文章目录
一、CNN:空间特征的局部感知器
1.核心底层原理
CNN的核心设计哲学是局部连接+参数共享,这源于图像等数据具有"局部相关性"(邻近像素更相关,远处像素相关性弱)。
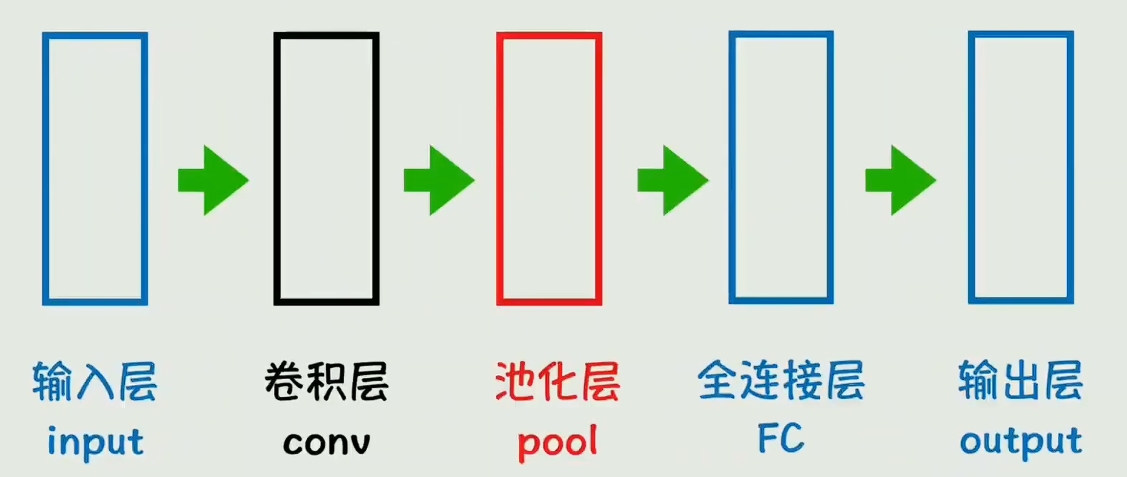
- 输入层:接收原始数据,比如一张图片的像素值(3×224×224)或一句话的词向量(长度×维度)
- 卷积层:用一个小卷积核(比如3×3)在输入上滑动,每次做点积运算,提取局部特征,比如边缘、纹理、颜色变化(对于文本就是n-gram组合)
- 池化层:下采样,比如取2×2区域里的最大值或平均值,把特征图缩小,最终得到降维后的特征图,保留了主要特征,去掉了冗余细节
- 全连接层:把前面提取到的高层特征"展平"后,通过全连接网络映射到具体的类别或数值,最终得到一个特征向量,里面包含了分类所需的信息
- 输出层:根据任务输出结果(softmax分类、线性回归等)
优点:
- 并行计算:每个卷积核独立计算
- 参数共享:参数量与输入尺寸解耦
- 平移不变性:模式出现在任何位置都能检测
缺点:
- 感受野受限:需要堆叠多层才能覆盖远距离依赖
- 不擅长建模长距离依赖:本质是局部操作
- 对序列顺序不敏感:需额外位置编码
- 处理变长输入需池化或全局池化
典型应用:图像分类、目标检测、OCR、短文本分类(n-gram特征)
二、RNN:循环神经网络
CNN只看局部,没法记住"之前看过什么"。而处理语言、语音、时间序列时,顺序和记忆特别重要。RNN通过一个叫隐藏状态的小本本,把之前看到的信息记下来,然后传给下一步。
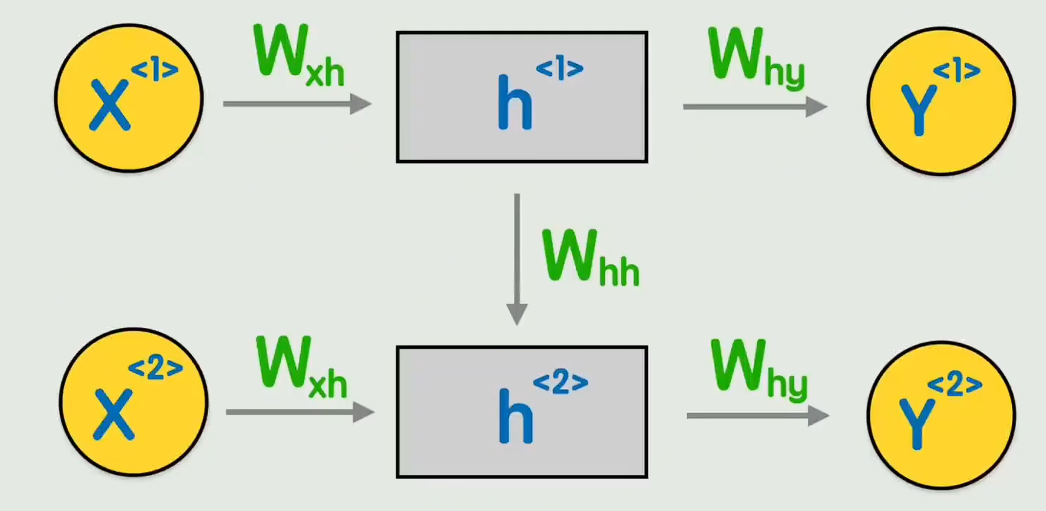
RNN通过隐藏状态在序列中传递信息,每个时间步的输出依赖于前一个时间步的隐藏状态,隐藏状态 ht 是一个向量,它是从第1个时间步到第 t 个时间步的所有输入信息的压缩表示。每个时间步的隐藏状态既用于输出,也传递给下一个时间步。
前向传播过程如下,
- 第一个词 x1 与权重矩阵 Wxh 相乘,得到隐藏状态 h1;h1 与 Why
相乘得到输出 y1; - 第二个词 x2 拼接 h1后,与 Wxh和额外的 Whh 共同作用,得到 h2;h 2与 Why 相乘得到 y2
- 后续同理
优点
- 天然适合处理可变长度的序列(不需要固定输入长度)
- 理论上可以捕捉任意长的依赖(只要隐藏状态足够大)
- 参数在不同时间步共享,模型大小与序列长度无关
缺点:
- 无法捕捉长期依赖:句子太长时,离得远的词之间的关联会丢失(因为梯度消失)
- 无法并行计算:必须一个词一个词地算,GPU的优势发挥不出来
- 训练困难:容易出现梯度爆炸或梯度消失,需要LSTM、GRU等变体来缓解
三、Transformer
Transformer的核心武器是注意力机制。它不再像RNN那样一步一步往后传,而是让序列里的每个词直接跟所有词"对视"一眼,然后根据重要程度聚合信息。
给定查询 Q、键 K、值 V,注意力输出为
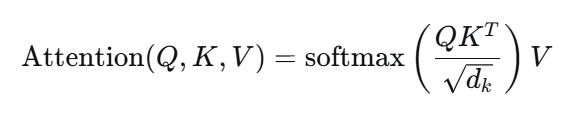
1.单头注意力机制
- 给词向量添加位置信息 :因为注意力本身不看顺序。所以我们需要给每个词加上一个"位置编号",叫位置编码。
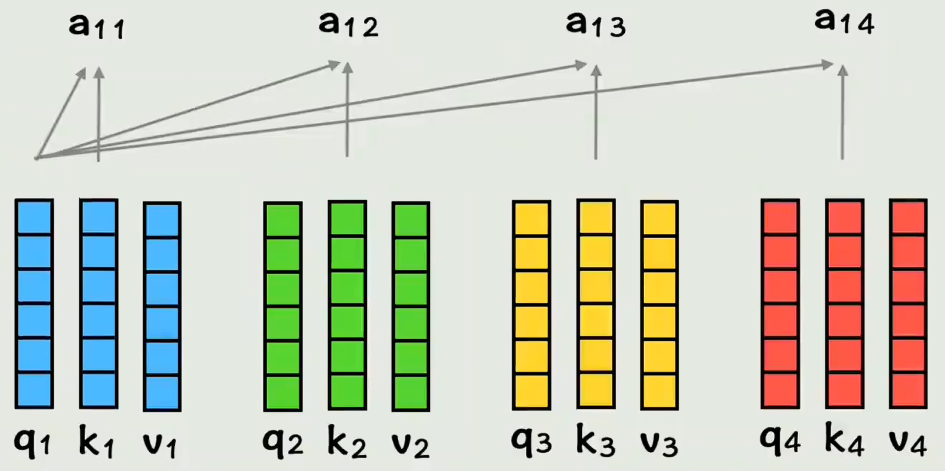
做法很简单:词向量 + 位置编码向量,得到新的输入。 - 把每个词变成三个角色:Q、K、V:输入序列 X 通过三个不同的权重矩阵 WQ,WK,WV映射到三个空间,每一行对应一个位置的向量(q1, k1, v1 表示第1个位置的query, key, value)
- 计算相似度 :拿第一个词的 q1 去和所有词的 k1、k2、k3、k4 做点积,得到分数
- a11表示在词1视角下,自己和自己的相似度
- a12表示在q1视角下,词1和词2的相似度
- a13表示在q1视角下,词1和词3的相似度
- a14表示在q1视角下,词1和词4的相似度
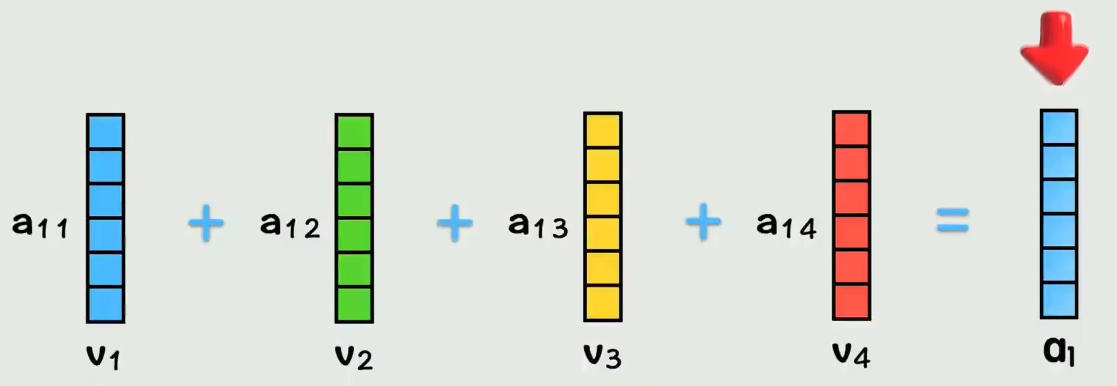
- 归一化并加权求和:把这些分数通过 softmax 变成概率(加起来等于1),然后用这个概率作为权重,去乘每个词的 v 向量,最后全部加起来。
- 最终得到的向量 = 原来的位置信息 + 从所有词那里吸收来的上下文信息。
2.多头注意力机制
刚才我们只用了一组 Q、K、V,相当于只从一个角度看句子。
多头注意力就是多用几组不同的权重,生成多组 Q、K、V(比如 8 组),每组独立计算注意力,得到 8 个不同的结果。
然后把这 8 个结果拼接在一起,再经过一层线性变换,得到最终的输出。
这个多组qkv得到多组向量,将向量进行拼接
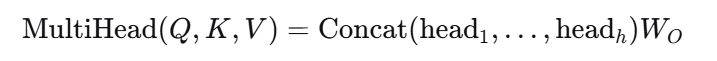
每个 headi 都是一个Attention
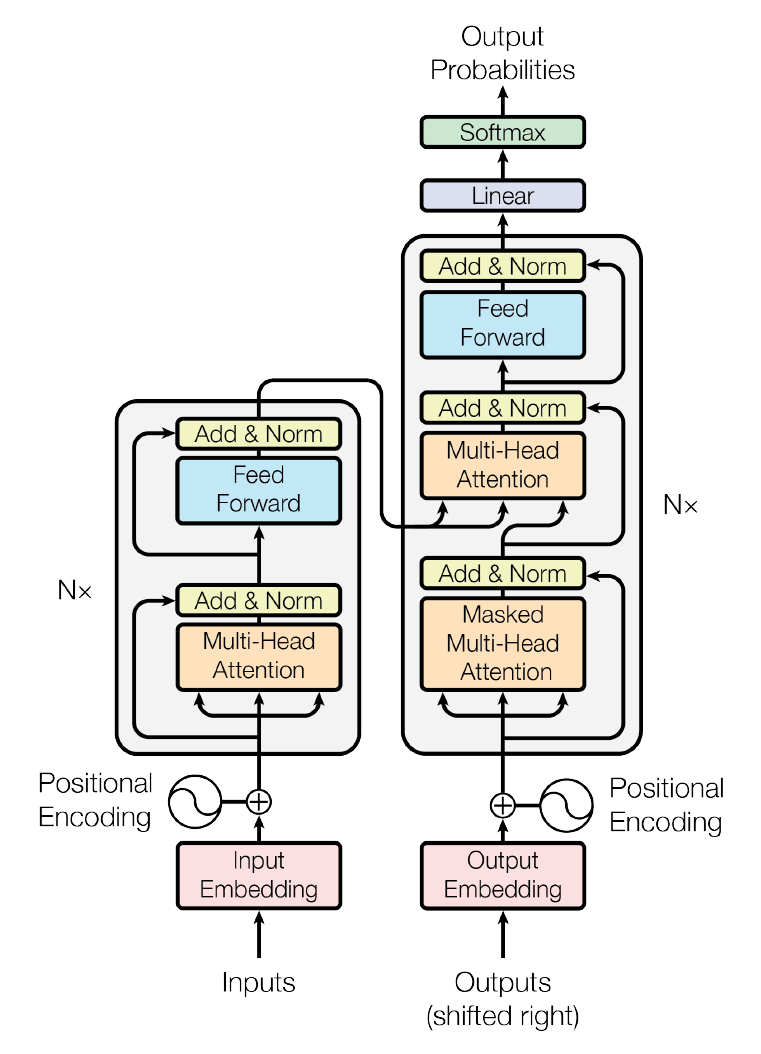
3.Transformer架构
如下图,左边的是编码器,右遍的是解码器,其过程如下,
-
编码器(负责"读懂"输入)
- 先添加位置信息,把位置编码加到词向量上
- 多头注意力:让每个词看到整个句子,吸收上下文
- 残差 + 归一化:把注意力输出和原始输入相加(残差),再做归一化(稳定训练)
- 前馈网络(全连接层):进一步加工每个词的特征
- 残差 + 归一化:再次相加和归一化
- 将编码器的最终输出传给解码器,供解码器"查阅"
-
解码器(负责"生成"输出,比如翻译后的句子)
- 添加位置信息:同样给目标句子(训练时)加位置编码
- 带掩码的多头注意力:因为生成时不能"偷看"未来的词(比如生成第2个词时,不能看到第3个词),所以用掩码把未来位置的注意力分数变成负无穷,softmax后权重为0
- 残差 + 归一化
- 第二个多头注意力:它的 Q 来自解码器自身(经过掩码后的结果),K 和 V 来自编码器的输出。也就是说解码器当前要生成的词,去编码器的输出里找最相关的信息。
- 残差 + 归一化
- 前馈网络(全连接层)
- 残差 + 归一化
- 线性变换:把输出向量映射到词表大小(比如 5 万个词)
- Softmax:转换成概率,概率最大的词就是预测的下一个词