内容参考于:图灵AI大模型全栈
实现一个RAG的流程:
首先加载文件,然后读取文件中的文本,然后分割文本,然后把文本转成向量,然后保存成知识库,然后把我们的问题也转成向量,然后使用问题的向量去知识库中搜索,把搜索到的知识添加到向ai大模型提问的提示词中,然后提交给大模型回答
RAG存在的问题:
RAG痛点问题分析论文 ● 论文:《Seven Failure Points When Engineering a Retrieval Augmented Generation System》 ● 地址:https://arxiv.org/pdf/2401.05856
问题总结:
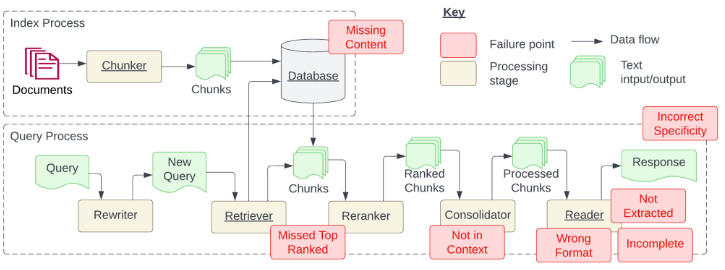
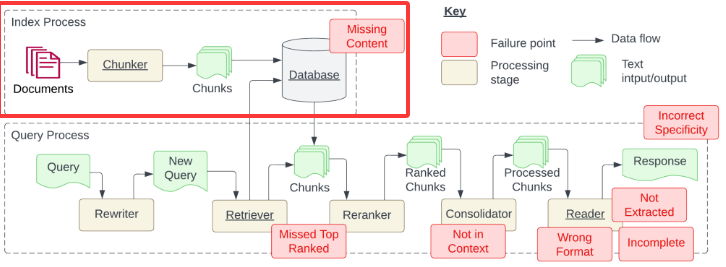
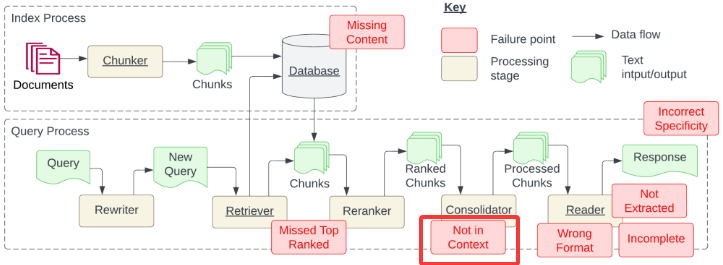
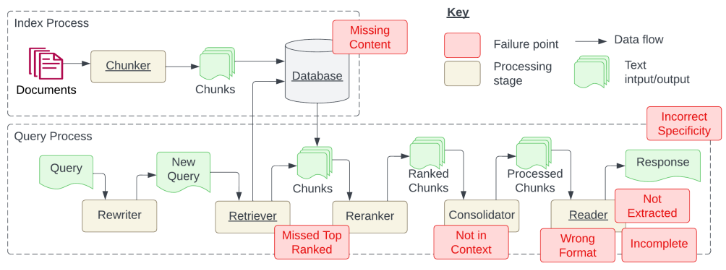
构建索引(构建知识库)的时候会有内容缺失的问题、文档加载的准确性、文档分割的颗粒度
内容缺失就是说,我们通过问题没办法在知识库中找到知识
文档加载的准确性就是说,如何更好的处理文档的数据,比如PDF
文档的分割,它的颗粒度影响会很大,怎么确定文档分割的颗粒度,这是一个很重要的事情,也没有标准答案,要根据项目来结合,以上就是下图红框里的问题
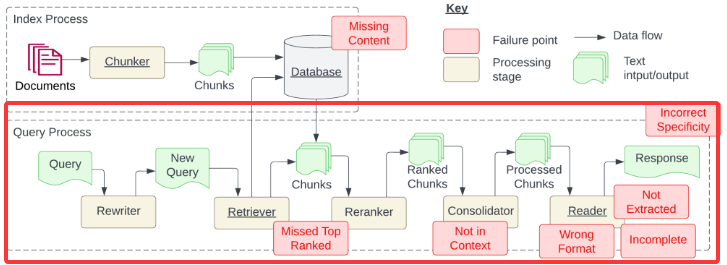
下图红框的部分是检索,Query是提交问题,通过Rewriter把提交的问题生成新问题NewQuery(由用户的一个问题,延伸出多个问题),然后使用这个多个问题进行检索(Retirever),检索之后得到多个知识,然后把多个知识进行重排(Reranker),然后RankedChunsk(重排),然后合并(Consolidator),ProcessedChunks把问题和知识进行拼接,然后读取拼接好的内容(Reader)发送给大模型(Response)
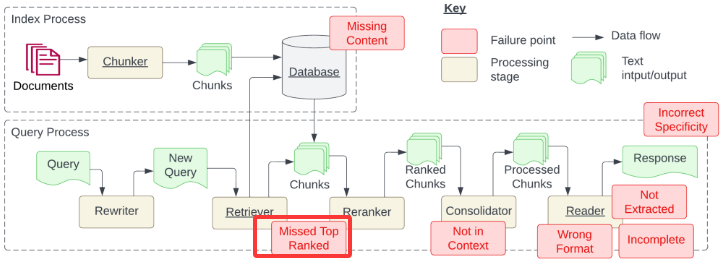
检索时出现的问题:错过排名靠前的文档,在做检索的过程,现在假如查出了5个文档(知识),1、2、3、4、5,第一个和问题相关性不大但语义相似度高,第二个问题相似度特别高,但是排在第二,或者是第5个与问题相似度是非常高的,但是排在第5位,排在后面的文档权重就会很低,这样就造成了错过排名靠前的文档(MissedTopRanked),也就是下图红框里的问题
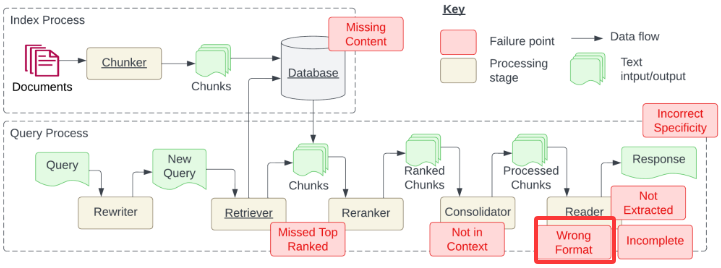
Not in Context提取的上下文和答案无关,就是获取到的知识和问题没有关系
Wrong Format格式错误,要求返回json格式的数据,但是返回的是普通文本
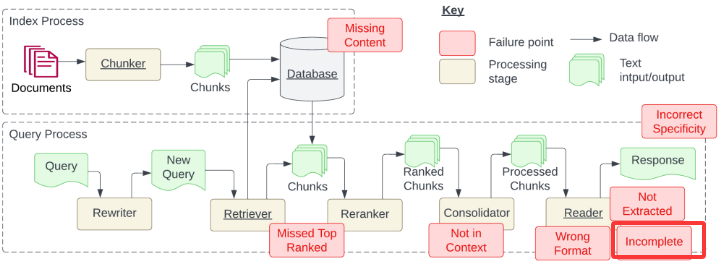
incomplete答案不完整,就是提了两个问题,但是它只回答一部分
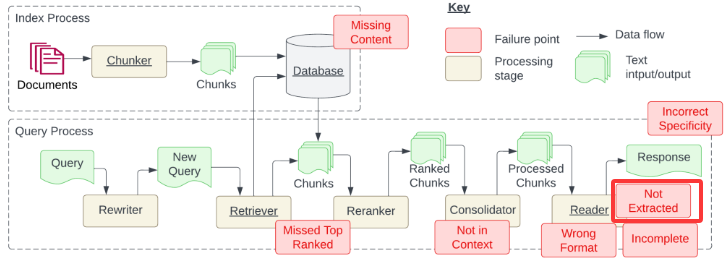
Not Extracted没有提取答案,就是说检索的文档有正确的内容,但是回复的时候不对,没有提取正确的内容,这个问题一般是模型不够强
Incorrect Specificity答案不够具体或者过于具体
我们的RAG系统就是我围绕着上方所说的问题来进行优化
内容缺失问题
这个问题跟RAG关系不大,我们整理的问题就没有答案,RAG也没办法,但是没有内容大模型会瞎编乱讲,会给一下情绪价值,解决办法就是添加内容,在用户搜索不到内容时打一个日志,后期再维护进去,如果内容缺失要利用提示词来约束大模型,让大模型回答的好一点,比如内容缺失就回答不知道,不让它瞎编
文档加载的准确性
这个问题只是在PDF中存在,PDF的格式是最复杂的,可以进行ocr识别,pdf转md文件
文档分割的颗粒度
要根据项目来看,比如RAG是做商品搜索的,商品的价格这种的就适合小的分割,还有医疗、法律这种做的一定要越精细越好,这种的处理非常严格的项目就越长越好,越长一句话产出的内容就越多,内容就会更准确
不管是长还是短都会有问题,短的它语义检索效率会好,长一点就会很耗费Token,检索效率就不会好
可以进行图RAG、父子文档、文档摘要,就是对文档进行多次分割,比如第一个通过2000大小来分割,第二次对这分割后的2000内容,这个两千的就是父文档,再次分割比如以500来分割,这就是子文档,500分割完再对它分割,也就是还有子文档,通过子文档去找父文档,使用父文档去问大模型
然后图RAG:就是比如说嫌疑人,跟A是什么关系,跟B是什么关系,跟C又是什么关系,然后B跟C是什么关系,这样的一个图谱
错过排名靠前的文档
检索出来与问题相关的知识排名不靠前,这个可以增加召回量,原本返回的知识只有2个,增加召回量就是让它变成7,就是让返回的知识变多,这样原本与问题相关的知识排在第6也能找到了,召回量增加Token就会增加很多
还可以进行重排,过召回,就是原本返回2个,现在让它返回8个或更多,然后让这个8个根据内容再重新排序,重新排完序依然取前2个,这个过召回用的比较多,这个会用单独的大模型进行重排序,虽然这个也会消耗很多的Token但是它会让最终的答案更加准确
提取的上下文和答案无关
这个没办法解决,这个就是错过排名靠前的文档和内容缺失的具体表现
格式错误
这个没有很好的办法解决,只能通过提示词约束
答案不完整
在提问的不要一股脑的一次性的问很多问题,如果一次性问了很多问题,大模型很大可能只会回答一部分问题,解决办法引导用户一个一个问题去提问,或者对用户的问题进行拆分,拆成子问题,通过子问题来找答案,比如用户提了一个问题,然后我们通过大模型把用户的问题拆成多个子问题,通过子问题去向量数据库中检索文档,通过这样的方式来解决
未提取答案
检索到3个内容,分割的文档过长的情况下,大模型的重点没有集中在需要关注的那里,这种情况可以对检索到的内容进行压缩,通过大模型来压缩,让语义不变,让内容体积变小,未提前答案就是答案的内容太杂了
答案不够具体或过于具体
比如问1+1等于几,有些模型直接回答1+1=2,有些模型就会思考用户是不是在玩,会有很多思考的步骤,这样的过程会把简单的事情变得复杂,这种情况是模型本身的问题,我们没办法干扰它
RAG没办法做到百分百无问题,只能尽力围绕上方的问题来达到一个比较高的准确率
之前的内容都是普通RAG,接下来是Advanced RAG(高级RAG),它就是围绕上方的问题来开发RAG,有些人连百度都用不明白更别说大模型了,只能通过对RAG加各种提示词优化来解决
