文章目录
- 前言
- 1.数据类型及其存储
-
- [1.1 基本数据类型](#1.1 基本数据类型)
-
- 基本数据类型两大类-常量与变量
- [基本数据类型1 - 整型](#基本数据类型1 - 整型)
- [基本数据类型2 - 实型](#基本数据类型2 - 实型)
- [基本数据类型3 - 字符型](#基本数据类型3 - 字符型)
- [基本数据类型4 - 枚举类型](#基本数据类型4 - 枚举类型)
- 数据类型易错点:隐式类型转换
- [1.2 构造数据类型](#1.2 构造数据类型)
- 大小端模式
- 类型转换
- 2.运算符
- [3. 函数](#3. 函数)
- [4.控制语句(for, while, if)](#4.控制语句(for, while, if))
- 数据的输入
前言
C语言是一种可以直接操作内存单元的语言,在嵌入式开发中经常使用得到。
C语言的基础知识可以分为关键字,数据类型,运算符,程序控制结构,函数,输入输出这及部分,关键字。
关于C语言的关键字,要懂得各个关键字的用途。
数据类型,要知道其数据类型种类及其存储方式。
运算符,要懂得各种运算符的使用方法,重点是其优先级和结合性。
程序控制结构,要了解语言的顺序结构,条件结构,循环结构。
函数,要了解函数的型参和实参,函数的嵌套调用,函数的递归调用,函数指针,钩子函数,回调函数等概念。
输入输出要了解格式输入输出,字符输入输出,字符串输入输出,文件输入输出。
参考资料:《C语言谭浩强板》
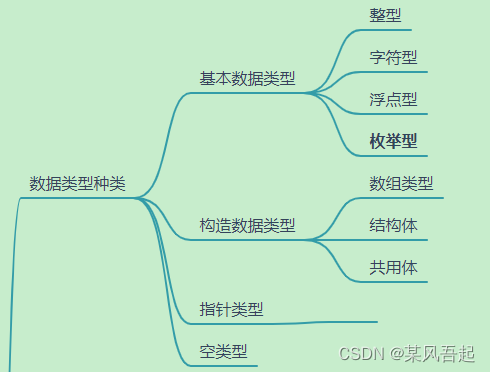
1.数据类型及其存储
一门语言会有它固有的数据类型,如python的字符,字符串,列表,元组等,C语言其也有其固有的数据类型。
C夜有中数据类型细分为基本数据类型,构造数据类型,指针类型,空类型。
基本数据类型具体有整型,实型,字符型,枚举型。
构造数据类型(复合类型)有数组,结构体,联合体。
指针类型内容包括指针的概念,数组指针,函数指针。
1.1 基本数据类型
基本数据类型两大类-常量与变量
基本数据类型中,有常量和变量之分。
常量是在程序运行过程中不变的量,其表示的方式有两种,分别是字面常量,符号常量。
-
字面常量就是直接写出来的数组,字符。

-
符号常量即是通过宏定义定义出来的常量

常量是在程序运行过程中会变的量,变量要用变量名和变量值。
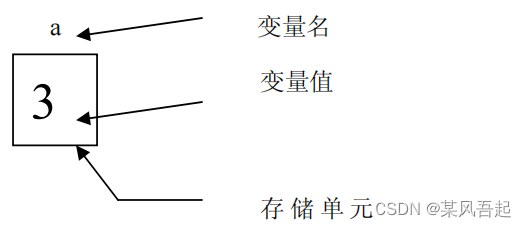
基本数据类型1 - 整型
整性常量的表示方法十进制,八进制,十六进制,后缀有长整型后缀,无符号后缀

整型变量的表示方法int a=0;,存储格式是补码,类型细分有基本型Int, 长整型long int, 无符号整性unsigned int等等。
基本数据类型2 - 实型
存储格式是IEEE754浮点数格式,细分有,单精度浮点数float,双精度浮点数double,长双精度浮点数long double。
实型常量表示方法十进制小数点法,指数法
基本数据类型3 - 字符型
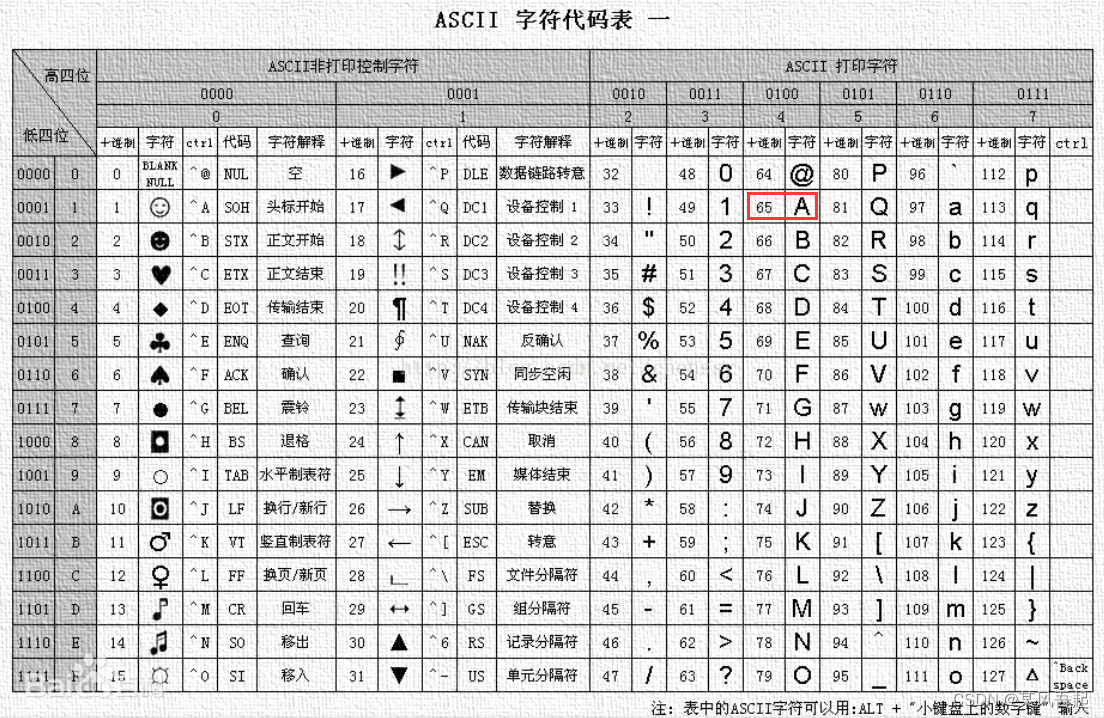
存储格式是ASCII码,可以把字符型理解为只有8bit的整型。
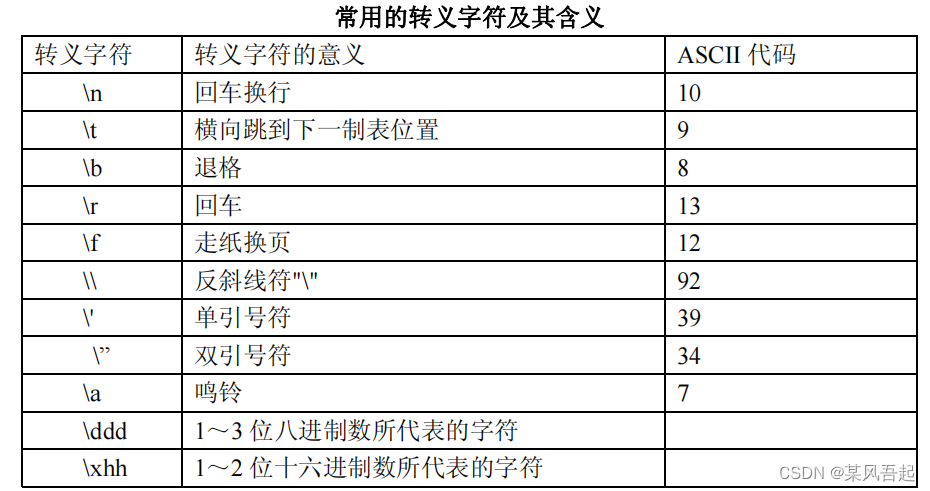
ASCII码中记住十进制的65表示字符'A',一些常用的转移字符
字符串的输入获取
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main() {
char input[1024]; // 假设输入不会超过1023个字符(最后一个字符为'\0')
printf("请输入一行字符串: ");
if (fgets(input, sizeof(input), stdin) != NULL) {
// fgets() 会包含换行符(如果有的话),所以我们可以选择去掉它
input[strcspn(input, "\n")] = 0; // 使用strcspn移除换行符
printf("你输入的是: %s\n", input);
} else {
// 读取错误或EOF
perror("fgets failed");
}
return 0;
}基本数据类型4 - 枚举类型
有些变量的取值被限定在一个有限的范围内,使用枚举类型;
例如一周只有七天,这时可以使用枚举类型定义星期一,星期二...
枚举类型的定义同构造类型的结构体。
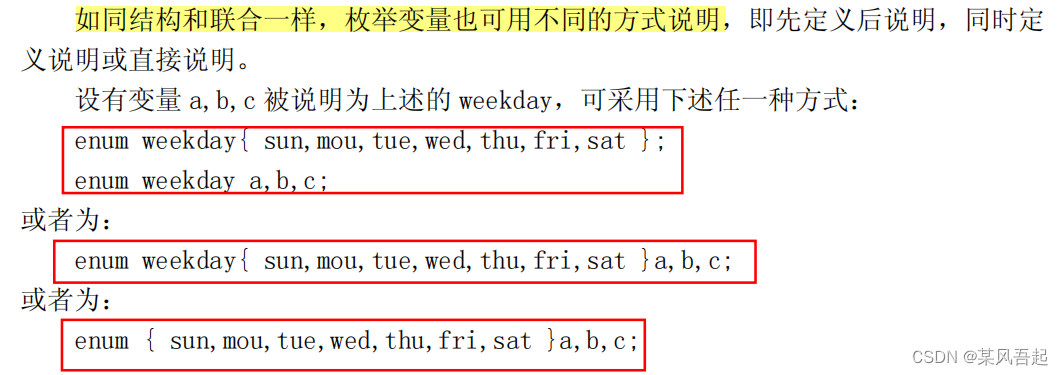
注意点:
枚举值是常量;枚举元素序号从0开始。

数据类型易错点:隐式类型转换
隐式类型转换(Implicit Conversion)是C语言中编译器自动进行的数据类型转换过程,无需程序员显式指定。
- 转换规则一:低字节数据类型向高字节数据类型转换
bool→char→short int→int→unsigned int→long→unsigned long→long long→float→double→long double
(注意:有符号int类型 会被 转换成 无符号int类型)
小试牛刀:根据如下代码,猜测输出的c的值是多少?
#include <stdio.h>
unsigned long Sum(long x, long y)
{
return (x+y);
}
int main(void)
{
unsigned long a = 10;
long b= -15;
long c= 0;
c = Sum(((a+b>0)?a:b), b);
printf("a+b>0:%d\n", a+b > 0);//输出a+b>0:1
printf("c:%d\n", c);//输出c:-5
}二试牛刀
下面代码会输出什么?
cpp
#include <stdio.h>
#include <stdint.h>
#define VALUE_DETECTOR_READ_INITIAL_VALUE (0X8888)
#define VALUE_DETECTOR_READ_FAILD (0X5555)
int main(void)
{
int16_t addr = VALUE_DETECTOR_READ_INITIAL_VALUE;
if (addr == VALUE_DETECTOR_READ_INITIAL_VALUE)
{
printf("==\n");
}
else
{
printf("!=\n");
}
return 0;
}答案:输出`!=
解析
问题在于数据类型不匹配 导致的比较结果不符合预期
VALUE_DETECTOR_READ_INITIAL_VALUE 定义为 0X8888,这是一个 16 位的十六进制值(十进制为 34952)
变量 addr 被声明为 int16_t 类型(有符号 16 位整数)
在有符号 16 位整数的表示范围中:最大值为 0x7FFF(32767)
0x8888 超出了有符号 16 位整数的表示范围,会被解释为负数 (根据补码规则,0x8888 表示 -30576)
因此实际比较的是:if (-30576 == 34952),条件为假,输出!=
1.2 构造数据类型
数组
按序排列的同类数据元素的集合称为数组。
数组注意点:数组声明元素个数时不可以使用变量来声明。

按维度,数组有一维数组,二维数组,多维数组;
按元素数据类型分,分为整型数组,字符数组(字符串)等。
一维数组
初始化注意点:①部分元素初始化,剩余的元素初始化为0
二维数组(用的不多,略)
字符串 ,字符串是一种特殊的一维数组,数组的元素是字符,以'\0'作为字符串结束符。

字符串的处理函数







数组与指针,数组的步进单位
char arr[3][2] = {'a','b', 'c','d','e','f'};
printf("&arr:%p\n", &arr);//&arr表示数组首地址, 061FE1A
printf("&arr+1:%p\n", &arr+1);//&arr步进单位为整个数组,+1即加上数组的大小6,061FE20
printf("arr:%p\n", arr);//arr表示数组首地址, 061FE1A
printf("arr+1:%p\n", arr+1);//arr步进步进单位为一个数组行,+1即加上数组行的大小2,061FE1C
printf("*arr:%p\n", *arr);//061FE1A,*arr等同于arr[0],步进单位为数组元素大小
printf("(*arr)+1:%p\n", *arr+1);//061FE1B,+1即加上数组元素char的大小1
printf("arr[0]:%p\n", arr[0]);//061FE1A,表示一维数组arr[0]的首地址,步进单位为数组元素大小
printf("arr[0]+1:%p\n", arr[0]+1);//061FE1B,+1即加上数组元素char的大小1
printf("&arr[0]:%p\n", &arr[0]);//&arr[0]表示数组第0行首地址, 061FE1A
printf("&arr[0]+1:%p\n", &arr[0]+1);//&arr[0]步进单位为数组行,+1即加上数组行的大小2,061FE1C
printf("&arr[0][0]:%p\n", &arr[0][0]);//&arr[0]表示数组第0行第一列首地址, 061FE1A
printf("&arr[0][0]+1:%p\n", &arr[0][0]+1);//&arr[0]步进单位为一个数组元素,+1即加上数组元素char的大小1,061FE1B
char arr[3][2] = {'a','b', 'c','d','e','f'};
char (*p)[2] = arr;//指向元素个数为2的一维数组的指针,指针步进单位为一维数组大小
printf("p[2]:%p\n", p);//061FE1A
printf("p[2]+1:%p\n", p+1);//061FE1C结构体
结构体的初始化

结构体的字节对齐
结构体的字节对齐遵循以下三个规则:
-
规则一:结构体中元素按照定义顺序依次置于内存中,但并不是紧密排列(默认情况下)。从结构体首地址开始依次将元素放入内存时,元素会被放置在其自身对齐大小的整数倍地址上。
-
规则二:如果结构体大小不是所有元素中最大对齐大小的整数倍,则结构体对齐到最大元素对齐大小的整数倍;"末尾填充" 放在结构体末尾,而 "内部填充" 必须插在不对齐的成员之间。
-
规则三:基本数据类型 的对齐大小为其自身的大小 ;结构体数据类型 的对齐大小为其元素中最大对齐大小元素的对齐大小(嵌套结构体的对齐大小:取嵌套结构体的最大元素对齐大小)。
c++
#include <stdint.h>
// 验证规则一+规则三:元素对齐到自身大小整数倍
struct Test1 {
uint8_t a; // 对齐大小1 → 地址0(1的0倍)
uint32_t b; // 对齐大小4 → 地址4(4的1倍,a后填充3字节)
uint16_t c; // 对齐大小2 → 地址8(2的4倍)
};
// 规则二:总大小=1+3(填充)+4+2=10 → 不是最大对齐大小4的倍数 → 末尾填充2字节 → 最终大小=12
// 验证嵌套结构体(规则三)
struct Test2 {
struct Test1 s; // 对齐大小=Test1的最大元素对齐大小4 → 地址0
uint8_t d; // 对齐大小1 → 地址12
};
// 规则二:总大小=12+1=13 → 不是4的倍数 → 末尾填充3字节 → 最终大小=16
// 验证__packed打破规则(嵌入式重点)
struct __packed Test3 {
uint8_t a; // 地址0(无填充)
uint32_t b; // 地址1(非4字节对齐,打破规则一)
uint16_t c; // 地址5(非2字节对齐)
};
// __packed下规则二/三失效 → 总大小=1+4+2=7,无任何填充联合体(略)
指针类型
指针类型的理解
如下图所示
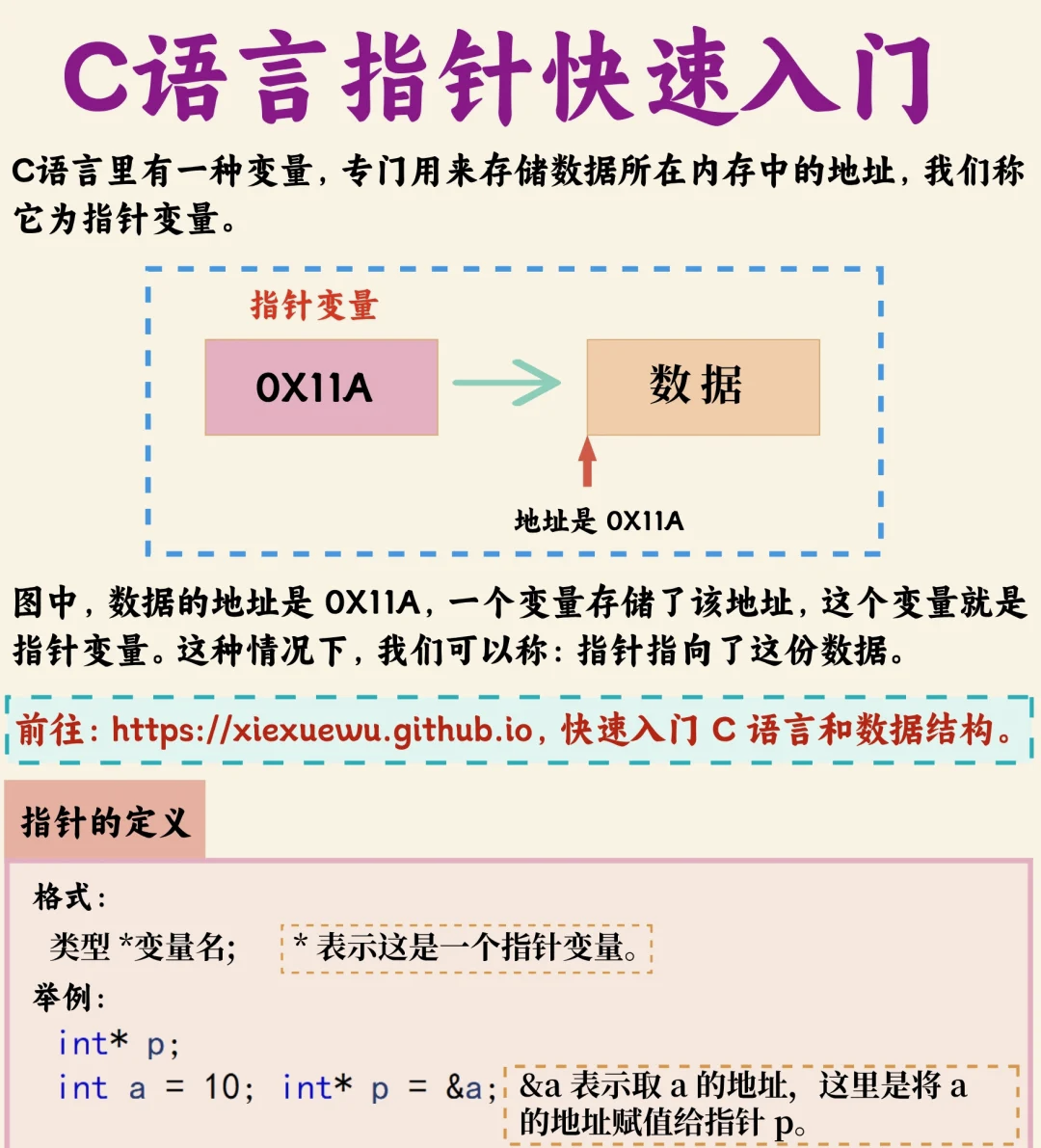
为什么指针类型是属于构造类型?
指针类型是基于其他数据类型(可以是基本类型、构造类型或其他指针类型)衍生出来的,用于表示内存地址,因此被归类为构造类型。
例如:
int*(指向整数的指针)依赖于int类型
char**(指向字符指针的指针)依赖于char*类型
变量指针
在 C 语言中,"变量指针" 通常指的是指向变量的指针,即一个存储了某个变量内存地址的指针变量。
cpp
int a = 10; // 定义一个int类型变量a,值为10
int* p = &a; // 定义指针p,存储变量a的地址(&是取地址符)这里的 p 就是变量 a 的指针,因为 p 中存放的是 a 在内存中的地址。通过 *p(解引用操作)可以访问或修改 a 的值,例如 *p = 20; 会将 a 的值改为 20。
函数指针
函数指针的定义

示例
cpp
#include <stdio.h>
// 普通函数:计算两数之和
int add(int a, int b) {
return a + b;
}
// 普通函数:计算两数之积
int multiply(int a, int b) {
return a * b;
}
int main() {
// 1. 定义函数指针,指向"返回int、接收两个int参数"的函数
int (*func_ptr)(int, int);
// 2. 赋值:指向add函数(函数名即函数的入口地址)
func_ptr = add;
// 3. 调用:两种等价方式
int result1 = func_ptr(3, 4); // 方式1:通过指针调用
int result2 = (*func_ptr)(5, 6); // 方式2:显式解引用(兼容早期C语法)
printf("add结果:%d, %d\n", result1, result2); // 输出:7, 11
// 4. 切换指向multiply函数
func_ptr = multiply;
int result3 = func_ptr(3, 4);
printf("multiply结果:%d\n", result3); // 输出:12
return 0;
}复杂的函数指针可以用 typedef 简化,提高可读性:
cpp
// 定义一个函数指针类型 FuncPtr,指向"返回int、接收两个int参数"的函数
typedef int (*FuncPtr)(int, int);
// 使用该类型定义指针变量
FuncPtr ptr;
ptr = add; // 等价于之前的定义
printf("%d\n", ptr(2, 3)); // 输出:5数组名与指针
uint8_t data[](数组声明)- 含义:声明了一个固定大小的数组,data 是数组名。
- 内存分配:
数组内存在声明处分配(栈/全局区)。
大小在编译时确定(显式指定或通过初始化推断)。 - 关键特性:
sizeof(data)返回 整个数组的字节大小 (元素数 × sizeof(uint8_t))
data 是常量指针,不可重新赋值(如 data = other; 非法)。
内存生命周期由作用域决定(自动或静态)。
cpp
uint8_t data[5] = {1, 2, 3, 4, 5};
// sizeof(data) == 5 * 1 = 5-
uint8_t* data(指针声明)- 含义:声明了一个指向 uint8_t 的指针。
- 内存分配:
指针变量本身占用固定大小(4/8字节),不包含数据内存。
数据内存需额外分配(动态/静态/栈数组地址)。 - 关键特性:
sizeof(data) 返回 指针本身的大小(通常 4 或 8 字节)。
可重新赋值指向其他内存(如 data = other_buffer;)。
可通过 malloc/new 动态管理内存(需手动释放)。
-
函数形参中的
uint8_t data[]和uint8_t* data的含义
在函数参数中,两者等价(数组退化为指针):
cpp
void func1(uint8_t data[]); // 实际视为 uint8_t* data
void func2(uint8_t* data); // 与 func1 完全相同此时:
数组语法仅为提示"期望数组",实际传递指针。
sizeof(data) 在函数内返回指针大小(非数组大小)。
数组名与指针的关系:步进单位,指向多维数组的指针int (*p)[4]

指针的应用
字符串复制函数

cprstr (char *pss,char *pds)
{while (*pdss++=*pss++);}//++与*的优先级一样,单目运算符号,右结合,*pss++相当于*(pss++)指针的运算
思考:有三种类型的指针:uint32 *, uint16 *, uint8 *,把这三种类型的指针都+1,它们的值是什么 ?
cpp
#include <stdio.h>
#include <stdint.h>
int main(void)
{
uint32_t num_uint32 = 0;
uint32_t* p_uint32 = 0;
uint16_t* p_uint16 = 0;
uint8_t* p_uint8 = 0;
printf("num_uint32 + 1 = %p\n", num_uint32 + 1);
printf("p_int + 1 = %p\n", p_uint32 + 1);
printf("p_int + 1 = %p\n", p_uint16 + 1);
printf("p_int + 1 = %p\n", p_uint8 + 1);
return 0;
}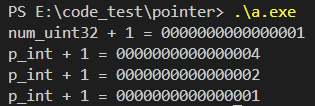
结论:指针+1是 加上 该指针的数据类型的大小的值
大小端模式
参考文章:大小端

BOOL IsBigEndian()
{
int a = 0x1234;
char b = *(char *)&a; //通过将int强制类型转换成char单字节,通过判断起始存储位置。即等于 取b等于a的低地址部分
if( b == 0x12)
{
return TRUE;
}
return FALSE;
}联合体union的存放顺序是所有成员都从低地址开始存放,利用该特性可以轻松地获得了CPU对内存采用Little-endian还是Big-endian模式读写:
BOOL IsBigEndian()
{
union NUM
{
int a;
char b;
}num;
num.a = 0x1234;
if( num.b == 0x12 )
{
return TRUE;
}
return FALSE;
}注意:C语言中,对数字的 位与&,位或| 运算,不需要考虑大小端问题 。(因为编译器在从内存读取到数据时,已经根据其大小端存储方式,把数据转换成了对应的数值)
eg:short num = 0x1234;,char num2 = (num &0xff00) >> 8,此时printf("%#x", num2)会打印0x12
只是在写内存时需要注意大小端的问题:
若是大端存储方式,则将数值为0x1234的变量写入内存0x20000000后,该内存值就是12 34,因为数值为0x1234的变量在内存的存储形式是12 34;
若是小端存储方式,则将数值为0x1234的变量写入内存0x20000000后,该内存值就是34 12,因为数值为0x1234的变量在内存的存储形式是34 12;。
STM32是小端模式 。

类型转换
c
1.强转类型
uint16_t a = 0xfeff;
uint8_t b = (uint8_t)a>>8; //b = 0x00 why????
b = a>>8; //b = 0xfe why????
//第二条语句,因为会先执行(uint8_t)a,强转成了0xff,然后再右移8bit,故b=0
//第三条语句,正常逻辑2.运算符
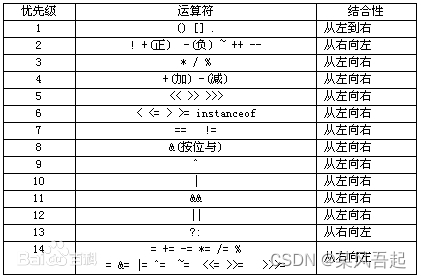
在嵌入式中,会经常使用到位运算符,要知晓其优先级高低,
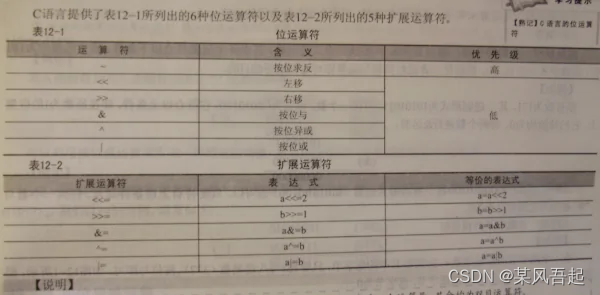
关系运算符>, >=, <, <=, !=, ==的优先级大于 逻辑运算符&&, ||
3. 函数
函数的调用方式
常用库函数
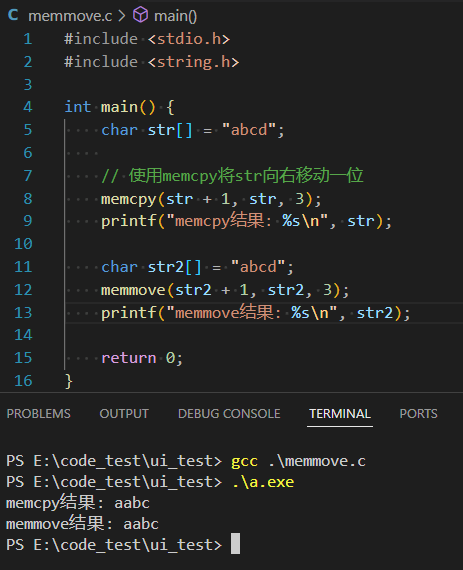
字符串操作函数 memcpy 注意点
在以前的库函数中(新版的库函数没这个问题了),memcpy在处理特定内存重叠情况时确实会产生错误结果,下面是一个典型的出错示例:
当目标地址在源地址之后且存在内存重叠时,memcpy的正向拷贝会导致数据被错误覆盖。考虑将字符串"abcd"向右移动一位的情况
cpp
#include <stdio.h>
#include <string.h>
int main() {
char str[] = "abcd";
// 使用memcpy将str向右移动一位
memcpy(str + 1, str, 3);
printf("结果: %s\n", str);
return 0;
}预期结果应该是"aabcd",但实际运行得到的结果却是"aaaad"
错误原因分析:
- 第一次拷贝:str1 = str0 → 得到"a"(正确)
- 第二次拷贝:str2 = str1 → 此时str1已经是'a',得到"aa"(错误开始)
- 第三次拷贝:str3 = str2 → 此时str2也是'a',得到"aaa"(完全错误)
这是因为memcpy采用从前往后的正向拷贝顺序,在拷贝过程中源数据区域已经被修改,导致后续拷贝使用了错误的数据
正确解决方案:
使用memmove函数可以正确处理这种情况,因为memmove会检测到目标地址在源地址之后,自动采用从后往前的拷贝顺序。
(注意,新版的库函数中memcpy已经不会出现这个问题了)
断言de
bug函数:assert()
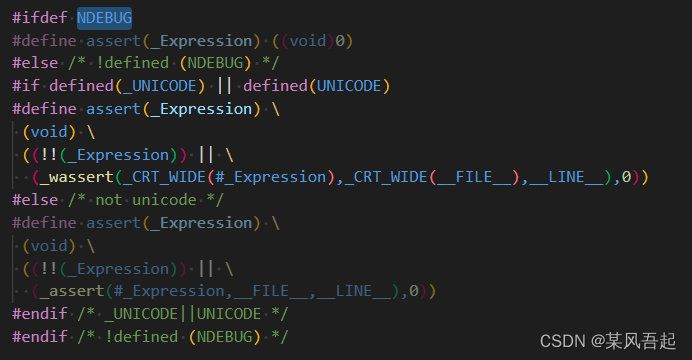
assert宏的原型定义在<assert.h>中,其作用是如果它的条件返回错误,则终止程序执行,原型定义:
#include <assert.h>
void assert( int expression );
assert的作用是先计算表达式expression,如果其值为假(即为0),那么它先向标准错误流stderr打印一条出错信息 ,然后通过调用abort来终止程序运行;否则,assert()无任何作用。宏assert()一般用于确认程序的正常操作,其中表达式构造无错时才为真值。
完成调试后,不必从源代码中删除assert()语句,因为宏NDEBUG 有定义时,宏assert()的定义为空。注意:#define NDEBUG必须在include <assert.h>前定义。
弱函数
注意兼容性:__attribute__((weak))是GCC/Clang扩展,非标准C语法
实现如下,在函数名称前面添加__attribute__((weak))关键字,即表示该函数是弱函数
cpp
//weak_func.c
#include <stdio.h>
// 声明弱函数(默认实现)
__attribute__((weak)) void weak_func(void)
{
printf("Default weak function\n");
}
void test_weak_func(void)
{
weak_func();
}
cpp
//main.c
#include <stdio.h>
// void weak_func(void)
// {
// printf("weak func!!!!!!!!\n");
// }
int main(void)
{
extern void test_weak_func(void);
test_weak_func();//通过注释 或 取消注释 上方的 weak_func() 来测试使用弱函数
return 0;
}注意:可以同时存在多个同名的弱函数,最终调用哪个是根据链接的先后顺序来决定的
4.控制语句(for, while, if)
循环
while循环与for循环的等价
cpp
while(condition)
{
loopbody();
}
//等价于:
for(;condition;)
{
loopbody();
}
for(initial();condition;operation())
{
loopbody();
}
//等价于:
initial();
while(condition)
{
loopbody();
operation();
}注意:
虽然while循环和for循环有如上等价关系,但是两者的continue是不同的。
for循环在执行continue时,会隐藏执行operation()
如下例子所示
cpp
int i;
//下面循环会打印:0 1 2 3 4 6 7 8 9
for (i = 0; i < 10; i++) {
if (i == 5)
continue;
printf("%d ", i);
}
//下面循环只会打印:0 1 2 3 4
//并且卡住在循环中
i = 0;
while (i < 10) {
if (i == 5)
continue;
printf("%d ", i);
i++;
}所以我们可以使用for来说操作链表
c
typdef struct m_node {
int data;
struct m_node *next;
}m_node_s;
int main()
{
m_node_s header;
m_node_s *p = header.next;
//下面的for语句会先判断 p != NULL,如果满足则进入到循环中执行 do something...
for (; p != NULL; p = p->next) {
//do something...
}
return 0;
} 数据的输入
获取输入的一行字符串,包括空格
c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main() {
char input[1024]; // 假设输入不会超过1023个字符(最后一个字符为'\0')
printf("请输入一行字符串: ");
if (fgets(input, sizeof(input), stdin) != NULL) {
// fgets() 会包含换行符(如果有的话),所以我们可以选择去掉它
input[strcspn(input, "\n")] = 0; // 使用strcspn移除换行符
printf("你输入的是: %s\n", input);
} else {
// 读取错误或EOF
perror("fgets failed");
}
return 0;
}获取输入的一个数字,以回车作为结尾
#include <stdio.h>
int main()
{
int num;
int array[500] = {0};
scanf("%d", &num);
printf("num:%d\n", num);
int i = 0;
while(i < num) {
scanf("%d", array+i);
i++;
}
for (i = 0; i < num; i++) {
printf("%d ", array[i]);
}
}