IM 系统是后端领域公认的技术深水区。长连接管理、消息可靠投递、多端同步、高并发处理,每一个单独拿出来都是硬骨头,而 IM 需要把它们全部整合到一起还能稳定运行。这篇从架构层面拆解我这套 IM 系统的每个设计决策,所有内容基于真实项目源码,不纸上谈兵。
先介绍下项目
XZLL-IM,一个人、两年业余时间、从零到生产级的分布式即时通讯系统。
不是 Demo,不是课程作业,不是把开源项目跑起来的部署教程。是从协议设计到消息投递、从 Java 微服务到 Flutter 跨端 SDK、从 Docker 部署到线上监控的全链路自研 。市面上你能看到的 IM 技术博客,大多数只讲后端。我这篇,后端 + SDK + 客户端 + 管理后台,四端全栈一个人扛下来。
一句话概括:Java 微服务后端 + 自研 Flutter IM SDK + Flutter 客户端 + Vue 管理后台。
直接上硬指标,不整虚的:
- 7 个微服务:网关、认证、长连接、业务、数据同步、社交、管理后台,各司其职,独立部署、独立扩缩容
- Protobuf 二进制协议:相比 JSON 体积砍掉 60%,序列化快 10 倍+,高频消息场景不做这个优化根本扛不住
- Netty 百万级长连接架构:Epoll 原生驱动、Boss/Worker 线程分离、ByteBuf 池化、ZGC 亚毫秒停顿、百万级文件描述符------单节点设计容量百万连接,横向扩展无上限
- 分布式消息路由:三层路由策略(本地直推 → gRPC 跨节点转发 → 离线存储),消息端到端延迟压到毫秒级
- 消息不丢不重:Redis ZSet 三级渐进重试 + Lua 原子去重 + 双 ID 设计(UUID 去重 + 雪花排序),这套组合拳是我踩了无数坑才定下来的
- 多设备同时在线:最多 5 台设备(Android/iOS/Web/小程序),独立 Token 管理,已读状态跨设备实时同步
- MongoDB 分片存储:按 chatId 哈希分片,消息追加写入,水平扩展理论上无上限
- Elasticsearch 全文搜索:RocketMQ 异步同步 MongoDB → ES,消息搜索毫秒级响应,写入和搜索互不影响
- 音视频通话:WebSocket 信令 + LiveKit,IM 系统内闭环,不依赖第三方通话 SDK
- 跨平台客户端 + 自研 IM SDK:3500+ 行的 Flutter IM SDK,封装了 WebSocket 管理、离线队列、消息去重、断线重连------一个后端开发硬生生写出来的
技术栈全家桶:
| 层 | 技术 |
|---|---|
| 后端 | Java 21、Spring Boot 3.3.7、Spring Cloud 2023.0.4、Spring Cloud Alibaba |
| 长连接 | Netty 4.1.108、WebSocket、Protobuf 3.25.3 |
| 服务间通信 | gRPC 1.62.2(同步)、RocketMQ(异步) |
| 存储 | MySQL(关系数据)、MongoDB(消息分片)、Redis/Redisson(缓存+锁+队列) |
| 搜索 | Elasticsearch 7.17 |
| 认证 | Spring Security 6 + JWT RS256 + OAuth2 |
| 配置中心 | Nacos(服务注册 + 配置热更新) |
| 客户端 | Flutter + GetX + RxDart + 自研 IM SDK |
| 音视频 | LiveKit |
| 部署 | Docker Compose、Nginx 反向代理 |
这不是 PPT 架构,不是从别处抄来的技术选型表。每一行代码都是我亲手敲出来的,每一个技术决策背后都有"为什么不选另一个方案"的反复论证。后面的系列文章会逐层拆解每个技术点的实现细节,这篇先看全貌。
架构总览
先上一张架构图,心里有个数:
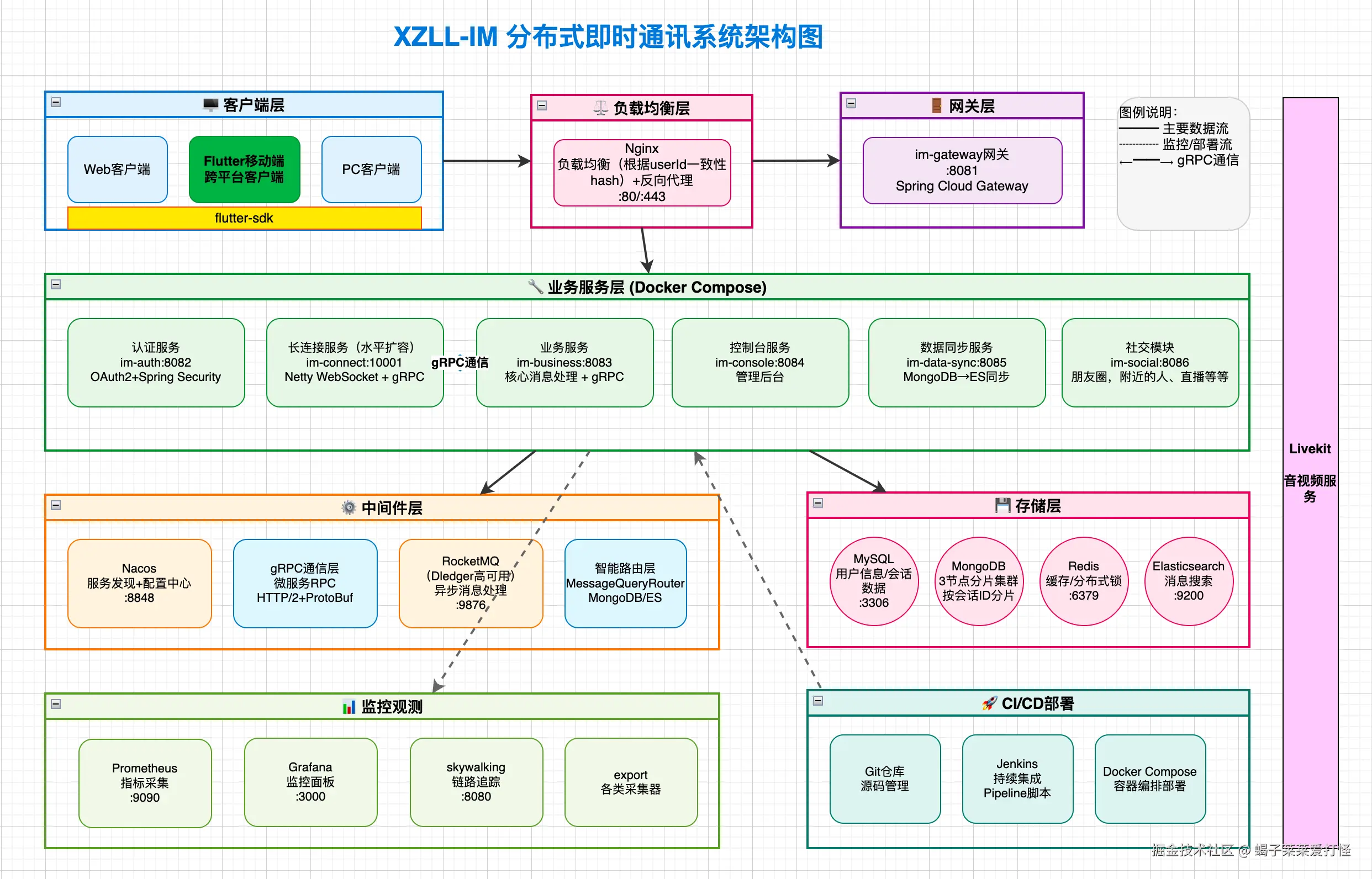
这套系统一共 7 个核心微服务 + 1 个管理后台 + 1 个 Flutter 客户端 + 1 个 Flutter IM SDK。四个独立 Git 仓库,各管各的。
很多人第一次看到这个架构图,第一反应是"至于拆这么多吗?"。下面逐个拆解,每个模块为什么存在,核心代码长什么样。看完你就知道了。
一、七个模块,各管各的
1.1 im-connect ------ 长连接层(最核心)
职责: 管 WebSocket 连接,收消息、推消息、不管存储。
这是整个系统的"门面"------客户端所有实时交互都通过它,它的稳定性直接决定用户能不能聊天。IM 系统的连接层和业务层必须分开,这是架构层面的铁律,没有商量的余地。
连接层要求低延迟、高吞吐,不能被数据库 I/O 阻塞;业务层要求事务一致性、批量写入优化。两者混合部署,互相拖累,必出问题。
看代码,它是一个基于 Netty 的独立服务器,所有参数都通过 Nacos 动态配置,改参数不需要重启:
java
// NettyServer.java --- Netty 服务启动
@Component
public class NettyServer implements ApplicationRunner {
@Override
public void run(ApplicationArguments args) {
EventLoopGroup bossGroup = Epoll.isAvailable()
? new EpollEventLoopGroup(bossThreads)
: new NioEventLoopGroup(bossThreads);
EventLoopGroup workerGroup = Epoll.isAvailable()
? new EpollEventLoopGroup(workerThreads)
: new NioEventLoopGroup(workerThreads);
ServerBootstrap bootstrap = new ServerBootstrap()
.group(bossGroup, workerGroup)
.channel(Epoll.isAvailable() ? EpollServerSocketChannel.class : NioServerSocketChannel.class)
.option(ChannelOption.SO_BACKLOG, backlog)
.childOption(ChannelOption.TCP_NODELAY, true)
.childOption(ChannelOption.SO_KEEPALIVE, true)
.childOption(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT);
bootstrap.childHandler(new WebSocketChannelInitializer());
bootstrap.bind(port).sync();
}
}几个关键设计:
1) Pipeline 分层处理
java
// WebSocketChannelInitializer.java
protected void initChannel(SocketChannel ch) {
ch.pipeline()
.addLast("logging", new LoggingHandler(LogLevel.DEBUG))
.addLast("http-codec", new HttpServerCodec())
.addLast("aggregator", new HttpObjectAggregator(65536))
.addLast("http-chunked", new ChunkedWriteHandler())
.addLast("compression", new WebSocketServerCompressionHandler())
.addLast("idle", new IdleStateHandler(idleCheckInterval, 0, 0, SECONDS))
.addLast("connectionLimit", connectionLimitHandler) // 连接数限制
.addLast("flowControl", flowControlHandler) // 流控
.addLast("metrics", new MetricsHandler()) // 监控指标
.addLast("auth", authHandler) // JWT 鉴权(一次性)
.addLast("websocket", webSocketServerHandler); // 主处理器
}Pipeline 的顺序很有讲究,调错一个位置就可能出线上事故:IdleStateHandler 必须在 AuthHandler 前面------心跳检测应该在认证前就开始工作,否则认证前的连接假死不会被清理;FlowControlHandler 必须在业务 Handler 前面------消息积压时先在流控层拦住,不能让后面的 Handler 被打爆。
2) 本地连接管理
java
// LocalChannelManager.java --- 本地连接映射
public class LocalChannelManager {
// userId -> Channel(主要查找路径)
private final ConcurrentMap<String, Channel> userIdChannelMap;
// channelId -> userId(反向查找,断连清理用)
private final ConcurrentMap<String, String> channelIdUserIdMap;
// userId -> Set<channelId>(多设备支持,最多 5 个)
private final ConcurrentMap<String, Set<String>> userMultiChannelMap;
// userId -> 连接时间(监控用)
private final ConcurrentMap<String, Long> userConnectTimeMap;
// 统计指标
private final AtomicInteger totalConnections = new AtomicInteger(0);
private final AtomicInteger activeConnections = new AtomicInteger(0);
}为什么用本地 Map 而不是 Redis?因为连接是本地的。一个用户连到了这台机器,他的 Channel 对象只在这台机器的 JVM 内存里,Redis 存不了 Netty Channel,序列化都没法序列化。这就是为什么需要分布式路由------消息要找到用户在哪台机器上。
3) 策略模式分发消息
java
// ProtoMsgHandlerStrategy.java --- 消息处理策略接口
public interface ProtoMsgHandlerStrategy {
MsgType supportMsgType();
void exchange(ChannelHandlerContext ctx, ImProtoRequest protoRequest);
}
// HandlerDispatcher.java --- 自动注册所有策略实现
@Component
public class HandlerDispatcher implements ApplicationContextAware {
private Map<MsgType, ProtoMsgHandlerStrategy> protoHandlers;
@Override
public void setApplicationContext(ApplicationContext ctx) {
// Spring 容器启动时自动收集所有策略实现
Map<String, ProtoMsgHandlerStrategy> beans =
ctx.getBeansOfType(ProtoMsgHandlerStrategy.class);
// 按 MsgType 注册到 Map
protoHandlers = beans.values().stream()
.collect(Collectors.toMap(
ProtoMsgHandlerStrategy::supportMsgType,
Function.identity()));
}
}目前注册了 12 个策略实现 ,涵盖 C2C 消息、群消息、已读回执、输入状态、音视频信令等。新增消息类型只需要实现接口 + 加 @Component,零侵入,不动老代码。这是我觉得整个连接层设计中最优雅的一个点。
4) gRPC 协议与跨节点通信
im-connect 是 multi-module 结构,其中 im-connect-api 子模块专门存放 gRPC 的 proto 定义和生成代码,im-connect-service 是实际运行的服务。im-business 也依赖这个 api 模块来调用 gRPC 接口。
protobuf
// message_service.proto --- gRPC 服务定义
service MessageService {
// 服务端 ACK 推送(im-business → im-connect → 客户端)
rpc ResponseServerAck2Client(ServerAckPush) returns (WebBaseResponse);
// 客户端 ACK 推送
rpc ResponseClientAck2Client(ClientAckPush) returns (WebBaseResponse);
// 消息撤回推送
rpc SendWithdrawMsg2Client(WithdrawPush) returns (WebBaseResponse);
// 好友请求/响应推送
rpc PushFriendRequest2Client(FriendRequestPush) returns (WebBaseResponse);
rpc PushFriendResponse2Client(FriendResponsePush) returns (WebBaseResponse);
// 跨节点消息转发(im-connect A → im-connect B)
rpc TransferC2CMsg(ImProtoRequest) returns (WebBaseResponse);
}TransferC2CMsg 是整个分布式架构的命脉。当用户 A 在节点 1,用户 B 在节点 2,A 给 B 发消息时:节点 1 发现 B 不在本地 → Redis 查到 B 在节点 2 → gRPC 调用节点 2 的 TransferC2CMsg → 节点 2 通过本地 Channel 推送给 B。
gRPC 客户端还做了连接池管理和 30 秒健康检查:
java
// SmartGrpcClientManager.java --- 智能 gRPC 连接池
public class SmartGrpcClientManager {
private final ConcurrentMap<String, ChannelInfo> channelPool;
// 路由:通过 Redis 查找用户在哪台 im-connect 上
public String getServerAddress(String userId) {
return redisTemplate.opsForHash()
.get("userLogin:server:", userId);
}
// 健康检查:每 30 秒检测一次连接状态
@Scheduled(fixedDelay = 30000)
public void healthCheck() {
channelPool.forEach((addr, info) -> {
if (!info.getChannel().isShutdown()) return;
channelPool.remove(addr);
});
}
}1.2 im-business ------ 业务逻辑层
职责: 消息存储、好友关系、群组管理、消息搜索。所有"重活"都在这里。
和 im-connect 分开的核心原因前面说了:存储和连接的生命周期完全不同。存储挂了不应该影响消息接收(走重试队列兜底),连接挂了不应该影响历史消息查看。
java
// C2CSendMsgHandler.java --- C2C 消息处理核心逻辑
public class C2CSendMsgHandler {
public void sendC2CMsgDeal(C2CSendMsgAO msg) {
// 1. 保存到 MongoDB(分片集合)
msgRecordService.saveC2CMsg(msg);
// 2. 更新会话列表元数据(Redis)
chatListService.updateChatList(msg);
// 3. 构建服务端 ACK,通过 RocketMQ 异步推回
ServerAckPush ack = buildServerAck(msg);
serverAckRetryService.sendWithRetry(ack);
// 4. 发数据同步事件 → ES 索引
dataSyncProducer.sendSyncEvent(msg);
}
}im-connect 和 im-business 之间通过 RocketMQ 解耦,不走同步 RPC。为什么?因为消息存储可能失败,需要重试。RocketMQ 自带重试机制,还能保证消息不丢。如果用同步 RPC,存储一卡,连接层也跟着卡,用户连消息都发不出去------这个坑我踩过,所以改成了 MQ 异步。
MongoDB 消息表设计:
java
// ImC2CMsgRecordMongo.java --- C2C 消息实体
@Document(collection = "im_c2c_msg_record")
@Sharded(shardKey = "chatId") // 按 chatId 哈希分片
public class ImC2CMsgRecordMongo {
@Id
private String id; // 格式: chatId_msgId
private String chatId; // 会话ID,如 "100-1-123-456"
private Long msgId; // 雪花算法,全局唯一且有序
private Long fromUserId;
private Long toUserId;
private Integer msgFormat; // 文本/图片/语音/视频/文件...
private String msgContent;
private Long msgCreateTime;
private Integer msgStatus;
private Integer withdrawFlag;
}
// 复合索引:{chatId, msgCreateTime}、{fromUserId, chatId, msgCreateTime}为什么用 MongoDB 不用 MySQL 存消息?这个问题我被问过无数次。三个硬核原因:
- 写入吞吐:聊天消息是追加写入场景,MongoDB 的 WAL 机制天然适合,MySQL 的 B+ 树在这类场景下是劣势
- 水平扩展:按 chatId 分片,不需要应用层分库分表,加机器就行
- 灵活 Schema:不同消息类型(文本、图片、位置、视频)的字段差异大,MongoDB 不需要加一堆 NULL 列
1.3 im-gateway ------ API 网关
职责: 统一入口、JWT 鉴权、路由转发、限流。
java
// AuthGlobalFilter.java --- 全局认证过滤器
public class AuthGlobalFilter implements GlobalFilter, Ordered {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// 1. 解析 JWT Token
String token = exchange.getRequest().getHeaders().getFirst("Authorization");
JWSObject jwsObject = JWSObject.parse(token.replace("Bearer ", ""));
// 2. 提取用户信息
String userId = jwsObject.getPayload().toJSONObject().get("userId").toString();
// 3. 注入到请求头,传给下游服务
ServerHttpRequest request = exchange.getRequest().mutate()
.header("X-User-Id", userId)
.build();
return chain.filter(exchange.mutate().request(request).build());
}
}注意:WebSocket 连接不经过网关,直接走 Nginx 反代到 im-connect。因为 WebSocket 是长连接,走网关(Spring Cloud Gateway 基于 WebFlux)会多一层不必要的转发开销和内存占用。网关只处理 HTTP API 请求(拉历史消息、好友列表、搜索等)。
1.4 im-auth ------ 认证服务
职责: 登录、发 Token、刷新 Token、踢人。
java
// AuthController.java --- 核心登录接口
@PostMapping("/oauth/token")
public WebBaseResponse<Oauth2TokenDto> login(@RequestBody TokenRequest request) {
// 1. Spring Security 认证
Authentication auth = authenticationManager.authenticate(
new UsernamePasswordAuthenticationToken(
request.getUsername(), request.getPassword()));
// 2. 生成 JWT(RS256 签名)
String accessToken = jwtTokenService.generateAccessToken(user, deviceType);
String refreshToken = jwtTokenService.generateRefreshToken(user, deviceType);
// 3. 存入 Redis(支持多设备)
// key = userLogin:token:{userId}:{deviceType}:{md5(token)}
// TTL = token 超时时间
redisTemplate.opsForValue().set(redisKey, userId, timeout, TimeUnit.SECONDS);
return WebBaseResponse.success(new Oauth2TokenDto(accessToken, refreshToken));
}几个设计细节:
- RS256 非对称签名 :用 RSA 私钥签 JWT,公钥验签。这样 im-gateway 只需要存公钥,不需要和 im-auth 通信就能验证 Token,认证服务挂了也不影响网关验权
- 多设备支持 :Redis Key 包含
deviceType(android/ios/web/mini_program),同一账号最多 5 设备同时在线 - Token 黑名单 :登出时删 Redis Key,网关每次请求都校验 Redis 中是否存在该 Token,已登出的 Token 即使没过期也无法使用------比纯 JWT 无状态方案安全得多
1.5 im-data-sync ------ 数据同步
职责: 消费 RocketMQ 消息,把 MongoDB 的消息同步到 Elasticsearch。
java
// BatchDataSyncConsumer.java --- 批量同步消费者
public class BatchDataSyncConsumer implements MessageListenerConcurrently {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs) {
List<ImC2CMsgRecordES> inserts = new ArrayList<>();
List<ImC2CMsgRecordES> updates = new ArrayList<>();
for (MessageExt msg : msgs) {
ClusterEvent event = JSON.parseObject(msg.getBody(), ClusterEvent.class);
if (event.getOperationType() == SAVE) {
inserts.add(convertToES(event));
} else {
updates.add(convertToES(event));
}
}
// 批量写入 ES
BulkRequest bulkRequest = new BulkRequest();
inserts.forEach(doc -> bulkRequest.add(
new IndexRequest("im_c2c_msg_record").id(doc.getId())
.source(JSON.toJSONString(doc), XContentType.JSON)));
restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
}为什么不直接在 im-business 里写 ES?因为写入 MongoDB 和写入 ES 的失败概率不同 。MongoDB 是核心链路,ES 搜索不是。如果 ES 写入失败拖慢了消息存储,得不偿失。异步解耦后,ES 即使挂了也不影响发消息------这就是微服务的意义:故障隔离。
1.6 im-social ------ 社交模块
职责: 圈子、帖子、活动、话题、打招呼。
这个模块是后来加的,和核心 IM 链路完全独立。如果把它和 im-business 合在一起,社交功能的任何变更都会影响核心消息链路,风险太高。独立出来后,可以单独部署、单独扩容。社交模块挂了,聊天功能照样用。
二、消息从发送到接收,经历了什么?
这是理解整个架构的关键。一条 C2C 消息从 A 发到 B,要经过四个节点、两种通信协议、三次路由决策------但整个过程对用户来说是无感的:
bash
A 的手机 im-connect (节点1) im-business B 的手机
│ │ │ │
│── C2CSendReq(Protobuf)──▶│ │ │
│ │── RocketMQ ───────────────▶│ │
│ │ │── 存 MongoDB │
│ │ │── 更新 Redis 会话 │
│ │◀── gRPC ServerACK ────────│ │
│◀── ServerACK(消息已收到)──│ │ │
│ │ │ │
│ │── 检查 B 是否在线 ──────────│ │
│ │ B 在本地?直接推送 │ │
│ │ B 在其他节点?gRPC 转发 │ │
│ │ B 不在线?走离线消息 │ │
│ │ │ │
│ │── C2CMsgPush ──────────────────────────────────────▶│
│ │ │ │对应 im-connect 的核心路由逻辑:
java
// C2CMsgSendProtoStrategyImpl.java --- 三层路由
public void exchange(ChannelHandlerContext ctx, ImProtoRequest protoRequest) {
C2CSendReq sendReq = C2CSendReq.parseFrom(protoRequest.getPayload());
// 路径1:本地在线 --- 直接通过本地 Channel 推送
Channel targetChannel = localChannelManager.getChannelByUserId(toUserId);
if (targetChannel != null && targetChannel.isActive()) {
pushDirectly(targetChannel, pushMsg);
return;
}
// 路径2:远程在线 --- Redis 查到目标节点,gRPC 转发
String serverAddr = smartGrpcClientManager.getServerAddress(toUserId);
if (serverAddr != null) {
smartGrpcClientManager.transferC2CMsg(serverAddr, protoRequest);
return;
}
// 路径3:离线 --- 发 RocketMQ 离线消息事件
offlineMsgProvider.sendOfflineEvent(sendReq);
}三层路由的设计哲学:能本地解决的绝不跨网络,能异步的绝不同步。 本地直推是纳秒级内存操作,gRPC 跨节点是毫秒级网络调用,离线存储是兜底方案。优先级递减,延迟递增。
三、消息可靠性:IM 的灵魂
架构是骨架,消息不丢、不重、有序才是 IM 的灵魂。很多同学写了个聊天 Demo 就觉得 IM 不过如此,但 Demo 和生产级系统之间的差距,可能比 Java 和 JavaScript 的差距还大。这一节展开讲讲这几个核心问题我是怎么解的。
3.1 双 ID 设计:clientMsgId + msgId
这是整个消息可靠性的基石。
protobuf
// message_service.proto --- C2CSendReq 消息结构
message C2CSendReq {
bytes clientMsgId = 1; // 客户端生成的 UUID,16 字节,用来去重
fixed64 msgId = 2; // 服务端生成的雪花 ID,8 字节,用来排序
fixed64 from = 3;
fixed64 to = 4;
int32 format = 5;
string content = 6;
fixed64 time = 7;
}为什么需要两个 ID?因为它们解决的是两个完全不同的问题:
| ID | 类型 | 谁生成的 | 解决什么问题 |
|---|---|---|---|
clientMsgId |
UUID (16 bytes) | 客户端 | 去重:重试、断线重连、网络重传都会产生重复消息,用 UUID 判重 |
msgId |
雪花算法 (fixed64) | 服务端 | 排序:雪花 ID 天然递增,保证消息全局有序 |
只用一个 ID 行不行?真不行:
- 用 UUID 排序?UUID 无序,群聊里多个人的消息没法按时间排
- 用自增 ID?分布式环境下会冲突,还需要额外的协调服务
- 用雪花 ID 去重?可以,但客户端离线重试时没有服务端 ID,没法做发送端去重
雪花 ID 的生成------为了极致性能,我用了预生成池:
java
// SnowflakeIdService.java --- 雪花 ID 生成 + 预生成池
public class SnowflakeIdService {
private static final int ONCE_BATCH_COUNT = 1000;
private final AtomicLong currentId = new AtomicLong(0);
private final AtomicLong maxId = new AtomicLong(0);
public long generateSimpleMessageId() {
// 池子里没了,批量预生成 1000 个
if (currentId.get() >= maxId.get()) {
synchronized (this) {
refillPool();
}
}
return currentId.getAndIncrement();
}
private void refillPool() {
// 从 Snowflake 算法批量获取 1000 个 ID
// 避免每条消息都走一次 Snowflake 计算,极致吞吐
}
}chatId 的计算 ------注意 Protobuf 里没有 chatId 字段,它是双方 ID 动态算出来的,不占一比特带宽:
java
// ChatIdUtils.java --- 会话 ID 生成
public static String buildC2CChatId(Integer bizType, Long fromUserId, Long toUserId) {
// 小 ID 在前,大 ID 在后,保证 A→B 和 B→A 的 chatId 相同
Long smallUserId = Math.min(fromUserId, toUserId);
Long bigUserId = Math.max(fromUserId, toUserId);
return bizType + "-1-" + smallUserId + "-" + bigUserId;
// 结果如: "100-1-123-456"
}一条消息从 Protobuf 字段设计上就完成了职责分离:clientMsgId 管去重,msgId 管排序,chatId 动态计算不占带宽。每个字段都有且只有一个职责,没有冗余。
3.2 消息有序性:雪花 ID 的天然保证
IM 的"有序"不是说消息必须按发送时间戳排,而是接收方看到的消息顺序必须和发送顺序一致。群聊里 5 个人同时说话,消息到达服务端的顺序可能和发送顺序不一样,但客户端显示的时候必须是对的。
雪花 ID 的结构决定了它天然有序:
bash
| 1 bit | 41 bit 时间戳 | 5 bit 机房 | 5 bit 机器 | 12 bit 序列号 |高位是时间戳,所以 ID 越大,生成时间越晚 。客户端收到消息后直接按 msgId 排序就行,完全不依赖消息到达的先后顺序:
java
// MongoDB 查询 --- 按 msgCreateTime + msgId 双字段排序
// 处理同一毫秒内的多条消息
criteria.orOperator(
Criteria.where("msgCreateTime").lt(lastMsgTime),
Criteria.where("msgCreateTime").is(lastMsgTime).and("msgId").lt(lastMessageId)
);
// 排序:msgCreateTime DESC, msgId DESC为什么用 (msgCreateTime, msgId) 双字段而不是只排 msgId?因为 msgId 是服务端生成时间,msgCreateTime 是客户端发送时间。极端情况下(客户端本地时钟偏移、服务端批处理),两者可能不完全一致。双字段排序是防御性设计,宁可多一个字段,也不能在极端场景下出现消息乱序。
3.3 消息去重:服务端 + 客户端双重保障
去重要在两个地方做:服务端防止重试消息入库,客户端防止重复推送显示。只做一端的去重是不够的。
服务端去重------在重试队列的 Lua 脚本里,原子操作,不会出现并发问题:
lua
-- add_to_retry_queue.lua --- 原子入队 + 去重判断
-- 如果 msgId 已存在,说明这条消息已经在重试队列里了,直接跳过
if redis.call('HEXISTS', hashKey, msgId) == 1 then
return 0 -- 已存在,不入队
end
redis.call('ZADD', zsetKey, score, msgId)
redis.call('HSET', hashKey, msgId, compressedData)
return 1客户端去重------SDK 用内存缓存 + 双 key 校验:
dart
// xzll_im_client.dart --- 消息去重缓存
final Map<String, int> _messageCache = {};
static const int _maxCacheSize = 1000;
static const int _messageCacheTtlMs = 2 * 60 * 1000; // 2 分钟过期
// 双 key 去重:同时用服务端 msgId 和客户端 clientMsgId 检查
bool _isDuplicateMessage({String? msgId, String? clientMsgId}) {
if (msgId != null && _messageCache.containsKey('s:$msgId')) return true;
if (clientMsgId != null && _messageCache.containsKey('c:$clientMsgId')) return true;
return false;
}为什么客户端也要去重?因为服务端重试机制会在 5s、30s、300s 后重发消息。如果网络延迟导致第一次推送和重试推送几乎同时到达客户端,没有去重就会显示两条一样的消息------用户体验灾难。
3.4 消息重试:三级渐进式重试
这是整个消息可靠性链条中最复杂的部分,也是我觉得最有技术含量的设计之一。
消息推送给接收方后,如果接收方没 ACK,服务端怎么处理?直接放弃?那消息就丢了。无限重试?那服务器资源会被耗尽。
我的方案:Redis ZSet + Lua 原子操作 + 三级渐进式延迟:
java
// C2CMsgRetryServiceImpl.java --- 消息重试服务
public class C2CMsgRetryServiceImpl implements C2CMsgRetryService {
// 三级延迟:5秒 → 30秒 → 5分钟
private final int[] delays = {5, 30, 300};
private final int maxRetries = 3;
// 消息推送成功后,加入重试队列
public void addToRetryQueue(ImProtoRequest protoRequest, String toUserId) {
long firstExecuteTime = System.currentTimeMillis() + delays[0] * 1000L;
byte[] compressed = LZ4_COMPRESSOR.compress(protoRequest.toByteArray());
// Lua 原子操作:ZSet 存 score(执行时间),Hash 存压缩后的消息体
// 如果 msgId 已存在,跳过(去重)
luaScriptExecutor.executeAddToRetryQueue(
zsetKey, hashKey, msgId, firstExecuteTime, compressed);
}
// 定时扫描:每 1 秒扫一次到期消息
@Scheduled(fixedDelay = 1000)
public void scanRetryQueue() {
long now = System.currentTimeMillis();
// Lua 原子认领:ZRANGEBYSCORE + ZREM 原子操作,防止多节点并发处理同一条消息
List<String> expiredMsgIds = luaScriptExecutor.executeClaimRetryMessages(zsetKey, now);
for (String msgId : expiredMsgIds) {
byte[] data = redisTemplate.opsForHash().get(hashKey, msgId);
ImProtoRequest request = ImProtoRequest.parseFrom(LZ4_DECOMPRESSOR.decompress(data));
int retryCount = getRetryCount(msgId);
if (retryCount < maxRetries && isUserOnline(toUserId)) {
// 重推 + 重新入队(下一级延迟)
pushToUser(toUserId, request);
requeue(msgId, now + delays[retryCount + 1] * 1000L);
} else {
// 超过重试次数或用户已离线,转离线处理
removeFromRetryQueue(msgId);
offlineMsgHandler.handle(request);
}
}
}
}整个重试流程:
bash
推送消息给 B
│
├── B 收到了,回复 ClientACK ──▶ 从重试队列移除 ✓
│
└── B 没回复
│
├── 5 秒后:第 1 次重推
│ └── 还没 ACK?
│ ├── 30 秒后:第 2 次重推
│ │ └── 还没 ACK?
│ │ ├── 5 分钟后:第 3 次重推
│ │ │ └── 还没 ACK?
│ │ │ └── 转离线消息处理
│ │ │ 更新 MongoDB 状态为 OFFLINE
│ │ │ 发送 MobPush 通知唤醒
│
└── 用户上线后拉取会话列表,按需加载历史消息为什么用 Redis ZSet 而不是 RocketMQ 做重试?因为重试队列需要按到期时间精确扫描 ,MQ 的延迟消息粒度不够(RocketMQ 延迟级别是固定的 18 档),而且每条消息的重试状态需要随机读写(改 retryCount、改 delay),ZSet + Hash + Lua 的组合比 MQ 灵活得多。这个决策是在实际踩坑之后做出的------一开始用 RocketMQ 延迟消息做重试,发现延迟级别不够精细,改成了 Redis 方案,效果好得多。
3.5 客户端重试:离线队列 + 指数退避
服务端有重试,客户端也有。网络断开时消息不能丢,要先进队列,连上后自动发------用户感知不到网络波动:
dart
// xzll_im_client.dart --- 离线消息队列 + 重试
final Map<String, _PendingSendTask> _pendingSends = {};
static const int _maxMessageRetry = 3;
// 发送时如果没连接,先进队列
void sendTextMessage(toUserId, content, ...) {
if (!isConnected) {
_enqueuePendingSend(clientMsgId, chatId);
return; // 不报错,用户看到"发送中"
}
_channel?.sink.add(bytes);
}
// 重连成功后,自动 flush 所有待发消息
void _flushPendingMessages() {
for (var task in _pendingSends.values) {
_executeRetrySend(task); // 逐条发送
}
}
// 单条消息的重试:指数退避 2s → 4s → 8s
void _scheduleMessageRetry(_PendingSendTask task) {
if (task.retryCount >= _maxMessageRetry) {
_markMessageFailed(task.clientMsgId); // 显示红色感叹号
return;
}
final delaySeconds = 2 << task.retryCount; // 2, 4, 8
Timer(Duration(seconds: delaySeconds), () => _executeRetrySend(task));
}3.6 服务端 ACK:告诉发送方"我收到了"
消息到达服务端后,需要给发送方一个确认,否则发送方不知道消息到底发出去了没:
java
// C2CSendMsgHandler.java --- 消息存储 + 服务端 ACK
public void sendC2CMsgDeal(C2CSendMsgAO msg) {
// 1. 存 MongoDB
msgRecordService.saveC2CMsg(msg);
// 2. 构建服务端 ACK,通过 gRPC 推给发送方所在的 im-connect 节点
ServerAckPush ack = ServerAckPush.newBuilder()
.setToUserId(msg.getFromUserId()) // 注意:ACK 发给发送方
.setClientMsgId(msg.getClientMsgId())
.setMsgId(msg.getMsgId())
.setMsgReceivedStatus(1) // SERVER_RECEIVED
.setReceiveTime(System.currentTimeMillis())
.build();
// 3. gRPC 发送,失败则走 RocketMQ 重试(同样的 5s/30s/300s 三级)
serverAckRetryService.sendServerAckWithRetry(ack);
}ACK 也有重试机制。因为 gRPC 调用可能失败(目标 im-connect 节点正在重启、网络抖动),通过 RocketMQ 延迟消息兜底:
java
// ServerAckSimpleRetryService.java
public void sendServerAckWithRetry(ServerAckPush ack) {
boolean sent = grpcMessageService.sendServerAck(ack);
if (!sent) {
// gRPC 失败,发 RocketMQ 延迟消息,稍后重试
rocketMQProducer.sendDelayMsg(
SERVER_ACK_RETRY_TOPIC,
JSON.toJSONString(ack),
delayLevel // 5s, 30s, 300s
);
}
}ACK 链路本身也是可靠的------gRPC 失败走 MQ 兜底,MQ 失败有重试机制。整条链路没有任何单点故障。
3.7 完整的消息可靠性链路
把上面所有机制串起来,一条消息从发送到确认的完整生命周期:
bash
客户端 A 服务端 客户端 B
│ │ │
│── C2CSendReq ─────────────────────▶│ │
│ (clientMsgId=UUID) │ │
│ │── 生成 msgId(雪花算法) │
│ │── 存 MongoDB(chatId_msgId) │
│ │── 去重检查(Lua 原子操作) │
│◀── ServerACK(msgId, code=1) ───────│ │
│ A 的 UI:发送中 → 已发送 ✓ │ │
│ │ │
│ │── 推送 C2CMsgPush ────────────────▶│
│ │ 加入重试队列(5s/30s/300s) │
│ │ │
│ │◀── ClientACK(status=3) ───────────│
│ │ 从重试队列移除 │
│ │ │
│◀── ClientAckPush(status=3) ────────│ │
│ A 的 UI:已发送 → 已送达 ✓ │ │如果 B 不在线,链路变成:
bash
重试 3 次无响应
│
├── 更新 MongoDB 消息状态 → OFFLINE
├── 发送 MobPush 通知唤醒 B
│
└── B 上线后
├── 拉取会话列表(含未读数)
├── 打开聊天窗口
└── 按需加载历史消息(MongoDB 分页查询)四、技术栈选型背后的考量
每一项技术选型都不是拍脑袋决定的,都有"为什么不选另一个"的论证过程:
| 技术 | 用在哪 | 为什么选它 |
|---|---|---|
| Netty | im-connect | Java 生态唯一能支撑百万级 WebSocket 长连接的方案。Tomcat/WebFlux 根本做不到这个量级 |
| Protobuf | 客户端协议 | 比 JSON 体积小 3-5 倍、序列化快 10 倍+。IM 高频消息场景下,每条消息省 60% 带宽,积少成多非常可观 |
| gRPC | 服务间通信 | Protobuf 原生支持、双向流、HTTP/2 多路复用。比 REST + JSON 高效一个数量级 |
| RocketMQ | 异步解耦 | 金融级消息可靠性、自带重试和死信队列、支持广播消费(群消息场景刚需)。Kafka 做不到这个级别的消息精确性 |
| MongoDB | 消息存储 | 按 chatId 分片零成本水平扩展、追加写入性能碾压 MySQL、Schema 灵活适配多种消息类型 |
| MySQL | 关系数据 | 好友、群组、用户等强事务场景。MongoDB 做不了复杂事务,各司其职 |
| Redis | 缓存/状态 | 未读计数、在线状态、Token 存储、分布式锁。Redis 单线程模型在 IM 场景下反而是优势------不用担心并发问题 |
| Elasticsearch | 消息搜索 | 全文检索、高亮、分词、分页。MongoDB 的文本搜索和 ES 比就是玩具 |
| Nacos | 配置/注册中心 | 配置热更新是杀手锏------Netty 的 Boss/Worker 线程数、心跳间隔、重试策略全都能在线改,不用重启服务 |
五、部署架构
bash
192.168.1.131 (主节点) 192.168.1.132 (连接节点) 192.168.1.130 (基础设施)
┌─────────────────────┐ ┌─────────────────────┐ ┌───────────────────┐
│ im-gateway (8081) │ │ im-connect (8085) │ │ MySQL │
│ im-auth (8082) │ │ │ │ MongoDB │
│ im-business (8083) │ │ 专门处理 WebSocket │ │ Redis │
│ im-console (8084) │ │ 可以水平扩展多节点 │ │ Nacos │
│ im-data-sync │ │ │ │ RocketMQ │
│ im-social │ │ │ │ Elasticsearch │
│ im-connect (8085) │ │ │ │ MinIO │
└─────────────────────┘ └─────────────────────┘ └───────────────────┘
▲ ▲
│ Nginx 反向代理 │
└───────────────────────────┘
192.168.1.101Docker Compose 部署,所有服务 network_mode: host,直接用宿主机网络,避免 Docker NAT 带来的额外延迟。im-connect 是资源大户,Docker 单独分配了 12G 内存 + ZGC 垃圾回收器 + 百万级文件描述符:
yaml
# docker-compose.yml --- im-connect 的资源配置
im-connect:
image: eclipse-temurin:21-jdk
network_mode: host
deploy:
resources:
limits:
memory: 12G
reservations:
memory: 4G
ulimits:
nofile:
soft: 1048576
hard: 1048576
nproc:
soft: 65535
environment:
- JAVA_OPTS=-XX:+UseZGC -XX:MaxGCPauseMillis=50
-XX:+UseStringDeduplication
-Dio.netty.leakDetection.level=DISABLED为什么 im-connect 用 ZGC 而不是 G1?因为长连接层对延迟极其敏感 。G1 的 STW(Stop-The-World)可能达到几十毫秒,在百万级连接场景下,这几十毫秒会导致大量心跳超时、消息推送延迟雪崩。ZGC 的 pause time 目标是亚毫秒级------这东西调优的时候我是真的对比过 G1 和 ZGC 的 GC 日志,差距肉眼可见。这也是支撑百万连接的关键基础设施之一。
六、Flutter 客户端 + SDK 架构
作为一个后端开发去写 Flutter 客户端,这个经历说起来一把辛酸泪。但回头看看,SDK 的设计还算干净:
bash
Flutter 客户端
├── SDK 层 (xzll-im-flutter-sdk)
│ └── XZLLIMClient (单例,3500+ 行)
│ ├── WebSocket 连接管理(指数退避重连)
│ ├── 消息收发(Protobuf 序列化)
│ ├── 消息去重(内存缓存 1000 条,2 分钟 TTL)
│ ├── 离线队列 (_pendingSends Map)
│ └── SQLite 本地存储
│
└── App 层 (xzll-im-flutter-client)
├── IMSDKManager (GetX Service, 封装 SDK)
├── AppEvent (RxDart 事件总线)
└── UI 层 (GetX: Binding + Controller + View)SDK 的连接管理------指数退避重连,后台切前台自动恢复:
dart
// xzll_im_client.dart --- 指数退避重连
void _scheduleReconnect({bool immediate = false}) {
if (_isManualDisconnect) return;
_reconnectAttempts++;
Duration delay;
if (_isAppInBackground) {
delay = Duration(seconds: 30); // 后台统一 30s,省电
} else {
final delaySeconds = (1 << (_reconnectAttempts - 1)).clamp(1, 30); // 1→2→4→8→16→30
delay = Duration(seconds: delaySeconds);
}
_reconnectTimer = Timer(delay, () => _performReconnect());
}消息发送的离线保障------断网无感知:
dart
// 断网时消息不丢,先进队列,连上后自动 flush
if (!isConnected) {
_enqueuePendingSend(clientMsgId, chatId);
callback?.call(true, clientMsgId: clientMsgId, content: content);
return;
}
_channel?.sink.add(bytes);SDK 和 App 之间通过 RxDart 事件总线解耦,SDK 不依赖任何 UI 框架,可以独立使用:
dart
// AppEvent --- RxDart 事件总线
sealed class AppEvent {
// SDK → UI 的所有事件通道
static PublishSubject<ChatMessage> onMessageReceived = PublishSubject();
static BehaviorSubject<WebSocketStatus> webSocketStatus = BehaviorSubject();
static PublishSubject<Conversation> onConversationUpdated = PublishSubject();
static PublishSubject<Map<String, dynamic>> onReadReceiptReceived = PublishSubject();
// ... 更多事件
}七、总结
回顾整篇文章的核心设计:
- im-connect 和 im-business 必须分开:连接管理吃内存、存储重 IO,生命周期完全不同,独立扩缩容是刚需
- 三层消息路由:本地直推 → gRPC 跨节点转发 → 离线存储,能本地解决的绝不跨网络,延迟从纳秒到毫秒到秒级递增
- RocketMQ 解耦 :连接层和业务层之间异步通信,存储失败不影响消息接收,故障隔离
- 双 ID 体系:clientMsgId 管去重、msgId 管排序、chatId 动态计算不占带宽,每个字段各司其职
- Redis ZSet + Lua 三级重试:5s → 30s → 5min 渐进式重推,LZ4 压缩节省内存,原子认领防并发
- MongoDB 分片 + ES 异步同步:写入和搜索互不影响,ES 挂了聊天照样用
IM干货系列 下一篇预告 :《Protobuf 协议设计:从 JSON 到二进制,我是怎么把消息体积砍掉 60% 的》------ 字段级优化(fixed64 替换 string、bytes 替换 UUID、chatId 动态计算不传)、信封模式设计。
后续计划:百万连接压测实战、LiveKit 音视频调通、直播功能、全链路性能调优等,都是待攻克的硬骨头,感兴趣的持续关注。
如果觉得有用,点个关注不迷路,系列持续更新中~
说明:本文内容基于我此前开源的 XZLL IM 项目的真实架构和源码。项目目前已闭源,不再维护开源版本,但文章中的所有设计思路、代码实现和踩坑经验都来自真实的开发过程,希望对正在做 IM 的同学有帮助。