前言
这次整理的是浏览器用户画像分析大屏的完整搭建过程。
前面已经完成了用户画像统计表 user_profile_stats 的加工,本次主要围绕这张表继续做数据大屏:先在助睿 Max 中搭出用户画像页面,再通过蓝图编辑器把数据接入地图、指标卡、饼图、柱状图和排行榜,最后补上页面切换、地图热力层和省份点击联动。
整个过程可以理解成一条连续的大屏配置流程:
text
user_profile_stats 用户画像统计表
→ 用户画像大屏静态布局
→ 蓝图编辑器接入真实数据
→ 浏览器筛选器联动多个图表
→ 市场分析 / 用户画像大屏切换
→ 地图省份点击联动核心指标
→ 地图热力层按省份用户数渲染
→ 保存、预览、发布这类大屏看起来是"拖组件",但真正配置时会发现,关键点主要在三处:
第一,页面结构要围绕分析问题设计。
用户画像大屏不是把所有字段都摆上去,而是要回答"用户是谁、来自哪里、结构如何、不同浏览器之间有没有差异"。
第二,蓝图接入时要处理好字段格式。
饼图要 name/value,柱状图要 x/y/s,指标卡要 value,地图热力层还要 area_id。SQL 查询成功不代表图表一定能显示,字段格式不对也会导致组件为空。
第三,交互逻辑要串起来。
浏览器筛选器、Tab 切换、地图点击、省份指标查询、热力层渲染,这些都不是单独存在的组件,而是要通过蓝图节点连成完整的数据流。
第一部分:实验背景
1.1 实验目的
本次实验使用 助睿数智(Uniplore)一站式数据科学实验平台 完成浏览器用户画像大屏的静态布局、数据接入和交互联动配置。
平台信息如下:
text
平台全称:助睿数智(Uniplore)一站式数据科学实验平台
平台定位:覆盖数据接入、ETL处理、机器学习建模到可视化分析的全链路 Agentic 零代码数据智能产品
产品官网:https://www.uniplore.com/
实验平台地址:https://lab.guilian.cn/本次主要使用助睿 Max 数据大屏平台。助睿 Max 支持拖拽式页面搭建、图层管理、地图可视化、图表组件配置、筛选器组件以及蓝图编辑器。整个过程不需要单独开发前端页面,而是通过组件配置和蓝图连线完成大屏搭建。
本次实验要掌握的内容包括:
text
1. 根据用户画像分析需求设计大屏信息结构;
2. 使用地图、指标卡、饼图、柱状图、条形图和轮播列表搭建静态页面;
3. 将大屏组件导出到蓝图编辑器;
4. 使用 SQL 请求节点查询 user_profile_stats 表;
5. 使用并行数据处理节点把查询结果分发给不同图表;
6. 配置浏览器筛选器,实现多图表联动刷新;
7. 使用 Tab 列表和图层可见性控制,实现市场分析和用户画像切换;
8. 使用地图点击事件,实现省份级核心指标联动;
9. 配置区域热力层,让地图根据省份用户数显示颜色深浅。1.2 实验数据
本次大屏使用的核心数据表是:
text
user_profile_stats这张表是前序流程已经加工好的用户画像统计表,按浏览器维度保存用户的人口属性和地域分布信息。它不是原始日志表,而是大屏可以直接读取的统计结果表。
主要字段如下:
| 字段 | 含义 | 在大屏中的用途 |
|---|---|---|
| browser_name | 浏览器名称 | 浏览器筛选条件 |
| gender | 性别 | 性别分布饼图 |
| age | 年龄 | 平均年龄指标 |
| age_group | 年龄段 | 年龄段分布柱状图 |
| edu | 学历 | 学历分布、本科及以上占比 |
| job | 职业 | 职业分布柱状图 |
| income | 收入 | 收入分布、中高收入占比 |
| city_type | 居住地类型 | 城市 / 城郊 / 乡村占比 |
| province | 省份 | 中国地图、省份 TOP5、地图点击联动 |
| user_count | 用户数 | 各类统计图表的基础数值 |
使用统计表而不是原始日志表的好处是,大屏端不需要每次都做复杂聚合,只需要读取已经整理好的结果。这样页面加载和筛选刷新会更稳定,图表配置也更清楚。
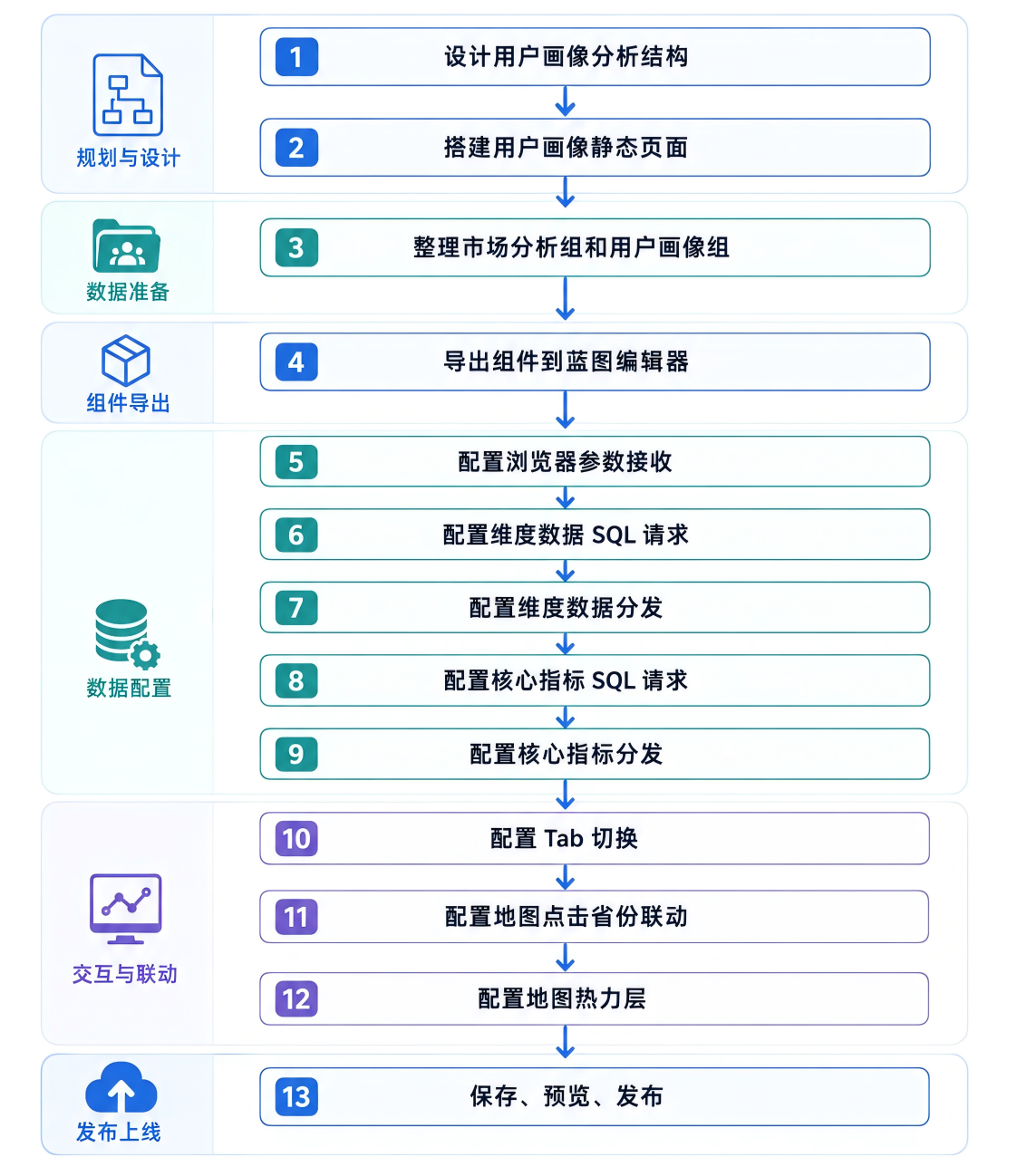
1.3 整体流程
这次大屏配置可以分成三个连续阶段。
第一阶段是页面布局。
先在助睿 Max 中搭建用户画像大屏,完成地图、指标卡、排行榜、饼图、柱状图、条形图和筛选器的静态布局。
第二阶段是数据接入。
进入蓝图编辑器,把 user_profile_stats 表中的数据接入各个图表,并通过浏览器筛选器控制所有组件刷新。
第三阶段是交互增强。
配置市场分析和用户画像两个大屏的切换;配置地图点击省份后联动核心指标卡;配置地图热力层,根据省份用户数渲染颜色深浅。
整体流程如下:
第二部分:实验步骤
2.1 先搭页面骨架:从用户画像大屏的分析结构开始
做用户画像大屏之前,我先把页面要回答的问题列出来。这样后面选组件时就不会变成"哪里空就放哪里"。
用户画像大屏主要回答这些问题:
| 分析问题 | 对应字段 | 展示组件 |
|---|---|---|
| 用户主要来自哪些省份? | province、user_count | 中国地图 |
| 哪些省份用户数最高? | province、user_count | TOP5 轮播列表 |
| 当前浏览器用户规模多大? | user_count | 数字翻牌器 |
| 用户平均年龄是多少? | age、user_count | 数字翻牌器 |
| 本科及以上用户占比多少? | edu、user_count | 数字翻牌器 |
| 中高收入用户占比多少? | income、user_count | 数字翻牌器 |
| 男女比例如何? | gender、user_count | 饼图 |
| 年龄结构如何? | age_group、user_count | 柱状图 |
| 学历结构如何? | edu、user_count | 水平柱状图 |
| 职业结构如何? | job、user_count | 柱状图 |
| 收入结构如何? | income、user_count | 柱状图 |
| 城市、城郊、乡村用户占比如何? | city_type、user_count | 饼图 |
| 不同浏览器用户画像是否不同? | browser_name | 下拉筛选器 |
页面结构我按"先看整体,再看细节"的思路来安排:
text
顶部:标题、浏览器筛选器、页面切换入口
中间:省份地图、核心指标卡、省份 TOP5
两侧:性别、年龄、学历、职业、收入、居住地类型图表地图负责回答"用户从哪里来",指标卡负责展示核心结论,细分图表负责解释用户结构,排行榜补充具体省份排名。
配置要点:
text
1. 先确定分析问题,再选择图表组件。
2. 地图适合展示省份空间分布。
3. 指标卡适合展示总用户数、平均年龄、本科及以上占比、中高收入占比。
4. 饼图适合展示性别、居住地类型这类占比结构。
5. 柱状图和条形图适合展示年龄、学历、职业、收入等分类对比。2.2 整理图层结构:让市场分析和用户画像共存在同一个大屏文件中
当前大屏文件中已经有市场分析页面,本次新增用户画像页面。为了后面实现两个页面之间的切换,我先在图层面板中把组件分组整理好。
图层结构如下:
text
市场分析组
用户画像组市场分析组中放已有的市场分析图表。
用户画像组中放本次新增的地图、指标卡、画像图表、排行榜和筛选器。
这样做有一个明显好处:后面配置 Tab 切换时,只需要控制两个图层组的显示和隐藏,不需要单独控制每一个组件。

配置要点:
text
1. 市场分析相关组件统一放入"市场分析组"。
2. 用户画像相关组件统一放入"用户画像组"。
3. 制作用户画像页面时,可以先隐藏市场分析组,避免组件重叠。
4. 图层命名要清楚,后面导出到蓝图编辑器时会直接显示这些名称。2.3 主视觉区域:用中国地图展示用户省份分布
用户画像大屏中,我把中国地图放在主视觉区域。省份分布属于空间信息,用地图展示比普通柱状图更直观。
操作时添加:
text
基础平面地图然后在地图组件中添加:
text
区域热力层区域热力层用于后面根据省份用户数显示颜色深浅。静态布局阶段先把它加好,后面进入蓝图时再导入真实数据。
这里地图承担两个作用:
text
1. 展示全国各省份用户分布;
2. 捕获用户点击省份的事件,用于后续联动核心指标卡。
配置要点:
text
1. 地图建议放在页面中间或右侧核心区域。
2. 地图组件中需要添加区域热力层。
3. 区域热力层后续需要导入 name、value、area_id。
4. 地图组件后续要导出到蓝图编辑器,用于省份点击事件。2.4 数据概览区域:用四个指标卡承接核心结论
地图旁边放四个核心指标卡:
text
总用户数
平均年龄
本科及以上占比
中高收入占比这四个指标分别对应用户规模、年龄水平、教育水平和收入水平。
用户进入页面后,先看这四个数字,就能对当前浏览器用户群体有一个整体判断。
组件使用:
text
数字翻牌器在静态布局阶段,我主要调整标题、数值字体、单位、背景和位置。后续接入数据时,每个指标卡只需要接收一个 value 字段。
配置要点:
text
1. 四个指标卡样式保持一致。
2. 指标标题要明确,不要只显示数字。
3. 百分比指标预留 % 后缀。
4. 指标卡后续接收的数据格式为 [{ value: 数值 }]。2.5 排名补充:用 TOP5 列表补足地图不够精确的问题
地图适合看空间分布,但不适合看具体排名。比如地图能看出某些区域颜色更深,但不能直接告诉用户前五名是谁。
所以我在地图附近添加了"省份用户数 TOP5"排行榜,使用轮播列表组件展示。
后续蓝图返回的数据格式可以设计为:
javascript
[
{ province: '广东', user_count: 120 },
{ province: '江苏', user_count: 98 }
]这样地图和排行榜形成互补:
text
地图:看全国分布趋势
排行榜:看省份具体排名
配置要点:
text
1. 轮播列表至少包含省份名称和用户数两列。
2. 后续数据字段建议使用 province、user_count。
3. 省份数据要按 user_count 降序排序。
4. 排行榜只取前 5 条即可,避免信息过多。2.6 画像分析区域:配置性别、年龄、学历、职业、收入和居住地类型图表
用户画像的细分区域主要展示性别、年龄、学历、职业、收入和居住地类型。
不同字段适合不同图表:
| 模块 | 使用组件 | 选择原因 |
|---|---|---|
| 性别分布 | 基础饼图 | 类别少,适合展示占比 |
| 年龄段分布 | 基础柱图 | 年龄段有顺序,适合比较 |
| 学历分布 | 水平基础柱图 | 学历名称较长,横向展示更清楚 |
| 职业分布 | 基础柱图 | 适合比较不同职业用户数 |
| 收入分布 | 柱状图或水平柱图 | 收入段有顺序,适合看分布 |
| 居住地类型分布 | 饼图或轮播饼图 | 类别少,适合看结构 |
配置时我把组件名称改成了业务名称,例如:
text
性别分布饼图
年龄段分布柱状图
学历分布条形图
职业分布柱状图
收入分布柱状图
居住地类型饼图后面导出到蓝图编辑器时,节点名称会直接沿用这些组件名称。提前命名可以减少后面连线时的判断成本。
配置要点:
text
1. 饼图后续需要 name、value 字段。
2. 柱状图后续需要 x、y、s 字段。
3. 水平柱图适合学历这种文本较长的字段。
4. 组件命名要和业务含义一致。
5. 所有画像图表统一放入"用户画像组"。2.7 全局筛选入口:配置浏览器下拉选择器
浏览器筛选器放在页面顶部右侧,作为整张用户画像大屏的统一筛选入口。用户进入页面后,可以先选择浏览器,再观察地图、指标卡和各类画像图表的变化。
组件使用:
text
下拉选择组件命名为:
text
浏览器筛选器筛选器选项值需要和 user_profile_stats 表中的 browser_name 保持一致,例如:
text
IE 浏览器
360 极速
360se
Google
搜狗
QQ 浏览器这里要注意,筛选器显示什么不重要,关键是输出值必须能和数据库字段匹配。比如表里存的是 Google,筛选器就不要写成 Chrome,否则后面 SQL 查询会查不到对应数据。
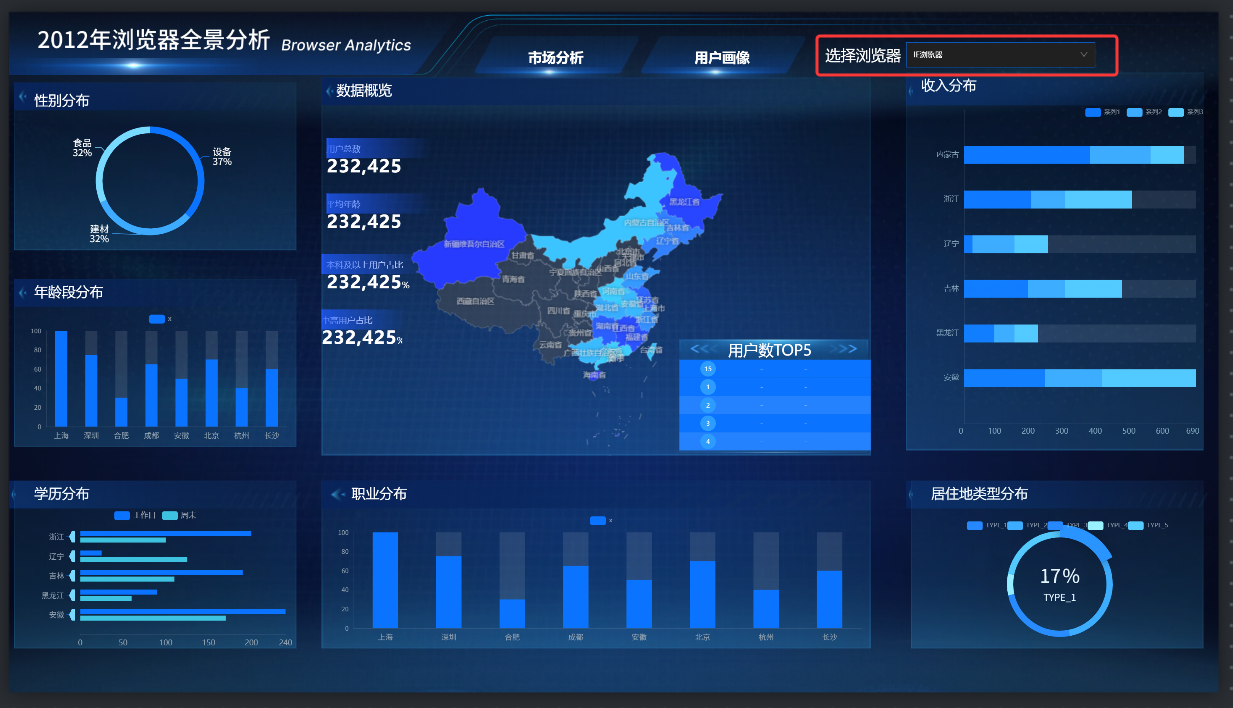
配置要点:
text
1. 筛选器选项值必须和 browser_name 字段一致。
2. 筛选器适合放在顶部,作为全局过滤入口。
3. 建议设置默认选中项,保证页面初始化时有数据。
4. 该组件后续需要导出到蓝图编辑器,用来触发数据刷新。2.8 进入蓝图编辑器:把静态组件导出为可交互节点
静态页面搭好后,组件还不能读取数据库数据。要让它参与数据交互,需要先导出到蓝图编辑器。
我导出的组件主要包括:
text
浏览器筛选器
用户省份分布地图
省份 TOP5 轮播列表
性别分布饼图
年龄段分布柱状图
学历分布条形图
职业分布柱状图
收入分布柱状图
居住地类型饼图
总用户数指标卡
平均年龄指标卡
本科及以上占比指标卡
中高收入占比指标卡
市场分析组
用户画像组
Tab 列表组件背景图、装饰线、标题背景这类组件如果不参与交互,就不需要导出。蓝图节点越少,后面越好维护。
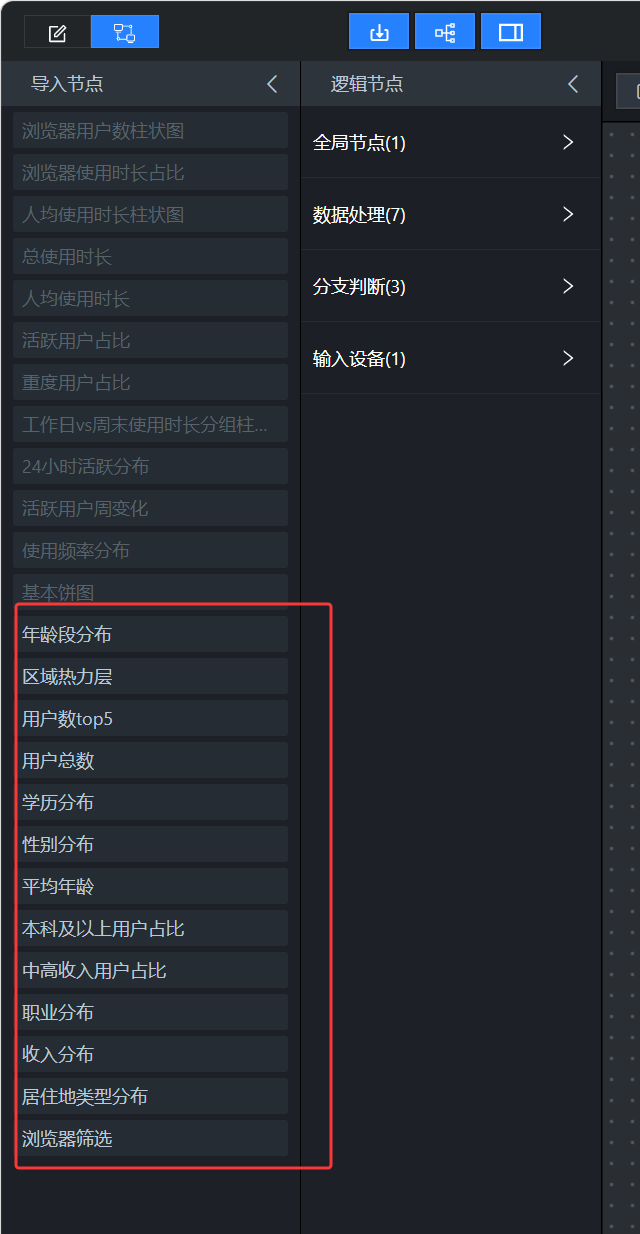
配置要点:
text
1. 需要接收数据的图表组件要导出。
2. 需要触发事件的筛选器和地图要导出。
3. 需要控制显示隐藏的图层组要导出。
4. 装饰类组件一般不用导出。
5. 导出前确保组件名称已经改成业务名称。2.9 浏览器参数接收:让筛选器成为整张大屏的数据入口
浏览器筛选器只负责输出当前选中的浏览器名称。比如用户选择 Google,它输出的就是 Google。
为了让这个值能被多个 SQL 节点复用,我添加了一个并行数据处理节点,命名为:
text
浏览器参数接收处理代码如下:
javascript
const SELECTED_BROWSER = data.value;
window.GLOBAL_SELECTED_BROWSER = SELECTED_BROWSER;
return { value: SELECTED_BROWSER };这段代码把当前浏览器保存到全局变量:
javascript
window.GLOBAL_SELECTED_BROWSER后面的维度数据 SQL、核心指标 SQL、地图省份指标 SQL 都可以读取这个变量。
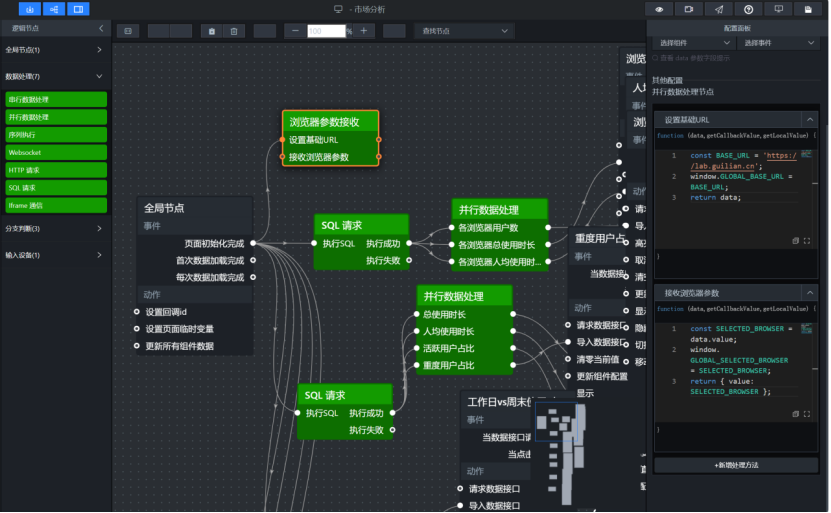
配置要点:
text
1. data.value 要和筛选器实际输出结构一致。
2. 全局变量名称保持统一,后续都使用 GLOBAL_SELECTED_BROWSER。
3. 页面加载时也要触发一次数据请求。
4. 如果切换浏览器后图表没变,先检查这个变量有没有更新。2.10 维度数据接入:一次 SQL 查询多个画像维度
用户画像图表比较多,如果每个图表都单独写一个 SQL 请求节点,蓝图会很臃肿。这里采用一次查询多个维度,再分发给不同图表的方式。
添加 SQL 请求节点,命名为:
text
维度数据 SQL 请求SQL 写法如下:
javascript
const selectedBrowser = window.GLOBAL_SELECTED_BROWSER;
let sql = `
-- 性别分布
select
'gender' as dimension_type,
gender as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
group by gender
union all
-- 年龄段分布
select
'age' as dimension_type,
age_group as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
group by age_group
union all
-- 学历分布
select
'edu' as dimension_type,
edu as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
group by edu
union all
-- 职业分布
select
'job' as dimension_type,
job as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
group by job
union all
-- 收入分布
select
'income' as dimension_type,
income as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
group by income
union all
-- 居住地类型分布
select
'city_type' as dimension_type,
city_type as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
group by city_type
union all
-- 省份分布
select
'province' as dimension_type,
province as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
group by province
`;
return sql;这个 SQL 返回统一的三列:
text
dimension_type
name
value例如:
text
gender 男 320
age 18-25 180
province 广东 96后面只需要根据 dimension_type 判断数据属于哪个维度,就能分发到不同组件。
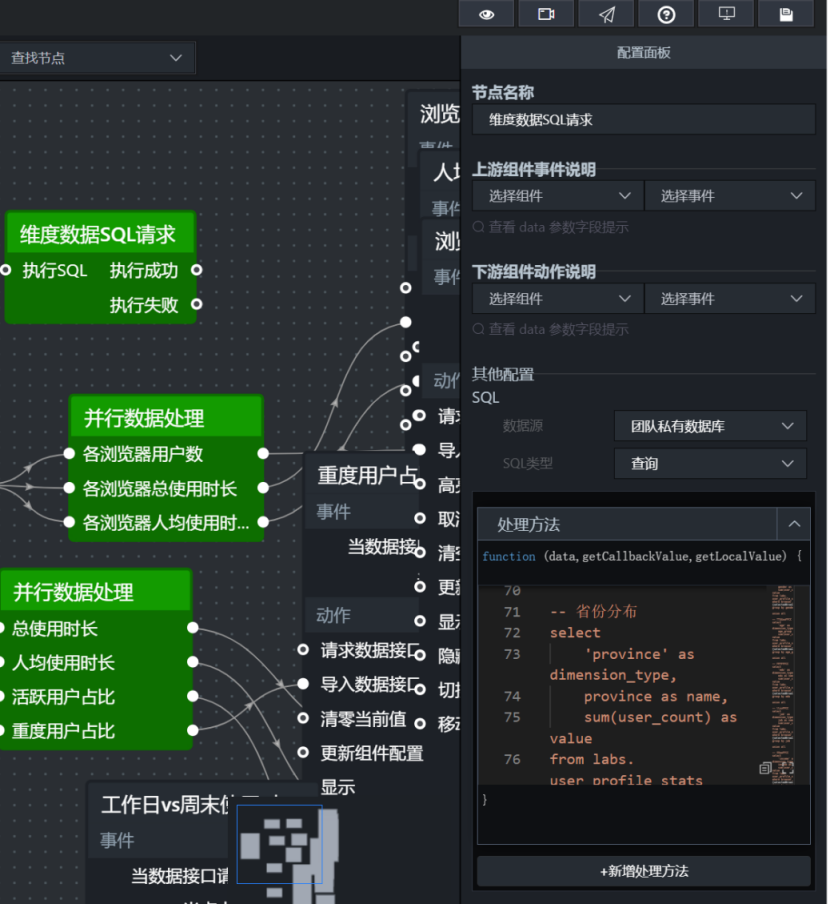
配置要点:
text
1. 每段 SQL 返回字段必须统一。
2. dimension_type 用来标识维度类型。
3. name 作为图表分类字段。
4. value 作为图表数值字段。
5. 使用 sum(user_count),不要直接 count 行数。2.11 数据分发:按 dimension_type 把查询结果送到不同图表
维度 SQL 查询出来的是一张混合表,里面包含性别、年龄、学历、职业、收入、居住地类型和省份数据。接下来需要把它拆开。
添加并行数据处理节点,命名为:
text
维度数据分发性别饼图分支:
javascript
var filtered = data.filter(item => item.dimension_type === 'gender');
return filtered.map(item => ({
name: item.name,
value: item.value
}));年龄段柱状图分支:
javascript
var filtered = data.filter(item => item.dimension_type === 'age');
var order = ['<18', '18-25', '26-35', '36-45', '>45'];
filtered.sort((a, b) => order.indexOf(a.name) - order.indexOf(b.name));
return filtered.map(item => ({
x: item.name,
y: item.value,
s: '用户数'
}));学历分布分支:
javascript
var filtered = data.filter(item => item.dimension_type === 'edu');
var order = ['小学及以下', '初中', '高中/中专/技校', '大专', '大学本科', '硕士及以上'];
filtered.sort((a, b) => order.indexOf(a.name) - order.indexOf(b.name));
return filtered.map(item => ({
x: item.name,
y: item.value,
s: '学历'
}));职业分布分支:
javascript
var filtered = data.filter(item => item.dimension_type === 'job');
return filtered.map(item => ({
x: item.name,
y: item.value,
s: '职业'
}));收入分布分支:
javascript
var filtered = data.filter(item => item.dimension_type === 'income');
var getMinIncome = (incomeStr) => {
if (incomeStr === '无收入') return -1;
if (incomeStr === '500元及以下') return 0;
var match = incomeStr.match(/(\d+)/);
return match ? parseInt(match[1]) : 999999;
};
filtered.sort((a, b) => getMinIncome(a.name) - getMinIncome(b.name));
return filtered.map(item => ({
x: item.name,
y: item.value,
s: '收入'
}));居住地类型饼图分支:
javascript
var filtered = data.filter(item => item.dimension_type === 'city_type');
return filtered.map(item => ({
name: item.name === 'unknown' ? '未知' : item.name,
value: item.value
}));省份 TOP5 排行榜分支:
javascript
var filtered = data.filter(item => item.dimension_type === 'province');
filtered.sort((a, b) => b.value - a.value);
var top5 = filtered.slice(0, 5);
return top5.map(item => ({
province: item.name,
user_count: item.value
}));分发节点配置完成后,把每个分支连接到对应组件的"导入数据接口"。
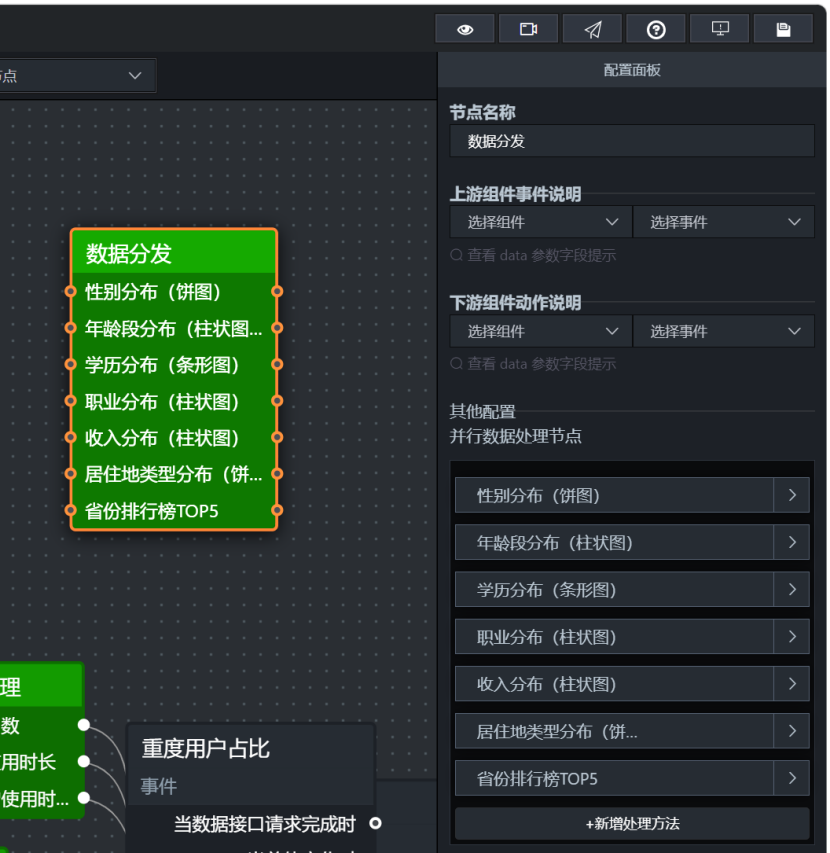
配置要点:
text
1. 饼图返回 name、value。
2. 柱状图返回 x、y、s。
3. 轮播列表返回 province、user_count。
4. 年龄、学历、收入这类有顺序的数据最好手动排序。
5. 图表为空时,优先检查字段格式是否符合组件要求。2.12 核心指标接入:单独查询总用户数、平均年龄、本科及以上占比和中高收入占比
核心指标卡和普通图表不同。普通图表展示一组分类数据,而指标卡只展示一个数字。
因此我单独添加一个 SQL 请求节点,命名为:
text
核心指标 SQL 请求SQL 如下:
javascript
const selectedBrowser = window.GLOBAL_SELECTED_BROWSER;
let sql = `
-- 总用户数
select
'total_users' as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
union all
-- 平均年龄
select
'avg_age' as name,
round(sum(age * user_count) / sum(user_count), 1) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
union all
-- 本科及以上占比
select
'high_edu_ratio' as name,
round(sum(case when edu in ('本科', '硕士及以上') then user_count else 0 end) * 100.0 / sum(user_count), 1) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
union all
-- 中高收入占比
select
'high_income_ratio' as name,
round(sum(case when income in ('5001~8000元', '8001~12000元','12000元以上') then user_count else 0 end) * 100.0 / sum(user_count), 1) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
`;
return sql;查询结果仍然是 name/value 结构。
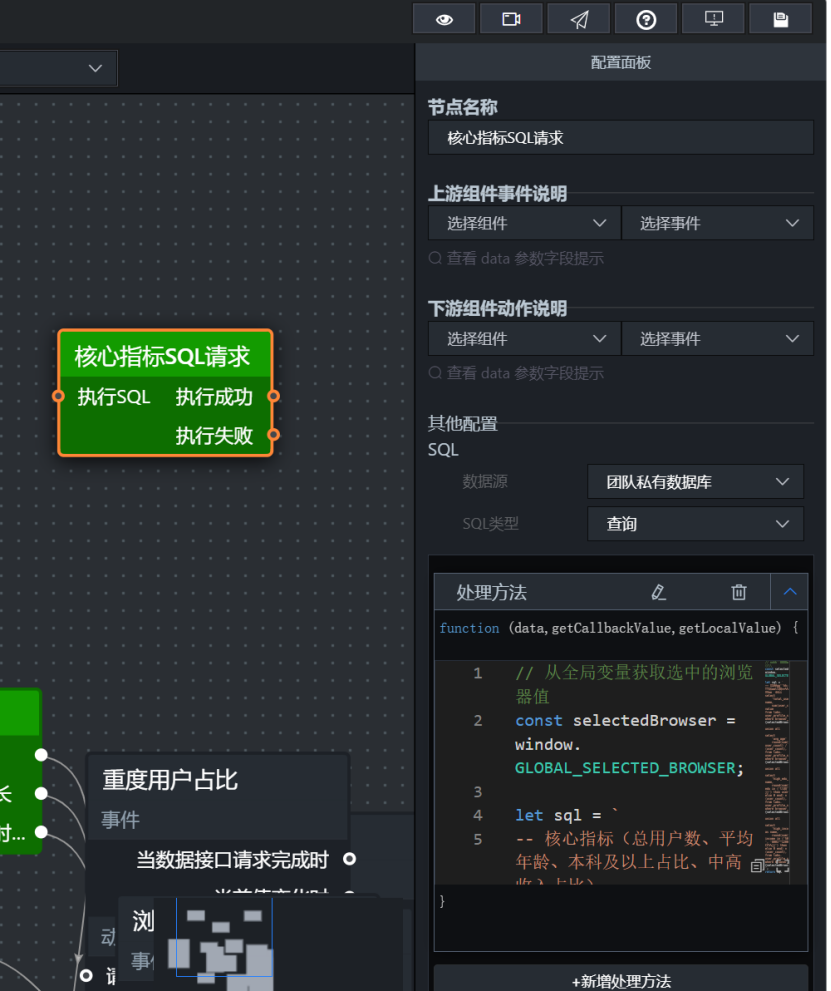
接着添加"核心指标分发"节点,把四个指标分别送到四个数字翻牌器。
总用户数分支:
javascript
var item = data.find(item => item.name === 'total_users');
return [{ value: item ? item.value : 0 }];平均年龄分支:
javascript
var item = data.find(item => item.name === 'avg_age');
return [{ value: item ? item.value : 0 }];本科及以上占比分支:
javascript
var item = data.find(item => item.name === 'high_edu_ratio');
return [{ value: item ? item.value : 0 }];中高收入占比分支:
javascript
var item = data.find(item => item.name === 'high_income_ratio');
return [{ value: item ? item.value : 0 }];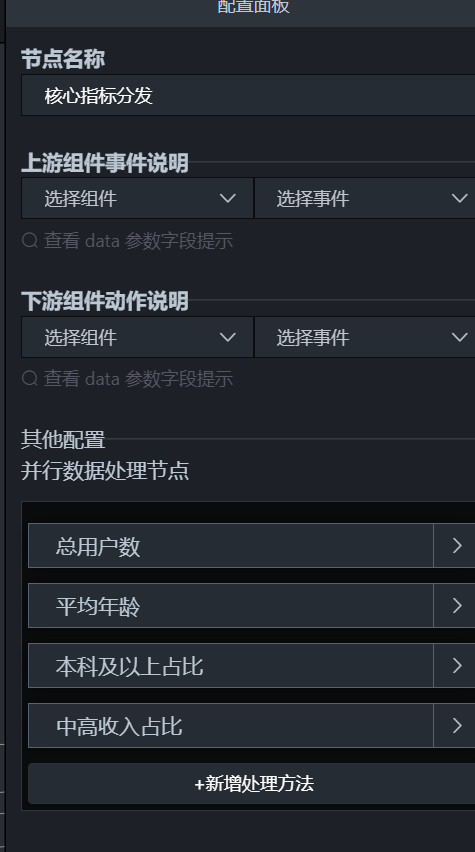
配置要点:
text
1. 指标卡只需要 value 字段。
2. 平均年龄使用 age * user_count / user_count 加权计算。
3. 占比指标使用条件聚合计算。
4. 百分比类指标在组件中设置 % 后缀。
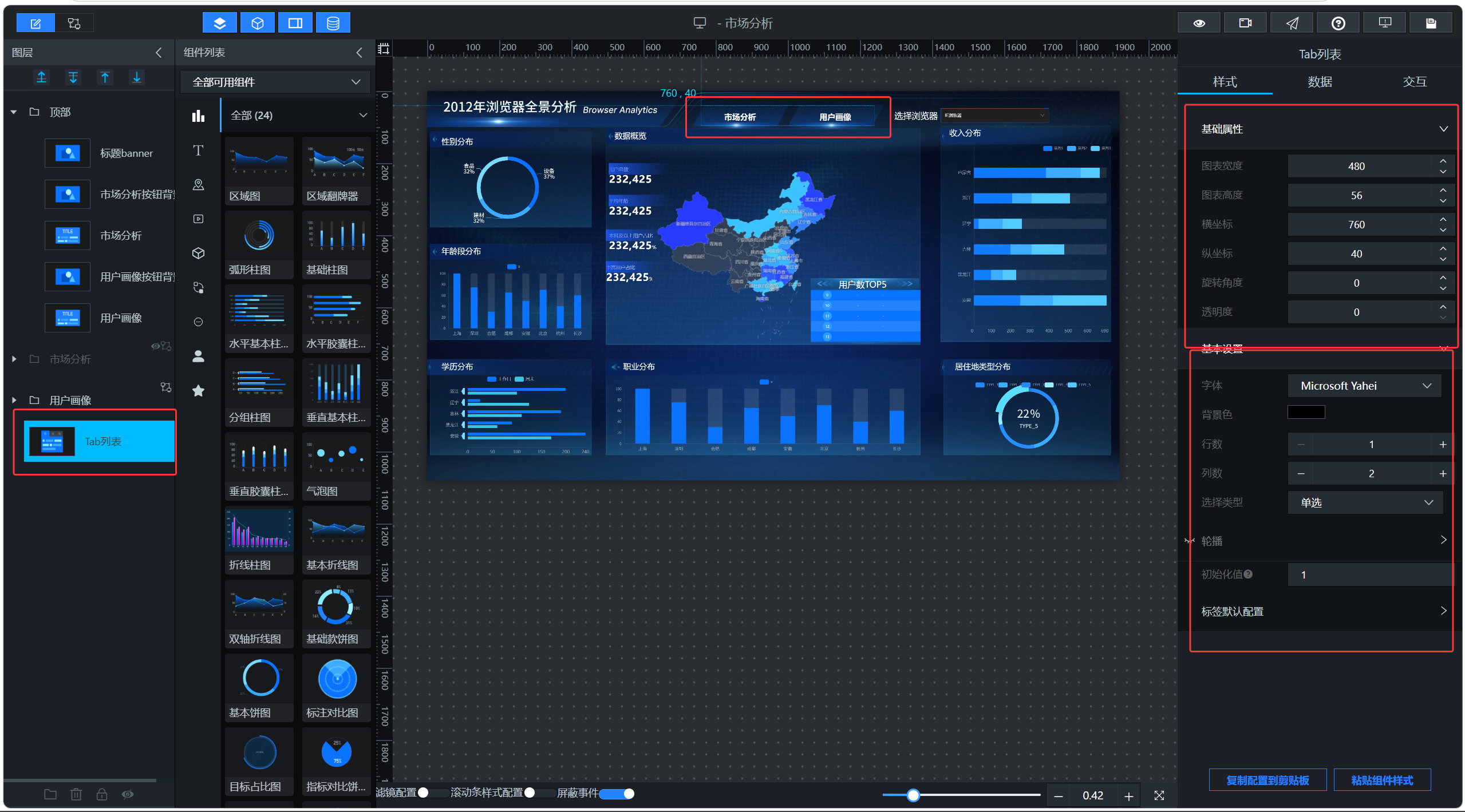
5. item 不存在时返回 0,避免组件显示异常。2.13 页面切换:用 Tab 列表控制市场分析组和用户画像组显示隐藏
市场分析和用户画像都在同一个大屏文件里,切换时不需要跳转页面,只需要控制两个图层组的显示和隐藏。
这里使用 Tab 列表组件作为切换入口。Tab 设置为 1 行 2 列:
| id | 含义 |
|---|---|
| 1 | 市场分析 |
| 2 | 用户画像 |
为了让它看起来像导航按钮,可以把 Tab 列表的背景色、选中背景色、悬浮背景色透明度调为 0,然后把它覆盖在导航按钮区域上。
导出到蓝图编辑器的对象包括:
text
Tab 列表组件
市场分析组
用户画像组在蓝图中添加分支判断节点:
javascript
return data.id == 1;满足条件时:
text
市场分析组 → 显示
用户画像组 → 隐藏不满足条件时:
text
市场分析组 → 隐藏
用户画像组 → 显示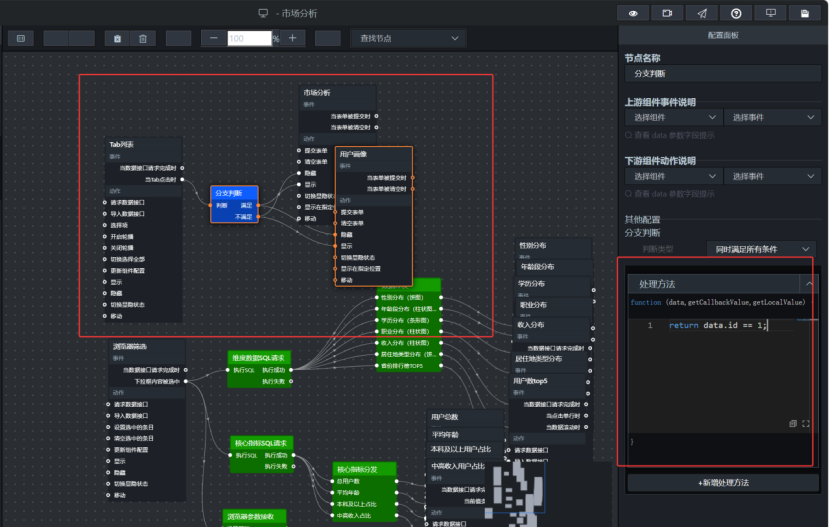
配置要点:
text
1. 市场分析和用户画像必须提前整理成两个图层组。
2. Tab 两个选项的 id 要区分清楚。
3. 分支判断根据 id 判断当前点击项。
4. 切换时要同时显示一个组、隐藏另一个组。
5. 如果只显示不隐藏,两个页面会重叠。2.14 地图点击联动:点击省份后刷新右侧核心指标卡
用户画像大屏中,地图不仅用于展示省份分布,还可以作为交互入口。
点击某个省份后,右侧四个核心指标卡要显示该省份的数据。
整体数据流如下:
text
点击地图省份
→ 地图输出省份名称
→ 处理省份名称
→ 根据当前浏览器和当前省份查询核心指标
→ 分发四个指标
→ 指标卡刷新先添加并行数据处理节点,命名为:
text
提取地区名称地图返回的名称通常是"江苏省""广西壮族自治区"这种全称,而数据库里可能存的是"江苏""广西"。所以需要做名称处理:
javascript
const specialMap = {
'北京市': '北京',
'天津市': '天津',
'上海市': '上海',
'重庆市': '重庆',
'广西壮族自治区': '广西',
'内蒙古自治区': '内蒙古',
'西藏自治区': '西藏',
'宁夏回族自治区': '宁夏',
'新疆维吾尔自治区': '新疆',
'香港特别行政区': '香港',
'澳门特别行政区': '澳门'
};
let provinceName = data.name;
if (specialMap[provinceName]) {
provinceName = specialMap[provinceName];
} else {
provinceName = provinceName.replace(/(省|自治区|市)$/, '');
}
window.globalProvinceName = provinceName;
return provinceName;接着添加 SQL 请求节点,命名为:
text
省份核心指标查询SQL 如下:
javascript
const selectedProvince = window.globalProvinceName;
const selectedBrowser = window.GLOBAL_SELECTED_BROWSER;
const sql = `
select 'total_users' as name, sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}' and province = '${selectedProvince}'
union all
select 'avg_age' as name,
round(sum(age * user_count) / sum(user_count), 0) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}' and province = '${selectedProvince}'
union all
select 'high_edu_ratio' as name,
round(sum(case when edu in ('本科', '硕士及以上') then user_count else 0 end) * 100.0 / sum(user_count), 2) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}' and province = '${selectedProvince}'
union all
select 'high_income_ratio' as name,
round(sum(case when income in ('5001~8000元', '8001~12000元','12000元以上') then user_count else 0 end) * 100.0 / sum(user_count), 2) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}' and province = '${selectedProvince}'
`;
return sql;最后通过"省份核心指标分发"节点,把四个指标拆给四个指标卡。
分支示例:
javascript
var item = data.find(item => item.name === 'total_users');
return [{ value: item ? item.value : 0 }];其他三个分支把 total_users 换成:
text
avg_age
high_edu_ratio
high_income_ratio蓝图连线如下:
text
区域热力层点击区域时 → 提取地区名称
提取地区名称 → 省份核心指标查询
省份核心指标查询执行成功 → 省份核心指标分发
省份核心指标分发四个分支 → 四个核心指标卡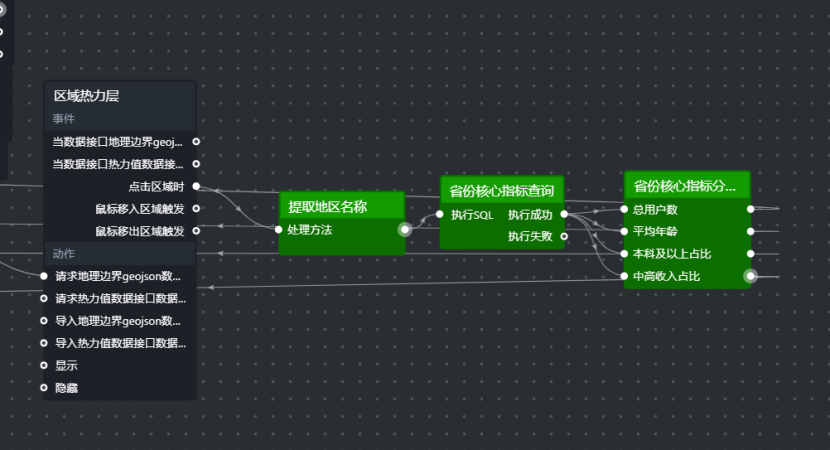
配置要点:
text
1. 地图返回省份全称,数据库中通常是简称,需要映射。
2. 查询省份指标时同时依赖当前浏览器和当前省份。
3. 当前浏览器来自 GLOBAL_SELECTED_BROWSER。
4. 当前省份来自 globalProvinceName。
5. 点击省份后指标为 0 时,优先检查省份名称是否匹配。2.15 地图热力层:根据省份用户数渲染颜色深浅
地图热力层的作用是让用户一眼看出哪些省份用户更多。
区域热力层需要的数据格式一般是:
javascript
{
name: '广东',
value: 120,
area_id: 440000
}其中:
text
name:省份名称
value:用户数
area_id:行政区划代码这里只传省份名称和用户数还不够,地图通常还需要 area_id 来准确匹配区域。所以需要先从地图 GeoJSON 中提取省份名称和 adcode,建立映射表。
可以添加并行数据处理节点,命名为:
text
提取 adcode 映射表然后查询当前浏览器下各省份用户数:
sql
select
province as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = 当前浏览器
group by province再把查询结果和 adcode 映射表合并,输出热力层需要的数据格式:
javascript
return data.map(item => {
const provinceName = item.name;
const area_id = window.globalProvinceAdcode[provinceName] || "000000";
return {
name: provinceName,
value: parseFloat(item.value) || 0,
area_id: Number(area_id)
};
});最后将结果连接到区域热力层的:
text
导入热力值数据接口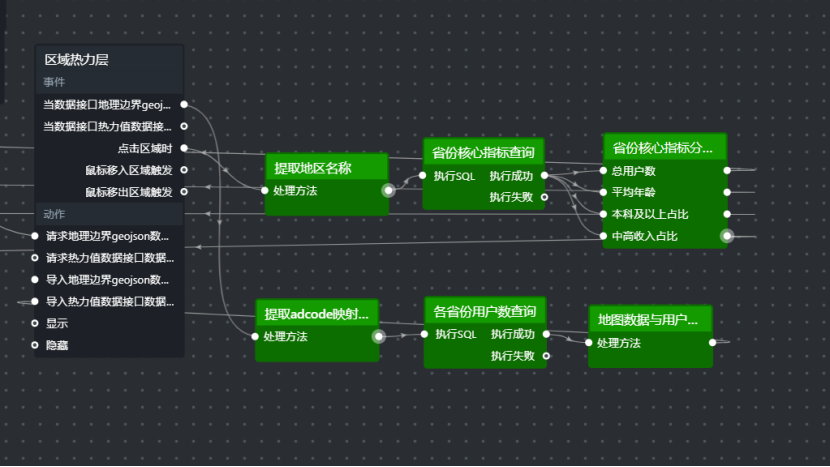
配置要点:
text
1. 热力层数据需要 name、value、area_id。
2. adcode 来自地图 GeoJSON 数据。
3. 用户数来自 user_profile_stats 表的 province 聚合结果。
4. 浏览器筛选变化后,地图热力层也要刷新。
5. 地图没有颜色变化时,重点检查 area_id 是否正确。2.16 保存、预览和发布:检查筛选、切换、点击联动是否正常
完成蓝图配置后,回到大屏页面点击保存和预览。
我主要检查这些内容:
text
1. 用户画像大屏静态布局是否完整;
2. 浏览器筛选器切换后,地图、图表、指标卡是否同步刷新;
3. 省份 TOP5 是否按用户数降序展示;
4. 市场分析和用户画像两个页面是否能正常切换;
5. 点击地图省份后,核心指标卡是否显示该省份数据;
6. 地图热力层颜色是否能反映省份用户数差异;
7. 发布后的链接是否能正常访问。确认效果正常后,点击发布,打开发布分享开关,复制分享链接,即可在线查看最终大屏。
配置要点:
text
1. 蓝图修改后要先保存,再预览。
2. 浏览器筛选建议多切换几个选项测试。
3. 地图点击建议测试普通省份、自治区和直辖市。
4. 发布前检查默认显示的是哪个图层组。第三部分:实验结果
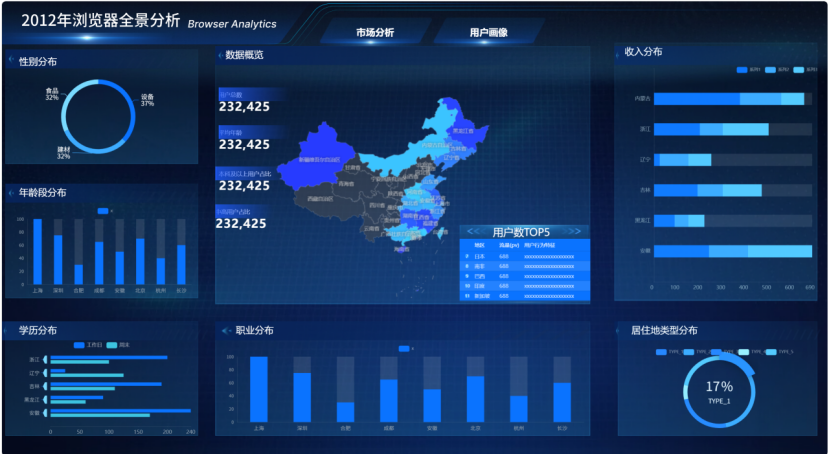
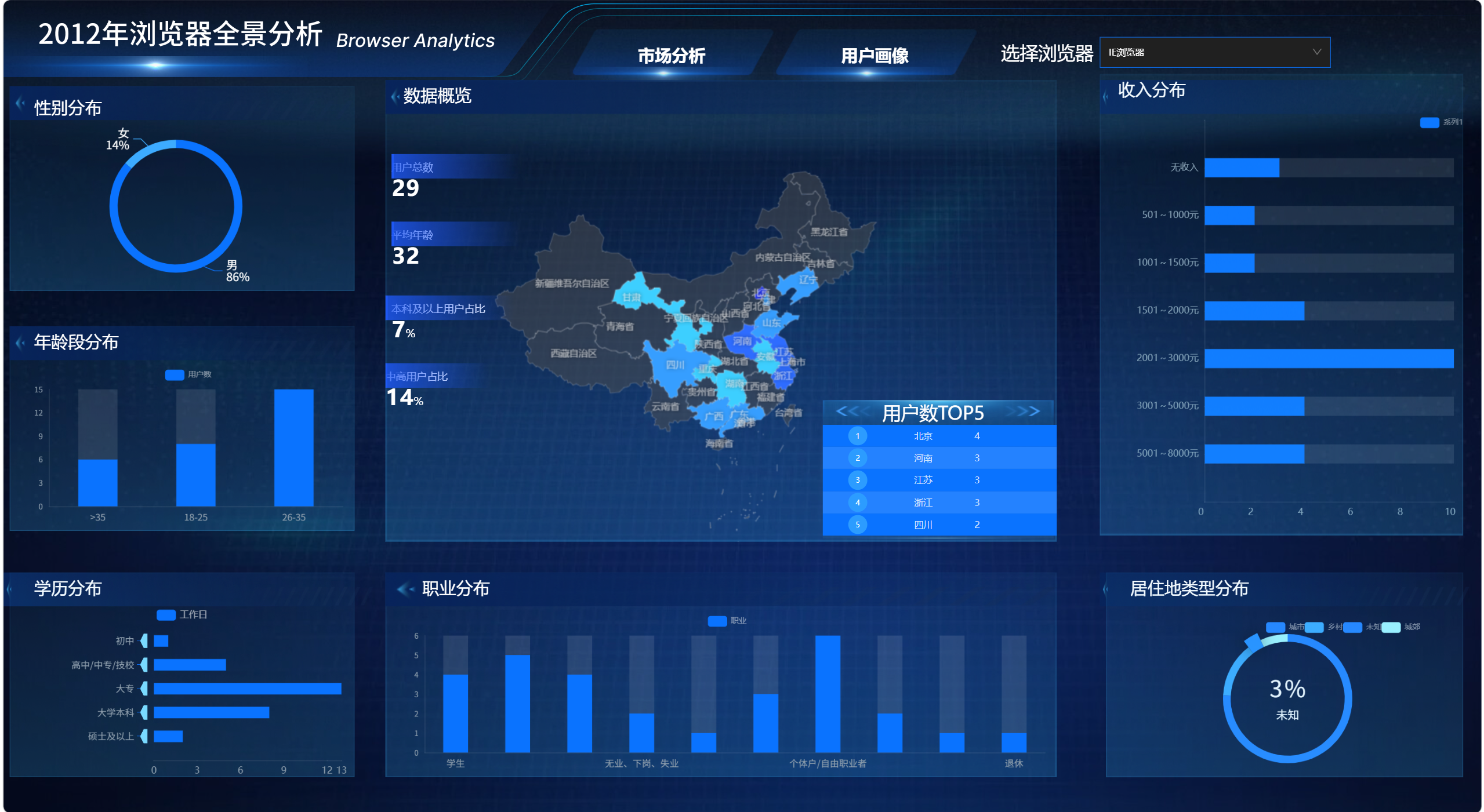
3.1 用户画像大屏页面完成
最终完成的用户画像大屏包含以下模块:
text
用户省份分布地图
总用户数指标卡
平均年龄指标卡
本科及以上占比指标卡
中高收入占比指标卡
省份用户数 TOP5 排行榜
性别分布饼图
年龄段分布柱状图
学历分布条形图
职业分布柱状图
收入分布柱状图
居住地类型分布饼图
浏览器筛选器
页面结构上,地图和核心指标负责展示整体情况,画像图表负责展示细分结构,排行榜补充省份排名。
3.2 用户画像数据成功接入图表组件
通过蓝图编辑器配置后,user_profile_stats 表中的数据已经可以正常进入各个组件。
| 组件 | 接收字段 | 验证结果 |
|---|---|---|
| 性别分布饼图 | name、value | 能显示性别占比 |
| 年龄段柱状图 | x、y、s | 能显示年龄段用户数 |
| 学历分布条形图 | x、y、s | 能显示学历分布 |
| 职业分布柱状图 | x、y、s | 能显示职业分布 |
| 收入分布柱状图 | x、y、s | 能显示收入段分布 |
| 居住地类型饼图 | name、value | 能显示城市 / 城郊 / 乡村占比 |
| 省份 TOP5 | province、user_count | 能显示用户数前五省份 |
| 核心指标卡 | value | 能显示四个核心指标 |
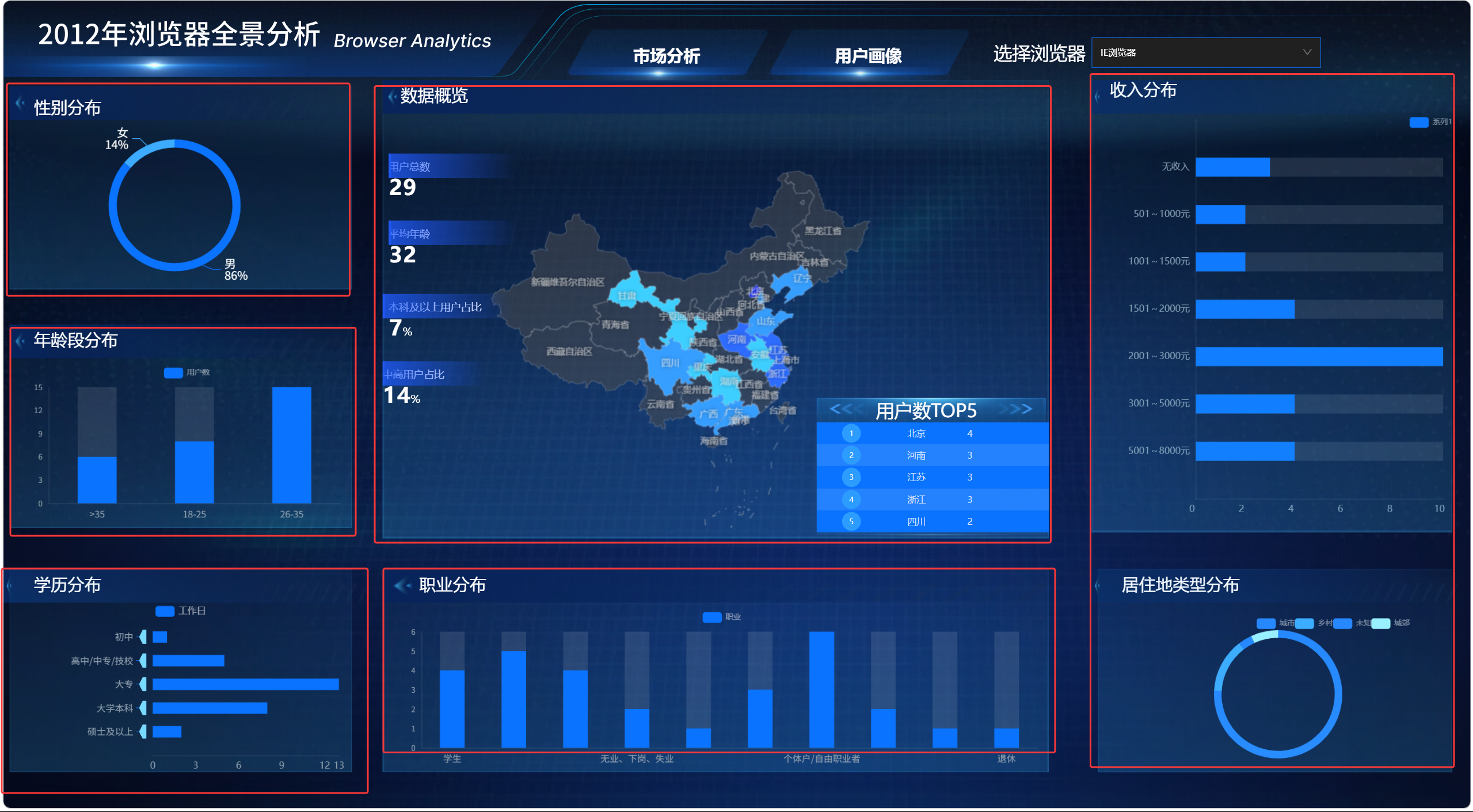
这说明 SQL 请求、并行数据处理和组件导入数据接口已经连通。
3.3 浏览器筛选器联动正常
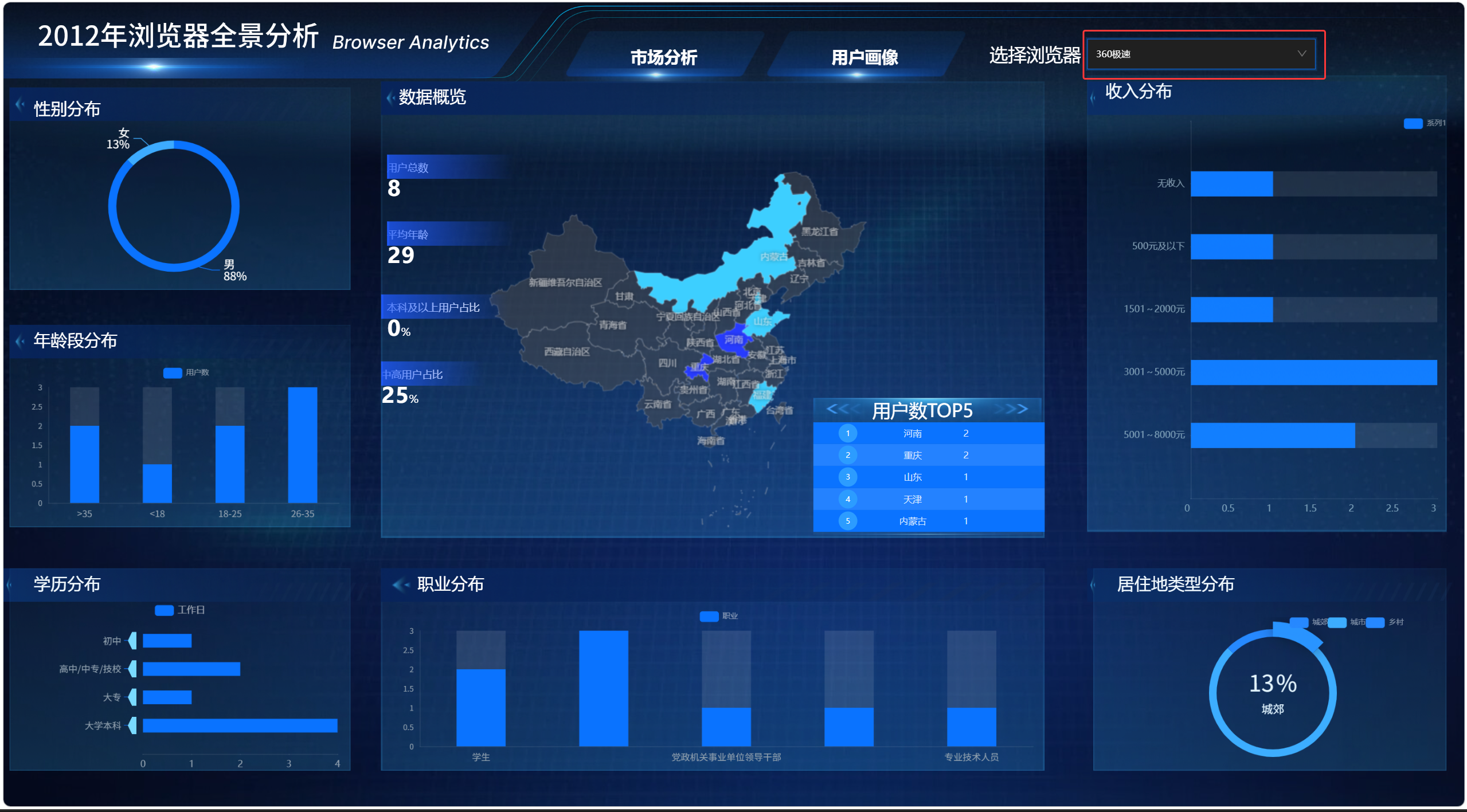
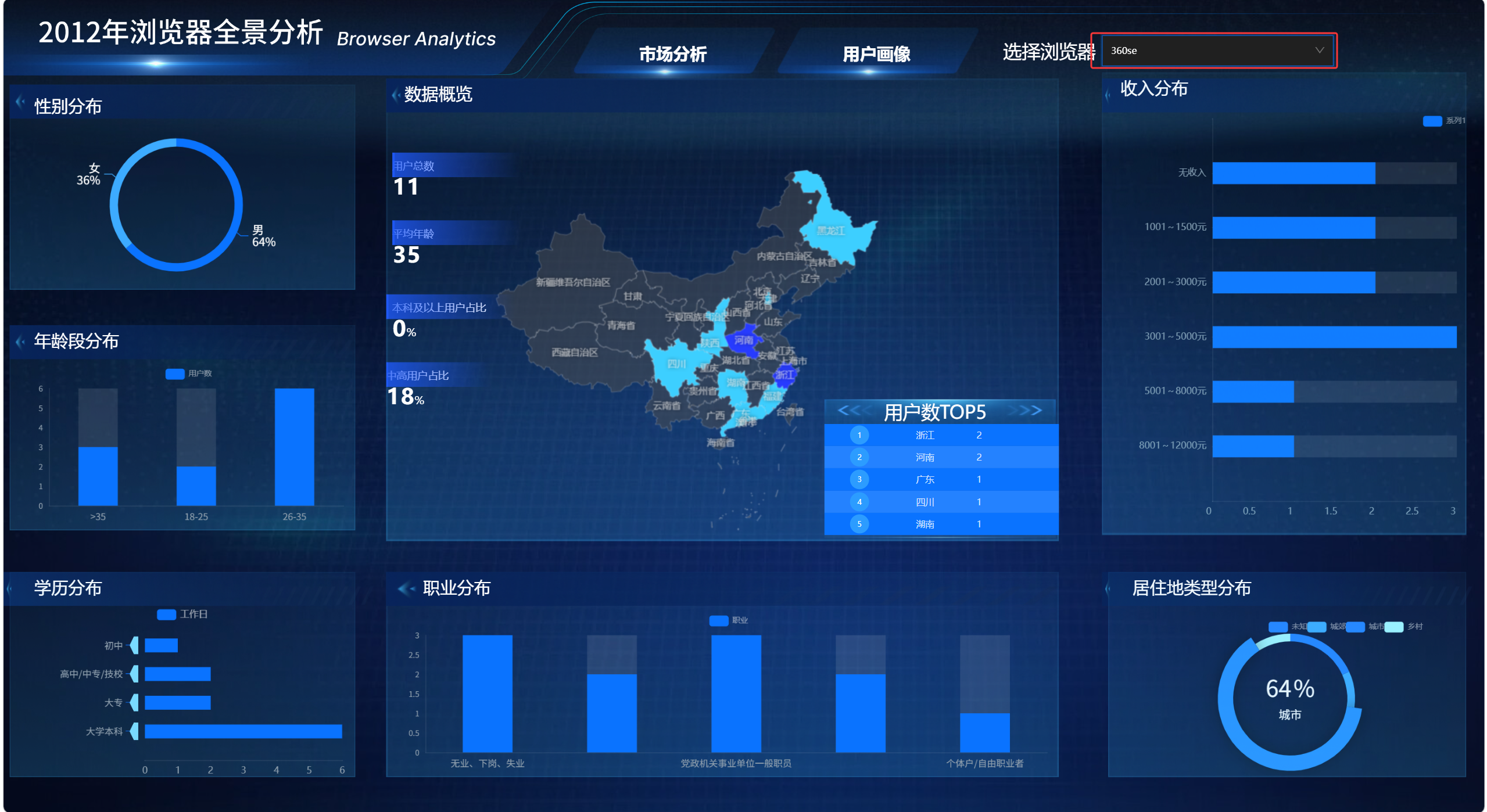
切换浏览器筛选器后,大屏中的地图、饼图、柱状图、排行榜和指标卡都可以同步刷新。
比如选择 Google 时,页面展示 Google 浏览器用户画像;选择 QQ 浏览器时,页面切换为 QQ 浏览器用户画像。
这说明浏览器筛选器、全局变量 GLOBAL_SELECTED_BROWSER、维度 SQL 请求和核心指标 SQL 请求之间的数据链路是正常的。
3.4 市场分析和用户画像切换正常
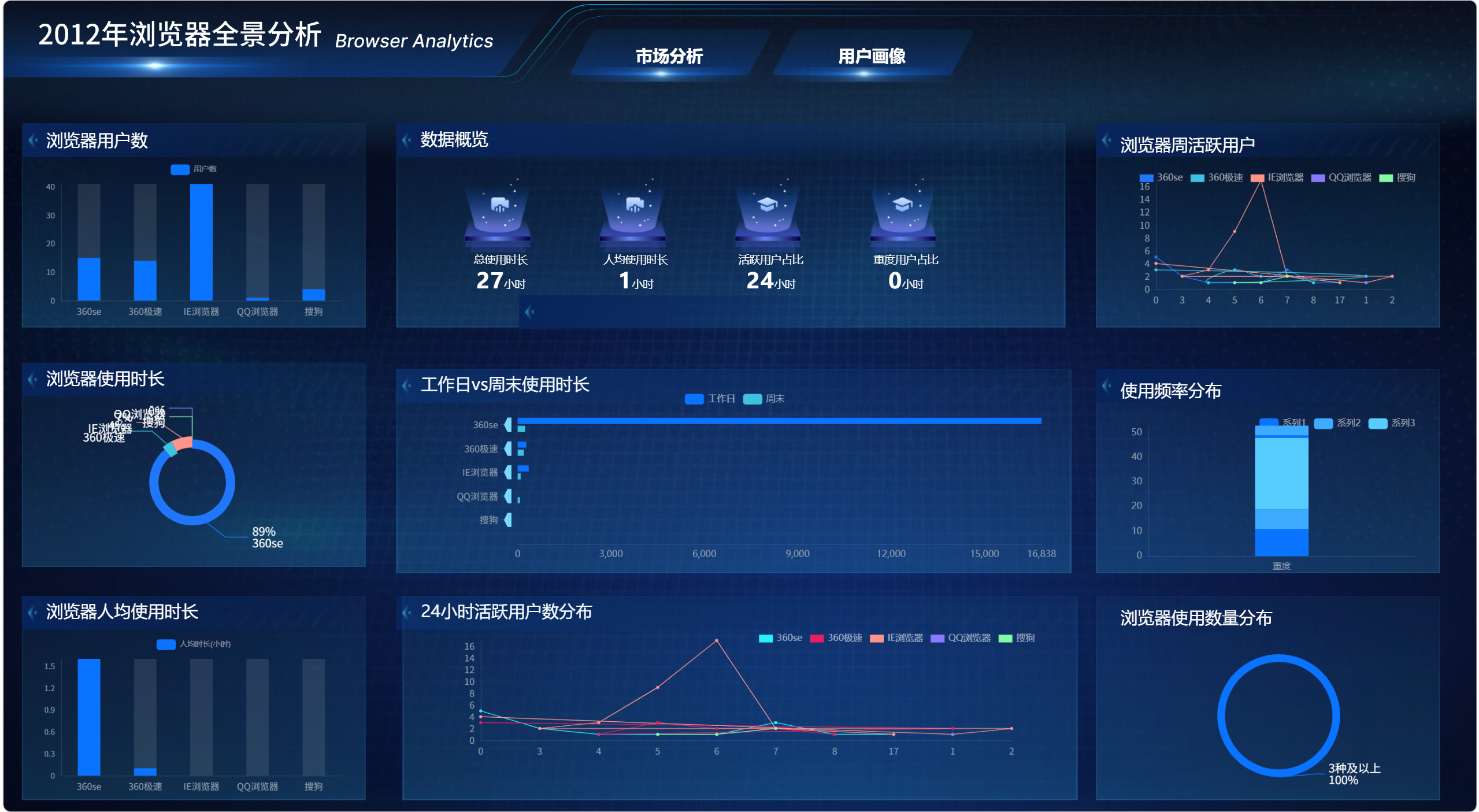
通过 Tab 列表和图层可见性控制,市场分析和用户画像两个页面可以在同一个大屏文件中切换。
点击"市场分析"时:
text
市场分析组显示
用户画像组隐藏点击"用户画像"时:
text
市场分析组隐藏
用户画像组显示这样既保留了两个分析主题,又避免创建多个独立页面。
3.5 地图点击省份后核心指标可以刷新
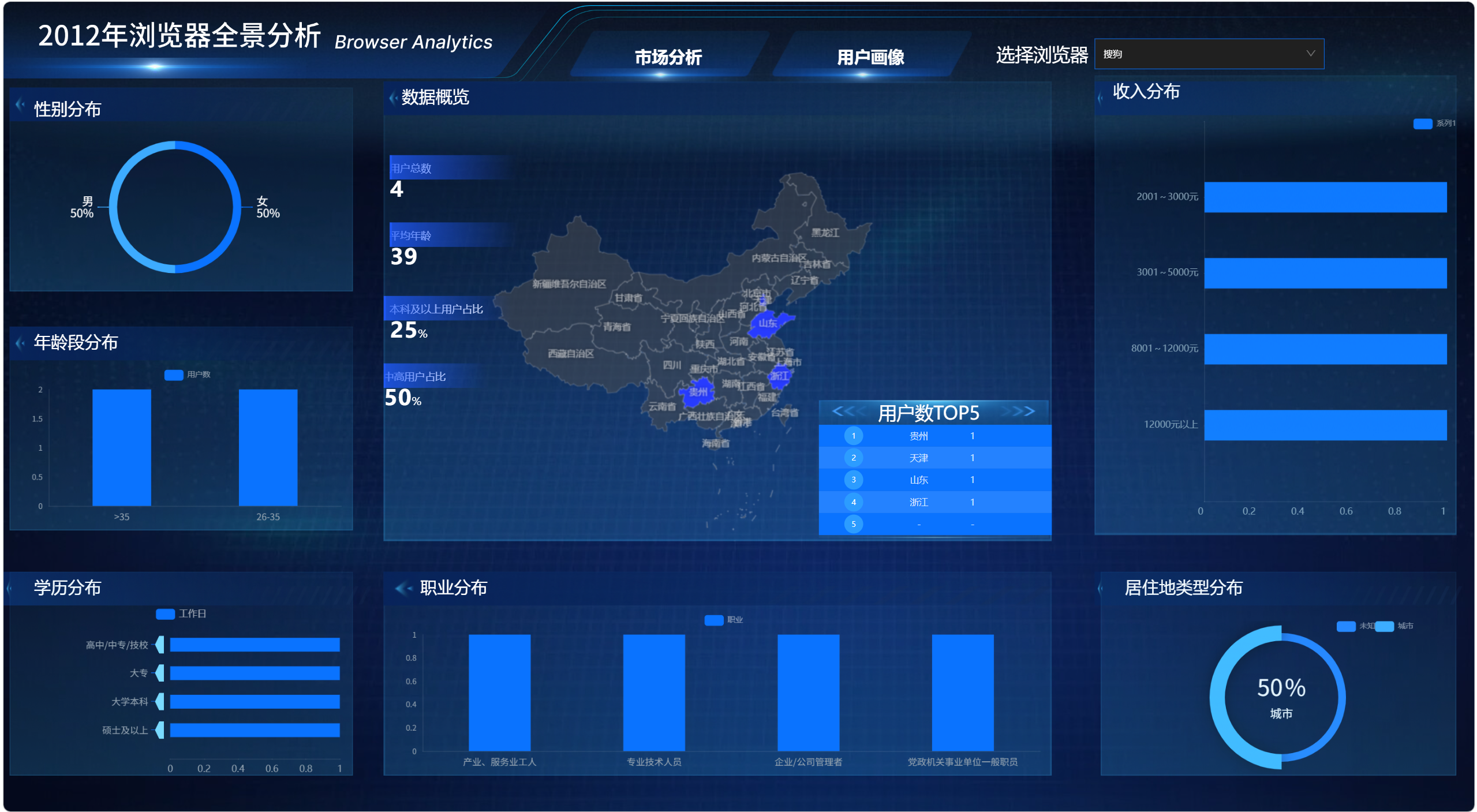
点击地图上的某个省份后,右侧核心指标卡可以刷新为该省份的数据。
例如点击"广东省"后,系统会先把地图返回的"广东省"转换为数据库中的"广东",再结合当前浏览器筛选值查询该省份的:
text
总用户数
平均年龄
本科及以上占比
中高收入占比这说明地图点击事件、省份名称处理、动态 SQL 查询和指标卡分发逻辑已经打通。
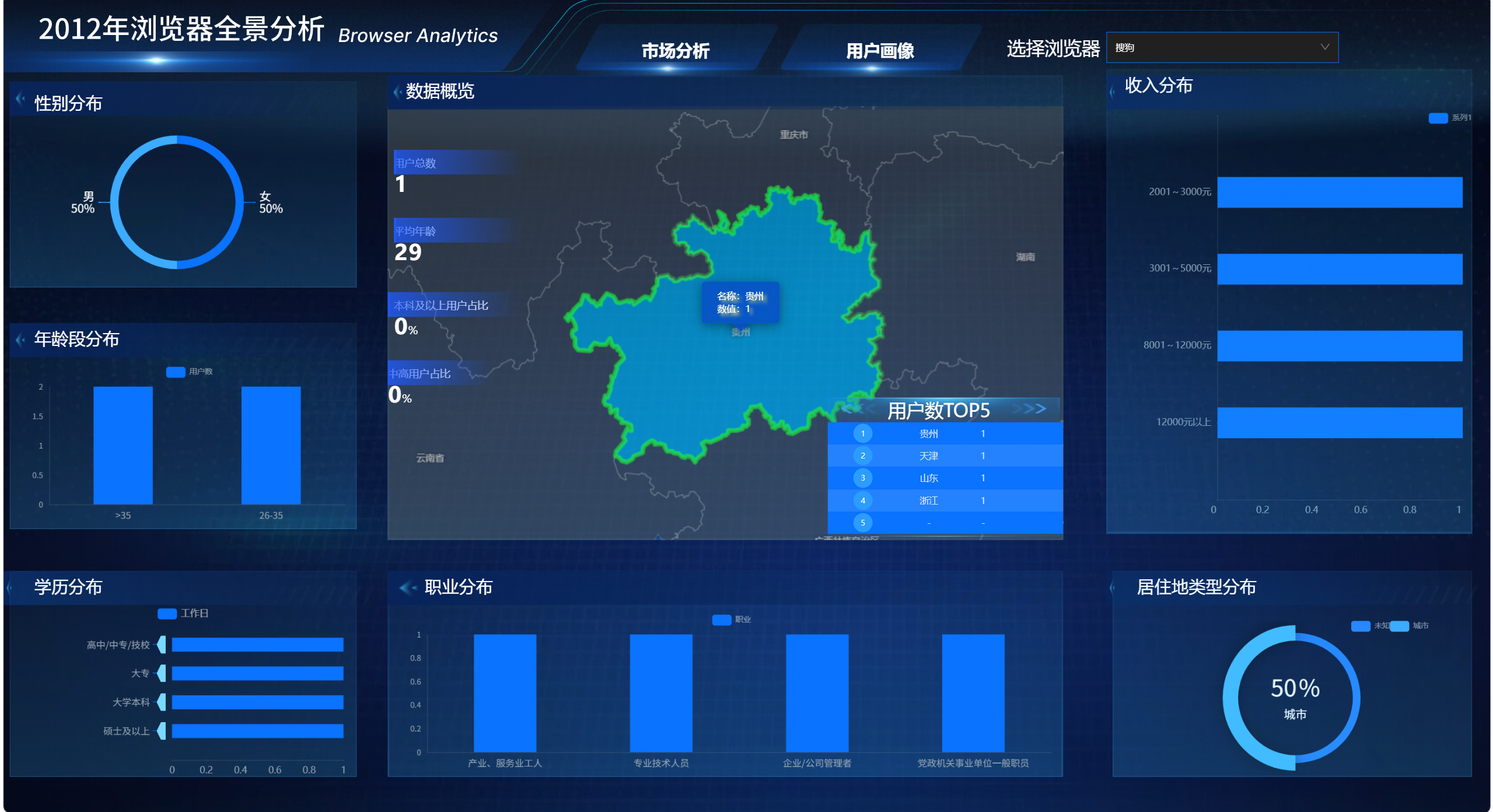
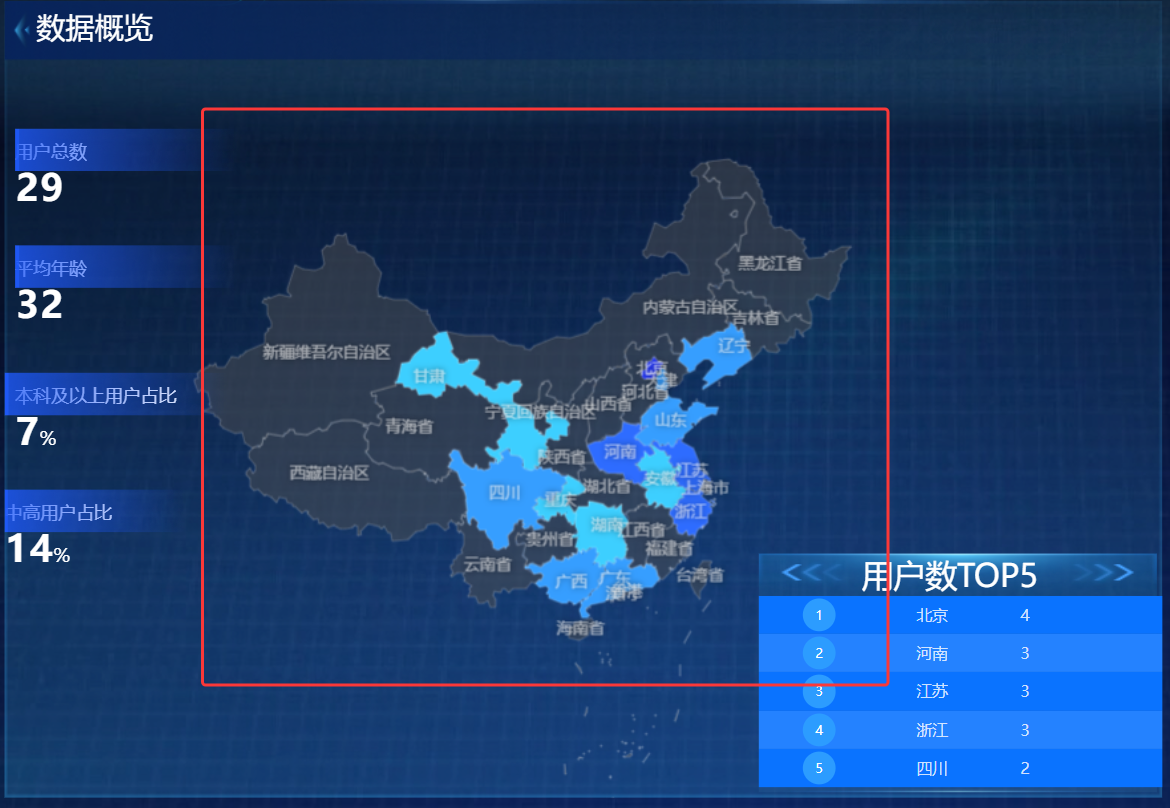
3.6 地图热力层可以按用户数显示颜色深浅
地图区域热力层接入省份用户数后,不同省份可以根据用户数量显示不同深浅的颜色。
用户数较多的省份颜色更明显,用户数较少的省份颜色较浅。
这样用户可以直接从地图上观察浏览器用户的地域分布情况。
第四部分:问题与解决
4.1 SQL 请求成功,但图表不显示数据
问题现象:
蓝图中的 SQL 请求节点执行成功,但大屏中的某些图表为空。
问题原因:
SQL 返回字段和组件要求字段不一致。
比如饼图需要 name/value,柱状图需要 x/y/s,指标卡需要 value。如果直接把数据库字段返回给组件,组件可能无法识别。
解决方法:
在并行数据处理节点中转换字段格式。
饼图示例:
javascript
return data.map(item => ({
name: item.name,
value: item.value
}));柱状图示例:
javascript
return data.map(item => ({
x: item.name,
y: item.value,
s: '用户数'
}));指标卡示例:
javascript
return [{ value: item ? item.value : 0 }];4.2 浏览器筛选后部分组件没有刷新
问题现象:
切换浏览器筛选器后,有些图表更新了,有些图表仍然显示旧数据。
问题原因:
部分组件没有连接到正确的数据分发分支,或者浏览器筛选器只触发了其中一个 SQL 请求节点。
解决方法:
检查蓝图连线,确保浏览器筛选器变化后,维度数据 SQL 和核心指标 SQL 都会重新执行。
正确链路应为:
text
浏览器筛选器
→ 浏览器参数接收
→ 维度数据 SQL 请求 / 核心指标 SQL 请求
→ 数据分发
→ 各图表导入数据接口4.3 平均年龄无法计算或结果不准确
问题现象:
平均年龄指标显示为空,或者计算结果明显不合理。
问题原因:
user_profile_stats 表中如果只有 age_group,没有具体 age 字段,就无法准确计算平均年龄。直接用年龄段估算会有误差。
解决方法:
在 user_profile_stats 表中增加 age 字段,并在计算平均年龄时使用加权方式:
sql
round(sum(age * user_count) / sum(user_count), 1)这样计算出来的是按用户数加权后的平均年龄。
4.4 点击地图省份后指标卡显示为 0
问题现象:
点击地图某个省份后,SQL 正常执行,但核心指标卡显示为 0。
问题原因:
地图返回的省份名称和数据库中的省份名称不一致。
例如地图返回"江苏省",数据库中保存的是"江苏";地图返回"广西壮族自治区",数据库中保存的是"广西"。
解决方法:
在地图点击后增加省份名称处理节点,将全称转换为数据库中的简称。
示例代码:
javascript
const specialMap = {
'北京市': '北京',
'天津市': '天津',
'上海市': '上海',
'重庆市': '重庆',
'广西壮族自治区': '广西',
'内蒙古自治区': '内蒙古',
'西藏自治区': '西藏',
'宁夏回族自治区': '宁夏',
'新疆维吾尔自治区': '新疆'
};
let provinceName = data.name;
if (specialMap[provinceName]) {
provinceName = specialMap[provinceName];
} else {
provinceName = provinceName.replace(/(省|自治区|市)$/, '');
}处理后再把省份名称传给 SQL 查询节点。
4.5 地图热力层没有颜色变化
问题现象:
省份用户数已经查出来,但地图没有按用户数显示颜色深浅。
问题原因:
区域热力层需要的不只是省份名称和用户数,还需要 area_id。如果缺少行政区划代码,地图可能无法把数据匹配到区域。
解决方法:
从地图 GeoJSON 中提取省份名称和 adcode,建立映射关系,再将用户数数据转换为:
javascript
{
name: provinceName,
value: userCount,
area_id: adcode
}然后连接到区域热力层的"导入热力值数据接口"。
4.6 市场分析和用户画像两个页面重叠
问题现象:
点击 Tab 切换后,市场分析和用户画像的组件同时显示,页面出现重叠。
问题原因:
只设置了目标图层组显示,没有同步隐藏另一个图层组;或者组件没有提前整理到对应图层组中。
解决方法:
先整理图层组:
text
市场分析组
用户画像组然后在蓝图中同时配置显示和隐藏动作:
text
点击市场分析:
市场分析组显示
用户画像组隐藏
点击用户画像:
市场分析组隐藏
用户画像组显示这样可以保证同一时间只显示一个页面内容。
第五部分:实验总结
这次实验完整走了一遍浏览器用户画像大屏从页面布局到数据接入,再到交互联动的配置过程。
在页面布局阶段,我最大的体会是:大屏不是组件堆叠,而是要先确定分析问题。用户画像大屏主要回答"用户是谁、来自哪里、结构如何、不同浏览器之间是否有差异",所以地图、指标卡、饼图、柱状图和排行榜各自承担不同的信息表达任务。
在数据接入阶段,重点是字段格式。SQL 查询出来的数据不能直接随意丢给组件,而是要转换成组件能识别的格式。饼图需要 name/value,柱状图需要 x/y/s,指标卡需要 value,地图热力层需要 name/value/area_id。很多图表不显示的问题,本质上不是 SQL 没查到数据,而是字段格式没有对上。
在交互配置阶段,蓝图编辑器的作用比较明显。浏览器筛选器通过全局变量控制多个 SQL 请求;Tab 列表通过图层可见性控制市场分析和用户画像切换;地图点击事件通过省份名称处理和动态 SQL 查询,实现省份级指标联动。这样一来,大屏就不只是静态展示页面,而是可以进行筛选、切换和下钻分析的交互式数据看板。
整个流程可以总结为:

这套流程对于类似的商业数据分析大屏也可以复用:先把业务问题拆清楚,再把页面结构搭好,然后用蓝图把数据和交互串起来,最后通过预览不断检查字段、连线和组件状态。