
一、引言:从"我该信谁?"说起
假设你有一个需要定位的移动目标------一架无人机、一辆自动驾驶汽车,或者阿波罗飞船上的登月舱。你有两个信息来源:
- 一个数学模型:你知道它的大致运动规律(比如匀速直线运动),但模型不完美,还有风、摩擦、推力误差等"过程噪声"。
- 一个传感器:GPS、雷达或激光测距仪能给你位置测量值,但传感器同样不完美,存在"测量噪声"。
问题来了:模型说它在 A 点,传感器说它在 B 点,你该信谁?
如果只信模型,误差会随时间累积(比如惯性导航的漂移)。如果只信传感器,每次测量都独立,你会丢失目标的运动趋势信息,而且在传感器瞬时失效时会完全失控。
你可能会想:"能不能把两者结合起来,各自取长补短?"
这正是卡尔曼滤波 要解决的问题。它用一种简洁而优美的方式,递归地融合模型预测和传感器观测,给出在统计意义下的"最优"估计。
卡尔曼滤波 被公认为 20 世纪最伟大的算法之一。它让阿波罗计划得以成功,让 GPS 变得平滑,让自动驾驶成为可能。它的故事始于 1960 年的一篇论文,那篇论文曾差点被期刊拒稿,却在接下来的几十年里彻底改变了控制、导航、机器人、金融、气象......几乎所有需要从"噪声"中提取"信号"的领域。
二、历史的转折:从卡尔曼到阿波罗
2.1 卡尔曼:被拒稿的"最优估计"
1960 年,匈牙利裔美国数学家鲁道夫·卡尔曼 在斯坦福大学任教。他发表了一篇题为《A New Approach to Linear Filtering and Prediction Problems》的论文,提出了一种递归状态估计算法 ------后来被称为卡尔曼滤波(Kalman Filter)。
 鲁道夫·埃米尔·卡尔曼(Rudolf Emil Kálmán,1930-2016),匈牙利裔美国电机工程师、数学家。
鲁道夫·埃米尔·卡尔曼(Rudolf Emil Kálmán,1930-2016),匈牙利裔美国电机工程师、数学家。
这篇论文的核心思想出奇简洁:用"模型预测"和"测量更新"两个步骤循环往复,每次更新都把两者的不确定性(协方差)融合进去,给出当前时刻的最优估计。这个"预测+更新"的递归结构,使得卡尔曼滤波运算量极小,非常适合计算机实现。
然而,这篇后来被称为"开创性"的论文,最初的投稿历程却异常艰难。卡尔曼自己回忆道,它被ASME 和 IEEE 等权威期刊多次拒稿。审稿人的普遍反应是:"这个结果已知""太简单""不感兴趣"。一位审稿人甚至直言不讳地批评卡尔曼的方法"数学上不严谨",认为它缺乏对收敛性和稳定性的严格证明。面对这类质疑,卡尔曼不得不花费数年时间来完善滤波器的数学基础。
最终,论文于 1961 年发表在《Journal of Basic Engineering》上。而这次投稿,史无前例地同时邀请六位审稿人审核------几乎是被"架在火上烤",但也是学术审稿史上罕见的重视程度。
2.2 斯沃林与阿波罗:从怀疑到信仰
卡尔曼滤波从论文变成工程史传奇,关键转折点来自一位叫理查德·巴顿 (Richard Battin)的工程师。当时他把卡尔曼的论文推荐给了正在为阿波罗登月舱设计导航计算机的NASA 工程师团队。
团队的负责人斯坦利·施密特(Stanley Schmidt)读到这篇论文后,敏锐地意识到:登月舱导航正好是"模型+传感器"的经典问题------惯性导航提供模型预测,但存在漂移;地面雷达和登月舱自身的敏感器提供测量,但存在噪声。卡尔曼滤波正好可以"最优地融合"两者。施密特后来成为卡尔曼滤波在阿波罗项目中落地的核心推动者。
然而,并非所有人都像施密特一样乐观。约翰·斯沃林(John S. Swearingen)就是一位著名的怀疑者。他和他的团队曾在 1964 年提交了一份报告,尖锐地指出:卡尔曼滤波从理论上来看不适合阿波罗导航,因为计算量太大、数值稳定性差。这个判断几乎让 NASA 放弃了这一方案。
转机出现在 1966 年。在一次关键飞行测试中,用于验证卡尔曼滤波算法的数据被证明极大优于传统方法------位置误差从数英里缩小到几百米。斯沃林事后在传记中承认:"事实胜于一切。"
最终,阿波罗计划的导航计算机(AGC)中,卡尔曼滤波成为了登月舱与指令舱导航的核心算法。1969 年 7 月 20 日,当阿姆斯特朗和奥尔德林踏上月球时,他们的位置估计,正是卡尔曼滤波实时输出的结果。
2.3 卡尔曼滤波的遗产
卡尔曼滤波的应用早已不限于登月。在 GPS 导航中,它把卫星信号和惯性传感器平滑融合,让你手机上的蓝点不再乱跳。在自动驾驶中,它融合激光雷达、摄像头和毫米波雷达的多传感器数据,实时估计车辆位置和速度。在机器人中,扩展卡尔曼滤波(EKF)用于同时定位与地图构建(SLAM),让扫地机器人能边探索边建图。在金融中,它用于估计隐含的波动率和动态系统状态。在气象中,**集合卡尔曼滤波(EnKF)**是数值天气预报的数据同化核心算法。
甚至可以说:在任何一个需要实时从噪声中提取状态估计的领域,都能看到卡尔曼滤波的身影。
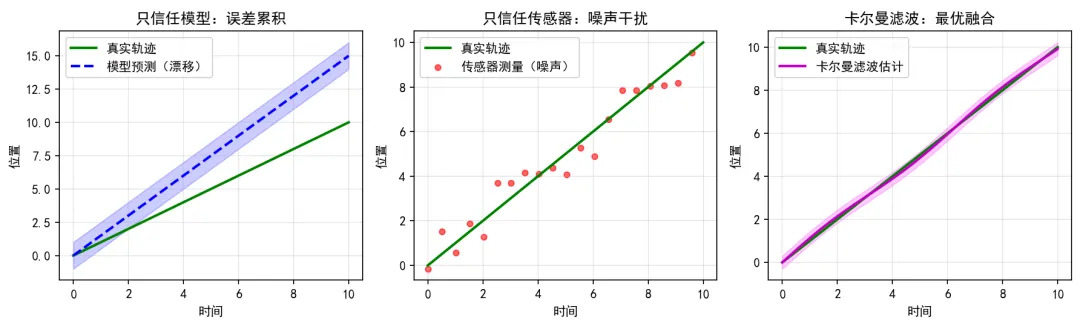 图1:卡尔曼滤波核心思想------模型预测的漂移(左)、传感器测量的噪声(中)、以及卡尔曼滤波的最优融合(右)。蓝色区域表示不确定性,融合后估计的不确定性显著降低。
图1:卡尔曼滤波核心思想------模型预测的漂移(左)、传感器测量的噪声(中)、以及卡尔曼滤波的最优融合(右)。蓝色区域表示不确定性,融合后估计的不确定性显著降低。
三、从直觉到数学:一个"互补滤波"的例子
在进入完整卡尔曼滤波之前,我们先从一个更简单的例子------"互补滤波"------开始,体会"模型预测 + 测量修正"的基本思路。
假设你想估计一个角度 θ\thetaθ。你有两个信息来源:
- 陀螺仪 (Gyroscope):测量角速度 ω\omegaω,可以通过积分得到角度预测。但积分存在漂移,长期误差会累积。
- 加速度计(Accelerometer):直接测量角度,但瞬时噪声大,短期抖动明显。
互补滤波的思路非常简单:
θ^=α⋅(θ^gyro)+(1−α)⋅(θaccel) \hat{\theta} = \alpha \cdot (\hat{\theta}{\text{gyro}}) + (1 - \alpha) \cdot (\theta{\text{accel}}) θ^=α⋅(θ^gyro)+(1−α)⋅(θaccel)
它给陀螺仪(模型)和加速度计(测量)各分配一个权重,α\alphaα 接近 1 时更信任模型,α\alphaα 接近 0 时更信任测量。但互补滤波的权重是固定的,它不会根据噪声的变化随时调整。如果你做一次实验,运动很平滑,加速度计的噪声很小,你可能希望多相信它一点;如果突然遇到剧烈抖动,你又希望多相信陀螺仪的积分。
卡尔曼滤波正是"互补滤波"的智能升级版 :它也会做"模型预测 + 测量修正"这样的加权融合,但权重不是固定的,而是根据当前对各自不确定性的估计动态调整。估计更精准的一方,权重更高;更不确定的一方,权重更低。
这种"自适应加权"正是卡尔曼滤波被称为"最优估计"的核心原因。
四、卡尔曼滤波的数学本质:递归贝叶斯估计
要真正理解卡尔曼滤波,需要从三个维度来认识它的数学本质:递归贝叶斯估计、状态空间模型,以及它与傅里叶变换在哲学上的对偶关系。
4.1 本质一:递归贝叶斯估计器
卡尔曼滤波首先是一个递归贝叶斯估计器。贝叶斯公式告诉我们,后验 = 似然 × 先验 / 证据。在卡尔曼滤波中:
- 先验 :由模型预测得到的 x^k∣k−1\hat{\mathbf{x}}{k|k-1}x^k∣k−1 及其协方差 Pk∣k−1\mathbf{P}{k|k-1}Pk∣k−1
- 似然 :当前测量 zkz_kzk 在给定状态下的概率分布
- 后验 :更新后的最优估计 x^k\hat{\mathbf{x}}_kx^k 及其协方差 Pk\mathbf{P}_kPk
递归的含义 :每一次迭代的后验,成为下一次迭代的先验。卡尔曼滤波不需要存储历史数据,每一时刻的计算只依赖上一时刻的"充分统计量 "(均值和协方差)。这是它与批处理最小二乘法的根本区别------批处理需要保存所有历史数据并全局重新计算,而卡尔曼滤波的每一轮计算量恒定。
高斯假设的妙用 :当噪声服从高斯分布时,条件概率分布完全由均值和协方差刻画。卡尔曼滤波的五个方程,本质上是高斯分布在线性动态系统下的精确贝叶斯递推解。
一个重要边界 :如果噪声不是高斯的,卡尔曼滤波不再是最优贝叶斯估计,但它仍然是"最佳线性无偏估计(BLUE,Best Linear Unbiased Estimator)"------在所有线性估计器中表现最优。这个区别至关重要:
| 维度 | 高斯噪声 | 非高斯噪声 |
|---|---|---|
| 估计类型 | 最优贝叶斯估计(MMSE = MAP) | 最佳线性无偏估计(BLUE) |
| 后验分布 | 精确高斯,完全刻画 | 未知,仅有均值和协方差 |
| 最优性范围 | 所有估计器(包括非线性) | 仅限线性估计器 |
| 充分统计量 | 均值和协方差(充分) | 均值和协方差(不充分) |
在实践中,即使噪声不完全高斯(例如 GPS 信号偶尔出现"野值"),卡尔曼滤波依然表现良好。这是因为中心极限定理保证了大量独立噪声的叠加趋近于高斯分布,且卡尔曼滤波的线性结构本身具有一定的鲁棒性。
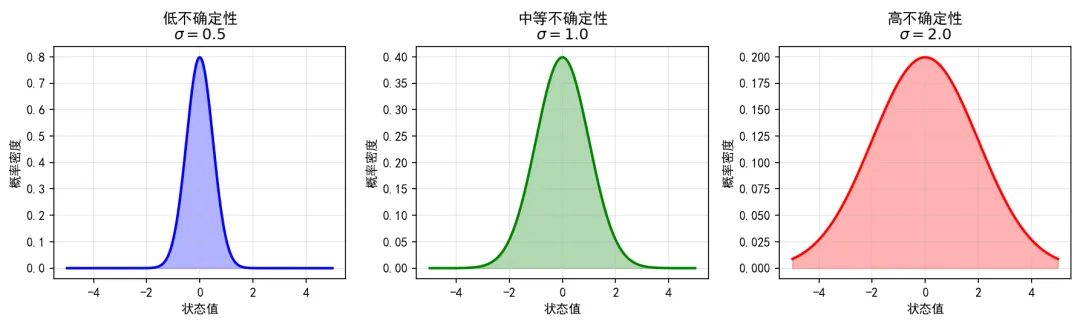 图2:高斯分布与不确定性。卡尔曼滤波假设所有噪声服从高斯分布,分布的方差σ²量化了估计的不确定度------方差越大,曲线越"扁宽",信息越模糊。
图2:高斯分布与不确定性。卡尔曼滤波假设所有噪声服从高斯分布,分布的方差σ²量化了估计的不确定度------方差越大,曲线越"扁宽",信息越模糊。
4.2 本质二:状态空间模型------线性系统的另一种表示
卡尔曼滤波的第二个本质是它基于状态空间模型 。传统控制理论用传递函数 描述系统(输入-输出的频域关系)。状态空间模型则用一阶差分/微分方程组描述系统的内部演化。
| 维度 | 传递函数(频域) | 状态空间模型(时域) |
|---|---|---|
| 视角 | 黑箱:只关心输入输出关系 | 白箱:显式建模内部状态 |
| 数学形式 | 有理分式 G(s)=Y(s)U(s)G(s) = \frac{Y(s)}{U(s)}G(s)=U(s)Y(s) | \\dot{x}=Ax+Bu y=Cx+Duy=Cx+Duy=Cx+Du |
| 处理能力 | 单输入单输出(SISO)为主 | 天然支持多输入多输出(MIMO) |
| 初始状态 | 通常假设零初始条件 | 显式包含初始状态估计 |
| 噪声处理 | 困难 | 自然融入过程噪声和测量噪声 |
卡尔曼滤波之所以适合"状态空间模型",正是因为:它要估计的恰好是那些不可直接测量的内部状态。比如惯性导航中的"速度"和"姿态角",你无法直接测量,但可以通过加速度计和陀螺仪的读数递推估计。状态空间模型给了卡尔曼滤波一个清晰的"对象"------状态------去追踪和修正。
4.3 本质三:与傅里叶变换的哲学对偶
卡尔曼滤波与傅里叶变换构成了信号处理中两种互补的范式:
傅里叶变换 :将一个时间序列分解为不同频率的正余弦波的叠加。它回答的是"信号的能量在频率上如何分布"。在通信工程中,你用傅里叶变换分析信道特性、设计滤波器(低通、高通、带通),本质上是在频域上做"信号与噪声的分离"。
卡尔曼滤波 :在线性动态系统上处理"状态"和"噪声"。它回答的是"系统当前处于什么状态",以及"模型和测量各自的不确定性有多大"。它做的是在状态空间中动态融合模型与数据。
| 维度 | 傅里叶变换 / 频域滤波 | 卡尔曼滤波 |
|---|---|---|
| 核心概念 | 频率、幅度、相位 | 状态、协方差、增益 |
| 分离对象 | 信号 vs 噪声(基于频率) | 模型预测 vs 传感器测量(基于不确定性) |
| 先验假设 | 信号和噪声频带不重叠 | 线性动态 + 高斯噪声 |
| 输出 | 滤波后的信号 | 状态的最优估计 + 不确定度 |
| 实时性 | 需要整段信号或加窗 | 天然递归,每步更新 |
一个有趣的交叉点:在 GPS/INS 组合导航中,卡尔曼滤波输出的位置误差序列,有时也会被送入低通滤波器 或小波滤波器做后处理,去除残留的高频噪声。这就是"状态空间"和"频域"两种滤波视角的联姻。
4.4 一个统一的视角:信息融合的谱系
如果上升到"信息融合"的抽象层面,可以画出一条"确定性-概率性"的谱系:
- 确定性方法:互补滤波(固定权重)、低通滤波(固定截止频率)
- 概率性方法:卡尔曼滤波(线性高斯)、扩展卡尔曼滤波(非线性)、无迹卡尔曼滤波(非线性更好)、粒子滤波(非高斯、强非线性)
卡尔曼滤波恰好处于这条谱系的**"简洁与强大"的平衡点**:比确定性方法更智能(自适应加权),比粒子滤波更高效(解析递推)。这也是为什么它自 1960 年代以来经久不衰------它在计算复杂度和估计精度之间给出了一个黄金分割。
这三种本质身份共同解释了卡尔曼滤波为什么能跨越航空航天、机器人、金融、气象等看似不相关的领域------因为它触及的,是"在不确定性中做最优推理"这个更底层的数学命题。
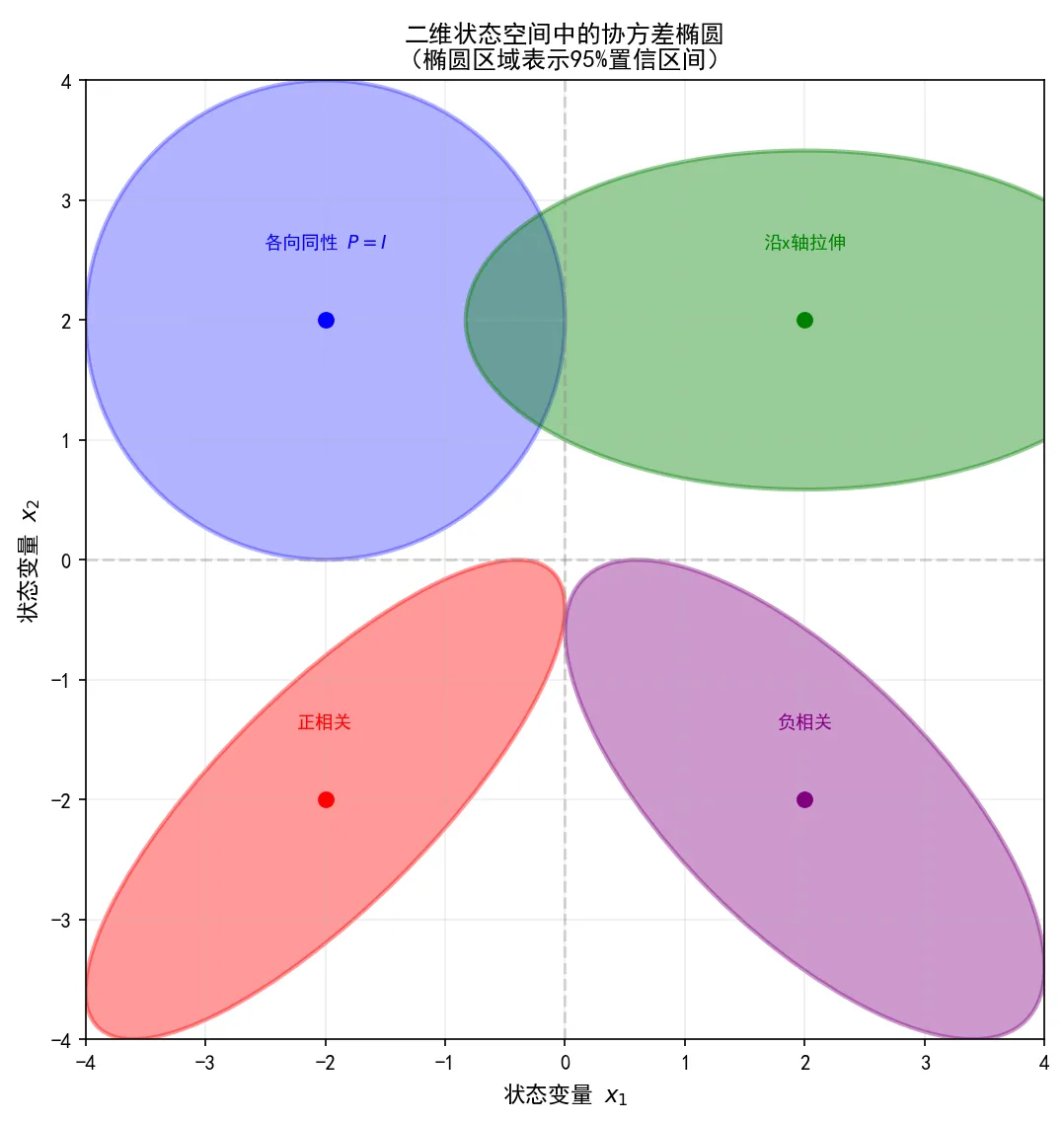 图3:二维状态空间中的协方差椭圆(95%置信区间)。椭圆形状反映了两个状态变量之间的相关性:正相关(红色)、负相关(紫色)、各向同性(蓝色)。
图3:二维状态空间中的协方差椭圆(95%置信区间)。椭圆形状反映了两个状态变量之间的相关性:正相关(红色)、负相关(紫色)、各向同性(蓝色)。
五、状态空间模型:系统的数学语言
卡尔曼滤波适用的系统,通常用状态空间模型描述。状态是描述系统当前状况的最少变量集合,比如:
- 无人机:位置 x,y,zx, y, zx,y,z、速度 vx,vy,vzv_x, v_y, v_zvx,vy,vz、姿态角等
- 汽车:位置、速度、偏航角等
- 登月舱:位置、速度、加速度偏差等
状态转移模型(预测方程) 描述状态随时间的变化:
xk=Fk−1xk−1+Bk−1uk−1+wk−1 \mathbf{x}{k} = \mathbf{F}{k-1} \mathbf{x}{k-1} + \mathbf{B}{k-1} \mathbf{u}{k-1} + \mathbf{w}{k-1} xk=Fk−1xk−1+Bk−1uk−1+wk−1
其中 wk−1∼N(0,Qk−1)\mathbf{w}{k-1} \sim \mathcal{N}(0, \mathbf{Q}{k-1})wk−1∼N(0,Qk−1) 是过程噪声(模型的不确定性)。
观测模型(测量方程) 描述传感器读数与状态的关系:
zk=Hkxk+vk \mathbf{z}{k} = \mathbf{H}{k} \mathbf{x}{k} + \mathbf{v}{k} zk=Hkxk+vk
其中 vk∼N(0,Rk)\mathbf{v}{k} \sim \mathcal{N}(0, \mathbf{R}{k})vk∼N(0,Rk) 是测量噪声(传感器的不确定性)。
卡尔曼滤波的基本假设是:过程噪声和测量噪声都是零均值高斯白噪声,且互不相关。当噪声不是高斯时,卡尔曼滤波不再是最优的,但仍常作为"最佳线性无偏估计(BLUE)"使用。
六、卡尔曼滤波的"两步走"算法
卡尔曼滤波的核心是一个**"预测-更新"循环**:
6.1 预测(时间更新)
状态预测 :用上一时刻的最优估计 x^k−1\hat{\mathbf{x}}_{k-1}x^k−1 预测当前时刻的状态:
x^k∣k−1=Fk−1x^k−1+Bk−1uk−1 \hat{\mathbf{x}}{k|k-1} = \mathbf{F}{k-1} \hat{\mathbf{x}}{k-1} + \mathbf{B}{k-1} \mathbf{u}_{k-1} x^k∣k−1=Fk−1x^k−1+Bk−1uk−1
协方差预测:同时预测估计的不确定性(协方差矩阵):
Pk∣k−1=Fk−1Pk−1Fk−1T+Qk−1 \mathbf{P}{k|k-1} = \mathbf{F}{k-1} \mathbf{P}{k-1} \mathbf{F}{k-1}^T + \mathbf{Q}_{k-1} Pk∣k−1=Fk−1Pk−1Fk−1T+Qk−1
这一步回答了"模型告诉我们应该在哪",以及"我们对这个预测有多大把握"。
6.2 更新(测量更新)
计算卡尔曼增益:决定模型预测和传感器测量各自的权重:
Kk=Pk∣k−1HkT(HkPk∣k−1HkT+Rk)−1 \mathbf{K}k = \mathbf{P}{k|k-1} \mathbf{H}_k^T (\mathbf{H}k \mathbf{P}{k|k-1} \mathbf{H}_k^T + \mathbf{R}_k)^{-1} Kk=Pk∣k−1HkT(HkPk∣k−1HkT+Rk)−1
卡尔曼增益 Kk\mathbf{K}_kKk 是核心。它的取值体现了"当前更应该相信谁":当测量噪声 Rk\mathbf{R}_kRk 很大时,Kk→0\mathbf{K}k \to 0Kk→0,更相信模型;当模型预测本身很不确定(Pk∣k−1\mathbf{P}{k|k-1}Pk∣k−1 很大)时,Kk→Hk−1\mathbf{K}_k \to \mathbf{H}_k^{-1}Kk→Hk−1,更相信测量。
状态更新 :用当前测量 zk\mathbf{z}_kzk 修正状态预测:
x^k=x^k∣k−1+Kk(zk−Hkx^k∣k−1) \hat{\mathbf{x}}k = \hat{\mathbf{x}}{k|k-1} + \mathbf{K}_k (\mathbf{z}_k - \mathbf{H}k \hat{\mathbf{x}}{k|k-1}) x^k=x^k∣k−1+Kk(zk−Hkx^k∣k−1)
协方差更新:更新估计的不确定性:
Pk=(I−KkHk)Pk∣k−1 \mathbf{P}_k = (\mathbf{I} - \mathbf{K}_k \mathbf{H}k) \mathbf{P}{k|k-1} Pk=(I−KkHk)Pk∣k−1
这个递归过程不需要存储历史数据,只依赖上一时刻的估计和当前测量,非常适合实时系统。
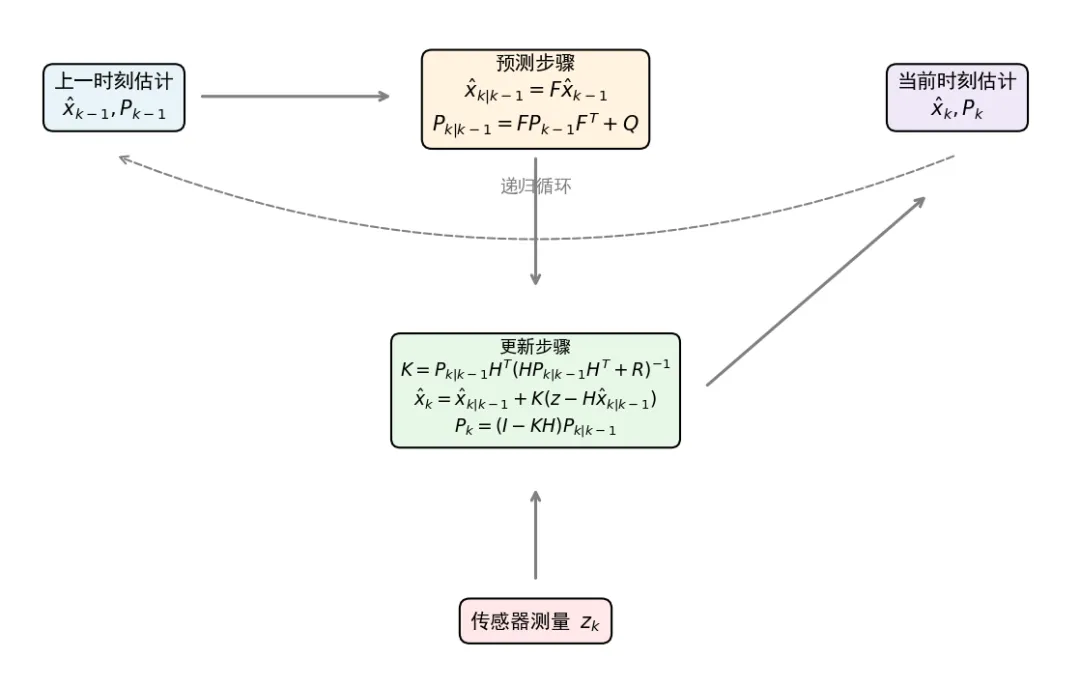 图4:卡尔曼滤波的预测-更新递归循环。每一轮迭代包含"时间更新(预测)"和"测量更新(修正)"两个步骤,上一时刻的后验成为下一时刻的先验。
图4:卡尔曼滤波的预测-更新递归循环。每一轮迭代包含"时间更新(预测)"和"测量更新(修正)"两个步骤,上一时刻的后验成为下一时刻的先验。
七、一个一维的数值例子
假设你用一个传感器测量一辆汽车的位置,测量值 zkz_kzk,测量噪声方差 R=1R = 1R=1。汽车做匀速运动,速度 v=1v = 1v=1,一个简单的状态空间模型是:
xk=xk−1+v⋅Δt=xk−1+1 x_k = x_{k-1} + v \cdot \Delta t = x_{k-1} + 1 xk=xk−1+v⋅Δt=xk−1+1
过程噪声方差 Q=0.1Q = 0.1Q=0.1,初始估计 x^0=0\hat{x}_0 = 0x^0=0,初始协方差 P0=1P_0 = 1P0=1。下面我们逐步迭代,观察滤波器如何从不确定中收敛。
第1步(k = 1)
预测 :
x^1∣0=x^0+1=0+1=1 \hat{x}_{1|0} = \hat{x}_0 + 1 = 0 + 1 = 1 x^1∣0=x^0+1=0+1=1
P1∣0=P0+Q=1+0.1=1.1 P_{1|0} = P_0 + Q = 1 + 0.1 = 1.1 P1∣0=P0+Q=1+0.1=1.1
卡尔曼增益 :
K1=P1∣0P1∣0+R=1.11.1+1≈0.524 K_1 = \frac{P_{1|0}}{P_{1|0} + R} = \frac{1.1}{1.1 + 1} \approx 0.524 K1=P1∣0+RP1∣0=1.1+11.1≈0.524
假设传感器测量值为 z1=1.2z_1 = 1.2z1=1.2。
更新 :
x^1=x^1∣0+K1(z1−x^1∣0)=1+0.524×(1.2−1)≈1.105 \hat{x}1 = \hat{x}{1|0} + K_1 (z_1 - \hat{x}_{1|0}) = 1 + 0.524 \times (1.2 - 1) \approx 1.105 x^1=x^1∣0+K1(z1−x^1∣0)=1+0.524×(1.2−1)≈1.105
P1=(1−K1)P1∣0=(1−0.524)×1.1≈0.524 P_1 = (1 - K_1) P_{1|0} = (1 - 0.524) \times 1.1 \approx 0.524 P1=(1−K1)P1∣0=(1−0.524)×1.1≈0.524
第2步(k = 2)
预测 :
x^2∣1=x^1+1=1.105+1=2.105 \hat{x}_{2|1} = \hat{x}_1 + 1 = 1.105 + 1 = 2.105 x^2∣1=x^1+1=1.105+1=2.105
P2∣1=P1+Q=0.524+0.1=0.624 P_{2|1} = P_1 + Q = 0.524 + 0.1 = 0.624 P2∣1=P1+Q=0.524+0.1=0.624
卡尔曼增益 :
K2=P2∣1P2∣1+R=0.6240.624+1≈0.384 K_2 = \frac{P_{2|1}}{P_{2|1} + R} = \frac{0.624}{0.624 + 1} \approx 0.384 K2=P2∣1+RP2∣1=0.624+10.624≈0.384
假设传感器测量值为 z2=2.3z_2 = 2.3z2=2.3。
更新 :
x^2=x^2∣1+K2(z2−x^2∣1)=2.105+0.384×(2.3−2.105)≈2.180 \hat{x}2 = \hat{x}{2|1} + K_2 (z_2 - \hat{x}_{2|1}) = 2.105 + 0.384 \times (2.3 - 2.105) \approx 2.180 x^2=x^2∣1+K2(z2−x^2∣1)=2.105+0.384×(2.3−2.105)≈2.180
P2=(1−K2)P2∣1=(1−0.384)×0.624≈0.384 P_2 = (1 - K_2) P_{2|1} = (1 - 0.384) \times 0.624 \approx 0.384 P2=(1−K2)P2∣1=(1−0.384)×0.624≈0.384
前5步结果汇总
继续迭代至第5步,得到如下结果(计算过程省略,方法与第1、2步相同):
| 时刻 kkk | 预测位置 xpredx_{pred}xpred | 预测协方差 PpredP_{pred}Ppred | 卡尔曼增益 KKK | 测量值 zkz_kzk | 更新后估计 x^k\hat{x}_kx^k | 更新后协方差 PkP_kPk |
|---|---|---|---|---|---|---|
| 1 | 1.000 | 1.100 | 0.524 | 1.2 | 1.105 | 0.524 |
| 2 | 2.105 | 0.624 | 0.384 | 2.3 | 2.180 | 0.384 |
| 3 | 3.180 | 0.484 | 0.326 | 3.5 | 3.284 | 0.326 |
| 4 | 4.284 | 0.426 | 0.299 | 4.1 | 4.229 | 0.299 |
| 5 | 5.229 | 0.399 | 0.285 | 5.0 | 5.164 | 0.285 |
观察与分析
从上表可以观察到几个重要趋势:
-
卡尔曼增益 KKK 逐渐减小 :从第1步的 0.524 下降到第5步的 0.285。这是因为随着时间推移,滤波器对自身估计的信心越来越强(协方差 PkP_kPk 从 0.524 降至 0.285),因此对新测量的依赖程度逐渐降低。这是卡尔曼滤波"自适应加权"特性的直接体现。
-
估计值平滑逼近真实轨迹 :真实位置是 x=kx = kx=k(即 1, 2, 3, 4, 5),而滤波估计值分别为 1.105, 2.180, 3.284, 4.229, 5.164。虽然测量值存在噪声(例如第3步测量值 3.5 明显偏高,第4步 4.1 明显偏低),但滤波器没有被"带偏",而是平滑地追踪真实位置。
-
协方差 PkP_kPk 单调递减:从 0.524 → 0.384 → 0.326 → 0.299 → 0.285。这说明滤波器对自身估计的不确定性在持续降低------每一轮更新都在"学习",对状态的把握越来越准。
-
鲁棒性体现 :注意第4步的测量值 4.1 远低于预测值 4.284,但滤波器只将估计值从 4.284 修正到 4.229(修正量仅 0.055),而不是直接跳到 4.1。这是因为此时的增益 K4=0.299K_4 = 0.299K4=0.299 已经较小,滤波器更信任自己的模型预测。这正是卡尔曼滤波在噪声环境下的优雅之处:它不会因为一次异常测量而剧烈震荡,而是在长期中平稳收敛。
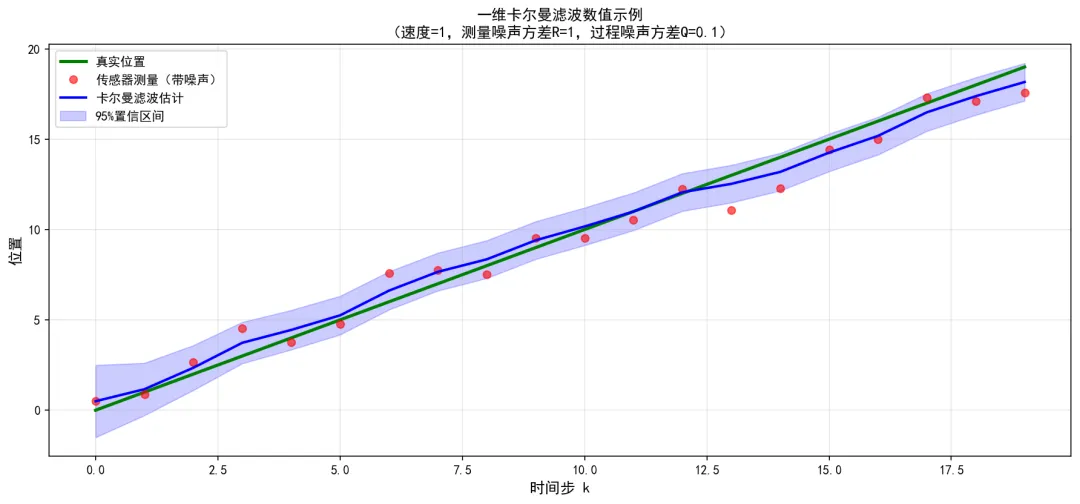 图5:一维卡尔曼滤波数值示例。红色散点为含噪声的传感器测量,蓝色实线为卡尔曼滤波估计,蓝色半透明带为95%置信区间。滤波器在20个时间步内成功抑制了噪声,估计值平滑地接近真实轨迹(绿色)。
图5:一维卡尔曼滤波数值示例。红色散点为含噪声的传感器测量,蓝色实线为卡尔曼滤波估计,蓝色半透明带为95%置信区间。滤波器在20个时间步内成功抑制了噪声,估计值平滑地接近真实轨迹(绿色)。
八、超越卡尔曼:当高斯假设不再成立时
卡尔曼滤波在高斯线性系统中是最优的。然而,现实世界往往更复杂。当噪声明显非高斯(如多模态分布、重尾分布、有界噪声)或系统呈现强非线性时,线性估计可能不够好。此时工程师可以根据具体问题选择更先进的滤波方法:
8.1 扩展卡尔曼滤波(EKF,Extended Kalman Filter)
EKF 是卡尔曼滤波在非线性系统上的直接推广。其核心思想是将非线性函数进行一阶泰勒展开(线性化),然后在局部用标准卡尔曼滤波递推。
优点:计算量较小,工程实现成熟,是 SLAM 和无人机导航等领域的经典选择。
缺点:线性化会引入近似误差;对于强非线性系统,EKF 可能发散;仍然假设噪声为高斯分布。
8.2 无迹卡尔曼滤波(UKF,Unscented Kalman Filter)
UKF 用另一种方式处理非线性:它选取一组精心设计的"Sigma 点",让这些点经过非线性变换后,用变换后的点集重新拟合高斯分布(均值和协方差)。这种方法被称为无迹变换(Unscented Transform)。
优点:比 EKF 更精确(二阶精度 vs 一阶精度),不需要计算雅可比矩阵,对适度非线性的系统表现优异。
缺点:计算量略高于 EKF(但仍属同一量级);仍然假设噪声为高斯分布。
8.3 粒子滤波(Particle Filter)
粒子滤波是完全抛弃高斯假设的非参数贝叶斯滤波。它用大量随机采样点("粒子")来近似任意的后验概率分布,每个粒子代表一个可能的状态假设,通过"预测-加权-重采样"的过程递推更新。
优点:可以处理任意非高斯、多模态分布;适用于高度非线性的系统;理论上随着粒子数增加,估计趋近于真实后验。
缺点:计算量极大(通常需要数千到数万个粒子);存在粒子退化问题;实时性要求高的场景(如自动驾驶)往往难以承受其计算开销。
8.4 H∞ 滤波(H-infinity Filter)
与前三种概率方法不同,H∞ 滤波采用鲁棒控制 的视角。它不假设噪声的统计分布,而是假设噪声是有界的(但界未知),目标是最小化最差情况下的估计误差(即极小化极大问题)。
优点:对模型不确定性和噪声的鲁棒性强;不需要噪声的统计假设。
缺点:估计精度通常不如卡尔曼滤波(在噪声确实为高斯时);需要调节一个阈值参数,工程调参较复杂。
8.5 方法对比总览
| 方法 | 非线性处理 | 高斯假设 | 计算量 | 典型应用场景 |
|---|---|---|---|---|
| 标准卡尔曼滤波 | 仅线性系统 | 需要 | 低 | GPS/INS 组合导航、金融时间序列 |
| 扩展卡尔曼滤波(EKF) | 一阶线性化 | 需要 | 中低 | 机器人 SLAM、无人机姿态估计 |
| 无迹卡尔曼滤波(UKF) | 无迹变换(二阶) | 需要 | 中 | 卫星轨道确定、电池状态估计 |
| 粒子滤波 | 完全非线性 | 不需要 | 高 | 机器人定位(非高斯噪声)、目标追踪 |
| H∞ 滤波 | 可扩展 | 不需要 | 中 | 鲁棒控制、恶劣环境下的导航 |
工程选择的经验法则:
- 系统线性、噪声接近高斯 → 标准卡尔曼滤波
- 系统弱非线性、仍可接受高斯假设 → EKF 或 UKF(UKF 通常更精确)
- 系统强非线性、计算资源充足 → 粒子滤波
- 噪声统计特性未知、对鲁棒性要求极高 → H∞ 滤波
- 噪声明显非高斯(如多模态、重尾)→ 粒子滤波或专门的非高斯滤波器
九、卡尔曼滤波改变了什么
1. 阿波罗计划与航空航天
卡尔曼滤波最早的成功应用就是阿波罗登月舱的导航系统。惯性导航存在漂移,地面雷达信号存在延迟和噪声,卡尔曼滤波在登月舱上融合了惯性传感器、雷达测距、星敏感器等多种数据源,精确估计出位置和速度。
2. GPS 与导航
你的手机里,GPS 信号(几米精度)和惯性传感器(短期精确但长期漂移)通过卡尔曼滤波平滑融合,让你看到平滑移动的蓝点,而不是跳跃、乱飘的位置。
3. 自动驾驶
一辆自动驾驶汽车上,激光雷达、摄像头、毫米波雷达、GPS、惯性测量单元(IMU)等多传感器数据的融合,由卡尔曼滤波或其变体完成。车道线检测的输出、雷达的目标跟踪、车身姿态估计,最终都会被送入一个多层卡尔曼滤波框架。
4. 机器人 SLAM
扫地机器人为什么会"认识"你家?它使用同时定位与地图构建 (SLAM)算法,其中的核心模块就是扩展卡尔曼滤波(EKF)。机器人在行走中不断估计自己的位置与姿态,同时建立环境地图。
5. 金融与经济
卡尔曼滤波也被用于动态系统的建模中:算法交易中估计隐含的波动率,宏观经济模型中估计不可观测的状态变量(如潜在 GDP、通胀趋势),比固定系数的回归更灵活。
6. 气象与气候
数值天气预报 中的"数据同化"模块的核心算法之一就是集合卡尔曼滤波(EnKF)。它将观测数据(卫星、雷达)与数值预报模型结果融合,从而得到更准确的初始条件。
九、结语:不确定世界中的最优估计
卡尔曼滤波想解决的问题其实很朴素:当模型和测量都不完美时,如何折中?传统方法要么"全信模型",要么"全信测量"。卡尔曼滤波的回答是:谁更确定,就多信谁一点。
这种"不确定度的动态加权",正是卡尔曼滤波的核心智慧。它不要求你放弃模型,也不要求你抛弃传感器,而是把它们放在同一个数学框架下,让不确定性自己说话。
站在更高的视角看,卡尔曼滤波本质上是三件事的统一:它是一个递归贝叶斯估计器 ,用后验不断更新先验;它建立在状态空间模型之上,显式追踪系统的内部状态;它与傅里叶变换构成哲学上的对偶------一个在频域分离信号与噪声,一个在状态空间融合模型与测量。
从 1960 年那篇被拒稿的论文,到阿波罗登月的工程传奇,再到今天每一部手机里的导航芯片------卡尔曼滤波走出了一条奇怪而悠长的路:从最枯燥的控制理论,走向最浪漫的月球,再回到每个人口袋里。
这正是数学的力量:它不会消灭不确定,但它教会我们如何在不确定中,做出最优的选择。
参考文献
- Kalman, R. E. (1960). A new approach to linear filtering and prediction problems. Journal of Basic Engineering, 82(1), 35-45.
- Kalman, R. E., & Bucy, R. S. (1961). New results in linear filtering and prediction theory. Journal of Basic Engineering, 83(1), 95-108.
- Grewal, M. S., & Andrews, A. P. (2014). Kalman Filtering: Theory and Practice Using MATLAB. John Wiley & Sons.
- Maybeck, P. S. (1979). Stochastic Models, Estimation, and Control. Academic Press.
- Welch, G., & Bishop, G. (1995). An introduction to the Kalman filter. UNC Chapel Hill Technical Report.