摘要
可重构智能表面(RIS)凭借其可编程调控无线信号传播的能力,被认为是第六代(6G)移动通信系统的关键技术之一。针对非理想信道状态信息(CSI)和硬件损伤带来的挑战,本文研究基站发射波束赋形矩阵与RIS相位偏移矩阵的联合设计问题,目标是在发射功率和单位模约束下最大化系统总速率。提出一种基于深度强化学习(DRL)的求解框架。将问题建模为马尔可夫决策过程(MDP),采用深度确定性策略梯度(DDPG)算法,通过试错交互与环境学习。
1 研究背景
- 6G与RIS的兴起
可重构智能表面(RIS)被认为是下一代无线通信系统的关键技术之一。RIS由多个亚波长间距的反射单元构成,通过调节每个单元的阻抗,可对入射波施加所需的相位偏移,从而在接收端调控多径干扰。然而,实际RIS硬件的反射系数不仅与相位有关,其幅度也会随施加的相位变化而衰减,即相位相关幅度模型。这种非线性特性会导致显著的性能损失,并使传统的优化方法(通常假设理想反射)变得不切实际 - 现有DRL方法的局限
- 深度强化学习(DRL)已成为RIS辅助无线系统(如非正交多址、毫米波通信、车联网等)中一种广泛研究的替代方法。例如,已有工作采用深度确定性策略梯度(DDPG)算法调节RIS相位偏移,或在理想反射假设下联合设计下行波束赋形与RIS相移。但是,这些DRL应用均假设理想反射(幅度恒为1)和完美CSI,没有考虑实际RIS的硬件损伤(相位相关幅度)以及信道估计误差的影响。
2 系统与问题建模
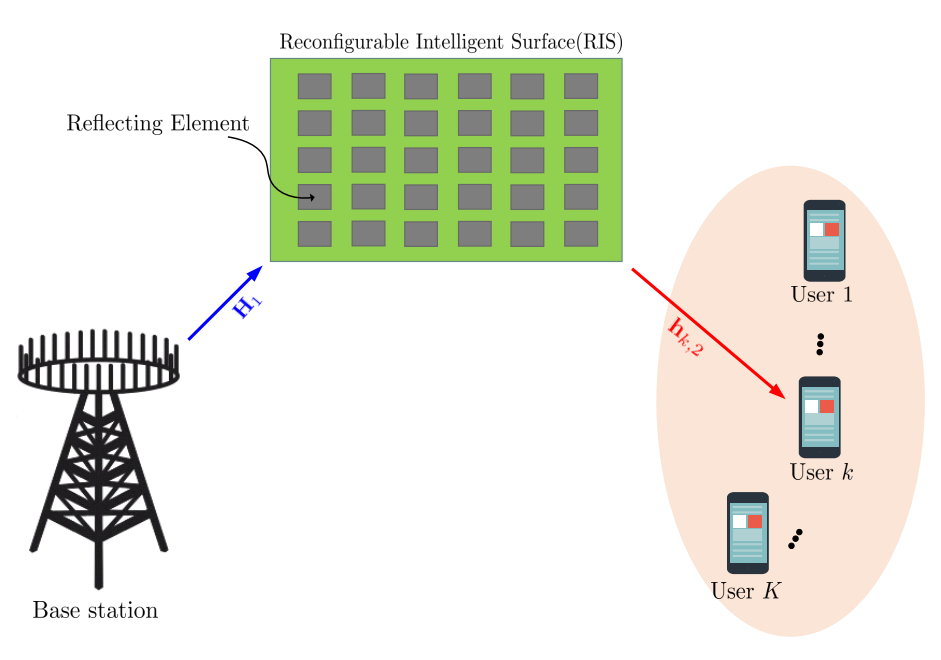
- 一个配备 M 根天线的基站
- 一个配备 N 个反射单元的 被动RIS
- K个单天线用户
-
- BS 与用户之间的直射链路被完全阻挡,信号仅通过 RIS 反射传输
令G表示基站波束成形矩阵 ,Φ表示RIS的相移矩阵, H表示从基站到RIS的信道矩阵,hk表示从RIS到用户k的信道向量,则第k个用户的接收信号为
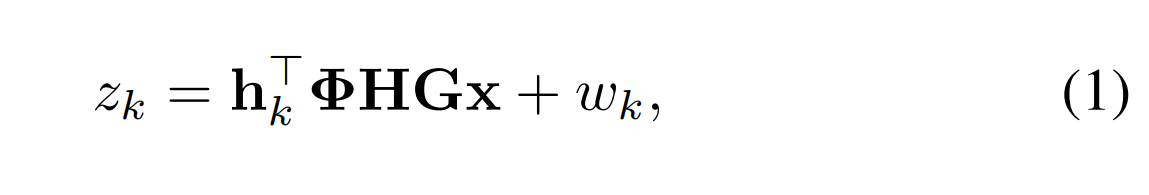
- BS 与用户之间的直射链路被完全阻挡,信号仅通过 RIS 反射传输
传统的RIS相移模型,只改变相位,不改变幅度,为
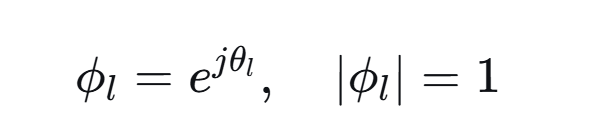
考虑到实际RIS硬件存在与相位相关的幅度衰减,即不同相位偏移会导致不同的反射损耗


进一步,考虑基站只能获得带估计误差的级联信道,模拟实际系统中基站难以获得完美CSI和精确硬件模型的情况,即

则用户k的速率表达式为
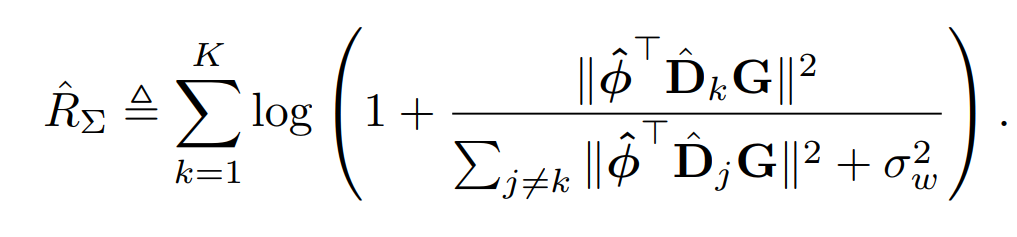
优化目标在基站仅能已知估计信道的条件以及硬件损失的情况下 ,优化使得实际系统总速率接近真实环境下的最优值
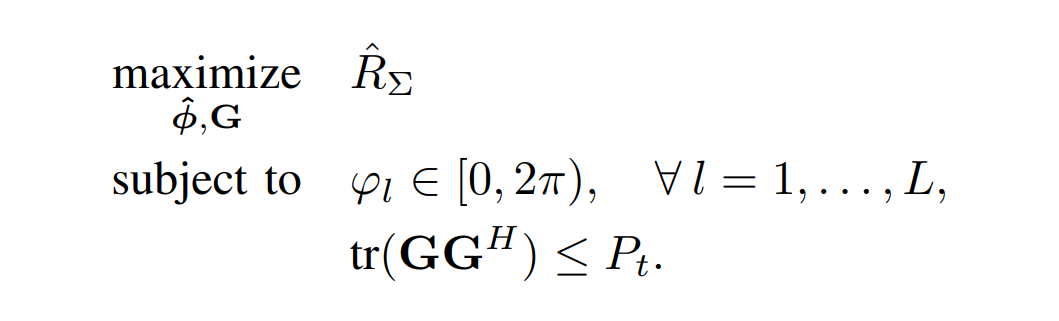
- 由于误差存在,问题非凸
- 大多数已有工作采用交替优化,缺点为交替迭代可能慢、依赖初始值、且不能保证全局最优
3 强化学习方法
马尔可夫决策过程:**
- 状态:带噪的级联信道估计;各个用户的发射波束成形;各个用户的接收功率;上一时刻的的动作;
1、CSI是问题的核心参数:智能体需要知道信道才能推断何种动作能产生高奖励。
2、上一时刻的动作:使智能体知道当前解的"位置",便于做微小调整。没有历史动作,网络只能依赖当前功率间接推断,效率更低。
3、功率信息:反映当前波束赋形和相位偏移对每个用户的信号与干扰的影响,是计算奖励的基础。 - 动作:一般为待优化的变量,为波束成形和相移矩阵G和Φ;
- 奖励:即优化问题的目标函数。
2 关键设计:网络结构优化
- 用平均奖励修正目标
无线通信系统中,基站持续进行波束赋形和RIS配置,没有明确终止状态,若采用折扣因子 γ<1,会偏向短期奖励;若 γ=1,则累积奖励可能发散。通过引入平均奖励的概念来适应,
1、定义平均奖励为到当前时间步为止的奖励滑动平均。
2、将修正后的奖励用于Q值更新
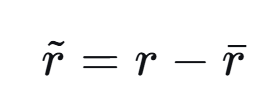
- 引入β‑Space Exploration
1、在硬件损失的情况下,基站不知道RIS的相位‑幅度函数,导致实际反射幅度远小于1。如果智能体仅使用原始动作,环境实际接收到的信号会被幅度衰减,使奖励远低于预期,智能体无法有效学习。
2、将 Actor 网络输出的理想反射动作(假设 RIS 单元反射幅度为 1)转换为更接近真实硬件特性的动作,使得环境反馈的奖励能够隐含真实幅度损耗信息,从而让智能体间接学会补偿硬件损伤
3、增加一个探索网络专门预测每个RIS单元的反射幅度,其输出为
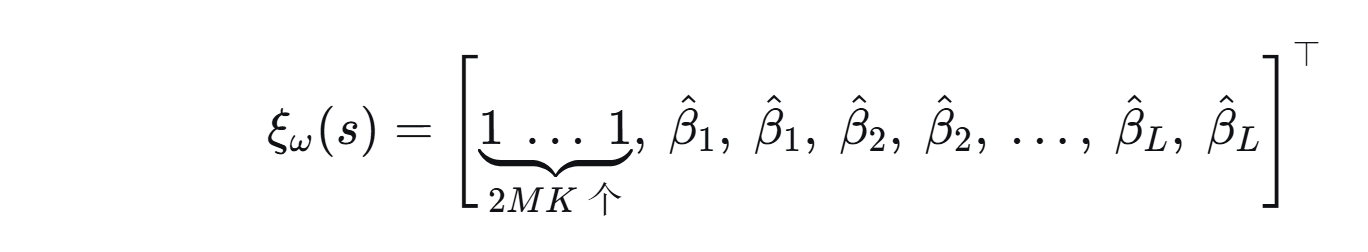
 缩放后 RIS 反射系数的实际形式
缩放后 RIS 反射系数的实际形式
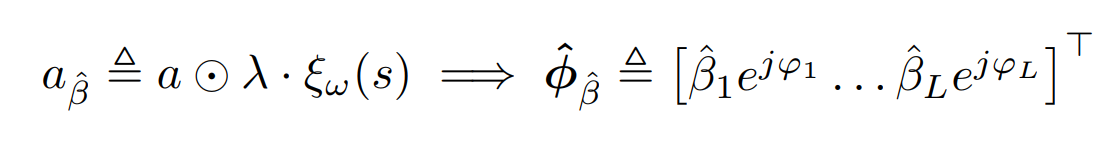

- 通过缩放动作,智能体主动降低其输出的相位幅度,使得期望的反射信号强度与环境实际产生的强度更匹配,从而奖励更真实。
- 在训练初期λ较大,说明探索网络对动作的扰动强,迫使 Q 网络和 Actor 快速适应硬件损伤,在训练后期扰动会减弱。
探索网络的损失函数为
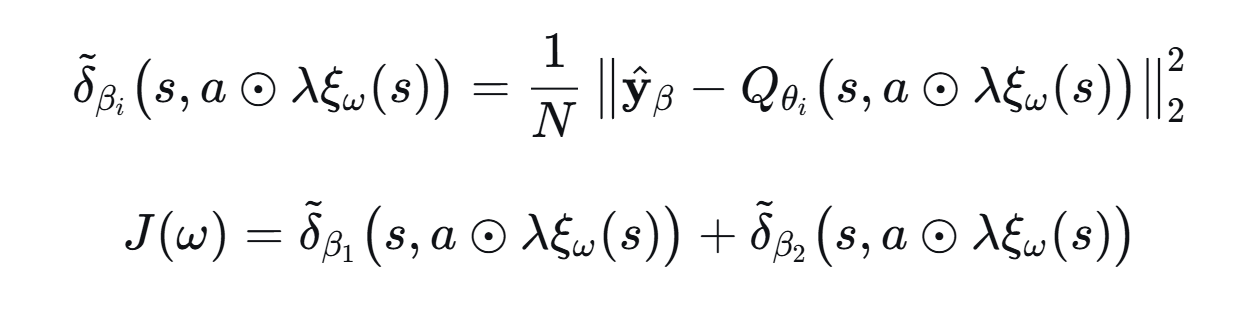
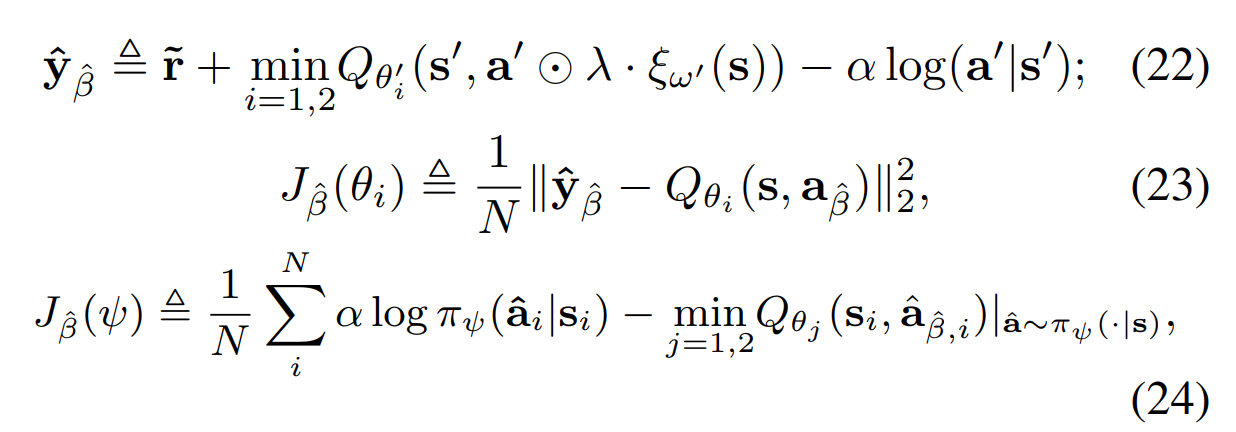
仿真参数和结果
| 类别 | 参数 | 取值 |
|---|---|---|
| 神经网络 | 隐藏层数量 | 2 |
| 每隐藏层单元数 | 256 | |
| 隐藏层激活函数 | ReLU | |
| Q网络输出层激活 | Linear | |
| Actor / Explorer 输出层激活 | tanh / sigmoid | |
| 权重初始化 | Xavier uniform | |
| 偏置初始化 | constant (0) | |
| 优化器 | Adam | |
| SAC 算法 | 折扣因子 | 1 |
| 目标网络软更新率 | 0.001 | |
| 网络更新间隔 | 1 step | |
| 熵正则化系数(初始) | 0.2 |
| | SAC log 标准差裁剪 | (-20, 2) |
| | 数值稳定常数 | 10⁻⁶ |
| 训练超参数 | 学习率 | 10⁻³ |
| | 权重衰减 | 0 |
| | 经验回放池大小 | 20000 |
| | 经验采样方式 | 均匀随机 |
| | 小批量大小 | 16 |
| | 总训练时间步 | 20000 |
| β‑Space Exploration | 探索强度初始值 | 0.3 |
| | 探索强度衰减 | 线性衰减至 0 |
| 环境参数 | AWGN 方差 | 10⁻² |
| | 信道估计噪声方差 | 10⁻² |
| | RIS 硬件参数 (μ) | 0 |
| | RIS 硬件参数 (κ) | 1.5 |
| | RIS 最小反射幅度 (β_min) | 0.3 或 0.6 |
| | 发射功率 | 5--30 dBm |
| | 基站天线数 | 4 |
| | RIS 单元数 | 16 或 64 |
| | 用户数 | 4 |
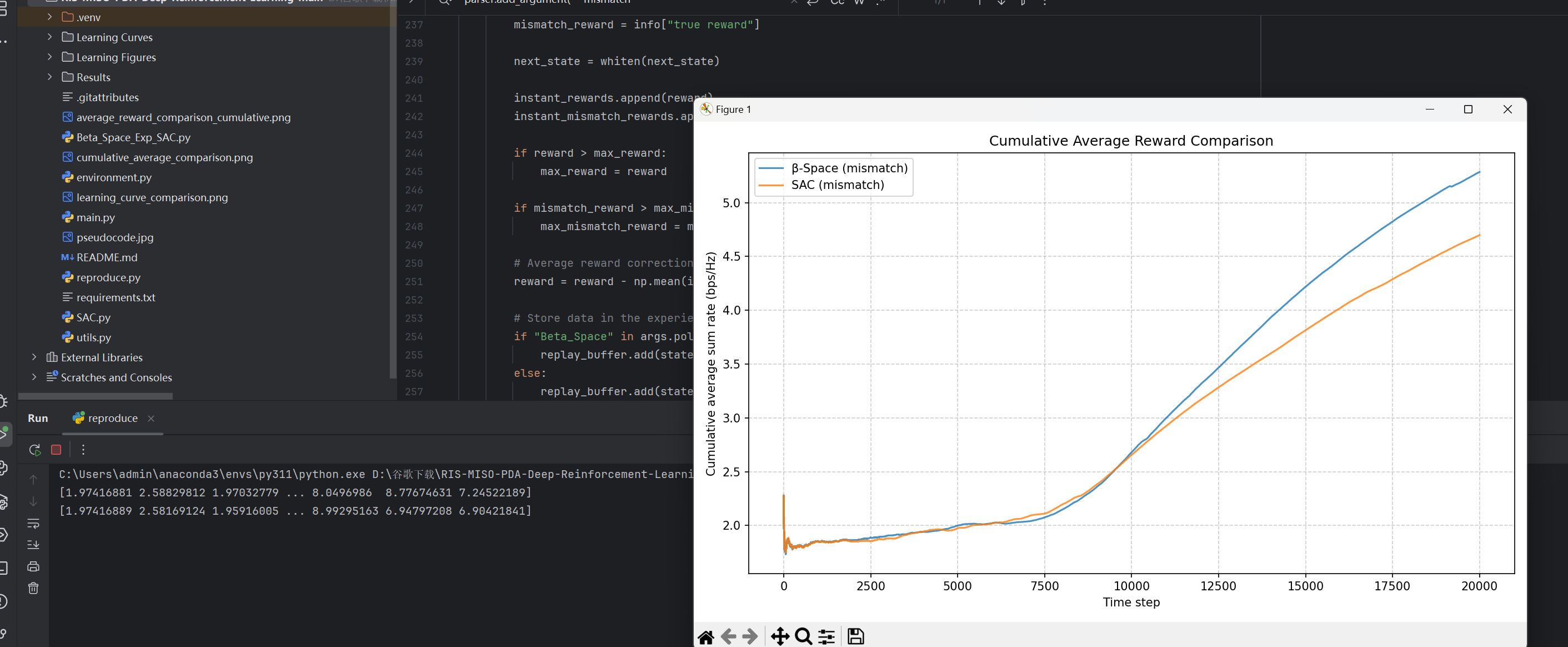
可看到优化后的网络reward优于经典的SAC。
4 总结
本文针对RIS辅助MU‑MISO系统中存在的硬件损伤和非理想CSI问题,提出了基于深度强化学习的方法,通过引入探索网络对相位动作进行自适应缩放,使智能体在仅能获得不完美信道估计并假设理想反射的条件下,仍能隐式学习真实幅度损耗,从而逼近理想上界性能,通过实验表明结论的有效性。未来研究可进一步拓展至多RIS协同、时变信道与用户移动性,同时可探索更高效的探索策略或迁移学习以加速收敛,并将该方法应用于能效最大化、安全速率优化等其他RIS辅助通信目标。
参考文献:
Saglam, Baturay, et al. "Deep Reinforcement Learning Based Joint Downlink Beamforming and RIS Configuration in RIS-Aided MU-MISO Systems Under Hardware Impairments and Imperfect CSI." 2023 IEEE International Conference on Communications Workshops (ICC Workshops), IEEE, 2023, pp. 66-72. DOI, doi:10.1109/ICCWorkshops57953.2023.10283517.