本节重点
- 进程创建:fork
- 进程终止,理解环境变量 $?
- 进程等待
- 进程程序替换
- 微型 Shell,深入理解 Shell 运行原理
1. 进程创建
1-1 fork函数初识
在Linux系统中,fork函数是极为核心的系统调用,主要作用是从一个已经存在的进程中创建一个全新的进程。其中,原有的进程称为父进程,新创建的进程称为子进程。
函数所需头文件与函数原型如下:
cpp
#include <unistd.h>
pid_t fork(void);返回值规则:子进程中返回 0,父进程中返回子进程的 PID,函数调用出错时返回 -1。
学习 fork 函数,必须弄懂三个核心经典问题,这是理解多进程原理的关键,下面给出标准详细解答:
问题1:为什么要给子进程返回 0,父进程返回子进程 pid?
系统设计的核心目的是区分进程身份、方便进程管理。在Linux系统中,一个父进程可以创建若干个子进程,而每一个子进程有且仅有一个父进程。对于父进程而言,它需要通过唯一的子进程PID来精准区分、管理、回收不同的子进程,因此必须返回大于0的子进程PID;对于子进程而言,它不需要识别父进程,自身只需要一个固定标识证明自己是子进程即可,所以统一返回0。该设计可以极简地实现父子进程身份区分。
问题2:为什么一个 fork 函数会有两个返回值?
本质原因:fork函数调用后,内核会创建一个新的独立子进程,系统中存在两个进程执行同一段代码 。fork函数的执行分为两个阶段:第一阶段,父进程执行fork的内核逻辑,创建子进程、拷贝资源;第二阶段,创建完成后,父子两个独立进程各自完成一次函数返回。并非一个函数逻辑返回两次,而是两个进程各自返回一次,因此最终呈现出两个不同的返回值。
问题3:为什么同一个返回值变量,既可以等于 0,又可以大于 0?
该现象不存在逻辑冲突,核心是变量属于两个不同进程,各自独立赋值。fork之前,只有父进程存在,变量未赋值;fork创建子进程后,父子进程拥有各自独立的pid变量副本。父进程的变量赋值为子进程PID(大于0),子进程的变量赋值为0,两个变量互不干扰,因此看似同一个变量有两种数值,实则是两个进程的独立变量。
进程调用 fork 后,程序控制权会转移到内核中的 fork 执行代码,内核会自动完成一系列进程创建操作,具体步骤如下:
-
为子进程分配全新的内存块与内核数据结构
-
将父进程的部分数据结构内容拷贝至子进程
-
将新创建的子进程添加到系统进程列表中
-
fork 执行返回,交由系统调度器进行进程调度
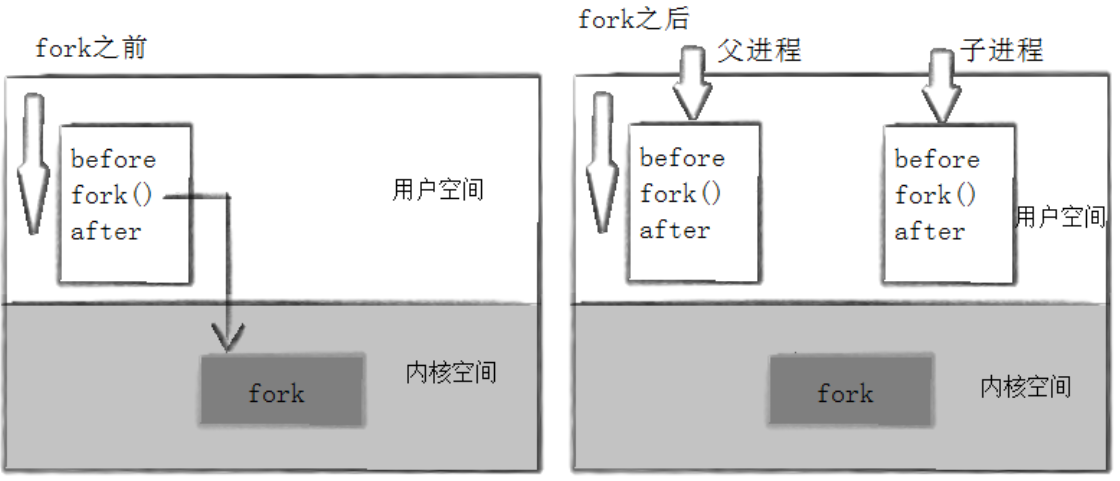
当进程成功调用 fork 之后,系统中会存在两个二进制代码完全相同的进程,且两个进程均执行到代码的同一位置。自此,父子进程拥有独立的执行流,可以各自执行不同的后续逻辑。
测试代码示例:
cpp
int main( void )
{
pid_t pid;
printf("Before: pid is %d\n", getpid());
if ( (pid=fork()) == -1 )perror("fork()"),exit(1);
printf("After:pid is %d, fork return %d\n", getpid(), pid);
sleep(1);
return 0;
}程序运行结果:
bash
[root@localhost linux]# ./a.out
Before: pid is 43676
After:pid is 43676, fork return 43677
After:pid is 43677, fork return 0从运行结果可以看出,程序一共输出三行内容:一行 Before 输出,两行 After 输出。
进程 43676 为父进程,优先执行并打印了 Before 信息,随后继续执行打印 After 信息;进程 43677 为新建的子进程,仅打印了 After 信息,没有打印 Before 信息。
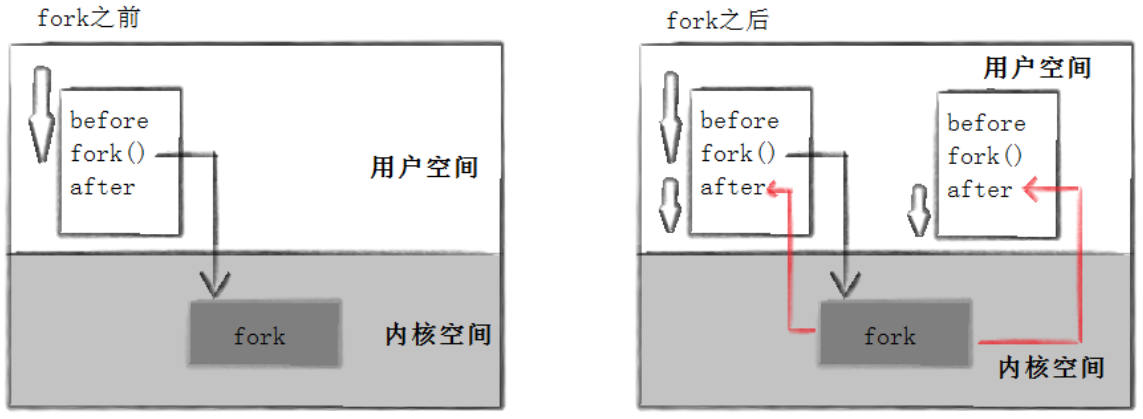
由此可以得出核心结论:fork 执行之前,只有父进程单独执行代码;fork 执行之后,父子两个执行流并行独立执行代码。fork 创建子进程完成后,父子进程的执行先后顺序完全由系统调度器决定,人为无法干预。
1-2 fork函数返回值
结合上述原理与测试案例,对 fork 函数返回值进行总结:
-
子进程:固定返回 0
-
父进程:固定返回新建子进程的 PID(大于0)
1-3 写时拷贝
fork 创建子进程后,在父子进程均不进行数据写入操作的前提下,父子进程共享同一份代码和数据资源。
当父子进程中任意一方试图对数据进行写入、修改操作时,系统会通过写时拷贝技术,为执行修改的进程单独拷贝一份数据副本,实现数据分离。
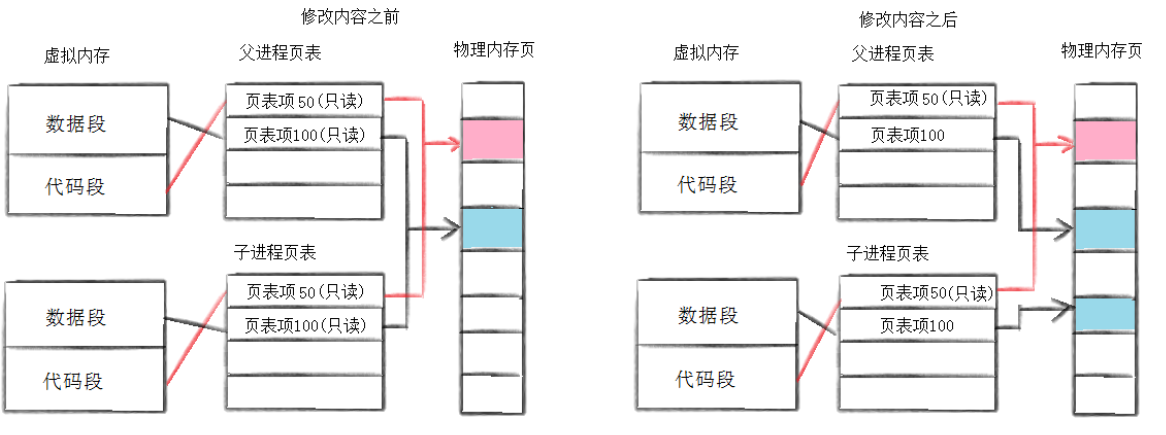
写时拷贝技术是保障父子进程彻底分离、实现进程独立性的核心技术,从底层保证了多进程运行互不干扰。fork刚创建子进程时,并不会立刻拷贝父进程的数据和代码,而是采用「只读共享」的模式,父子进程共用同一块物理内存空间,极大节省内存资源。只有当任意一方尝试修改数据时,系统才会触发拷贝,为修改进程单独开辟新内存、拷贝数据,实现数据分离。
同时,写时拷贝属于延时申请、延时拷贝技术,规避了大多数场景下无意义的内存拷贝操作。如果子进程仅读取数据、不修改数据,全程无需拷贝内存,大幅提升整机的内存使用率和进程创建效率,是 Linux 系统高效管理进程内存的核心优化机制。
1-4 fork常规用法
在实际开发场景中,fork 函数主要有两大核心用法:
-
父进程复制自身,让父子进程分别执行不同的代码段,实现多任务并发。例如服务端程序中,父进程持续等待客户端连接请求,每接入一个请求就创建一个子进程,由子进程单独处理客户端业务。
-
实现程序替换,完成不同程序的执行。进程通过 fork 创建子进程后,子进程从 fork 调用处返回,随后调用 exec 系列函数,加载并执行全新的程序。
1-5 fork调用失败的原因
fork 创建进程并非百分百成功,常见的失败原因有两种:
-
系统中运行的进程数量过多,达到系统最大进程上限,无法新建进程。
-
普通用户创建的进程数量超出了系统配置的用户进程数限制,触发资源限制导致调用失败。
2. 进程终止
进程终止的本质是释放系统资源,即释放进程申请的相关内核数据结构,以及对应的程序数据和代码资源,彻底结束进程生命周期。
2-1 进程退出场景
Linux中进程退出分为三类核心场景:
-
代码运行完毕,执行结果正确
-
代码运行完毕,执行结果不正确
-
代码异常终止
2-2 进程常见退出方法
进程退出分为正常终止 和异常退出 两类,正常终止可通过 Shell 指令 echo $? 查看进程退出码。
正常终止方式:
-
从 main 函数 return 返回
-
调用 exit() 函数终止进程
-
调用 _exit() 函数终止进程
异常退出方式:
- 终端按下 ctrl + c,通过系统信号强制终止进程
2-2-1 退出码
退出码也叫退出状态,用于标识上一次执行命令或程序的运行状态,可直观判断程序是执行成功还是异常结束。核心规则:程序退出码为 0 代表执行成功、无任何错误;退出码为非 0 数值,均判定为程序执行失败。
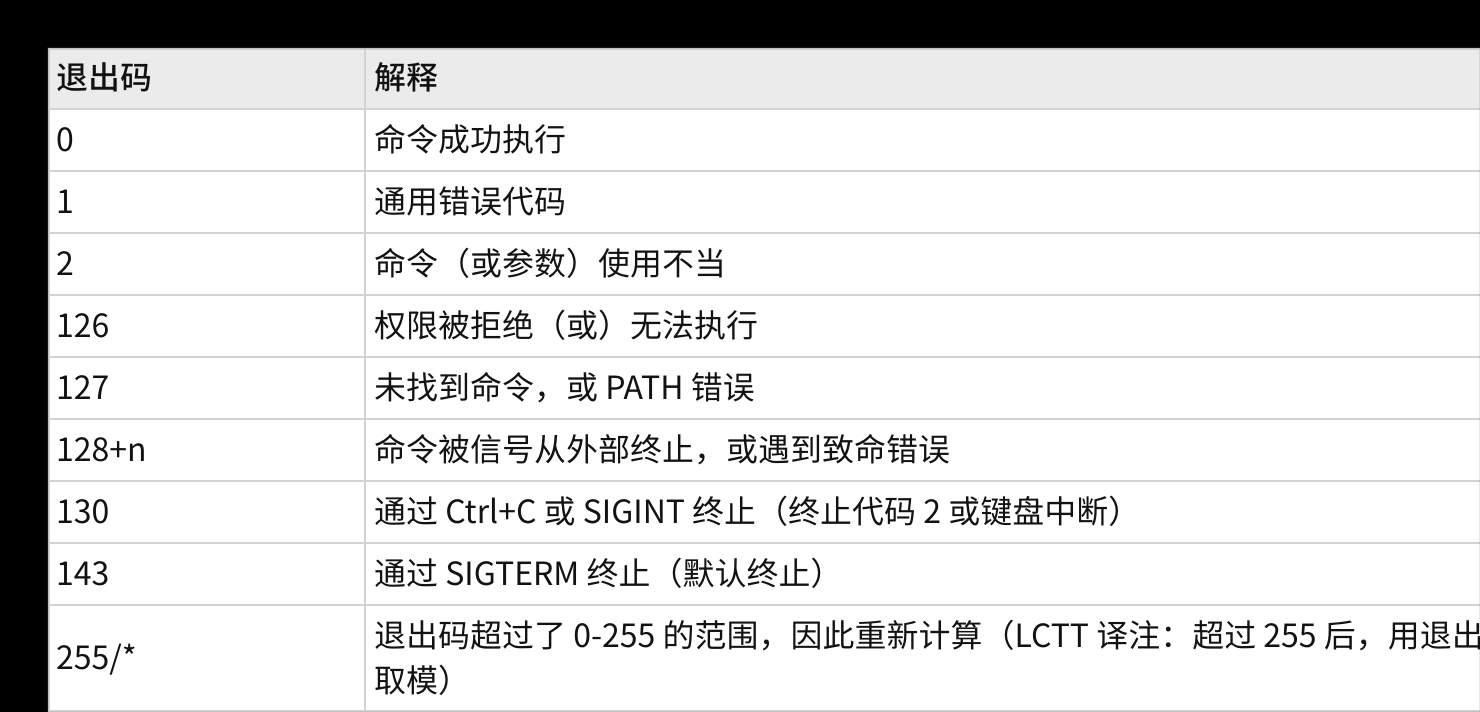
Linux Shell 常用标准退出码说明:
-
退出码 0:命令执行无误,是程序正常结束的理想状态。
-
退出码 1 :代表不被允许的非法操作。例如无 sudo 权限执行 yum 命令、程序中执行除以 0 的非法运算(
let a=1/0)等场景,都会返回错误码 1。 -
退出码 130、143 :属于典型的信号终止退出码,遵循
128+n规则,n 为系统终止信号编号。其中 130 对应 SIGINT 信号(ctrl+c 终止程序),143 对应 SIGTERM 信号(正常终止信号)。
开发中可借助 strerror 函数,根据退出码获取对应的文字描述,快速定位错误原因。
2-3-2 _exit函数
_exit 是内核级系统调用,用于直接终止进程,函数定义如下:
cpp
#include <unistd.h>
void _exit(int status);参数说明:status 用于定义进程的终止状态,父进程可通过 wait 系列函数获取该状态值。
核心特性:status 为整型变量,但仅有低8位数据可被父进程识别使用 ,高24位会被系统自动丢弃。因此当传入负数(如-1,二进制全1),低8位全部为1,对应十进制255,所以调用 _exit(-1) 时,终端执行 echo $? 会得到返回值 255。同时 _exit 是纯内核调用,不会刷新缓冲区、不执行任何用户层清理函数,直接强制销毁进程。
2-3-3 exit函数
exit 是标准库函数,是对 _exit 系统调用的上层封装,函数定义如下:
cpp
#include <unistd.h>
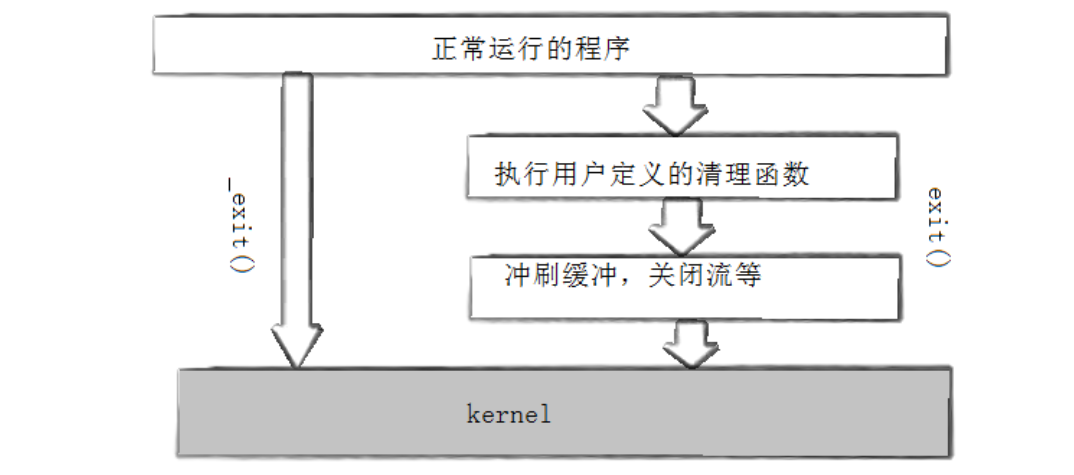
void exit(int status);exit 函数是用户层标准库函数,本质是对 _exit 系统调用的封装,安全性更高、功能更完整。exit 函数最终会调用 _exit 完成进程终止,但在调用 _exit 之前,会额外执行三步收尾工作,这也是 exit 与 _exit 的核心区别:
-
执行用户通过 atexit 或 on_exit 定义的自定义清理函数;
-
关闭进程所有已打开的文件流,将缓冲区中的缓存数据强制写入文件;
-
调用 _exit() 系统调用,正式终止进程。
-
代码对比实例(缓冲区刷新差异)
示例1:exit 函数(自动刷新缓冲区)
cpp
int main()
{
printf("hello");
exit(0);
}运行结果:
bash
[root@localhost linux]# ./a.out
hello[root@localhost linux]#示例2:_exit 函数(不刷新缓冲区)
cpp
int main()
{
printf("hello");
_exit(0);
}运行结果:
bash
[root@localhost linux]# ./a.out
[root@localhost linux]#2-3-4 return退出
return 是程序中最常见、最简洁的进程退出方式。在 main 函数中,执行 return n 完全等价于执行 exit(n),原因是程序运行时的启动机制,会自动捕获main函数的返回值,并将其作为exit的参数完成进程退出。需要重点区分:只有main函数的return可以终止进程,普通函数中的return仅表示函数调用结束、返回上层逻辑,不会终止整个进程。
3. 进程等待
3-1 进程等待必要性
进程等待是父进程回收子进程资源、规避系统问题的核心机制,必要性主要分为四点:
-
解决僵尸进程与内存泄漏问题:子进程退出后,代码和数据资源会被系统释放,但PCB进程控制块会短暂保留,用于存储退出状态信息。若父进程不做任何处理、不读取退出状态、不回收资源,子进程PCB无法被释放,进程进入僵尸状态,长期积累会造成系统内存泄漏,占用系统进程资源。
-
僵尸进程无法被强制杀死:进程进入僵尸状态,本质是进程已经彻底终止,仅残留PCB结构体 ,不属于活跃进程。因此即便使用
kill -9强制杀死命令,也无法对其生效,唯一消除僵尸进程的方式就是父进程调用wait系列函数回收子进程资源。 -
获取子进程执行结果:父进程创建子进程执行任务后,需要通过进程等待,判断子进程是否正常退出、任务执行结果正确与否。
-
回收系统资源:父进程通过进程等待的方式,主动回收子进程占用的内核资源,同时获取子进程的详细退出信息。
3-2 进程等待的方法
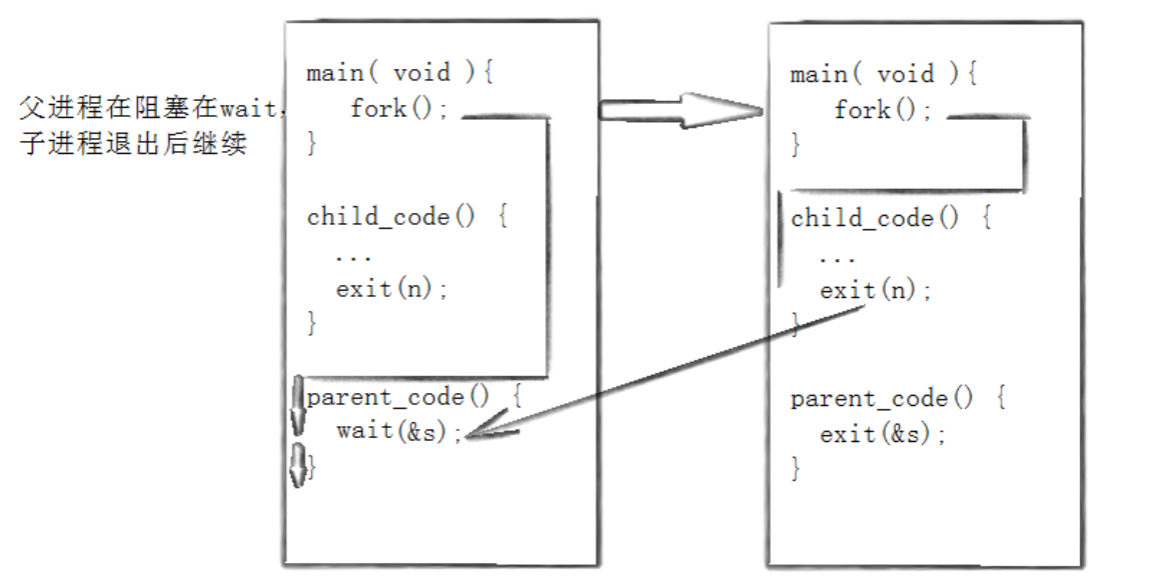
3-2-1 wait方法
wait 是基础的进程阻塞等待函数,适用于简单的子进程回收场景,函数定义如下:
cpp
#include<sys/types.h>
#include<sys/wait.h>
pid_t wait(int* status);返回值:成功返回被等待子进程的 PID,失败返回 -1。
参数:status 为输出型参数,用于获取子进程的退出状态;若不关心退出状态,可直接传入 NULL。
3-2-2 waitpid方法
waitpid 是 wait 的增强版,功能更灵活,支持指定等待进程、阻塞/非阻塞等待,函数定义如下:
cpp
pid_t waitpid(pid_t pid, int *status, int options);返回值规则:
-
正常成功:返回成功回收的子进程 PID;
-
设置 WNOHANG 非阻塞模式,且无已退出子进程:返回 0;
-
调用出错:返回 -1,同时系统会赋值 errno,标识具体错误原因。
参数详细解析:
- pid 参数(指定等待对象):
-
pid = -1:等待任意一个子进程,功能与 wait 函数完全等效;
-
pid > 0:等待 PID 与参数值完全一致的指定子进程。
- status 参数:输出型参数,用于接收子进程退出状态,配合系统宏可解析详细退出信息:
-
WIFEXITED(status):判断子进程是否为正常终止,正常退出返回真;
-
WEXITSTATUS(status):若子进程正常退出,通过该宏提取子进程的退出码。
- options 参数(等待模式):
-
默认值 0:阻塞等待,父进程会一直卡住,直到子进程退出;
-
WNOHANG:非阻塞等待,若指定子进程未结束,函数直接返回 0,不阻塞父进程执行。
waitpid 核心特性:
-
若子进程已退出,调用 wait/waitpid 会立即返回,释放资源并获取退出信息;
-
若子进程正常运行,阻塞模式下父进程会阻塞,非阻塞模式下父进程正常执行;
-
若目标子进程不存在,函数直接报错返回 -1。
3-2-3 获取子进程status
wait 和 waitpid 的 status 参数均为操作系统填充的输出型参数,并非普通整型变量,需要以位图(按位解析) 的形式读取有效信息,系统仅使用该整型变量的低16比特位存储进程退出信息。
status低16位位图详细解析:
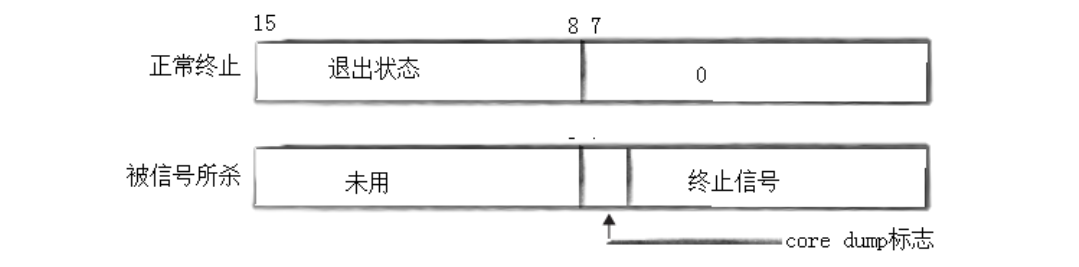
-
高8位 :存储进程正常退出的退出码,子进程正常退出时有效,可通过
(status >> 8) & 0XFF提取; -
低7位 :存储进程异常终止的信号编号,子进程被信号杀死时有效,可通过
status & 0X7F提取; -
第8位:core dump标志位,标识进程退出时是否产生核心转储文件。
若传入 NULL,代表父进程不关心子进程退出状态,系统自动丢弃该部分信息。
测试代码:
cpp
#include <sys/wait.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
int main( void )
{
pid_t pid;
if ( (pid=fork()) == -1 )
perror("fork"),exit(1);
if ( pid == 0 ){
sleep(20);
exit(10);
} else {
int st;
int ret = wait(&st);
// 正常退出
if ( ret > 0 && ( st & 0X7F ) == 0 ){
printf("child exit code:%d\n", (st>>8)&0XFF);
} else if( ret > 0 ) {
// 异常退出,被信号终止
printf("sig code : %d\n", st&0X7F );
}
}
}代码解析:程序通过fork创建子进程,子进程休眠20秒后调用exit(10)指定退出码为10;父进程调用wait阻塞等待子进程退出。若子进程正常运行结束,通过位图运算提取高8位退出码;若在子进程运行期间执行kill命令杀死子进程,子进程属于异常退出,低7位存储终止信号编号,可精准捕获异常原因。
- 子进程正常运行20秒后退出:
cpp
# ./a.out
child exit code:10- 子进程运行期间,在其他终端执行 kill 命令杀死进程:
cpp
# ./a.out
sig code : 93-2-4 阻塞与非阻塞等待
进程等待分为阻塞等待 和非阻塞等待两种模式,适配不同的开发场景。阻塞等待简单易用,但会阻塞父进程执行;非阻塞等待效率更高,可实现「等待子进程+执行自身任务」并发执行,是实际开发主流用法。
1. 阻塞式等待(options=0)
父进程等待子进程期间会暂停自身所有逻辑、进入阻塞状态,一直卡着等待,直至子进程退出、父进程成功回收资源后,才会继续往下执行代码。优点是逻辑简单、不会遗漏子进程;缺点是父进程无法执行其他任务,资源利用率低。
cpp
int main()
{
pid_t pid;
pid = fork();
if(pid < 0){
printf("%s fork error\n",__FUNCTION__);
return 1;
} else if( pid == 0 ){
// 子进程业务
printf("child is run, pid is : %d\n",getpid());
sleep(5);
exit(257);
} else{
// 父进程阻塞等待子进程
int status = 0;
pid_t ret = waitpid(-1, &status, 0);
printf("this is test for wait\n");
if( WIFEXITED(status) && ret == pid ){
printf("wait child 5s success, child return code is :%d.\n",WEXITSTATUS(status));
}else{
printf("wait child failed, return.\n");
return 1;
}
}
return 0;
}运行结果:
bash
[root@localhost linux]# ./a.out
child is run, pid is : 45110
this is test for wait
wait child 5s success, child return code is :1.2. 非阻塞式等待(options=WNOHANG)
父进程不会阻塞暂停执行,通过循环轮询的方式不断检测子进程状态。子进程未退出时,waitpid返回0,父进程可以正常执行自身的临时任务;子进程退出后,函数返回子进程PID,父进程完成资源回收。该模式最大化利用父进程资源,是实际项目中的主流等待方式。
cpp
#include <stdio.h>
#include <stdlib.h>
#include <sys/wait.h>
#include <unistd.h>
#include <vector>
// 函数指针类型
typedef void (*handler_t)();
// 函数指针数组,存放临时任务
std::vector<handler_t> handlers;
void fun_one() {
printf("这是一个临时任务1\n");
}
void fun_two() {
printf("这是一个临时任务2\n");
}
// 加载临时任务
void Load() {
handlers.push_back(fun_one);
handlers.push_back(fun_two);
}
// 执行临时任务
void handler() {
if (handlers.empty())
Load();
for (auto iter : handlers)
iter();
}
int main() {
pid_t pid;
pid = fork();
if (pid < 0) {
printf("%s fork error\n", __FUNCTION__);
return 1;
} else if (pid == 0) {
// 子进程运行
printf("child is run, pid is : %d\n", getpid());
sleep(5);
exit(1);
} else {
int status = 0;
pid_t ret = 0;
// 循环非阻塞轮询等待
do {
ret = waitpid(-1, &status, WNOHANG);
if (ret == 0) {
printf("child is running\n");
}
// 等待期间执行父进程临时任务
handler();
} while (ret == 0);
// 回收完成,判断退出状态
if (WIFEXITED(status) && ret == pid) {
printf("wait child 5s success, child return code is :%d.\n",WEXITSTATUS(status));
} else {
printf("wait child failed, return.\n");
return 1;
}
}
return 0;
}4. 进程程序替换
通过 fork 创建的子进程,默认执行与父进程完全相同的程序代码。若需要让子进程执行全新的、与父进程无关的程序,就需要通过进程程序替换功能实现。
程序替换的核心作用:通过系统提供的专属接口,将磁盘上的全新程序(代码+数据)加载到当前进程的地址空间中,替换原有程序资源,实现进程功能的完全切换。
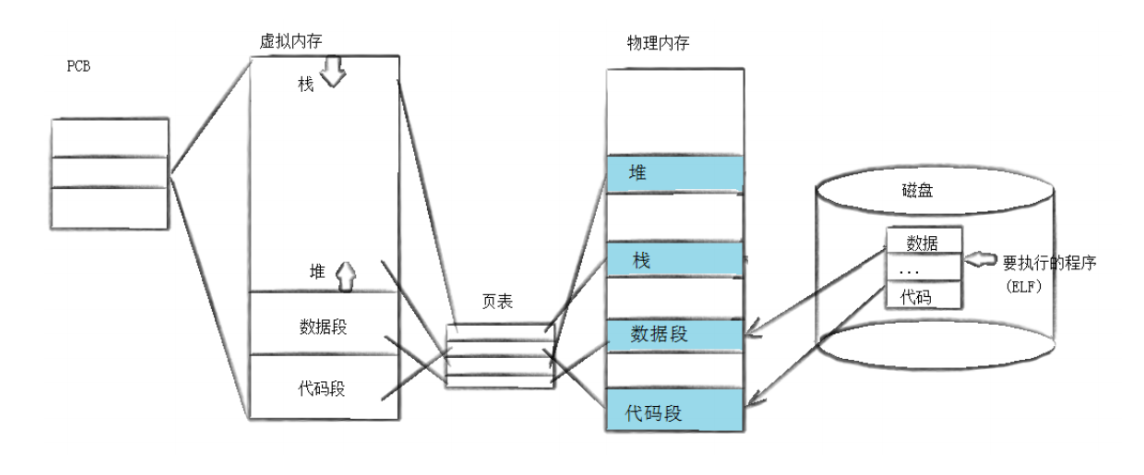
4-1 替换原理
fork 创建子进程后,父子进程共享同一份程序代码,仅执行不同代码分支。若子进程调用 exec 系列函数,会触发程序替换:系统会将进程用户空间的原有代码和数据全部清空,替换为全新程序的代码和数据,随后从新程序的启动入口开始执行。
核心关键点 :exec 程序替换不会创建新进程,不会改变进程PID、PCB、进程状态、文件描述符等内核属性,仅替换进程用户空间的代码段、数据段、堆栈内容。替换完成后,进程彻底抛弃原有代码逻辑,全新程序完全接管进程执行,因此exec调用成功后,原程序exec后续的所有代码永远不会执行。
4-2 替换函数
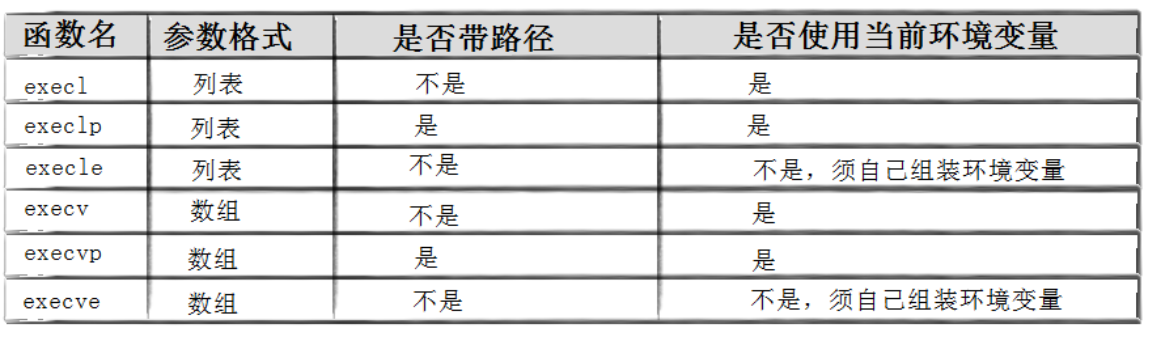
Linux 提供六个以 exec 开头的程序替换函数,统称 exec 函数族,所有函数均定义在 unistd.h 头文件中:
cpp
#include <unistd.h>
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ...,char *const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execve(const char *path, char *const argv[], char *const envp[]);4-2-1 函数解释
-
调用成功:加载全新程序,从新程序启动代码开始执行,函数无返回值,原进程后续代码全部失效;
-
调用失败:返回 -1,不会替换程序,原进程代码继续正常执行;
总结:exec 函数族只有调用失败的返回值,没有调用成功的返回值。成功则无返回、直接切换程序执行;失败返回-1,继续执行原程序后续代码。该特性也侧面说明:exec成功后,原程序执行流彻底消亡。
4-2-2 命名理解
六个函数命名存在固定规律,掌握后缀含义即可快速区分、记忆:
-
l(list):参数以列表形式逐个罗列,手动传参,末尾必须以 NULL 结尾;
-
v(vector):参数以字符串数组形式统一传递;
-
p(path):自动检索系统 PATH 环境变量,无需填写程序完整路径,直接写程序名即可;
-
e(env):支持自定义环境变量,不使用系统默认环境变量运行程序。
-
exec函数族调用完整示例:
cpp
#include <unistd.h>
int main()
{
// 定义命令参数数组、自定义环境变量数组
char *const argv[] = {"ps", "-ef", NULL};
char *const envp[] = {"PATH=/bin:/usr/bin", "TERM=console", NULL};
// l:列表传参,绝对路径
execl("/bin/ps", "ps", "-ef", NULL);
// l+p:列表传参,自动匹配PATH
execlp("ps", "ps", "-ef", NULL);
// l+e:列表传参,自定义环境变量
execle("ps", "ps", "-ef", NULL, envp);
// v:数组传参,绝对路径
execv("/bin/ps", argv);
// v+p:数组传参,自动匹配PATH
execvp("ps", argv);
// v+e:数组传参,自定义环境变量(真正的系统调用)
execve("/bin/ps", argv, envp);
exit(0);
}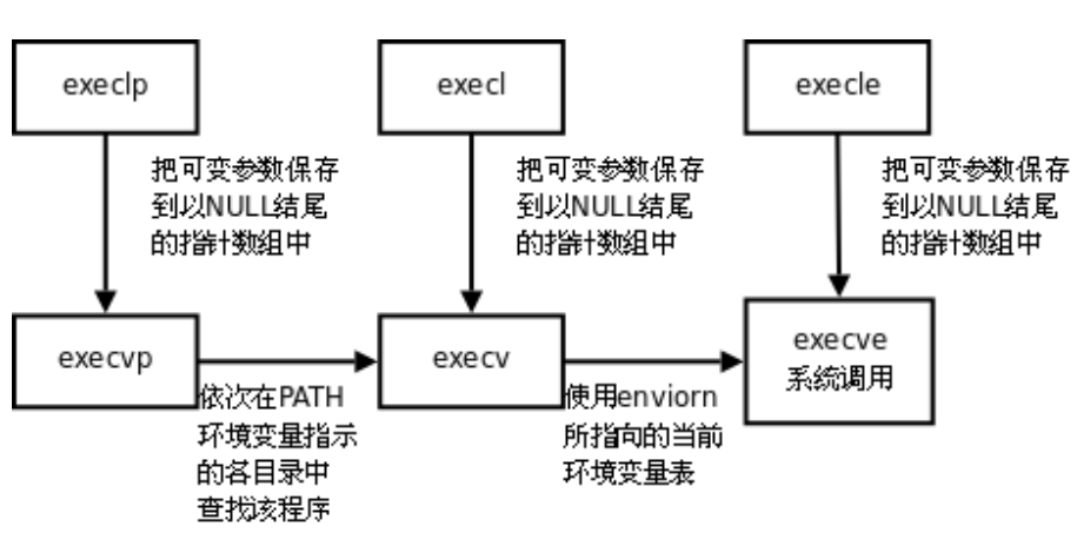
函数层级关系与开发选择 :六个函数中,仅 execve 是真正的内核系统调用(man 手册第2节),是操作系统对外的底层接口;其余五个函数均为上层用户态库函数(man 手册第3节),是系统为了方便开发者使用封装的接口,最终都会封装调用 execve 完成程序替换。日常开发中,优先使用 execlp、execvp 等带p的函数,无需书写绝对路径,代码更简洁通用。
4-2-3 环境变量进阶:继承系统ENV + 追加自定义变量(重点)
核心误区纠正 :上文 execle/execve 传入自定义 envp 数组属于全覆盖替换,会直接丢弃系统默认的所有环境变量(PATH、HOME、USER等),仅保留自己定义的变量,极易导致程序运行失败、命令找不到等问题。
实际开发刚需:保留系统原有全部环境变量,仅追加/覆盖自己定义的环境变量,兼顾系统兼容性与自定义需求。
1. 核心原理
Linux 系统提供全局环境变量指针 environ(全局变量),该指针保存了当前进程完整的系统环境变量表。我们可以基于该原生环境变量表,追加自定义环境变量,再传给 exec 函数,实现「系统默认环境 + 自定义环境」的融合效果。
头文件依赖:无需额外头文件,直接使用全局变量 extern char** environ;
2. 实现思路
-
先获取系统原生环境变量表
environ; -
在原生环境变量基础上,新增自定义键值对环境变量;
-
通过
execle/execve传递融合后的环境变量,不丢失系统原有配置。
3. 完整可运行实战代码(系统ENV+自定义ENV)
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
// 声明系统全局环境变量
extern char** environ;
int main()
{
// 1. 先打印原有系统环境变量(部分),验证继承效果
printf("系统原有PATH:%s\n", getenv("PATH"));
// 2. 自定义追加环境变量(可自定义多个)
char *my_env[] = {
"AUTHOR=Linux_Study",
"VERSION=1.0.0",
"PROJECT=C_Call_Python",
NULL // 数组必须以NULL结尾
};
// 3. 核心:fork子进程,子进程做程序替换
pid_t pid = fork();
if(pid == 0)
{
// 子进程:执行env命令,打印所有环境变量
// 用法:继承系统环境 + 追加自定义环境变量
execle("/bin/env", "env", NULL, my_env);
// execle执行失败才会走到这里
perror("execle failed");
exit(1);
}
sleep(1);
printf("父进程执行结束\n");
return 0;
}4. 关键说明与原理解析
上述代码看似直接传入了 my_env,实则底层逻辑为:execle 会在当前进程的系统环境基础上,叠加用户传入的自定义环境变量,若自定义变量与系统变量重名,会覆盖系统原有值,不冲突则直接追加。
和全覆盖式的区别:
-
纯自定义envp(旧写法):清空PATH/HOME等系统变量,仅保留自定义变量,兼容性极差;
-
系统ENV+自定义ENV(新写法):保留全部系统环境,仅新增业务变量,生产环境标准用法。
5. 两种工程化拼接写法
方法1:手动逐个追加(适合少量自定义变量)
少量环境变量可直接下标追加,写法简单直观,适合临时少量配置场景:
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
extern char** environ;
#define MAX_ENV_NUM 100
char* new_env[MAX_ENV_NUM];
int main()
{
int i = 0;
// 1. 拷贝所有系统原生环境变量
for(; environ[i] != NULL; i++)
{
new_env[i] = environ[i];
}
// 2. 手动追加少量自定义环境变量
new_env[i++] = "CUSTOM_FLAG=ON";
new_env[i++] = "APP_NAME=Process_Demo";
new_env[i] = NULL; // 结尾补NULL
// 3. 程序替换,使用拼接后的完整环境变量
execve("/bin/env", (char*[]){"env", NULL}, new_env);
perror("execve error");
return 0;
}方法2:for循环批量写入(适合大量自定义变量,推荐)
若需要定义多个环境变量,手动逐个追加冗余度高。通过for循环批量遍历写入自定义环境变量,统一管理、便于增删,是实际开发标准写法。核心逻辑:先批量定义所有自定义环境变量,再通过循环统一追加到系统环境变量数组末尾,实现环境变量融合。
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
// 声明系统全局环境变量
extern char** environ;
#define MAX_ENV_NUM 100
char* new_env[MAX_ENV_NUM];
int main()
{
int i = 0;
// 1. 第一步:循环拷贝系统所有原生环境变量
// 遍历系统默认环境表,完整继承系统ENV,不丢失任何系统配置
for (; environ[i] != NULL; i++)
{
new_env[i] = environ[i];
}
// 2. 第二步:批量定义所有自定义环境变量(统一管理,可随意增删)
char *custom_env[] = {
"VERSION=2.0.0",
"AUTHOR=Study_Linux",
"PROJECT=C_Process_Demo",
"ENABLE_LOG=1",
"LANG=C.UTF-8",
NULL // 自定义数组必须以NULL结尾,作为循环终止条件
};
// 3. 第三步:for循环批量写入自定义环境变量到总环境表
int j = 0;
for (; custom_env[j] != NULL; j++)
{
new_env[i++] = custom_env[j];
}
// 4. 数组末尾补NULL,满足exec函数环境变量数组格式要求
new_env[i] = NULL;
// 5. 程序替换:继承系统环境 + 批量追加自定义环境
execve("/bin/env", (char*[]){"env", NULL}, new_env);
// 执行失败才会执行到此处
perror("execve failed");
return 0;
}两种写法核心总结
-
手动追加:适合自定义变量≤3个的简单场景,代码简洁、无需额外数组;
-
for循环批量写入:适合多环境变量配置,变量统一维护、增删灵活,不易出错,适配正式项目开发;
-
两种写法均实现不覆盖系统原有环境变量,仅追加自定义变量,彻底解决execle/execve默认全覆盖的弊端。
若需要精准控制 环境变量(手动拼接系统+自定义),可遍历 environ 拷贝系统变量,再追加自定义变量,彻底灵活可控:
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
extern char** environ;
#define MAX_ENV_NUM 100
char* new_env[MAX_ENV_NUM];
int main()
{
int i = 0;
// 1. 拷贝所有系统原生环境变量
for(; environ[i] != NULL; i++)
{
new_env[i] = environ[i];
}
// 2. 追加自定义环境变量
new_env[i++] = "CUSTOM_FLAG=ON";
new_env[i++] = "APP_NAME=Process_Demo";
new_env[i] = NULL; // 结尾补NULL
// 3. 程序替换,使用拼接后的完整环境变量
execve("/bin/env", (char*[]){"env", NULL}, new_env);
perror("execve error");
return 0;
}4-2-4 环境变量总结
-
无e函数(execlp/execvp等):默认自动继承系统全部环境变量,无需手动配置,适合绝大多数场景;
-
带e函数(execle/execve) :支持自定义环境,默认全覆盖系统ENV;生产环境必须采用「系统ENV+自定义追加」写法;
-
环境变量继承只会影响子进程替换后的程序,不会修改父进程自身环境变量,进程间完全隔离。