文章目录
前言
上篇我们介绍了删除法、均值填充和中位数填充,适合快速处理简单缺失问题。
本篇将带来三种更"智能"的填充方式:众数填充(分组模式)、线性回归预测填充和随机森林预测填充。
它们能更好地利用数据内在关系,尤其适合缺失值较多或特征关联性强的场景。
一、方法4:分组众数填充
这个方法主旨是用整列中出现次数最多的值填补缺失。
在本次案例按标签(矿物类型)分组,在每组内分别用该组的众数填充。
c
def mode_method(data):
fill_values = data.mode()
return data.fillna(fill_values.iloc[0])
def mode_train_fill(train_data,train_label):
data = pd.concat([train_data,train_label],axis=1)
data = data.reset_index(drop=True)
A = data[data['矿物类型'] == 0]
B = data[data['矿物类型'] == 1]
C = data[data['矿物类型'] == 2]
D = data[data['矿物类型'] == 3]
A = mode_method(A)
B = mode_method(B)
C = mode_method(C)
D = mode_method(D)
df_filled = pd.concat([A,B,C,D])
df_filled = df_filled.reset_index(drop=True)
return df_filled.drop('矿物类型',axis=1),df_filled.矿物类型
def mode_teat_meyhod(train_data,test_data):
fill_values = train_data.mode()
return test_data.fillna(fill_values.iloc[0])
def mode_teat_fill(train_data,train_label,test_data,test_label):
train_data_all = pd.concat([train_data,train_label],axis=1)
train_data_all = train_data_all.reset_index(drop=True)
test_data_all = pd.concat([test_data,test_label],axis=1)
test_data_all = test_data_all.reset_index(drop=True)
A_train = train_data_all[train_data_all['矿物类型'] == 0]
B_train = train_data_all[train_data_all['矿物类型'] == 1]
C_train = train_data_all[train_data_all['矿物类型'] == 2]
D_train = train_data_all[train_data_all['矿物类型'] == 3]
A_test = test_data_all[test_data_all['矿物类型'] == 0]
B_test = test_data_all[test_data_all['矿物类型'] == 1]
C_test = test_data_all[test_data_all['矿物类型'] == 2]
D_test = test_data_all[test_data_all['矿物类型'] == 3]
A = mode_teat_meyhod(A_train, A_test)
B = mode_teat_meyhod(B_train, B_test)
C = mode_teat_meyhod(C_train, C_test)
D = mode_teat_meyhod(D_train, D_test)
df_filled = pd.concat([A,B,C,D])
df_filled = df_filled.reset_index(drop=True)
return df_filled.drop('矿物类型',axis=1),df_filled.矿物类型代码详解
训练集
首先我么写入一个计算众数的函数,他会帮我们统计在这一列中出现次数最多的数。
同时我们应该考虑到相同数量的数可能不止一个,所以.iloc0会帮助我们选择第一个数作为众数。
c
def mode_method(data):
fill_values = data.mode()
return data.fillna(fill_values.iloc[0])导入训练集的标签和特征,合并并且排列。
c
def mode_train_fill(train_data,train_label):
data = pd.concat([train_data,train_label],axis=1)
data = data.reset_index(drop=True)单独提取出各个种类的数据,同时每个种类的数据单独查询众数。
c
A = data[data['矿物类型'] == 0]
B = data[data['矿物类型'] == 1]
C = data[data['矿物类型'] == 2]
D = data[data['矿物类型'] == 3]
A = mode_method(A)
B = mode_method(B)
C = mode_method(C)
D = mode_method(D)将填充好的A,B,C,D数据合并为一个数据,再切分为特征和标签。
c
df_filled = pd.concat([A,B,C,D])
df_filled = df_filled.reset_index(drop=True)
return df_filled.drop('矿物类型',axis=1),df_filled.矿物类型测试集
测试集的处理和训练集没什么两样,只是填充测试集空缺值是由训练集提供,所以处理测试集数据的时候需要将训练集的数据一起导入。
c
def mode_teat_meyhod(train_data,test_data):
fill_values = train_data.mode()
return test_data.fillna(fill_values.iloc[0])导入训练集的特征和标签,合并并且排序
导入测试集的特征和标签,合并并且排序
c
def mode_teat_fill(train_data,train_label,test_data,test_label):
train_data_all = pd.concat([train_data,train_label],axis=1)
train_data_all = train_data_all.reset_index(drop=True)
test_data_all = pd.concat([test_data,test_label],axis=1)
test_data_all = test_data_all.reset_index(drop=True)将各个类型的训练集数据分割,再将测试集的数据分割开
再将相对应的训练数据和测试数据同时导入计算众数的函数中。
这样就可以将训练集的众数填充到测试集的空缺上了。
c
A_train = train_data_all[train_data_all['矿物类型'] == 0]
B_train = train_data_all[train_data_all['矿物类型'] == 1]
C_train = train_data_all[train_data_all['矿物类型'] == 2]
D_train = train_data_all[train_data_all['矿物类型'] == 3]
A_test = test_data_all[test_data_all['矿物类型'] == 0]
B_test = test_data_all[test_data_all['矿物类型'] == 1]
C_test = test_data_all[test_data_all['矿物类型'] == 2]
D_test = test_data_all[test_data_all['矿物类型'] == 3]
A = mode_teat_meyhod(A_train, A_test)
B = mode_teat_meyhod(B_train, B_test)
C = mode_teat_meyhod(C_train, C_test)
D = mode_teat_meyhod(D_train, D_test)将填充好的A,B,C,D数据合并为一个数据,再切分为特征和标签。
c
df_filled = pd.concat([A,B,C,D])
df_filled = df_filled.reset_index(drop=True)
return df_filled.drop('矿物类型',axis=1),df_filled.矿物类型二、方法5:线性回归预测填充
使用线性回归填充训练数据集中的缺失值,主要是基于这样一个思想:特征和目标变量之间行在一定的关系,因此可以利用这种关系对缺失的特征进行预测。
具体遵循以下步骤就可以实现使用逻辑回归对数据预处理。
-
首先,确定哪些特征包含缺失值
-
对于包含缺失值的特征,将其作为目标变量,而其他特征(可以包括原始的目标变量)作为输入特征。注意,如果多个特征都有缺失值通常建议按照缺失值的数量从小到大进行处理。因为缺失值较少的特征对预测的要求较低,准确性可能更高。
-
在处理某个特征的缺大值时,将该特征中的已知值(即非缺失值)作为训练集,而缺失值作为需要预测的目标。此时,其他特征的相应值作为输入特征。
-
使用线性回归模型进行训练,并对缺失值进行预测。
-
将预测得到的值填充到原始数据中的相应位置。
-
重复上述步骤,直到处理完所有包含缺失值的特征。
c
def lr_train_fill(train_data,train_label):
train_data_all = pd.concat([train_data,train_label],axis=1)
train_data_all = train_data_all.reset_index(drop=True)
train_data_X = train_data_all.drop('矿物类型',axis=1)
null_num = train_data_X.isnull().sum()
null_num_sorted = null_num.sort_values(ascending=True)
filling_feature =[]
for i in null_num_sorted.index:
filling_feature.append(i)
if null_num_sorted[i]!=0:
X = train_data_X[filling_feature].drop(i,axis=1)
y = train_data_X[i]
row_number_mg_null = train_data_X[train_data_X[i].isnull()].index.tolist()
X_train = X.drop(row_number_mg_null)
y_train = y.drop(row_number_mg_null)
X_test = X.iloc[row_number_mg_null]
regr = LinearRegression()
regr.fit(X_train,y_train)
y_pred = regr.predict(X_test)
train_data_X.loc[row_number_mg_null,i] = y_pred
print('完成训练集中的{}列数据的填充'.format(i))
return train_data_X,train_data_all.矿物类型
def lr_test_fill(train_data,train_label,test_data,test_label):
train_data_all = pd.concat([train_data,train_label],axis=1)
train_data_all = train_data_all.reset_index(drop=True)
test_data_all = pd.concat([test_data,test_label],axis=1)
test_data_all = test_data_all.reset_index(drop=True)
train_data_X = train_data_all.drop('矿物类型',axis=1)
test_data_X = test_data_all.drop('矿物类型',axis=1)
null_num = test_data_X.isnull().sum()
null_num_sorted = null_num.sort_values(ascending=True)
filling_feature =[]
for i in null_num_sorted.index:
filling_feature.append(i)
if null_num_sorted[i]!=0:
X_train = train_data_X[filling_feature].drop(i,axis=1)
y_train = train_data_X[i]
X_test = test_data_X[filling_feature].drop(i,axis=1)
y_test = test_data_X[i]
row_number_mg_null = test_data_X[test_data_X[i].isnull()].index.tolist()
X_train = X_train.dropna()
y_train = y_train.dropna()
X_pred = X_test.iloc[row_number_mg_null]
regr = LinearRegression()
regr.fit(X_train,y_train)
y_pred = regr.predict(X_pred)
test_data_X.loc[row_number_mg_null,i] = y_pred
print('完成测试集中的{}列数据的填充'.format(i))
return test_data_X,test_data_all.矿物类型代码详解
训练集
首先导入训练集的特征和标签。
将标签和特征合并并排序,得到一张完整的表。
在表中将'矿物类型'那一列单独提取出来,赋值给train_data_X,此时表中是没有'矿物类型'这一列的
将每一列有多少个缺失值记录在一个新表中,表名为null_num
最后进行升序(从小到大)排列,是为了哪些列没有缺失,哪些列缺失严重
c
def lr_train_fill(train_data,train_label):
train_data_all = pd.concat([train_data,train_label],axis=1)
train_data_all = train_data_all.reset_index(drop=True)
train_data_X = train_data_all.drop('矿物类型',axis=1)
null_num = train_data_X.isnull().sum()
null_num_sorted = null_num.sort_values(ascending=True)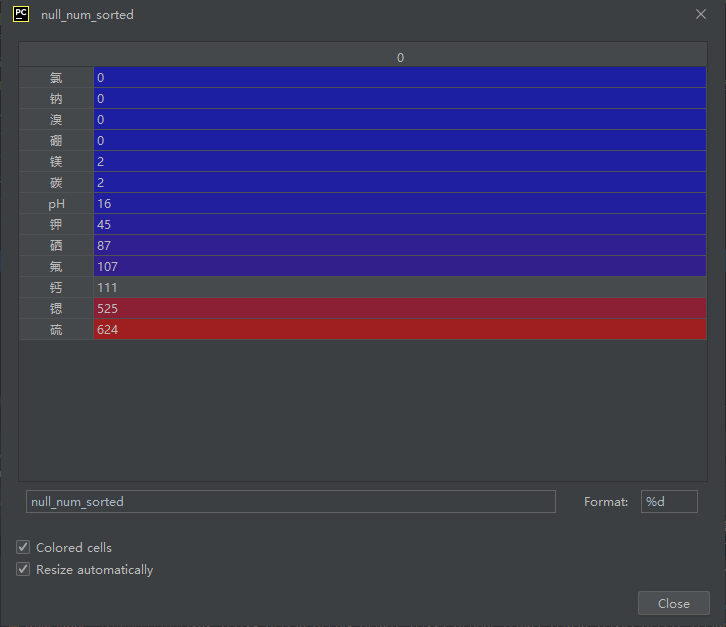
可以看到前四个元素的缺失值为零,所以会先作为线性回归的训练集,将有空缺值的数据作为测试集进行测试,然后将得到数据填充到空缺的位置上。
填充好之后我们就又得到一列完整的数据,数据集将会扩大,以扩大的数据集作为新的训练集,对下一个有空缺的数据进行逻辑回归运算,如此反复,我们就可以将传入的空缺的训练集数据修复到完整。
建立一个for 循环遍历语句,每次循环的时候又会进行一次if判断,判断当前的数据缺失值是否为0。
为0,则没有缺失的列直接跳过,不用处理
不为0,进入下面的填充逻辑
c
filling_feature =[]
for i in null_num_sorted.index:
filling_feature.append(i)
if null_num_sorted[i]!=0:
X = train_data_X[filling_feature].drop(i,axis=1)
y = train_data_X[i]将有缺失值的行号提取出来,转换为列表。
在准备好的用于预测的特征数据中删掉缺失值所在的行,最终X_train = 没有缺失、干净的特征训练集(只保留有完整数据的行,用来训练模型)
同样y为当前要填充的目标列,y_train = 干净、完整的目标值训练标签
提取缺失值所在的行赋值给X_test ,后面就是对X_test 进行预测。
创建一个线性回归模型,用X_train和y_train训练模型。
训练完成后将X_test 输入模型进行预测,预测的结果为y_pred
最后把预测好的y_pred直接填入空缺的位置。
c
row_number_mg_null = train_data_X[train_data_X[i].isnull()].index.tolist()
X_train = X.drop(row_number_mg_null)
y_train = y.drop(row_number_mg_null)
X_test = X.iloc[row_number_mg_null]
regr = LinearRegression()
regr.fit(X_train,y_train)
y_pred = regr.predict(X_test)
train_data_X.loc[row_number_mg_null,i] = y_pred
print('完成训练集中的{}列数据的填充'.format(i))
return train_data_X,train_data_all.矿物类型测试集
同样的,我们需要将训练集的数据填充到测试集中。
可以理解为,在逻辑回归这个模型中,训练集数据作为训练集训练模型,测试集的数据输入模型,返回的值,填充到测试集中空缺的位置。
c
def lr_test_fill(train_data,train_label,test_data,test_label):
train_data_all = pd.concat([train_data,train_label],axis=1)
train_data_all = train_data_all.reset_index(drop=True)
test_data_all = pd.concat([test_data,test_label],axis=1)
test_data_all = test_data_all.reset_index(drop=True)
train_data_X = train_data_all.drop('矿物类型',axis=1)
test_data_X = test_data_all.drop('矿物类型',axis=1)
null_num = test_data_X.isnull().sum()
null_num_sorted = null_num.sort_values(ascending=True)在本段代码上,用来填充空缺地方的数据使用的是训练集h的数据,但是同时要注意的是,使用训练集的到数据的时候,要将训练集的空值删除,避免训练集对测试集有影响
c
filling_feature =[]
for i in null_num_sorted.index:
filling_feature.append(i)
if null_num_sorted[i]!=0:
X_train = train_data_X[filling_feature].drop(i,axis=1)
y_train = train_data_X[i]
X_test = test_data_X[filling_feature].drop(i,axis=1)
y_test = test_data_X[i]
row_number_mg_null = test_data_X[test_data_X[i].isnull()].index.tolist()
X_train = X_train.dropna()
y_train = y_train.dropna()
X_pred = X_test.iloc[row_number_mg_null]
regr = LinearRegression()
regr.fit(X_train,y_train)
y_pred = regr.predict(X_pred)
test_data_X.loc[row_number_mg_null,i] = y_pred
print('完成测试集中的{}列数据的填充'.format(i))
return test_data_X,test_data_all.矿物类型三、方法6:使用随机森林填充
本质上是和使用逻辑回归填充空缺一个思路,不同的是,我们要将代码里面的模型从逻辑回归替换成随机森林。
除此以外没什么不同。
c
import pandas as pd
from sklearn.ensemble import RandomForestRegressor # 换成随机森林
def rf_train_fill(train_data,train_label):
train_data_all = pd.concat([train_data,train_label],axis=1)
train_data_all = train_data_all.reset_index(drop=True)
train_data_X = train_data_all.drop('矿物类型',axis=1)
null_num = train_data_X.isnull().sum()
null_num_sorted = null_num.sort_values(ascending=True)
filling_feature =[]
for i in null_num_sorted.index:
filling_feature.append(i)
if null_num_sorted[i]!=0:
X = train_data_X[filling_feature].drop(i,axis=1)
y = train_data_X[i]
row_number_mg_null = train_data_X[train_data_X[i].isnull()].index.tolist()
X_train = X.drop(row_number_mg_null)
y_train = y.drop(row_number_mg_null)
X_test = X.iloc[row_number_mg_null]
regr = RandomForestRegressor(n_estimators=100, random_state=42)
regr.fit(X_train,y_train)
y_pred = regr.predict(X_test)
train_data_X.loc[row_number_mg_null,i] = y_pred
print('完成训练集中的{}列数据的填充'.format(i))
return train_data_X,train_data_all.矿物类型
def rf_test_fill(train_data,train_label,test_data,test_label):
train_data_all = pd.concat([train_data,train_label],axis=1)
train_data_all = train_data_all.reset_index(drop=True)
test_data_all = pd.concat([test_data,test_label],axis=1)
test_data_all = test_data_all.reset_index(drop=True)
train_data_X = train_data_all.drop('矿物类型',axis=1)
test_data_X = test_data_all.drop('矿物类型',axis=1)
null_num = test_data_X.isnull().sum()
null_num_sorted = null_num.sort_values(ascending=True)
filling_feature =[]
for i in null_num_sorted.index:
filling_feature.append(i)
if null_num_sorted[i]!=0:
X_train = train_data_X[filling_feature].drop(i,axis=1)
y_train = train_data_X[i]
X_test = test_data_X[filling_feature].drop(i,axis=1)
y_test = test_data_X[i]
row_number_mg_null = test_data_X[test_data_X[i].isnull()].index.tolist()
X_train = X_train.dropna()
y_train = y_train.dropna()
X_pred = X_test.iloc[row_number_mg_null]
regr = RandomForestRegressor(n_estimators=100, random_state=42)
regr.fit(X_train,y_train)
y_pred = regr.predict(X_pred)
test_data_X.loc[row_number_mg_null,i] = y_pred
print('完成测试集中的{}列数据的填充'.format(i))
return test_data_X,test_data_all.矿物类型我们设定树的数量为100棵,随机种子设定为42,训练集的空缺使用训练集的数据填充,测试集的空缺值使用训练集的数据填充。
相比逻辑回归填充,随机森林算法捕捉非线性关系,对矿物、地质这类数据更贴合,填充精度更高。
四、三种方法的直观对比
| 方法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 众数填充 | 数据量小、缺失比例低、对精度要求不高 | 实现简单、运行速度极快无需训练模型,无额外计算开销 | 缺失比例高时,会严重扭曲原始数据 |
| 逻辑回归填充 | 数据分布较规整、特征相关性明确 | 依托其他特征做预测,比众数更贴合数据规律 | 仅擅长捕捉线性关系,非线性关联下效果差 |
| 随机森林填充 | 连续数值特征、分类特征均可,通用性强,特征间存在复杂非线性关联 | 抗异常值、抗轻微缺失干扰能力好 | 模型复杂度高,运行耗时明显高于前两种 |
总结
本文围绕矿物分类数据缺失值填充,详细讲解了分组众数填充、线性回归填充、随机森林填充三种智能预处理方法。
众数填充按矿物类型分组取高频值填充,简单高效、无模型开销,适合快速基础处理;线性回归利用特征间线性关系预测填充,比众数更贴合数据规律,适用于分布规整、关联明确的数据;随机森林则替换模型实现非线性拟合,通用性强、抗干扰与填充精度更高,更适配矿物等复杂实测数据。
三种方法从简单到精准层层递进,分别满足低开销、中等精度、高拟合度的不同填充需求,完整覆盖训练集与测试集的缺失值处理流程,为后续建模提供干净、可靠的数据基础。