量化压缩实战:INT8 / INT4 / AWQ / GPTQ 全面对比
《大模型知识与部署》系列 · No.12 / 35
适合人群:AI 工程师、后端开发
阅读时间:约 28 分钟
写在前面
上一篇我们讲了推理加速三板斧。这一篇我们讲另一个与"放得下"直接相关 的工程武器------量化(Quantization)。
如果说三板斧解决的是"GPU 跑得满不满",量化解决的就是"模型放得下放不下"------它通过把高精度权重压缩到低精度,直接把显存占用砍掉 50-87.5%。
这是个对工程师特别现实的话题。三个常见场景:
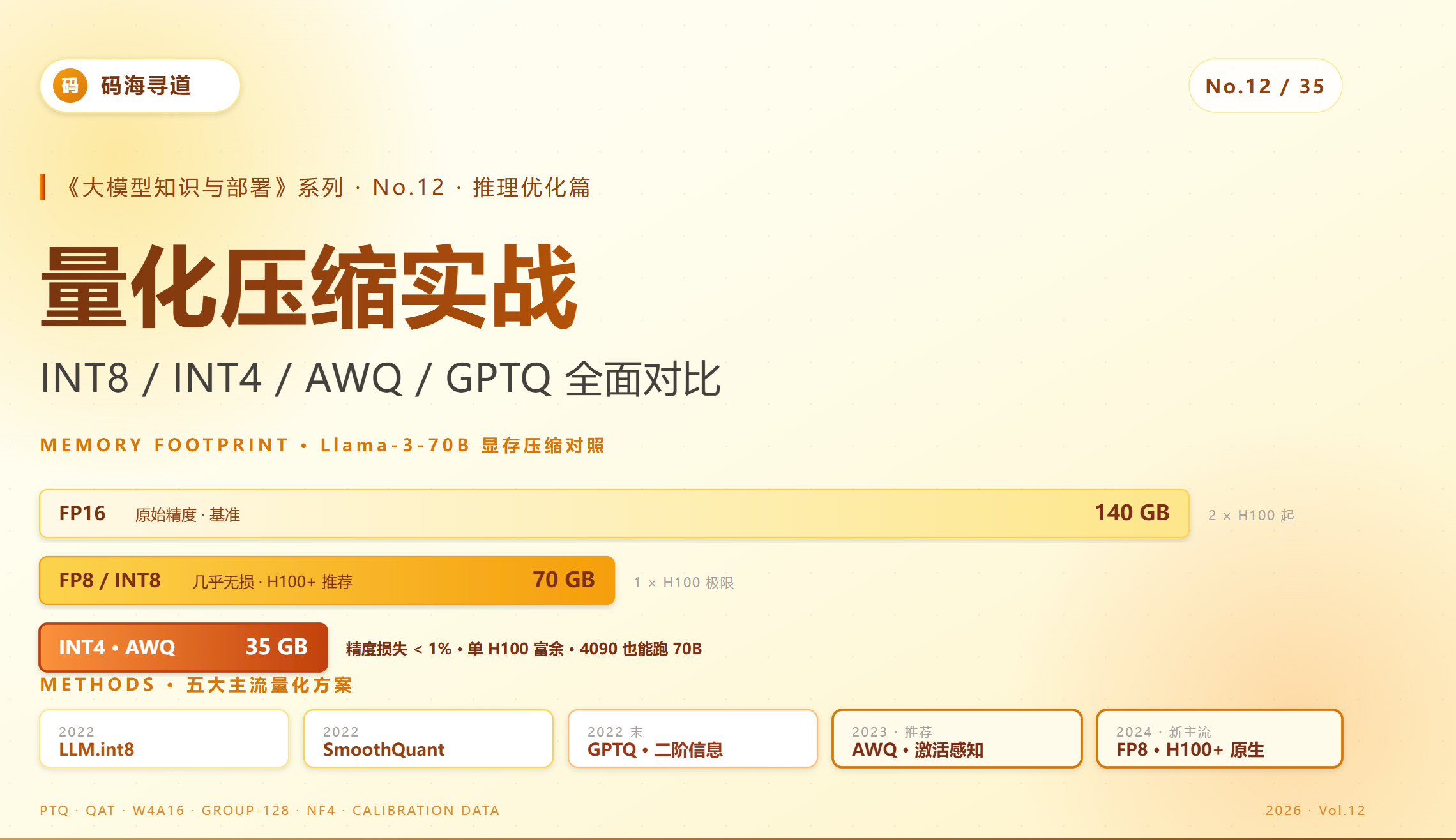
- 场景 1:手头有张 H100 80G,想跑 Llama-3-70B。FP16 要 140 GB,放不下。INT4 只要 35 GB,单卡富余。
- 场景 2:DeepSeek V3 671B 太大,8 卡 H100 都装不下。INT8 量化后 670 GB,刚好能塞进 8×96GB H100。
- 场景 3:想在 4090(24GB)上跑 14B 模型。FP16 要 28 GB 装不下,INT4 只要 7 GB,富余 17 GB 给 KV Cache。
但量化不是免费午餐。下面这些问题你一定碰过:
- 量化后效果掉了多少?怎么评估?
- INT8 / INT4 / AWQ / GPTQ / FP8,到底用哪个?
- 量化是不是越激进越好?
- 不同硬件支持哪种量化?
- 量化后推理是更快还是更慢?
读完本文你将能:
- 理解量化的基本原理(所有方法的共同底层)
- 区分 5 大主流量化方法的差异、优劣、适用场景
- 用 GPTQ / AWQ 实际量化一个模型
- 用 vLLM 部署量化模型并实测性能
- 知道每种业务该用什么量化方案
我们开始。
一、为什么量化是大模型部署的必修课
1.1 量化能带来什么
量化在三个维度同时给力:
| 维度 | FP16 → INT8 | FP16 → INT4 |
|---|---|---|
| 显存占用 | 减 50% | 减 75% |
| 推理速度 | +30-80% | +50-150% |
| 能耗 | 减 40% | 减 60% |
具体到主流大模型:
| 模型 | FP16 显存 | INT8 显存 | INT4 显存 |
|---|---|---|---|
| Llama-3-8B | 16 GB | 8 GB | 4 GB |
| Qwen3-32B | 64 GB | 32 GB | 16 GB |
| Llama-3-70B | 140 GB | 70 GB | 35 GB |
| Qwen3-72B | 144 GB | 72 GB | 36 GB |
| DeepSeek-V3 671B | 1342 GB | 671 GB | 336 GB |
最关键的工程意义:
- 8B / 14B 模型可以在消费级显卡上跑(4090、5090)
- 32B 模型可以单 H100 跑
- 70B 模型可以单 H100 跑(INT4)
- 671B 大模型可以 8 卡跑(INT8)
这就是为什么量化是从消费级到数据中心通吃的技术。
1.2 为什么推理速度也变快
很多人直觉以为:量化只省显存,速度应该不变。错了。
回忆第 11 篇我们讲的:
Decode 阶段是 memory-bound------GPU 显存带宽是瓶颈。
GPU 算力远超带宽能喂的速度。量化把权重从 16 bit 压到 8 bit,每秒能读取的"逻辑权重"翻倍------推理直接提速。
实测以 H100 跑 Llama-3-70B:
| 精度 | 单序列吞吐 (tokens/s) | 显存 |
|---|---|---|
| FP16 | 24 | 140 GB |
| INT8 | 42 | 70 GB |
| INT4 | 65 | 35 GB |
INT4 比 FP16 快 2.7×,省 4× 显存。
1.3 但代价是「精度损失」
量化不是无损的------把连续的浮点数压到离散的整数,必然有信息丢失。
不同量化方法的精度损失有数量级差异。我们用 MMLU 评测做对比(Llama-3-70B 基线 79.5%):
| 方法 | MMLU | 损失 |
|---|---|---|
| FP16 baseline | 79.5% | - |
| FP8 | 79.4% | -0.1 |
| INT8 (LLM.int8) | 79.2% | -0.3 |
| AWQ INT4 | 78.9% | -0.6 |
| GPTQ INT4 | 78.7% | -0.8 |
| BNB NF4 | 78.3% | -1.2 |
| INT4 (朴素) | 72.1% | -7.4 ⚠️ |
关键认知:
- INT8 几乎无损(< 0.5% 掉点)
- INT4 用对方法(AWQ/GPTQ)损失约 1%
- INT4 朴素量化损失巨大------这就是为什么需要 AWQ / GPTQ 这些"聪明的"算法
下面我们就来理解这些算法的本质。
二、量化的基本原理
所有量化方法的共同底层只有一件事:把浮点数映射到整数。
2.1 最基础的量化公式
设你有一组 FP16 权重 W,要量化到 INT8(范围 -128 ~ 127):
# 找到 W 的最大绝对值
max_val = max(abs(W))
# 计算缩放因子
scale = max_val / 127
# 量化
W_int8 = round(W / scale).clip(-128, 127)
# 反量化(推理时用)
W_recovered = W_int8 * scale核心问题:
原始:[0.0023, -1.5, 4.7, 0.001, 8.9, -2.3, ...]
量化:[0, -21, 67, 0, 127, -33, ...] ← 损失!特别是小值(0.0023、0.001)全都变成 0------信息丢失。这就是为什么朴素量化效果差。
2.2 量化的两个关键维度
维度 1:对称 vs 非对称
- 对称量化:用 max(|W|) 作为 scale,零点固定为 0。简单快,激活分布对称时好用
- 非对称量化:用 (max - min) 作为 scale + 零点偏移。对偏斜分布友好
LLM 权重通常用对称量化(分布对称),激活有时用非对称。
维度 2:量化粒度
per-tensor ── 整个张量一个 scale ← 粗,但快
per-channel ── 每个输出通道一个 scale ← 中
per-group ── 每 N 个权重一个 scale ← 细,精度高主流选择:
- 权重:per-channel 或 per-group(group=128)
- 激活:per-tensor(速度优先)
更细的粒度 = 更高精度 = 更多存储 scale 的开销。Group-128 是当下平衡点。
2.3 W4A16 vs W8A16 vs W8A8
LLM 量化的命名约定:
W{x}A{y} = Weight 量化到 x bit,Activation 量化到 y bit主流组合:
| 方案 | 权重 | 激活 | 适用场景 |
|---|---|---|---|
| W8A16 | INT8 | FP16 | 易实现、几乎无损 |
| W4A16 | INT4 | FP16 | 最常见,AWQ/GPTQ 标配 |
| W8A8 | INT8 | INT8 | 极致速度,精度损失大 |
| W4A4 | INT4 | INT4 | 实验性,仅个别场景 |
核心认知:
激活很难量化好(动态范围大、跨样本变化大),所以保 FP16 / BF16 通常是最稳妥的。
这是为什么主流量化方案都叫 W4A16 / W8A16------只量化权重,激活保持高精度。
2.4 量化的三种"姿势"
PTQ (Post-Training Quantization)
── 训完模型后直接量化,不重训
── 主流,因为简单
QAT (Quantization-Aware Training)
── 训练时就模拟量化误差
── 精度更高,但要重训
GPTQ / AWQ
── 介于两者之间
── 用少量校准数据 + 优化算法
── 接近 QAT 精度,PTQ 成本下面我们就重点讲 GPTQ 和 AWQ------它们是当下 INT4 量化的事实标准。
三、主流量化方法详解
3.1 LLM.int8():开启 LLM 量化时代(2022)
最早的 LLM 量化方案之一,作者 Tim Dettmers(也是 QLoRA 作者)。
核心问题 :朴素 INT8 量化会让 LLM 效果显著下降------因为 LLM 激活值有少数极端 outlier(远大于均值),强行量化会损坏所有数值的精度。
LLM.int8() 的解法:
- 混合精度 ------大部分用 INT8,outlier 用 FP16
- 检测哪些是 outlier(一种启发式规则)
- 把 outlier 单独拎出来,保持 FP16 运算
- 其余用 INT8 矩阵乘法,再合并
优点:
- 几乎无损(< 0.5% 掉点)
- 不需要重训
缺点:
- 速度提升有限(要做 outlier 检测 + 双精度计算)
- INT8 上限
当下地位 :被 bitsandbytes 库实现,是 HuggingFace 的默认 INT8 方案。但生产推理已经被更新的方案替代。
3.2 SmoothQuant:把 outlier "平滑"掉
LLM.int8() 处理 outlier 的方式是特殊照顾 。SmoothQuant 想:能不能消灭 outlier?
核心思想:
- 观察:outlier 主要在激活,不在权重
- 数学等价变换:
activation × weight = (activation / s) × (weight × s) - 选合适的
s,把激活的 outlier "挪到"权重里 - 权重相对容易量化(结构稳定),激活也变得平滑
效果:
- W8A8 量化可用了!速度更快
- 比 LLM.int8 简单
当下地位:在某些硬件场景仍在用(A100、L40),但 H100 时代已经被 FP8 取代。
3.3 GPTQ:基于二阶信息的精确量化
GPTQ(2022 末)是INT4 量化的开山之作。
核心思想:
- 量化某个权重时,用 Hessian 矩阵的二阶信息找最优量化方向
- 利用"少量校准数据"(128-1024 样本)估计 Hessian
- 逐层、逐权重地量化,每次量化都补偿前面的误差
直观:
朴素量化:[w1=0.7→1] [w2=0.4→0] [w3=0.6→1] ...
GPTQ: 量化 w1 后,调整 w2 的目标值,让总误差最小
量化 w2 后,调整 w3 的目标值
...优点:
- INT4 几乎无损(MMLU 掉 0.8% 左右)
- 量化过程相对快(70B 模型约 4-8 小时)
- 不需要重训
缺点:
- 需要校准数据集
- 算法实现复杂
当下地位 :INT4 量化主流之一,HuggingFace、vLLM、TensorRT-LLM 都支持。
3.4 AWQ:激活感知权重量化(2023)
AWQ(Activation-aware Weight Quantization)和 GPTQ 几乎同时出现,思路不同但效果类似。
核心洞察:
- LLM 的权重不是"同等重要"
- 那些配合大激活的权重,量化误差影响更大
- 那些配合小激活的权重,量化误差可以忽略
做法:
- 用校准数据找出"重要"的权重通道
- 在量化前,给这些通道乘一个 scale,把它们"放大"
- 量化后再除回去
- 重要权重的精度损失被压缩到几乎为零
优点:
- INT4 几乎无损(MMLU 掉 0.6% 左右,比 GPTQ 略好)
- 量化速度比 GPTQ 快(~ 30 分钟搞定 70B)
- 推理速度更快(更适合 GPU 优化)
缺点:
- 仍需校准数据
- 实现相对新,部分老硬件支持差
当下地位 :与 GPTQ 平分秋色,多数场景 AWQ 略优。
3.5 BNB NF4:QLoRA 用的那个
NF4(Normal Float 4)是 QLoRA 论文中提出的 4-bit 量化方案。
核心思想:
- LLM 权重经验上呈正态分布
- 设计 16 个"专为正态分布优化的 INT4 编码点"
- 量化时把权重映射到最近的 NF4 点
优点:
- 最简单(无需校准)
- 对训练友好(QLoRA 的基础)
缺点:
- 精度略差于 AWQ / GPTQ(掉点约 1.2%)
- 主要用于训练而非推理
当下地位 :训练(QLoRA)首选,推理用得少。
3.6 FP8:新硬件时代的宠儿
FP8 不是新的量化算法,而是新的数值格式------8 bit 浮点数。
两种变种:
E4M3:1 符号 + 4 指数 + 3 尾数 ← 精度高,范围小(推理主流)
E5M2:1 符号 + 5 指数 + 2 尾数 ← 精度低,范围大(训练用)优势:
- 比 INT8 精度更高(指数位带来动态范围)
- H100、H200、B200 原生硬件支持
- 速度和 INT8 一样
- 量化几乎无损(< 0.1% 掉点)
劣势:
- 仅 H100 及以上硬件支持
- 老 GPU(A100)不能用
当下地位 :H100+ 时代的 KV Cache 和模型量化首选。
3.7 一表打尽
| 方法 | 比特 | 校准数据 | MMLU 损失 | 适用硬件 | 当下地位 |
|---|---|---|---|---|---|
| LLM.int8 | 8 | 不需要 | -0.3% | 全部 | 已被替代 |
| SmoothQuant | 8 | 少量 | -0.5% | A100/L40 | 部分场景 |
| FP8 | 8 | 不需要 | -0.1% | H100+ | 新主流 |
| GPTQ | 4 | 128-1024 样本 | -0.8% | 全部 | 主流 |
| AWQ | 4 | 128-1024 样本 | -0.6% | 全部 | 主流 |
| NF4 | 4 | 不需要 | -1.2% | 全部 | 训练专用 |
| INT4 朴素 | 4 | 不需要 | -7%+ | 全部 | 不要用 |
四、实战:量化 + 部署完整流程
4.1 用 AWQ 量化 Qwen3-32B
python
"""
AWQ 量化完整脚本
依赖:pip install autoawq transformers accelerate
"""
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer
MODEL_PATH = "Qwen/Qwen3-32B-Instruct"
QUANT_PATH = "./qwen3-32b-awq"
# 量化配置
quant_config = {
"zero_point": True, # 用 zero point(非对称量化更稳)
"q_group_size": 128, # group 大小
"w_bit": 4, # INT4
"version": "GEMM", # 推理 kernel
}
# 1. 加载模型
model = AutoAWQForCausalLM.from_pretrained(MODEL_PATH, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
# 2. 准备校准数据(256-1024 条业务相关样本)
calib_data = [
"解释一下大模型推理优化的核心原理。",
"请总结这段技术文档...",
"如何用 Python 实现一个简单的 web 服务?",
# ... 加更多业务相关样本
] * 50
# 3. 量化(耗时约 30-60 分钟)
model.quantize(
tokenizer,
quant_config=quant_config,
calib_data=calib_data,
)
# 4. 保存
model.save_quantized(QUANT_PATH)
tokenizer.save_pretrained(QUANT_PATH)
print(f"量化完成!模型保存到 {QUANT_PATH}")
print(f"原始大小: ~64 GB")
print(f"AWQ INT4 大小: ~17 GB")关键提示:
- 校准数据必须和业务相关------否则精度损失会比 benchmark 数字大
- 256-1024 条样本足够,太多反而过拟合校准集
- 量化时不要量化
lm_head(输出层)------容易掉点
4.2 用 GPTQ 量化 Qwen3-32B
python
"""
GPTQ 量化完整脚本
依赖:pip install auto-gptq optimum transformers accelerate
"""
from transformers import AutoTokenizer
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
MODEL_PATH = "Qwen/Qwen3-32B-Instruct"
QUANT_PATH = "./qwen3-32b-gptq"
# 量化配置
quant_config = BaseQuantizeConfig(
bits=4,
group_size=128,
desc_act=False, # True 更精确但更慢
)
model = AutoGPTQForCausalLM.from_pretrained(
MODEL_PATH,
quantize_config=quant_config,
)
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
# 准备校准数据
calib_data = ... # 同上
# 量化(耗时约 4-8 小时,比 AWQ 慢)
model.quantize(
[tokenizer(text, return_tensors="pt") for text in calib_data]
)
model.save_quantized(QUANT_PATH)4.3 用 vLLM 部署量化模型
vLLM 对各种量化的支持:
bash
# AWQ 模型
vllm serve ./qwen3-32b-awq \
--quantization awq \
--dtype half
# GPTQ 模型
vllm serve ./qwen3-32b-gptq \
--quantization gptq \
--dtype half
# FP8 模型(H100+)
vllm serve Qwen/Qwen3-32B-Instruct \
--quantization fp8 \
--kv-cache-dtype fp8
# BnB INT8(不推荐生产)
vllm serve Qwen/Qwen3-32B-Instruct \
--quantization bitsandbytes4.4 真实业务性能对比
我们用 Qwen3-32B 做完整对比实验(H100 80G、batch=16、prompt=2K、生成=512):
| 量化方案 | 显存 | 吞吐 (tok/s) | TTFT | MMLU |
|---|---|---|---|---|
| FP16 | 64 GB | 1850 | 320ms | 82.1 |
| FP8 (W+KV) | 32 GB | 2900 | 280ms | 82.0 |
| INT8 (W8A16) | 32 GB | 2400 | 290ms | 81.9 |
| AWQ INT4 | 17 GB | 3200 | 250ms | 81.5 |
| GPTQ INT4 | 17 GB | 3100 | 260ms | 81.3 |
关键观察:
- FP8 和 AWQ INT4 是 2026 年的双子星------前者精度最佳,后者显存最省
- INT4 比 FP16 快 1.7×(显存带宽优势)
- 精度损失都在 1% 以内------业务场景几乎感知不到
五、避坑 + 决策建议
5.1 5 大常见量化坑
坑 1:用错校准数据
症状:用通用语料校准,业务场景效果掉得厉害。
对策:用业务真实分布的数据校准。比如做客服模型就用客服对话作校准。
坑 2:量化输出层 / Embedding
症状:模型输出乱码或概率分布异常。
对策:
lm_head不量化(强烈建议)- 部分 embedding 层不量化
- AWQ/GPTQ 默认会跳过这些层
坑 3:硬件不匹配
症状:量化模型部署后速度反而变慢。
对策:
- INT8 在 A100 / L40 / H100 都好
- INT4(AWQ/GPTQ)在 A100+ 主流支持
- FP8 仅 H100+,老硬件用不了
- T4 / V100 上量化收益有限(kernel 不优化)
坑 4:迷信"越激进越好"
症状:用 INT2 或更激进方案,业务效果崩盘。
对策:
- 生产场景止步于 INT4
- INT2 / 1.58 bit 是研究方向,不要轻易上生产
坑 5:忽视任务敏感性
症状:通用任务量化没问题,特定任务(数学、代码)量化后明显退化。
对策:
- 数学、代码、推理任务对量化更敏感
- 建议这些场景用 INT8 / FP8,而非 INT4
- 对量化后模型做业务真实评测,不要只跑通用 benchmark
5.2 决策树
你的硬件是?
│
├─ H100 / H200 / B200
│ │
│ ├─ 模型 < 单卡显存(FP8 装得下) → FP8 (推理框架原生支持)
│ └─ 模型大 → AWQ INT4 + FP8 KV Cache
│
├─ A100 / L40 (Ampere)
│ │
│ ├─ 模型不大 → INT8 / W8A16
│ └─ 模型大 → AWQ INT4
│
├─ 4090 / 5090 (消费级)
│ └─ AWQ INT4 几乎必选(显存有限)
│
└─ 旧硬件(V100 / T4)
└─ INT8 还行,INT4 收益小5.3 业务场景推荐
| 业务场景 | 推荐方案 | 理由 |
|---|---|---|
| 通用对话 | AWQ INT4 | 损失小、速度快、显存省 |
| 客服 / 知识问答 | AWQ INT4 | 同上 |
| 代码生成 | FP8 / INT8 | 代码对精度敏感 |
| 数学 / 推理 | FP8 / INT8 | 推理链精度敏感 |
| 长上下文 (1M) | INT4 + FP8 KV Cache | 显存压力大 |
| 端侧 / 移动 | INT4 (llama.cpp Q4_K_M) | 极致压缩 |
| 生产高并发 | FP8 / AWQ INT4 | 吞吐优先 |
5.4 部署 Checklist
部署量化模型前必做:
- 在业务真实数据上跑准确率评测
- 在 hold-out 测试集上跑通用 benchmark(看灾难性退化)
- 实测显存占用和峰值
- 实测吞吐和延迟
- 长时间稳定性测试(24 小时不间断跑)
- 对抗性测试(prompt injection / 长输入等边缘场景)
六、扩展话题与下一篇预告
6.1 端侧极致量化:llama.cpp 的 K-Quants
llama.cpp 为端侧推理设计了一套独特的量化方案:
| 方案 | 平均比特 | 备注 |
|---|---|---|
| Q8_0 | 8.5 | 接近无损 |
| Q6_K | 6.6 | 中等 |
| Q4_K_M | 4.85 | 端侧标配 |
| Q3_K_M | 3.9 | 极限压缩 |
| Q2_K | 2.6 | 实验 |
Q4_K_M 是端侧大模型部署的事实标准------iPhone、Mac、消费级电脑上跑大模型基本都用它。
👉 详见 系列第 33 篇:端侧大模型。
6.2 KV Cache 量化:另一个维度
上一篇我们讲过 KV Cache 量化------它和权重量化是独立的两个维度,可以叠加使用:
权重 INT4 (AWQ) + KV Cache INT8 = 综合显存省 60%+
权重 FP8 + KV Cache FP8 = H100 最佳组合6.3 量化感知微调(QAT-LoRA)
如果纯 PTQ 效果不够,可以做量化后微调:
1. 量化模型(AWQ/GPTQ)
2. 加 LoRA 适配器(FP16)
3. 在业务数据上做小数据量微调
4. 推理时合并这种方式能恢复 70-90% 的量化损失,且训练成本很低。
6.4 量化的未来趋势
观察 2025-2026 的方向:
- FP8 全面普及------H100/H200 加 B200 时代的默认
- 1.58 bit 探索(BitNet)------极致压缩的研究方向
- 混合精度量化------不同层用不同精度
- 量化感知预训练------从 0 开始训 INT8 模型(节省训练显存)
结语:量化是部署工程师的核心武器
读完本文你应该明白:
- 量化能在三个维度(显存、速度、能耗)同时给力
- AWQ 和 GPTQ 是 INT4 的双子星------AWQ 略优,GPTQ 历史更久
- FP8 是 H100+ 时代的新主流------精度几乎无损
- 业务场景下,FP8 / AWQ INT4 是 80% 场景的最佳选择
- 校准数据 + 业务真实评测 是量化成功的关键
下一篇我们继续推理优化:
- 第 13 篇:Flash Attention 原理与实践 ------ 这是另一个推理(和训练)的杀手锏,把 attention 计算的显存从 O(n²) 降到 O(n),速度提升 2-4×。我们会讲透它的 IO 优化思想 + 怎么在实际部署中启用。
之后是投机解码(第 14 篇)、长上下文优化(第 15 篇)。
我们下篇见。
📮 关于「码海寻道」
这里是一个聚焦 AI 工程化、大模型部署、后端架构实战的技术专栏。
写最一线的踩坑经验,做最务实的技术拆解。
如果这篇文章对你有启发,欢迎点赞、转发、关注。我们下篇见。