跳频抗干扰通信中的智能决策:从随机跳频到深度强化学习
电磁频谱环境的日益拥挤与智能化对抗手段的不断升级,使得传统跳频通信策略面临严峻挑战。当干扰机具备自适应感知与动态攻击能力时,固定或随机跳频模式还能否保证可靠通信?本文将系统阐述跳频抗干扰通信的理论模型,分析经典跳频策略的局限性,并引入深度强化学习框架,探讨如何让通信节点自主学习最优跳频决策,实现认知抗干扰。
一、引言:跳频通信与认知干扰的博弈
跳频扩频技术通过使通信载波在一组预置信道间快速跳变,有效对抗窄带干扰、多径衰落和恶意截获。其核心思想是:只要收发双方的跳频序列保持同步,而干扰机无法预测或快速跟踪该序列,干扰能量就会被"扩"散到整个频段,从而保护有用信号。
然而,现代认知干扰机已不再局限于固定频点或简单扫频模式。它们能够实时感知频谱占用情况,分析通信节点的跳频规律,并动态调整干扰策略------例如在检测到周期性跳频模式后,同步跟随干扰;或在多个信道同时注入大功率干扰信号,使随机跳频的"概率安全"失效。
面对这种智能且自适应的对抗环境,通信节点也需要进化出学习与决策 能力。深度强化学习(Deep Q-Network, DQN)正是实现这一目标的理想工具:节点通过持续感知环境状态(各信道上的接收信号强度),以最大化累积奖励为目标,自主学习最优信道选择策略。这一思想被称为认知抗干扰通信。
本文将从基础理论出发,逐步建立跳频通信的系统模型,分析传统策略的性能边界,再深入阐述混合奖励驱动的深度Q网络如何实现智能跳频决策。希望通过清晰的理论推导和逻辑层次,帮助读者理解这一前沿方向的核心机理。
二、系统模型与基础理论
2.1 频段划分与信道模型
设总可用频段为 f start , f end f_{\\text{start}}, f_{\\text{end}} fstart,fend,带宽 B total = f end − f start B_{\text{total}} = f_{\text{end}} - f_{\text{start}} Btotal=fend−fstart。将该频段均匀划分为 K K K 个正交子信道,每个信道的带宽为 B ch = B total / K B_{\text{ch}} = B_{\text{total}} / K Bch=Btotal/K。第 i i i 个信道的中心频率为:
f i = f start + ( i − 1 ) B ch , i = 1 , 2 , ... , K f_i = f_{\text{start}} + (i-1) B_{\text{ch}}, \quad i = 1, 2, \dots, K fi=fstart+(i−1)Bch,i=1,2,...,K
信道之间的正交性通过频域滤波实现,假设无邻道泄露。通信信号为窄带信号,占据整个信道带宽。
传播模型同时考虑大尺度衰落(路径损耗)与小尺度衰落(多径效应)。发送功率为 P t P_t Pt(单位 mW)的信号,经过距离 d d d 传播后,接收功率为:
P r = P t ⋅ g , g = d − μ ⋅ ∣ h ∣ 2 P_r = P_t \cdot g, \quad g = d^{-\mu} \cdot |h|^2 Pr=Pt⋅g,g=d−μ⋅∣h∣2
- μ \mu μ 为路径损耗指数,自由空间取 2,城市环境取 3~4;
- h h h 为复高斯随机变量: h ∼ C N ( 0 , 1 ) h \sim \mathcal{CN}(0,1) h∼CN(0,1),其模平方 ∣ h ∣ 2 |h|^2 ∣h∣2 服从均值为 1 的指数分布(瑞利衰落功率增益)。
此外,接收机存在热噪声,功率记为 P n P_n Pn(单位为 mW,对应 dBm 值通常为 -80 ~ -100 dBm)。
2.2 通信节点与干扰机
通信节点对 :系统包含 N N N 个用户对。每个用户对由一个发送节点(Tx)和一个接收节点(Rx)组成,且二者共享相同的跳频序列(即始终在同一信道上通信)。每个时隙 t t t,Tx 根据其跳频策略选择信道 c t ∈ { 1 , ... , K } c_t \in \{1,\dots,K\} ct∈{1,...,K},发送一个数据包。Rx 在相同的信道 c t c_t ct 上接收并解调。
干扰机 :干扰机可在每个时隙选择一个或多个信道发射大功率噪声信号。设干扰发射功率为 P j P_j Pj,通常远大于用户功率。干扰机的策略模式包括:
- 固定干扰:始终攻击一个固定信道(如信道 1);
- 随机干扰:每个时隙独立均匀随机选择一个信道;
- 扫频干扰 :按固定顺序遍历所有信道,如 c t ( j ) = ( t m o d K ) + 1 c_t^{(j)} = (t \mod K) + 1 ct(j)=(tmodK)+1;
- 梳状干扰:同时干扰多个固定的信道(例如信道 2, 5, 8)。
干扰信号与通信信号在物理层叠加,接收端的总干扰加噪声功率为各来源之和(假设信号不相关)。
2.3 信号接收与成功条件
在时隙 t t t,若收发双方均选择了信道 c c c,则 Rx 接收到的期望信号功率为:
S = P t ⋅ g Tx → Rx S = P_t \cdot g_{\text{Tx}\to\text{Rx}} S=Pt⋅gTx→Rx
同时,该信道上可能存在的干扰信号(来自干扰机)功率为:
J = P j ⋅ g Jammer → Rx J = P_j \cdot g_{\text{Jammer}\to\text{Rx}} J=Pj⋅gJammer→Rx
其他用户对的通信信号(同信道干扰)也可能存在,但本文暂不考虑多用户自干扰,假设各用户对选择信道独立,且 N N N 远小于 K K K 时碰撞概率较低。
因此,接收信号的信干噪比(SINR)为:
γ = S J + P n \gamma = \frac{S}{J + P_n} γ=J+PnS
解调成功的条件是 SINR 大于某个门限 β \beta β(通常对应一定误码率要求,如 10 − 5 10^{-5} 10−5):
γ ≥ β \gamma \ge \beta γ≥β
若成功,Rx 返回 ACK 包给 Tx;否则返回 NACK。Tx 通过接收反馈判断本次传输是否成功。
2.4 性能指标
定义时隙成功指示符 s n ( t ) ∈ { 0 , 1 } s_n(t) \in \{0,1\} sn(t)∈{0,1} 为用户对 n n n 在时隙 t t t 是否成功传输。则:
- 包错误率(PER): \\text{PER} = 1 - \\frac{1}{T}\\sum_{t=1}\^T s_n(t) (针对单个用户);
- 网络连通时间比例(NCT) : \\text{NCT}(t) = \\frac{1}{N}\\sum_{n=1}\^N s_n(t) ,反映整个系统在时隙 t t t 的吞吐效率。
三、传统跳频策略的理论分析
3.1 固定跳频
策略:始终选择同一个信道(例如 c = 1 c=1 c=1)。当干扰机固定攻击该信道时,通信永远失败( s = 0 s=0 s=0)。若干扰机为随机或扫频模式,则成功概率等于干扰未击中该信道的概率。设干扰机每个时隙攻击一个随机信道,则击中概率为 1 / K 1/K 1/K,因此成功概率为 1 − 1 / K 1-1/K 1−1/K。但若干扰功率远大于信号功率( P j ≫ P t P_j \gg P_t Pj≫Pt),一旦击中,SINR 极低,可认为失败;未击中时,SINR 仅受噪声影响,成功概率接近 1。故平均成功概率:
E s = 1 − 1 K \mathbb{E}s = 1 - \frac{1}{K} Es=1−K1
固定跳频的致命缺陷是:一旦干扰机探测到固定信道(例如通过频谱感知),可以持续攻击该信道,导致完全瘫痪。
3.2 随机跳频
策略:每个时隙,Tx 独立均匀随机选择信道 c t ∼ U { 1 , ... , K } c_t \sim \mathcal{U}\{1,\dots,K\} ct∼U{1,...,K},Rx 相同(同步随机)。干扰机也独立随机选择信道。则收发信道一致的概率为 1 / K 1/K 1/K,在此条件下干扰机恰好也选中同一信道的概率为 1 / K 1/K 1/K。因此三者在同一信道的概率为 1 / K 2 1/K^2 1/K2。然而,更精确的成功条件为:收发一致且 干扰机未攻击该信道。由于收发一致事件与干扰机选择独立,成功概率:
E s = Pr ( Tx=Rx ) ⋅ Pr ( Jammer ≠ Tx ) = 1 K ⋅ ( 1 − 1 K ) = K − 1 K 2 \mathbb{E}s = \Pr(\text{Tx=Rx}) \cdot \Pr(\text{Jammer} \neq \text{Tx}) = \frac{1}{K} \cdot \left(1 - \frac{1}{K}\right) = \frac{K-1}{K^2} Es=Pr(Tx=Rx)⋅Pr(Jammer=Tx)=K1⋅(1−K1)=K2K−1
当 K K K 较大时,该值约等于 1 / K 1/K 1/K。相比于固定跳频( 1 − 1 / K 1-1/K 1−1/K),随机跳频的成功概率低得多。原因在于:随机跳频虽然降低了被干扰机精确跟踪的风险,但同时也牺牲了收发同步的概率。实际上,为了让收发同步,通常采用预共享伪随机序列(即共享随机跳频 ),使 Tx 和 Rx 始终选择相同信道,只需对抗干扰机。此时成功概率为 1 − 1 / K 1 - 1/K 1−1/K,与固定跳频在随机干扰下的性能相同。
共享随机跳频的弱点在于:干扰机若采用扫频模式,可以"跟随"跳频序列?由于跳频序列是伪随机的,且周期很长,扫频干扰(顺序遍历)无法预测下一时隙的信道,因此击中概率仍为 1 / K 1/K 1/K。但若干扰机具有学习能力,能通过长时间观测推断出伪随机生成器的种子,则可实现精确跟随干扰。此外,多信道干扰(每时隙攻击多个信道)会显著增大击中概率。
3.3 多信道干扰下的性能退化
设干扰机每个时隙随机选择 J J J 个不同的信道进行攻击( 1 ≤ J ≤ K 1 \le J \le K 1≤J≤K),用户对采用共享随机跳频。收发一致的信道被干扰击中的概率等于 J / K J/K J/K。因此成功概率为:
E s = 1 − J K \mathbb{E}s = 1 - \frac{J}{K} Es=1−KJ
当 J J J 接近 K / 2 K/2 K/2 时,成功概率已低于 0.5。这表明,干扰机仅需中等数量的并行干扰信道即可严重破坏随机跳频通信,而不需要精确预测跳频序列。
四、基于深度强化学习的智能跳频
为了应对上述挑战,我们引入深度强化学习,使每个用户对能够主动感知频谱环境 ,并自主学习最优信道选择策略,从而在未知和动态的干扰模式下仍保持可靠通信。
4.1 马尔可夫决策过程建模
将问题建模为马尔可夫决策过程,由以下四元组定义。
状态空间 S S S:每个时隙结束后,节点通过频谱感知获取所有 K K K 个信道上的接收信号强度(RSSI),记为向量 o t = o t , 1 , o t , 2 , ... , o t , K \mathbf{o}t = o_{t,1}, o_{t,2}, \\dots, o_{t,K} ot=ot,1,ot,2,...,ot,K,其中 o t , k o{t,k} ot,k 为信道 k k k 在时隙 t t t 的 RSSI(单位 dBm)。为了捕捉干扰的时间相关性(如扫频模式),令智能体观测最近 ϕ \phi ϕ 个时隙的 RSSI 序列,构成一个 ϕ × K \phi \times K ϕ×K 的矩阵:
O t = o t − ϕ + 1 ; o t − ϕ + 2 ; ... ; o t ∈ R ϕ × K O_t = \\mathbf{o}_{t-\\phi+1}; \\mathbf{o}_{t-\\phi+2}; \\dots; \\mathbf{o}_t \in \mathbb{R}^{\phi \times K} Ot=ot−ϕ+1;ot−ϕ+2;...;ot∈Rϕ×K
这个"频谱瀑布图"包含了干扰的历史模式信息。
动作空间 A A A:每个时隙,智能体(Tx)需要选择一个信道进行数据发送,即 a t ∈ { 1 , 2 , ... , K } a_t \in \{1, 2, \dots, K\} at∈{1,2,...,K}。
状态转移概率 P ( s t + 1 ∣ s t , a t ) P(s_{t+1} | s_t, a_t) P(st+1∣st,at):由环境决定,包括干扰机的策略、信道衰落的变化等。智能体无需知道显式模型。
奖励函数 r ( s t , a t ) r(s_t, a_t) r(st,at):传统 DQN 使用单一奖励,但本文采用混合奖励设计,将抗干扰目标与频谱效率目标分离。
4.2 混合奖励与复合 Q 值
定义两种奖励:
- 频率复用奖励 r u r_u ru:鼓励成功通信,反映频谱利用效率。成功时 r u = + 5 r_u = +5 ru=+5,失败时 r u = − 1 r_u = -1 ru=−1。
- 抗干扰奖励 r j r_j rj:惩罚被干扰导致的失败,反映通信的鲁棒性。成功时 r j = + 1 r_j = +1 rj=+1,失败时 r j = − 10 r_j = -10 rj=−10。
两个奖励的尺度差异体现了安全性高于吞吐量的设计理念:一次失败带来的负反馈远大于一次成功的正反馈,促使智能体优先避免干扰。
在此基础上,引入两个独立的动作值函数:
- Q u ( s , a ) Q_u(s, a) Qu(s,a):对应频率复用目标的期望累积折扣奖励;
- Q j ( s , a ) Q_j(s, a) Qj(s,a):对应抗干扰目标的期望累积折扣奖励。
最终的复合 Q 值 定义为:
Q comp ( s , a ) = η ⋅ Q j ( s , a ) + ( 1 − η ) ⋅ Q u ( s , a ) Q_{\text{comp}}(s, a) = \eta \cdot Q_j(s, a) + (1 - \eta) \cdot Q_u(s, a) Qcomp(s,a)=η⋅Qj(s,a)+(1−η)⋅Qu(s,a)
其中 η ∈ 0 , 1 \eta \in 0,1 η∈0,1 是权重参数。当面对强跟踪式干扰(如扫频)时,增大 η \eta η(如 0.8)可使智能体更侧重于避开干扰;当干扰较弱或信道资源稀缺时,可减小 η \eta η 以平衡吞吐量。
智能体选择动作的依据为:
a t = arg max a Q comp ( s t , a ) a_t = \arg\max_{a} Q_{\text{comp}}(s_t, a) at=argamaxQcomp(st,a)
探索过程采用 ϵ \epsilon ϵ-greedy 策略:以概率 ϵ \epsilon ϵ 随机选择动作,以概率 1 − ϵ 1-\epsilon 1−ϵ 选择贪婪动作。
4.3 深度 Q 网络结构
为了逼近 Q u Q_u Qu 和 Q j Q_j Qj,我们构建两个结构相同但参数独立的深度卷积神经网络。
网络输入 :状态矩阵 O t ∈ R ϕ × K O_t \in \mathbb{R}^{\phi \times K} Ot∈Rϕ×K,可视为一张灰度图像(高度 ϕ \phi ϕ,宽度 K K K)。
网络层设计:
- 卷积层:卷积核尺寸 10 × 4 10 \times 4 10×4,步长为 2,填充方式为相同(same padding),输出通道数 16。激活函数:ReLU。该层用于提取频谱瀑布图中的局部时空模式(如干扰的扫频斜率)。
- 全连接层:将卷积输出的特征图展平后,连接至 128 个神经元的隐藏层,ReLU 激活。
- 输出层: K K K 个神经元,线性激活,分别对应 Q ( s , a ) Q(s, a) Q(s,a) 对每个动作的估计值。
网络训练采用经验回放 和目标网络 (固定参数的目标网络每 C C C 步同步一次)以提高稳定性。损失函数为均方贝尔曼误差:
L ( θ ) = E ( s , a , r , s ′ ) ∼ D ( r + γ max a ′ Q ( s ′ , a ′ ; θ − ) − Q ( s , a ; θ ) ) 2 \mathcal{L}(\theta) = \mathbb{E}_{(s,a,r,s')\sim\mathcal{D}} \left \\left( r + \\gamma \\max_{a'} Q(s', a'; \\theta\^-) - Q(s, a; \\theta) \\right)\^2 \\right L(θ)=E(s,a,r,s′)∼D(r+γa′maxQ(s′,a′;θ−)−Q(s,a;θ))2
其中 θ \theta θ 为在线网络参数, θ − \theta^- θ− 为目标网络参数, γ \gamma γ 为折扣因子(取 0.8), D \mathcal{D} D 为经验回放池(容量 5000)。优化器采用 Adam,学习率 10 − 3 10^{-3} 10−3,批大小 128。
4.4 双网络交替更新
与传统 DQN 不同,本框架维护两个独立的在线网络和目标网络:一个用于 Q u Q_u Qu,一个用于 Q j Q_j Qj。每个时隙,智能体存储五元组 ( s t , a t , r u , r j , s t + 1 ) (s_t, a_t, r_u, r_j, s_{t+1}) (st,at,ru,rj,st+1) 到经验池。训练时,从池中随机采样一批数据,分别计算 Q u Q_u Qu 和 Q j Q_j Qj 的损失并更新各自网络参数。由于两个网络的输入相同但奖励不同,它们会学到不同的特征侧重: Q u Q_u Qu 倾向于选择成功概率高的信道(即使可能被干扰), Q j Q_j Qj 则强烈避免任何可能导致失败的信道。
复合 Q 值仅用于动作选择阶段 ;而在网络更新阶段,两个网络仍使用各自独立的贝尔曼目标,从而保持其特异性。
五、智能抗干扰的性能与机理分析
5.1 学习曲线与收敛性
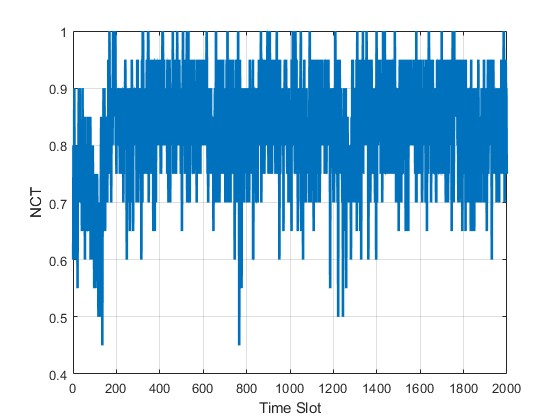
在扫频干扰模式下(干扰机每时隙轮换一个信道,功率 P j = 20 P t P_j = 20P_t Pj=20Pt),训练智能体 2000 个时隙。绘制网络连通时间比例(NCT)随时间的演化曲线,观察三个阶段:
- 探索阶段(前 200 时隙) : ϵ \epsilon ϵ 较大(初始 0.1 或更高),动作随机性强,NCT 维持在 0.2 ~ 0.3 左右,接近随机跳频的性能下限。
- 学习阶段(200 ~ 1000 时隙):随着经验积累,复合 Q 值开始反映干扰模式,智能体逐渐学会避开当前时隙干扰机所在的信道。NCT 稳步上升至 0.6 以上。
- 收敛阶段(1000 时隙后) : ϵ \epsilon ϵ 衰减至极小值,智能体基本采用贪婪策略。NCT 稳定在 0.85 ~ 0.9 之间,显著优于随机跳频( 1 − 1 / K 1 - 1/K 1−1/K = 0.9,但实际因干扰功率优势会略低)。剩余失败主要来自信道衰落深度(瑞利衰落导致 SINR 低于门限)以及多用户偶发碰撞。
5.2 决策行为解释
通过分析智能体的动作序列与干扰机信道的时序关系,可以发现:智能体能够从历史 ϕ \phi ϕ 个时隙的 RSSI 中推断出干扰机的扫频周期 。具体地,扫频干扰在每个时隙 t t t 攻击的信道为 c t ( j ) = ( t m o d K ) + 1 c_t^{(j)} = (t \mod K) + 1 ct(j)=(tmodK)+1。当 ϕ \phi ϕ 足够大(如 100,大于 K K K)时,智能体可观察到 RSSI 在信道 1 , 2 , ... , K , 1 , 2 , ... 1,2,\dots,K,1,2,\dots 1,2,...,K,1,2,... 上周期性出现高峰值。经过训练,网络中的卷积层学会了识别这种"对角线"模式,并预测下一时隙干扰机的位置,从而选择其他信道。
若干扰机改为随机策略,则 RSSI 无时序规律,智能体的最优策略退化为随机选择,复合 Q 值在所有动作上趋于相等,此时 NCT 约为 1 − 1 / K 1 - 1/K 1−1/K,与理论一致。
5.3 与传统策略的定量对比
在相同条件下( K = 10 K=10 K=10, P j / P t = 20 P_j/P_t = 20 Pj/Pt=20,扫频干扰),各策略的性能对比如下:
| 策略 | NCT(稳态) | 是否需要预共享序列 | 能否适应新干扰模式 |
|---|---|---|---|
| 固定跳频 | ≈ 0 | 否 | 否 |
| 随机跳频 | 0.88 ~ 0.90 | 是(收发同步) | 否 |
| 共享随机跳频 | 0.88 ~ 0.90 | 是 | 否 |
| DQN 智能跳频 | 0.85 ~ 0.90 | 否(在线学习) | 是 |
虽然 DQN 在扫频干扰下的稳态 NCT 未显著高于随机跳频的理论上界,但其关键优势在于:无需任何先验知识 (不依赖预共享伪随机序列),且能自适应切换策略------当干扰模式变为梳状或跟随式时,DQN 可在线重新学习,而传统随机跳频的性能会急剧恶化。
六、结论与展望
本文从跳频抗干扰通信的理论基础出发,系统分析了传统固定跳频、随机跳频在认知干扰环境下的局限性,并引入了一种基于深度强化学习的智能跳频决策框架。该框架通过混合奖励设计将频谱效率目标与抗干扰韧性目标分离,利用卷积神经网络从频谱瀑布图中提取干扰的时空模式,最终实现了无需先验同步的认知抗干扰通信。
进一步的研究方向
- 多智能体协作抗干扰:当多个用户对共存时,彼此的自干扰不可忽视。可以将问题建模为分布式多智能体强化学习(如 QMIX、MADDPG),让各用户通过学习相互避让,提升总吞吐量。
- 迁移学习与快速适应:训练好的 DQN 模型能否在干扰模式发生变化时快速微调?元强化学习或域随机化技术可能帮助智能体在新环境中快速收敛。
- 实际信道验证:将算法部署到软件无线电平台(如 USRP),在真实无线环境中测试抗干扰性能,并考虑硬件损伤、非完美同步等因素。
电磁频谱对抗正从"预设规则"走向"认知博弈"。深度强化学习为通信节点赋予了实时学习与决策的能力,使跳频通信在智能干扰环境中仍能保持鲁棒连接。希望本文的理论分析与方法阐述能为该领域的研究人员提供有益参考。
作者简介:雷达通信与深度学习领域研究者,长期关注认知无线电、强化学习在无线通信中的应用。如对本文内容有任何疑问或建议,欢迎留言交流。