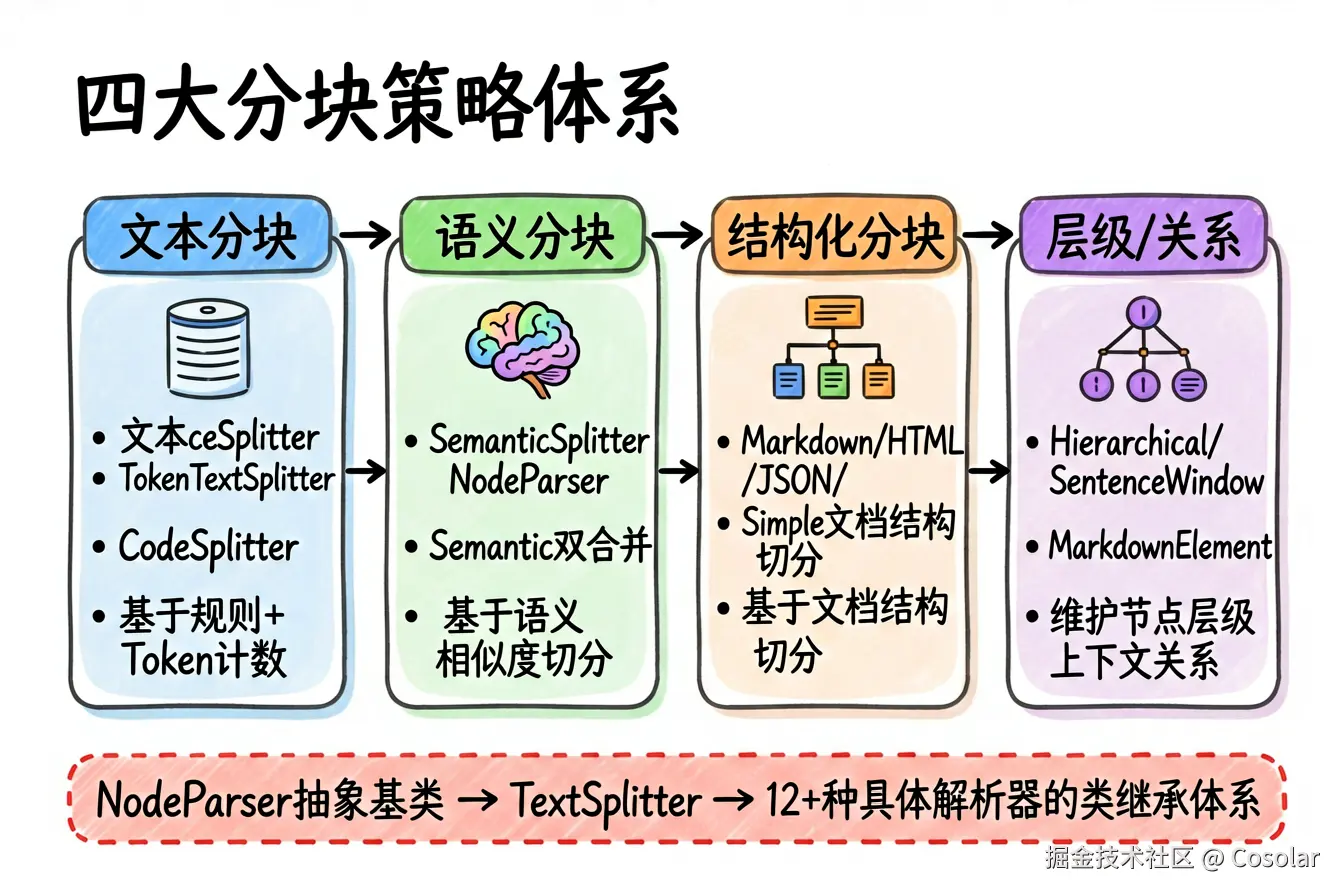
LlamaIndex 的分块策略可以分为 四大类别:
| 类别 | 解析器 | 核心思想 |
|---|---|---|
| 文本分块 | SentenceSplitter, TokenTextSplitter, CodeSplitter | 基于规则和 Token 计数切分 |
| 语义分块 | SemanticSplitterNodeParser, SemanticDoubleMergingSplitterNodeParser | 基于语义相似度切分 |
| 结构化分块 | MarkdownNodeParser, HTMLNodeParser, JSONNodeParser, SimpleFileNodeParser | 基于文档结构切分 |
| 层级/关系分块 | HierarchicalNodeParser, SentenceWindowNodeParser, MarkdownElementNodeParser, UnstructuredElementNodeParser | 维护节点间层级/上下文关系 |
4.1 类继承体系
scss
NodeParser (抽象基类)
├── TextSplitter (抽象,纯文本切分)
│ ├── MetadataAwareTextSplitter (元数据感知)
│ │ ├── SentenceSplitter (句子级切分,默认解析器)
│ │ └── TokenTextSplitter (Token级切分)
│ ├── CodeSplitter (代码切分)
│ └── LangchainNodeParser (LangChain适配器)
├── SemanticSplitterNodeParser (语义分块)
├── SemanticDoubleMergingSplitterNodeParser (语义双重合并)
├── SentenceWindowNodeParser (句子窗口)
├── HierarchicalNodeParser (层级分块)
├── MarkdownNodeParser (Markdown结构切分)
├── HTMLNodeParser (HTML结构切分)
├── JSONNodeParser (JSON结构切分)
├── SimpleFileNodeParser (自动文件类型检测)
├── MarkdownElementNodeParser (Markdown元素提取)
├── UnstructuredElementNodeParser (非结构化元素提取)
└── LlamaParseJsonNodeParser (LlamaParse JSON元素提取)五、文本分块策略详解
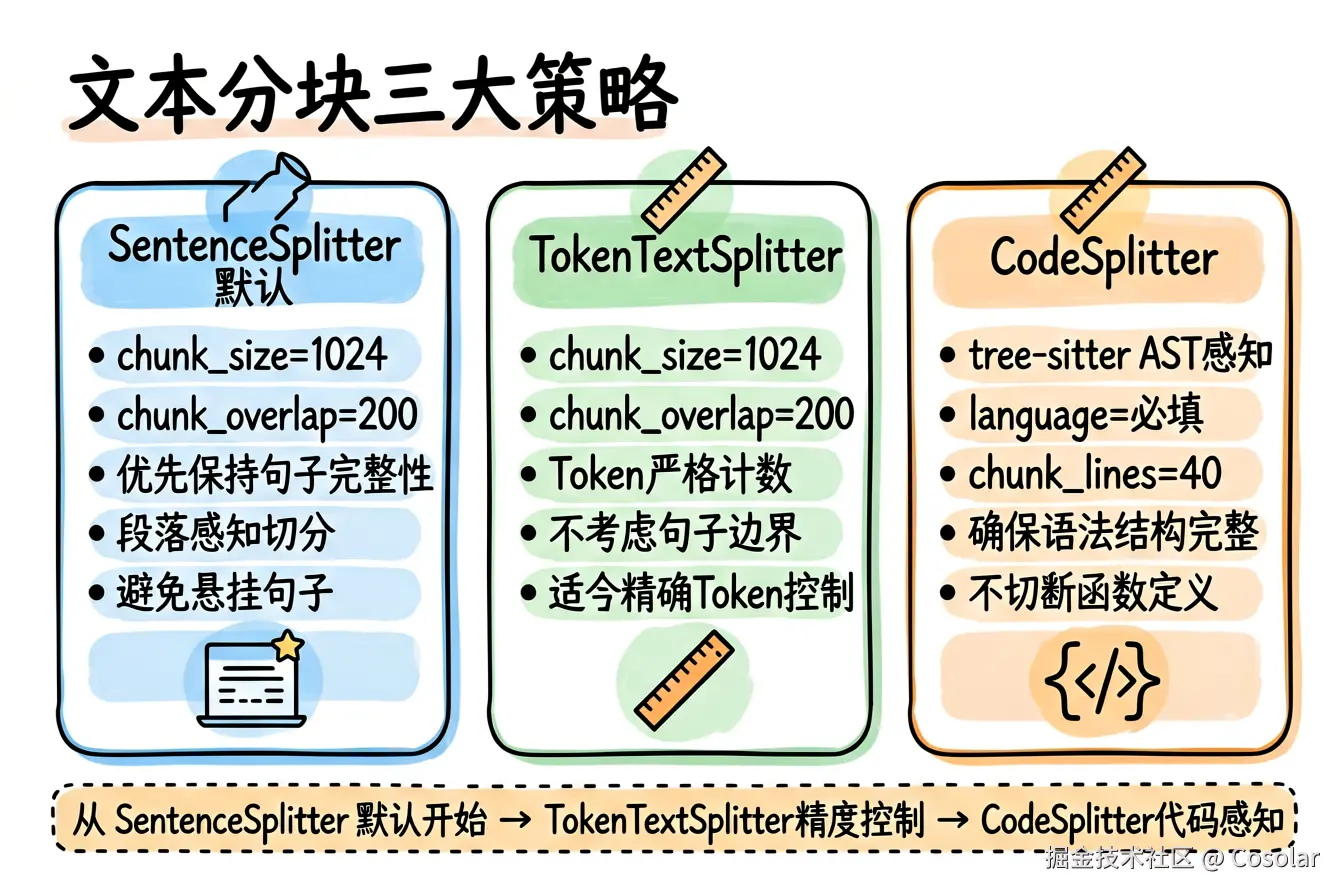
5.1 SentenceSplitter(句子级分块器)
这是 LlamaIndex 的默认分块器 ,在 settings.py 中可以看到:
python
class Settings(BaseSettings):
_node_parser: Optional[NodeParser] = None
def node_parser(self) -> NodeParser:
if self._node_parser is None:
self._node_parser = SentenceSplitter()
return self._node_parser核心参数 (源码来自 sentence.py):
| 参数 | 默认值 | 说明 |
|---|---|---|
chunk_size |
1024 | 每个 Chunk 的最大 Token 数 |
chunk_overlap |
200 | 相邻 Chunk 之间的重叠 Token 数 |
separator |
" " |
默认分词分隔符(空格) |
paragraph_separator |
"\n\n\n" |
段落分隔符 |
secondary_chunking_regex |
"[^,.;。?!]+[,.;。?!]?[,.;。?!]" |
句子级正则表达式 |
分块算法流程:
markdown
1. 按段落分隔符(\n\n\n)拆分
2. 如果段落超过 chunk_size,按句子正则拆分
3. 如果句子仍超过 chunk_size,按默认分隔符(空格)拆分
4. 合并小片段到 chunk_size 以内的块中
5. 处理 chunk_overlap 重叠区域源码中的核心方法:
python
def _split(self, text: str, chunk_size: int) -> List[_Split]:
# 1. split by paragraph separator
# 2. split by chunking regex (sentence level)
# 3. split by default separator (" ")
# 4. split by character (fallback)
def _merge(self, splits: List[_Split], chunk_size: int) -> List[str]:
# 合并小片段,处理重叠区域设计哲学:优先保持句子和段落的完整性,避免出现"悬挂句子"(hanging sentences),这是相比 TokenTextSplitter 的核心优势。
使用示例:
python
from llama_index.core.node_parser import SentenceSplitter
# 自定义参数
splitter = SentenceSplitter(
chunk_size=512,
chunk_overlap=50,
separator=" ",
paragraph_separator="\n\n\n",
)
nodes = splitter.get_nodes_from_documents(documents)5.2 TokenTextSplitter(Token 级分块器)
核心参数 (源码来自 token.py):
| 参数 | 默认值 | 说明 |
|---|---|---|
chunk_size |
1024 | 每个 Chunk 的最大 Token 数 |
chunk_overlap |
20 | 相邻 Chunk 之间的重叠 Token 数 |
separator |
" " |
分词分隔符 |
与 SentenceSplitter 的区别:
- TokenTextSplitter 以 Token 为单位严格切分,不考虑句子边界
- SentenceSplitter 优先保持句子完整性,chunk_overlap 默认更大(200 vs 20)
- SentenceSplitter 有段落感知和句子正则,TokenTextSplitter 更简单粗暴
适用场景:当对文本完整性要求不高、需要精确控制 Token 数量时使用(如严格受 Token 限制的 API 调用)。
5.3 CodeSplitter(代码分块器)
核心参数 (源码来自 code.py):
| 参数 | 默认值 | 说明 |
|---|---|---|
language |
必填 | 编程语言(如 "python", "javascript") |
chunk_lines |
40 | 每个 Chunk 的行数 |
chunk_lines_overlap |
15 | 相邻 Chunk 的重叠行数 |
max_chars |
1500 | 每个 Chunk 的最大字符数 |
核心特性 :基于 tree-sitter AST 解析器进行代码感知分块,确保代码块在语法结构上是完整的(如不会在函数定义中间切断)。
python
from llama_index.core.node_parser import CodeSplitter
splitter = CodeSplitter(
language="python",
chunk_lines=40,
chunk_lines_overlap=15,
max_chars=1500,
)
nodes = splitter.get_nodes_from_documents(documents)注意 :需要安装
tree_sitter_language_pack依赖。
六、语义分块策略详解
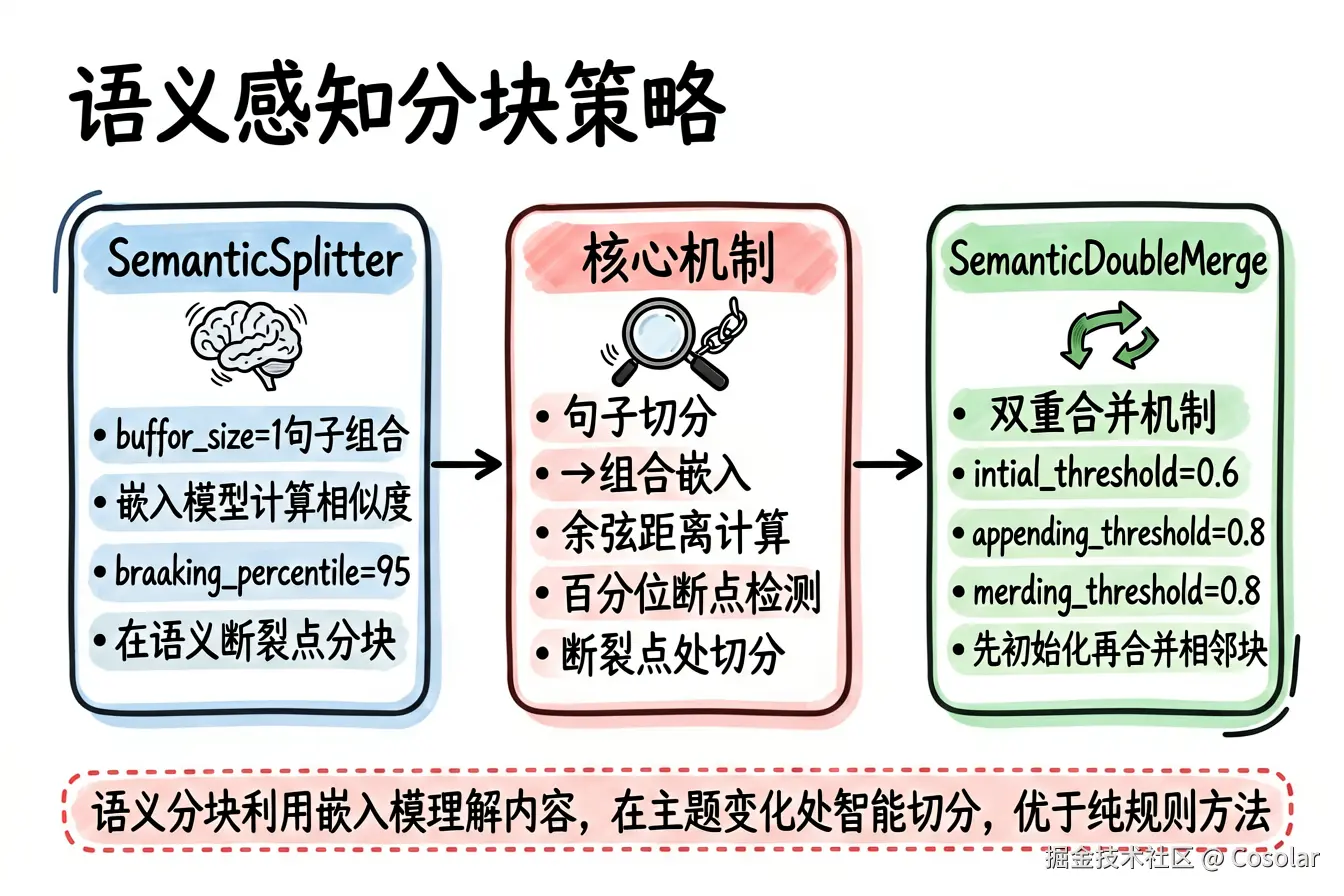
6.1 SemanticSplitterNodeParser(语义分块器)
核心思想:利用嵌入模型计算相邻句子的语义相似度,在语义"断裂点"处进行分块。
核心参数 (源码来自 semantic_splitter.py):
| 参数 | 默认值 | 说明 |
|---|---|---|
buffer_size |
1 | 评估语义相似度时组合的句子数 |
embed_model |
OpenAIEmbedding() | 嵌入模型 |
sentence_splitter |
split_by_sentence_tokenizer | 句子切分函数 |
breakpoint_percentile_threshold |
95 | 语义断裂点百分位阈值(越低产生越多节点) |
算法流程:
markdown
1. 将文本按句子切分
2. 将相邻 buffer_size 个句子组合,计算嵌入向量
3. 计算相邻组合句子的语义相似度(余弦距离)
4. 找到相似度的百分位断点(低于阈值的点即为语义断裂点)
5. 在断裂点处进行分块使用示例:
python
from llama_index.core.node_parser import SemanticSplitterNodeParser
from llama_index.core.embeddings import resolve_embed_model
embed_model = resolve_embed_model("local:BAAI/bge-small-zh-v1.5")
parser = SemanticSplitterNodeParser(
buffer_size=1,
breakpoint_percentile_threshold=95,
embed_model=embed_model,
)
nodes = parser.get_nodes_from_documents(documents)6.2 SemanticDoubleMergingSplitterNodeParser(语义双重合并分块器)
核心思想:在语义分块的基础上增加"双重合并"机制------先按语义相似度初始化分块,再对相邻分块进行二次合并。
核心参数 (源码来自 semantic_double_merging_splitter.py):
| 参数 | 默认值 | 说明 |
|---|---|---|
language_config |
LanguageConfig("english") | Spacy 语言配置 |
embed_model |
None | 嵌入模型(设置后替代 Spacy) |
initial_threshold |
0.6 | 初始化新 Chunk 的相似度阈值 |
appending_threshold |
0.8 | 追加句子到现有 Chunk 的阈值 |
merging_threshold |
0.8 | 合并相邻 Chunk 的阈值 |
max_chunk_size |
1000 | Chunk 最大字符数 |
merging_range |
1 | 合并时向前查看的 Chunk 数(1 或 2) |
算法流程:
ini
阶段一:初始化分块
- 逐句扫描,若当前句子与 Chunk 的相似度 < initial_threshold,则开新 Chunk
- 若相似度 >= appending_threshold 且未超 max_chunk_size,则追加到当前 Chunk
阶段二:合并分块
- 检查相邻 Chunk 的相似度,若 >= merging_threshold 且合并后不超 max_chunk_size,则合并
- merging_range=2 时,还会检查隔一个 Chunk 的相似度LanguageConfig 支持的语言 :目前仅支持 english、german、spanish。若需处理中文,应使用 embed_model 参数。
python
from llama_index.core.node_parser import SemanticDoubleMergingSplitterNodeParser
parser = SemanticDoubleMergingSplitterNodeParser(
embed_model=embed_model,
initial_threshold=0.6,
appending_threshold=0.8,
merging_threshold=0.8,
max_chunk_size=1000,
merging_range=1,
)
nodes = parser.get_nodes_from_documents(documents)七、结构化分块策略详解
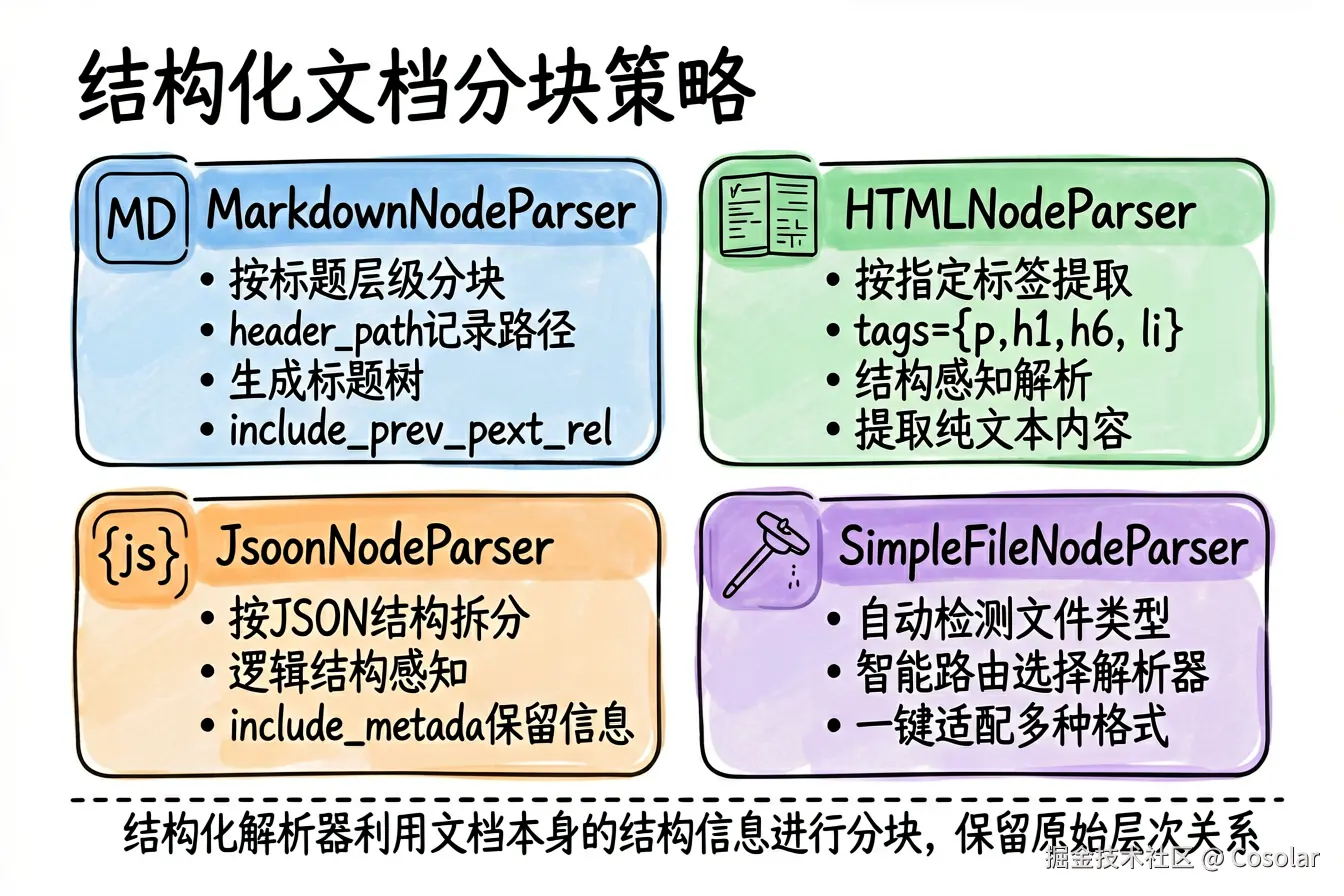
7.1 MarkdownNodeParser
核心思想 :基于 Markdown 标题层级(#, ##, ### 等)进行分块,每个节点包含其文本内容和标题路径。
核心参数 (源码来自 markdown.py):
| 参数 | 默认值 | 说明 |
|---|---|---|
include_metadata |
True | 是否在节点中包含元数据 |
include_prev_next_rel |
True | 是否包含前后节点关系 |
header_path_separator |
"/" |
标题路径分隔符 |
效果示例:
markdown
# 第一章
## 1.1 概述
这是概述内容。
## 1.2 详情
这是详情内容。将被解析为:
- Node 1:标题路径 =
"第一章/1.1 概述",内容 ="这是概述内容。" - Node 2:标题路径 =
"第一章/1.2 详情",内容 ="这是详情内容。"
python
from llama_index.core.node_parser import MarkdownNodeParser
parser = MarkdownNodeParser(
header_path_separator="/",
include_metadata=True,
)
nodes = parser.get_nodes_from_documents(documents)7.2 HTMLNodeParser
核心思想:基于 HTML 标签进行分块,从指定标签中提取文本。
核心参数 (源码来自 html.py):
| 参数 | 默认值 | 说明 |
|---|---|---|
tags |
["p", "h1"~"h6", "li", "b", "i", "u", "section"] |
要提取文本的 HTML 标签列表 |
python
from llama_index.core.node_parser import HTMLNodeParser
parser = HTMLNodeParser(
tags=["p", "h1", "h2", "h3", "table", "li"],
)
nodes = parser.get_nodes_from_documents(documents)7.3 JSONNodeParser
核心思想:基于 JSON 结构进行分块,将 JSON 文档按逻辑结构拆分为独立节点。
python
from llama_index.core.node_parser import JSONNodeParser
parser = JSONNodeParser(
include_metadata=True,
include_prev_next_rel=True,
)
nodes = parser.get_nodes_from_documents(documents)7.4 SimpleFileNodeParser
核心思想:根据文件类型自动选择合适的 NodeParser,是"智能路由"入口。
python
from llama_index.core.node_parser import SimpleFileNodeParser
parser = SimpleFileNodeParser()
nodes = parser.get_nodes_from_documents(documents)八、层级/关系分块策略详解
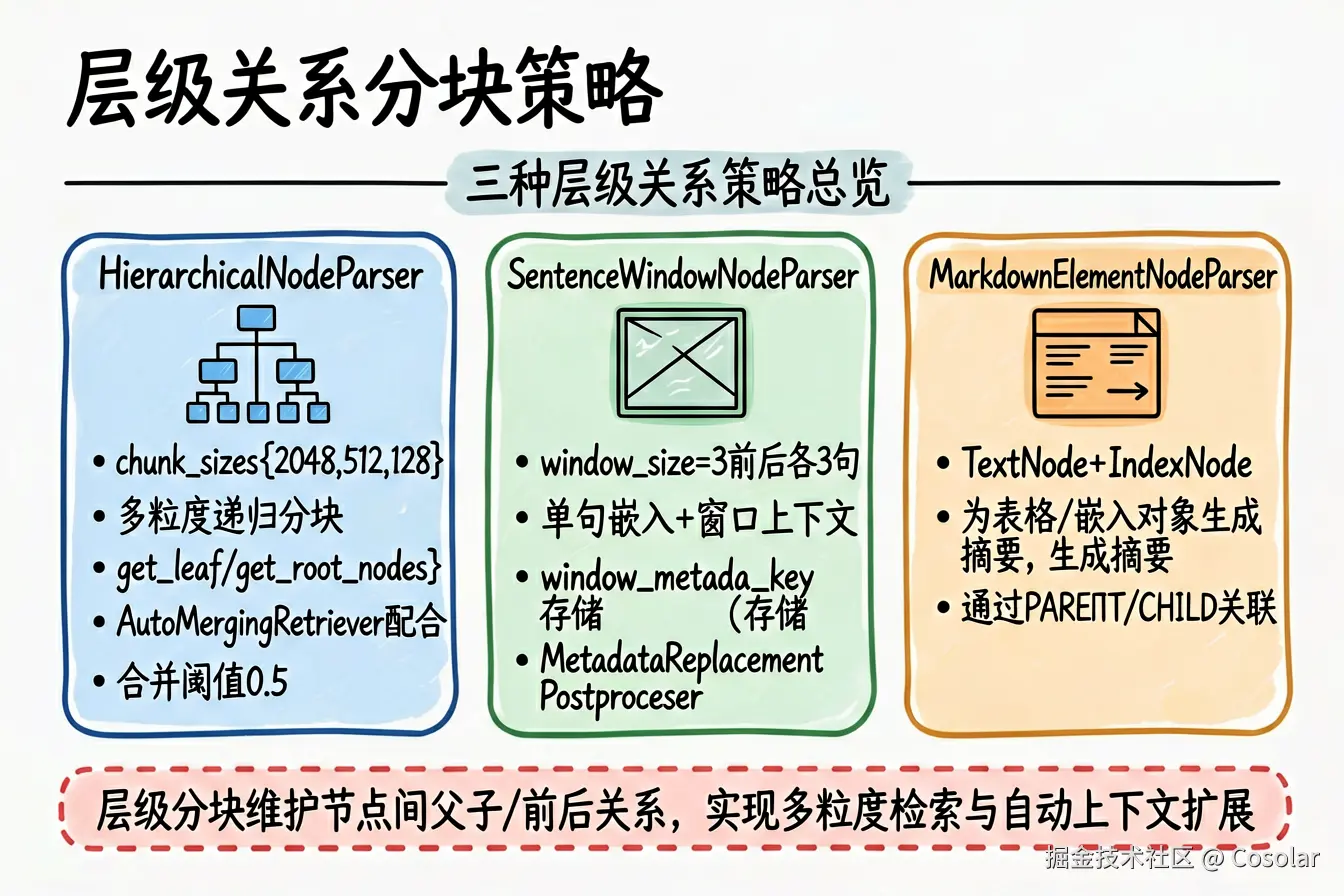
8.1 HierarchicalNodeParser(层级分块器)
核心思想 :将文档按多个粒度递归分块,形成父子层级关系。这是 AutoMergingRetriever 的基础。
核心参数 (源码来自 hierarchical.py):
| 参数 | 默认值 | 说明 |
|---|---|---|
chunk_sizes |
[2048, 512, 128] |
各层级的 Chunk 大小列表 |
层级结构示例:
ini
Level 0: chunk_size=2048 (顶层大块)
├── Level 1: chunk_size=512 (中等子块)
│ ├── Level 2: chunk_size=128 (最小叶节点)
│ ├── Level 2: chunk_size=128
│ └── Level 2: chunk_size=128
├── Level 1: chunk_size=512
│ └── ...辅助函数:
python
from llama_index.core.node_parser import (
HierarchicalNodeParser,
get_leaf_nodes,
get_root_nodes,
get_child_nodes,
get_deeper_nodes,
)
parser = HierarchicalNodeParser.from_defaults(
chunk_sizes=[2048, 512, 128]
)
nodes = parser.get_nodes_from_documents(documents)
leaf_nodes = get_leaf_nodes(nodes) # 获取叶节点(最小粒度)
root_nodes = get_root_nodes(nodes) # 获取根节点(最大粒度)
child_nodes = get_child_nodes(some_nodes, all_nodes) # 获取子节点与 AutoMergingRetriever 配合:
python
from llama_index.core.retrievers import AutoMergingRetriever
from llama_index.core import VectorStoreIndex, StorageContext
# 仅索引叶节点
leaf_nodes = get_leaf_nodes(nodes)
storage_context = StorageContext.from_defaults()
storage_context.docstore.add_documents(nodes) # 存储所有层级节点
index = VectorStoreIndex(leaf_nodes, storage_context=storage_context)
retriever = AutoMergingRetriever(
vector_retriever=index.as_retriever(similarity_top_k=6),
storage_context=storage_context,
simple_ratio_thresh=0.5, # 若超过50%的子节点被检索,则合并为父节点
)AutoMergingRetriever 的合并逻辑 :当检索到的叶节点中,同一父节点下的子节点占比超过 simple_ratio_thresh(默认 0.5),则自动用父节点替换这些子节点,提供更完整的上下文。
8.2 SentenceWindowNodeParser(句子窗口分块器)
核心思想:每个节点只包含一个句子,但在元数据中存储周围句子的"窗口",检索时用单句嵌入,生成时用窗口上下文。
核心参数 (源码来自 sentence_window.py):
| 参数 | 默认值 | 说明 |
|---|---|---|
sentence_splitter |
split_by_sentence_tokenizer | 句子切分函数 |
window_size |
3 | 窗口大小(前后各 N 个句子) |
window_metadata_key |
"window" |
窗口文本的元数据键 |
original_text_metadata_key |
"original_text" |
原始句子的元数据键 |
工作原理:
ini
原文: [S1] [S2] [S3] [S4] [S5] [S6] [S7]
节点 S4 的元数据:
window = "S1 S2 S3 S4 S5 S6 S7" (window_size=3, 前后各3句)
original_text = "S4"
嵌入时: 仅使用 S4 的文本
LLM 生成时: 使用 window 中的完整上下文源码中的关键逻辑:
python
for i, node in enumerate(nodes):
window_nodes = nodes[
max(0, i - self.window_size) : min(i + self.window_size + 1, len(nodes))
]
node.metadata[self.window_metadata_key] = " ".join([n.text for n in window_nodes])
node.metadata[self.original_text_metadata_key] = node.text
# 排除窗口元数据,不参与嵌入和 LLM
node.excluded_embed_metadata_keys.extend([self.window_metadata_key, self.original_text_metadata_key])
node.excluded_llm_metadata_keys.extend([self.window_metadata_key, self.original_text_metadata_key])与 MetadataReplacementPostProcessor 配合:
python
from llama_index.core.node_parser import SentenceWindowNodeParser
from llama_index.core.postprocessor import MetadataReplacementPostProcessor
parser = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
nodes = parser.get_nodes_from_documents(documents)
# 查询时替换为窗口上下文
postprocessor = MetadataReplacementPostProcessor(target_metadata_key="window")
query_engine = index.as_query_engine(
node_postprocessors=[postprocessor],
)8.3 MarkdownElementNodeParser / UnstructuredElementNodeParser
核心思想 :将文档拆分为 TextNode (普通文本)和 IndexNode(嵌入对象,如表格),并自动为嵌入对象生成摘要。
源码来自 base_element.py:
python
class BaseElementNodeParser(NodeParser):
llm: Optional[LLM] = Field(default=None, description="LLM model to use for summarization.")
summary_query_str: str = Field(default=DEFAULT_SUMMARY_QUERY_STR)
num_workers: int = Field(default=DEFAULT_NUM_WORKERS)- MarkdownElementNodeParser:从 Markdown 中提取表格等元素
- UnstructuredElementNodeParser:使用 Unstructured 库提取元素
- LlamaParseJsonNodeParser:从 LlamaParse 的 JSON 输出中提取元素
python
from llama_index.core.node_parser import MarkdownElementNodeParser
parser = MarkdownElementNodeParser()
nodes = parser.get_nodes_from_documents(documents)
# nodes 中包含 TextNode(文本)和 IndexNode(表格摘要)
# IndexNode 通过 PARENT/CHILD 关系关联到原始表格内容九、分块策略选型指南
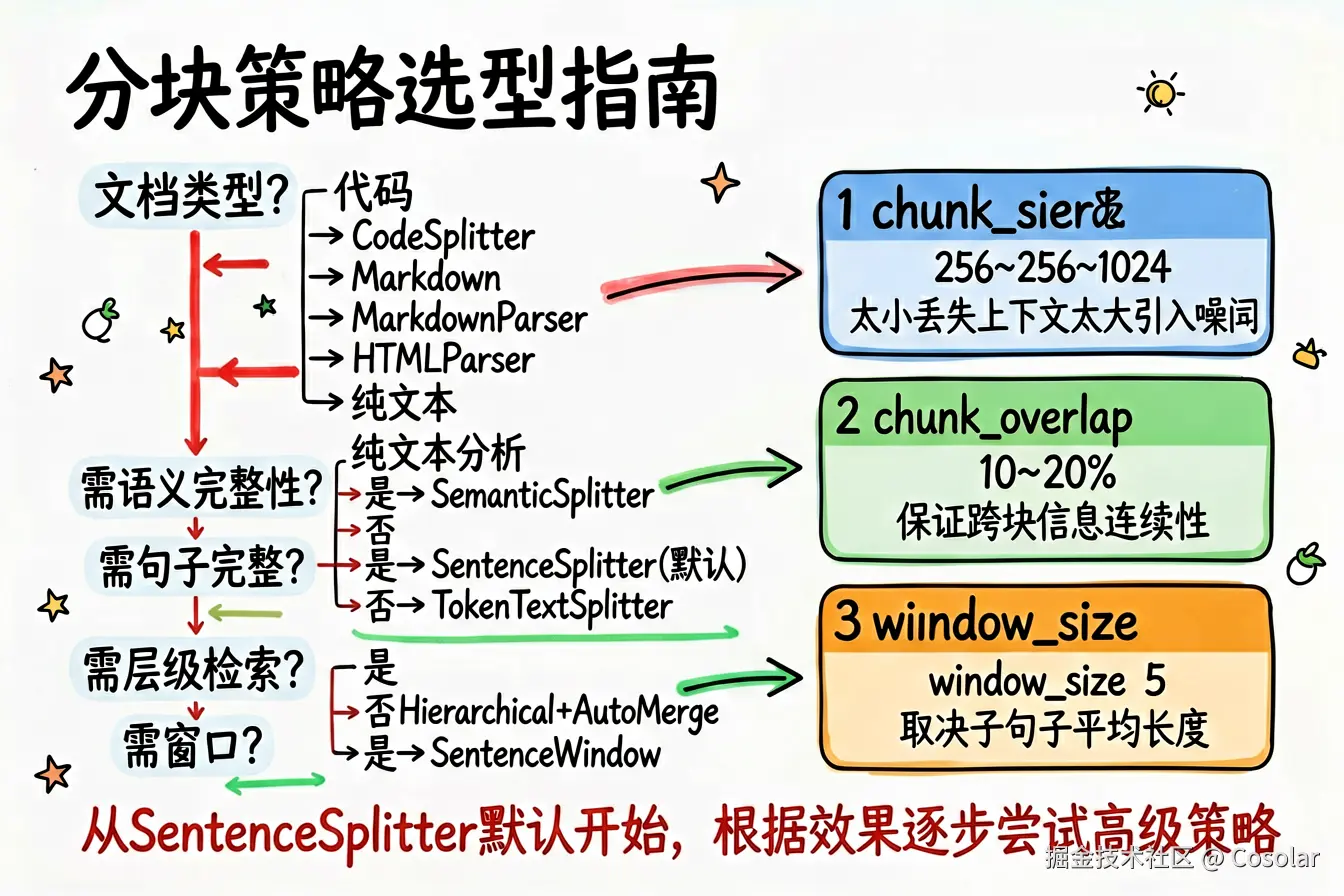
9.1 决策流程图
javascript
文档类型是什么?
├── 代码 → CodeSplitter
├── Markdown → MarkdownNodeParser 或 MarkdownElementNodeParser
├── HTML → HTMLNodeParser
├── JSON → JSONNodeParser
├── 混合格式 → SimpleFileNodeParser
└── 纯文本
├── 需要语义完整性?
│ ├── 是 → SemanticSplitterNodeParser
│ └── 否
│ ├── 需要句子完整性? → SentenceSplitter(默认)
│ └── 严格 Token 控制? → TokenTextSplitter
└── 需要层级检索?
├── 是 → HierarchicalNodeParser + AutoMergingRetriever
└── 需要上下文窗口?
└── 是 → SentenceWindowNodeParser9.2 关键参数调优建议
| 参数 | 建议值 | 说明 |
|---|---|---|
chunk_size |
256~1024 | 太小丢失上下文,太大引入噪声。嵌入模型维度越低,chunk_size 应越小 |
chunk_overlap |
chunk_size 的 10%~20% | 保证跨块信息的连续性 |
breakpoint_percentile_threshold |
90~95 | 越低产生越多分块,适合主题变化频繁的文档 |
window_size |
2~5 | 句子窗口大小,取决于句子平均长度和所需上下文量 |
simple_ratio_thresh |
0.3~0.5 | AutoMerging 的合并阈值,越低越容易合并 |
9.3 性能对比
| 策略 | 分块精度 | 语义完整性 | 计算开销 | 适用场景 |
|---|---|---|---|---|
| TokenTextSplitter | 低 | 低 | 极低 | 快速原型、Token 限制严格 |
| SentenceSplitter | 中 | 中 | 低 | 通用场景(默认选择) |
| SemanticSplitter | 高 | 高 | 高(需嵌入计算) | 主题变化明显的长文档 |
| HierarchicalParser | 高 | 高 | 中 | 需要多粒度检索 |
| SentenceWindow | 高 | 高(检索时) | 低 | 需要精确匹配+上下文扩展 |
| MarkdownNodeParser | 高 | 高 | 低 | 结构化 Markdown 文档 |
十、全局配置与自定义
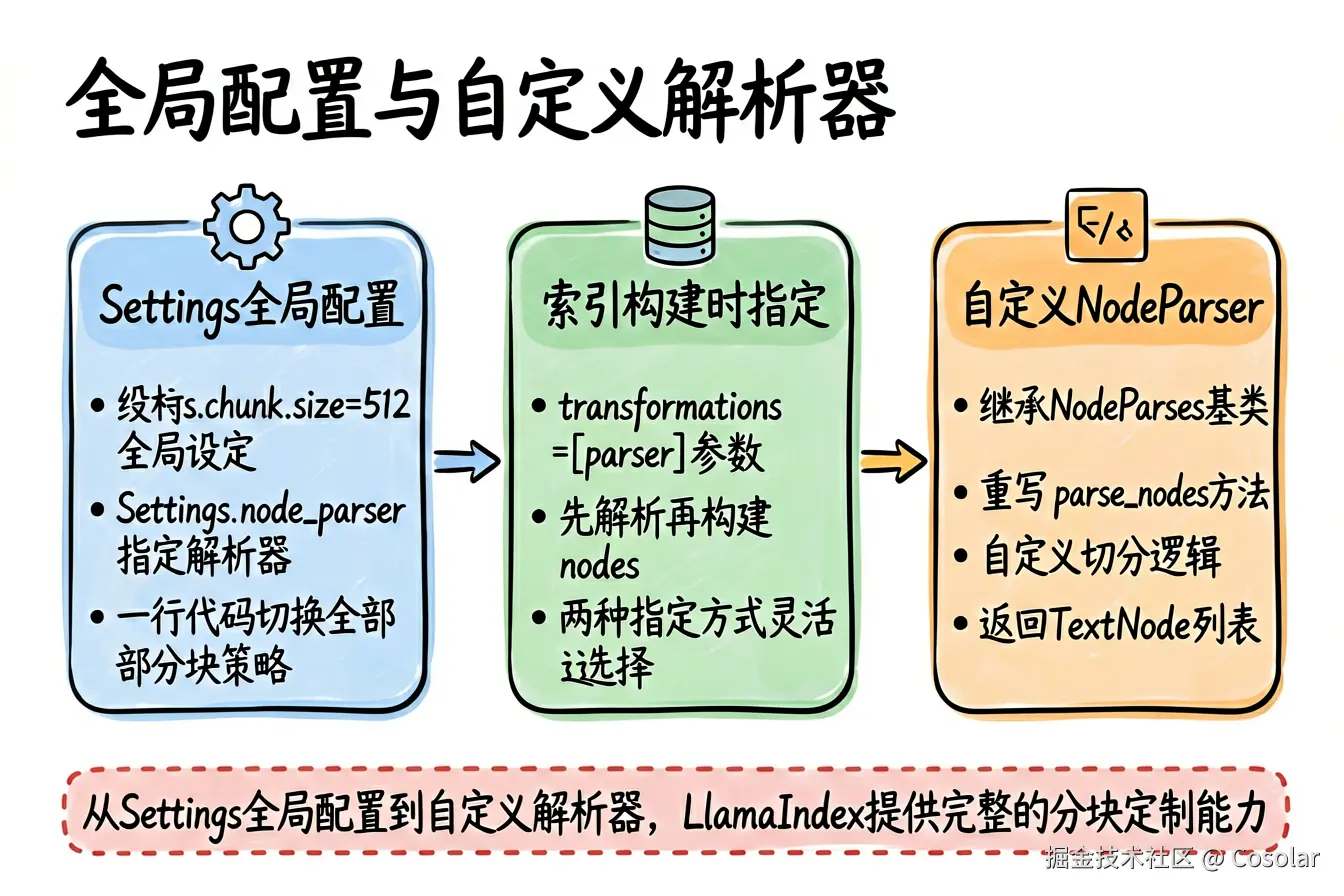
10.1 通过 Settings 全局配置
python
from llama_index.core import Settings
from llama_index.core.node_parser import SentenceSplitter
Settings.chunk_size = 512
Settings.chunk_overlap = 50
# 或直接设置解析器
Settings.node_parser = SentenceSplitter(
chunk_size=512,
chunk_overlap=50,
)10.2 在索引构建时指定
python
from llama_index.core import VectorStoreIndex
from llama_index.core.node_parser import SemanticSplitterNodeParser
parser = SemanticSplitterNodeParser(
buffer_size=1,
breakpoint_percentile_threshold=95,
embed_model=Settings.embed_model,
)
# 方式一:通过 transformations 参数
index = VectorStoreIndex.from_documents(
documents,
transformations=[parser],
)
# 方式二:先解析再构建
nodes = parser.get_nodes_from_documents(documents)
index = VectorStoreIndex(nodes)10.3 自定义 NodeParser
python
from llama_index.core.node_parser import NodeParser
from llama_index.core.schema import BaseNode, TextNode
from typing import List, Sequence
class CustomParagraphParser(NodeParser):
"""按自定义段落标记分块的解析器"""
def _parse_nodes(
self,
nodes: Sequence[BaseNode],
show_progress: bool = False,
**kwargs,
) -> List[BaseNode]:
result = []
for node in nodes:
text = node.get_content()
paragraphs = text.split("===PARA===")
for para in paragraphs:
if para.strip():
new_node = TextNode(
text=para.strip(),
metadata=node.metadata.copy(),
)
result.append(new_node)
return result十一、总结
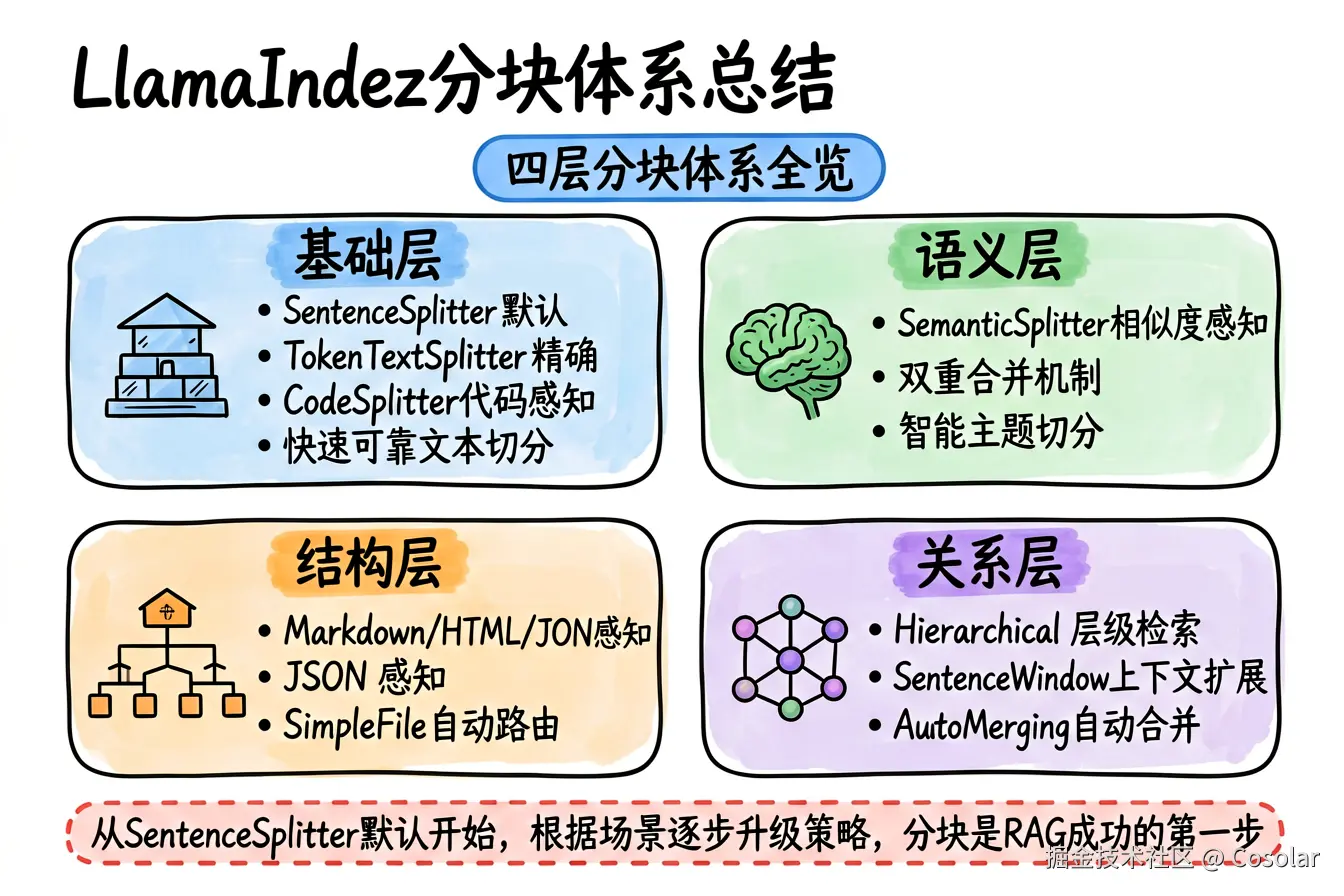
LlamaIndex 的文档解析与分块体系提供了从简单到复杂的完整解决方案:
- 基础层 :
SentenceSplitter(默认)和TokenTextSplitter提供快速可靠的文本切分 - 语义层 :
SemanticSplitterNodeParser和SemanticDoubleMergingSplitterNodeParser实现语义感知的智能分块 - 结构层 :
MarkdownNodeParser、HTMLNodeParser、JSONNodeParser针对结构化文档 - 关系层 :
HierarchicalNodeParser+AutoMergingRetriever、SentenceWindowNodeParser提供层级检索和上下文扩展能力
选择合适的分块策略,是构建高质量 RAG 系统的第一步,也是最关键的一步。建议从默认的 SentenceSplitter 开始,根据检索效果逐步尝试更高级的策略。